
Lorsqu'on travaille aujourd'hui avec l'intelligence artificielle, on pense souvent en premier lieu à ChatGPT ou à d'autres services en ligne similaires. On tape une question, on attend quelques secondes - et on obtient une réponse, comme si un interlocuteur très instruit et patient était assis à l'autre bout du fil. Mais ce que l'on oublie facilement : Chaque saisie, chaque phrase, chaque mot est transmis par Internet à des serveurs étrangers. C'est là que le véritable travail est effectué - sur d'énormes ordinateurs que l'on ne voit jamais soi-même.
Un modèle linguistique local fonctionne en principe de la même manière - mais sans Internet. Le modèle se trouve sous forme de fichier sur l'ordinateur personnel, est chargé dans la mémoire vive au démarrage et répond aux questions directement sur l'appareil. La technique sous-jacente est la même : un réseau neuronal qui comprend la langue, génère des textes et reconnaît des modèles. Sauf que tout le calcul reste en interne. On pourrait dire : ChatGPT sans cloud.
La particularité de cette technologie est qu'elle s'est entre-temps développée au point de ne plus dépendre d'énormes centres de calcul. Les ordinateurs Apple modernes équipés de processeurs M (comme le M3 ou le M4) disposent d'une énorme puissance de calcul, d'une connexion mémoire rapide et d'un moteur neuronal spécialisé pour l'apprentissage automatique. Cela permet aujourd'hui d'exploiter de nombreux modèles directement sur un Mac Mini ou un Mac Studio, sans ferme de serveurs, sans installation compliquée et sans bruit notable.


Dernières nouvelles sur Apple MLX et NVIDIA
26.03.2026Apple fait progresser stratégiquement son framework d'IA MLX et l'ouvre de plus en plus à d'autres plateformes. Optimisé à l'origine exclusivement pour Apple Silicon, MLX supporte désormais les GPU CUDA et donc du matériel Nvidia classique. Un obstacle central pour les développeurs disparaît ainsi : jusqu'à présent, les modèles devaient souvent être développés sur le Mac et ensuite entraînés sur des systèmes séparés à haute performance. Grâce à cette ouverture, MLX devient une plateforme de développement plus flexible, permettant à la fois l'IA locale sur les appareils Apple et l'entraînement évolutif sur du matériel externe. En même temps, l'avantage d'une intégration étroite avec l'architecture propre de Apple est maintenu, par exemple grâce à une gestion efficace de la mémoire et à une utilisation directe du GPU. Cette évolution indique un changement de cap stratégique : Apple quitte progressivement son écosystème fermé et positionne MLX comme une alternative sérieuse aux frameworks d'IA établis - avec des répercussions potentielles sur l'ensemble du développement de l'IA.
Une nouvelle porte s'ouvre ainsi, non seulement pour les développeurs, mais aussi pour les entrepreneurs, les auteurs, les avocats, les médecins, les enseignants ou les entreprises artisanales. Chacun peut désormais posséder sa propre petite IA - sur son bureau, sous contrôle total, prête à être utilisée à tout moment. Un modèle linguistique local peut :
- Textes résumer ou corriger,
- E-mails formuler ou structurer,
- Questions répondre à des questions et évaluer des connaissances,
- Processus dans les programmes,
- Documents rechercher ou classer,
- ou simplement comme assistant personnel sans que les données ne soient jamais transmises à l'extérieur.
C'est précisément à une époque où la protection des données et la souveraineté numérique reviennent au premier plan que cette approche gagne en importance. Il n'est pas nécessaire d'être un programmeur pour l'utiliser - un Mac moderne suffit. Les modèles peuvent être simplement lancés via une application ou une fenêtre de terminal et réagissent ensuite presque aussi naturellement qu'une fenêtre de chat dans le navigateur.
Cet article montre quels modèles peuvent aujourd'hui être exploités de manière judicieuse sur quel Mac, ce que le matériel doit être capable de faire et pourquoi les ordinateurs Apple Silicon sont particulièrement adaptés à cet effet. En bref, il s'agit de savoir comment reprendre en main le pouvoir de l'IA - silencieusement, efficacement et localement.
Modèles linguistiques locaux sur Mac - Pourquoi c'est désormais utile ?
