Każdy, kto pracuje dziś ze sztuczną inteligencją, często najpierw myśli o ChatGPT lub podobnych usługach online. Wpisujesz pytanie, czekasz kilka sekund - i otrzymujesz odpowiedź tak, jakby na drugim końcu linii siedział bardzo oczytany, cierpliwy rozmówca. Ale o czym łatwo zapomnieć: Każde wejście, każde zdanie, każde słowo jest wysyłane do zewnętrznych serwerów przez Internet. To tam wykonywana jest właściwa praca - na ogromnych komputerach, których nigdy nie można zobaczyć.
Zasadniczo lokalny model językowy działa dokładnie w ten sam sposób - ale bez Internetu. Model jest przechowywany jako plik na komputerze użytkownika, jest ładowany do pamięci roboczej podczas uruchamiania i odpowiada na pytania bezpośrednio na urządzeniu. Technologia stojąca za nim jest taka sama: sieć neuronowa, która rozumie język, generuje teksty i rozpoznaje wzorce. Jedyna różnica polega na tym, że całość obliczeń pozostaje w firmie. Można powiedzieć: ChatGPT bez chmury.
Szczególne jest to, że technologia ta rozwinęła się do tego stopnia, że nie wymaga już ogromnych centrów danych. Nowoczesne komputery Apple z procesorami M (takimi jak M3 lub M4) dysponują ogromną mocą obliczeniową, szybkimi połączeniami pamięci i wyspecjalizowanym silnikiem neuronowym do uczenia maszynowego. Oznacza to, że wiele modeli może być teraz obsługiwanych bezpośrednio na komputerach Mac Mini lub Mac Studio - bez farmy serwerów, bez skomplikowanej konfiguracji i bez znacznego rozwoju hałasu.



Najnowsze wiadomości o Apple MLX i NVIDIA
26.03.2026Apple kontynuuje strategiczny rozwój swojej struktury MLX AI i coraz bardziej otwiera ją na inne platformy. Pierwotnie zoptymalizowany wyłącznie dla Apple Silicon, MLX obsługuje teraz także procesory graficzne CUDA a zatem klasyczny sprzęt Nvidia. Usuwa to kluczową przeszkodę dla programistów: do tej pory modele często musiały być opracowywane na komputerach Mac, a następnie trenowane na oddzielnych systemach o wysokiej wydajności. Otwierając się, MLX staje się bardziej elastyczną platformą programistyczną, która umożliwia zarówno lokalną sztuczną inteligencję na urządzeniach Apple, jak i skalowalne szkolenie na sprzęcie zewnętrznym. Jednocześnie zachowana zostaje zaleta ścisłej integracji z własną architekturą Apple, na przykład poprzez wydajne zarządzanie pamięcią i bezpośrednie wykorzystanie GPU. Rozwój wskazuje na strategiczną zmianę kursu: Apple stopniowo opuszcza swój zamknięty ekosystem i pozycjonuje MLX jako poważną alternatywę dla uznanych frameworków AI - z potencjalnymi konsekwencjami dla rozwoju AI jako całości.
Otwiera to nowe drzwi nie tylko dla programistów, ale także dla przedsiębiorców, autorów, prawników, lekarzy, nauczycieli i handlowców. Każdy może teraz mieć własną małą sztuczną inteligencję - na swoim biurku, pod pełną kontrolą, gotową do użycia w dowolnym momencie. Lokalny model językowy może:
- Teksty podsumować lub poprawić,
- E-maile formułować lub strukturyzować,
- Pytania odpowiadać na pytania i analizować wiedzę,
- Procesy wsparcie w programach,
- Dokumenty wyszukiwać lub klasyfikować,
- lub po prostu jako osobisty asystent bez wycieku danych na zewnątrz.
Podejście to staje się coraz ważniejsze, zwłaszcza w czasach, gdy ochrona danych i suwerenność cyfrowa ponownie zajmują centralne miejsce. Nie trzeba być programistą, by z niego korzystać - wystarczy nowoczesny komputer Mac. Modele można po prostu uruchomić za pomocą aplikacji lub okna terminala, a następnie reagować niemal tak naturalnie, jak okno czatu w przeglądarce.
Ten artykuł pokazuje, które modele można obecnie uruchomić na którym komputerze Mac, co musi zrobić sprzęt i dlaczego komputery Apple Silicon są do tego szczególnie odpowiednie. Krótko mówiąc, chodzi o to, jak wziąć moc sztucznej inteligencji z powrotem w swoje ręce - cicho, wydajnie i lokalnie.
Lokalne modele językowe na komputerach Mac - dlaczego ma to teraz sens?
Uruchamianie modelu językowego „lokalnie“ oznacza, że jest on obsługiwany w całości na komputerze użytkownika - bez połączenia z usługą w chmurze. Obliczenia, analiza danych wejściowych, generowanie tekstów lub odpowiedzi - wszystko odbywa się bezpośrednio na urządzeniu użytkownika. Model jest zatem przechowywany jako plik na dysku SSD, jest ładowany do pamięci RAM podczas uruchamiania i działa tam z pełną wydajnością systemu.
Kluczową różnicą w stosunku do wariantu chmurowego jest niezależność. Żadne dane nie przepływają przez Internet, nie są używane żadne zewnętrzne serwery i nikt nie może śledzić tego, co jest przetwarzane wewnętrznie. Zapewnia to znaczny stopień ochrony danych i kontroli - zwłaszcza w czasach, gdy przepływ danych staje się coraz trudniejszy do śledzenia.
W przeszłości uruchamianie takich modeli lokalnie było nie do pomyślenia. Aby sieć neuronowa tej wielkości mogła w ogóle działać, potrzebny był komputer typu mainframe lub farma procesorów graficznych. Dziś, dzięki mocy obliczeniowej nowoczesnych układów Apple-Silicon, można to osiągnąć na urządzeniu stacjonarnym - wydajnie, cicho i przy niskim zużyciu energii.
Dlaczego Apple Silicon jest idealny
Wraz z przejściem na Apple Silicon przetasował karty. Zamiast klasycznej architektury Intela z oddzielnym CPU i GPU, Apple opiera się na tak zwanej zunifikowanej konstrukcji pamięci: procesor, grafika i silnik neuronowy uzyskują dostęp do tej samej szybkiej pamięci głównej. Eliminuje to potrzebę kopiowania danych między poszczególnymi komponentami - co jest decydującą zaletą w przypadku obliczeń AI.
