Wie tegenwoordig met kunstmatige intelligentie werkt, denkt vaak als eerste aan ChatGPT of soortgelijke online diensten. Je typt een vraag in, wacht een paar seconden - en krijgt antwoord alsof er een zeer belezen, geduldige gesprekspartner aan de andere kant van de lijn zit. Maar wat wordt gemakkelijk vergeten: Elke input, elke zin, elk woord reist via het internet naar externe servers. Daar wordt het echte werk gedaan - op enorme computers die je zelf nooit te zien krijgt.
In principe werkt een lokaal taalmodel op precies dezelfde manier - maar dan zonder internet. Het model wordt als bestand opgeslagen op de computer van de gebruiker, wordt bij het opstarten in het werkgeheugen geladen en beantwoordt vragen direct op het apparaat. De achterliggende technologie is hetzelfde: een neuraal netwerk dat taal begrijpt, teksten genereert en patronen herkent. Het enige verschil is dat de hele berekening binnenshuis blijft. Je zou kunnen zeggen: ChatGPT zonder de cloud.
Het bijzondere hieraan is dat de technologie nu zo ver ontwikkeld is dat het niet meer afhankelijk is van enorme datacenters. Moderne Apple computers met M-processors (zoals M3 of M4) hebben een enorme rekenkracht, snelle geheugenverbindingen en een gespecialiseerde neurale motor voor machinaal leren. Daardoor kunnen veel modellen nu rechtstreeks op een Mac Mini of Mac Studio worden gebruikt - zonder serverpark, zonder ingewikkelde set-up en zonder veel ruis.


Laatste nieuws over Apple MLX en NVIDIA
26.03.2026Apple blijft zijn MLX AI-framework strategisch verder ontwikkelen en stelt het steeds meer open voor andere platforms. Oorspronkelijk exclusief geoptimaliseerd voor Apple Silicon, MLX ondersteunt nu ook CUDA GPU's en dus klassieke Nvidia-hardware. Dit neemt een belangrijke hindernis weg voor ontwikkelaars: tot nu toe moesten modellen vaak worden ontwikkeld op de Mac en vervolgens worden getraind op aparte krachtige systemen. Door de opening wordt MLX een flexibeler ontwikkelplatform dat zowel lokale AI op Apple apparaten als schaalbare training op externe hardware mogelijk maakt. Tegelijkertijd blijft het voordeel van nauwe integratie met de eigen architectuur van Apple behouden, bijvoorbeeld door efficiënt geheugenbeheer en direct GPU-gebruik. De ontwikkeling duidt op een strategische koerswijziging: Apple verlaat geleidelijk zijn gesloten ecosysteem en positioneert MLX als een serieus alternatief voor gevestigde AI-frameworks - met mogelijke implicaties voor AI-ontwikkeling als geheel.
Dit opent een nieuwe deur, niet alleen voor ontwikkelaars, maar ook voor ondernemers, schrijvers, advocaten, artsen, leraren en vakmensen. Iedereen kan nu zijn eigen kleine AI hebben - op zijn bureau, onder volledige controle, klaar voor gebruik op elk moment. Een lokaal taalmodel kan:
- Teksten samenvatten of corrigeren,
- E-mails formuleren of structureren,
- Vragen vragen beantwoorden en kennis analyseren,
- Processen ondersteuning in programma's,
- Documenten zoeken of classificeren,
- of gewoon als persoonlijke assistent zonder ooit gegevens naar de buitenwereld te lekken.
Deze aanpak wordt steeds belangrijker, vooral in een tijd waarin gegevensbescherming en digitale soevereiniteit weer centraal komen te staan. Je hoeft geen programmeur te zijn om het te gebruiken - een moderne Mac is alles wat je nodig hebt. De modellen kunnen gewoon worden gestart via een app of een terminalvenster en reageren dan bijna net zo natuurlijk als een chatvenster in de browser.
Dit artikel laat zien welke modellen vandaag de dag op welke Mac kunnen draaien, wat de hardware moet doen en waarom Apple Silicon computers hier bijzonder geschikt voor zijn. Kortom, het gaat over hoe je de kracht van AI weer in eigen handen kunt nemen - stil, efficiënt en lokaal.
Lokale taalmodellen op de Mac - Waarom dit nu zinvol is
Een taalmodel „lokaal“ uitvoeren betekent dat het volledig op je eigen computer wordt uitgevoerd - zonder verbinding met een cloudservice. De berekening, de analyse van invoer, het genereren van teksten of antwoorden - alles gebeurt direct op je eigen apparaat. Het model wordt daarom opgeslagen als een bestand op de SSD, wordt geladen in het RAM bij het opstarten en werkt daar met de volledige prestatie van het systeem.
Het belangrijkste verschil met de cloudvariant is onafhankelijkheid. Er gaan geen gegevens over het internet, er worden geen externe servers gebruikt en niemand kan traceren wat er intern wordt verwerkt. Dit biedt een aanzienlijke mate van gegevensbescherming en -controle - vooral in tijden waarin gegevensbewegingen steeds moeilijker te traceren zijn.
In het verleden was het ondenkbaar om zulke modellen lokaal uit te voeren. Er was een mainframecomputer of GPU-farm nodig om een neuraal netwerk van deze omvang überhaupt draaiende te houden. Tegenwoordig kan dit met de rekenkracht van moderne Apple-Silicon chips worden gerealiseerd op een desktopapparaat - efficiënt, stil en met een laag energieverbruik.
Waarom Apple Silicon ideaal is
Met de overstap naar Silicon heeft Apple de kaarten opnieuw geschud. In plaats van de klassieke Intel-architectuur met aparte CPU en GPU, vertrouwt Apple op een zogenaamd unified memory design: processor, graphics en neural engine hebben toegang tot hetzelfde snelle hoofdgeheugen. Hierdoor hoeven er geen gegevens gekopieerd te worden tussen de afzonderlijke componenten - een doorslaggevend voordeel voor AI-berekeningen.
