
Cualquiera que trabaje hoy con inteligencia artificial suele pensar primero en ChatGPT o en servicios en línea similares. Escribes una pregunta, esperas unos segundos y recibes una respuesta como si al otro lado de la línea estuviera sentado un interlocutor muy leído y paciente. Pero lo que se olvida fácilmente: Cada entrada, cada frase, cada palabra viaja por Internet a servidores externos. Ahí es donde se hace el trabajo de verdad: en enormes ordenadores que usted nunca llega a ver.
En principio, un modelo lingüístico local funciona exactamente igual, pero sin Internet. El modelo se almacena como un archivo en el propio ordenador del usuario, se carga en la memoria de trabajo al arrancar y responde a las preguntas directamente en el dispositivo. La tecnología que hay detrás es la misma: una red neuronal que entiende el lenguaje, genera textos y reconoce patrones. La única diferencia es que todo el cálculo sigue siendo interno. Se podría decir: ChatGPT sin la nube.
La particularidad es que la tecnología se ha desarrollado hasta tal punto que ya no depende de enormes centros de datos. Los modernos ordenadores Apple con procesadores M (como M3 o M4) tienen una enorme potencia de cálculo, rápidas conexiones de memoria y un motor neuronal especializado para el aprendizaje automático. Como resultado, muchos modelos pueden funcionar ahora directamente en un Mac Mini o Mac Studio, sin necesidad de una granja de servidores, sin una configuración complicada y sin ruidos significativos.



Últimas noticias sobre Apple MLX y NVIDIA
26.03.2026Apple sigue avanzando estratégicamente en su marco MLX AI y lo abre cada vez más a otras plataformas. Originalmente optimizado en exclusiva para Apple Silicon, MLX ahora también es compatible con GPU CUDA y, por tanto, el hardware clásico de Nvidia. Esto elimina un obstáculo clave para los desarrolladores: hasta ahora, los modelos a menudo tenían que desarrollarse en el Mac y luego entrenarse en sistemas de alto rendimiento independientes. Al abrirse, MLX se convierte en una plataforma de desarrollo más flexible que permite tanto la IA local en dispositivos Apple como el entrenamiento escalable en hardware externo. Al mismo tiempo, se mantiene la ventaja de la estrecha integración con la propia arquitectura de Apple, por ejemplo, a través de la gestión eficiente de la memoria y la utilización directa de la GPU. El desarrollo apunta a un cambio de rumbo estratégico: Apple está abandonando gradualmente su ecosistema cerrado y posicionando MLX como una alternativa seria a los marcos de IA establecidos, con implicaciones potenciales para el desarrollo de la IA en su conjunto.
Esto abre una nueva puerta, no sólo para los desarrolladores, sino también para empresarios, autores, abogados, médicos, profesores y comerciantes. Ahora todo el mundo puede tener su propia IA en su escritorio, bajo control total y lista para usar en cualquier momento. Un modelo lingüístico local puede:
- Textos resumir o corregir,
- Correos electrónicos formular o estructurar,
- Preguntas responder a preguntas y analizar conocimientos,
- Procesos apoyo en los programas,
- Documentos buscar o clasificar,
- o simplemente como asistente personal sin filtrar nunca datos al exterior.
Este enfoque es cada vez más importante, sobre todo en un momento en que la protección de datos y la soberanía digital vuelven a ocupar un lugar central. No hace falta ser programador: basta con un Mac moderno. Los modelos pueden iniciarse simplemente a través de una aplicación o una ventana de terminal y responder casi con la misma naturalidad que una ventana de chat en el navegador.
Este artículo muestra qué modelos pueden ejecutarse en qué Mac hoy en día, qué debe hacer el hardware y por qué los ordenadores Apple Silicon son especialmente adecuados para ello. En resumen, se trata de cómo volver a poner el poder de la IA en tus manos, de forma silenciosa, eficiente y local.
Modelos lingüísticos locales en el Mac - Por qué tiene sentido ahora
Ejecutar un modelo lingüístico „localmente“ significa que funciona íntegramente en su propio ordenador, sin conexión a un servicio en la nube. El cálculo, el análisis de las entradas, la generación de textos o respuestas... todo sucede directamente en su propio dispositivo. Por lo tanto, el modelo se almacena como un archivo en el SSD, se carga en la memoria RAM en el arranque y funciona allí con todo el rendimiento del sistema.
La diferencia clave con la variante en nube es la independencia. Los datos no circulan por Internet, no se utilizan servidores externos y nadie puede rastrear lo que se procesa internamente. Esto proporciona un grado considerable de protección y control de los datos, especialmente en tiempos en los que cada vez es más difícil rastrear los movimientos de datos.
En el pasado, era impensable ejecutar este tipo de modelos localmente. Se necesitaba un ordenador central o una granja de GPU para mantener en funcionamiento una red neuronal de este tamaño. Hoy, con la potencia de cálculo de los modernos chips Apple-Silicon, esto puede hacerse realidad en un dispositivo de sobremesa, de forma eficiente, silenciosa y con un bajo consumo de energía.
Por qué Apple Silicon es ideal
Con el cambio a Apple Silicon ha barajado de nuevo las cartas. En lugar de la clásica arquitectura Intel con CPU y GPU separadas, Apple apuesta por el llamado diseño de memoria unificada: procesador, gráficos y motor neuronal acceden a la misma memoria principal rápida. Esto elimina la necesidad de copiar datos entre los distintos componentes, una ventaja decisiva para los cálculos de IA.