Sam silnik neuronowy to wyspecjalizowany rdzeń obliczeniowy do uczenia maszynowego, który jest zintegrowany bezpośrednio z chipami. Umożliwia on wykonywanie miliardów operacji obliczeniowych na sekundę - przy bardzo niskim zużyciu energii. Wraz z biblioteką MLX (Machine Learning for Apple Silicon) i nowoczesnymi frameworkami, takimi jak OLaMA, modele mogą teraz działać bezpośrednio na macOS bez skomplikowanych sterowników GPU lub zależności CUDA.
Układ M4 w komputerze Mac Mini jest już wystarczający do płynnego uruchamiania kompaktowych modeli językowych (np. 3-7 miliardów parametrów). Na Mac Studio z M4 Max lub M3 Ultra można nawet uruchamiać modele z 30 miliardami parametrów - całkowicie lokalnie.
Porównanie: Apple Silicon vs. sprzęt NVIDIA
Tradycyjnie, karty graficzne NVIDIA RTX były złotym standardem dla obliczeń AI. Przykładowo, obecny RTX 5090 oferuje ogromną surową wydajność i nadal jest pierwszym wyborem dla wielu systemów szkoleniowych. Niemniej jednak warto dokonać szczegółowego porównania, ponieważ priorytety są różne.
| Aspekt | Apple Silicon (M4 / M4 Max / M3 Ultra) | Procesor graficzny NVIDIA (5090 & Co.) |
|---|---|---|
| Zużycie energii | Bardzo wysoka wydajność - zwykle poniżej 100 W całkowitego zużycia energii | Do 450 W dla samego procesora graficznego |
| Rozwój hałasu | Praktycznie bezgłośny | Wyraźnie słyszalny pod obciążeniem |
| Stos oprogramowania | MLX / Core ML / Metal | CUDA / cuDNN / PyTorch |
| Konserwacja | Bez kierowcy i stabilnie | Częste aktualizacje i problemy z kompatybilnością |
| Stosunek ceny do wydajności | Wysoka wydajność w umiarkowanej cenie | Lepsza wydajność szczytowa, ale droższa |
| Idealny dla | Lokalne wnioskowanie i ciągłe działanie | Trening i duże modele |
W skrócie: NVIDIA to wybór dla centrów danych i ekstremalnych treningów. Apple Silicon, z drugiej strony, jest idealny do lokalnego, długotrwałego użytkowania - bez hałasu, bez gromadzenia się ciepła, ze stabilną podstawą oprogramowania i zarządzalnym zużyciem energii.
Apple Silicon w porównaniu z NVIDIA dla wnioskowania
M3 Ultra stanowi znaczący krok naprzód dla Apple Silicon: oprócz wysoce zintegrowanej konstrukcji układu z CPU, GPU i silnikiem neuronowym w jednym pakiecie, opiera się na ujednoliconej architekturze pamięci, w której pamięć RAM jest używana przez wszystkie jednostki obliczeniowe jednocześnie - bez klasycznego oddzielania pamięci RAM i GPU VRAM. Według testów porównawczych, podejście to już teraz osiąga porównywalną lub nawet lepszą wydajność w lokalnych zadaniach wnioskowania niż wysokiej klasy karty graficzne NVIDIA w niektórych przypadkach. Jeden przykład: W teście M3 Ultra osiągnął ok. 2320 tokenów/s z 4-bitowym modelem Qwen3-30B w porównaniu do RTX 3090 na poziomie 2157 tokenów/s.
Dodatkowo, porównanie Apple Silicon vs NVIDIA pod obciążeniem AI sugeruje, że system M3/M4 Max osiągnie około 40-80W pod obciążeniem, podczas gdy RTX 4090 będzie zazwyczaj pobierał do 450W.
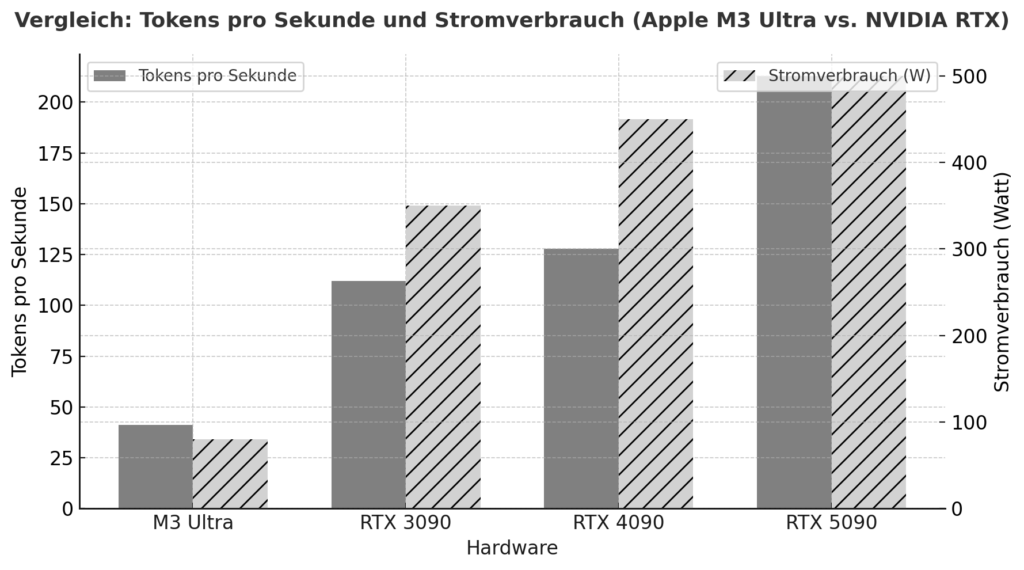
Pokazuje to, że jeśli spojrzeć nie tylko na szczytową wydajność, ale także na wydajność na wat, Apple Silicon jest w doskonałej pozycji. Z drugiej strony mamy karty NVIDIA (np. 3090, 4090, 5090) z ich ogromną równoległą architekturą GPU, bardzo wysoką gęstością rdzeni CUDA/tensorowych i wyspecjalizowanymi bibliotekami (CUDA, cuDNN, TensorRT). To właśnie tutaj surowa wydajność top-flops jest często lepsza - ale z decydującymi ograniczeniami dla lokalnych modeli językowych: dostępna pamięć VRAM (np. 24-32 GB dla kart do gier) szybko staje się wąskim gardłem, jeśli mają być ładowane modele z 20-30 miliardami parametrów lub więcej. Jeden z raportów użytkowników stwierdza na przykład, że w przypadku RTX 5090 z około 32 GB pamięci VRAM, model z 20-22 miliardami parametrów jest już trudny do dostosowania.
