
Každý, kdo dnes pracuje s umělou inteligencí, si často nejprve vybaví ChatGPT nebo podobné online služby. Zadáte otázku, počkáte několik sekund - a dostanete odpověď, jako by na druhém konci linky seděl velmi sečtělý a trpělivý partner pro dialog. Na co se však snadno zapomíná: Každý vstup, každá věta, každé slovo je odesíláno na externí servery prostřednictvím internetu. Tam se odehrává skutečná práce - na obrovských počítačích, které sami nikdy neuvidíte.
Model místního jazyka funguje v zásadě stejně, ale bez internetu. Model je uložen jako soubor na vlastním počítači uživatele, při spuštění se načte do pracovní paměti a odpovídá na otázky přímo v zařízení. Technologie, která za ním stojí, je stejná: neuronová síť, která rozumí jazyku, generuje texty a rozpoznává vzory. Jediný rozdíl je v tom, že celý výpočet zůstává ve vlastní režii. Dalo by se říct: ChatGPT bez cloudu.
Zvláštností je, že technologie se dnes vyvinula natolik, že již není závislá na obrovských datových centrech. Moderní počítače Apple s procesory M (například M3 nebo M4) mají obrovský výpočetní výkon, rychlé paměťové připojení a specializovaný neuronový engine pro strojové učení. Díky tomu lze nyní mnoho modelů provozovat přímo na počítačích Mac Mini nebo Mac Studio - bez serverové farmy, bez složitého nastavování a bez výrazného hluku.


Nejnovější zprávy o Apple MLX a NVIDIA
26.03.2026: Apple pokračuje ve strategickém rozvoji svého rámce MLX AI a stále více jej otevírá dalším platformám. Původně byl optimalizován výhradně pro Apple Silicon, MLX nyní podporuje také grafické procesory CUDA a tedy klasický hardware Nvidia. To odstraňuje klíčovou překážku pro vývojáře: dosud se modely často musely vyvíjet na Macu a poté trénovat na samostatných výkonných systémech. Otevřením se MLX stává flexibilnější vývojovou platformou, která umožňuje jak lokální AI na zařízeních Apple, tak škálovatelné trénování na externím hardwaru. Zároveň zůstává zachována výhoda úzké integrace s vlastní architekturou Apple, například díky efektivní správě paměti a přímému využití GPU. Vývoj naznačuje strategickou změnu kurzu: Apple postupně opouští svůj uzavřený ekosystém a staví MLX do pozice seriózní alternativy k zavedeným frameworkům AI - s potenciálním dopadem na vývoj AI jako celku.
To otevírá nové dveře nejen vývojářům, ale také podnikatelům, autorům, právníkům, lékařům, učitelům a řemeslníkům. Každý nyní může mít svou vlastní malou umělou inteligenci - na svém pracovním stole, plně pod kontrolou, připravenou kdykoli k použití. Místní jazykový model může:
- Texty shrnout nebo opravit,
- E-maily formulovat nebo strukturovat,
- Otázky odpovídat na otázky a analyzovat znalosti,
- Procesy podpora v programech,
- Dokumenty vyhledávat nebo klasifikovat,
- nebo jednoduše jako osobní asistent aniž by došlo k úniku dat do vnějšího světa.
Tento přístup je stále důležitější, zejména v době, kdy se do popředí zájmu opět dostává ochrana dat a digitální suverenita. Nemusíte být programátoři, abyste ho mohli používat - stačí vám moderní Mac. Modely lze jednoduše spustit prostřednictvím aplikace nebo terminálového okna a pak reagují téměř stejně přirozeně jako chatovací okno v prohlížeči.
V tomto článku se dozvíte, které modely lze dnes provozovat na kterých počítačích Mac, co je k tomu potřeba za hardware a proč jsou počítače Apple Silicon pro tento účel obzvláště vhodné. Stručně řečeno, jde o to, jak převzít výkon umělé inteligence zpět do vlastních rukou - tiše, efektivně a lokálně.
Místní jazykové modely na Macu - Proč to má smysl právě teď
Spuštění jazykového modelu „lokálně“ znamená, že je provozován výhradně na vašem počítači - bez připojení ke cloudové službě. Výpočet, analýza vstupů, generování textů nebo odpovědí - vše probíhá přímo na vašem vlastním zařízení. Model je tedy uložen jako soubor na disku SSD, při spuštění se načte do paměti RAM a tam pracuje s plným výkonem systému.
Klíčovým rozdílem oproti cloudové variantě je nezávislost. Žádná data neproudí přes internet, nepoužívají se žádné externí servery a nikdo nemůže sledovat, co se interně zpracovává. To poskytuje značnou míru ochrany a kontroly dat - zejména v době, kdy je stále obtížnější vysledovat pohyb dat.
V minulosti bylo lokální provozování takových modelů nemyslitelné. K tomu, aby neuronová síť takové velikosti vůbec běžela, bylo zapotřebí sálového počítače nebo farmy grafických procesorů. Dnes, s výpočetním výkonem moderních čipů Apple-Silicon, to lze realizovat na stolním zařízení - efektivně, tiše a s nízkou spotřebou energie.
Proč je ideální Apple Silicon
S přechodem na Apple Silicon Apple přehodila karty. Místo klasické architektury Intel s odděleným CPU a GPU sází Apple na tzv. unifikovanou paměťovou konstrukci: procesor, grafika a neurální engine přistupují do stejné rychlé hlavní paměti. Tím odpadá nutnost kopírování dat mezi jednotlivými komponentami - což je pro výpočty umělé inteligence rozhodující výhoda.
