
Chi si occupa di intelligenza artificiale oggi pensa spesso a ChatGPT o a servizi online simili. Si digita una domanda, si attende qualche secondo e si riceve una risposta come se all'altro capo del filo ci fosse un interlocutore molto colto e paziente. Ma ciò che è facilmente dimenticabile: Ogni input, ogni frase, ogni parola viaggia via Internet verso server esterni. È lì che si svolge il lavoro vero e proprio, su enormi computer che non si vedono mai di persona.
In linea di principio, un modello linguistico locale funziona esattamente nello stesso modo, ma senza Internet. Il modello è memorizzato come file sul computer dell'utente, viene caricato nella memoria di lavoro all'avvio e risponde alle domande direttamente sul dispositivo. La tecnologia alla base è la stessa: una rete neurale che comprende il linguaggio, genera testi e riconosce modelli. L'unica differenza è che l'intero calcolo rimane interno all'azienda. Si potrebbe dire: ChatGPT senza cloud.
La particolarità è che la tecnologia si è sviluppata a tal punto da non dipendere più da enormi centri dati. I moderni computer Apple con processori M (come M3 o M4) hanno un'enorme potenza di calcolo, connessioni di memoria veloci e un motore neurale specializzato per l'apprendimento automatico. Di conseguenza, molti modelli possono ora essere utilizzati direttamente su un Mac Mini o un Mac Studio, senza una server farm, senza una configurazione complicata e senza alcun rumore significativo.



Ultime notizie su Apple MLX e NVIDIA
26.03.2026: Apple continua a far progredire strategicamente il suo framework MLX AI e lo sta aprendo sempre più ad altre piattaforme. Originariamente ottimizzato esclusivamente per Apple Silicon, MLX ora supporta anche le GPU CUDA e quindi il classico hardware Nvidia. Questo elimina un ostacolo fondamentale per gli sviluppatori: finora i modelli dovevano spesso essere sviluppati sul Mac e poi addestrati su sistemi separati ad alte prestazioni. Con l'apertura, MLX diventa una piattaforma di sviluppo più flessibile che consente sia l'IA locale sui dispositivi Apple sia l'addestramento scalabile su hardware esterno. Allo stesso tempo, viene mantenuto il vantaggio della stretta integrazione con l'architettura dell'Apple, ad esempio attraverso una gestione efficiente della memoria e l'utilizzo diretto della GPU. Questo sviluppo indica un cambiamento di rotta strategico: Apple sta gradualmente abbandonando il suo ecosistema chiuso e sta posizionando MLX come una seria alternativa ai framework di IA consolidati, con potenziali implicazioni per lo sviluppo dell'IA nel suo complesso.
Questo apre una nuova porta, non solo per gli sviluppatori, ma anche per imprenditori, autori, avvocati, medici, insegnanti e commercianti. Ognuno può ora avere la propria piccola IA, sulla propria scrivania, sotto il pieno controllo e pronta all'uso in qualsiasi momento. Un modello linguistico locale può:
- Testi riassumere o correggere,
- Email formulare o strutturare,
- Domande rispondere alle domande e analizzare le conoscenze,
- Processi supporto nei programmi,
- Documenti ricerca o classificazione,
- o semplicemente come assistente personale senza mai far trapelare dati all'esterno.
Questo approccio sta diventando sempre più importante, soprattutto in un momento in cui la protezione dei dati e la sovranità digitale sono di nuovo al centro dell'attenzione. Non è necessario essere programmatori per utilizzarlo: basta un moderno Mac. I modelli possono essere avviati semplicemente tramite un'applicazione o una finestra di terminale e rispondono in modo quasi naturale come una finestra di chat nel browser.
Questo articolo mostra quali modelli possono essere eseguiti su quali Mac oggi, cosa deve fare l'hardware e perché i computer Apple Silicon sono particolarmente adatti a questo scopo. In breve, si tratta di capire come riportare la potenza dell'IA nelle proprie mani, in modo silenzioso, efficiente e locale.
Modelli linguistici locali sul Mac: perché ha senso ora
Eseguire un modello linguistico „localmente“ significa farlo funzionare interamente sul proprio computer, senza connessione a un servizio cloud. Il calcolo, l'analisi degli input, la generazione di testi o risposte: tutto avviene direttamente sul proprio dispositivo. Il modello è quindi memorizzato come file sull'SSD, viene caricato nella RAM all'avvio e funziona con tutte le prestazioni del sistema.
La differenza fondamentale rispetto alla variante cloud è l'indipendenza. I dati non transitano su Internet, non vengono utilizzati server esterni e nessuno può rintracciare ciò che viene elaborato internamente. Questo garantisce un notevole grado di protezione e controllo dei dati, soprattutto in tempi in cui è sempre più difficile rintracciare i movimenti dei dati.
In passato, l'esecuzione di modelli di questo tipo a livello locale era impensabile. Per mantenere in funzione una rete neurale di queste dimensioni era necessario un computer mainframe o una GPU farm. Oggi, grazie alla potenza di calcolo dei moderni chip Apple-Silicon, tutto ciò può essere realizzato su un dispositivo desktop, in modo efficiente, silenzioso e a basso consumo energetico.
Perché Apple Silicon è l'ideale
Con il passaggio all'Apple Silicon ha rimescolato le carte. Invece della classica architettura Intel con CPU e GPU separate, la Apple si affida al cosiddetto design a memoria unificata: processore, grafica e motore neurale accedono alla stessa veloce memoria principale. Questo elimina la necessità di copiare i dati tra i singoli componenti, un vantaggio decisivo per i calcoli di intelligenza artificiale.
