
Günümüzde yapay zeka ile çalışan herkesin aklına ilk olarak ChatGPT veya benzeri çevrimiçi hizmetler geliyor. Bir soru yazıyorsunuz, birkaç saniye bekliyorsunuz - ve sanki hattın diğer ucunda çok iyi okumuş, sabırlı bir diyalog ortağı oturuyormuş gibi bir cevap alıyorsunuz. Ancak kolayca unutulan şey: Her girdi, her cümle, her kelime internet üzerinden harici sunuculara gönderilir. Asıl iş burada yapılıyor - sizin asla göremeyeceğiniz devasa bilgisayarlarda.
Prensip olarak, yerel dil modeli de aynı şekilde çalışır - ancak internet olmadan. Model, kullanıcının kendi bilgisayarında bir dosya olarak saklanır, başlangıçta çalışma belleğine yüklenir ve soruları doğrudan cihaz üzerinde yanıtlar. Arkasındaki teknoloji aynı: dili anlayan, metinler üreten ve kalıpları tanıyan bir sinir ağı. Tek fark, tüm hesaplamanın şirket içinde kalmasıdır. Şöyle de diyebilirsiniz: Bulut olmadan ChatGPT.
Bu konuda özel olan şey, teknolojinin artık devasa veri merkezlerine ihtiyaç duymayacak kadar gelişmiş olmasıdır. M işlemcili (M3 veya M4 gibi) modern Apple bilgisayarlar muazzam bir hesaplama gücüne, hızlı bellek bağlantılarına ve makine öğrenimi için özel bir sinir motoruna sahiptir. Sonuç olarak, birçok model artık doğrudan bir Mac Mini veya Mac Studio üzerinde çalıştırılabilir - bir sunucu çiftliği olmadan, karmaşık kurulum olmadan ve önemli bir gürültü olmadan.



Apple MLX ve NVIDIA hakkındaki son haberler
26.03.2026: Apple, MLX AI çerçevesini stratejik olarak geliştirmeye devam ediyor ve bunu giderek diğer platformlara da açıyor. Başlangıçta yalnızca Apple Silicon için optimize edilmiştir, MLX artık CUDA GPU'ları da destekliyor ve dolayısıyla klasik Nvidia donanımı. Bu, geliştiriciler için önemli bir engeli ortadan kaldırıyor: şimdiye kadar modellerin genellikle Mac üzerinde geliştirilmesi ve ardından ayrı yüksek performanslı sistemlerde eğitilmesi gerekiyordu. MLX, açılarak hem Apple cihazlarda yerel yapay zeka hem de harici donanımlarda ölçeklenebilir eğitim sağlayan daha esnek bir geliştirme platformu haline geliyor. Aynı zamanda, örneğin verimli bellek yönetimi ve doğrudan GPU kullanımı yoluyla Apple'nin kendi mimarisiyle yakın entegrasyon avantajı korunuyor. Bu gelişme stratejik bir rota değişikliğine işaret ediyor: Apple kapalı ekosistemini yavaş yavaş terk ediyor ve MLX'i yerleşik yapay zeka çerçevelerine ciddi bir alternatif olarak konumlandırıyor - bir bütün olarak yapay zeka gelişimi için potansiyel etkileri var.
Bu sadece geliştiriciler için değil, aynı zamanda girişimciler, yazarlar, avukatlar, doktorlar, öğretmenler ve esnaflar için de yeni bir kapı açıyor. Artık herkes kendi küçük yapay zekasına sahip olabilir - masasında, tam kontrol altında, her an kullanıma hazır. Yerel bir dil modeli şunları yapabilir:
- Metinler özetleyin veya düzeltin,
- E-postalar formüle etmek veya yapılandırmak,
- Sorular soruları yanıtlamak ve bilgiyi analiz etmek,
- Süreçler programlarda destek,
- Belgeler arama veya sınıflandırma,
- veya basitçe kişisel asistan Dış dünyaya veri sızdırmadan.
Bu yaklaşım, özellikle veri koruma ve dijital egemenliğin bir kez daha ön plana çıktığı bir dönemde giderek daha önemli hale geliyor. Kullanmak için programcı olmanıza gerek yok - ihtiyacınız olan tek şey modern bir Mac. Modeller bir uygulama ya da terminal penceresi aracılığıyla kolayca başlatılabilir ve ardından tarayıcıdaki bir sohbet penceresi kadar doğal bir şekilde yanıt verebilir.
Bu makale, günümüzde hangi modellerin hangi Mac üzerinde çalıştırılabileceğini, donanımın ne yapması gerektiğini ve Apple Silicon bilgisayarların bunun için neden özellikle uygun olduğunu göstermektedir. Kısacası, yapay zekanın gücünü sessiz, verimli ve yerel olarak kendi ellerinize nasıl geri alacağınızla ilgili.
Mac'te yerel dil modelleri - Bu neden şimdi mantıklı?
Bir dil modelinin „yerel olarak“ çalıştırılması, bir bulut hizmetine bağlantı olmadan tamamen kendi bilgisayarınızda çalıştırılması anlamına gelir. Hesaplama, girdilerin analizi, metinlerin veya cevapların oluşturulması - her şey doğrudan kendi cihazınızda gerçekleşir. Bu nedenle model SSD'de bir dosya olarak saklanır, başlangıçta RAM'e yüklenir ve orada sistemin tam performansıyla çalışır.
Bulut varyantından en önemli farkı bağımsızlıktır. Hiçbir veri internet üzerinden akmaz, harici sunucular kullanılmaz ve hiç kimse dahili olarak neyin işlendiğini izleyemez. Bu, özellikle veri hareketlerinin izlenmesinin giderek zorlaştığı zamanlarda önemli ölçüde veri koruması ve kontrolü sağlar.
Geçmişte bu tür modellerin yerel olarak çalıştırılması düşünülemezdi. Bu büyüklükteki bir sinir ağını çalışır durumda tutmak için bir ana bilgisayar veya GPU çiftliği gerekiyordu. Bugün, modern Apple-Silicon çiplerin hesaplama gücü ile bu, verimli, sessiz ve düşük güç tüketimi ile bir masaüstü cihazda gerçekleştirilebilir.
Neden Apple Silicon idealdir
Apple Silicon'ye geçişle birlikte, Apple kartları yeniden karıştırdı. Ayrı CPU ve GPU'ya sahip klasik Intel mimarisi yerine, Apple birleşik bellek tasarımına dayanıyor: işlemci, grafik ve sinir motoru aynı hızlı ana belleğe erişiyor. Bu, tek tek bileşenler arasında veri kopyalama ihtiyacını ortadan kaldırıyor - yapay zeka hesaplamaları için belirleyici bir avantaj.