Samotný neuronový engine je specializované výpočetní jádro pro strojové učení, které je integrováno přímo v čipech. Umožňuje miliardy výpočetních operací za sekundu - s velmi nízkou spotřebou energie. Spolu s knihovnou MLX (Machine Learning for Apple Silicon) a moderními frameworky, jako je OLaMA, mohou nyní modely běžet přímo v systému macOS bez složitých ovladačů GPU nebo závislostí na CUDA.
Čip M4 v Macu Mini již postačuje k bezproblémovému běhu kompaktních jazykových modelů (např. 3-7 miliard parametrů). Na Mac Studiu s čipem M4 Max nebo M3 Ultra můžete spustit i modely s 30 miliardami parametrů - zcela lokálně.
Srovnání: Apple Silicon vs. hardware NVIDIA
Grafické karty RTX společnosti NVIDIA jsou tradičně zlatým standardem pro výpočty umělé inteligence. Například aktuální RTX 5090 nabízí obrovský hrubý výkon a stále je první volbou pro mnoho tréninkových systémů. Přesto se vyplatí podrobné srovnání - priority se totiž liší.
| Aspekt | Apple Silicon (M4 / M4 Max / M3 Ultra) | Grafický procesor NVIDIA (5090 & Co.) |
|---|---|---|
| Spotřeba energie | Velmi efektivní - obvykle méně než 100 W celkové spotřeby | Až 450 W pro samotný GPU |
| Vývoj hluku | Prakticky tichý | Zřetelně slyšitelné při zatížení |
| Zásobník softwaru | MLX / Jádro ML / Kov | CUDA / cuDNN / PyTorch |
| Údržba | Bez řidiče a stabilní | Časté aktualizace a problémy s kompatibilitou |
| Poměr cena/výkon | Vysoká účinnost za rozumnou cenu | Lepší špičkový výkon, ale dražší |
| Ideální pro | Lokální odvozování a spojité operace | Školení a velké modely |
Stručně řečeno: NVIDIA je volbou pro datová centra a extrémní školení. Apple Silicon je naproti tomu ideální pro lokální, dlouhodobé použití - bez hluku, bez zahřívání, se stabilním softwarovým základem a zvládnutelnou spotřebou energie.
Apple Silicon ve srovnání s NVIDIA pro odvozování
M3 Ultra představuje významný krok vpřed pro Apple Silicon: kromě vysoce integrovaného návrhu čipu s CPU, GPU a Neural Engine v jednom balení se spoléhá na jednotnou paměťovou architekturu, v níž je RAM využívána všemi výpočetními jednotkami současně - bez klasického oddělení RAM a GPU VRAM. Podle benchmarků již tento přístup dosahuje v úlohách lokální inference srovnatelného nebo v některých případech dokonce lepšího výkonu než špičkové grafické karty NVIDIA. Jeden z příkladů: V testu dosáhl M3 Ultra se 4bitovým modelem Qwen3-30B přibližně 2 320 tokenů/s ve srovnání s RTX 3090 s 2 157 tokeny/s.
Srovnání Apple Silicon vs. NVIDIA v zátěži AI navíc naznačuje, že systém M3/M4 Max dosáhne v zátěži přibližně 40-80 W, zatímco RTX 4090 bude obvykle odebírat až 450 W.
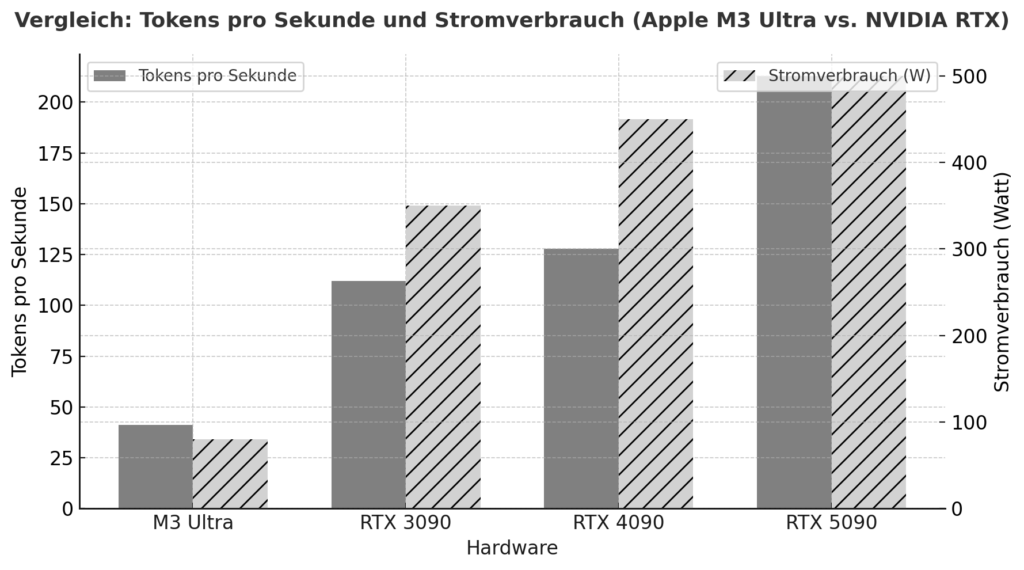
To ukazuje, že pokud se podíváte nejen na špičkový výkon, ale také na účinnost na watt, je Apple Silicon ve vynikající pozici. Na druhé straně jsou karty NVIDIA (např. 3090, 4090, 5090) s obrovskou paralelizovanou architekturou GPU, velmi vysokou hustotou CUDA/tensorových jader a specializovanými knihovnami (CUDA, cuDNN, TensorRT). Zde se často předbíhá hrubý výkon top-flops - ovšem s rozhodujícími omezeními pro modely v lokálním jazyce: dostupná paměť VRAM (např. 24-32 GB u herních karet) se rychle stává úzkým hrdlem, pokud je třeba načíst modely s 20-30 miliardami parametrů nebo více. Jedna uživatelská zpráva například uvádí, že s RTX 5090 s cca 32 GB VRAM je již obtížné pojmout model s 20-22 miliardami parametrů.
