
Тот, кто сегодня работает с искусственным интеллектом, первым делом думает о ChatGPT или подобных онлайн-сервисах. Вы вводите вопрос, ждете несколько секунд - и получаете ответ, как будто на другом конце линии сидит очень начитанный и терпеливый собеседник. Но о чем легко забыть: Каждый ввод, каждое предложение, каждое слово отправляется через Интернет на внешние серверы. Именно там происходит настоящая работа - на огромных компьютерах, которые вы никогда не увидите своими глазами.
В принципе, локальная языковая модель работает точно так же - но без Интернета. Модель хранится в виде файла на компьютере пользователя, загружается в рабочую память при запуске и отвечает на вопросы прямо на устройстве. В основе лежит та же технология: нейронная сеть, которая понимает язык, генерирует тексты и распознает паттерны. Разница лишь в том, что все вычисления остаются внутри компании. Можно сказать: ChatGPT без облака.
Особенность в том, что технология развилась настолько, что больше не зависит от огромных центров обработки данных. Современные компьютеры Apple с процессорами M (например, M3 или M4) обладают огромной вычислительной мощностью, быстрым доступом к памяти и специализированным нейронным движком для машинного обучения. Это означает, что многие модели теперь могут работать непосредственно на Mac Mini или Mac Studio - без серверной фермы, без сложной настройки и без значительного шума.


Последние новости о Apple MLX и NVIDIA
26.03.2026: Apple продолжает стратегически развивать свою систему искусственного интеллекта MLX и все больше открывает ее для других платформ. Изначально оптимизированная исключительно для Apple Silicon, MLX теперь также поддерживает графические процессоры CUDA и, следовательно, классическое оборудование Nvidia. Это устраняет ключевое препятствие для разработчиков: до сих пор модели часто приходилось разрабатывать на Mac, а затем обучать на отдельных высокопроизводительных системах. Благодаря открытию MLX становится более гибкой платформой разработки, позволяющей проводить как локальный ИИ на устройствах Apple, так и масштабируемое обучение на внешнем оборудовании. В то же время сохраняется преимущество тесной интеграции с собственной архитектурой Apple, например, за счет эффективного управления памятью и прямого использования GPU. Эта разработка указывает на стратегическую смену курса: Apple постепенно выходит из своей закрытой экосистемы и позиционирует MLX как серьезную альтернативу устоявшимся фреймворкам ИИ - с потенциальными последствиями для развития ИИ в целом.
Это открывает новые возможности не только для разработчиков, но и для предпринимателей, авторов, юристов, врачей, учителей и ремесленников. Теперь каждый может иметь свой собственный маленький ИИ - на своем столе, под полным контролем, готовый к использованию в любое время. Локальная языковая модель может:
- Тексты обобщить или исправить,
- Электронные письма формулировать или структурировать,
- Вопросы отвечать на вопросы и анализировать знания,
- Процессы поддержка в программах,
- Документы поиск или классификация,
- или просто как личный помощник Не допуская утечки данных во внешний мир.
Такой подход становится все более актуальным, особенно в то время, когда защита данных и цифровой суверенитет вновь выходят на первый план. Чтобы использовать эту систему, не нужно быть программистом - достаточно иметь современный Mac. Модели можно просто запустить через приложение или окно терминала, а затем реагировать на них почти так же естественно, как на окно чата в браузере.
В этой статье рассказывается о том, какие модели сегодня можно запустить на Mac, что для этого нужно сделать и почему компьютеры Apple Silicon особенно подходят для этого. Короче говоря, речь идет о том, как вернуть мощь искусственного интеллекта в свои руки - тихо, эффективно и локально.
Локальные языковые модели на Mac - почему это имеет смысл сейчас
Запуск языковой модели „локально“ означает, что она работает исключительно на вашем компьютере - без подключения к облачному сервису. Вычисления, анализ вводимых данных, генерация текстов или ответов - все происходит непосредственно на вашем устройстве. Модель хранится в виде файла на SSD, загружается в оперативную память при запуске и работает там с полной производительностью системы.
Ключевое отличие от облачного варианта - независимость. Данные не передаются через Интернет, не используются внешние серверы, и никто не может отследить, что обрабатывается внутри компании. Это обеспечивает значительную степень защиты и контроля данных - особенно в условиях, когда отследить их перемещение становится все сложнее.
В прошлом локальная работа таких моделей была немыслима. Чтобы поддерживать нейронную сеть такого размера в рабочем состоянии, требовался мейнфрейм или ферма графических процессоров. Сегодня, благодаря вычислительной мощности современных чипов Apple-Silicon, это можно реализовать на настольном устройстве - эффективно, тихо и с низким энергопотреблением.
Почему Apple Silicon - идеальный вариант
С переходом на Apple Silicon перетасовал карты. Вместо классической архитектуры Intel с раздельными CPU и GPU в Apple используется так называемый унифицированный дизайн памяти: процессор, графика и нейронный движок обращаются к одной и той же быстрой основной памяти. Это устраняет необходимость копирования данных между отдельными компонентами - решающее преимущество для вычислений в области искусственного интеллекта.