Nöral motorun kendisi, doğrudan çiplere entegre edilen makine öğrenimi için özel bir bilgi işlem çekirdeğidir. Çok düşük enerji tüketimiyle saniyede milyarlarca işlem yapılmasını sağlar. MLX kütüphanesi (Machine Learning for Apple Silicon) ve OLaMA gibi modern çerçevelerle birlikte, modeller artık karmaşık GPU sürücüleri veya CUDA bağımlılıkları olmadan doğrudan macOS üzerinde çalışabilir.
Mac Mini'deki bir M4 çipi, kompakt dil modellerini (örneğin 3-7 milyar parametre) sorunsuz bir şekilde çalıştırmak için zaten yeterlidir. M4 Max veya M3 Ultra'ya sahip bir Mac Studio'da, 30 milyar parametreli modelleri bile tamamen yerel olarak çalıştırabilirsiniz.
Karşılaştırma: Apple Silicon vs. NVIDIA donanımı
Geleneksel olarak, NVIDIA'nın RTX grafik kartları yapay zeka hesaplamaları için altın standart olmuştur. Örneğin güncel bir RTX 5090, muazzam bir ham performans sunar ve hala birçok eğitim sistemi için ilk tercihtir. Bununla birlikte, öncelikler farklı olduğu için ayrıntılı bir karşılaştırma yapmak faydalı olacaktır.
| Aspect | Apple Silicon (M4 / M4 Max / M3 Ultra) | NVIDIA GPU (5090 & Co.) |
|---|---|---|
| Enerji tüketimi | Çok verimli - genellikle 100 W'tan az toplam tüketim | Yalnızca GPU için 450 W'a kadar |
| Gürültü gelişimi | Neredeyse sessiz | Yük altında açıkça duyulabilir |
| Yazılım Yığını | MLX / Core ML / Metal | CUDA / cuDNN / PyTorch |
| Bakım | Sürücüsüz ve kararlı | Sık güncellemeler ve uyumluluk sorunları |
| Fiyat-performans oranı | Makul fiyata yüksek verimlilik | Daha iyi tepe performansı, ancak daha pahalı |
| Şunlar için ideal | Yerel çıkarım ve sürekli çalışma | Eğitim ve büyük modeller |
Kısacası: NVIDIA, veri merkezleri ve ekstrem eğitim için bir seçimdir. Apple Silicon ise gürültüsüz, ısı birikimsiz, istikrarlı bir yazılım temeli ve yönetilebilir güç tüketimi ile yerel, uzun süreli kullanım için idealdir.
Apple Silicon çıkarım için NVIDIA ile karşılaştırıldı
M3 Ultra, Apple Silicon için önemli bir adımdır: CPU, GPU ve nöral motoru tek bir pakette barındıran son derece entegre bir çip tasarımına ek olarak, RAM ve GPU VRAM'in klasik ayrımı olmaksızın RAM'in tüm bilgi işlem birimleri tarafından aynı anda kullanıldığı birleşik bir bellek mimarisine dayanır. Karşılaştırmalı testlere göre bu yaklaşım, yerel çıkarım görevlerinde bazı durumlarda NVIDIA'nın üst düzey grafik kartlarıyla karşılaştırılabilir hatta daha iyi performans elde ediyor. Bir örnek: Testte M3 Ultra, Qwen3-30B 4bit modeliyle yaklaşık 2.320 token/s'ye ulaşırken RTX 3090 2.157 token/s'de kaldı.
Ek olarak, Apple Silicon ile NVIDIA'nın AI yükleri altında karşılaştırılması, bir M3/M4 Max sisteminin yük altında yaklaşık 40-80W arasında bir değer elde edeceğini, bir RTX 4090'ın ise tipik olarak 450W'a kadar çekeceğini göstermektedir.
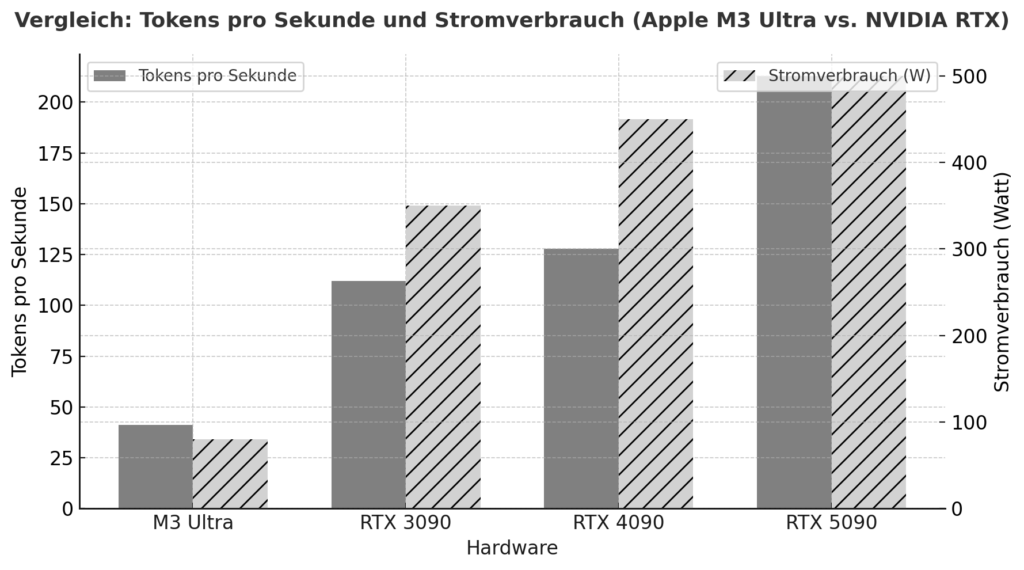
Bu, yalnızca en yüksek performansa değil, aynı zamanda watt başına verimliliğe de bakarsanız, Apple Silicon'nin mükemmel bir konumda olduğunu göstermektedir. Öte yandan, muazzam paralelleştirilmiş GPU mimarisi, çok yüksek CUDA/tensör çekirdek yoğunluğu ve özel kütüphaneleri (CUDA, cuDNN, TensorRT) ile NVIDIA kartları (örneğin 3090, 4090, 5090) var. Bu, ham üst-flop performansının genellikle önde olduğu yerdir - ancak yerel dil modelleri için belirleyici sınırlamalar vardır: 20-30 milyar veya daha fazla parametreye sahip modeller yüklenecekse mevcut VRAM (örneğin oyun kartları için 24-32 GB) hızla bir darboğaz haline gelir. Örneğin bir kullanıcı raporu, yaklaşık 32 GB VRAM'e sahip bir RTX 5090 ile 20-22 milyar parametreye sahip bir modeli yerleştirmenin zaten zor olduğunu belirtiyor.