V tomto ohledu byste se měli zaměřit nejen na jádra GPU, ale také na dostupnou velikost paměti, šířku pásma a architekturu paměti. Například M3 Ultra s až 512 GB unifikované paměti (v nejvyšších konfiguracích) zde nabízí výhody v mnoha scénářích lokálního nasazení - zejména pokud modely nemají běžet v cloudu, ale trvale lokálně.
| Hardware | Model / nastavení | Tokeny za sekundu (přibližně) | Poznámka |
|---|---|---|---|
| Apple M3 Ultra (Mac Studio) | z. např. Gemma-3-27B-Q4 na M3 Ultra | ≈ 41 tok/s :contentReference[oaicite:2]{index=2} | LLM Inference, kontext 4k tokenů, kvantifikované |
| NVIDIA RTX 5090 | 8 B model (kvantifikovaný) podle studie | ≈ 213 tok/s :contentReference[oaicite:3]{index=3} | Model 8 B, 4bitový, prostředí RLHF |
| NVIDIA RTX 4090 | 8 B Odkaz na model | ≈ 128 tok/s :contentReference[oaicite:4]{index=4} | 24 GB VRAM Prostředí |
| NVIDIA RTX 3090 | Rozpočet HighEnd v porovnání | ≈ 112 tok/s :contentReference[oaicite:5]{index=5} | Trh s použitým zbožím, 24 GB VRAM |
Praktický význam: Kde mají místní jazykové modely smysl
Možnosti využití lokální umělé inteligence jsou dnes téměř neomezené. Kdykoli je třeba zachovat důvěrnost dat nebo procesy běžet v reálném čase, vyplatí se lokální verze. Příklady z praxe:
- Systémy ERPAutomatická analýza textu, návrhy, předpovědi nebo komunikační pomůcky - přímo ze softwaru.
- Výroba knih a médiíKontrola stylu, překlad, shrnutí, rozšíření textu - vše lokálně, bez závislosti na cloudu.
- Advokáti a notářiAnalýza dokumentů, návrhy písemných podání, rešerše - v rámci nejpřísnějšího utajení.
- Lékaři a terapeutiVyhodnocení případu, dokumentace nebo automatizované zprávy - aniž by údaje o pacientovi opustily systém.
- Inženýrské kanceláře a architektiPrůvodci textem, projektem a výpočty, kteří fungují i bez internetu.
- Společnost obecněSpráva znalostí, asistenti interního chatu, analýza protokolů, klasifikace e-mailů - to vše v rámci vlastní sítě.
To je velký krok, zejména v komerčním sektoru: místo placení za externí služby AI a posílání dat do cloudu můžete nyní spouštět přizpůsobené modely na vlastních strojích. Ty lze přizpůsobovat, dolaďovat a rozšiřovat o vlastní znalosti - zcela pod kontrolou.
Výsledkem je moderní, ale tradičně suverénní IT prostředí, které využívá technologie, aniž by se vzdalo suverenity nad vlastními daty. Přístup, který připomíná staré ctnosti: udržet věci ve vlastních rukou.
Aktuální průzkum místních systémů umělé inteligence
Přehled: Mac Mini a Mac Studio - co je aktuálně k dispozici
Chceme-li dnes provozovat místní jazykové modely na počítači Mac, pak jsou v centru pozornosti zejména dvě třídy stolních počítačů: Mac mini a Mac Studio.
- Mac MiniNejnovější generace nabízí čip Apple M4 nebo volitelně M4 Pro. Podle technických specifikací jsou k dispozici varianty s unifikovanou pamětí 24 GB nebo 32 GB, varianta Pro je nabízena s konfigurovatelnou unifikovanou pamětí až 48 GB nebo 64 GB. Díky tomu je Mac Mini vhodný pro mnoho aplikací - zejména pokud se nejedná o extrémně rozsáhlý model nebo pokud není třeba paralelně spouštět několik velmi rozsáhlých úloh.
- Mac StudioZde se dostáváme o krok výš. Například s čipem Apple M4 Max nebo M3 Ultra - v závislosti na modelu. U verze M4 Max je možné využít 48 GB, 64 GB nebo až 128 GB unifikované paměti. Mac Studio ve verzi M3 Ultra může být vybaveno až 512 GB unifikované paměti. Výrazně se také zvětšují velikosti SSD disků a šířka paměťového pásma. Mac Studio je tak vhodné pro náročnější modely nebo paralelní procesy.
Krátká poznámka: The Mac Pro Existuje také a často nabízí „více šasi“ nebo sloty PCI-e na vnější straně - ale pokud jde o jazykové modely, nenabízí oproti Mac Studiu pro místní verzi příliš výhod, pokud nemáte žádné další rozšiřující karty nebo speciální požadavky na PCIe.
Také Notebooky (např. MacBook Pro), ale s omezeními: Chladicí systémy jsou menší, tepelný výkon je omezenější a rozpočet na operační paměť je často nižší. Dlouhodobé využívání (jako u modelů s umělou inteligencí) může snížit výkon.

AI: Apple lepší než Nvidia! 😮 | c't 3003
Proč je paměť RAM / sjednocená paměť tak důležitá
Při lokálním běhu jazykového modelu není zapotřebí pouze výkon CPU nebo GPU - rozhodující je také paměť RAM (nebo „unifikovaná paměť“ v případě Apple). Proč?