Il motore neurale è un nucleo di calcolo specializzato per l'apprendimento automatico, integrato direttamente nei chip. Consente miliardi di operazioni di calcolo al secondo, con un consumo energetico molto ridotto. Insieme alla libreria MLX (Machine Learning for Apple Silicon) e a moderni framework come OLaMA, i modelli possono ora essere eseguiti direttamente su macOS senza complessi driver GPU o dipendenze CUDA.
Un chip M4 nel Mac Mini è già sufficiente per eseguire senza problemi modelli linguistici compatti (ad esempio, 3-7 miliardi di parametri). Su un Mac Studio con M4 Max o M3 Ultra, è possibile eseguire modelli con 30 miliardi di parametri, completamente in locale.
Confronto: Apple Silicon contro hardware NVIDIA
Tradizionalmente, le schede grafiche RTX di NVIDIA sono state il gold standard per i calcoli di intelligenza artificiale. Un'attuale RTX 5090, ad esempio, offre enormi prestazioni grezze ed è ancora la prima scelta per molti sistemi di formazione. Tuttavia, vale la pena di fare un confronto dettagliato, perché le priorità sono diverse.
| Aspetto | Apple Silicon (M4 / M4 Max / M3 Ultra) | GPU NVIDIA (5090 & Co.) |
|---|---|---|
| Consumo di energia | Molto efficiente: di solito il consumo totale è inferiore a 100 W. | Fino a 450 W per la sola GPU |
| Sviluppo del rumore | Praticamente silenzioso | Chiaramente udibile sotto carico |
| Pila software | MLX / Core ML / Metallo | CUDA / cuDNN / PyTorch |
| Manutenzione | Senza conducente e stabile | Aggiornamenti frequenti e problemi di compatibilità |
| Rapporto prezzo/prestazioni | Alta efficienza a un prezzo moderato | Prestazioni di picco migliori, ma più costose |
| Ideale per | Inferenza locale e funzionamento continuo | Formazione e modelli di grandi dimensioni |
In breve: NVIDIA è la scelta per i data center e la formazione estrema. Apple Silicon, invece, è ideale per l'uso locale a lungo termine - senza rumore, senza accumulo di calore, con una base software stabile e un consumo energetico gestibile.
Apple Silicon a confronto con NVIDIA per l'inferenza
L'M3 Ultra segna un significativo passo avanti per l'Apple Silicon: oltre a un design del chip altamente integrato con CPU, GPU e motore neurale in un unico pacchetto, si basa su un'architettura di memoria unificata in cui la RAM viene utilizzata da tutte le unità di elaborazione simultaneamente - senza la classica separazione tra RAM e GPU VRAM. Secondo i benchmark, questo approccio raggiunge già prestazioni paragonabili o addirittura migliori in compiti di inferenza locale rispetto alle schede grafiche di fascia alta di NVIDIA in alcuni casi. Un esempio: Nel test, l'M3 Ultra ha raggiunto circa 2.320 token/s con un modello Qwen3-30B a 4 bit, rispetto alla RTX 3090 che ha raggiunto 2.157 token/s.
Inoltre, un confronto tra Apple e Silicon rispetto a NVIDIA sotto carico AI suggerisce che un sistema M3/M4 Max raggiungerà circa 40-80W sotto carico, mentre una RTX 4090 assorbirà in genere fino a 450W.
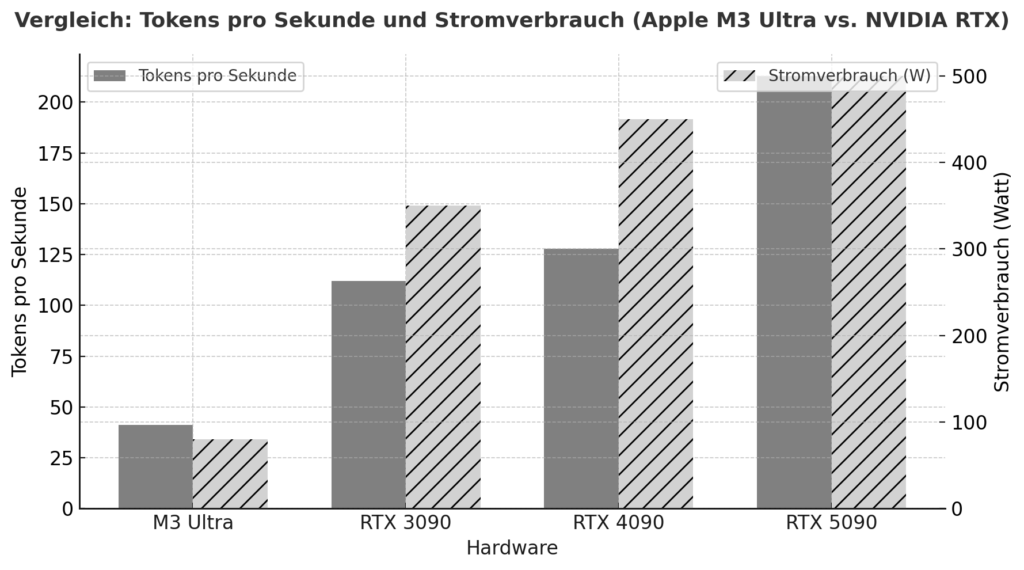
Questo dimostra che se si guarda non solo alle prestazioni di picco, ma anche all'efficienza per watt, l'Apple Silicon si trova in una posizione eccellente. D'altra parte, ci sono le schede NVIDIA (ad esempio 3090, 4090, 5090) con la loro enorme architettura di GPU parallelizzata, un'altissima densità di core CUDA/tensori e librerie specializzate (CUDA, cuDNN, TensorRT). È qui che le prestazioni top-flop grezze sono spesso superiori, ma con limitazioni decisive per i modelli in linguaggio locale: la VRAM disponibile (ad esempio 24-32 GB per le schede da gioco) diventa rapidamente un collo di bottiglia se si devono caricare modelli con 20-30 miliardi di parametri o più. Un utente ha riferito, ad esempio, che con una RTX 5090 con circa 32 GB di VRAM, un modello con 20-22 miliardi di parametri è già difficile da gestire.