Exécuter un modèle linguistique „localement“ signifie qu'il est entièrement exploité sur son propre ordinateur - sans connexion à un service en nuage. Le calcul, l'analyse des entrées, la génération de textes ou de réponses - tout se fait directement sur la propre machine. Le modèle se trouve donc sous forme de fichier sur le SSD, est chargé dans la mémoire vive au démarrage et y travaille avec toute la puissance du système.
La différence décisive avec la variante cloud est l'indépendance. Aucune donnée ne circule sur Internet, aucun serveur externe n'est sollicité et personne ne peut comprendre ce qui est traité en interne. Cela apporte un degré considérable de protection des données et de contrôle - surtout à une époque où les mouvements de données sont de plus en plus difficiles à suivre.
Auparavant, l'exécution locale de tels modèles était impensable. Il fallait un ordinateur central ou une ferme de GPU pour faire fonctionner un réseau neuronal de cette taille. Aujourd'hui, avec la puissance de calcul des puces modernes Apple-Silicon, cela peut être réalisé sur un appareil de bureau - de manière efficace, silencieuse et avec une faible consommation d'énergie.
Pourquoi le Apple Silicon est idéal ?
En passant à Apple Silicon, Apple a redistribué les cartes. Au lieu de l'architecture Intel classique avec CPU et GPU séparés, Apple mise sur une conception dite de mémoire unifiée : le processeur, le graphique et le moteur neuronal accèdent à la même mémoire vive rapide. Il n'y a donc pas de copies de données entre les différents composants - un avantage décisif pour les calculs d'IA.
Le moteur neuronal lui-même est un noyau de calcul spécialisé pour l'apprentissage automatique, directement intégré dans les puces. Il permet des milliards d'opérations de calcul par seconde - avec une très faible consommation d'énergie. Avec la bibliothèque MLX (Machine Learning for Apple Silicon) et des frameworks modernes comme OLaMA, les modèles peuvent aujourd'hui fonctionner directement sur macOS, sans pilotes GPU coûteux ou dépendances CUDA.
Une puce M4 dans un Mac Mini suffit déjà pour exécuter de manière fluide des modèles vocaux compacts (p. ex. 3-7 milliards de paramètres). Sur un Mac Studio équipé d'un M4 Max ou d'un M3 Ultra, il est même possible d'exécuter des modèles avec 30 milliards de paramètres - de manière totalement locale.
Comparaison : Apple Silicon vs. matériel NVIDIA
Traditionnellement, NVIDIA est considéré comme l'étalon-or pour les calculs d'IA avec ses cartes graphiques RTX. Une RTX 5090 actuelle, par exemple, offre une énorme puissance brute et reste le premier choix pour de nombreux systèmes d'entraînement. Néanmoins, il vaut la peine de comparer en détail - car les priorités diffèrent.
| Aspect | Apple Silicon (M4 / M4 Max / M3 Ultra) | GPU NVIDIA (5090 & Co.) |
|---|---|---|
| Consommation d'énergie | Très efficace - généralement moins de 100 W de consommation totale | Jusqu'à 450 W pour le seul GPU |
| Niveau sonore | Pratiquement silencieux | Nettement audible en charge |
| Pile logicielle | MLX / Core ML / Métal | CUDA / cuDNN / PyTorch |
| Entretien | Peu de pilote et stable | Mises à jour fréquentes et questions de compatibilité |
| Rapport qualité-prix | Une grande efficacité à un prix modéré | Meilleures performances de pointe, mais plus chères |
| Idéal pour | Inférence locale et fonctionnement continu | Entraînement et grands modèles |
En bref, NVIDIA est le choix par excellence pour les centres de données et l'entraînement extrême. Apple Silicon, en revanche, convient parfaitement à une utilisation locale et durable - sans bruit, sans accumulation de chaleur, avec une base logicielle stable et une consommation électrique gérable.
Apple Silicon en comparaison avec NVIDIA pour l'inférence
Le M3 Ultra marque un pas en avant significatif pour Apple Silicon : en plus d'une conception de puce hautement intégrée avec CPU, GPU et Neural Engine dans un seul package, elle mise sur une architecture de mémoire unifiée, dans laquelle la mémoire vive est utilisée simultanément par toutes les unités de calcul - sans séparation classique entre RAM et VRAM du GPU. Selon les benchmarks, cette approche atteint déjà dans certains cas une performance comparable ou même meilleure que les cartes graphiques haut de gamme de NVIDIA pour les tâches d'inférence locale. En voici un exemple : Lors du test, la M3 Ultra a atteint environ 2 320 tokens/s sur un modèle Qwen3-30B-4bit, contre 2 157 tokens/s pour la RTX 3090.