Samotný model (váhy, aktivace, mezivýsledky) musí být uložen v paměti. Čím větší je model, tím více paměti je potřeba. Čipy Apple-Silicon využívají "unifikovanou paměť", tj. CPU, GPU a neuronový engine přistupují ke stejnému fondu paměti. Tím odpadá nutnost kopírování dat mezi jednotlivými komponentami, což zvyšuje efektivitu a rychlost.
Pokud není dostatek paměti RAM, musí se systém vyměnit nebo modely nejsou plně vytíženy - což může znamenat pokles výkonu, nestabilitu nebo zrušení. Zejména u inferenčních aplikací (generování odpovědí, zadávání textu, rozšiřování modelů) je rozhodující doba odezvy a propustnost - zde výrazně pomáhá dostatek paměti. Tradiční stolní počítač byl zvyklý uvažovat v pojmech „paměť RAM CPU“ a „samostatná paměť RAM GPU“ - u Apple Silicon je to elegantně spojeno, což činí běh jazykových modelů obzvláště atraktivním.
Odhadované hodnoty: Jaký řád je reálný?
Abyste mohli odhadnout, jaký hardware budete potřebovat, uvádíme několik hrubých orientačních hodnot:
- Pro menší modely (např. několik miliard parametrů), mohlo by stačit 16 GB až 32 GB RAM - zejména pokud se mají zpracovávat pouze jednotlivé dotazy. Mac Mini s 16/32 GB by proto byl dobrým začátkem.
- Pro střední modely (např. 3-10 miliard parametrů) nebo úlohy s několika paralelními chaty či velkým množstvím textu, měli byste zvážit 32 GB RAM nebo více - např. Mac Studio s 32 nebo 48 GB.
- Pro velké modely (>20 miliard parametrů) nebo pokud má paralelně běžet více modelů, můžete zvolit 64 GB nebo více - zde jsou možné varianty Mac mini a Mac Studio s 64 GB nebo více.
Důležité: Nezapomeňte si naplánovat určitou rezervu - nejen model, ale i provoz (např. operační systém, vstup/výstup souborů, jiné aplikace) vyžaduje paměťovou rezervu.
| Kategorie | Typická velikost modelu | Doporučený rozpočet na paměť RAM | Příklad použití |
|---|---|---|---|
| Malé | 1-3 miliardy parametrů | 16-32 GB | Jednoduchý asistent, rozpoznávání textu |
| Střední | 7-13 miliard Parametry | 32-64 GB | Chat, analýza, tvorba textu |
| Velké | 30-70 miliard parametrů | 64 GB + | Odborné texty, právní dokumenty |
Zpochybnění tradičního přístupu "server vs. desktop"
Tradičně si lidé mysleli, že umělá inteligence vyžaduje serverové farmy, spoustu grafických procesorů, hodně energie a datové centrum. Situace se však mění: stolní počítače, jako je Mac Mini nebo Mac Studio, nyní nabízejí dostatečný výkon pro mnoho lokálně provozovaných jazykových modelů - bez obrovské infrastruktury. Místo vysokých nákladů na elektřinu, náročného chlazení a složité údržby získáte tiché a výkonné zařízení na svém stole.
Samozřejmě, pokud chcete trénovat modely ve velkém měřítku nebo používat velký počet parametrů, pak mají serverová řešení stále smysl. Pro inferenci, přizpůsobení a každodenní použití však často postačuje hardware stolních počítačů. To souvisí s tradičním přístupem: používejte technologie, ale nepředimenzovávejte je - spíše je používejte cíleně a efektivně. Pokud dnes vybudujete solidní lokální základnu, vytvoříte základ pro to, co bude možné zítra.

M3 Ultra vs RTX 5090 | Finální bitva (Česky)
Technická charakteristika jazykových modelů
Jazykové modely se dnes liší nejen svými schopnostmi, ale také technickou podobou, v níž jsou k dispozici. Tyto formáty určují, jak se model ukládá, načítá a používá - a zda vůbec může v daném systému běžet.
GGUF (GPT-Generated Unified Format)
Tento formát byl vyvinut pro praktické použití v nástrojích, jako je Ollama, LM Studio nebo Llama.cpp. Je kompaktní, přenosný a vysoce optimalizovaný pro lokální odvozování. Modely GGUF jsou obvykle kvantifikované, což znamená, že spotřebují podstatně méně paměti, protože vnitřní číselné hodnoty jsou uloženy v redukované podobě (např. 4bitové nebo 8bitové). Díky tomu lze modely, které měly původně velikost 30-50 GB, zkomprimovat na 5-10 GB - a to jen s nepatrnou ztrátou kvality.
- VýhodaBěží téměř na jakémkoli systému (macOS, Windows, Linux), není potřeba žádný speciální GPU.
- NevýhodaNení určeno k tréninku nebo dolaďování - čistá inference (tj. využití).
MLX (strojové učení pro Apple Silicon)
MLX je vlastní open source framework Apple pro strojové učení na Apple Silicon. Byl vyvinut speciálně pro využití plného výkonu CPU, GPU a Neural Engine v M-Chips. Modely MLX jsou obvykle k dispozici v nativním formátu MLX nebo jsou převedeny z jiných formátů.
- VýhodaMaximální výkon a energetická účinnost na hardwaru Apple.
- NevýhodaStále relativně mladý ekosystém, méně dostupných komunitních modelů než u GGUF nebo PyTorch.
Safetensors (.safetensors)
Tento formát pochází ze světa PyTorch (a je silně propagován společností Hugging Face). Jedná se o bezpečný, binární formát pro ukládání velkých modelů, který neumožňuje spouštění kódu - odtud název „safe“.