Bu bağlamda, yalnızca GPU çekirdeklerine değil, aynı zamanda mevcut bellek boyutuna, bant genişliğine ve bellek mimarisine de bakmalısınız. Örneğin 512 GB'a kadar birleşik belleğe sahip M3 Ultra (en üst konfigürasyonlarda), birçok yerel dağıtım senaryosunda avantajlar sunar - özellikle de modeller bulutta değil, kalıcı olarak yerel olarak çalışacaksa.
| Donanım | Model / Kurulum | Saniye başına jeton (yaklaşık) | Açıklama |
|---|---|---|---|
| Apple M3 Ultra (Mac Studio) | z. örneğin M3 Ultra'da Gemma-3-27B-Q4 | ≈ 41 tok/s :contentReference[oaicite:2]{index=2} | LLM Çıkarsaması, bağlam 4k belirteç, nicelleştirilmiş |
| NVIDIA RTX 5090 | 8 Çalışmaya göre B modeli (sayısallaştırılmış) | ≈ 213 tok/s :contentReference[oaicite:3]{index=3} | 8 B modeli, 4 bit, RLHF ortamı |
| NVIDIA RTX 4090 | 8 B Model referansı | ≈ 128 tok/s :contentReference[oaicite:4]{index=4} | 24 GB VRAM Ortamı |
| NVIDIA RTX 3090 | Karşılaştırmalı olarak Bütçe HighEnd | ≈ 112 tok/s :contentReference[oaicite:5]{index=5} | İkinci el piyasası, 24 GB VRAM |
Pratik uygunluk: Yerel dil modellerinin anlamlı olduğu yerler
Yerel yapay zekanın olası uygulamaları günümüzde neredeyse sınırsızdır. Verilerin gizli kalması gerektiğinde veya süreçlerin gerçek zamanlı olarak çalışması gerektiğinde, yerel sürüm faydalı olacaktır. Uygulamadan örnekler:
- ERP sistemleriOtomatik metin analizi, öneriler, tahminler veya iletişim yardımcıları - doğrudan yazılımdan.
- Kitap ve medya prodüksiyonuStil kontrolü, çeviri, özet, metin genişletme - hepsi yerel olarak, bulut bağımlılığı olmadan.
- Avukatlar ve noterlerBelge analizi, taslak savunmalar, araştırma - en katı gizlilik altında.
- Doktorlar ve terapistlerVaka değerlendirmesi, dokümantasyon veya otomatik raporlar - hasta verileri sistemden hiç çıkmadan.
- Mühendislik ofisleri ve mimarlarİnternet olmadan da çalışan metin, proje ve hesaplama sihirbazları.
- Genel olarak şirketBilgi yönetimi, dahili sohbet asistanları, protokol analizi, e-posta sınıflandırması - hepsi kendi ağınız içinde.
Bu, özellikle ticari sektörde büyük bir adım: harici yapay zeka hizmetlerine ödeme yapmak ve verileri buluta göndermek yerine, artık kendi makinelerinizde özelleştirilmiş modeller çalıştırabilirsiniz. Bunlar şirketin kendi bilgisiyle özelleştirilebilir, ince ayar yapılabilir ve genişletilebilir - tamamen kontrol altında.
Sonuç, kendi verileri üzerindeki egemenlikten vazgeçmeden teknolojiyi kullanan modern ancak geleneksel olarak egemen bir BT ortamıdır. Bize eski erdemleri hatırlatan bir yaklaşım: işleri kendi elimizde tutmak.
Yerel yapay zeka sistemleri üzerine güncel araştırma
Genel bakış: Mac Mini ve Mac Studio - şu anda mevcut olanlar
Bugün yerel dil modellerini bir Mac üzerinde çalıştırmak istiyorsak, özellikle iki masaüstü sınıfı odak noktasıdır: Mac mini ve Mac Studio.
- Mac MiniEn yeni nesil Apple M4 çip veya isteğe bağlı olarak M4 Pro sunmaktadır. Teknik özelliklere göre, 24 GB veya 32 GB birleşik belleğe sahip varyantlar mevcuttur; Pro varyantı 48 GB veya 64 GB'a kadar yapılandırılabilir birleşik bellek ile sunulmaktadır. Bu, Mac Mini'yi birçok uygulama için çok uygun hale getiriyor - özellikle de model aşırı büyük değilse veya paralel olarak çok büyük birkaç görevi çalıştırması gerekmiyorsa.
- Mac StüdyoBurada bir adım daha yukarı çıkıyoruz. Örneğin, modele bağlı olarak Apple M4 Max çip veya M3 Ultra çip ile donatılmıştır. M4 Max versiyonu ile 48 GB, 64 GB veya 128 GB'a kadar birleşik bellek mümkündür. Mac Studio'nun M3 Ultra versiyonu 512 GB'a kadar birleşik bellekle donatılabilir. SSD boyutları ve bellek bant genişlikleri de önemli ölçüde artıyor. Bu da Mac Studio'yu daha zorlu modeller veya paralel süreçler için uygun hale getiriyor.
Kısa bir not olarak Mac Pro Ayrıca „daha fazla kasa“ ya da PCI-e yuvaları da mevcut - ancak dil modelleri açısından, herhangi bir ek genişletme kartınız ya da özel PCIe gereksiniminiz yoksa yerel sürüm için Mac Studio'ya göre pek bir avantaj sunmuyor.
Ayrıca Defterler (örneğin MacBook Pro) kesinlikle kullanılabilir - ancak kısıtlamalarla: Soğutma sistemleri daha küçüktür, termal performans daha sınırlıdır ve RAM bütçesi genellikle daha düşüktür. Uzun süreli kullanım (AI modellerinde olduğu gibi) performansı düşürebilir.

AI: Apple Nvidia'dan daha iyi! 😮 | c't 3003
RAM / birleşik bellek neden bu kadar önemli?
Bir dil modeli yerel olarak çalıştığında, ihtiyaç duyulan sadece CPU veya GPU performansı değildir - RAM (veya Apple durumunda „birleşik bellek“) de çok önemlidir. Neden mi?
Modelin kendisi (ağırlıklar, aktivasyonlar, ara sonuçlar) bellekte tutulmalıdır. Model ne kadar büyük olursa, o kadar fazla bellek gerekir. Apple-Silicon yongaları "birleşik bellek" kullanır, yani CPU, GPU ve nöral motor aynı bellek havuzuna erişir. Bu da bileşenler arasında veri kopyalama ihtiyacını ortadan kaldırarak verimliliği ve hızı artırır.