De plus, une comparaison entre Apple Silicon vs NVIDIA pour les charges d'IA indique qu'un système M3/M4 Max atteint une consommation d'environ 40-80 W en charge, alors qu'une RTX 4090 tire généralement jusqu'à 450 W.
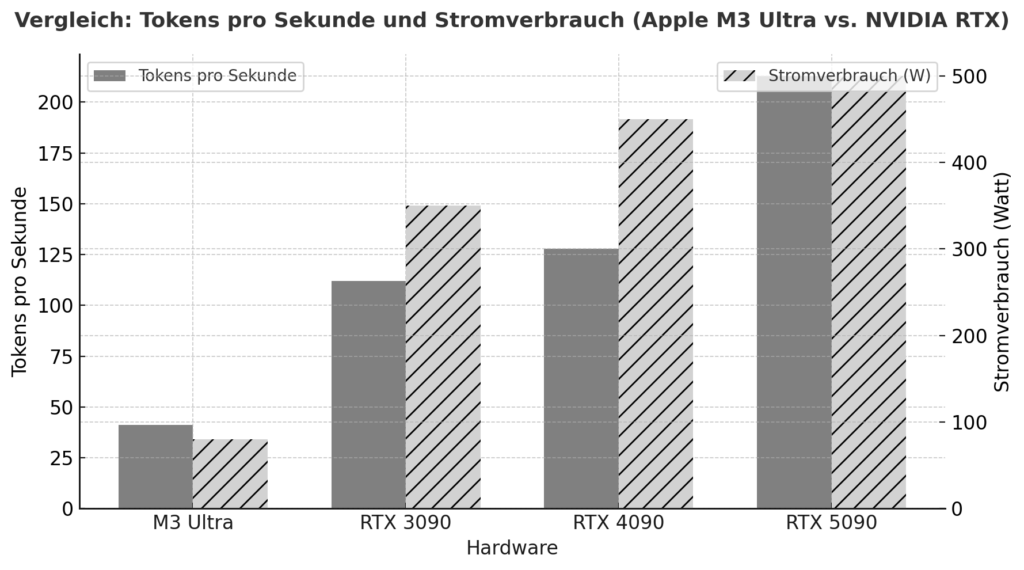
Cela montre que si l'on ne considère pas seulement la performance de pointe, mais aussi l'efficacité par watt, la Apple Silicon est en excellente position. De l'autre côté, on trouve les cartes NVIDIA (par ex. 3090, 4090, 5090) avec leur énorme architecture GPU parallélisée, leur très haute densité de cœurs CUDA/Tensor et leurs bibliothèques spécialisées (CUDA, cuDNN, TensorRT). Là, la performance Flops brute de pointe est souvent en tête - avec toutefois des restrictions décisives pour les modèles linguistiques locaux : la VRAM disponible (par exemple 24-32 Go pour les cartes de jeu) devient rapidement un goulot d'étranglement lorsque des modèles avec 20-30 milliards de paramètres ou plus doivent être chargés. Un rapport d'utilisateur indique par exemple qu'avec une RTX 5090 et environ 32 Go de VRAM, il est déjà difficile de loger un modèle avec 20-22 milliards de paramètres.
À cet égard, il ne faut donc pas seulement regarder les cœurs de GPU, mais aussi la taille de mémoire disponible, la bande passante et l'architecture de mémoire. Le M3 Ultra, avec par exemple jusqu'à 512 Go de mémoire unifiée (dans les configurations haut de gamme), offre ici des avantages dans de nombreux scénarios d'utilisation locale - en particulier lorsque les modèles ne doivent pas être exécutés dans le cloud, mais en local de manière permanente.