De neural engine zelf is een gespecialiseerde rekenkern voor machinaal leren die direct in de chips is geïntegreerd. Het maakt miljarden rekenbewerkingen per seconde mogelijk - met een zeer laag energieverbruik. Samen met de MLX-bibliotheek (Machine Learning voor Apple Silicon) en moderne frameworks zoals OLaMA kunnen modellen nu direct op macOS draaien zonder complexe GPU-stuurprogramma's of CUDA-afhankelijkheden.
Een M4-chip in de Mac Mini is al voldoende om compacte taalmodellen (bijvoorbeeld 3-7 miljard parameters) probleemloos uit te voeren. Op een Mac Studio met M4 Max of M3 Ultra kun je zelfs modellen met 30 miljard parameters draaien - volledig lokaal.
Vergelijking: Apple Silicon vs. NVIDIA-hardware
Van oudsher zijn de RTX grafische kaarten van NVIDIA de gouden standaard voor AI-berekeningen. Een huidige RTX 5090 biedt bijvoorbeeld enorme ruwe prestaties en is nog steeds de eerste keuze voor veel trainingssystemen. Toch is een gedetailleerde vergelijking de moeite waard, omdat de prioriteiten verschillen.
| Aspect | Apple Silicon (M4 / M4 Max / M3 Ultra) | NVIDIA GPU (5090 & Co.) |
|---|---|---|
| Energieverbruik | Zeer efficiënt - gewoonlijk minder dan 100 W totaal verbruik | Tot 450 W voor de GPU alleen |
| Geluidsontwikkeling | Vrijwel geluidloos | Duidelijk hoorbaar onder belasting |
| Software-stapel | MLX / Kern ML / Metaal | CUDA / cuDNN / PyTorch |
| Onderhoud | Bestuurderloos en stabiel | Frequente updates en compatibiliteitsproblemen |
| Prijs-prestatieverhouding | Hoog rendement voor een bescheiden prijs | Betere piekprestaties, maar duurder |
| Ideaal voor | Lokale inferentie en continue werking | Training en grote modellen |
Kortom: NVIDIA is de keuze voor datacenters en extreme training. Apple Silicon is daarentegen ideaal voor lokaal, langdurig gebruik - zonder ruis, zonder warmteontwikkeling, met een stabiele softwarebasis en een beheersbaar stroomverbruik.
Apple Silicon vergeleken met NVIDIA voor inferentie
De M3 Ultra betekent een belangrijke stap voorwaarts voor Apple Silicon: naast een sterk geïntegreerd chipontwerp met CPU, GPU en neural engine in één pakket, vertrouwt het op een uniforme geheugenarchitectuur waarbij RAM gelijktijdig door alle rekeneenheden wordt gebruikt - zonder de klassieke scheiding van RAM en GPU VRAM. Volgens benchmarks levert deze aanpak in sommige gevallen al vergelijkbare of zelfs betere prestaties in lokale inferentietaken dan high-end grafische kaarten van NVIDIA. Een voorbeeld: In de test behaalde de M3 Ultra ongeveer 2.320 tokens/s met een Qwen3-30B 4bit model, vergeleken met de RTX 3090 met 2.157 tokens/s.
Daarnaast suggereert een vergelijking van Apple Silicon vs NVIDIA onder AI-belastingen dat een M3/M4 Max systeem tussen de 40-80W zal halen onder belasting, terwijl een RTX 4090 typisch tot 450W zal trekken.
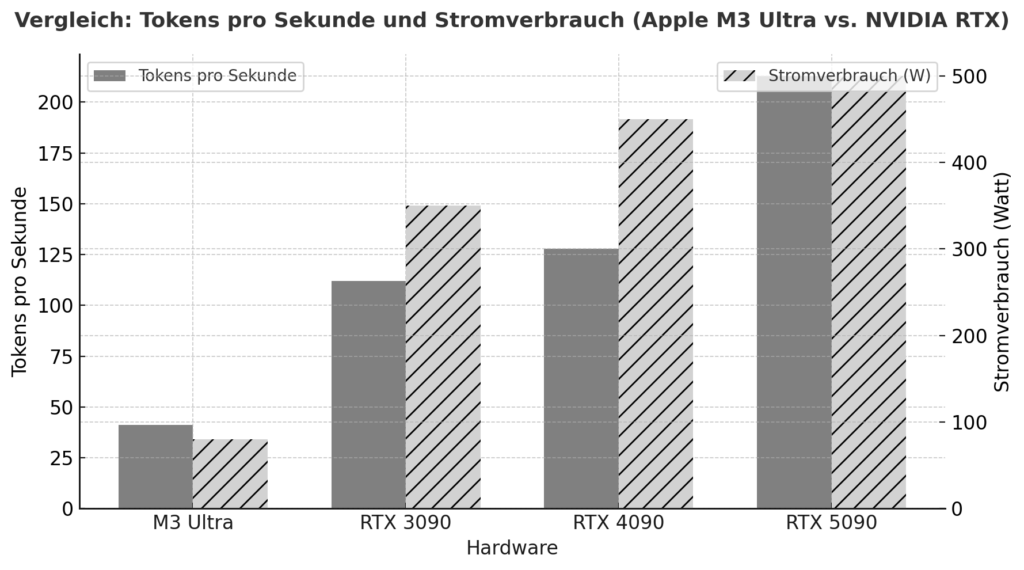
Hieruit blijkt dat als je niet alleen kijkt naar piekprestaties, maar ook naar efficiëntie per watt, de Apple Silicon een uitstekende positie inneemt. Aan de andere kant zijn er de NVIDIA-kaarten (bijvoorbeeld 3090, 4090, 5090) met hun enorm geparallelleerde GPU-architectuur, zeer hoge CUDA/tensor core-dichtheid en gespecialiseerde bibliotheken (CUDA, cuDNN, TensorRT). Dit is waar de ruwe top-flops prestaties vaak een voorsprong hebben - maar met doorslaggevende beperkingen voor lokale taalmodellen: het beschikbare VRAM (bijv. 24-32 GB voor gamingkaarten) wordt al snel een knelpunt als modellen met 20-30 miljard parameters of meer moeten worden geladen. In een gebruikersrapport staat bijvoorbeeld dat het met een RTX 5090 met ongeveer 32 GB VRAM al moeilijk is om een model met 20-22 miljard parameters te laden.