Нейронный движок - это специализированное вычислительное ядро для машинного обучения, интегрированное непосредственно в чипы. Он позволяет выполнять миллиарды вычислительных операций в секунду при очень низком энергопотреблении. Вместе с библиотекой MLX (Machine Learning for Apple Silicon) и современными фреймворками, такими как OLaMA, модели теперь могут работать непосредственно на macOS без сложных драйверов GPU или зависимостей от CUDA.
Чипа M4 в Mac Mini уже достаточно для плавного запуска компактных языковых моделей (например, с 3-7 миллиардами параметров). На Mac Studio с M4 Max или M3 Ultra можно запускать даже модели с 30 миллиардами параметров - полностью локально.
Сравнение: Apple Silicon против оборудования NVIDIA
Традиционно видеокарты NVIDIA RTX являются золотым стандартом для вычислений в области ИИ. Например, современная RTX 5090 обеспечивает огромную сырую производительность и по-прежнему является первым выбором для многих обучающих систем. Тем не менее, стоит провести детальное сравнение - ведь приоритеты у всех разные.
| Аспект | Apple Silicon (M4 / M4 Max / M3 Ultra) | Графический процессор NVIDIA (5090 и др.) |
|---|---|---|
| Потребление энергии | Очень эффективные - обычно потребление не превышает 100 Вт. | До 450 Вт только для графического процессора |
| Шумовое развитие | Практически бесшумный | Хорошо слышно под нагрузкой |
| Программный стек | MLX / Core ML / Metal | CUDA / cuDNN / PyTorch |
| Техническое обслуживание | Без водителя и стабильно | Частые обновления и проблемы совместимости |
| Соотношение цены и качества | Высокая эффективность по умеренной цене | Лучшая пиковая производительность, но дороже |
| Идеально подходит для | Локальный вывод и непрерывная работа | Обучение и большие модели |
Одним словом: NVIDIA - это выбор для центров обработки данных и экстремальных тренировок. С другой стороны, Apple Silicon идеально подходит для локального и длительного использования - без шума, без нагрева, со стабильной программной основой и управляемым энергопотреблением.
Apple Silicon по сравнению с NVIDIA для выводов
M3 Ultra - это значительный шаг вперед для Apple Silicon: помимо высокоинтегрированного дизайна чипа с CPU, GPU и нейронным движком в одном корпусе, он основан на унифицированной архитектуре памяти, в которой RAM используется всеми вычислительными блоками одновременно - без классического разделения RAM и GPU VRAM. Согласно бенчмаркам, такой подход уже позволяет достичь в задачах локального вывода сопоставимой или даже лучшей производительности, чем у high-end видеокарт от NVIDIA в некоторых случаях. Один из примеров: В тестах M3 Ultra достигла примерно 2 320 токенов/с с 4-битной моделью Qwen3-30B по сравнению с RTX 3090 - 2 157 токенов/с.
Кроме того, сравнение Apple Silicon с NVIDIA под нагрузкой AI показывает, что система M3/M4 Max будет потреблять около 40-80 Вт под нагрузкой, в то время как RTX 4090 обычно потребляет до 450 Вт.
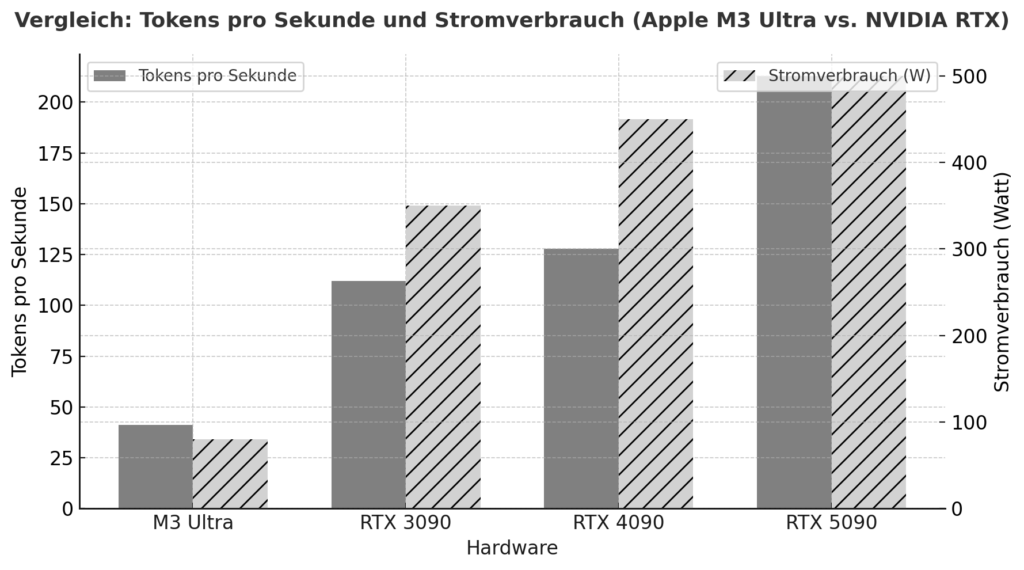
Это говорит о том, что если смотреть не только на пиковую производительность, но и на эффективность на ватт, то Apple Silicon находятся в отличном положении. С другой стороны, есть карты NVIDIA (например, 3090, 4090, 5090) с их огромной распараллеленной архитектурой GPU, очень высокой плотностью CUDA/тензорных ядер и специализированными библиотеками (CUDA, cuDNN, TensorRT). Именно здесь часто достигается максимальная производительность - но с решающими ограничениями для локальных языковых моделей: доступная VRAM (например, 24-32 ГБ для игровых карт) быстро становится узким местом, если необходимо загрузить модели с 20-30 миллиардами параметров или более. В одном из отчетов пользователей, например, говорится, что на RTX 5090 с примерно 32 ГБ VRAM уже сложно разместить модель с 20-22 миллиардами параметров.