Yeterli RAM yoksa, sistemin değiştirilmesi gerekir veya modeller tam olarak yüklenmez - bu da performansta düşüş, istikrarsızlık veya iptal anlamına gelebilir. Özellikle çıkarımsal uygulamalarda (yanıt oluşturma, metin girişi, model genişletme), yanıt süresi ve verim çok önemlidir - yeterli bellek burada önemli ölçüde yardımcı olur. Geleneksel bir masaüstü bilgisayar „CPU RAM“ ve „ayrı GPU RAM“ terimleriyle düşünürdü - Apple Silicon ile zarif bir şekilde birleştirilmiştir, bu da dil modellerini çalıştırmayı özellikle cazip hale getirir.
Tahmini değerler: Hangi büyüklük sırası gerçekçidir?
Hangi donanıma ihtiyacınız olacağını tahmin etmenize yardımcı olmak için, işte birkaç kaba kılavuz değer:
- Daha küçük modeller için (örneğin birkaç milyar parametre), 16 GB ila 32 GB RAM yeterli olabilir - özellikle de yalnızca tek tek sorgular işlenecekse. Bu nedenle 16/32 GB'lık bir Mac Mini iyi bir başlangıç olacaktır.
- Orta boy modeller için (örn. 3-10 milyar parametre) veya birkaç paralel sohbet veya büyük miktarda metin içeren görevler için 32 GB veya daha fazla RAM'i düşünmelisiniz - örn. 32 veya 48 GB'lık Mac Studio.
- Büyük modeller için (>20 milyar parametre) veya birden fazla model paralel çalışacaksa 64 GB veya daha fazlasını seçebilirsiniz - burada 64 GB veya daha yüksek Mac mini ve Mac Studio varyantları mümkündür.
Önemli: Bir miktar tampon planlamayı unutmayın - sadece model değil, aynı zamanda işlem de (örneğin işletim sistemi, dosya G/Ç, diğer uygulamalar) bellek rezervleri gerektirir.
| Kategori | Tipik model boyutu | Önerilen RAM bütçesi | Kullanım örneği |
|---|---|---|---|
| Küçük | 1-3 milyar parametre | 16-32 GB | Basit asistan, metin tanıma |
| Orta | 7-13 milyar Parametreler | 32-64 GB | Sohbet, analiz, metin oluşturma |
| Büyük | 30-70 milyar parametre | 64 GB + | Özel metinler, yasal belgeler |
Geleneksel "sunucu vs. masaüstü" zihniyetinin sorgulanması
Geleneksel olarak insanlar yapay zekanın sunucu çiftlikleri, çok sayıda GPU, çok fazla güç ve bir veri merkezi gerektirdiğini düşünüyordu. Ancak tablo değişiyor: Mac Mini veya Mac Studio gibi masaüstü bilgisayarlar artık büyük bir altyapı olmadan yerel olarak çalıştırılan birçok dil modeli için yeterli performans sunuyor. Yüksek elektrik maliyetleri, güçlü soğutma ve karmaşık bakım yerine, masanızda sessiz, etkili bir cihaz elde edersiniz.
Elbette, modelleri büyük ölçekte eğitmek veya çok sayıda parametre kullanmak istiyorsanız, sunucu çözümleri hala mantıklıdır. Ancak masaüstü donanımı genellikle çıkarım, özelleştirme ve günlük kullanım için yeterlidir. Bu, geleneksel bir tutumla ilişkilidir: teknolojiyi kullanın, ancak aşırı büyütmeyin - daha ziyade hedefli ve verimli bir şekilde kullanın. Bugün sağlam bir yerel temel oluşturursanız, yarın mümkün olacaklar için temel oluşturursunuz.

M3 Ultra vs RTX 5090 | Son Savaş (İngilizce)
Dil modellerinin teknik karakterizasyonu
Günümüzde dil modelleri yalnızca yetenekleri açısından değil, aynı zamanda mevcut oldukları teknik format açısından da farklılık göstermektedir. Bu formatlar modelin nasıl kaydedileceğini, yükleneceğini ve kullanılacağını ve belirli bir sistemde çalışıp çalışmayacağını belirler.
GGUF (GPT Tarafından Oluşturulan Birleşik Format)
Bu format Ollama, LM Studio veya Llama.cpp gibi araçlarda pratik kullanım için geliştirilmiştir. Kompakt, taşınabilir ve yerel çıkarım için son derece optimize edilmiştir. GGUF modelleri genellikle sayısallaştırılmıştır, bu da dahili sayısal değerler azaltılmış biçimde (örneğin 4 bit veya 8 bit) saklandığı için önemli ölçüde daha az bellek tükettikleri anlamına gelir. Sonuç olarak, başlangıçta 30-50 GB boyutunda olan modeller, yalnızca hafif bir kalite kaybıyla 5-10 GB'a sıkıştırılabilir.
- AvantajNeredeyse tüm sistemlerde (macOS, Windows, Linux) çalışır, özel bir GPU gerektirmez.
- DezavantajEğitim veya ince ayar için tasarlanmamıştır - saf çıkarım (yani kullanım).
MLX (Apple Silicon için Makine Öğrenimi)
MLX, Apple Silicon üzerinde makine öğrenimi için Apple'nin kendi açık kaynak çerçevesidir. M-Chip'lerdeki CPU, GPU ve Neural Engine'in tüm gücünü kullanmak için özel olarak geliştirilmiştir. MLX modelleri genellikle yerel MLX formatında mevcuttur veya diğer formatlardan dönüştürülür.
- AvantajApple donanımında maksimum performans ve enerji verimliliği.
- DezavantajHala nispeten genç bir ekosistem, GGUF veya PyTorch'a göre daha az topluluk modeli mevcut.
Safetensors (.safetensors)
Bu format PyTorch dünyasından gelmektedir (ve Hugging Face tarafından güçlü bir şekilde desteklenmektedir). Kod yürütülmesine izin vermeyen büyük modeller için güvenli, ikili bir depolama formatıdır - dolayısıyla „güvenli“ adı verilmiştir.
- AvantajÇok hızlı yükleme, bellek tasarrufu, standartlaştırılmış.