Hierbij moet je niet alleen kijken naar GPU-kernen, maar ook naar de beschikbare geheugengrootte, bandbreedte en geheugenarchitectuur. De M3 Ultra met tot 512 GB verenigd geheugen (in de topconfiguraties) biedt hier bijvoorbeeld voordelen in veel lokale implementatiescenario's - vooral als modellen niet in de cloud moeten draaien, maar permanent lokaal.
| Hardware | Model / Opstelling | Tokens per seconde (bij benadering) | Opmerking |
|---|---|---|---|
| Apple M3 Ultra (Mac Studio) | z. bijv. Gemma-3-27B-Q4 op M3 Ultra | ≈ 41 tok/s :contentReference[oaicite:2]{index=2} | LLM-inferentie, context 4k tokens, gekwantificeerd |
| NVIDIA RTX 5090 | 8 B-model (gekwantificeerd) volgens onderzoek | ≈ 213 tok/s :contentReference[oaicite:3]{index=3} | 8 B-model, 4-bit, RLHF-omgeving |
| NVIDIA RTX 4090 | 8 B Referentie model | ≈ 128 tok/s :contentReference[oaicite:4]{index=4} | 24 GB VRAM Omgeving |
| NVIDIA RTX 3090 | Budget High End in vergelijking | ≈ 112 tok/s :contentReference[oaicite:5]{index=5} | Tweedehandsmarkt, 24 GB VRAM |
Praktische relevantie: Waar lokale taalmodellen zinvol zijn
De mogelijke toepassingen van lokale AI zijn tegenwoordig bijna onbeperkt. Wanneer gegevens vertrouwelijk moeten blijven of processen in realtime moeten draaien, is de lokale versie de moeite waard. Voorbeelden uit de praktijk:
- ERP-systemenAutomatische tekstanalyse, suggesties, voorspellingen of communicatiehulpmiddelen - rechtstreeks vanuit de software.
- Boek- en mediaproductieStijlcontrole, vertaling, samenvatting, tekstuitbreiding - allemaal lokaal, zonder afhankelijkheid van de cloud.
- Advocaten en notarissenAnalyse van documenten, ontwerppleidooien, onderzoek - onder de strengste geheimhouding.
- Artsen en therapeutenEvaluatie van casussen, documentatie of geautomatiseerde rapporten - zonder dat patiëntgegevens ooit het systeem verlaten.
- Ingenieursbureaus en architectenTekst-, project- en rekenwizards die ook zonder internet werken.
- Bedrijf in het algemeenKennisbeheer, interne chatassistenten, protocolanalyse, e-mailclassificatie - allemaal binnen uw eigen netwerk.
Dit is een grote stap, vooral in de commerciële sector: in plaats van te betalen voor externe AI-diensten en gegevens naar de cloud te sturen, kun je nu op maat gemaakte modellen uitvoeren op je eigen machines. Deze kunnen worden aangepast, verfijnd en uitgebreid met de eigen kennis van het bedrijf - volledig onder controle.
Het resultaat is een modern maar traditioneel soeverein IT-landschap dat technologie gebruikt zonder de controle over de eigen gegevens op te geven. Een aanpak die ons doet denken aan oude deugden: de dingen in eigen hand houden.
Huidig onderzoek naar lokale AI-systemen
Overzicht: Mac Mini en Mac Studio - wat is er momenteel verkrijgbaar?
Als we tegenwoordig lokale taalmodellen willen uitvoeren op een Mac, dan zijn er twee desktopklassen die in het bijzonder in aanmerking komen: de Mac mini en de Mac Studio.
- Mac MiniDe nieuwste generatie biedt de Apple M4 chip of optioneel de M4 Pro. Volgens de technische specificaties zijn varianten met 24 GB of 32 GB gecombineerd geheugen beschikbaar; de Pro-variant wordt aangeboden met configureerbaar gecombineerd geheugen van maximaal 48 GB of 64 GB. Dit maakt de Mac Mini zeer geschikt voor veel programma's, vooral als het model niet extreem groot is of niet meerdere zeer grote taken parallel hoeft te draaien.
- Mac StudioHier gaan we nog een stapje hoger. Uitgerust met bijvoorbeeld de Apple M4 Max chip of de M3 Ultra chip - afhankelijk van het model. Met de M4 Max versie is 48 GB, 64 GB of tot 128 GB unified memory mogelijk. De M3 Ultra-versie van de Mac Studio kan worden uitgerust met maximaal 512 GB gecombineerd geheugen. De SSD-groottes en geheugenbandbreedtes nemen ook aanzienlijk toe. Dit maakt de Mac Studio geschikt voor meer veeleisende modellen of parallelle processen.
In het kort: De Mac Pro bestaat ook en biedt vaak „meer chassis“ of PCI-e slots aan de buitenkant - maar in termen van taalmodellen biedt het niet veel voordeel ten opzichte van de Mac Studio voor de lokale versie als je geen extra uitbreidingskaarten of speciale PCIe vereisten hebt.
Ook Notitieboekjes (bijv. MacBook Pro) kunnen zeker worden gebruikt, maar met beperkingen: De koelsystemen zijn kleiner, de thermische prestaties zijn beperkter en het RAM-budget is vaak lager. Langdurig gebruik (zoals bij AI-modellen) kan de prestaties verminderen.

AI: Apple beter dan Nvidia! 😮 | k't 3003
Waarom RAM / unified memory zo belangrijk is
Wanneer een taalmodel lokaal draait, zijn niet alleen de CPU- of GPU-prestaties nodig - het RAM-geheugen (of „unified memory“ in het geval van Apple) is ook cruciaal. Waarom?