В этом отношении следует обращать внимание не только на ядра GPU, но и на объем доступной памяти, пропускную способность и архитектуру памяти. Например, M3 Ultra с объемом объединенной памяти до 512 ГБ (в топовых конфигурациях) имеет преимущества во многих сценариях локального развертывания - особенно если модели должны работать не в облаке, а постоянно локально.
| Оборудование | Модель / установка | Токены в секунду (приблизительно) | Ремарка |
|---|---|---|---|
| Apple M3 Ultra (Mac Studio) | z. например, Gemma-3-27B-Q4 на M3 Ultra | ≈ 41 tok/s :contentReference[oaicite:2]{index=2} | Вывод LLM, контекст 4k лексем, квантифицированный |
| NVIDIA RTX 5090 | 8 B модель (количественная оценка) в соответствии с исследованием | ≈ 213 tok/s :contentReference[oaicite:3]{index=3} | Модель 8 B, 4-битная, среда RLHF |
| NVIDIA RTX 4090 | 8 B Ссылка на модель | ≈ 128 tok/s :contentReference[oaicite:4]{index=4} | 24 ГБ VRAM Окружающая среда |
| NVIDIA RTX 3090 | Бюджетный HighEnd в сравнении | ≈ 112 tok/s :contentReference[oaicite:5]{index=5} | Рынок подержанных товаров, 24 ГБ VRAM |
Практическая значимость: где локальные языковые модели имеют смысл
Возможности применения локального ИИ сегодня практически безграничны. Если необходимо сохранить конфиденциальность данных или запустить процессы в режиме реального времени, стоит использовать локальную версию. Примеры из практики:
- ERP-системыАвтоматический анализ текста, предложения, прогнозы или средства коммуникации - прямо из программного обеспечения.
- Производство книг и средств массовой информацииПроверка стиля, перевод, резюме, расширение текста - все локально, без зависимости от облака.
- Адвокаты и нотариусыАнализ документов, составление состязательных бумаг, исследования - в условиях строжайшей конфиденциальности.
- Врачи и терапевтыОценка случая, документирование или автоматизированные отчеты - при этом данные пациента никогда не покидают систему.
- Инженерные бюро и архитекторыМастера работы с текстом, проектами и расчетами, которые работают и без Интернета.
- Компания в целомУправление знаниями, внутренние чат-помощники, анализ протоколов, классификация электронной почты - все это в вашей собственной сети.
Это большой шаг, особенно в коммерческом секторе: вместо того чтобы платить за внешние услуги ИИ и отправлять данные в облако, теперь вы можете запускать индивидуальные модели на собственных машинах. Их можно настраивать, дорабатывать и расширять, используя собственные знания компании - полностью под контролем.
В результате мы получаем современный, но традиционно суверенный ИТ-ландшафт, который использует технологии, не отказываясь от суверенитета над собственными данными. Такой подход напоминает нам о старой добродетели: держать все в своих руках.
Текущий обзор локальных систем искусственного интеллекта
Обзор: Mac Mini и Mac Studio - что доступно в настоящее время
Если мы хотим запускать локальные языковые модели на Mac, то в этом случае особое внимание уделяется двум классам настольных компьютеров: Mac mini и Mac Studio.
- Mac MiniПоследнее поколение предлагает чип Apple M4 или опционально M4 Pro. Согласно техническим характеристикам, доступны варианты с 24 или 32 ГБ объединенной памяти; вариант Pro предлагается с настраиваемой объединенной памятью объемом до 48 или 64 ГБ. Благодаря этому Mac Mini хорошо подходит для многих приложений - особенно если модель не очень большая или не требуется параллельно выполнять несколько очень больших задач.
- Mac StudioЗдесь мы поднимаемся на ступень выше. Например, оснащенные чипом Apple M4 Max или M3 Ultra - в зависимости от модели. В версии M4 Max можно установить 48 ГБ, 64 ГБ или до 128 ГБ объединенной памяти. Версия M3 Ultra для Mac Studio может быть оснащена до 512 ГБ объединенной памяти. Размеры твердотельных накопителей и пропускная способность памяти также значительно увеличиваются. Благодаря этому Mac Studio подходит для более требовательных моделей или параллельных процессов.