- Dezavantaj: Temel olarak PyTorch veya TensorFlow gibi çerçeveler için tasarlanmıştır - yani geliştirici ortamlarında ve eğitim süreçlerinde daha yaygındır.
| Biçim | Platform | Amaç | Avantajlar | Dezavantajlar |
|---|---|---|---|---|
| GGUF | macOS, Windows, Linux | Çıkarım | Kompakt, hızlı, evrensel | Eğitim mümkün değil |
| MLX | macOS (Apple Silicon) | Çıkarım + Eğitim | M-Chip'ler için optimize edilmiş, yüksek verimlilik | Daha az model mevcut |
| Safetensörler | Çapraz platform (PyTorch / TensorFlow) | Eğitim ve Araştırma | Güvenli, standartlaştırılmış, hızlı | Ollama / MLX ile doğrudan uyumlu değildir |
Hugging Face - merkezi tedarik kaynağı
Bugün, Hugging Face yapay zeka dünyasının "kütüphanesi" gibi bir şey. Üzerinde huggingface.co on binlerce model, veri seti ve araç bulacaksınız - bunların çoğunu kullanmak ücretsizdir. İsme, mimariye, lisans türüne veya dosya formatına göre filtreleme yapabilirsiniz. İster Mistral, LLaMA, Falcon, Gemma veya Phi-3 olsun - neredeyse tüm iyi bilinen modeller burada temsil edilmektedir. Çok sayıda geliştirici, GGUF veya MLX ile yerel kullanım için özelleştirilmiş sürümler sunmaktadır.
Bu da Hugging Face'i, bir modeli denemek ya da macOS için uygun bir varyant bulmak isteyen çoğu kullanıcı için ilk başvuru noktası haline getiriyor.

Tipik modeller ve uygulama alanları
Mevcut modellerin sayısını takip etmek artık neredeyse imkansız. Bununla birlikte, yerel kullanım için özellikle başarılı olduğu kanıtlanmış birkaç ana aile vardır:
- LLaMA ailesi (Meta): En iyi bilinen açık kaynak modellerinden biridir. Sayısız türev için temel oluşturur (örneğin Vicuna, WizardLM, Open-Hermes). Güçlü yönleri: Dil anlama, diyalog, çok yönlü kullanım. Uygulama alanı: Genel sohbet uygulamaları, içerik üretimi, yardım sistemleri.
- Mistral & Mixtral (Mistral AI)Küçük bir model boyutuyla yüksek verimlilik ve iyi kalite ile tanınır. Mixtral 8x7B birkaç uzman modelini birleştirir (Mixture-of-Experts mimarisi). Güçlü yönleri: Hızlı, kesin cevaplar, kaynak tasarrufu. Uygulama alanı: Şirket içi asistanlar, metin analizi, veri hazırlama.
- Phi-3 (Microsoft Research)Kompakt model, düşük parametre sayısına rağmen yüksek ses kalitesi için optimize edilmiştir. Güçlü yönleri: Verimlilik, iyi dilbilgisi, yapılandırılmış yanıtlar. Uygulama alanı: Daha küçük sistemler, yerel bilgi modelleri, entegre asistanlar.
- Gemma (Google): Google Research tarafından açık bir model olarak yayınlanmıştır. Özet ve açıklayıcı görevler için iyi. Güçlü yönleri: Tutarlılık, bağlamsallaştırılmış açıklamalar. Uygulama alanı: bilgi işleme, eğitim, danışmanlık sistemleri.
- GPT-OSS / OpenHermes modelleriLLaMA modifikasyonları ile birlikte, açık kaynak modelleri ile ticari sistemlerin işlevsel kapsamı arasında bir "köprü" oluştururlar. Güçlü yönleri: Geniş dil tabanı, esnek kullanım. Uygulama alanı: İçerik oluşturma, sohbet ve analiz görevleri, dahili yapay zeka yardımı.
- Claude / Command R / Falcon / Yi / ZephyrBunlar ve diğer birçok model (çoğunlukla araştırma projelerinden veya açık topluluklardan) bilgi alma, kod oluşturma veya çok dillilik gibi özel işlevler sunar.
En önemli nokta, hiçbir modelin her şeyi mükemmel bir şekilde yapamayacağıdır. Her birinin güçlü ve zayıf yönleri vardır - ve uygulamaya bağlı olarak, hedefe yönelik bir karşılaştırma yapmaya değer.
Hangi model hangi amaç için uygundur?
Gerçekçi bir değerlendirme elde etmek için modeller kabaca performans ve uygulama sınıflarına ayrılabilir:
Özetler, yazışmalar, çeviri, analiz gibi çoğu gerçekçi masaüstü uygulaması için orta modeller (7-13 B) tamamen yeterlidir. İnanılmaz derecede iyi sonuçlar verirler, sorunsuz çalışırlar 32-48 GB RAM ile Mac Mini M4 Pro ve neredeyse hiç yeniden ayarlama gerektirmez.
Büyük modeller Daha derin bir anlayış veya daha uzun bağlamlar önemli olduğunda - örneğin yasal metinleri veya teknik belgeleri işlerken - güçlü yönlerini gösterirler. Ancak, en az bir tanesine sahip olmalısınız 64-128 GB ile Mac Studio Çalışma belleğini kullanın.
| Model ailesi | Köken | Güçlü Yönler | Uygulama alanı |
|---|---|---|---|
| LLaMA | Meta | Dili anlama, diyalog | Genel sohbet uygulamaları |
| Mistral / Mixtral | Mistral AI | Verimlilik, yüksek hassasiyet | Şirket asistanları, analiz |
| Phi-3 | Microsoft Araştırma | Kompakt, dilsel açıdan güçlü | Küçük sistemler, yerel yapay zeka |
| Gemma | Google Araştırma | Tutarlılık, açıklanabilirlik | Danışmanlık, öğretim, metin açıklama |
Dil modellerini yerel olarak çalıştırma seçenekleri
Bugün kendi Mac'inizde bir dil modeli kullanmak istiyorsanız, teknik gereksinimlerinize ve istediğiniz amaca bağlı olarak birkaç uygulanabilir seçenek vardır. İşin en güzel yanı, başlamak için artık karmaşık bir geliştirme ortamına ihtiyacınız olmaması.
Ollama - karmaşık olmayan başlangıç
Ollama hızla yerel yapay zeka modelleri için standart bir araç haline gelmiştir. MacOS üzerinde yerel olarak çalışır, Apple Silicon'nin performansını en iyi şekilde kullanır ve bir modelin tek bir komutla başlatılmasına olanak tanır:
ollama run mistral
Bu, istenen modeli otomatik olarak yükler ve hazırlar, daha sonra terminalde veya yerel arayüzler aracılığıyla kullanılabilir. Ollama, GGUF formatını destekler, Hugging Face'ten model indirilmesine izin verir ve REST API'leri aracılığıyla veya doğrudan diğer programlara entegre edilebilir.
Nasıl çalışılır Ollama yerel bir dil modeli installiert ve başka hangi seçeneklere sahip olduğunuz başka bir makalede ayrıntılı olarak açıklanmaktadır. Ayrıca nasıl kullanılacağına dair başka makaleler de vardır Qdrant esnek bir bellek yerel yapay zekası için.