Pod tym względem należy zwrócić uwagę nie tylko na rdzenie GPU, ale także na dostępny rozmiar pamięci, przepustowość i architekturę pamięci. Przykładowo, M3 Ultra z nawet 512 GB zunifikowanej pamięci (w najlepszych konfiguracjach) oferuje tutaj przewagę w wielu scenariuszach lokalnych wdrożeń - zwłaszcza jeśli modele nie mają być uruchamiane w chmurze, ale na stałe lokalnie.
| Sprzęt | Model / konfiguracja | Żetony na sekundę (w przybliżeniu) | Uwaga |
|---|---|---|---|
| Apple M3 Ultra (Mac Studio) | z. np. Gemma-3-27B-Q4 na M3 Ultra | ≈ 41 tok/s :contentReference[oaicite:2]{index=2} | Wnioskowanie LLM, kontekst 4k tokenów, kwantyzacja |
| NVIDIA RTX 5090 | 8 Model B (ilościowy) zgodnie z badaniem | ≈ 213 tok/s :contentReference[oaicite:3]{index=3} | Model 8 B, 4-bitowy, środowisko RLHF |
| NVIDIA RTX 4090 | 8 B Odniesienie do modelu | ≈ 128 tok/s :contentReference[oaicite:4]{index=4} | 24 GB pamięci VRAM Środowisko |
| NVIDIA RTX 3090 | Budżet HighEnd w porównaniu | ≈ 112 tok/s :contentReference[oaicite:5]{index=5} | Rynek wtórny, 24 GB VRAM |
Praktyczne znaczenie: gdzie lokalne modele językowe mają sens
Możliwości zastosowania lokalnej sztucznej inteligencji są dziś niemal nieograniczone. Wszędzie tam, gdzie dane muszą pozostać poufne lub procesy muszą działać w czasie rzeczywistym, warto skorzystać z wersji lokalnej. Przykłady z praktyki:
- Systemy ERPAutomatyczna analiza tekstu, sugestie, prognozy lub pomoce komunikacyjne - bezpośrednio z oprogramowania.
- Produkcja książek i mediówSprawdzanie stylu, tłumaczenie, podsumowanie, rozszerzanie tekstu - wszystko lokalnie, bez zależności od chmury.
- Prawnicy i notariuszeAnaliza dokumentów, projekty pism procesowych, badania - z zachowaniem ścisłej poufności.
- Lekarze i terapeuciOcena przypadku, dokumentacja lub zautomatyzowane raporty - bez opuszczania systemu przez dane pacjenta.
- Biura inżynieryjne i architekciKreatory tekstu, projektów i obliczeń, które działają również bez Internetu.
- Firma ogólnieZarządzanie wiedzą, asystenci czatów wewnętrznych, analiza protokołów, klasyfikacja wiadomości e-mail - wszystko w ramach własnej sieci.
To duży krok, zwłaszcza w sektorze komercyjnym: zamiast płacić za zewnętrzne usługi AI i wysyłać dane do chmury, można teraz uruchamiać niestandardowe modele na własnych maszynach. Można je dostosowywać, dopracowywać i rozszerzać o własną wiedzę firmy - całkowicie pod kontrolą.
Rezultatem jest nowoczesny, ale tradycyjnie suwerenny krajobraz IT, który wykorzystuje technologię bez rezygnacji z kontroli nad własnymi danymi. Podejście, które przypomina nam o starych cnotach: trzymaniu rzeczy we własnych rękach.
Bieżąca analiza lokalnych systemów sztucznej inteligencji
Przegląd: Mac Mini i Mac Studio - co jest obecnie dostępne
Jeśli chcemy dziś uruchamiać lokalne modele językowe na komputerach Mac, to szczególnie ważne są dwie klasy komputerów stacjonarnych: Mac mini i Mac Studio.
- Mac MiniNajnowsza generacja oferuje układ Apple M4 lub opcjonalnie M4 Pro. Zgodnie ze specyfikacją techniczną, dostępne są warianty ze zunifikowaną pamięcią 24 GB lub 32 GB; wariant Pro oferowany jest z konfigurowalną zunifikowaną pamięcią do 48 GB lub 64 GB. Sprawia to, że Mac Mini dobrze nadaje się do wielu zastosowań - zwłaszcza jeśli model nie jest wyjątkowo duży lub nie musi równolegle uruchamiać kilku bardzo dużych zadań.
- Mac StudioTutaj idziemy o krok wyżej. Wyposażone na przykład w układ Apple M4 Max lub M3 Ultra - w zależności od modelu. W wersji M4 Max możliwe jest zastosowanie 48 GB, 64 GB lub do 128 GB zunifikowanej pamięci. Wersja M3 Ultra komputera Mac Studio może być wyposażona w maksymalnie 512 GB zunifikowanej pamięci. Rozmiary dysków SSD i przepustowość pamięci również znacznie wzrosły. Dzięki temu Mac Studio nadaje się do bardziej wymagających modeli lub procesów równoległych.
W skrócie: The Mac Pro również istnieje i często oferuje „więcej obudowy“ lub gniazd PCI-e na zewnątrz - ale pod względem modeli językowych nie oferuje dużej przewagi nad Mac Studio dla wersji lokalnej, jeśli nie masz żadnych dodatkowych kart rozszerzeń lub specjalnych wymagań PCIe.
Również Notatniki (np. MacBook Pro) z pewnością mogą być używane - ale z ograniczeniami: Systemy chłodzenia są mniejsze, wydajność termiczna jest bardziej ograniczona, a budżet pamięci RAM jest często niższy. Długotrwałe użytkowanie (jak w przypadku modeli AI) może obniżyć wydajność.

AI: Apple lepszy niż Nvidia! 😮 | c't 3003
Dlaczego pamięć RAM / pamięć zunifikowana jest tak ważna
Gdy model językowy działa lokalnie, potrzebna jest nie tylko wydajność CPU lub GPU - kluczowa jest pamięć RAM (lub w przypadku Apple: „pamięć zunifikowana“). Dlaczego?
Sam model (wagi, aktywacje, wyniki pośrednie) musi być przechowywany w pamięci. Im większy model, tym więcej pamięci jest wymagane. Układy Apple-Silicon wykorzystują „zunifikowaną pamięć“, tj. CPU, GPU i silnik neuronowy uzyskują dostęp do tej samej puli pamięci. Eliminuje to potrzebę kopiowania danych między komponentami, co zwiększa wydajność i szybkość.
Jeśli nie ma wystarczającej ilości pamięci RAM, system musi się wymieniać lub modele nie są w pełni załadowane - co może oznaczać spadek wydajności, niestabilność lub anulowanie. Zwłaszcza w przypadku aplikacji wnioskowania (generowanie odpowiedzi, wprowadzanie tekstu, rozszerzanie modeli) czas reakcji i przepustowość mają kluczowe znaczenie - wystarczająca ilość pamięci znacznie tu pomaga. Tradycyjny komputer stacjonarny zwykł myśleć w kategoriach „pamięci RAM CPU“ i „oddzielnej pamięci RAM GPU“ - z Apple Silicon jest to elegancko połączone, co sprawia, że uruchamianie modeli językowych jest szczególnie atrakcyjne.