Het model zelf (gewichten, activeringen, tussenresultaten) moet in het geheugen worden opgeslagen. Hoe groter het model, hoe meer geheugen er nodig is. Apple-Silicon chips maken gebruik van "unified memory", dat wil zeggen dat CPU, GPU en neural engine toegang hebben tot dezelfde geheugenpool. Hierdoor hoeven er geen gegevens gekopieerd te worden tussen de componenten, wat de efficiëntie en snelheid verhoogt.
Als er niet genoeg RAM is, moet het systeem uitwijken of worden modellen niet volledig geladen - wat een daling van de prestaties, instabiliteit of annulering kan betekenen. Vooral bij inferentietoepassingen (responsgeneratie, tekstinvoer, modeluitbreiding) zijn reactietijd en doorvoer cruciaal - voldoende geheugen helpt hier aanzienlijk. Een traditionele desktop-pc dacht vroeger in termen van „CPU RAM“ en „afzonderlijke GPU RAM“ - met de Apple Silicon wordt dit elegant gecombineerd, wat het uitvoeren van taalmodellen bijzonder aantrekkelijk maakt.
Geschatte waarden: Welke orde van grootte is realistisch?
Om je te helpen inschatten welke hardware je nodig zult hebben, volgen hier enkele ruwe richtwaarden:
- Voor kleinere modellen (bijvoorbeeld een paar miljard parameters), zou 16 GB tot 32 GB RAM voldoende kunnen zijn - vooral als er alleen individuele queries verwerkt moeten worden. Een Mac Mini met 16/32 GB zou daarom een goed begin zijn.
- Voor middelgrote modellen (bijvoorbeeld 3-10 miljard parameters) of taken met meerdere parallelle chats of grote hoeveelheden tekst, moet u 32 GB RAM of meer overwegen - bijvoorbeeld Mac Studio met 32 of 48 GB.
- Voor grote modellen (>20 miljard parameters) of als meerdere modellen parallel moeten draaien, kun je kiezen voor 64 GB of meer - Mac mini- en Mac Studio-varianten met 64 GB of meer zijn hier mogelijk.
Belangrijk: Vergeet niet om wat buffer in te plannen - niet alleen het model, maar ook de werking (bijvoorbeeld het besturingssysteem, bestands-I/O, andere toepassingen) vereist geheugenreserves.
| Categorie | Typische modelgrootte | Aanbevolen RAM-budget | Voorbeeld van gebruik |
|---|---|---|---|
| Klein | 1-3 miljard parameters | 16-32 GB | Eenvoudige assistent, tekstherkenning |
| Medium | 7-13 miljard parameters | 32-64 GB | Chat, analyse, tekstcreatie |
| Groot | 30-70 miljard parameters | 64 GB + | Gespecialiseerde teksten, juridische documenten |
De traditionele denkwijze "server vs. desktop" in twijfel trekken
Traditioneel dacht men dat voor AI serverparken, veel GPU's, veel vermogen en een datacenter nodig waren. Maar het beeld verandert: desktopcomputers zoals Mac Mini of Mac Studio bieden nu voldoende prestaties voor veel lokaal beheerde taalmodellen - zonder een enorme infrastructuur. In plaats van hoge elektriciteitskosten, krachtige koeling en complex onderhoud, krijg je een stil, effectief apparaat op je bureau.
Als je modellen op grote schaal wilt trainen of een groot aantal parameters wilt gebruiken, zijn serveroplossingen natuurlijk nog steeds zinvol. Desktop hardware is echter vaak voldoende voor inferentie, aanpassing en dagelijks gebruik. Dit wordt geassocieerd met een traditionele houding: gebruik technologie, maar maak er niet te veel van - gebruik het liever op een gerichte en efficiënte manier. Als je vandaag een solide lokale basis bouwt, creëer je de basis voor wat morgen mogelijk is.

M3 Ultra vs RTX 5090 | De eindstrijd (Engels)
Technische karakterisering van taalmodellen
Vandaag de dag verschillen taalmodellen niet alleen in hun mogelijkheden, maar ook in het technische formaat waarin ze beschikbaar zijn. Deze formaten bepalen hoe het model wordt opgeslagen, geladen en gebruikt - en of het überhaupt op een bepaald systeem kan draaien.
GGUF (GPT-gegenereerd verenigd formaat)
Dit formaat is ontwikkeld voor praktisch gebruik in tools zoals Ollama, LM Studio of Llama.cpp. Het is compact, draagbaar en sterk geoptimaliseerd voor lokale inferentie. GGUF-modellen zijn meestal gekwantificeerd, wat betekent dat ze aanzienlijk minder geheugen innemen omdat de interne numerieke waarden in gereduceerde vorm worden opgeslagen (bv. 4-bit of 8-bit). Hierdoor kunnen modellen die oorspronkelijk 30-50 GB groot waren, gecomprimeerd worden tot 5-10 GB - met slechts een klein kwaliteitsverlies.
- VoordeelDraait op bijna elk systeem (macOS, Windows, Linux), geen speciale GPU vereist.
- NadeelNiet bedoeld voor training of fijnafstemming - pure inferentie (d.w.z. gebruik).
MLX (machinaal leren voor Apple Silicon)
MLX is Apple's eigen open source framework voor machine learning op Apple Silicon. Het is speciaal ontwikkeld om de volledige kracht van de CPU, GPU en Neural Engine in M-Chips te benutten. MLX-modellen zijn meestal beschikbaar in native MLX-formaat of zijn geconverteerd van andere formaten.
- VoordeelMaximale prestaties en energie-efficiëntie op Apple hardware.
- NadeelNog relatief jong ecosysteem, minder community modellen beschikbaar dan bij GGUF of PyTorch.
Veiligheidssensoren (.safetensors)
Dit formaat komt oorspronkelijk uit de PyTorch-wereld (en wordt sterk gepromoot door Hugging Face). Het is een veilig, binair opslagformaat voor grote modellen dat geen code-uitvoering toestaat - vandaar de naam „safe“.