LM Studio - grafiksel kullanıcı arayüzü ve yönetim
LM Stüdyo grafiksel bir kullanıcı arayüzünü tercih eden herkese yöneliktir. Model indirmeleri, sohbet pencereleri, sıcaklık kontrolleri, sistem uyarıları ve bellek yönetimini tek bir uygulamada sunar. Bu özellikle yeni başlayanlar için idealdir: komut satırıyla çalışmak zorunda kalmadan farklı modelleri deneyebilir, karşılaştırabilir, kaydedebilir ve bunlar arasında geçiş yapabilirsiniz. Yazılım Apple Silicon üzerinde kararlı bir şekilde çalışır ve GGUF modellerini de destekler.
MLX / Python - geliştiriciler ve entegratörler için
Daha derine inmek veya modelleri kendi programlarınıza entegre etmek istiyorsanız, Apple'nin MLX çerçevesini kullanabilirsiniz. Bu, modellerin doğrudan Python veya Swift uygulamalarına gömülmesini sağlar. Avantajı, maksimum kontrol ve mevcut iş akışlarına entegrasyonda yatmaktadır - örneğin, bir şirket kendi yazılımına AI işlevleri eklemek istiyorsa.
FileMaker Sunucu 2025 - Kurumsal bağlamda yapay zeka
O zamandan beri FileMaker Sunucu 2025 MLX tabanlı dil modelleri sunucu tarafında da ele alınabilir. Bu da ilk kez merkezi bir iş uygulamasının (örneğin ERP veya CRM sistemi) kendi yerel yapay zekası ile donatılmasını mümkün kılıyor. Örneğin, destek talepleri otomatik olarak sınıflandırılabilir, müşteri talepleri değerlendirilebilir veya belgelerdeki içerik analiz edilebilir - veriler şirket dışına çıkmadan.
Bu özellikle katı veri koruma veya uyumluluk gereklilikleri olan sektörler (tıp, hukuk, idare, endüstri) için ilgi çekicidir.
Tipik engeller ve bunlardan nasıl kaçınılacağı
Giriş engeli düşük olsa bile, dikkat etmeniz gereken birkaç nokta var:
Bellek sınırları: Model mevcut bellek için çok büyükse, hiç başlamayacak veya çok yavaş olacaktır. Nicelleştirme (örneğin 4 bit) veya daha küçük bir model burada yardımcı olabilir.
- Yük ve ısı gelişiminin hesaplanması: Mac, uzun oturumlar sırasında fark edilir derecede ısınabilir. İyi havalandırma ve etkinlik ekranına göz kulak olmanız tavsiye edilir.
- Üçüncü taraf yazılımlar için GPU desteği eksikliğiBazı eski araçlar veya bağlantı noktaları Neural Engine'i verimli bir şekilde kullanmaz. Bu gibi durumlarda MLX daha iyi sonuçlar sağlayabilir.
- Ağ bağlantı noktaları ve haklarıBirden fazla istemci aynı modele erişecekse (örneğin bir şirket ağı içinde), yerel bağlantı noktaları serbest bırakılmalıdır - tercihen HTTPS veya dahili bir proxy aracılığıyla güvence altına alınmalıdır.
- Veri güvenliğiModeller yerel olarak çalışsa bile hassas metinler güvensiz ortamlarda saklanmamalıdır. Yerel günlükler ve sohbet günlüklerinin unutulması kolaydır, ancak genellikle değerli bilgiler içerir.
Bu noktalara dikkat ederseniz, şaşırtıcı derecede az çabayla güvenli, sessiz ve verimli çalışan güçlü, yerel bir AI sistemi çalıştırabilirsiniz.
Zaman çizelgesi ve stratejik hususlar
Önümüzdeki yıllarda birçok mesleğin günlük yaşamını değiştirecek bir gelişmenin henüz başındayız. Yerel yapay zeka modelleri giderek daha küçük, daha hızlı ve daha verimli hale gelirken kaliteleri de artmaya devam edecek. Bugün hala 30 GB bellek gerektiren bir şey, bir yıl sonra aynı ses kalitesiyle yalnızca 10 GB gerektirebilir. Aynı zamanda, modelleri doğrudan Office programlarına, tarayıcılara veya şirket yazılımlarına entegre etmek için kullanılabilecek yeni arayüzler ortaya çıkıyor.
Bugün yerel bir yapay zeka altyapısına doğru adım atan şirketler, kendileri için bir avantaj yaratıyor. Uzmanlık geliştiriyor, veri egemenliklerini güvence altına alıyor ve kendilerini fiyat dalgalanmalarından veya harici sağlayıcılar tarafından uygulanan kullanım kısıtlamalarından bağımsız hale getiriyorlar. Mantıklı bir strateji şu şekilde olabilir:
- İlk olarak küçük bir modelle deneme yapın (örneğin Ollama veya LM Studio aracılığıyla 3-7 milyar parametre).
- Ardından hangi görevlerin otomatikleştirilebileceğini özellikle kontrol edin.
- Gerekirse, daha büyük modelleri entegre edin veya "AI sunucusu" olarak merkezi bir Mac Studio kurun.
- Orta vadede, yapay zeka desteği ile iç süreçleri (örneğin dokümantasyon, metin analizi, iletişim) yeniden düzenleyin.
Bu adım adım yaklaşım sadece ekonomik olarak mantıklı değil, aynı zamanda sürdürülebilirdir - trendler tarafından yönlendirilmek yerine teknolojiyi kendi hızınızda benimseme ilkesini takip eder.
Ayrı bir makalede, daha yeni teknolojilerin nasıl kullanıldığını ayrıntılı olarak anlattım. GGUF ile karşılaştırıldığında MLX formatı Mac'te Ollama aracılığıyla.
Dijital egemenliğe giden sessiz bir yol olarak yerel yapay zeka
Yerel dil modelleri, dijital dünyada kendi kaderini tayin etmeye geri dönüşü işaret ediyor.
Verileri ve fikirleri uzaktaki bulut veri merkezlerine göndermek yerine, artık kendi araçlarınızla yine doğrudan masanızda, kendi kontrolünüz altında çalışabilirsiniz.
İster Mac Mini, ister Mac Studio veya güçlü bir dizüstü bilgisayarda olsun - doğru donanıma sahipseniz, artık kendi yapay zekanızı kullanabilir, eğitebilir ve daha da geliştirebilirsiniz. İster kişisel asistan olarak, ister bir ERP sisteminin parçası olarak, ister bir yayınevinde araştırma yardımcısı olarak veya bir hukuk firmasında veri koruma uyumlu bir çözüm olarak - olasılıklar şaşırtıcı derecede geniş.