El motor neuronal es un núcleo informático especializado en aprendizaje automático integrado directamente en los chips. Permite miles de millones de operaciones de cálculo por segundo, con un consumo de energía muy bajo. Junto con la librería MLX (Machine Learning for Apple Silicon) y marcos de trabajo modernos como OLaMA, ahora los modelos pueden ejecutarse directamente en macOS sin necesidad de complejos controladores de GPU ni dependencias de CUDA.
Un chip M4 en el Mac Mini ya es suficiente para ejecutar sin problemas modelos de lenguaje compacto (por ejemplo, de 3.000 a 7.000 millones de parámetros). En un Mac Studio con M4 Max o M3 Ultra, puedes incluso ejecutar modelos con 30.000 millones de parámetros, de forma completamente local.
Comparación: Apple Silicon frente a hardware NVIDIA
Tradicionalmente, las tarjetas gráficas RTX de NVIDIA han sido el estándar de oro para los cálculos de IA. Una RTX 5090 actual, por ejemplo, ofrece un enorme rendimiento bruto y sigue siendo la primera opción para muchos sistemas de entrenamiento. No obstante, merece la pena realizar una comparación detallada, porque las prioridades difieren.
| Aspecto | Apple Silicon (M4 / M4 Max / M3 Ultra) | GPU NVIDIA (5090 & Co.) |
|---|---|---|
| Consumo de energía | Muy eficiente: suele consumir menos de 100 W en total | Hasta 450 W sólo para la GPU |
| Evolución del ruido | Prácticamente silencioso | Claramente audible bajo carga |
| Pila de software | MLX / Core ML / Metal | CUDA / cuDNN / PyTorch |
| Mantenimiento | Sin conductor y estable | Actualizaciones frecuentes y problemas de compatibilidad |
| Relación calidad-precio | Alta eficiencia a un precio moderado | Mejor rendimiento máximo, pero más caro |
| Ideal para | Inferencia local y funcionamiento continuo | Formación y grandes modelos |
En resumen: NVIDIA es la elección para centros de datos y entrenamiento extremo. Apple Silicon, por su parte, es ideal para uso local a largo plazo: sin ruido, sin acumulación de calor, con una base de software estable y un consumo de energía manejable.
Apple Silicon comparado con NVIDIA para inferencia
El M3 Ultra supone un importante paso adelante para el Apple Silicon: además de un diseño de chip altamente integrado con CPU, GPU y motor neuronal en un solo paquete, se basa en una arquitectura de memoria unificada en la que la RAM es utilizada simultáneamente por todas las unidades de cálculo, sin la clásica separación entre RAM y VRAM de GPU. Según las pruebas comparativas, este enfoque ya alcanza un rendimiento comparable o incluso mejor en tareas de inferencia local que las tarjetas gráficas de gama alta de NVIDIA en algunos casos. Un ejemplo: En la prueba, la M3 Ultra alcanzó aproximadamente 2.320 tokens/s con un modelo Qwen3-30B de 4 bits, frente a los 2.157 tokens/s de la RTX 3090.
Además, una comparación de Apple Silicon frente a NVIDIA bajo cargas de IA sugiere que un sistema M3/M4 Max alcanzará entre unos 40-80W bajo carga, mientras que una RTX 4090 consumirá normalmente hasta 450W.
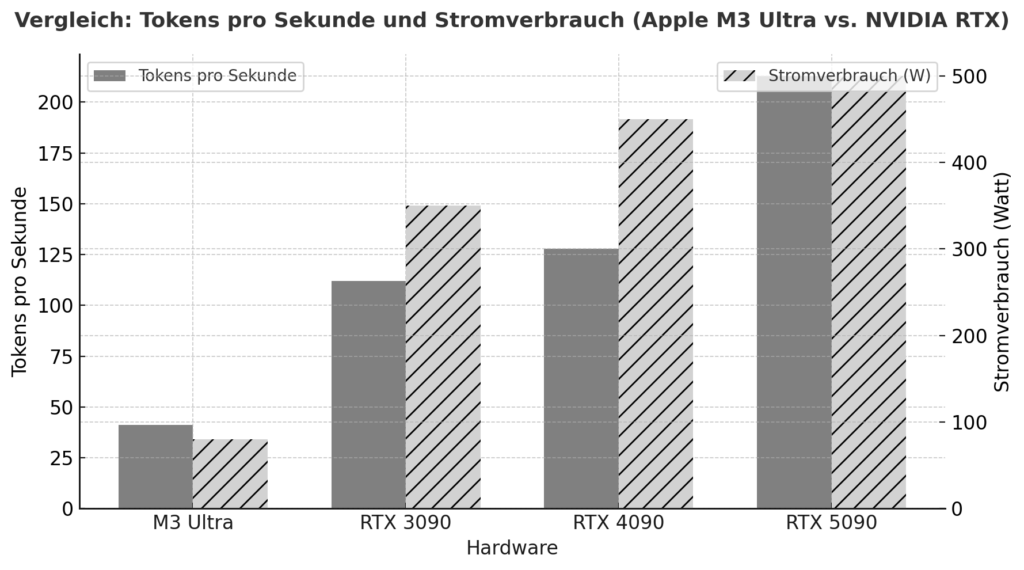
Esto demuestra que, si nos fijamos no sólo en el rendimiento máximo, sino también en la eficiencia por vatio, Apple Silicon se encuentra en una posición excelente. Por otro lado, están las tarjetas NVIDIA (por ejemplo, 3090, 4090, 5090) con su enorme arquitectura de GPU paralelizada, altísima densidad de núcleos CUDA/tensor y librerías especializadas (CUDA, cuDNN, TensorRT). Aquí es donde el rendimiento en términos brutos suele estar por delante, pero con limitaciones decisivas para los modelos de lenguaje local: la VRAM disponible (por ejemplo, de 24 a 32 GB para las tarjetas de juegos) se convierte rápidamente en un cuello de botella si hay que cargar modelos con 20-30.000 millones de parámetros o más. Un informe de usuario, por ejemplo, afirma que con una RTX 5090 con aproximadamente 32 GB de VRAM, un modelo con 20-22 mil millones de parámetros ya es difícil de acomodar.