Szacowane wartości: Jaki rząd wielkości jest realistyczny?
Aby pomóc ci oszacować, jakiego sprzętu będziesz potrzebować, oto kilka przybliżonych wartości orientacyjnych:
- Dla mniejszych modeli (np. kilka miliardów parametrów), 16 GB do 32 GB pamięci RAM może być wystarczające - zwłaszcza jeśli przetwarzane mają być tylko pojedyncze zapytania. Mac Mini z 16/32 GB byłby zatem dobrym początkiem.
- Dla modeli średnich (np. 3-10 miliardów parametrów) lub zadania z kilkoma równoległymi czatami lub dużymi ilościami tekstu, warto rozważyć 32 GB RAM lub więcej - np. Mac Studio z 32 lub 48 GB.
- Dla dużych modeli (>20 miliardów parametrów) lub jeśli kilka modeli ma działać równolegle, można wybrać 64 GB lub więcej - możliwe są tutaj warianty Mac mini i Mac Studio z 64 GB lub więcej.
Ważne: Należy pamiętać o zaplanowaniu bufora - nie tylko model, ale także działanie (np. system operacyjny, wejścia/wyjścia plików, inne aplikacje) wymaga rezerw pamięci.
| Kategoria | Typowy rozmiar modelu | Zalecany budżet pamięci RAM | Przykład zastosowania |
|---|---|---|---|
| Mały | 1-3 miliardy parametrów | 16-32 GB | Prosty asystent, rozpoznawanie tekstu |
| Średni | 7-13 miliardów Parametry | 32-64 GB | Czat, analiza, tworzenie tekstu |
| Duży | Parametry 30-70 mld | 64 GB + | Teksty specjalistyczne, dokumenty prawne |
Kwestionowanie tradycyjnego sposobu myślenia „serwer kontra desktop“
Tradycyjnie ludzie uważali, że sztuczna inteligencja wymaga farm serwerów, wielu procesorów graficznych, dużej mocy i centrum danych. Obraz ten ulega jednak zmianie: komputery stacjonarne, takie jak Mac Mini lub Mac Studio, oferują obecnie wystarczającą wydajność dla wielu lokalnie obsługiwanych modeli językowych - bez ogromnej infrastruktury. Zamiast wysokich kosztów energii elektrycznej, potężnego chłodzenia i skomplikowanej konserwacji, zyskujesz ciche, wydajne urządzenie na swoim biurku.
Oczywiście, jeśli chcesz trenować modele na dużą skalę lub używać dużej liczby parametrów, rozwiązania serwerowe nadal mają sens. Jednak sprzęt stacjonarny jest często wystarczający do wnioskowania, dostosowywania i codziennego użytku. Wiąże się to z tradycyjnym podejściem: używaj technologii, ale nie przesadzaj z nią - raczej używaj jej w ukierunkowany i wydajny sposób. Jeśli dziś zbudujesz solidną bazę lokalną, stworzysz fundament dla tego, co będzie możliwe jutro.

M3 Ultra vs RTX 5090 | Ostateczna bitwa (w języku angielskim)
Charakterystyka techniczna modeli językowych
Obecnie modele językowe różnią się nie tylko możliwościami, ale także formatem technicznym, w jakim są dostępne. Formaty te określają, w jaki sposób model jest zapisywany, ładowany i używany - i czy w ogóle może działać w danym systemie.
GGUF (GPT-Generated Unified Format)
Format ten został opracowany do praktycznego wykorzystania w narzędziach takich jak Ollama, LM Studio lub Llama.cpp. Jest on kompaktowy, przenośny i wysoce zoptymalizowany pod kątem lokalnego wnioskowania. Modele GGUF są zwykle kwantyzowane, co oznacza, że zużywają znacznie mniej pamięci, ponieważ wewnętrzne wartości liczbowe są przechowywane w zredukowanej formie (np. 4-bitowej lub 8-bitowej). W rezultacie modele, które pierwotnie miały rozmiar 30-50 GB, można skompresować do 5-10 GB - z niewielką utratą jakości.
- PrzewagaDziała na prawie każdym systemie (macOS, Windows, Linux), nie wymaga specjalnego GPU.
- WadaNie jest przeznaczony do szkolenia lub dostrajania - czyste wnioskowanie (tj. wykorzystanie).
MLX (uczenie maszynowe dla Apple Silicon)
MLX to własny framework open source Apple do uczenia maszynowego na Apple Silicon. Został on specjalnie opracowany w celu wykorzystania pełnej mocy CPU, GPU i silnika neuronowego w układach M-Chip. Modele MLX są zwykle dostępne w natywnym formacie MLX lub są konwertowane z innych formatów.
- PrzewagaMaksymalna wydajność i energooszczędność na sprzęcie Apple.
- WadaWciąż stosunkowo młody ekosystem, mniej dostępnych modeli społeczności niż w przypadku GGUF lub PyTorch.
Safetensors (.safetensors)
Format ten wywodzi się ze świata PyTorch (i jest mocno promowany przez Hugging Face). Jest to bezpieczny, binarny format przechowywania dużych modeli, który nie pozwala na wykonanie kodu - stąd nazwa „bezpieczny“.
- PrzewagaBardzo szybkie ładowanie, oszczędność pamięci, standaryzacja.
- WadaPrzeznaczony głównie dla frameworków takich jak PyTorch lub TensorFlow - tj. bardziej powszechnych w środowiskach programistycznych i procesach szkoleniowych.
| Format | Platforma | Cel | Zalety | Wady |
|---|---|---|---|---|
| GGUF | macOS, Windows, Linux | Wnioskowanie | Kompaktowy, szybki, uniwersalny | Brak możliwości szkolenia |
| MLX | macOS (Apple Silicon) | Wnioskowanie + szkolenie | Zoptymalizowany dla układów M-Chip, wysoka wydajność | Mniej dostępnych modeli |
| Czujniki bezpieczeństwa | Międzyplatformowy (PyTorch / TensorFlow) | Szkolenia i badania | Bezpieczne, znormalizowane, szybkie | Nie jest bezpośrednio kompatybilny z Ollama / MLX |
Hugging Face - centralne źródło zaopatrzenia
Dziś Hugging Face jest czymś w rodzaju „biblioteki“ świata AI. Na huggingface.co znajdziesz dziesiątki tysięcy modeli, zestawów danych i narzędzi, z których wiele jest darmowych. Możesz filtrować według nazwy, architektury, typu licencji lub formatu pliku. Czy to Mistral, LLaMA, Falcon, Gemma czy Phi-3 - prawie wszystkie znane modele są tam reprezentowane. Wielu deweloperów oferuje już dostosowane wersje do użytku lokalnego z GGUF lub MLX.