- VýhodaVelmi rychlé načítání, úspora paměti, standardizace.
- Nevýhoda: Určeno hlavně pro frameworky jako PyTorch nebo TensorFlow - tj. častěji ve vývojářském prostředí a pro tréninkové procesy.
| Formát | Platforma | Účel | Výhody | Nevýhody |
|---|---|---|---|---|
| GGUF | macOS, Windows, Linux | Odvození | Kompaktní, rychlý, univerzální | Školení není možné |
| MLX | macOS (Apple Silicon) | Odvozování + školení | Optimalizováno pro M-Chips, vysoká účinnost | Méně dostupných modelů |
| Safetové snímače | Napříč platformami (PyTorch / TensorFlow) | Školení a výzkum | Bezpečné, standardizované, rychlé | Není přímo kompatibilní s Ollama / MLX |
Objetí tváře - hlavní zdroj zásobování
Dnes je Hugging Face něco jako "knihovna" světa umělé inteligence. Na adrese huggingface.co najdete desítky tisíc modelů, datových sad a nástrojů, z nichž mnohé jsou k dispozici zdarma. Filtrovat můžete podle názvu, architektury, typu licence nebo formátu souboru. Ať už se jedná o Mistral, LLaMA, Falcon, Gemma nebo Phi-3 - jsou zde zastoupeny téměř všechny známé modely. Řada vývojářů již nabízí verze přizpůsobené pro lokální použití s GGUF nebo MLX.
Díky tomu je Hugging Face pro většinu uživatelů první volbou, pokud chtějí vyzkoušet nějaký model nebo najít vhodnou variantu pro macOS.

Typické modely a oblasti jejich použití
Počet dostupných modelů je nyní téměř nemožné sledovat. Přesto existuje několik hlavních rodin, které se pro místní použití obzvláště osvědčily:
- Rodina LLaMA (Meta): Jeden z nejznámějších modelů open source. Tvoří základ pro nespočet derivátů (např. Vicuna, WizardLM, Open-Hermes). Silné stránky: Porozumění jazyku, dialog, všestranné použití. Oblast použití: Obecné chatovací aplikace, generování obsahu, asistenční systémy.
- Mistral & Mixtral (Mistral AI)Známý vysokou účinností a dobrou kvalitou při malé velikosti modelu. Mixtral 8x7B kombinuje několik expertních modelů (architektura Mixture-of-Experts). Silné stránky: Rychlé a přesné odpovědi, úspora zdrojů. Oblast použití: Interní asistenti společnosti, analýza textu, příprava dat.
- Phi-3 (Microsoft Research)Kompaktní model optimalizovaný pro vysokou kvalitu hlasu navzdory nízkému počtu parametrů. Silné stránky: Efektivita, dobrá gramatika, strukturované odpovědi. Oblast použití: Menší systémy, lokální znalostní modely, integrovaní asistenti.
- Gemma (Google): Zveřejněno společností Google Research jako otevřený model. Vhodný pro shrnující a vysvětlující úlohy. Silné stránky: Soudržnost, vysvětlení v souvislostech. Oblast použití: Zpracování znalostí, školení, poradenské systémy.
- Modely GPT-OSS / OpenHermesSpolu s modifikacemi LLaMA tvoří "most" mezi modely s otevřeným zdrojovým kódem a funkčním rozsahem komerčních systémů. Silné stránky: Široká jazyková základna, flexibilní použití. Oblast použití: Tvorba obsahu, chatové a analytické úlohy, interní asistence AI.
- Claude / Command R / Falcon / Yi / ZephyrTyto a mnohé další modely (většinou z výzkumných projektů nebo otevřených komunit) nabízejí speciální funkce, jako je vyhledávání znalostí, generování kódu nebo vícejazyčnost.
Nejdůležitější je, že žádný model nemůže dělat všechno dokonale. Každý z nich má své silné a slabé stránky - a v závislosti na použití se vyplatí provést cílené srovnání.
Který model je vhodný pro jaký účel?
Pro realistické posouzení lze modely zhruba rozdělit do výkonnostních a aplikačních tříd:
Pro většinu realistických desktopových aplikací - jako jsou souhrny, korespondence, překlady, analýzy - jsou střední modely (7-13 B) jsou zcela dostačující. Poskytují úžasně dobré výsledky, běží hladce na Mac Mini M4 Pro s 32-48 GB RAM a nevyžadují téměř žádné úpravy.
Velké modely ukázat své silné stránky, když je důležité hlubší porozumění nebo delší souvislosti - například při zpracování právních textů nebo technické dokumentace. Měli byste však mít alespoň jeden Mac Studio s kapacitou 64-128 GB Používejte pracovní paměť.
| Modelová řada | Původ | Silné stránky | Oblast použití |
|---|---|---|---|
| LLaMA | Meta | Porozumění jazyku, dialog | Obecné chatovací aplikace |
| Mistral / Mixtral | Mistral AI | Efektivita, vysoká přesnost | Asistenti společnosti, analýza |
| Phi-3 | Microsoft Research | Kompaktní, jazykově silný | Malé systémy, místní UI |
| Gemma | Výzkum Google | Soudržnost, vysvětlitelnost | Poradenství, výuka, výklad textu |
Možnosti lokálního provozování jazykových modelů
Chcete-li dnes používat jazykový model na vlastním Macu, existuje několik použitelných možností - v závislosti na vašich technických požadavcích a požadovaném účelu. Skvělé je, že pro začátek již nepotřebujete složité vývojové prostředí.