En este sentido, no sólo hay que fijarse en los núcleos de la GPU, sino también en el tamaño de la memoria disponible, el ancho de banda y la arquitectura de la memoria. La M3 Ultra con hasta 512 GB de memoria unificada (en las configuraciones superiores), por ejemplo, ofrece ventajas aquí en muchos escenarios de despliegue local, especialmente si los modelos no se van a ejecutar en la nube, sino localmente de forma permanente.
| Hardware | Modelo / Configuración | Fichas por segundo (aproximado) | Observación |
|---|---|---|---|
| Apple M3 Ultra (Mac Studio) | z. por ejemplo, Gemma-3-27B-Q4 en M3 Ultra | ≈ 41 tok/s :contentReference[oaicite:2]{index=2} | Inferencia LLM, contexto 4k tokens, cuantificado |
| NVIDIA RTX 5090 | 8 Modelo B (cuantificado) según el estudio | ≈ 213 tok/s :contentReference[oaicite:3]{index=3} | Modelo 8 B, 4 bits, entorno RLHF |
| NVIDIA RTX 4090 | 8 B Referencia del modelo | ≈ 128 tok/s :contentReference[oaicite:4]{index=4} | 24 GB de VRAM Entorno |
| NVIDIA RTX 3090 | Presupuesto HighEnd en comparación | ≈ 112 tok/s :contentReference[oaicite:5]{index=5} | Mercado de segunda mano, 24 GB VRAM |
Importancia práctica: dónde tienen sentido los modelos lingüísticos locales
Las posibles aplicaciones de la IA local son hoy casi ilimitadas. Siempre que los datos deban permanecer confidenciales o los procesos deban ejecutarse en tiempo real, la versión local merece la pena. Ejemplos prácticos:
- Sistemas ERPAnálisis automático de textos, sugerencias, previsiones o ayudas a la comunicación, directamente desde el software.
- Producción de libros y medios de comunicaciónComprobación de estilo, traducción, resumen, ampliación de texto: todo localmente, sin depender de la nube.
- Abogados y notariosAnálisis de documentos, borradores de alegaciones, investigación, todo ello bajo la más estricta confidencialidad.
- Médicos y terapeutasEvaluación de casos, documentación o informes automatizados, sin que los datos del paciente salgan nunca del sistema.
- Oficinas de ingeniería y arquitectosAsistentes de texto, proyecto y cálculo que también funcionan sin Internet.
- Empresa en generalGestión del conocimiento, asistentes de chat internos, análisis de protocolos, clasificación del correo electrónico... todo dentro de su propia red.
Se trata de un gran paso, especialmente en el sector comercial: en lugar de pagar por servicios externos de IA y enviar datos a la nube, ahora se pueden ejecutar modelos personalizados en las propias máquinas. Estos pueden personalizarse, afinarse y ampliarse con los conocimientos propios de la empresa, completamente bajo control.
El resultado es un paisaje informático moderno pero tradicionalmente soberano, que utiliza la tecnología sin renunciar al control sobre sus propios datos. Un enfoque que nos recuerda viejas virtudes: mantener las cosas en nuestras propias manos.
Encuesta actual sobre sistemas locales de IA
Información general: Mac Mini y Mac Studio: lo que hay disponible actualmente
Si hoy en día queremos ejecutar modelos de lenguaje local en un Mac, hay dos clases de ordenadores de sobremesa que nos interesan especialmente: el Mac mini y el Mac Studio.
- Mac MiniLa última generación ofrece el chip Apple M4 u opcionalmente el M4 Pro. Según las especificaciones técnicas, hay disponibles variantes con 24 GB o 32 GB de memoria unificada; la variante Pro se ofrece con memoria unificada configurable de hasta 48 GB o 64 GB. Esto hace que el Mac Mini sea muy adecuado para muchas aplicaciones, especialmente si el modelo no es extremadamente grande o no tiene que ejecutar varias tareas muy grandes en paralelo.
- Estudio MacAquí vamos un paso más allá. Equipado, por ejemplo, con el chip Apple M4 Max o el chip M3 Ultra, según el modelo. Con la versión M4 Max es posible disponer de 48 GB, 64 GB o hasta 128 GB de memoria unificada. La versión M3 Ultra del Mac Studio puede equiparse con hasta 512 GB de memoria unificada. Los tamaños de las unidades SSD y los anchos de banda de memoria también aumentan considerablemente. Esto hace que el Mac Studio sea adecuado para modelos más exigentes o procesos paralelos.
Como nota breve: El Mac Pro también existe y a menudo ofrece „más chasis“ o ranuras PCI-e en el exterior - pero en términos de modelos de idiomas, no ofrece mucha ventaja sobre el Mac Studio para la versión local si no tienes tarjetas de expansión adicionales o requisitos especiales de PCIe.
También Cuadernos (por ejemplo, MacBook Pro) pueden utilizarse, pero con restricciones: Los sistemas de refrigeración son más pequeños, el rendimiento térmico es más limitado y el presupuesto de RAM suele ser menor. El uso prolongado (como ocurre con los modelos de IA) puede reducir el rendimiento.

AI: ¡Apple mejor que Nvidia! 😮 | c't 3003
Por qué es tan importante la RAM / memoria unificada
Cuando un modelo lingüístico se ejecuta localmente, no sólo se necesita el rendimiento de la CPU o la GPU: la RAM (o „memoria unificada“ en el caso del Apple) también es crucial. ¿Por qué?