- VoordeelZeer snel laden, geheugenbesparend, gestandaardiseerd.
- Nadeel: Voornamelijk bedoeld voor frameworks zoals PyTorch of TensorFlow - dus meer gebruikelijk in ontwikkelaarsomgevingen en voor trainingsprocessen.
| Formaat | Platform | Doel | Voordelen | Nadelen |
|---|---|---|---|---|
| GGUF | macOS, Windows, Linux | Inferentie | Compact, snel, universeel | Geen training mogelijk |
| MLX | macOS (Apple Silicon) | Inferentie + Training | Geoptimaliseerd voor M-Chips, hoog rendement | Minder modellen beschikbaar |
| Veiligheidssensoren | Platformoverschrijdend (PyTorch / TensorFlow) | Training en onderzoek | Veilig, gestandaardiseerd, snel | Niet rechtstreeks compatibel met Ollama / MLX |
Hugging Face - de centrale bevoorradingsbron
Vandaag de dag is Hugging Face zoiets als de "bibliotheek" van de AI-wereld. Op knuffelgezicht.co vindt u tienduizenden modellen, gegevenssets en tools - waarvan vele gratis te gebruiken zijn. U kunt filteren op naam, architectuur, licentietype of bestandsformaat. Of het nu gaat om Mistral, LLaMA, Falcon, Gemma of Phi-3 - bijna alle bekende modellen zijn er vertegenwoordigd. Talrijke ontwikkelaars bieden al aangepaste versies aan voor lokaal gebruik met GGUF of MLX.
Hierdoor is Hugging Face voor de meeste gebruikers de eerste aanloophaven als ze een model willen uitproberen of een geschikte variant voor macOS willen vinden.

Typische modellen en hun toepassingsgebieden
Het aantal beschikbare modellen is nu bijna niet meer bij te houden. Toch zijn er een paar hoofdfamilies die bijzonder succesvol zijn gebleken voor lokaal gebruik:
- LLaMA-familie (Meta)Een van de bekendste open source modellen. Het vormt de basis voor talloze afgeleiden (bijv. Vicuna, WizardLM, Open-Hermes). Sterke punten: Taalbegrip, dialoog, veelzijdig gebruik. Toepassingsgebied: Algemene chattoepassingen, contentgeneratie, assistentiesystemen.
- Mistral & Mixtral (Mistral AI)Bekend om zijn hoge efficiëntie en goede kwaliteit met een klein modelformaat. Mixtral 8x7B combineert meerdere expertmodellen (Mixture-of-Experts-architectuur). Sterke punten: Snelle, precieze antwoorden, hulpbronnenbesparend. Toepassingsgebied: Interne bedrijfsassistenten, tekstanalyse, gegevensvoorbereiding.
- Phi-3 (Microsoft Onderzoek)Compact model, geoptimaliseerd voor hoge spraakkwaliteit ondanks een laag aantal parameters. Sterke punten: Efficiëntie, goede grammatica, gestructureerde antwoorden. Toepassingsgebied: Kleinere systemen, lokale kennismodellen, geïntegreerde assistenten.
- Gemma (Google)Gepubliceerd door Google Research als open model. Goed voor samenvattende en verklarende taken. Sterke punten: coherentie, contextuele verklaringen. Toepassingsgebied: kennisverwerking, training, adviessystemen.
- GPT-OSS / OpenHermes modellenSamen met LLaMA-aanpassingen vormen ze de "brug" tussen open source modellen en het functionele bereik van commerciële systemen. Sterke punten: Brede taalbasis, flexibel gebruik. Toepassingsgebied: Inhoud creëren, chat- en analysetaken, interne AI-hulp.
- Claude / Command R / Valk / Yi / ZephyrDeze en vele andere modellen (meestal uit onderzoeksprojecten of open gemeenschappen) bieden speciale functies zoals het ophalen van kennis, het genereren van code of meertaligheid.
Het belangrijkste punt is dat geen enkel model alles perfect kan. Elk model heeft zijn sterke en zwakke punten - en afhankelijk van de toepassing is het de moeite waard om een gerichte vergelijking te maken.
Welk model is geschikt voor welk doel?
Voor een realistische beoordeling kunnen de modellen grofweg worden ingedeeld in prestatie- en toepassingsklassen:
Voor de meeste realistische desktoptoepassingen - zoals samenvattingen, correspondentie, vertaling, analyse - zijn middelgrote modellen (7-13 B) zijn volledig toereikend. Ze leveren verbluffend goede resultaten, draaien soepel op een Mac Mini M4 Pro met 32-48 GB RAM en hoeven nauwelijks aangepast te worden.
Grote modellen tonen hun sterke punten wanneer dieper begrip of langere contexten belangrijk zijn - bijvoorbeeld bij het verwerken van juridische teksten of technische documentatie. Je moet echter ten minste één Mac Studio met 64-128 GB Gebruik het werkgeheugen.
| Model familie | Oorsprong | Sterke punten | Toepassingsgebied |
|---|---|---|---|
| LLaMA | Meta | Taalbegrip, dialoog | Algemene chattoepassingen |
| Mistral / Mixtral | Mistral AI | Efficiëntie, hoge precisie | Bedrijfsassistenten, analyse |
| Phi-3 | Microsoft Onderzoek | Compact, taalkundig sterk | Kleine systemen, lokale AI |
| Gemma | Google Onderzoek | Samenhang, verklaarbaarheid | Consultancy, onderwijs, tekstuitleg |
Opties om taalmodellen lokaal te gebruiken
Als u vandaag een taalmodel wilt gebruiken op uw eigen Mac, zijn er verschillende uitvoerbare opties - afhankelijk van uw technische vereisten en het gewenste doel. Het mooie is dat je niet langer een complexe ontwikkelomgeving nodig hebt om aan de slag te gaan.