A questo proposito, non bisogna considerare solo i core della GPU, ma anche le dimensioni della memoria disponibile, la larghezza di banda e l'architettura della memoria. L'M3 Ultra con fino a 512 GB di memoria unificata (nelle configurazioni top), ad esempio, offre vantaggi in molti scenari di implementazione locale, soprattutto se i modelli non devono essere eseguiti nel cloud, ma permanentemente in locale.
| Hardware | Modello / Configurazione | Gettoni al secondo (approssimativi) | Osservazione |
|---|---|---|---|
| Apple M3 Ultra (Mac Studio) | z. ad esempio Gemma-3-27B-Q4 su M3 Ultra | ≈ 41 tok/s :contentReference[oaicite:2]{index=2} | Inferenza LLM, contesto 4k tokens, quantizzato |
| NVIDIA RTX 5090 | 8 Modello B (quantificato) secondo lo studio | ≈ 213 tok/s :contentReference[oaicite:3]{index=3} | Modello 8 B, 4 bit, ambiente RLHF |
| NVIDIA RTX 4090 | 8 B Riferimento del modello | ≈ 128 tok/s :contentReference[oaicite:4]{index=4} | 24 GB di VRAM Ambiente |
| NVIDIA RTX 3090 | Budget HighEnd a confronto | ≈ 112 tok/s :contentReference[oaicite:5]{index=5} | Mercato di seconda mano, 24 GB di VRAM |
Rilevanza pratica: dove i modelli linguistici locali hanno senso
Le possibili applicazioni dell'IA locale sono oggi quasi illimitate. Quando i dati devono rimanere riservati o i processi devono essere eseguiti in tempo reale, la versione locale è utile. Esempi dalla pratica:
- Sistemi ERPAnalisi automatica del testo, suggerimenti, previsioni o aiuti alla comunicazione - direttamente dal software.
- Produzione di libri e mediaControllo dello stile, traduzione, riassunto, espansione del testo: tutto in locale, senza dipendere dal cloud.
- Avvocati e notaiAnalisi di documenti, bozze di memorie, ricerche - con la massima riservatezza.
- Medici e terapistiValutazione dei casi, documentazione o report automatici, senza che i dati del paziente lascino mai il sistema.
- Studi di ingegneria e architettiProcedure guidate per testi, progetti e calcoli che funzionano anche senza Internet.
- Azienda in generaleGestione delle conoscenze, assistenti di chat interni, analisi dei protocolli, classificazione delle e-mail, tutto all'interno della vostra rete.
Si tratta di un grande passo, soprattutto nel settore commerciale: invece di pagare per servizi di intelligenza artificiale esterni e inviare dati al cloud, ora è possibile eseguire modelli personalizzati sulle proprie macchine. Questi possono essere personalizzati, messi a punto e ampliati con le conoscenze dell'azienda, sotto il suo completo controllo.
Il risultato è un paesaggio informatico moderno ma tradizionalmente sovrano, che utilizza la tecnologia senza rinunciare al controllo dei propri dati. Un approccio che ci ricorda le vecchie virtù: tenere le cose nelle proprie mani.
Indagine attuale sui sistemi di intelligenza artificiale locali
Panoramica: Mac Mini e Mac Studio: cosa è attualmente disponibile
Se oggi vogliamo eseguire modelli linguistici locali su un Mac, due classi di desktop sono particolarmente importanti: il Mac mini e il Mac Studio.
- Mac MiniL'ultima generazione offre il chip Apple M4 o, a scelta, l'M4 Pro. Secondo le specifiche tecniche, sono disponibili varianti con memoria unificata da 24 GB o 32 GB; la variante Pro viene offerta con memoria unificata configurabile fino a 48 GB o 64 GB. Questo rende il Mac Mini adatto a molte applicazioni, soprattutto se il modello non è estremamente grande o se non deve eseguire diverse attività molto grandi in parallelo.
- Mac StudioQui facciamo un passo avanti. Ad esempio, con il chip Apple M4 Max o il chip M3 Ultra, a seconda del modello. Con la versione M4 Max sono possibili 48 GB, 64 GB o fino a 128 GB di memoria unificata. La versione M3 Ultra del Mac Studio può essere dotata di una memoria unificata fino a 512 GB. Anche le dimensioni delle SSD e le larghezze di banda della memoria aumentano notevolmente. Ciò rende il Mac Studio adatto a modelli più esigenti o a processi paralleli.
Una breve nota: il Mac Pro esiste e spesso offre „più chassis“ o slot PCI-e all'esterno - ma in termini di modelli linguistici, non offre grandi vantaggi rispetto al Mac Studio per la versione locale se non si hanno schede di espansione aggiuntive o requisiti PCIe speciali.
Inoltre Quaderni (ad esempio MacBook Pro) possono certamente essere utilizzati, ma con delle limitazioni: I sistemi di raffreddamento sono più piccoli, le prestazioni termiche sono più limitate e il budget per la RAM è spesso inferiore. Un utilizzo prolungato (come nel caso dei modelli AI) può ridurre le prestazioni.

AI: Apple meglio di Nvidia! 😮 | c't 3003
Perché la RAM/memoria unificata è così importante
Quando un modello di linguaggio viene eseguito localmente, non sono necessarie solo le prestazioni della CPU o della GPU: anche la RAM (o „memoria unificata“ nel caso dell'Apple) è fondamentale. Perché?
Il modello stesso (pesi, attivazioni, risultati intermedi) deve essere tenuto in memoria. Più grande è il modello, più memoria è necessaria. I chip Apple-Silicon utilizzano la "memoria unificata", ovvero CPU, GPU e motore neurale accedono allo stesso pool di memoria. Questo elimina la necessità di copiare i dati tra i componenti, aumentando l'efficienza e la velocità.