El propio modelo (pesos, activaciones, resultados intermedios) debe almacenarse en memoria. Cuanto mayor sea el modelo, más memoria se necesitará. Los chips Apple-Silicon utilizan "memoria unificada", es decir, la CPU, la GPU y el motor neuronal acceden al mismo pool de memoria. Esto elimina la necesidad de copiar datos entre componentes, lo que aumenta la eficiencia y la velocidad.
Si no hay suficiente memoria RAM, el sistema tiene que cambiar o los modelos no se cargan completamente, lo que puede significar una caída del rendimiento, inestabilidad o cancelación. Especialmente con las aplicaciones inferenciales (generación de respuestas, introducción de texto, ampliación de modelos), el tiempo de respuesta y el rendimiento son cruciales: una memoria suficiente ayuda considerablemente en este caso. Un PC de sobremesa tradicional solía pensar en términos de „RAM de CPU“ y „RAM de GPU separada“ - con Apple Silicon se combina de forma elegante, lo que hace especialmente atractiva la ejecución de modelos lingüísticos.
Valores estimados: ¿Qué orden de magnitud es realista?
Para ayudarte a calcular el hardware que necesitarás, aquí tienes algunos valores orientativos:
- Para modelos más pequeños (por ejemplo, unos cuantos miles de millones de parámetros), entre 16 GB y 32 GB de RAM podrían ser suficientes, sobre todo si sólo se van a procesar consultas individuales. Por tanto, un Mac Mini con 16/32 GB sería un buen comienzo.
- Para modelos medianos (por ejemplo, entre 3.000 y 10.000 millones de parámetros) o tareas con varios chats paralelos o grandes cantidades de texto, debería considerar 32 GB de RAM o más; por ejemplo, Mac Studio con 32 o 48 GB.
- Para modelos grandes (>20.000 millones de parámetros) o si varios modelos van a funcionar en paralelo, podría elegir 64 GB o más: aquí son posibles las variantes Mac mini y Mac Studio con 64 GB o más.
Importante: Recuerda planificar algo de memoria intermedia - no sólo el modelo, sino también el funcionamiento (por ejemplo, el sistema operativo, la E/S de archivos, otras aplicaciones) requieren reservas de memoria.
| Categoría | Tamaño típico del modelo | Presupuesto de RAM recomendado | Ejemplo de uso |
|---|---|---|---|
| Pequeño | 1-3 mil millones de parámetros | 16-32 GB | Asistente sencillo, reconocimiento de texto |
| Medio | 7-13 mil millones Parámetros | 32-64 GB | Chat, análisis, creación de textos |
| Grande | 30-70.000 millones de parámetros | 64 GB + | Textos especializados, documentos jurídicos |
Cuestionar la mentalidad tradicional de "servidor frente a sobremesa
Tradicionalmente, la gente pensaba que la IA requería granjas de servidores, montones de GPU, mucha potencia y un centro de datos. Pero el panorama está cambiando: ordenadores de sobremesa como el Mac Mini o el Mac Studio ofrecen ahora rendimiento suficiente para muchos modelos lingüísticos operados localmente, sin necesidad de una enorme infraestructura. En lugar de elevados costes de electricidad, una potente refrigeración y un mantenimiento complejo, se obtiene un dispositivo silencioso y eficaz en el escritorio.
Por supuesto, si desea entrenar modelos a gran escala o utilizar un gran número de parámetros, las soluciones de servidor siguen teniendo sentido. Sin embargo, el hardware de sobremesa suele ser suficiente para la inferencia, la personalización y el uso cotidiano. Esto está vinculado a un enfoque tradicional: utilizar la tecnología, pero no sobredimensionarla, sino utilizarla de forma selectiva y eficiente. Si construyes hoy una sólida base local, creas los cimientos de lo que será posible mañana.

M3 Ultra vs RTX 5090 | La batalla final (en inglés)
Caracterización técnica de los modelos lingüísticos
Hoy en día, los modelos lingüísticos difieren no sólo en sus capacidades, sino también en el formato técnico en el que están disponibles. Estos formatos determinan cómo se guarda, carga y utiliza el modelo, y si puede funcionar en un sistema concreto.
GGUF (Formato Unificado Generado por GPT)
Este formato se desarrolló para su uso práctico en herramientas como Ollama, LM Studio o Llama.cpp. Es compacto, portátil y muy optimizado para la inferencia local. Los modelos GGUF suelen estar cuantificados, lo que significa que consumen mucha menos memoria porque los valores numéricos internos se almacenan en forma reducida (por ejemplo, 4 u 8 bits). Como resultado, modelos que originalmente tenían un tamaño de 30-50 GB pueden comprimirse a 5-10 GB, con sólo una ligera pérdida de calidad.
- VentajaFunciona en casi cualquier sistema (macOS, Windows, Linux), sin necesidad de una GPU especial.
- DesventajaNo está pensada para el entrenamiento o el ajuste fino, sino para la inferencia pura (es decir, la utilización).
MLX (Aprendizaje automático para Apple Silicon)
MLX es el marco de código abierto propio de Apple para el aprendizaje automático en Apple Silicon. Se ha desarrollado especialmente para aprovechar toda la potencia de la CPU, la GPU y el motor neuronal de los M-Chips. Los modelos MLX suelen estar disponibles en formato MLX nativo o convertidos a partir de otros formatos.
- VentajaMáximo rendimiento y eficiencia energética en hardware Apple.
- DesventajaEcosistema aún relativamente joven, menos modelos comunitarios disponibles que con GGUF o PyTorch.