To sprawia, że Hugging Face jest pierwszym portem dla większości użytkowników, którzy chcą wypróbować model lub znaleźć odpowiedni wariant dla macOS.

Typowe modele i obszary ich zastosowania
Liczba dostępnych modeli jest obecnie niemal niemożliwa do ogarnięcia. Niemniej jednak istnieje kilka głównych rodzin, które okazały się szczególnie udane do użytku lokalnego:
- Rodzina LLaMA (Meta)Jeden z najbardziej znanych modeli open source. Stanowi podstawę dla niezliczonych pochodnych (np. Vicuna, WizardLM, Open-Hermes). Mocne strony: rozumienie języka, dialog, wszechstronne zastosowanie. Obszar zastosowań: Ogólne aplikacje czatu, generowanie treści, systemy pomocy.
- Mistral i Mixtral (Mistral AI)Znany z wysokiej wydajności i dobrej jakości przy niewielkich rozmiarach modelu. Mixtral 8x7B łączy w sobie kilka modeli eksperckich (architektura Mixture-of-Experts). Mocne strony: Szybkie, precyzyjne odpowiedzi, oszczędność zasobów. Obszar zastosowań: Wewnętrzni asystenci firmy, analiza tekstu, przygotowywanie danych.
- Phi-3 (Microsoft Research)Kompaktowy model, zoptymalizowany pod kątem wysokiej jakości głosu pomimo niewielkiej liczby parametrów. Mocne strony: Wydajność, dobra gramatyka, ustrukturyzowane odpowiedzi. Obszar zastosowań: Mniejsze systemy, lokalne modele wiedzy, zintegrowani asystenci.
- Gemma (Google)Opublikowany przez Google Research jako model otwarty. Dobry do zadań podsumowujących i wyjaśniających. Mocne strony: spójność, kontekstowe wyjaśnienia. Obszar zastosowań: przetwarzanie wiedzy, szkolenia, systemy doradcze.
- Modele GPT-OSS / OpenHermesWraz z modyfikacjami LLaMA tworzą one „pomost“ między modelami open source a zakresem funkcjonalnym systemów komercyjnych. Mocne strony: Szeroka baza językowa, elastyczne zastosowanie. Obszar zastosowań: Tworzenie treści, czat i zadania analityczne, wewnętrzna pomoc AI.
- Claude / Command R / Falcon / Yi / ZephyrTe i wiele innych modeli (głównie z projektów badawczych lub otwartych społeczności) oferują specjalne funkcje, takie jak wyszukiwanie wiedzy, generowanie kodu lub wielojęzyczność.
Najważniejszą kwestią jest to, że żaden model nie może zrobić wszystkiego idealnie. Każdy z nich ma swoje mocne i słabe strony - i w zależności od zastosowania warto dokonać ukierunkowanego porównania.
Który model jest odpowiedni do jakiego celu?
Aby uzyskać realistyczną ocenę, modele można z grubsza podzielić na klasy wydajności i zastosowań:
W przypadku większości realistycznych aplikacji desktopowych - takich jak streszczenia, korespondencja, tłumaczenia, analizy - średnie modele (7-13 B) są w zupełności wystarczające. Zapewniają zadziwiająco dobre wyniki, działają płynnie na Mac Mini M4 Pro z 32-48 GB pamięci RAM i nie wymagają prawie żadnej regulacji.
Duże modele pokazują swoje mocne strony, gdy ważne jest głębsze zrozumienie lub dłuższy kontekst - na przykład podczas przetwarzania tekstów prawnych lub dokumentacji technicznej. Powinieneś jednak mieć co najmniej jedną Mac Studio z pamięcią 64-128 GB Korzystanie z pamięci roboczej.
| Rodzina modeli | Pochodzenie | Mocne strony | Zakres zastosowania |
|---|---|---|---|
| LLaMA | Meta | Rozumienie języka, dialog | Ogólne aplikacje do czatowania |
| Mistral / Mixtral | Mistral AI | Wydajność, wysoka precyzja | Asystenci firmy, analiza |
| Phi-3 | Microsoft Research | Kompaktowy, silny językowo | Małe systemy, lokalna sztuczna inteligencja |
| Gemma | Google Research | Spójność, wytłumaczalność | Doradztwo, nauczanie, objaśnianie tekstów |
Opcje lokalnej obsługi modeli językowych
Jeśli chcesz dziś korzystać z modelu językowego na własnym komputerze Mac, istnieje kilka praktycznych opcji - w zależności od wymagań technicznych i pożądanego celu. Wspaniałą rzeczą jest to, że nie potrzebujesz już złożonego środowiska programistycznego, aby zacząć.
Ollama - nieskomplikowany start
Ollama szybko stała się standardowym narzędziem dla lokalnych modeli AI. Działa natywnie na macOS, optymalnie wykorzystuje wydajność Apple Silicon i umożliwia uruchomienie modelu za pomocą jednego polecenia:
ollama run mistral
Powoduje to automatyczne załadowanie i przygotowanie żądanego modelu, który jest następnie dostępny w terminalu lub za pośrednictwem lokalnych interfejsów. Ollama obsługuje format GGUF, umożliwia pobieranie modeli z Hugging Face i może być zintegrowany za pośrednictwem interfejsów API REST lub bezpośrednio z innymi programami.
Jak pracować z Ollama lokalny model językowy installiert i inne opcje z nim związane zostały szczegółowo opisane w innym artykule. Istnieją również dalsze artykuły na temat korzystania z Qdrant - elastyczna pamięć dla lokalnej sztucznej inteligencji.