Se la RAM non è sufficiente, il sistema deve effettuare uno swap out o i modelli non vengono caricati completamente, il che può significare un calo delle prestazioni, instabilità o cancellazione. Soprattutto con le applicazioni inferenziali (generazione di risposte, immissione di testo, estensione dei modelli), i tempi di risposta e il throughput sono cruciali: in questo caso, una memoria sufficiente è di grande aiuto. Un PC desktop tradizionale era solito pensare in termini di „RAM della CPU“ e „RAM separata della GPU“; con l'Apple Silicon tutto questo è elegantemente combinato, il che rende particolarmente interessante l'esecuzione di modelli linguistici.
Valori stimati: Quale ordine di grandezza è realistico?
Per aiutarvi a stimare l'hardware necessario, ecco alcuni valori indicativi:
- Per i modelli più piccoli (ad esempio qualche miliardo di parametri), potrebbero essere sufficienti da 16 a 32 GB di RAM, soprattutto se si devono elaborare solo singole query. Un Mac Mini con 16/32 GB sarebbe quindi un buon inizio.
- Per i modelli medi (ad esempio 3-10 miliardi di parametri) o attività con diverse chat parallele o grandi quantità di testo, dovreste considerare 32 GB di RAM o più, ad esempio Mac Studio con 32 o 48 GB.
- Per i modelli di grandi dimensioni (>20 miliardi di parametri) o se più modelli devono funzionare in parallelo, si possono scegliere 64 GB o più - sono possibili varianti di Mac mini e Mac Studio con 64 GB o più.
Importante: ricordarsi di pianificare un po' di buffer: non solo il modello, ma anche il funzionamento (ad esempio il sistema operativo, l'I/O dei file, altre applicazioni) richiede riserve di memoria.
| Categoria | Dimensioni tipiche del modello | Budget di RAM consigliato | Esempio di utilizzo |
|---|---|---|---|
| Piccolo | 1-3 miliardi di parametri | 16-32 GB | Assistente semplice, riconoscimento del testo |
| Medio | 7-13 miliardi Parametri | 32-64 GB | Chat, analisi, creazione di testi |
| Grande | Parametri da 30 a 70 miliardi | 64 GB + | Testi specialistici, documenti legali |
Mettere in discussione la tradizionale mentalità "server vs. desktop".
Tradizionalmente si pensava che l'IA richiedesse server farm, molte GPU, molta potenza e un data center. Ma il quadro sta cambiando: computer desktop come Mac Mini o Mac Studio offrono oggi prestazioni sufficienti per molti modelli linguistici gestiti localmente, senza bisogno di un'enorme infrastruttura. Invece di costi elevati di elettricità, raffreddamento potente e manutenzione complessa, si ottiene un dispositivo silenzioso ed efficace sulla propria scrivania.
Naturalmente, se si desidera addestrare modelli su larga scala o utilizzare un numero elevato di parametri, le soluzioni server hanno ancora senso. Tuttavia, l'hardware desktop è spesso sufficiente per l'inferenza, la personalizzazione e l'uso quotidiano. Ciò si associa a un atteggiamento tradizionale: usare la tecnologia, ma non sovradimensionarla, piuttosto usarla in modo mirato ed efficiente. Se si costruisce una solida base locale oggi, si creano le fondamenta per ciò che sarà possibile fare domani.

M3 Ultra vs RTX 5090 | La battaglia finale (inglese)
Caratterizzazione tecnica dei modelli linguistici
Oggi i modelli linguistici differiscono non solo per le loro capacità, ma anche per il formato tecnico in cui sono disponibili. Questi formati determinano il modo in cui il modello viene salvato, caricato e utilizzato, e se può essere eseguito su un particolare sistema.
GGUF (formato unificato generato da GPT)
Questo formato è stato sviluppato per l'uso pratico in strumenti come Ollama, LM Studio o Llama.cpp. È compatto, portatile e altamente ottimizzato per l'inferenza locale. I modelli GGUF sono solitamente quantizzati, il che significa che consumano molta meno memoria perché i valori numerici interni sono memorizzati in forma ridotta (ad esempio a 4 o 8 bit). Di conseguenza, modelli che originariamente avevano dimensioni di 30-50 GB possono essere compressi a 5-10 GB, con solo una leggera perdita di qualità.
- VantaggioFunziona su quasi tutti i sistemi (macOS, Windows, Linux), non è richiesta alcuna GPU speciale.
- SvantaggioNon destinato all'addestramento o alla messa a punto - pura inferenza (cioè utilizzo).
MLX (apprendimento automatico per Apple Silicon)
MLX è il framework open source di Apple per l'apprendimento automatico su Apple Silicon. È stato sviluppato appositamente per utilizzare tutta la potenza della CPU, della GPU e del motore neurale nei chip M. I modelli MLX sono solitamente disponibili in formato MLX nativo o convertiti da altri formati.
- VantaggioMassime prestazioni ed efficienza energetica su hardware Apple.
- SvantaggioEcosistema ancora relativamente giovane, meno modelli comunitari disponibili rispetto a GGUF o PyTorch.
Safetensor (.safetensor)
Questo formato proviene dal mondo di PyTorch (ed è fortemente promosso da Hugging Face). Si tratta di un formato di memorizzazione binario e sicuro per modelli di grandi dimensioni che non consente l'esecuzione di codice - da qui il nome „sicuro“.
- VantaggioCaricamento molto rapido, risparmio di memoria, standardizzazione.