Sensores de seguridad (.safetensors)
Este formato se origina en el mundo PyTorch (y es fuertemente promovido por Hugging Face). Es un formato de almacenamiento binario y seguro para modelos grandes que no permite la ejecución de código - de ahí el nombre „seguro“.
- VentajaCarga muy rápida, ahorro de memoria, estandarizado.
- Desventaja: Principalmente pensado para frameworks como PyTorch o TensorFlow - es decir, más común en entornos de desarrolladores y para procesos de formación.
| Formato | Plataforma | Propósito | Ventajas | Desventajas |
|---|---|---|---|---|
| GGUF | macOS, Windows, Linux | Inferencia | Compacto, rápido, universal | No es posible la formación |
| MLX | macOS (Apple Silicon) | Inferencia + Formación | Optimizado para M-Chips, alta eficiencia | Menos modelos disponibles |
| Safetensors | Multiplataforma (PyTorch / TensorFlow) | Formación e investigación | Seguro, normalizado, rápido | No directamente compatible con Ollama / MLX |
Hugging Face: la fuente central de suministro
En la actualidad, Hugging Face es algo así como la "biblioteca" del mundo de la IA. En huggingface.co encontrará decenas de miles de modelos, conjuntos de datos y herramientas, muchos de ellos de uso gratuito. Puede filtrar por nombre, arquitectura, tipo de licencia o formato de archivo. Ya se trate de Mistral, LLaMA, Falcon, Gemma o Phi-3, casi todos los modelos conocidos están representados. Numerosos desarrolladores ya ofrecen versiones personalizadas para uso local con GGUF o MLX.
Esto convierte a Hugging Face en el primer puerto de escala para la mayoría de los usuarios cuando quieren probar un modelo o encontrar una variante adecuada para macOS.

Modelos típicos y sus ámbitos de aplicación
En la actualidad, es casi imposible seguir la pista al número de modelos disponibles. Sin embargo, hay algunas familias principales que han demostrado ser especialmente exitosas para uso local:
- Familia LLaMA (Meta)Uno de los modelos de código abierto más conocidos. Constituye la base de innumerables derivados (por ejemplo, Vicuna, WizardLM, Open-Hermes). Puntos fuertes: comprensión del lenguaje, diálogo, uso versátil. Campo de aplicación: aplicaciones generales de chat, generación de contenidos, sistemas de asistencia.
- Mistral y Mixtral (Mistral AI)Conocido por su gran eficacia y buena calidad con un modelo de tamaño reducido. Mixtral 8x7B combina varios modelos de expertos (arquitectura Mixture-of-Experts). Puntos fuertes: respuestas rápidas y precisas, ahorro de recursos. Campo de aplicación: asistentes internos de la empresa, análisis de textos, preparación de datos.
- Phi-3 (Microsoft Research)Modelo compacto, optimizado para una gran calidad de voz a pesar de un número reducido de parámetros. Puntos fuertes: eficacia, buena gramática, respuestas estructuradas. Ámbito de aplicación: sistemas más pequeños, modelos de conocimiento local, asistentes integrados.
- Gemma (Google)Modelo abierto publicado por Google Research. Bueno para tareas de resumen y explicación. Puntos fuertes: coherencia, explicaciones contextualizadas. Ámbito de aplicación: procesamiento de conocimientos, formación, sistemas de asesoramiento.
- Modelos GPT-OSS / OpenHermesJunto con las modificaciones de LLaMA, constituyen el "puente" entre los modelos de código abierto y el ámbito funcional de los sistemas comerciales. Puntos fuertes: Amplia base lingüística, uso flexible. Ámbito de aplicación: creación de contenidos, tareas de chat y análisis, asistencia interna de IA.
- Claude / Comando R / Halcón / Yi / CéfiroEstos y muchos otros modelos (en su mayoría procedentes de proyectos de investigación o comunidades abiertas) ofrecen funciones especiales como la recuperación de conocimientos, la generación de código o el multilingüismo.
Lo más importante es que ningún modelo puede hacerlo todo a la perfección. Cada uno tiene sus puntos fuertes y débiles y, dependiendo de la aplicación, merece la pena hacer una comparación específica.
¿Qué modelo es adecuado para cada finalidad?
Para obtener una evaluación realista, los modelos pueden clasificarse a grandes rasgos en clases de rendimiento y de aplicación:
Para la mayoría de las aplicaciones de escritorio realistas - como resúmenes, correspondencia, traducción, análisis - los modelos medios (7-13 B) son totalmente suficientes. Ofrecen resultados sorprendentemente buenos, funcionan sin problemas en un Mac Mini M4 Pro con 32-48 GB de RAM y apenas requieren reajustes.
Modelos grandes mostrar sus puntos fuertes cuando es importante una comprensión más profunda o contextos más largos, por ejemplo, al procesar textos jurídicos o documentación técnica. Sin embargo, debería tener al menos un Mac Studio con 64-128 GB Utilizar la memoria de trabajo.
| Familia de modelos | Origen | Puntos fuertes | Ámbito de aplicación |
|---|---|---|---|
| LLaMA | Meta | Comprensión lingüística, diálogo | Aplicaciones generales de chat |
| Mistral / Mixtral | Mistral AI | Eficacia, alta precisión | Asistentes de empresa, análisis |
| Phi-3 | Investigación de Microsoft | Compacto, lingüísticamente fuerte | Sistemas pequeños, IA local |
| Gemma | Google Investigación | Coherencia, explicabilidad | Asesoramiento, enseñanza, explicación de textos |
Opciones de funcionamiento local de los modelos lingüísticos
Si desea utilizar un modelo de lenguaje en su propio Mac hoy en día, existen varias opciones viables, en función de sus requisitos técnicos y de la finalidad deseada. Lo mejor es que ya no necesita un entorno de desarrollo complejo para empezar.