LM Studio - graficzny interfejs użytkownika i administracja
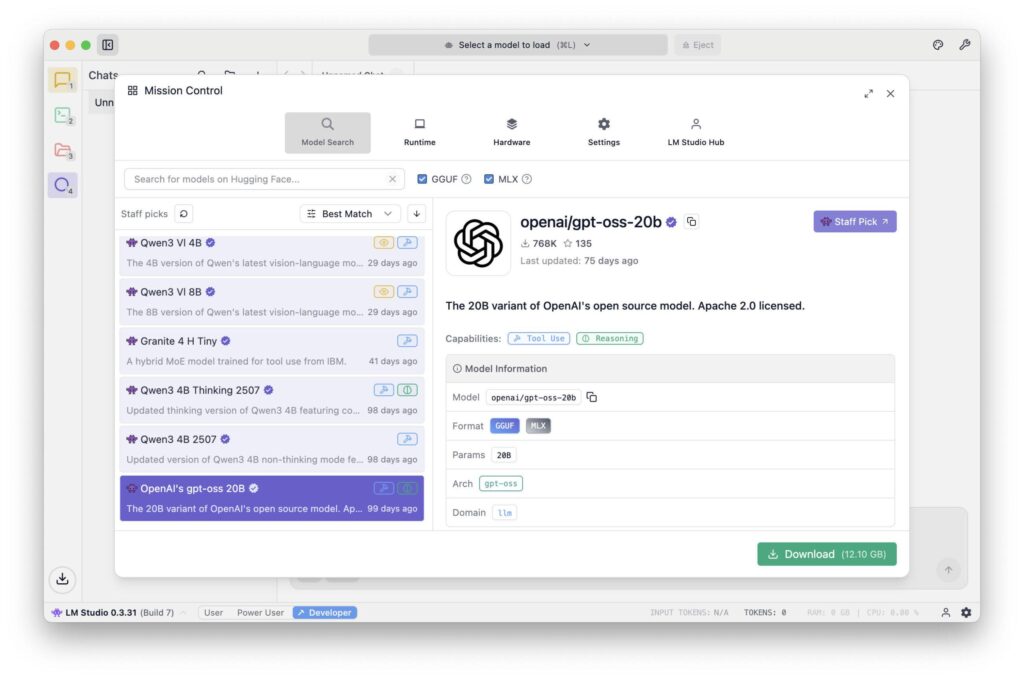
LM Studio jest przeznaczony dla każdego, kto preferuje graficzny interfejs użytkownika. Oferuje pobieranie modeli, okna czatu, kontrolę temperatury, podpowiedzi systemowe i zarządzanie pamięcią w jednej aplikacji. Jest to idealne rozwiązanie zwłaszcza dla początkujących: można wypróbować, porównać, zapisać i przełączać się między różnymi modelami bez konieczności pracy z wierszem poleceń. Oprogramowanie działa stabilnie na Apple Silicon i obsługuje również modele GGUF.
MLX / Python - dla programistów i integratorów
Jeśli chcesz wejść głębiej lub zintegrować modele z własnymi programami, możesz skorzystać z frameworka MLX firmy Apple. Pozwala to na osadzanie modeli bezpośrednio w aplikacjach Python lub Swift. Zaletą jest maksymalna kontrola i integracja z istniejącymi przepływami pracy - na przykład, jeśli firma chce dodać funkcje AI do własnego oprogramowania.
FileMaker Serwer 2025 - sztuczna inteligencja w kontekście korporacyjnym
Od FileMaker Serwer 2025 Modele językowe oparte na MLX mogą być również adresowane po stronie serwera. Umożliwia to po raz pierwszy wyposażenie centralnej aplikacji biznesowej (np. systemu ERP lub CRM) we własną lokalną sztuczną inteligencję. Przykładowo, zgłoszenia do pomocy technicznej mogą być automatycznie klasyfikowane, zapytania klientów oceniane lub treści w dokumentach analizowane - bez opuszczania firmy.
Jest to szczególnie interesujące dla sektorów, które mają ścisłe wymagania dotyczące ochrony danych lub zgodności (medycyna, prawo, administracja, przemysł).
Typowe przeszkody i sposoby ich unikania
Nawet jeśli próg wejścia jest niski, należy pamiętać o kilku kwestiach:
Limity pamięci: Jeśli model jest zbyt duży dla dostępnej pamięci, nie uruchomi się w ogóle lub będzie działał bardzo wolno. Pomóc może tutaj kwantyzacja (np. 4-bitowa) lub mniejszy model.
- Obliczanie obciążenia i rozwoju ciepłaMac może stać się zauważalnie ciepły podczas dłuższych sesji. Wskazana jest dobra wentylacja i obserwowanie wyświetlacza aktywności.
- Brak wsparcia GPU dla oprogramowania firm trzecichNiektóre starsze narzędzia lub porty nie wykorzystują efektywnie silnika neuronowego. W takich przypadkach MLX może zapewnić lepsze wyniki.
- Porty sieciowe i uprawnieniaJeśli kilku klientów ma uzyskać dostęp do tego samego modelu (np. w sieci firmowej), porty lokalne muszą zostać zwolnione - najlepiej zabezpieczone przez HTTPS lub przez wewnętrzny serwer proxy.
- Bezpieczeństwo danychNawet jeśli modele działają lokalnie, wrażliwe teksty nie powinny być przechowywane w niezabezpieczonych środowiskach. Lokalne dzienniki i dzienniki czatów są łatwe do zapomnienia, ale często zawierają cenne informacje.
Jeśli zwrócisz uwagę na te punkty, możesz obsługiwać potężny, lokalny system AI, który działa bezpiecznie, cicho i wydajnie przy zaskakująco niewielkim wysiłku.
Oś czasu i względy strategiczne
Jesteśmy dopiero na początku rozwoju, który zmieni codzienne życie wielu zawodów w nadchodzących latach. Lokalne modele sztucznej inteligencji będą coraz mniejsze, szybsze i wydajniejsze, a ich jakość będzie się stale poprawiać. To, co dziś wymaga 30 GB pamięci, za rok może wymagać tylko 10 GB - przy tej samej jakości głosu. Jednocześnie pojawiają się nowe interfejsy, które można wykorzystać do integracji modeli bezpośrednio z programami pakietu Office, przeglądarkami lub oprogramowaniem firmowym.
Firmy, które już dziś robią krok w kierunku lokalnej infrastruktury AI, zapewniają sobie przewagę. Budują wiedzę specjalistyczną, zabezpieczają swoją suwerenność danych i uniezależniają się od wahań cen lub ograniczeń użytkowania narzuconych przez zewnętrznych dostawców. Rozsądna strategia mogłaby wyglądać następująco:
- Najpierw eksperymentuj z małym modelem (np. 3-7 miliardów parametrów, za pośrednictwem Ollama lub LM Studio).
- Następnie sprawdź, które zadania można zautomatyzować.
- W razie potrzeby zintegruj większe modele lub skonfiguruj centralny Mac Studio jako „serwer AI“.
- W perspektywie średnioterminowej reorganizacja procesów wewnętrznych (np. dokumentacji, analizy tekstu, komunikacji) przy wsparciu sztucznej inteligencji.
Takie podejście krok po kroku jest nie tylko rozsądne z ekonomicznego punktu widzenia, ale także zrównoważone - jest zgodne z zasadą przyjmowania technologii we własnym tempie, zamiast kierowania się trendami.
W osobnym artykule opisałem szczegółowo, w jaki sposób nowsze Format MLX w porównaniu z GGUF przez Ollama na komputerze Mac.