Ollama - de ongecompliceerde start
Ollama is snel een standaardtool geworden voor lokale AI-modellen. Het draait direct op macOS, maakt optimaal gebruik van de prestaties van Apple Silicon en maakt het mogelijk om een model te starten met één commando:
ollama run mistral
Dit laadt en prepareert automatisch het gewenste model, dat vervolgens beschikbaar is in de terminal of via lokale interfaces. Ollama ondersteunt het GGUF-formaat, maakt modeldownloads van Hugging Face mogelijk en kan geïntegreerd worden via REST API's of rechtstreeks in andere programma's.
Hoe werken met Ollama een lokaal taalmodel installiert en welke andere opties je ermee hebt, wordt in detail beschreven in een ander artikel. Er zijn ook andere artikelen over het gebruik van Qdrant een flexibel geheugen voor zijn lokale AI.
LM Studio - grafische gebruikersinterface en beheer
LM Studio is bedoeld voor iedereen die de voorkeur geeft aan een grafische gebruikersinterface. Het biedt modeldownloads, chatvensters, temperatuurregeling, systeemaanwijzingen en geheugenbeheer in één app. Dit is vooral ideaal voor beginners: je kunt verschillende modellen uitproberen, vergelijken, opslaan en schakelen zonder met de opdrachtregel te hoeven werken. De software draait stabiel op Apple Silicon en ondersteunt ook GGUF-modellen.
MLX / Python - voor ontwikkelaars en integrators
Als je dieper wilt gaan of modellen wilt integreren in je eigen programma's, kun je het MLX-framework van Apple gebruiken. Hiermee kunnen modellen direct worden ingebed in Python- of Swift-toepassingen. Het voordeel ligt in maximale controle en integratie in bestaande workflows - bijvoorbeeld als een bedrijf AI-functies wil toevoegen aan zijn eigen software.
FileMaker Server 2025 - AI in de bedrijfscontext
Sinds FileMaker Server 2025 MLX-gebaseerde taalmodellen kunnen ook op de server worden aangesproken. Dit maakt het voor het eerst mogelijk om een centrale bedrijfsapplicatie (bijv. ERP- of CRM-systeem) uit te rusten met zijn eigen lokale AI. Zo kunnen bijvoorbeeld supporttickets automatisch worden geclassificeerd, vragen van klanten worden geëvalueerd of de inhoud van documenten worden geanalyseerd - zonder dat de gegevens het bedrijf hoeven te verlaten.
Dit is vooral interessant voor sectoren die strenge eisen stellen aan gegevensbescherming of naleving (geneeskunde, recht, administratie, industrie).
Typische struikelblokken en hoe ze te vermijden
Zelfs als de instapdrempel laag is, zijn er een paar punten waar je rekening mee moet houden:
Geheugenbeperkingen: Als het model te groot is voor het beschikbare geheugen, zal het helemaal niet starten of extreem traag zijn. Kwantificering (bijv. 4-bit) of een kleiner model kan hier helpen.
- Belasting en warmteontwikkeling berekenenDe Mac kan merkbaar warm worden tijdens langere sessies. Goede ventilatie en het activiteitenscherm in de gaten houden zijn aan te raden.
- Gebrek aan GPU-ondersteuning voor software van derdenSommige oudere tools of ports maken geen efficiënt gebruik van de Neural Engine. In zulke gevallen kan MLX betere resultaten leveren.
- Netwerkpoorten en -rechtenAls meerdere clients toegang moeten krijgen tot hetzelfde model (bijvoorbeeld binnen een bedrijfsnetwerk), moeten lokale poorten worden vrijgegeven - bij voorkeur beveiligd via HTTPS of via een interne proxy.
- GegevensbeveiligingZelfs als de modellen lokaal draaien, moeten gevoelige teksten niet worden opgeslagen in onveilige omgevingen. Lokale logs en chatlogs worden gemakkelijk vergeten, maar bevatten vaak waardevolle informatie.
Als je op deze punten let, kun je met verrassend weinig moeite een krachtig, lokaal AI-systeem gebruiken dat veilig, stil en efficiënt werkt.
Tijdlijn en strategische overwegingen
We staan nog maar aan het begin van een ontwikkeling die het dagelijks leven van veel beroepen de komende jaren zal veranderen. Lokale AI-modellen worden steeds kleiner, sneller en efficiënter, terwijl hun kwaliteit steeds beter wordt. Wat nu nog 30 GB geheugen vereist, heeft over een jaar misschien nog maar 10 GB nodig - met dezelfde spraakkwaliteit. Tegelijkertijd verschijnen er nieuwe interfaces waarmee modellen rechtstreeks in Office-programma's, browsers of bedrijfssoftware kunnen worden geïntegreerd.
Bedrijven die vandaag de stap zetten naar een lokale AI-infrastructuur, creëren een voorsprong voor zichzelf. Ze bouwen expertise op, stellen hun gegevenssoevereiniteit veilig en maken zichzelf onafhankelijk van prijsschommelingen of gebruiksbeperkingen die door externe aanbieders worden opgelegd. Een verstandige strategie zou er als volgt uit kunnen zien:
- Experimenteer eerst met een klein model (bijvoorbeeld 3-7 miljard parameters, via Ollama of LM Studio).
- Controleer dan specifiek welke taken geautomatiseerd kunnen worden.
- Integreer indien nodig grotere modellen of zet een centrale Mac Studio op als "AI-server".
- Reorganiseer op middellange termijn interne processen (bijv. documentatie, tekstanalyse, communicatie) met AI-ondersteuning.
Deze stapsgewijze aanpak is niet alleen economisch verstandig, maar ook duurzaam - het volgt het principe van technologie adopteren in je eigen tempo in plaats van gedreven te worden door trends.
In een apart artikel heb ik in detail beschreven hoe de nieuwere MLX-formaat vergeleken met GGUF via Ollama op de Mac.
Lokale AI als stille weg naar digitale soevereiniteit
Lokale taalmodellen betekenen een terugkeer naar zelfbeschikking in de digitale wereld.
In plaats van gegevens en ideeën naar externe datacentra in de cloud te sturen, kun je nu weer met je eigen tools werken - direct op je bureau, onder je eigen controle.