Ollama: el comienzo sin complicaciones
Ollama se ha convertido rápidamente en una herramienta estándar para modelos locales de IA. Se ejecuta de forma nativa en macOS, aprovecha al máximo el rendimiento de Apple Silicon y permite iniciar un modelo con un solo comando:
ollama run mistral
De este modo, se carga y prepara automáticamente el modelo deseado, que queda disponible en el terminal o a través de interfaces locales. Ollama es compatible con el formato GGUF, permite descargar modelos de Hugging Face y puede integrarse mediante API REST o directamente en otros programas.
Cómo trabajar con Ollama un modelo de lengua local installiert y qué otras opciones tienes con él se describen en detalle en otro artículo. También hay otros artículos sobre cómo utilizar Qdrant una memoria flexible para su IA local.
LM Studio: interfaz gráfica de usuario y administración
Estudio LM está dirigida a quienes prefieren una interfaz gráfica de usuario. Ofrece descargas de modelos, ventanas de chat, controles de temperatura, avisos del sistema y gestión de la memoria en una sola aplicación. Esto es ideal sobre todo para principiantes: puedes probar, comparar, guardar y cambiar entre distintos modelos sin tener que trabajar con la línea de comandos. El software funciona de forma estable en Apple Silicon y también es compatible con los modelos GGUF.
MLX / Python - para desarrolladores e integradores
Si desea profundizar o integrar modelos en sus propios programas, puede utilizar el marco MLX de Apple. Esto permite incrustar modelos directamente en aplicaciones Python o Swift. La ventaja reside en el máximo control y la integración en los flujos de trabajo existentes; por ejemplo, si una empresa quiere añadir funciones de IA a su propio software.
FileMaker Servidor 2025 - IA en el contexto corporativo
Desde FileMaker Servidor 2025 Los modelos lingüísticos basados en MLX también pueden abordarse en el lado del servidor. Esto hace posible por primera vez equipar una aplicación empresarial central (por ejemplo, un sistema ERP o CRM) con su propia IA local. Por ejemplo, se pueden clasificar automáticamente las solicitudes de asistencia, evaluar las consultas de los clientes o analizar el contenido de los documentos, sin que los datos salgan de la empresa.
Esto es especialmente interesante para sectores con estrictos requisitos de protección de datos o de cumplimiento de la normativa (medicina, derecho, administración, industria).
Tropiezos típicos y cómo evitarlos
Aunque la barrera de entrada sea baja, hay algunos puntos que debe tener en cuenta:
Límites de memoria: Si el modelo es demasiado grande para la memoria disponible, no se iniciará o lo hará con extrema lentitud. La cuantificación (por ejemplo, 4 bits) o un modelo más pequeño pueden ayudar en este caso.
- Cálculo de la carga y del desarrollo térmicoEl Mac puede calentarse notablemente durante sesiones prolongadas. Se recomienda una buena ventilación y vigilar la pantalla de actividad.
- Falta de compatibilidad de la GPU con software de tercerosAlgunas herramientas o puertos antiguos no utilizan el motor neuronal de forma eficiente. En estos casos, MLX puede ofrecer mejores resultados.
- Puertos de red y derechosSi varios clientes deben acceder al mismo modelo (por ejemplo, dentro de una red de empresa), deben liberarse los puertos locales, preferiblemente protegidos mediante HTTPS o a través de un proxy interno.
- Seguridad de los datosAunque los modelos se ejecuten localmente, los textos sensibles no deben almacenarse en entornos inseguros. Los registros locales y los registros de chat son fáciles de olvidar, pero a menudo contienen información valiosa.
Si presta atención a estos puntos, podrá operar un potente sistema de IA local que funcione de forma segura, silenciosa y eficiente con sorprendentemente poco esfuerzo.
Calendario y consideraciones estratégicas
Estamos solo al principio de una evolución que cambiará el día a día de muchas profesiones en los próximos años. Los modelos locales de IA serán cada vez más pequeños, rápidos y eficientes, al tiempo que su calidad seguirá mejorando. Lo que hoy requiere 30 GB de memoria puede que dentro de un año sólo necesite 10 GB, con la misma calidad de voz. Al mismo tiempo, están surgiendo nuevas interfaces que permiten integrar los modelos directamente en los programas de Office, los navegadores o el software de las empresas.
Las empresas que hoy dan el paso hacia una infraestructura local de IA están creando una ventaja para sí mismas. Adquieren experiencia, garantizan la soberanía de sus datos y se independizan de las fluctuaciones de precios o las restricciones de uso impuestas por proveedores externos. Una estrategia sensata podría ser la siguiente:
- Experimente primero con un modelo pequeño (por ejemplo, de 3.000 a 7.000 millones de parámetros, mediante Ollama o LM Studio).
- A continuación, compruebe específicamente qué tareas pueden automatizarse.
- Si es necesario, integre modelos más grandes o cree un Mac Studio central como "servidor de IA".
- A medio plazo, reorganizar los procesos internos (por ejemplo, documentación, análisis de textos, comunicación) con ayuda de la IA.
Este enfoque paso a paso no sólo es sensato desde el punto de vista económico, sino también sostenible: sigue el principio de adoptar la tecnología a tu propio ritmo en lugar de dejarte llevar por las tendencias.
En otro artículo, he descrito en detalle cómo los nuevos Formato MLX comparado con GGUF a través de Ollama en el Mac.
La IA local como vía silenciosa hacia la soberanía digital
Los modelos lingüísticos locales marcan el retorno a la autodeterminación en el mundo digital.
En lugar de enviar datos e ideas a centros de datos remotos en la nube, ahora puede volver a trabajar con sus propias herramientas, directamente en su escritorio, bajo su propio control.