Lokalna sztuczna inteligencja jako cicha ścieżka do cyfrowej suwerenności
Lokalne modele językowe oznaczają powrót do samostanowienia w cyfrowym świecie.
Zamiast wysyłać dane i pomysły do zdalnych centrów danych w chmurze, możesz teraz ponownie pracować z własnymi narzędziami - bezpośrednio na biurku, pod własną kontrolą.
Niezależnie od tego, czy jest to Mac Mini, Mac Studio czy potężny notebook - jeśli masz odpowiedni sprzęt, możesz teraz używać, trenować i dalej rozwijać własną sztuczną inteligencję. Jako osobisty asystent, jako część systemu ERP, jako pomoc naukowa w wydawnictwie lub jako rozwiązanie zgodne z ochroną danych w kancelarii prawnej - możliwości są zadziwiająco szerokie.
A co najlepsze: przypomina nam o dawnej sile komputera - czyli byciu narzędziem, które sam kontrolujesz, a nie usługą, która dyktuje nam, jak mamy pracować. To sprawia, że lokalna sztuczna inteligencja jest symbolem nowoczesnej autonomii - cichej, wydajnej, a jednak z imponującym efektem.
Lokalna sztuczna inteligencja w firmie rozwija swoją wartość dzięki odpowiedniej bazie systemowej
 Dyskusja na temat lokalnej sztucznej inteligencji często koncentruje się na sprzęcie, modelach i szybkości - ale rzeczywiste korzyści stają się widoczne dopiero wtedy, gdy wchodzi ona w interakcję z własnymi danymi i procesami. Jeśli naprawdę chcesz rozsądnie korzystać ze sztucznej inteligencji, potrzebujesz stabilnego, kontrolowanego środowiska, w którym informacje nie są rozproszone, ale dostępne w uporządkowany sposób. To jest właśnie miejsce, w którym lokalnie obsługiwane rozwiązanie ERP Stanowi ona szkielet dla danych, procesów i korelacji w firmie. W połączeniu z rozwiązaniem takim jak gFM Business ERP, tworzy to zamkniętą pętlę, w której lokalna sztuczna inteligencja nie tylko dostarcza odpowiedzi, ale także działa w sposób kontekstowy - na przykład poprzez integrację własnego grafu wiedzy. Decyzje nie są już wtedy oparte na ogólnych modelach, ale na rzeczywistych danych firmy. Rezultatem jest cichy, ale skuteczny krok w kierunku prawdziwej cyfrowej suwerenności: większa kontrola, większa wydajność i system, który dostosowuje się do firmy - a nie odwrotnie.
Dyskusja na temat lokalnej sztucznej inteligencji często koncentruje się na sprzęcie, modelach i szybkości - ale rzeczywiste korzyści stają się widoczne dopiero wtedy, gdy wchodzi ona w interakcję z własnymi danymi i procesami. Jeśli naprawdę chcesz rozsądnie korzystać ze sztucznej inteligencji, potrzebujesz stabilnego, kontrolowanego środowiska, w którym informacje nie są rozproszone, ale dostępne w uporządkowany sposób. To jest właśnie miejsce, w którym lokalnie obsługiwane rozwiązanie ERP Stanowi ona szkielet dla danych, procesów i korelacji w firmie. W połączeniu z rozwiązaniem takim jak gFM Business ERP, tworzy to zamkniętą pętlę, w której lokalna sztuczna inteligencja nie tylko dostarcza odpowiedzi, ale także działa w sposób kontekstowy - na przykład poprzez integrację własnego grafu wiedzy. Decyzje nie są już wtedy oparte na ogólnych modelach, ale na rzeczywistych danych firmy. Rezultatem jest cichy, ale skuteczny krok w kierunku prawdziwej cyfrowej suwerenności: większa kontrola, większa wydajność i system, który dostosowuje się do firmy - a nie odwrotnie.
Zalecane źródła
- Profilowanie dużych modeli językowych na Apple SiliconA Quantisation Perspective (Benazir & Lin et al., 2025) - szczegółowo analizuje wydajność wnioskowania na procesorach graficznych Apple Silicon w porównaniu z procesorami graficznymi NVIDIA, koncentrując się w szczególności na kwantyzacji.
- Lokalne wnioskowanie LLM na poziomie produkcyjnym na Apple SiliconA Comparative Study of MLX, MLC-LLM, Ollama, llama.cpp, and PyTorch MPS (Rajesh et al., 2025) - Porównanie różnych platform na Apple, Silicon, w tym MLX, w odniesieniu do przepustowości, opóźnienia, długości kontekstu.
- Benchmarking uczenia maszynowego na urządzeniu Apple Silicon z MLX (Ajayi & Odunayo, 2025) - Skupiono się na MLX i Apple Silicon, z danymi porównawczymi z systemami NVIDIA.



Często zadawane pytania
- Czym dokładnie jest model języka lokalnego?
Lokalny model językowy to sztuczna inteligencja, która może rozumieć i generować teksty - podobnie jak ChatGPT. Różnica polega na tym, że nie działa on przez Internet, ale bezpośrednio na komputerze użytkownika. Wszystkie obliczenia odbywają się lokalnie i żadne dane nie są wysyłane na zewnętrzne serwery. Oznacza to, że użytkownik zachowuje pełną kontrolę nad własnymi informacjami. - Jakie korzyści oferuje lokalna sztuczna inteligencja w porównaniu z rozwiązaniem w chmurze, takim jak ChatGPT?
Trzy największe zalety to ochrona danych, niezależność i kontrola kosztów.
- Ochrona danych: żadne teksty nie opuszczają komputera.
- Niezależność: Nie wymaga połączenia z Internetem, nie wymaga zmiany dostawcy ani ryzyka awarii.
- Koszty: Brak bieżących opłat za zapytanie. Płacisz raz za sprzęt - to wszystko. - Czy do lokalnego korzystania z modelu językowego potrzebne są umiejętności programowania?
Nie. Dzięki nowoczesnym narzędziom, takim jak Ollama lub LM Studio, model można uruchomić za pomocą zaledwie kilku kliknięć. Dziś nawet początkujący mogą uruchomić lokalną sztuczną inteligencję w zaledwie kilka minut bez pisania ani jednej linii kodu. - Które urządzenia Apple są szczególnie odpowiednie?
Dla początkujących często wystarczający jest Mac Mini z M4 lub M4 Pro i co najmniej 32 GB RAM. Jeśli chcesz korzystać z większych modeli lub kilku jednocześnie, lepiej wybrać Mac Studio z 64 GB lub 128 GB pamięci RAM. Mac Pro nie oferuje prawie żadnych korzyści, chyba że potrzebujesz gniazd PCI-e. Notebooki są odpowiednie, ale szybciej osiągają swoje limity termiczne. - Jaka jest minimalna ilość pamięci RAM, którą powinieneś mieć?