Ollama - nekomplikovaný start
Ollama se rychle stala standardním nástrojem pro místní modely umělé inteligence. Běží nativně v systému macOS, optimálně využívá výkon Apple Silicon a umožňuje spustit model jediným příkazem:
ollama run mistral
Tím se automaticky načte a připraví požadovaný model, který je pak k dispozici v terminálu nebo prostřednictvím místních rozhraní. Ollama podporuje formát GGUF, umožňuje stahování modelů z Hugging Face a lze jej integrovat prostřednictvím rozhraní REST API nebo přímo do jiných programů.
Jak pracovat s Ollama místní jazykový model installiert a další možnosti, které s ním máte, jsou podrobně popsány v jiném článku. K dispozici jsou také další články o tom, jak používat Qdrant flexibilní paměť pro svou místní umělou inteligenci.
LM Studio - grafické uživatelské rozhraní a správa
LM Studio je určen všem, kteří dávají přednost grafickému uživatelskému rozhraní. Nabízí stahování modelů, okna chatu, ovládání teploty, systémové výzvy a správu paměti v jedné aplikaci. To je ideální zejména pro začátečníky: můžete zkoušet, porovnávat, ukládat a přepínat mezi různými modely, aniž byste museli pracovat s příkazovým řádkem. Software běží stabilně na Apple Silicon a podporuje také modely GGUF.
MLX / Python - pro vývojáře a integrátory
Pokud chcete jít hlouběji nebo integrovat modely do vlastních programů, můžete použít rámec MLX společnosti Apple. Ten umožňuje vkládat modely přímo do aplikací Python nebo Swift. Výhoda spočívá v maximální kontrole a integraci do stávajících pracovních postupů - například pokud chce společnost přidat funkce AI do svého vlastního softwaru.
FileMaker Server 2025 - Umělá inteligence v podnikovém kontextu
Vzhledem k tomu, že FileMaker Server 2025 Jazykové modely založené na MLX lze řešit také na straně serveru. Díky tomu je poprvé možné vybavit centrální podnikovou aplikaci (např. systém ERP nebo CRM) vlastní lokální umělou inteligencí. Například lze automaticky klasifikovat tikety podpory, vyhodnocovat dotazy zákazníků nebo analyzovat obsah dokumentů - aniž by data opustila firmu.
To je zajímavé zejména pro odvětví, která mají přísné požadavky na ochranu údajů nebo dodržování předpisů (medicína, právo, administrativa, průmysl).
Typické překážky a jak se jim vyhnout
I když je vstupní překážka nízká, měli byste si uvědomit několik bodů:
Omezení paměti: Pokud je model příliš velký na dostupnou paměť, vůbec se nespustí nebo bude velmi pomalý. Zde může pomoci kvantifikace (např. 4bitová) nebo menší model.
- Výpočet zatížení a vývoje tepla: Mac se může při delších sezeních znatelně zahřát. Doporučuje se dobré větrání a sledování displeje aktivity.
- Chybějící podpora GPU pro software třetích stranNěkteré starší nástroje nebo porty nevyužívají Neural Engine efektivně. V takových případech může MLX poskytovat lepší výsledky.
- Síťové porty a právaPokud má ke stejnému modelu přistupovat více klientů (např. v rámci podnikové sítě), je třeba uvolnit místní porty - nejlépe zabezpečené prostřednictvím protokolu HTTPS nebo interního proxy serveru.
- Zabezpečení datI když modely běží lokálně, citlivé texty by neměly být ukládány v nezabezpečených prostředích. Místní protokoly a protokoly chatu se snadno zapomenou, ale často obsahují cenné informace.
Pokud věnujete pozornost těmto bodům, můžete provozovat výkonný místní systém umělé inteligence, který pracuje bezpečně, tiše a efektivně s překvapivě malým úsilím.
Časová osa a strategické úvahy
Jsme teprve na začátku vývoje, který v příštích letech změní každodenní život mnoha profesí. Lokální modely umělé inteligence budou stále menší, rychlejší a efektivnější, přičemž jejich kvalita se bude stále zlepšovat. To, co dnes ještě vyžaduje 30 GB paměti, může za rok vyžadovat jen 10 GB - při stejné kvalitě hlasu. Zároveň se objevují nová rozhraní, která lze využít k integraci modelů přímo do programů Office, prohlížečů nebo firemního softwaru.
Společnosti, které dnes učiní krok směrem k místní infrastruktuře umělé inteligence, si vytvářejí náskok. Vybudují si odborné znalosti, zajistí si datovou suverenitu a stanou se nezávislými na cenových výkyvech nebo omezeních používání ze strany externích poskytovatelů. Rozumná strategie by mohla vypadat následovně:
- Nejprve proveďte experiment s malým modelem (např. 3-7 miliard parametrů, prostřednictvím Ollama nebo LM Studia).
- Pak konkrétně zkontrolujte, které úlohy lze automatizovat.
- V případě potřeby integrujte větší modely nebo zřiďte centrální Mac Studio jako "server umělé inteligence".
- Ve střednědobém horizontu reorganizujte interní procesy (např. dokumentace, analýza textů, komunikace) s podporou AI.
Tento postupný přístup je nejen ekonomicky smysluplný, ale také udržitelný - řídí se zásadou zavádění technologií vlastním tempem, nikoli podle trendů.
V samostatném článku jsem podrobně popsal, jak se novější Formát MLX ve srovnání s formátem GGUF prostřednictvím Ollama v počítači Mac.
Místní umělá inteligence jako tichá cesta k digitální suverenitě
Místní jazykové modely znamenají návrat k sebeurčení v digitálním světě.
Místo odesílání dat a nápadů do vzdálených cloudových datových center můžete nyní opět pracovat s vlastními nástroji - přímo na svém stole a pod vlastní kontrolou.