Ya sea en un Mac Mini, en un Mac Studio o en un potente portátil: si dispone del hardware adecuado, ahora puede utilizar, entrenar y seguir desarrollando su propia IA. Ya sea como asistente personal, como parte de un sistema ERP, como ayuda a la investigación en una editorial o como solución para la protección de datos en un bufete de abogados, las posibilidades son asombrosamente amplias.
Y lo mejor de todo: nos recuerda la antigua fuerza del ordenador: ser una herramienta que controlas tú mismo, en lugar de un servicio que nos dicta cómo debemos trabajar. Esto convierte a la IA local en un símbolo de la autonomía moderna: silenciosa, eficiente y, sin embargo, con un efecto impresionante.
La IA local en la empresa despliega su valor con la base de sistema adecuada
 El debate sobre la IA local suele centrarse en el hardware, los modelos y la velocidad, pero las ventajas reales sólo se hacen patentes cuando interactúa con sus propios datos y procesos. Si realmente se quiere utilizar la IA con sensatez, se necesita un entorno estable y controlado en el que la información no esté dispersa, sino disponible de forma estructurada. Aquí es precisamente donde una solución ERP de gestión local Forma la columna vertebral de los datos, procesos y correlaciones dentro de la empresa. En combinación con una solución como gFM Business ERP, se crea un bucle cerrado en el que la IA local no sólo proporciona respuestas, sino que también trabaja contextualmente, por ejemplo, integrando su propio gráfico de conocimiento. De este modo, las decisiones ya no se basan en modelos generales, sino en datos reales de la empresa. El resultado es un paso silencioso pero eficaz hacia la verdadera soberanía digital: más control, más eficiencia y un sistema que se adapta a la empresa, y no al revés.
El debate sobre la IA local suele centrarse en el hardware, los modelos y la velocidad, pero las ventajas reales sólo se hacen patentes cuando interactúa con sus propios datos y procesos. Si realmente se quiere utilizar la IA con sensatez, se necesita un entorno estable y controlado en el que la información no esté dispersa, sino disponible de forma estructurada. Aquí es precisamente donde una solución ERP de gestión local Forma la columna vertebral de los datos, procesos y correlaciones dentro de la empresa. En combinación con una solución como gFM Business ERP, se crea un bucle cerrado en el que la IA local no sólo proporciona respuestas, sino que también trabaja contextualmente, por ejemplo, integrando su propio gráfico de conocimiento. De este modo, las decisiones ya no se basan en modelos generales, sino en datos reales de la empresa. El resultado es un paso silencioso pero eficaz hacia la verdadera soberanía digital: más control, más eficiencia y un sistema que se adapta a la empresa, y no al revés.
Fuentes recomendadas
- Perfiles de inferencia de grandes modelos lingüísticos en Apple SiliconA Quantisation Perspective (Benazir & Lin et al., 2025) - Examina en detalle el rendimiento de inferencia en Apple Silicon en comparación con las GPU NVIDIA, centrándose específicamente en la cuantificación.
- Inferencia LLM local de grado de producción en Apple SiliconA Comparative Study of MLX, MLC-LLM, Ollama, llama.cpp, and PyTorch MPS (Rajesh et al., 2025) - Comparación de diferentes plataformas en Apple Silicon incl. MLX, con respecto al rendimiento, latencia, longitud de contexto.
- Evaluación comparativa del aprendizaje automático en dispositivos Apple Silicon con MLX (Ajayi & Odunayo, 2025) - Centrado en MLX y Apple Silicon, con datos de referencia frente a sistemas NVIDIA.


Preguntas más frecuentes
- ¿Qué es exactamente un modelo lingüístico local?
Un modelo de lenguaje local es una IA capaz de comprender y generar textos, similar a ChatGPT. La diferencia es que no se ejecuta a través de Internet, sino directamente en tu propio ordenador. Todos los cálculos se realizan localmente y no se envían datos a servidores externos. Esto significa que usted mantiene el control total sobre su propia información. - ¿Qué ventajas ofrece una IA local frente a una solución en la nube como ChatGPT?
Las tres mayores ventajas son la protección de datos, la independencia y el control de costes.
- Protección de datos: ningún texto sale del ordenador.
- Independencia: No se necesita conexión a Internet, no hay que cambiar de proveedor ni riesgo de fallos.
- Costes: Sin cuotas por consulta. Pagas una vez por el hardware y ya está. - ¿Necesita conocimientos de programación para utilizar localmente un modelo lingüístico?
No. Con herramientas modernas como Ollama o LM Studio, se puede poner en marcha un modelo con sólo unos clics. Hoy en día, incluso los principiantes pueden ejecutar una IA local en pocos minutos sin escribir una sola línea de código. - ¿Qué dispositivos Apple son especialmente adecuados?
Para los principiantes, un Mac Mini con M4 o M4 Pro y al menos 32 GB de RAM suele ser suficiente. Si desea utilizar modelos más grandes o varios al mismo tiempo, es mejor optar por un Mac Studio con 64 GB o 128 GB de RAM. Un Mac Pro apenas ofrece ventajas, a menos que necesites ranuras PCI-e. Los portátiles son adecuados, pero alcanzan sus límites térmicos más rápidamente. - ¿Cuál es la cantidad mínima de RAM que debe tener?
Depende del tamaño del modelo.
- Modelos pequeños (1-3.000 millones de parámetros): 16-32 GB son suficientes.
- Modelos medianos (7-13 mil millones): mejor 48-64 GB.
- Modelos grandes (más de 30.000 millones): 128 GB o más.
Es importante planificar con cierta reserva; de lo contrario, habrá tiempos de espera o cancelaciones. - ¿Qué significa "memoria unificada" para Apple Silicon?