| Matériel informatique | Modèle / Configuration | Tokens par seconde (environ) | Remarque |
|---|---|---|---|
| Apple M3 Ultra (Mac Studio) | z. par ex. Gemma-3-27B-Q4 sur M3 Ultra | ≈ 41 tok/s :contentReference[oaicite:2]{index=2} | Inférence LLM, contexte jetons 4k, quantifiés |
| NVIDIA RTX 5090 | 8 B Modèle (Quantized) selon l'étude | ≈ 213 tok/s :contentReference[oaicite:3]{index=3} | Modèle 8 B, 4 bits, environnement RLHF |
| NVIDIA RTX 4090 | 8 B Modèle de référence | ≈ 128 tok/s :contentReference[oaicite:4]{index=4} | 24 Go de VRAM Environnement |
| NVIDIA RTX 3090 | Comparaison des hauts-de-gamme à petit budget | ≈ 112 tok/s :contentReference[oaicite:5]{index=5} | Marché de l'occasion, 24 Go de VRAM |
Lien avec la pratique : quand les modèles linguistiques locaux sont utiles
Les possibilités d'utilisation de l'IA locale sont aujourd'hui presque illimitées. Chaque fois que les données doivent rester confidentielles ou que les processus doivent se dérouler en temps réel, la variante locale vaut la peine. Exemples tirés de la pratique :
- Systèmes ERP: analyse automatique de textes, suggestions, prévisions ou aides à la communication - directement à partir du logiciel.
- Production de livres et de médias: vérification du style, traduction, résumé, enrichissement du texte - le tout en local, sans dépendance au cloud.
- Avocats et notairesAnalyse de documents, projets de mémoires, recherche - dans la plus stricte confidentialité.
- Médecins et thérapeutesLes données des patients ne quittent jamais le système.
- Bureaux d'ingénieurs et architectes: Assistants de texte, de projet et de calcul qui fonctionnent également sans Internet.
- Entreprises en général: gestion des connaissances, assistants de chat interne, évaluation des protocoles, classification des e-mails - le tout sur son propre réseau.
Au lieu de payer des services d'IA externes et d'envoyer des données dans le cloud, il est désormais possible d'exploiter des modèles sur mesure sur ses propres machines. Ceux-ci peuvent être adaptés, affinés et étendus avec des connaissances propres à l'entreprise - entièrement sous contrôle.
Il en résulte un paysage informatique moderne, mais traditionnellement souverain, qui utilise la technologie sans renoncer à la souveraineté sur ses propres données. Une approche qui rappelle les anciennes vertus : garder les choses en main.
Dernière enquête sur les systèmes d'IA locaux
Aperçu de la situation : Mac Mini et Mac Studio - ce qui est actuellement disponible
Si nous voulons aujourd'hui faire fonctionner des modèles linguistiques locaux sur un Mac, deux classes de bureau sont particulièrement visées : le Mac mini et le Mac Studio.
- Mac MiniLa dernière génération propose la puce Apple M4 ou, en option, la puce M4 Pro. Selon les spécifications techniques, des variantes avec 24 Go ou 32 Go de mémoire unifiée sont disponibles ; la variante Pro est proposée configurable avec jusqu'à 48 Go ou 64 Go de mémoire unifiée. Le Mac Mini est donc bien adapté à de nombreuses applications - surtout si le modèle n'est pas extrêmement grand ou si plusieurs tâches très importantes ne doivent pas être exécutées en parallèle.
- Mac Studio: Ici, on monte d'un cran. Équipé par exemple de la puce Apple M4 Max ou de la puce M3 Ultra - selon le modèle. Pour la version M4 Max, 48 Go, 64 Go ou jusqu'à 128 Go de mémoire unifiée sont possibles. En tant que M3 Ultra, le Mac Studio peut être équipé de jusqu'à 512 Go de mémoire unifiée. Les tailles de SSD et les largeurs de bande de mémoire augmentent également considérablement. Le Mac Studio est ainsi adapté à des modèles plus exigeants ou à des processus parallèles.
En guise de brève remarque, le Mac Pro existe également et offre souvent en apparence „plus de boîtier“ ou des slots PCI-e - mais en ce qui concerne les modèles linguistiques, il n'apporte pas un grand avantage par rapport au Mac Studio pour l'exécution locale si l'on n'a pas de cartes d'extension supplémentaires ou de besoins PCIe spécifiques.
Aussi Ordinateurs portables (par ex. MacBook-Pro) peuvent tout à fait être utilisés - mais avec des restrictions : Les systèmes de refroidissement sont plus petits, la chaleur est plus limitée et le budget RAM est souvent plus faible. Une utilisation prolongée (comme pour les modèles d'intelligence artificielle) peut réduire les performances.

IA : Apple meilleur que Nvidia ! 😮 | c't 3003
Pourquoi la RAM / mémoire unifiée est si importante
Lorsqu'un modèle linguistique est exécuté localement, la puissance du CPU ou du GPU n'est pas la seule à être utilisée - la mémoire de travail (RAM ou, dans le cas du Apple, „Unified Memory“) joue un rôle déterminant. Pourquoi ?