Na Mac Mini, Mac Studiu nebo výkonném notebooku - pokud máte správný hardware, můžete nyní používat, trénovat a dále rozvíjet vlastní umělou inteligenci. Ať už jako osobní asistent, jako součást systému ERP, jako pomůcka pro výzkum v nakladatelství nebo jako řešení pro ochranu dat v právnické firmě - možnosti jsou překvapivě široké.
A to nejlepší na tom je, že nám připomíná starou sílu počítače - totiž to, že je to nástroj, který sami ovládáte, a ne služba, která nám diktuje, jak máme pracovat. Díky tomu je místní AI symbolem moderní autonomie - tichá, efektivní a přitom s působivým efektem.
Místní umělá inteligence ve firmě rozvíjí svou hodnotu se správným systémovým základem
 Diskuse o místní umělé inteligenci se často soustředí na hardware, modely a rychlost, ale skutečné výhody se projeví až při interakci s vlastními daty a procesy. Pokud chcete umělou inteligenci skutečně smysluplně využívat, potřebujete stabilní, kontrolované prostředí, ve kterém nejsou informace rozptýlené, ale jsou k dispozici ve strukturované podobě. Právě v tomto případě je lokálně provozované řešení ERP Tvoří páteř pro data, procesy a korelace v rámci společnosti. V kombinaci s řešením, jako je gFM Business ERP, tak vzniká uzavřená smyčka, v níž místní AI nejen poskytuje odpovědi, ale také pracuje kontextuálně - například integrací vlastního znalostního grafu. Rozhodnutí pak již nejsou založena na obecných modelech, ale na skutečných podnikových datech. Výsledkem je nenápadný, ale účinný krok ke skutečné digitální suverenitě: větší kontrola, větší efektivita a systém, který se přizpůsobuje firmě - nikoli naopak.
Diskuse o místní umělé inteligenci se často soustředí na hardware, modely a rychlost, ale skutečné výhody se projeví až při interakci s vlastními daty a procesy. Pokud chcete umělou inteligenci skutečně smysluplně využívat, potřebujete stabilní, kontrolované prostředí, ve kterém nejsou informace rozptýlené, ale jsou k dispozici ve strukturované podobě. Právě v tomto případě je lokálně provozované řešení ERP Tvoří páteř pro data, procesy a korelace v rámci společnosti. V kombinaci s řešením, jako je gFM Business ERP, tak vzniká uzavřená smyčka, v níž místní AI nejen poskytuje odpovědi, ale také pracuje kontextuálně - například integrací vlastního znalostního grafu. Rozhodnutí pak již nejsou založena na obecných modelech, ale na skutečných podnikových datech. Výsledkem je nenápadný, ale účinný krok ke skutečné digitální suverenitě: větší kontrola, větší efektivita a systém, který se přizpůsobuje firmě - nikoli naopak.
Doporučené zdroje
- Profilování odvozování velkého jazykového modelu na Apple SiliconA Quantisation Perspective (Benazir & Lin et al., 2025) - podrobně zkoumá výkon inference na Apple Silicon ve srovnání s grafickými procesory NVIDIA, konkrétně se zaměřením na kvantifikaci.
- Místní odvozování LLM na úrovni výroby na Apple Silicon: Srovnávací studie MLX, MLC-LLM, Ollama, llama.cpp a PyTorch MPS (Rajesh et al., 2025) - Srovnání různých platforem na Apple Silicon včetně MLX s ohledem na propustnost, latenci a délku kontextu.
- Srovnávací testování strojového učení na zařízení Apple Silicon s MLX (Ajayi & Odunayo, 2025) - Zaměřeno na MLX a Apple Silicon, se srovnávacími daty se systémy NVIDIA.




Často kladené otázky
- Co přesně je místní jazykový model?
Model místního jazyka je umělá inteligence, která dokáže porozumět textům a generovat je - podobně jako ChatGPT. Rozdíl je v tom, že neběží přes internet, ale přímo na vašem počítači. Všechny výpočty probíhají lokálně a žádná data se neodesílají na externí servery. To znamená, že si zachováváte plnou kontrolu nad vlastními informacemi. - Jaké výhody nabízí lokální UI oproti cloudovému řešení, jako je ChatGPT?
Tři největší výhody jsou ochrana dat, nezávislost a kontrola nákladů.
- Ochrana dat: Žádné texty neopouštějí počítač.
- Nezávislost: Není nutné připojení k internetu, žádná změna poskytovatele ani riziko selhání.
- Náklady: Žádné průběžné poplatky za dotaz. Jednou zaplatíte za hardware - to je vše. - Potřebujete k lokálnímu používání jazykového modelu programátorské dovednosti?
Ne. S moderními nástroji, jako je Ollama nebo LM Studio, lze model spustit na několik kliknutí. I začátečníci dnes mohou spustit lokální UI během několika minut, aniž by napsali jediný řádek kódu. - Která zařízení Apple jsou obzvláště vhodná?
Začátečníkům často stačí Mac Mini s M4 nebo M4 Pro a alespoň 32 GB RAM. Pokud chcete používat větší modely nebo několik modelů najednou, je lepší zvolit Mac Studio s 64 GB nebo 128 GB RAM. Mac Pro nenabízí téměř žádné výhody, pokud nepotřebujete sloty PCI-e. Notebooky jsou vhodné, ale rychleji dosahují svých tepelných limitů. - Jaké je minimální množství paměti RAM, které byste měli mít?
To závisí na velikosti modelu.
- Malé modely (1-3 miliardy parametrů): stačí 16-32 GB.
- Střední modely (7-13 miliard): lepší 48-64 GB.
- Velké modely (nad 30 miliard): 128 GB nebo více.