В качестве небольшой заметки: The Mac Pro также существует и часто предлагает „больше шасси“ или слоты PCI-e снаружи - но с точки зрения языковых моделей, он не дает особых преимуществ перед Mac Studio для локальной версии, если у вас нет дополнительных карт расширения или особых требований к PCIe.
Также Блокноты (например, MacBook Pro), конечно, можно использовать - но с ограничениями: Системы охлаждения меньше, тепловые характеристики более ограничены, а бюджет оперативной памяти зачастую меньше. Длительное использование (как в моделях с искусственным интеллектом) может снизить производительность.

AI: Apple лучше, чем Nvidia! 😮 | c't 3003
Почему так важна оперативная память / унифицированная память
Когда языковая модель работает локально, требуется не только производительность CPU или GPU, но и оперативная память (или, в случае Apple, „унифицированная память“). Почему?
Сама модель (веса, активации, промежуточные результаты) должна храниться в памяти. Чем больше модель, тем больше памяти требуется. В чипах Apple-Silicon используется „унифицированная память“, то есть CPU, GPU и нейронный движок обращаются к одному и тому же пулу памяти. Это устраняет необходимость копирования данных между компонентами, что повышает эффективность и скорость работы.
Если оперативной памяти недостаточно, система вынуждена подкачивать данные или модели загружаются не полностью, что может означать падение производительности, нестабильность или отказ от работы. Особенно в инференциальных приложениях (генерация ответов, ввод текста, расширение моделей) время отклика и пропускная способность имеют решающее значение - достаточный объем памяти здесь значительно помогает. В традиционных настольных ПК принято думать в терминах „оперативная память CPU“ и „отдельная оперативная память GPU“ - в Apple Silicon они элегантно объединены, что делает запуск языковых моделей особенно привлекательным.
Оценочные значения: Какой порядок величины является реалистичным?
Чтобы помочь вам оценить, какое оборудование вам понадобится, вот несколько приблизительных значений:
- Для небольших моделей (например, несколько миллиардов параметров), может быть достаточно от 16 до 32 ГБ оперативной памяти - особенно если необходимо обрабатывать только отдельные запросы. Поэтому Mac Mini с 16/32 ГБ будет хорошим началом.
- Для средних моделей (например, 3-10 миллиардов параметров) или задачи с несколькими параллельными чатами или большими объемами текста, вам следует обратить внимание на 32 ГБ оперативной памяти или больше - например, Mac Studio с 32 или 48 ГБ.
- Для больших моделей (>20 млрд. параметров) или если несколько моделей будут работать параллельно, можно выбрать 64 ГБ или больше - здесь возможны варианты Mac mini и Mac Studio с 64 ГБ или больше.
Важно: Не забудьте предусмотреть запас памяти - не только модель, но и работа (например, операционной системы, файлового ввода-вывода, других приложений) требует резерва памяти.
| Категория | Типовой размер модели | Рекомендуемый бюджет оперативной памяти | Пример использования |
|---|---|---|---|
| Маленький | 1-3 миллиарда параметров | 16-32 ГБ | Простой помощник, распознавание текста |
| Средний | 7-13 млрд. Параметры | 32-64 ГБ | Чат, анализ, создание текстов |
| Большой | Параметры 30-70 млрд. | 64 ГБ + | Специализированные тексты, юридические документы |
Подвергая сомнению традиционное мышление „сервер против настольного компьютера“.
Традиционно люди считали, что для ИИ нужны серверные фермы, множество графических процессоров, большие мощности и центры обработки данных. Но картина меняется: настольные компьютеры, такие как Mac Mini или Mac Studio, теперь обеспечивают достаточную производительность для множества локально управляемых языковых моделей - без огромной инфраструктуры. Вместо высоких затрат на электроэнергию, мощного охлаждения и сложного обслуживания вы получаете тихое и эффективное устройство на своем столе.
Конечно, если вы хотите обучать модели в больших масштабах или использовать большое количество параметров, то серверные решения все еще имеют смысл. Однако для выводов, настройки и повседневного использования часто достаточно настольного оборудования. Это связано с традиционным отношением: используйте технологии, но не перегружайте их, а применяйте целенаправленно и эффективно. Если вы создаете прочную локальную основу сегодня, вы создаете фундамент для того, что будет возможно завтра.

M3 Ultra против RTX 5090 | Финальная битва (на английском языке)
Техническая характеристика языковых моделей
Сегодня языковые модели различаются не только по своим возможностям, но и по техническому формату, в котором они доступны. Эти форматы определяют, как модель сохраняется, загружается и используется - и может ли она вообще работать в той или иной системе.
GGUF (GPT-Generated Unified Format)
Этот формат был разработан для практического использования в таких инструментах, как Ollama, LM Studio или Llama.cpp. Он компактен, портативен и хорошо оптимизирован для локального вывода. Модели GGUF обычно квантованы, что означает, что они занимают значительно меньше памяти, поскольку внутренние числовые значения хранятся в уменьшенном виде (например, 4- или 8-битные). В результате модели, размер которых изначально составлял 30-50 ГБ, могут быть сжаты до 5-10 ГБ - лишь с небольшой потерей качества.