Ve bununla ilgili en iyi şey: bize bilgisayarın eski gücünü hatırlatıyor - yani nasıl çalışmamız gerektiğini dikte eden bir hizmetten ziyade kendi kendinizi kontrol ettiğiniz bir araç olmak. Bu da yerel yapay zekayı modern özerkliğin bir sembolü haline getiriyor - sessiz, verimli ve yine de etkileyici bir etkiye sahip.
Şirketteki yerel yapay zeka, doğru sistem temeli ile değerini ortaya çıkarır
 Yerel yapay zeka hakkındaki tartışmalar genellikle donanım, modeller ve hıza odaklanır; ancak gerçek faydalar yalnızca kendi verileriniz ve süreçlerinizle etkileşim halinde ortaya çıkar. Yapay zekayı gerçekten mantıklı bir şekilde kullanmak istiyorsanız, bilginin dağınık değil, yapılandırılmış bir şekilde mevcut olduğu istikrarlı, kontrollü bir ortama ihtiyacınız vardır. İşte tam da bu noktada yerel olarak işletilen ERP çözümü Şirket içindeki veriler, süreçler ve korelasyonlar için omurgayı oluşturur. Bu, gFM Business ERP gibi bir çözümle birlikte, yerel yapay zekanın yalnızca yanıtlar sağlamakla kalmayıp, aynı zamanda bağlamsallaştırılmış bir şekilde - örneğin kendi bilgi grafiğini entegre ederek - çalıştığı kapalı bir döngü oluşturur. Kararlar artık genel modellere değil, gerçek şirket verilerine dayanıyor. Sonuç, gerçek dijital egemenliğe doğru sessiz ama etkili bir adımdır: daha fazla kontrol, daha fazla verimlilik ve şirkete uyum sağlayan bir sistem - tam tersi değil.
Yerel yapay zeka hakkındaki tartışmalar genellikle donanım, modeller ve hıza odaklanır; ancak gerçek faydalar yalnızca kendi verileriniz ve süreçlerinizle etkileşim halinde ortaya çıkar. Yapay zekayı gerçekten mantıklı bir şekilde kullanmak istiyorsanız, bilginin dağınık değil, yapılandırılmış bir şekilde mevcut olduğu istikrarlı, kontrollü bir ortama ihtiyacınız vardır. İşte tam da bu noktada yerel olarak işletilen ERP çözümü Şirket içindeki veriler, süreçler ve korelasyonlar için omurgayı oluşturur. Bu, gFM Business ERP gibi bir çözümle birlikte, yerel yapay zekanın yalnızca yanıtlar sağlamakla kalmayıp, aynı zamanda bağlamsallaştırılmış bir şekilde - örneğin kendi bilgi grafiğini entegre ederek - çalıştığı kapalı bir döngü oluşturur. Kararlar artık genel modellere değil, gerçek şirket verilerine dayanıyor. Sonuç, gerçek dijital egemenliğe doğru sessiz ama etkili bir adımdır: daha fazla kontrol, daha fazla verimlilik ve şirkete uyum sağlayan bir sistem - tam tersi değil.
Önerilen kaynaklar
- Apple Silicon üzerinde Büyük Dil Modeli Çıkarımının Profilinin ÇıkarılmasıBir Niceleme Perspektifi (Benazir & Lin vd., 2025) - NVIDIA GPU'lara kıyasla Apple Silicon üzerindeki çıkarım performansını, özellikle nicelemeye odaklanarak ayrıntılı olarak inceler.
- Apple Silicon üzerinde Üretim Sınıfı Yerel LLM Çıkarsaması: MLX, MLC-LLM, Ollama, llama.cpp ve PyTorch MPS Üzerine Karşılaştırmalı Bir Çalışma (Rajesh vd., 2025) - MLX dahil Apple Silicon üzerinde farklı platformların verim, gecikme, bağlam uzunluğu açısından karşılaştırılması.
- MLX ile Apple Silicon üzerinde Cihaz Üzerinde Makine Öğrenimini Kıyaslama (Ajayi & Odunayo, 2025) - NVIDIA sistemlerine karşı kıyaslama verileriyle MLX ve Apple Silicon'ye odaklanmıştır.



Sıkça sorulan sorular
- Yerel dil modeli tam olarak nedir?
Yerel dil modeli, ChatGPT'ye benzer şekilde metinleri anlayabilen ve oluşturabilen bir yapay zekadır. Aradaki fark, internet üzerinden değil, doğrudan kendi bilgisayarınızda çalışmasıdır. Tüm hesaplamalar yerel olarak gerçekleşir ve harici sunuculara hiçbir veri gönderilmez. Bu, kendi bilgileriniz üzerinde tam kontrole sahip olduğunuz anlamına gelir. - Yerel bir yapay zeka ChatGPT gibi bir bulut çözümüne göre ne gibi avantajlar sunuyor?
En büyük üç avantaj veri koruması, bağımsızlık ve maliyet kontrolüdür.
- Veri koruma: Hiçbir metin bilgisayardan çıkmaz.
- Bağımsızlık: İnternet bağlantısı gerekmez, sağlayıcı değişikliği veya arıza riski yoktur.
- Maliyetler: Talep başına devam eden ücret yok. Donanım için bir kez ödeme yaparsınız - hepsi bu. - Bir dil modelini yerel olarak kullanmak için programlama becerilerine ihtiyacınız var mı?
Hayır. Ollama veya LM Studio gibi modern araçlarla, bir model sadece birkaç tıklama ile başlatılabilir. Bugün, yeni başlayanlar bile tek bir satır kod yazmadan sadece birkaç dakika içinde yerel bir yapay zeka çalıştırabilir. - Hangi Apple cihazları özellikle uygundur?
Yeni başlayanlar için M4 veya M4 Pro ve en az 32 GB RAM'e sahip bir Mac Mini genellikle yeterlidir. Daha büyük modelleri veya aynı anda birkaç modeli kullanmak istiyorsanız, 64 GB veya 128 GB RAM'li bir Mac Studio tercih etmeniz daha iyi olur. Mac Pro, PCI-e yuvalarına ihtiyacınız olmadığı sürece neredeyse hiçbir avantaj sunmaz. Dizüstü bilgisayarlar uygundur, ancak termal sınırlarına daha çabuk ulaşırlar. - Sahip olmanız gereken minimum RAM miktarı nedir?
Bu, model boyutuna bağlıdır.
- Küçük modeller (1-3 milyar parametre): 16-32 GB yeterlidir.
- Orta modeller (7-13 milyar): 48-64 GB daha iyi.
- Büyük modeller (30bn+): 128 GB veya daha fazla.
Bir miktar rezerv planlamak önemlidir - aksi takdirde bekleme süreleri veya iptaller olacaktır. - Apple Silicon için "Birleşik Bellek" ne anlama geliyor?