Je důležité naplánovat si určitou rezervu - jinak se budou tvořit čekací doby nebo se bude muset letadlo zrušit. - Co znamená "Unified Memory" pro Apple Silicon?
Sjednocená paměť je sdílená paměť, ke které přistupují současně CPU, GPU a neuronový engine. To šetří čas a energii, protože není třeba kopírovat data mezi různými oblastmi paměti. To je obrovská výhoda zejména pro výpočty umělé inteligence, protože vše funguje v jednom toku. - Jaký je rozdíl mezi GGUF, MLX a Safetensors?
- GGUF: Kompaktní formát pro místní použití (např. v Ollama nebo LM Studiu). Ideální pro inferenci, tj. provádění hotových modelů.
- MLX: vlastní formát Apple, zejména pro čipy M. Velmi efektivní, ale stále mladý.
- Safetensors: Formát ze světa PyTorch, určený především pro školení a výzkum.
GGUF nebo MLX jsou ideální pro místní použití na Macu. - Odkud máte modely?
Nejznámější platformou je huggingface.co - obrovská knihovna modelů umělé inteligence. Najdete zde varianty LLaMA, Mistral, Gemma, Phi-3 a mnoho dalších. Mnoho modelů je již k dispozici ve formátu GGUF a lze je načíst přímo do Ollama. - S jakými nástroji je nejjednodušší začít?
Pro začátek jsou ideální Ollama a LM Studio. Ollama běží v terminálu a je lehký. LM Studio nabízí grafické uživatelské rozhraní s oknem chatu. Oba programy načítají a spouštějí modely automaticky a nevyžadují žádné složité nastavování. - Lze jazykové modely používat také se serverem FileMaker?
Ano - od verze FileMaker Server 2025 lze modely MLX adresovat přímo. To umožňuje například textové analýzy, klasifikace nebo automatické vyhodnocování v rámci systémů ERP nebo CRM. Důvěrná obchodní data tak lze zpracovávat lokálně, aniž by bylo nutné je posílat externím poskytovatelům. - Jak velké jsou takové modely obvykle?
Malé modely mají jen několik gigabajtů, velké mohou mít 20 - 30 GB a více. Jejich velikost lze výrazně zmenšit kvantifikací (např. 4bitovou), často s minimální ztrátou kvality. Například komprimovaný 13-B model může zabírat pouze 7 GB - ideální pro Mac Mini M4 Pro. - Je možné trénovat nebo přizpůsobovat místní modely?
V podstatě ano - ale trénink je velmi náročný na výpočetní výkon. Pro lokální doladění menších modelů lze použít rámce MLX nebo Python. V současné době obsahuje FileMaker integrovanou funkci pro Přímé doladění jazykových modelů aby to bylo možné. Pro rozsáhlé trénování (např. 50 miliard parametrů) by však byla nutná specializovaná farma GPU. Pro většinu aplikací stačí použít stávající modely a ovládat je specificky pomocí výzev. - Kolik energie spotřebuje Mac při výpočtech umělé inteligence?
Překvapivě málo. Mac Studio má v plném provozu často spotřebu pod 100 W, zatímco jedna grafická karta NVIDIA (např. RTX 5090) odebírá až 450 W - bez procesoru a periferií. To znamená, že místní UI na hardwaru Apple je nejen tišší, ale také výrazně energeticky úspornější. - Je MacBook Pro vhodný pro místní umělou inteligenci?
Ano, ale s omezeními.
Přestože je výkon vysoký, tepelná zatížitelnost je omezená. Procesor se při delších sezeních škrtil. MacBook Pro M3/M4 je ideální pro krátké konverzace, textové úlohy nebo analýzy - ne však pro dlouhodobé používání. - Jak bezpečné jsou místní modely?
Stejně bezpečné jako systém, na kterém jsou spuštěny. Protože se žádná data neodesílají přes internet, prakticky nehrozí žádné riziko ze strany třetích stran. Měli byste se však ujistit, že dočasné soubory, protokoly nebo historie chatu náhodou neskončí v cloudových složkách (např. iCloud Drive). Ideální je místní úložiště na interním disku SSD. - Jaké jsou typické chyby začátečníků?
- Načítání příliš velkých modelů, přestože není k dispozici dostatek paměti RAM.
- Použijte starší verze programu Ollama nebo LM Studio.
- Neaktivujte akceleraci GPU (např. MLX).
- Příliš mnoho procesů spuštěných na pozadí.
- Načítání modelů z pochybných zdrojů.
Náprava: Používejte pouze důvěryhodné zdroje (např. Hugging Face) a sledujte systémové prostředky. - Jak se bude v příštích letech vyvíjet místní technologie umělé inteligence?
Modely jsou stále kompaktnější a přesnější. Společnosti Apple, Mistral a Meta již pracují na architekturách, které při stejné kvalitě vyžadují méně paměti a energie. Současně se vyvíjejí pohodlná rozhraní - například zásuvné moduly AI pro textové editory, poštovní programy nebo aplikace pro poznámky. V dlouhodobém horizontu bude mít pravděpodobně každý profesionální systém jakousi „vestavěnou lokální AI“. - Proč se vyplatí začít právě teď?
Protože základy pro nadcházející roky se vytvářejí právě teď. Každý, kdo se dnes naučí lokálně spouštět model, strukturovaně zpracovávat data a cíleně formulovat podněty, bude později schopen jednat samostatně - aniž by se musel spoléhat na drahé poskytovatele cloudových služeb. Stručně řečeno: lokální umělá inteligence je klidná a jistá cesta k digitální budoucnosti, v níž můžete mít svá data a nástroje opět ve vlastních rukou.