- ПреимуществоРаботает практически на любой системе (macOS, Windows, Linux), не требует специального GPU.
- НедостатокНе предназначен для обучения или тонкой настройки - чистое умозаключение (т.е. использование).
MLX (Машинное обучение для Apple Silicon)
MLX - это собственный фреймворк Apple с открытым исходным кодом для машинного обучения на Apple Silicon. Он был специально разработан для использования всей мощности CPU, GPU и нейронного движка в M-чипах. Модели MLX обычно доступны в родном формате MLX или конвертированы из других форматов.
- ПреимуществоМаксимальная производительность и энергоэффективность на оборудовании Apple.
- НедостатокВсе еще относительно молодая экосистема, доступно меньше моделей сообщества, чем в GGUF или PyTorch.
Safetensors (.safetensors)
Этот формат берет свое начало в мире PyTorch (и активно продвигается Hugging Face). Это безопасный двоичный формат хранения больших моделей, который не допускает выполнения кода - отсюда и название „безопасный“.
- ПреимуществоОчень быстрая загрузка, экономия памяти, стандартизация.
- Недостаток: В основном предназначен для таких фреймворков, как PyTorch или TensorFlow - т.е. более распространенных в среде разработчиков и для процессов обучения.
| Формат | Платформа | Назначение | Преимущества | Недостатки |
|---|---|---|---|---|
| GGUF | macOS, Windows, Linux | Заключение | Компактный, быстрый, универсальный | Обучение невозможно |
| MLX | macOS (Apple Silicon) | Вывод + обучение | Оптимизирован для M-чипов, высокая эффективность | Меньшее количество доступных моделей |
| Сейфетензоры | Кроссплатформенность (PyTorch / TensorFlow) | Обучение и исследования | Безопасно, стандартно, быстро | Непосредственная совместимость с Ollama / MLX |
Обнимающееся лицо - центральный источник снабжения
Сегодня Hugging Face - это что-то вроде „библиотеки“ в мире ИИ. На сайте huggingface.co вы найдете десятки тысяч моделей, наборов данных и инструментов, многие из которых можно использовать бесплатно. Вы можете фильтровать по названию, архитектуре, типу лицензии или формату файла. Будь то Mistral, LLaMA, Falcon, Gemma или Phi-3 - здесь представлены практически все известные модели. Многочисленные разработчики уже предлагают адаптированные версии для локального использования с GGUF или MLX.
Таким образом, Hugging Face становится первым пунктом назначения для большинства пользователей, если они хотят опробовать модель или найти подходящий вариант для macOS.

Типовые модели и области их применения
За количеством доступных моделей сейчас практически невозможно уследить. Тем не менее, есть несколько основных семейств, которые особенно хорошо зарекомендовали себя при использовании в местных условиях:
- Семейство LLaMA (Meta): Одна из самых известных моделей с открытым исходным кодом. На ее основе создано бесчисленное множество производных (например, Vicuna, WizardLM, Open-Hermes). Сильные стороны: понимание языка, диалог, универсальность использования. Область применения: общие чат-приложения, генерация контента, системы помощи.
- Mistral и Mixtral (Mistral AI)Известен высокой эффективностью и высоким качеством при небольшом размере модели. Mixtral 8x7B объединяет несколько экспертных моделей (архитектура Mixture-of-Experts). Сильные стороны: быстрые, точные ответы, экономия ресурсов. Область применения: внутренние помощники, анализ текстов, подготовка данных.
- Фи-3 (Microsoft Research)Компактная модель, оптимизированная для высокого качества голоса, несмотря на небольшое количество параметров. Сильные стороны: Эффективность, хорошая грамматика, структурированные ответы. Область применения: небольшие системы, локальные модели знаний, интегрированные ассистенты.
- Джемма (Google): Опубликовано Google Research как открытая модель. Хорошо подходит для обобщающих и объяснительных задач. Сильные стороны: согласованность, контекстуализированные объяснения. Область применения: обработка знаний, обучение, системы консультирования.
- Модели GPT-OSS / OpenHermesВместе с модификациями LLaMA они образуют „мост“ между моделями с открытым исходным кодом и функциональным объемом коммерческих систем. Сильные стороны: Широкая языковая база, гибкость использования. Область применения: создание контента, чат и аналитические задачи, внутренняя помощь ИИ.
- Клод / Command R / Falcon / Yi / ZephyrЭти и многие другие модели (в основном из исследовательских проектов или открытых сообществ) предлагают специальные функции, такие как поиск знаний, генерация кода или многоязычие.
Самое главное, что ни одна модель не может делать все идеально. У каждой из них есть свои сильные и слабые стороны - и в зависимости от области применения стоит провести целенаправленное сравнение.
Какая модель подходит для какой цели?
Чтобы получить реалистичную оценку, модели можно условно разделить на классы производительности и применения:
Для большинства реалистичных настольных приложений - таких как резюме, переписка, перевод, анализ - средние модели (7-13 B) вполне достаточно. Они дают удивительно хорошие результаты, работают без сбоев на Mac Mini M4 Pro с 32-48 ГБ оперативной памяти и практически не требуют перенастройки.