Of het nu op een Mac Mini, een Mac Studio of een krachtige notebook is - als je de juiste hardware hebt, kun je nu je eigen AI gebruiken, trainen en verder ontwikkelen. Als persoonlijke assistent, als onderdeel van een ERP-systeem, als onderzoekshulp in een uitgeverij of als gegevensbeschermingsoplossing in een advocatenkantoor - de mogelijkheden zijn verbluffend breed.
En het mooiste is: het herinnert ons aan de oude kracht van de computer - namelijk dat het een gereedschap is dat je zelf bestuurt, in plaats van een dienst die dicteert hoe we moeten werken. Dit maakt lokale AI tot een symbool van moderne autonomie - stil, efficiënt en toch met een indrukwekkend effect.
Lokale AI in het bedrijf ontvouwt zijn waarde met de juiste systeembasis
 De discussie over lokale AI gaat vaak over hardware, modellen en snelheid - maar de werkelijke voordelen worden pas duidelijk als er interactie is met je eigen gegevens en processen. Als je AI echt verstandig wilt gebruiken, heb je een stabiele, gecontroleerde omgeving nodig waarin informatie niet verspreid is, maar op een gestructureerde manier beschikbaar is. Dit is precies waar een lokaal beheerde ERP-oplossing Het vormt de ruggengraat voor gegevens, processen en correlaties binnen het bedrijf. In combinatie met een oplossing zoals gFM Business ERP creëert dit een gesloten lus waarin lokale AI niet alleen antwoorden geeft, maar ook gecontextualiseerd werkt - bijvoorbeeld door het integreren van een eigen kennisgrafiek. Beslissingen worden dan niet langer gebaseerd op algemene modellen, maar op actuele bedrijfsgegevens. Het resultaat is een stille maar effectieve stap naar echte digitale soevereiniteit: meer controle, meer efficiëntie en een systeem dat zich aanpast aan het bedrijf - en niet andersom.
De discussie over lokale AI gaat vaak over hardware, modellen en snelheid - maar de werkelijke voordelen worden pas duidelijk als er interactie is met je eigen gegevens en processen. Als je AI echt verstandig wilt gebruiken, heb je een stabiele, gecontroleerde omgeving nodig waarin informatie niet verspreid is, maar op een gestructureerde manier beschikbaar is. Dit is precies waar een lokaal beheerde ERP-oplossing Het vormt de ruggengraat voor gegevens, processen en correlaties binnen het bedrijf. In combinatie met een oplossing zoals gFM Business ERP creëert dit een gesloten lus waarin lokale AI niet alleen antwoorden geeft, maar ook gecontextualiseerd werkt - bijvoorbeeld door het integreren van een eigen kennisgrafiek. Beslissingen worden dan niet langer gebaseerd op algemene modellen, maar op actuele bedrijfsgegevens. Het resultaat is een stille maar effectieve stap naar echte digitale soevereiniteit: meer controle, meer efficiëntie en een systeem dat zich aanpast aan het bedrijf - en niet andersom.
Aanbevolen bronnen
- Profilering van grote taalmodellen op Apple SiliconA Quantisation Perspective (Benazir & Lin et al., 2025) - Onderzoekt in detail de inferentieprestaties op Apple Silicon in vergelijking met NVIDIA GPU's, specifiek met de nadruk op kwantificering.
- Lokale LLM-inferentie op productieniveau op Apple SiliconEen vergelijkende studie van MLX, MLC-LLM, Ollama, llama.cpp en PyTorch MPS (Rajesh et al., 2025) - Vergelijking van verschillende platforms op Apple Silicon incl. MLX, met betrekking tot doorvoer, latentie, contextlengte.
- Benchmarken van on-device machinaal leren op Apple Silicon met MLX (Ajayi & Odunayo, 2025) - Gericht op MLX en Apple Silicon, met benchmarkgegevens tegen NVIDIA-systemen.



Veelgestelde vragen
- Wat is een lokaal taalmodel precies?
Een lokaal taalmodel is een AI die teksten kan begrijpen en genereren - vergelijkbaar met ChatGPT. Het verschil is dat het niet via het internet loopt, maar direct op je eigen computer. Alle berekeningen vinden lokaal plaats en er worden geen gegevens naar externe servers gestuurd. Dit betekent dat je volledige controle behoudt over je eigen informatie. - Welke voordelen biedt een lokale AI ten opzichte van een cloudoplossing zoals ChatGPT?
De drie grootste voordelen zijn gegevensbescherming, onafhankelijkheid en kostenbeheersing.
- Gegevensbescherming: Geen teksten verlaten de computer.
- Onafhankelijkheid: Geen internetverbinding nodig, geen verandering van provider of risico op storing.
- Kosten: Geen doorlopende kosten per aanvraag. Je betaalt één keer voor de hardware - dat is alles. - Heb je programmeerkennis nodig om een taalmodel lokaal te gebruiken?
Nee. Met moderne tools zoals Ollama of LM Studio kan een model worden gestart met slechts een paar klikken. Vandaag de dag kunnen zelfs beginners een lokale AI uitvoeren in slechts enkele minuten zonder ook maar één regel code te schrijven. - Welke Apple apparaten zijn bijzonder geschikt?
Voor beginners is een Mac Mini met M4 of M4 Pro en minstens 32 GB RAM vaak voldoende. Als je grotere modellen of meerdere tegelijk wilt gebruiken, kun je beter gaan voor een Mac Studio met 64 GB of 128 GB RAM. Een Mac Pro biedt nauwelijks voordelen, tenzij je PCI-e slots nodig hebt. Notebooks zijn geschikt, maar bereiken sneller hun thermische grenzen. - Wat is de minimale hoeveelheid RAM die je moet hebben?
Dit hangt af van de grootte van het model.
- Kleine modellen (1-3 miljard parameters): 16-32 GB is voldoende.
- Middelgrote modellen (7-13 miljard): beter 48-64 GB.
- Grote modellen (30bn+): 128 GB of meer.