- Svantaggio: principalmente destinato a framework come PyTorch o TensorFlow, cioè più comuni negli ambienti degli sviluppatori e per i processi di formazione.
| Formato | Piattaforma | Scopo | Vantaggi | Svantaggi |
|---|---|---|---|---|
| GGUF | macOS, Windows, Linux | Inferenza | Compatto, veloce, universale | Nessuna formazione possibile |
| MLX | macOS (Apple Silicon) | Inferenza + formazione | Ottimizzato per M-Chips, ad alta efficienza | Meno modelli disponibili |
| Sensori di sicurezza | Piattaforma trasversale (PyTorch / TensorFlow) | Formazione e ricerca | Sicuro, standardizzato, veloce | Non direttamente compatibile con Ollama / MLX |
Hugging Face - la fonte centrale di approvvigionamento
Oggi, Hugging Face è una sorta di "biblioteca" del mondo dell'IA. Su huggingface.co troverete decine di migliaia di modelli, set di dati e strumenti, molti dei quali utilizzabili gratuitamente. È possibile filtrare per nome, architettura, tipo di licenza o formato di file. Che si tratti di Mistral, LLaMA, Falcon, Gemma o Phi-3, quasi tutti i modelli più noti sono rappresentati. Numerosi sviluppatori offrono già versioni personalizzate per l'uso locale con GGUF o MLX.
Questo rende Hugging Face il primo punto di riferimento per la maggior parte degli utenti che desiderano provare un modello o trovare una variante adatta a macOS.

Modelli tipici e loro aree di applicazione
Il numero di modelli disponibili è ormai quasi impossibile da tenere sotto controllo. Tuttavia, ci sono alcune famiglie principali che si sono dimostrate particolarmente efficaci per l'uso locale:
- Famiglia LLaMA (Meta)Uno dei modelli open source più noti. Costituisce la base di innumerevoli derivati (ad esempio Vicuna, WizardLM, Open-Hermes). Punti di forza: Comprensione del linguaggio, dialogo, versatilità d'uso. Campo di applicazione: Applicazioni generali di chat, generazione di contenuti, sistemi di assistenza.
- Mistral e Mixtral (Mistral AI)Conosciuto per l'elevata efficienza e la buona qualità con un modello di dimensioni ridotte. Mixtral 8x7B combina diversi modelli di esperti (architettura Mixture-of-Experts). Punti di forza: Risposte rapide e precise, risparmio di risorse. Campo di applicazione: assistenti interni all'azienda, analisi del testo, preparazione dei dati.
- Phi-3 (Microsoft Research)Modello compatto, ottimizzato per un'elevata qualità vocale nonostante il basso numero di parametri. Punti di forza: Efficienza, buona grammatica, risposte strutturate. Campo di applicazione: sistemi di piccole dimensioni, modelli di conoscenza locale, assistenti integrati.
- Gemma (Google)Pubblicato da Google Research come modello aperto. Ottimo per compiti di sintesi e di spiegazione. Punti di forza: coerenza, spiegazioni contestualizzate. Ambito di applicazione: elaborazione della conoscenza, formazione, sistemi di consulenza.
- Modelli GPT-OSS / OpenHermesInsieme alle modifiche di LaMa, costituiscono il "ponte" tra i modelli open source e l'ambito funzionale dei sistemi commerciali. Punti di forza: Ampia base linguistica, utilizzo flessibile. Ambito di applicazione: creazione di contenuti, attività di chat e analisi, assistenza AI interna.
- Claude / Command R / Falcon / Yi / ZephyrQuesti e molti altri modelli (per lo più provenienti da progetti di ricerca o comunità aperte) offrono funzioni speciali come il reperimento della conoscenza, la generazione di codice o il multilinguismo.
Il punto più importante è che nessun modello può fare tutto alla perfezione. Ognuno ha i suoi punti di forza e di debolezza e, a seconda dell'applicazione, vale la pena fare un confronto mirato.
Quale modello è adatto a quale scopo?
Per ottenere una valutazione realistica, i modelli possono essere suddivisi grossolanamente in classi di prestazioni e applicazioni:
Per la maggior parte delle applicazioni desktop realistiche - come riassunti, corrispondenza, traduzione, analisi - i modelli medi (7-13 B) sono del tutto sufficienti. Forniscono risultati straordinariamente buoni, funzionano senza problemi su un Mac Mini M4 Pro con 32-48 GB di RAM e non richiedono praticamente alcuna regolazione.
Modelli grandi mostrano i loro punti di forza quando è importante una comprensione più approfondita o contesti più lunghi, ad esempio nell'elaborazione di testi giuridici o di documentazione tecnica. Tuttavia, è necessario avere almeno un Mac Studio con 64-128 GB Utilizzare la memoria di lavoro.
| Famiglia di modelli | Origine | Punti di forza | Campo di applicazione |
|---|---|---|---|
| LLaMA | Meta | Comprensione della lingua, dialogo | Applicazioni generali di chat |
| Mistral / Misto | Mistral AI | Efficienza, alta precisione | Assistenti aziendali, analisi |
| Phi-3 | Ricerca Microsoft | Compatto, linguisticamente forte | Piccoli sistemi, IA locale |
| Gemma | Ricerca Google | Coerenza, spiegabilità | Consulenza, insegnamento, spiegazione di testi |
Opzioni per il funzionamento dei modelli linguistici a livello locale
Se si desidera utilizzare un modello linguistico sul proprio Mac, esistono diverse opzioni praticabili, a seconda dei requisiti tecnici e dello scopo desiderato. L'aspetto positivo è che non è più necessario un ambiente di sviluppo complesso per iniziare.
Ollama - l'inizio senza complicazioni
Ollama è diventato rapidamente uno strumento standard per i modelli AI locali. Funziona in modo nativo su macOS, sfrutta in modo ottimale le prestazioni di Apple Silicon e consente di avviare un modello con un solo comando:
ollama run mistral
Questo carica e prepara automaticamente il modello desiderato, che è poi disponibile nel terminale o tramite interfacce locali. L'Ollama supporta il formato GGUF, consente di scaricare i modelli da Hugging Face e può essere integrato tramite API REST o direttamente in altri programmi.