Большие модели проявить свои сильные стороны, когда важно более глубокое понимание или более длительный контекст - например, при работе с юридическими текстами или технической документацией. Тем не менее, у вас должен быть хотя бы один Mac Studio с 64-128 ГБ Используйте рабочую память.
| Семейство моделей | Происхождение | Сильные стороны | Область применения |
|---|---|---|---|
| LLaMA | Мета | Понимание языка, диалог | Общие приложения для чата |
| Mistral / Mixtral | Mistral AI | Эффективность, высокая точность | Ассистенты компании, анализ |
| Фи-3 | Microsoft Research | Компактный, лингвистически сильный | Малые системы, локальный ИИ |
| Джемма | Исследования Google | Согласованность, объяснимость | Консультации, преподавание, объяснение текстов |
Варианты локального управления языковыми моделями
Если вы хотите использовать языковую модель на своем Mac, то сегодня есть несколько практичных вариантов - в зависимости от ваших технических требований и целей. Самое приятное, что для начала работы вам больше не нужна сложная среда разработки.
Ollama - незамысловатый старт
Ollama быстро стал стандартным инструментом для создания локальных моделей ИИ. Он работает на macOS, оптимально использует производительность Apple Silicon и позволяет запускать модель одной командой:
ollama run mistral
Это автоматически загружает и подготавливает нужную модель, которая затем доступна в терминале или через локальные интерфейсы. Ollama поддерживает формат GGUF, позволяет загружать модели из Hugging Face и может быть интегрирован через REST API или непосредственно в другие программы.
Как работать с Ollama модель местного языка installiert и другие возможности, которые вы можете использовать, подробно описаны в другой статье. Также есть другие статьи о том, как использовать Qdrant - гибкая память для своего локального ИИ.
LM Studio - графический пользовательский интерфейс и администрирование
Студия LM предназначено для тех, кто предпочитает графический интерфейс пользователя. В одном приложении можно загружать модели, общаться в чате, контролировать температуру, получать системные подсказки и управлять памятью. Это идеально подходит, в частности, для новичков: вы можете пробовать, сравнивать, сохранять и переключаться между различными моделями без необходимости работать с командной строкой. Программа стабильно работает на Apple Silicon, а также поддерживает модели GGUF.
MLX / Python - для разработчиков и интеграторов
Если вы хотите углубиться или интегрировать модели в свои собственные программы, вы можете использовать фреймворк MLX от Apple. Это позволяет встраивать модели непосредственно в приложения на Python или Swift. Преимущество заключается в максимальном контроле и интеграции в существующие рабочие процессы - например, если компания хочет добавить функции ИИ в свое собственное программное обеспечение.
FileMaker Сервер 2025 - ИИ в корпоративном контексте
Поскольку FileMaker Сервер 2025 Языковые модели на основе MLX могут также работать на стороне сервера. Это впервые позволяет оснастить центральное бизнес-приложение (например, ERP- или CRM-систему) собственным локальным ИИ. Например, можно автоматически классифицировать заявки в службу поддержки, оценивать запросы клиентов или анализировать содержимое документов - и при этом данные не покидают пределов компании.
Это особенно интересно для отраслей, где существуют строгие требования к защите данных или соблюдению нормативных требований (медицина, юриспруденция, администрация, промышленность).
Типичные камни преткновения и как их избежать
Даже если начальный барьер невелик, есть несколько моментов, о которых вам следует знать:
Ограничения памяти: Если модель слишком велика для доступной памяти, она не запустится вообще или будет работать крайне медленно. Здесь может помочь квантование (например, 4-битное) или модель меньшего размера.
- Вычисление нагрузки и теплового режима: При длительной работе Mac может ощутимо нагреваться. Рекомендуется обеспечить хорошую вентиляцию и следить за дисплеем активности.
- Отсутствие поддержки GPU для стороннего программного обеспеченияНекоторые старые инструменты или порты не могут эффективно использовать нейронный движок. В таких случаях MLX может обеспечить лучшие результаты.
- Сетевые порты и праваЕсли несколько клиентов должны получить доступ к одной и той же модели (например, в сети компании), локальные порты должны быть освобождены - желательно защищенные по HTTPS или через внутренний прокси.
- Безопасность данныхДаже если модели работают локально, конфиденциальные тексты не должны храниться в незащищенных средах. Локальные журналы и журналы чатов легко забыть, но в них часто содержится ценная информация.
Если вы обратите внимание на эти моменты, то сможете управлять мощной локальной системой искусственного интеллекта, которая будет работать безопасно, тихо и эффективно, не прилагая при этом особых усилий.
Сроки и стратегические соображения
Мы находимся только в начале пути, который в ближайшие годы изменит повседневную жизнь многих профессий. Локальные модели ИИ становятся все меньше, быстрее и эффективнее, а их качество продолжает улучшаться. То, что сегодня требует 30 ГБ памяти, через год может потребовать всего 10 ГБ - при том же качестве голоса. В то же время появляются новые интерфейсы, позволяющие интегрировать модели непосредственно в офисные программы, браузеры или программное обеспечение компании.