Het is belangrijk om wat reserve in te plannen - anders zijn er wachttijden of annuleringen. - Wat betekent "Unified Memory" voor Apple Silicon?
Unified memory is een gedeeld geheugen dat gelijktijdig wordt benaderd door de CPU, GPU en neurale motor. Dit bespaart tijd en energie, omdat er geen gegevens tussen verschillende geheugengebieden hoeven te worden gekopieerd. Dit is een enorm voordeel, vooral voor AI-berekeningen, omdat alles in één stroom werkt. - Wat is het verschil tussen GGUF, MLX en Safetensors?
- GGUF: Een compact formaat voor lokaal gebruik (bijv. in Ollama of LM Studio). Ideaal voor inferentie, d.w.z. de uitvoering van voltooide modellen.
- MLX: Apple's eigen formaat, speciaal voor M-chips. Zeer efficiënt, maar nog jong.
- Safetensors: Een formaat uit de PyTorch-wereld, voornamelijk bedoeld voor training en onderzoek.
GGUF of MLX zijn ideaal voor lokaal gebruik op de Mac. - Waar haal je de modellen vandaan?
Het bekendste platform is huggingface.co - een enorme bibliotheek voor AI-modellen. Daar vind je varianten van LLaMA, Mistral, Gemma, Phi-3 en vele andere. Veel modellen zijn al beschikbaar in GGUF-formaat en kunnen direct in Ollama worden geladen. - Met welke tools kun je het makkelijkst aan de slag?
Om te beginnen zijn Ollama en LM Studio ideaal. Ollama draait in de terminal en is licht van gewicht. LM Studio biedt een grafische gebruikersinterface met een chatvenster. Beide laden en starten modellen automatisch en vereisen geen ingewikkelde set-up. - Kunnen taalmodellen ook worden gebruikt met FileMaker Server?
Ja - sinds FileMaker Server 2025 kunnen MLX-modellen direct worden aangesproken. Dit maakt tekstanalyses, classificaties of automatische evaluaties binnen bijvoorbeeld ERP- of CRM-systemen mogelijk. Vertrouwelijke bedrijfsgegevens kunnen zo lokaal worden verwerkt zonder dat ze naar externe leveranciers hoeven te worden gestuurd. - Hoe groot zijn zulke modellen meestal?
Kleine modellen zijn slechts enkele gigabytes groot, grote modellen kunnen 20 - 30 GB of meer hebben. Ze kunnen sterk in grootte worden teruggebracht door kwantisering (bijv. 4-bit), vaak met minimaal kwaliteitsverlies. Een gecomprimeerd 13-B model kan bijvoorbeeld slechts 7 GB in beslag nemen - perfect voor een Mac Mini M4 Pro. - Is het mogelijk om lokale modellen te trainen of aan te passen?
In principe wel, maar de training is erg rekenintensief. MLX of Python frameworks kunnen worden gebruikt voor lokale fijnafstemming van kleinere modellen. Vandaag bevat FileMaker een geïntegreerde functie om Taalmodellen direct verfijnen om dit te kunnen doen. Voor grootschalige training (bijv. 50 miljard parameters) is echter een speciale GPU-farm nodig. Voor de meeste toepassingen is het voldoende om bestaande modellen te gebruiken en deze specifiek aan te sturen via prompts. - Hoeveel stroom verbruikt een Mac tijdens AI-berekeningen?
Verrassend weinig. Een Mac Studio is vaak minder dan 100 W in vol bedrijf, terwijl een enkele NVIDIA grafische kaart (bijv. RTX 5090) tot 450 W trekt - zonder CPU en randapparatuur. Dit betekent dat lokale AI op Apple hardware niet alleen stiller is, maar ook aanzienlijk energiezuiniger. - Is een MacBook Pro geschikt voor lokale AI?
Ja, maar met beperkingen.
Hoewel de prestaties hoog zijn, is de thermische belastbaarheid beperkt. De processor geeft gas tijdens langere sessies. Een MacBook Pro M3/M4 is perfect voor korte chats, teksttaken of analyses, maar niet voor langdurig gebruik. - Hoe veilig zijn lokale modellen echt?
Net zo veilig als het systeem waarop ze draaien. Omdat er geen gegevens over het internet worden verstuurd, is er praktisch geen risico van derden. Je moet er echter wel voor zorgen dat tijdelijke bestanden, logbestanden of chatgeschiedenissen niet per ongeluk in cloudmappen terechtkomen (bijv. iCloud Drive). Lokale opslag op de interne SSD is ideaal. - Wat zijn typische fouten die beginners maken?
- Te grote modellen laden, ook al is er niet genoeg RAM.
- Gebruik oude versies van Ollama of LM Studio.
- Activeer geen GPU-versnelling (bijv. MLX).
- Er draaien te veel processen op de achtergrond.
- Modellen laden uit dubieuze bronnen.
Remedie: Gebruik alleen betrouwbare bronnen (bijv. Hugging Face) en houd systeembronnen in de gaten. - Hoe zal lokale AI-technologie zich de komende jaren ontwikkelen?
De modellen worden nog compacter en preciezer. Apple, Mistral en Meta werken al aan architecturen die minder geheugen en stroom nodig hebben voor dezelfde kwaliteit. Tegelijkertijd worden er handige interfaces ontwikkeld, zoals AI-plug-ins voor tekstverwerking, mailprogramma's of notitie-apps. Op de lange termijn zal elk professioneel systeem waarschijnlijk een soort „ingebouwde lokale AI“ hebben. - Waarom is het de moeite waard om nu te beginnen?
Want de basis voor de komende jaren wordt nu gelegd. Wie vandaag leert om lokaal een model op te starten, gegevens gestructureerd te verwerken en gerichte prompts te formuleren, kan straks zelfstandig handelen - zonder afhankelijk te zijn van dure cloudproviders. Kortom: lokale AI is de rustige, zelfverzekerde weg naar een digitale toekomst waarin je je gegevens en tools weer in eigen handen kunt houden.