Come lavorare con Ollama un modello di lingua locale installiert e le altre opzioni disponibili sono descritte in dettaglio in un altro articolo. Ci sono anche altri articoli su come utilizzare Qdrant una memoria flessibile per la sua IA locale.
LM Studio - interfaccia grafica e amministrazione
Studio LM si rivolge a tutti coloro che preferiscono un'interfaccia grafica. Offre il download dei modelli, le finestre di chat, il controllo della temperatura, le richieste di sistema e la gestione della memoria in un'unica applicazione. È ideale soprattutto per i principianti: è possibile provare, confrontare, salvare e passare da un modello all'altro senza dover lavorare con la riga di comando. Il software funziona stabilmente su Apple Silicon e supporta anche i modelli GGUF.
MLX / Python - per sviluppatori e integratori
Se si desidera approfondire o integrare i modelli nei propri programmi, è possibile utilizzare il framework MLX di Apple. Questo permette di incorporare i modelli direttamente nelle applicazioni Python o Swift. Il vantaggio sta nel massimo controllo e nell'integrazione nei flussi di lavoro esistenti, ad esempio se un'azienda vuole aggiungere funzioni di IA al proprio software.
FileMaker Server 2025 - L'intelligenza artificiale nel contesto aziendale
Da quando FileMaker Server 2025 I modelli linguistici basati su MLX possono essere utilizzati anche sul lato server. In questo modo è possibile, per la prima volta, dotare un'applicazione aziendale centrale (ad esempio un sistema ERP o CRM) di una propria intelligenza artificiale locale. Ad esempio, è possibile classificare automaticamente i ticket di assistenza, valutare le richieste dei clienti o analizzare i contenuti dei documenti, senza che i dati lascino l'azienda.
Questo è particolarmente interessante per i settori che hanno requisiti rigorosi di protezione dei dati o di conformità (medicina, legge, amministrazione, industria).
I tipici ostacoli e come evitarli
Anche se l'ostacolo all'ingresso è basso, ci sono alcuni punti da tenere presenti:
Limiti di memoria: Se il modello è troppo grande per la memoria disponibile, non si avvia affatto o è estremamente lento. In questo caso può essere utile una quantizzazione (ad es. 4 bit) o un modello più piccolo.
- Calcolo del carico e dello sviluppo di caloreIl Mac può diventare sensibilmente caldo durante le sessioni più lunghe. È consigliabile una buona ventilazione e tenere d'occhio il display delle attività.
- Mancanza di supporto GPU per il software di terze partiAlcuni vecchi strumenti o porte non utilizzano il Neural Engine in modo efficiente. In questi casi, MLX può fornire risultati migliori.
- Porte e diritti di reteSe più client devono accedere allo stesso modello (ad esempio all'interno di una rete aziendale), è necessario rilasciare le porte locali, preferibilmente protette da HTTPS o da un proxy interno.
- Sicurezza dei datiAnche se i modelli vengono eseguiti localmente, i testi sensibili non dovrebbero essere archiviati in ambienti non sicuri. I log locali e i log delle chat sono facili da dimenticare, ma spesso contengono informazioni preziose.
Se si presta attenzione a questi punti, è possibile gestire un potente sistema di intelligenza artificiale locale che funziona in modo sicuro, silenzioso ed efficiente con uno sforzo sorprendentemente ridotto.
Tempistica e considerazioni strategiche
Siamo solo all'inizio di uno sviluppo che cambierà la vita quotidiana di molte professioni nei prossimi anni. I modelli di intelligenza artificiale locale diventeranno sempre più piccoli, veloci ed efficienti, mentre la loro qualità continuerà a migliorare. Ciò che oggi richiede 30 GB di memoria, tra un anno potrebbe richiederne solo 10 - con la stessa qualità vocale. Allo stesso tempo, stanno emergendo nuove interfacce che possono essere utilizzate per integrare i modelli direttamente nei programmi di Office, nei browser o nei software aziendali.
Le aziende che oggi compiono il passo verso un'infrastruttura di IA locale si creano un vantaggio per se stesse. Costruiscono competenze, si assicurano la sovranità dei dati e si rendono indipendenti dalle fluttuazioni dei prezzi o dalle restrizioni d'uso imposte da fornitori esterni. Una strategia sensata potrebbe essere la seguente:
- Sperimentare prima un modello di piccole dimensioni (ad esempio, 3-7 miliardi di parametri, tramite Ollama o LM Studio).
- Quindi verificate specificamente quali compiti possono essere automatizzati.
- Se necessario, integrare modelli più grandi o creare un Mac Studio centrale come "server AI".
- A medio termine, riorganizzare i processi interni (ad es. documentazione, analisi dei testi, comunicazione) con il supporto dell'IA.
Questo approccio graduale non è solo sensato dal punto di vista economico, ma anche sostenibile: segue il principio di adottare la tecnologia al proprio ritmo, invece di farsi guidare dalle tendenze.
In un articolo separato, ho descritto in dettaglio come il più recente Formato MLX a confronto con GGUF tramite Ollama sul Mac.
L'intelligenza artificiale locale come percorso silenzioso verso la sovranità digitale
I modelli linguistici locali segnano un ritorno all'autodeterminazione nel mondo digitale.
Invece di inviare dati e idee a centri dati cloud remoti, ora potete lavorare di nuovo con i vostri strumenti, direttamente sulla vostra scrivania, sotto il vostro controllo.