La memoria unificada es una memoria compartida a la que acceden simultáneamente la CPU, la GPU y el motor neuronal. Esto ahorra tiempo y energía, ya que no es necesario copiar datos entre distintas áreas de memoria. Es una gran ventaja, sobre todo para los cálculos de IA, porque todo funciona en un solo flujo. - ¿Cuál es la diferencia entre GGUF, MLX y Safetensors?
- GGUF: formato compacto para uso local (por ejemplo, en Ollama o LM Studio). Ideal para la inferencia, es decir, la ejecución de modelos acabados.
- MLX: formato propio de Apple, especial para chips M. Muy eficiente, pero aún joven.
- Safetensors: Un formato del mundo PyTorch, destinado principalmente a la formación y la investigación.
GGUF o MLX son ideales para uso local en el Mac. - ¿De dónde saca los modelos?
La plataforma más conocida es huggingface.co, una enorme biblioteca de modelos de IA. En ella se pueden encontrar variantes de LLaMA, Mistral, Gemma, Phi-3 y muchos otros. Muchos modelos ya están disponibles en formato GGUF y pueden cargarse directamente en Ollama. - ¿Con qué herramientas es más fácil empezar?
Para empezar, Ollama y LM Studio son ideales. Ollama se ejecuta en el terminal y es ligero. LM Studio ofrece una interfaz gráfica de usuario con una ventana de chat. Ambos cargan e inician los modelos automáticamente y no requieren una configuración complicada. - ¿Se pueden utilizar también modelos lingüísticos con FileMaker Server?
Sí, desde FileMaker Server 2025 se puede acceder directamente a los modelos MLX. Esto permite realizar análisis de texto, clasificaciones o evaluaciones automáticas dentro de sistemas ERP o CRM, por ejemplo. Esto permite procesar datos empresariales confidenciales de forma local sin tener que enviarlos a proveedores externos. - ¿Qué tamaño suelen tener estos modelos?
Los modelos pequeños son de unos pocos gigabytes, los grandes pueden tener de 20 a 30 GB o más. Su tamaño puede reducirse considerablemente mediante la cuantificación (por ejemplo, 4 bits), a menudo con una pérdida mínima de calidad. Un modelo 13-B comprimido, por ejemplo, sólo puede ocupar 7 GB, perfecto para un Mac Mini M4 Pro. - ¿Es posible entrenar o personalizar los modelos locales?
Básicamente, sí, pero el entrenamiento es muy intensivo desde el punto de vista computacional. Los marcos MLX o Python pueden utilizarse para el ajuste local de modelos más pequeños. Actualmente, FileMaker contiene una función integrada para Ajuste directo de los modelos lingüísticos para poder hacerlo. Sin embargo, para el entrenamiento a gran escala (por ejemplo, 50.000 millones de parámetros), sería necesaria una granja de GPU dedicadas. Para la mayoría de las aplicaciones, basta con utilizar los modelos existentes y controlarlos específicamente mediante avisos. - ¿Cuánta energía consume un Mac durante los cálculos de inteligencia artificial?
Sorprendentemente poco. Un Mac Studio suele consumir menos de 100 W en pleno funcionamiento, mientras que una sola tarjeta gráfica NVIDIA (por ejemplo, RTX 5090) consume hasta 450 W, sin CPU ni periféricos. Esto significa que la IA local en hardware Apple no solo es más silenciosa, sino también mucho más eficiente desde el punto de vista energético. - ¿Es adecuado un MacBook Pro para la IA local?
Sí, pero con restricciones.
Aunque el rendimiento es alto, la capacidad de carga térmica es limitada. El procesador se ralentiza durante las sesiones más largas. Un MacBook Pro M3/M4 es perfecto para chats breves, tareas de texto o análisis, pero no para un uso prolongado. - ¿Hasta qué punto son seguros los modelos locales?
Tan seguros como el sistema en el que se ejecutan. Como no se envían datos a través de Internet, prácticamente no hay riesgo por parte de terceros. Sin embargo, debes asegurarte de que los archivos temporales, registros o historiales de chat no acaben accidentalmente en carpetas en la nube (por ejemplo, iCloud Drive). Lo ideal es el almacenamiento local en el SSD interno. - ¿Cuáles son los errores típicos que cometen los principiantes?
- Carga de modelos demasiado grandes, aunque no haya suficiente memoria RAM.
- Utiliza versiones antiguas de Ollama o LM Studio.
- No active la aceleración de la GPU (por ejemplo, MLX).
- Demasiados procesos ejecutándose en segundo plano.
- Carga de modelos de dudosa procedencia.
Remedio: Utilice sólo fuentes fiables (por ejemplo, Hugging Face) y vigile los recursos del sistema. - ¿Cómo evolucionará la tecnología local de IA en los próximos años?
Los modelos son cada vez más compactos y precisos. Apple, Mistral y Meta ya trabajan en arquitecturas que requieren menos memoria y potencia para la misma calidad. Al mismo tiempo, se están desarrollando interfaces cómodas, como plug-ins de inteligencia artificial para procesadores de texto, programas de correo o aplicaciones de notas. A largo plazo, es probable que todos los sistemas profesionales cuenten con una especie de „IA local integrada“. - ¿Por qué merece la pena empezar ahora?
Porque las bases para los próximos años se están sentando ahora mismo. Quien aprenda hoy a poner en marcha un modelo localmente, a procesar datos de forma estructurada y a formular avisos de forma específica, podrá actuar de forma independiente más adelante, sin tener que depender de costosos proveedores en la nube. En resumen: la IA local es el camino tranquilo y seguro hacia un futuro digital en el que podrá volver a tener sus datos y herramientas en sus propias manos.