Компании, которые сегодня делают шаг к созданию локальной инфраструктуры ИИ, создают для себя преимущество. Они накапливают опыт, обеспечивают суверенитет своих данных и становятся независимыми от колебаний цен или ограничений на использование, налагаемых внешними поставщиками. Разумная стратегия может выглядеть следующим образом:
- Сначала поэкспериментируйте с небольшой моделью (например, 3-7 миллиардов параметров, через Ollama или LM Studio).
- Затем проверьте, какие задачи можно автоматизировать.
- При необходимости интегрируйте более крупные модели или организуйте центральную Mac Studio в качестве „сервера искусственного интеллекта“.
- В среднесрочной перспективе реорганизуйте внутренние процессы (например, документирование, анализ текстов, коммуникация) с помощью ИИ.
Такой поэтапный подход не только экономически целесообразен, но и устойчив - он следует принципу внедрения технологий в собственном темпе, а не под влиянием тенденций.
В отдельной статье я подробно описал, как новые Формат MLX в сравнении с GGUF через Ollama на компьютере Mac.
Местный ИИ как тихий путь к цифровому суверенитету
Местные языковые модели означают возвращение к самоопределению в цифровом мире.
Вместо того чтобы отправлять данные и идеи в удаленные облачные центры обработки данных, теперь вы можете снова работать с собственными инструментами - прямо на своем рабочем столе, под собственным контролем.
Mac Mini, Mac Studio или мощный ноутбук - если у вас есть подходящее оборудование, вы можете использовать, обучать и развивать свой собственный ИИ. Персональный ассистент, ERP-система, исследовательский центр в издательстве или решение для защиты данных в юридической фирме - возможности поразительно широки.
И что самое приятное: он напоминает нам о старой сильной стороне компьютера, а именно о том, что он является инструментом, которым вы управляете сами, а не сервисом, который диктует нам, как работать. Это делает локальный ИИ символом современной автономии - тихой, эффективной и при этом впечатляющей.
Рекомендуемые источники
- Профилирование больших языковых моделей на Apple SiliconA Quantisation Perspective (Benazir & Lin et al., 2025) - детально рассматривает производительность вычислений на Apple Silicon по сравнению с NVIDIA GPU, уделяя особое внимание квантованию.
- Локальное LLM-предположение производственного уровня на Apple SiliconСравнительное исследование MLX, MLC-LLM, Ollama, llama.cpp и PyTorch MPS (Rajesh et al., 2025) - Сравнение различных платформ на Apple Silicon, включая MLX, с точки зрения пропускной способности, задержки, длины контекста.
- Бенчмаркинг машинного обучения на устройствах Apple Silicon с помощью MLX (Ajayi & Odunayo, 2025) - сфокусирован на MLX и Apple Silicon, с эталонными данными на системах NVIDIA.


Часто задаваемые вопросы
- Что такое локальная языковая модель?
Локальная языковая модель - это искусственный интеллект, способный понимать и генерировать тексты - подобно ChatGPT. Разница в том, что он работает не через интернет, а непосредственно на вашем компьютере. Все вычисления происходят локально, и никакие данные не отправляются на внешние серверы. Это означает, что вы сохраняете полный контроль над собственной информацией. - Какие преимущества дает локальный ИИ по сравнению с облачными решениями, такими как ChatGPT?
Три главных преимущества - защита данных, независимость и контроль затрат.
- Защита данных: тексты не покидают компьютер.
- Независимость: не требуется подключение к Интернету, смена провайдера или риск сбоя.
- Стоимость: Никаких постоянных платежей за запрос. Вы платите один раз за оборудование - и все. - Нужны ли вам навыки программирования, чтобы использовать языковую модель локально?
Нет. С помощью современных инструментов, таких как Ollama или LM Studio, модель можно запустить всего несколькими щелчками мыши. Сегодня даже новички могут запустить локальный ИИ всего за несколько минут, не написав ни строчки кода. - Какие устройства Apple особенно подходят?
Для новичков часто достаточно Mac Mini с M4 или M4 Pro и не менее 32 ГБ оперативной памяти. Если вы хотите использовать более крупные модели или несколько одновременно, лучше выбрать Mac Studio с 64 или 128 ГБ оперативной памяти. Mac Pro практически не имеет преимуществ, если вам не нужны слоты PCI-e. Ноутбуки тоже подходят, но быстрее достигают своего теплового предела. - Какой минимальный объем оперативной памяти должен быть у вас?
Это зависит от размера модели.
- Небольшие модели (1-3 млрд параметров): достаточно 16-32 ГБ.
- Средние модели (7-13 миллиардов): лучше 48-64 ГБ.
- Большие модели (более 30 миллиардов): 128 ГБ или более.
Важно предусмотреть некоторый запас - в противном случае придется ждать или отменять встречу. - Что означает „унифицированная память“ для Apple Silicon?