Che si tratti di un Mac Mini, di un Mac Studio o di un potente notebook, se si dispone dell'hardware giusto è ora possibile utilizzare, addestrare e sviluppare ulteriormente la propria IA. Che si tratti di un assistente personale, di un sistema ERP, di un ausilio alla ricerca in una casa editrice o di una soluzione conforme alla protezione dei dati in uno studio legale, le possibilità sono sorprendentemente ampie.
E la cosa migliore è che ci ricorda la vecchia forza del computer: essere uno strumento che si controlla da solo, piuttosto che un servizio che ci impone come lavorare. Questo rende l'IA locale un simbolo dell'autonomia moderna: silenziosa, efficiente e di grande effetto.
L'IA locale in azienda sviluppa il suo valore con la giusta base di sistema
 La discussione sull'IA locale è spesso incentrata su hardware, modelli e velocità, ma i vantaggi effettivi diventano evidenti solo quando si interagisce con i propri dati e processi. Se si vuole davvero utilizzare l'IA in modo sensato, è necessario un ambiente stabile e controllato in cui le informazioni non siano disperse ma disponibili in modo strutturato. È proprio qui che un soluzione ERP gestita localmente Costituisce la spina dorsale per i dati, i processi e le correlazioni all'interno dell'azienda. In combinazione con una soluzione come gFM Business ERP, si crea un ciclo chiuso in cui l'IA locale non solo fornisce risposte, ma lavora anche in modo contestualizzato, ad esempio integrando il proprio knowledge graph. Le decisioni non si basano più su modelli generici, ma sui dati aziendali reali. Il risultato è un passo silenzioso ma efficace verso la vera sovranità digitale: più controllo, più efficienza e un sistema che si adatta all'azienda, non il contrario.
La discussione sull'IA locale è spesso incentrata su hardware, modelli e velocità, ma i vantaggi effettivi diventano evidenti solo quando si interagisce con i propri dati e processi. Se si vuole davvero utilizzare l'IA in modo sensato, è necessario un ambiente stabile e controllato in cui le informazioni non siano disperse ma disponibili in modo strutturato. È proprio qui che un soluzione ERP gestita localmente Costituisce la spina dorsale per i dati, i processi e le correlazioni all'interno dell'azienda. In combinazione con una soluzione come gFM Business ERP, si crea un ciclo chiuso in cui l'IA locale non solo fornisce risposte, ma lavora anche in modo contestualizzato, ad esempio integrando il proprio knowledge graph. Le decisioni non si basano più su modelli generici, ma sui dati aziendali reali. Il risultato è un passo silenzioso ma efficace verso la vera sovranità digitale: più controllo, più efficienza e un sistema che si adatta all'azienda, non il contrario.
Fonti consigliate
- Profilazione dell'inferenza di modelli linguistici di grandi dimensioni su Apple SiliconA Quantisation Perspective (Benazir & Lin et al., 2025) - Esamina in dettaglio le prestazioni di inferenza su Apple Silicon rispetto alle GPU NVIDIA, con particolare attenzione alla quantizzazione.
- Inferenza LLM locale di livello produttivo su Apple SiliconUno studio comparativo di MLX, MLC-LLM, Ollama, llama.cpp e PyTorch MPS (Rajesh et al., 2025) - Confronto di diverse piattaforme su Apple Silicon incl. MLX, in relazione a throughput, latenza, lunghezza del contesto.
- Benchmarking dell'apprendimento automatico sul dispositivo su Apple Silicon con MLX (Ajayi & Odunayo, 2025) - Concentrato su MLX e Apple Silicon, con dati di benchmark rispetto ai sistemi NVIDIA.



Domande frequenti
- Che cos'è esattamente un modello linguistico locale?
Un modello linguistico locale è un'intelligenza artificiale in grado di comprendere e generare testi, simile a ChatGPT. La differenza è che non viene eseguito su Internet, ma direttamente sul vostro computer. Tutti i calcoli avvengono localmente e nessun dato viene inviato a server esterni. Ciò significa che l'utente mantiene il pieno controllo sulle proprie informazioni. - Quali vantaggi offre un'AI locale rispetto a una soluzione cloud come ChatGPT?
I tre principali vantaggi sono la protezione dei dati, l'indipendenza e il controllo dei costi.
- Protezione dei dati: nessun testo lascia il computer.
- Indipendenza: non è necessaria una connessione a Internet, non è necessario cambiare provider o rischiare di fallire.
- Costi: nessuna spesa continua per ogni richiesta. Si paga una sola volta per l'hardware - tutto qui. - È necessario avere competenze di programmazione per utilizzare un modello linguistico a livello locale?
No. Con strumenti moderni come Ollama o LM Studio, è possibile avviare un modello con pochi clic. Oggi anche i principianti possono eseguire un'IA locale in pochi minuti senza scrivere una sola riga di codice. - Quali dispositivi Apple sono particolarmente adatti?
Per i principianti, spesso è sufficiente un Mac Mini con M4 o M4 Pro e almeno 32 GB di RAM. Se si desidera utilizzare modelli più grandi o diversi contemporaneamente, è meglio optare per un Mac Studio con 64 GB o 128 GB di RAM. Un Mac Pro non offre quasi nessun vantaggio, a meno che non abbiate bisogno di slot PCI-e. I notebook sono adatti, ma raggiungono più rapidamente i loro limiti termici. - Qual è la quantità minima di RAM che si dovrebbe avere?
Questo dipende dalle dimensioni del modello.
- Modelli piccoli (1-3 miliardi di parametri): sono sufficienti 16-32 GB.
- Modelli medi (7-13 miliardi): meglio 48-64 GB.
- Modelli di grandi dimensioni (oltre 30 miliardi): 128 GB o più.
È importante pianificare una riserva, altrimenti ci saranno tempi di attesa o cancellazioni. - Cosa significa "memoria unificata" per Apple Silicon?