Birleşik bellek, CPU, GPU ve nöral motor tarafından aynı anda erişilen paylaşılan bir bellektir. Bu, farklı bellek alanları arasında veri kopyalamaya gerek olmadığından zaman ve enerji tasarrufu sağlar. Bu, özellikle yapay zeka hesaplamaları için büyük bir avantajdır, çünkü her şey tek bir akışta çalışır. - GGUF, MLX ve Safetensors arasındaki fark nedir?
- GGUF: Yerel kullanım için kompakt bir format (örneğin Ollama veya LM Studio'da). Çıkarım, yani bitmiş modellerin yürütülmesi için idealdir.
- MLX: Apple'nin özellikle M çipleri için kendi formatı. Çok verimli, ancak hala genç.
- Safetensörler: PyTorch dünyasından, öncelikle eğitim ve araştırma amaçlı bir format.
GGUF veya MLX, Mac'te yerel kullanım için idealdir. - Modelleri nereden alıyorsunuz?
En iyi bilinen platform huggingface.co'dur - AI modelleri için büyük bir kütüphane. Burada LLaMA, Mistral, Gemma, Phi-3 ve diğerlerinin varyantlarını bulabilirsiniz. Birçok model GGUF formatında zaten mevcuttur ve doğrudan Ollama'ye yüklenebilir. - Başlamak için en kolay araçlar hangileridir?
Yeni başlayanlar için Ollama ve LM Studio idealdir. Ollama terminalde çalışır ve hafiftir. LM Studio, sohbet pencereli bir grafik kullanıcı arayüzü sunar. Her ikisi de modelleri otomatik olarak yükler ve başlatır ve karmaşık kurulum gerektirmez. - Dil modelleri FileMaker Server ile de kullanılabilir mi?
Evet - FileMaker Server 2025'ten beri MLX modelleri doğrudan adreslenebilir. Bu, örneğin ERP veya CRM sistemlerinde metin analizlerine, sınıflandırmalara veya otomatik değerlendirmelere olanak tanır. Bu, gizli iş verilerinin harici sağlayıcılara gönderilmesine gerek kalmadan yerel olarak işlenmesine olanak tanır. - Bu tür modeller genellikle ne kadar büyüktür?
Küçük modeller sadece birkaç gigabayt, büyük modeller ise 20 - 30 GB veya daha fazla olabilir. Niceleme yoluyla (örneğin 4 bit), genellikle minimum kalite kaybıyla boyutları büyük ölçüde azaltılabilir. Örneğin sıkıştırılmış bir 13-B modeli yalnızca 7 GB yer kaplayabilir - Mac Mini M4 Pro için mükemmeldir. - Yerel modelleri eğitmek veya özelleştirmek mümkün mü?
Temel olarak evet - ancak eğitim hesaplama açısından çok yoğundur. MLX veya Python çerçeveleri daha küçük modellerin yerel ince ayarı için kullanılabilir. Bugün, FileMaker aşağıdakiler için entegre bir işlev içermektedir Dil modellerine doğrudan ince ayar yapın bunu yapabilmek için. Ancak büyük ölçekli eğitim için (örneğin 50 milyar parametre) özel bir GPU çiftliği gerekli olacaktır. Çoğu uygulama için mevcut modelleri kullanmak ve bunları özellikle istemler aracılığıyla kontrol etmek yeterlidir. - Yapay zeka hesaplamaları sırasında bir Mac ne kadar güç tüketir?
Şaşırtıcı derecede az. Tek bir NVIDIA grafik kartı (örneğin RTX 5090) CPU ve çevre birimleri olmadan 450 W'a kadar enerji çekerken, bir Mac Studio tam çalışma sırasında genellikle 100 W'ın altındadır. Bu, Apple donanımında yerel yapay zekanın yalnızca daha sessiz değil, aynı zamanda önemli ölçüde daha enerji verimli olduğu anlamına gelir. - MacBook Pro yerel yapay zeka için uygun mu?
Evet, ama kısıtlamalarla.
Performans yüksek olmasına rağmen termal yük kapasitesi sınırlıdır. İşlemci uzun oturumlar sırasında yavaşlıyor. MacBook Pro M3/M4 kısa sohbetler, metin görevleri veya analizler için mükemmeldir ancak uzun süreli kullanım için uygun değildir. - Yerel modeller gerçekten ne kadar güvenli?
Üzerinde çalıştıkları sistem kadar güvenlidirler. İnternet üzerinden hiçbir veri gönderilmediğinden, üçüncü taraflardan kaynaklanan neredeyse hiçbir risk yoktur. Ancak geçici dosyaların, günlüklerin veya sohbet geçmişlerinin yanlışlıkla bulut klasörlerine (örn. iCloud Drive) düşmediğinden emin olmalısınız. Dahili SSD'de yerel depolama idealdir. - Yeni başlayanların yaptığı tipik hatalar nelerdir?
- Yeterli RAM olmamasına rağmen çok büyük modellerin yüklenmesi.
- Ollama veya LM Studio'nun eski sürümlerini kullanın.
- GPU hızlandırmayı etkinleştirmeyin (örn. MLX).
- Arka planda çok fazla işlem çalışıyor.
- Şüpheli kaynaklardan model yükleme.
Çözüm: Yalnızca güvenilir kaynakları kullanın (örn. Hugging Face) ve sistem kaynaklarına dikkat edin. - Yerel yapay zeka teknolojisi önümüzdeki birkaç yıl içinde nasıl gelişecek?
Modeller daha da kompakt ve hassas hale geliyor. Apple, Mistral ve Meta halihazırda aynı kalite için daha az bellek ve güç gerektiren mimariler üzerinde çalışıyor. Aynı zamanda, kelime işlem, posta programları veya not uygulamaları için yapay zeka eklentileri gibi kullanışlı arayüzler geliştiriliyor. Uzun vadede, her profesyonel sistemin bir tür „yerleşik yerel yapay zekaya“ sahip olması muhtemeldir. - Neden şimdi başlamaya değer?
Çünkü önümüzdeki yılların temelleri şu anda atılıyor. Bugün bir modeli yerel olarak başlatmayı, verileri yapılandırılmış bir şekilde işlemeyi ve hedeflenen istemleri formüle etmeyi öğrenen herkes, daha sonra pahalı bulut sağlayıcılarına güvenmek zorunda kalmadan bağımsız olarak hareket edebilecektir. Kısacası: yerel yapay zeka, verilerinizi ve araçlarınızı bir kez daha kendi ellerinizde tutabileceğiniz dijital bir geleceğe giden sakin ve emin bir yoldur.