Объединенная память - это общая память, к которой одновременно обращаются CPU, GPU и нейронный движок. Это экономит время и энергию, поскольку нет необходимости копировать данные между различными областями памяти. Это огромное преимущество, особенно для вычислений ИИ, поскольку все работает в одном потоке. - В чем разница между GGUF, MLX и Safetensors?
- GGUF: компактный формат для локального использования (например, в Ollama или LM Studio). Идеально подходит для вывода, т. е. выполнения готовых моделей.
- MLX: собственный формат Apple, специально для чипов M. Очень эффективный, но все еще молодой.
- Safetensors: формат из мира PyTorch, предназначенный в первую очередь для обучения и исследований.
GGUF или MLX идеально подходят для локального использования на Mac. - Откуда вы берете модели?
Самой известной платформой является huggingface.co - огромная библиотека для моделей искусственного интеллекта. Там можно найти варианты LLaMA, Mistral, Gemma, Phi-3 и многих других. Многие модели уже доступны в формате GGUF и могут быть загружены непосредственно в Ollama. - С какими инструментами легче всего начать работу?
Для начала идеально подойдут Ollama и LM Studio. Ollama работает в терминале и имеет небольшой вес. LM Studio предлагает графический пользовательский интерфейс с окном чата. Обе программы загружают и запускают модели автоматически и не требуют сложной настройки. - Могут ли языковые модели также использоваться с FileMaker Server?
Да - начиная с FileMaker Server 2025, к моделям MLX можно обращаться напрямую. Это позволяет проводить текстовый анализ, классификацию или автоматическую оценку, например, в ERP- или CRM-системах. Это позволяет обрабатывать конфиденциальные бизнес-данные локально, не отправляя их внешним провайдерам. - Какого размера обычно бывают такие модели?
Маленькие модели занимают всего несколько гигабайт, большие - 20-30 ГБ и более. Их размер можно значительно уменьшить с помощью квантования (например, 4-битного), часто с минимальной потерей качества. Например, сжатая модель 13-B может занимать всего 7 ГБ - идеальный вариант для Mac Mini M4 Pro. - Можно ли обучать или настраивать локальные модели?
В принципе да, но обучение требует больших вычислительных затрат. Для локальной тонкой настройки небольших моделей можно использовать фреймворки MLX или Python. Сегодня FileMaker содержит встроенную функцию для Прямая точная настройка языковых моделей чтобы быть в состоянии сделать это. Однако для масштабного обучения (например, 50 миллиардов параметров) потребуется специальная ферма GPU. Для большинства приложений достаточно использовать существующие модели и управлять ими с помощью специальных подсказок. - Сколько энергии потребляет Mac во время вычислений ИИ?
На удивление мало. В режиме полной работы Mac Studio часто потребляет менее 100 Вт, в то время как одна видеокарта NVIDIA (например, RTX 5090) потребляет до 450 Вт - без процессора и периферийных устройств. Это означает, что локальный ИИ на оборудовании Apple не только тише, но и значительно энергоэффективнее. - Подходит ли MacBook Pro для локального ИИ?
Да, но с ограничениями.
Несмотря на высокую производительность, тепловая нагрузка ограничена. При длительной работе процессор дросселируется. MacBook Pro M3/M4 идеально подходит для коротких разговоров, текстовых задач или аналитических исследований, но не для длительного использования. - Насколько безопасны местные модели?
Так же безопасны, как и система, на которой они работают. Поскольку никакие данные не передаются через Интернет, риск от третьих лиц практически отсутствует. Однако необходимо следить за тем, чтобы временные файлы, журналы или истории чатов случайно не попали в облачные папки (например, iCloud Drive). Идеальным вариантом является локальное хранение на внутреннем SSD-накопителе. - Какие типичные ошибки допускают новички?
- Загрузка слишком больших моделей, даже если не хватает оперативной памяти.
- Используйте старые версии Ollama или LM Studio.
- Не включайте ускорение GPU (например, MLX).
- Слишком много процессов, работающих в фоновом режиме.
- Загрузка моделей из сомнительных источников.
Устранение: Используйте только надежные источники (например, Hugging Face) и следите за системными ресурсами. - Как будут развиваться местные технологии искусственного интеллекта в ближайшие несколько лет?
Модели становятся еще более компактными и точными. Компании Apple, Mistral и Meta уже работают над архитектурами, которые требуют меньше памяти и энергии при том же качестве. Одновременно разрабатываются удобные интерфейсы - например, AI-плагины для текстовых редакторов, почтовых программ или приложений для заметок. В долгосрочной перспективе каждая профессиональная система, вероятно, будет иметь своего рода „встроенный локальный ИИ“. - Почему стоит начать именно сейчас?
Потому что фундамент для будущих лет закладывается уже сейчас. Тот, кто сегодня научится локально запускать модель, структурированно обрабатывать данные и целенаправленно формулировать подсказки, в дальнейшем сможет действовать самостоятельно - без необходимости полагаться на дорогостоящих облачных провайдеров. Одним словом, локальный ИИ - это спокойный и уверенный путь к цифровому будущему, в котором вы снова сможете держать свои данные и инструменты в собственных руках.