La memoria unificata è una memoria condivisa a cui accedono contemporaneamente CPU, GPU e motore neurale. Ciò consente di risparmiare tempo ed energia, poiché non è necessario copiare i dati tra le diverse aree di memoria. Questo è un enorme vantaggio, soprattutto per i calcoli di intelligenza artificiale, perché tutto funziona in un unico flusso. - Qual è la differenza tra GGUF, MLX e Safetensor?
- GGUF: un formato compatto per l'uso locale (ad esempio, in Ollama o LM Studio). Ideale per l'inferenza, cioè per l'esecuzione di modelli finiti.
- MLX: formato proprio dell'Apple, specialmente per i chip M. Molto efficiente, ma ancora giovane.
- Safetensors: un formato del mondo PyTorch, destinato principalmente alla formazione e alla ricerca.
GGUF o MLX sono ideali per l'uso locale sul Mac. - Da dove prendete i modelli?
La piattaforma più nota è huggingface.co, un'enorme libreria di modelli AI. Vi si possono trovare varianti di LLaMA, Mistral, Gemma, Phi-3 e molti altri. Molti modelli sono già disponibili in formato GGUF e possono essere caricati direttamente in Ollama. - Con quali strumenti è più facile iniziare?
Per iniziare, Ollama e LM Studio sono ideali. Ollama viene eseguito nel terminale ed è leggero. LM Studio offre un'interfaccia grafica con una finestra di chat. Entrambi caricano e avviano i modelli automaticamente e non richiedono una configurazione complessa. - I modelli linguistici possono essere utilizzati anche con il server FileMaker?
Sì: da FileMaker Server 2025, i modelli MLX possono essere indirizzati direttamente. Ciò consente di effettuare analisi del testo, classificazioni o valutazioni automatiche all'interno di sistemi ERP o CRM, ad esempio. In questo modo è possibile elaborare localmente i dati aziendali riservati senza doverli inviare a fornitori esterni. - Quanto sono grandi questi modelli?
I modelli piccoli sono di pochi gigabyte, quelli grandi possono avere 20-30 GB o più. Le dimensioni possono essere notevolmente ridotte grazie alla quantizzazione (ad esempio, 4 bit), spesso con una perdita minima di qualità. Un modello 13-B compresso, ad esempio, può occupare solo 7 GB, perfetto per un Mac Mini M4 Pro. - È possibile addestrare o personalizzare i modelli locali?
Fondamentalmente sì, ma l'addestramento è molto impegnativo dal punto di vista computazionale. I framework MLX o Python possono essere utilizzati per la messa a punto locale di modelli più piccoli. Oggi, FileMaker contiene una funzione integrata per Messa a punto diretta dei modelli linguistici per poterlo fare. Per un addestramento su larga scala (ad esempio, 50 miliardi di parametri), tuttavia, sarebbe necessaria una GPU farm dedicata. Per la maggior parte delle applicazioni, è sufficiente utilizzare i modelli esistenti e controllarli in modo specifico tramite prompt. - Quanta energia consuma un Mac durante i calcoli dell'intelligenza artificiale?
Sorprendentemente poco. Un Mac Studio è spesso sotto i 100 W in piena attività, mentre una singola scheda grafica NVIDIA (ad esempio RTX 5090) assorbe fino a 450 W - senza CPU e periferiche. Ciò significa che l'AI locale su hardware Apple non è solo più silenziosa, ma anche significativamente più efficiente dal punto di vista energetico. - Un MacBook Pro è adatto all'intelligenza artificiale locale?
Sì, ma con delle restrizioni.
Sebbene le prestazioni siano elevate, la capacità di carico termico è limitata. Il processore si blocca durante le sessioni più lunghe. Un MacBook Pro M3/M4 è perfetto per brevi chat, attività di testo o analisi, ma non per un uso prolungato. - Quanto sono sicuri i modelli locali?
Sicuri come il sistema su cui vengono eseguiti. Poiché i dati non vengono inviati su Internet, non vi è praticamente alcun rischio da parte di terzi. Tuttavia, è necessario assicurarsi che i file temporanei, i registri o la cronologia delle chat non finiscano accidentalmente in cartelle cloud (ad esempio, iCloud Drive). L'ideale è l'archiviazione locale sull'unità SSD interna. - Quali sono gli errori tipici che commettono i principianti?
- Caricamento di modelli troppo grandi, anche se la RAM non è sufficiente.
- Utilizzare le vecchie versioni di Ollama o LM Studio.
- Non attivare l'accelerazione della GPU (ad es. MLX).
- Troppi processi in esecuzione in background.
- Caricamento di modelli da fonti dubbie.
Rimedio: utilizzare solo fonti affidabili (ad esempio, Hugging Face) e tenere sotto controllo le risorse di sistema. - Come si svilupperà la tecnologia AI locale nei prossimi anni?
I modelli stanno diventando ancora più compatti e precisi. Apple, Mistral e Meta stanno già lavorando su architetture che richiedono meno memoria e meno energia a parità di qualità. Allo stesso tempo, si stanno sviluppando comode interfacce, come i plug-in AI per l'elaborazione di testi, i programmi di posta elettronica o le app per le note. A lungo termine, ogni sistema professionale sarà probabilmente dotato di una sorta di „IA locale integrata“. - Perché vale la pena iniziare ora?
Perché le basi per gli anni a venire vengono gettate proprio ora. Chiunque impari oggi ad avviare un modello in locale, a elaborare i dati in modo strutturato e a formulare suggerimenti mirati, sarà in grado di agire in modo indipendente in seguito, senza doversi affidare a costosi fornitori di cloud. In breve: l'IA locale è il percorso tranquillo e sicuro verso un futuro digitale in cui potrete di nuovo tenere i vostri dati e i vostri strumenti nelle vostre mani.