Zależy to od rozmiaru modelu.
- Małe modele (1-3 mld parametrów): wystarczy 16-32 GB.
- Średnie modele (7-13 mld): lepiej 48-64 GB.
- Duże modele (30bn+): 128 GB lub więcej.
Ważne jest, aby zaplanować pewną rezerwę - w przeciwnym razie wystąpią czasy oczekiwania lub odwołania. - Co oznacza „zunifikowana pamięć“ dla Apple Silicon?
Ujednolicona pamięć to pamięć współdzielona, do której dostęp uzyskują jednocześnie CPU, GPU i silnik neuronowy. Oszczędza to czas i energię, ponieważ nie ma potrzeby kopiowania danych między różnymi obszarami pamięci. Jest to ogromna zaleta, szczególnie w przypadku obliczeń AI, ponieważ wszystko działa w jednym przepływie. - Jaka jest różnica między GGUF, MLX i Safetensors?
- GGUF: Kompaktowy format do użytku lokalnego (np. w Ollama lub LM Studio). Idealny do wnioskowania, tj. wykonywania gotowych modeli.
- MLX: własny format Apple, szczególnie dla chipów M. Bardzo wydajny, ale wciąż młody.
- Safetensors: Format ze świata PyTorch, przeznaczony głównie do szkoleń i badań.
GGUF lub MLX są idealne do użytku lokalnego na komputerach Mac. - Skąd pochodzą modele?
Najbardziej znaną platformą jest huggingface.co - ogromna biblioteka modeli AI. Można tam znaleźć warianty LLaMA, Mistral, Gemma, Phi-3 i wiele innych. Wiele modeli jest już dostępnych w formacie GGUF i można je załadować bezpośrednio do Ollama. - Z którymi narzędziami najłatwiej zacząć?
Na początek Ollama i LM Studio są idealne. Ollama działa w terminalu i jest lekki. LM Studio oferuje graficzny interfejs użytkownika z oknem czatu. Oba modele ładują i uruchamiają się automatycznie i nie wymagają skomplikowanej konfiguracji. - Czy modele językowe mogą być również używane z serwerem FileMaker?
Tak - od wersji FileMaker Server 2025 modele MLX mogą być adresowane bezpośrednio. Umożliwia to na przykład analizę tekstu, klasyfikację lub automatyczną ocenę w systemach ERP lub CRM. Dzięki temu poufne dane biznesowe mogą być przetwarzane lokalnie, bez konieczności wysyłania ich do zewnętrznych dostawców. - Jak duże są zazwyczaj takie modele?
Małe modele to zaledwie kilka gigabajtów, duże mogą mieć 20-30 GB lub więcej. Ich rozmiar można znacznie zmniejszyć poprzez kwantyzację (np. 4-bitową), często przy minimalnej utracie jakości. Na przykład skompresowany model 13-B może zajmować tylko 7 GB - idealnie dla Mac Mini M4 Pro. - Czy możliwe jest trenowanie lub dostosowywanie modeli lokalnych?
Zasadniczo tak - ale szkolenie jest bardzo intensywne obliczeniowo. Do lokalnego dostrajania mniejszych modeli można użyć frameworków MLX lub Python. Obecnie FileMaker zawiera zintegrowaną funkcję do Bezpośrednie dostrajanie modeli językowych aby móc to zrobić. W przypadku uczenia na dużą skalę (np. 50 miliardów parametrów) konieczna byłaby jednak dedykowana farma GPU. W przypadku większości aplikacji wystarczy wykorzystać istniejące modele i sterować nimi za pomocą podpowiedzi. - Ile energii zużywa komputer Mac podczas obliczeń AI?
Zaskakująco mało. Mac Studio często pobiera poniżej 100 W podczas pełnej pracy, podczas gdy pojedyncza karta graficzna NVIDIA (np. RTX 5090) pobiera do 450 W - bez procesora i urządzeń peryferyjnych. Oznacza to, że lokalna sztuczna inteligencja na sprzęcie Apple jest nie tylko cichsza, ale też znacznie bardziej energooszczędna. - Czy MacBook Pro nadaje się do lokalnej sztucznej inteligencji?
Tak, ale z ograniczeniami.
Chociaż wydajność jest wysoka, obciążenie termiczne jest ograniczone. Procesor dławi się podczas dłuższych sesji. MacBook Pro M3/M4 jest idealny do krótkich rozmów, zadań tekstowych lub analiz - ale nie do długotrwałego użytkowania. - Jak bezpieczne są lokalne modele?
Tak bezpieczne jak system, na którym działają. Ponieważ żadne dane nie są przesyłane przez Internet, praktycznie nie ma ryzyka ze strony osób trzecich. Należy jednak upewnić się, że pliki tymczasowe, dzienniki lub historie czatów nie trafią przypadkowo do folderów w chmurze (np. iCloud Drive). Lokalne przechowywanie na wewnętrznym dysku SSD jest idealne. - Jakie są typowe błędy popełniane przez początkujących?
- Wczytywanie zbyt dużych modeli, mimo braku wystarczającej ilości pamięci RAM.
- Użyj starych wersji Ollama lub LM Studio.
- Nie aktywuj akceleracji GPU (np. MLX).
- Zbyt wiele procesów działających w tle.
- Ładowanie modeli z wątpliwych źródeł.
Rozwiązanie: Korzystaj tylko z zaufanych źródeł (np. Hugging Face) i miej oko na zasoby systemowe. - Jak rozwinie się lokalna technologia AI w ciągu najbliższych kilku lat?
Modele stają się jeszcze bardziej kompaktowe i precyzyjne. Apple, Mistral i Meta już pracują nad architekturami, które wymagają mniej pamięci i mocy przy tej samej jakości. Jednocześnie opracowywane są wygodne interfejsy - takie jak wtyczki AI do edytorów tekstu, programów pocztowych lub aplikacji do notatek. W dłuższej perspektywie każdy profesjonalny system będzie prawdopodobnie posiadał coś w rodzaju „wbudowanej lokalnej sztucznej inteligencji“. - Dlaczego warto zacząć już teraz?
Ponieważ fundamenty na nadchodzące lata są kładzione już teraz. Każdy, kto dziś nauczy się uruchamiać model lokalnie, przetwarzać dane w ustrukturyzowany sposób i formułować podpowiedzi w ukierunkowany sposób, będzie mógł później działać niezależnie - bez konieczności polegania na drogich dostawcach usług w chmurze. Krótko mówiąc: lokalna sztuczna inteligencja to spokojna, pewna ścieżka do cyfrowej przyszłości, w której ponownie możesz trzymać swoje dane i narzędzia we własnych rękach.