Le modèle lui-même (poids, activations, résultats intermédiaires) doit être conservé en mémoire. Plus le modèle est grand, plus il faut de mémoire. Les puces Apple-Silicon utilisent la "mémoire unifiée", c'est-à-dire que le CPU, le GPU et le moteur neuronal accèdent au même pool de mémoire. Il n'est donc pas nécessaire de copier les données entre les composants, ce qui augmente l'efficacité et la vitesse.
S'il n'y a pas assez de RAM, le système doit se décharger ou les modèles ne sont pas complètement chargés - ce qui peut signifier une baisse des performances, une instabilité ou un arrêt. Le temps de réaction et le débit sont particulièrement importants pour les applications inférentielles (génération de réponses, saisie de texte, extension de modèles) - une mémoire suffisante aide alors considérablement. Un PC de bureau traditionnel pensait auparavant en „RAM CPU“ et „RAM GPU séparée“ - sur le Apple Silicon, elles sont élégamment réunies, ce qui rend l'exécution de modèles vocaux particulièrement attrayante.
Valeurs estimatives : Quel est l'ordre de grandeur réaliste ?
Afin de pouvoir évaluer le matériel dont on a besoin, voici quelques valeurs empiriques :
- Pour les petits modèles (par ex. quelques milliards de paramètres), 16 Go à 32 Go de RAM pourraient suffire - en particulier si seules des requêtes individuelles doivent être traitées. Un Mac Mini avec 16/32 Go serait donc une entrée en matière.
- Pour les modèles moyens (p. ex. 3 à 10 milliards de paramètres) ou des tâches impliquant plusieurs chats parallèles ou de grandes quantités de texte, il faut envisager 32 Go de RAM ou plus - p. ex. Mac Studio avec 32 ou 48 Go.
- Pour les grands modèles (>20 milliards de paramètres) ou si plusieurs modèles doivent fonctionner en parallèle, on pourrait choisir 64 Go ou plus - dans ce cas, les variantes Mac mini et Mac Studio avec 64 Go ou plus entrent en ligne de compte.
Important : n'oubliez pas de prévoir un peu de mémoire tampon - non seulement le modèle, mais aussi le fonctionnement (par exemple le système d'exploitation, les E/S de fichiers, d'autres applications) ont besoin de réserves de mémoire.
| Catégorie | Taille typique du modèle | Budget RAM recommandé | Exemple d'utilisation |
|---|---|---|---|
| Petit | 1-3 milliards Paramètres | 16-32 GO | Assistant simple, reconnaissance de texte |
| Moyens | 7-13 milliards Paramètres | 32-64 GO | Chat, analyse, rédaction |
| Grand | 30-70 milliards Paramètres | 64 GB + | Textes spécialisés, documents juridiques |
Remettre en question l'approche traditionnelle "serveur versus bureau".
Traditionnellement, on pensait que l'IA nécessitait des fermes de serveurs, de nombreux GPU, beaucoup d'électricité, un centre de calcul. Mais l'image évolue : les ordinateurs de bureau comme le Mac Mini ou le Mac Studio offrent aujourd'hui suffisamment de puissance pour de nombreux modèles linguistiques exploités localement - sans infrastructure gigantesque. Au lieu de coûts d'électricité élevés, d'un refroidissement puissant et d'une maintenance complexe, vous gagnez une machine silencieuse et efficace sur votre bureau.
Bien sûr : si vous voulez entraîner des modèles à grande échelle ou utiliser un grand nombre de paramètres, les solutions serveur restent utiles. Mais pour l'inférence, l'adaptation et l'utilisation au quotidien, le matériel de bureau suffit souvent. Une attitude traditionnelle s'y associe : utiliser la technique, mais ne pas la surdimensionner - il vaut mieux la cibler et la rendre efficace. Construire aujourd'hui une base locale solide, c'est jeter les bases de ce qui sera possible demain.

M3 Ultra vs RTX 5090 | The Final Battle (Anglais)
Caractérisation technique des modèles linguistiques
Aujourd'hui, les modèles linguistiques ne se distinguent pas seulement par leurs capacités, mais aussi par le format technique dans lequel ils sont disponibles. Ces formats déterminent la manière dont le modèle est stocké, chargé et utilisé - et s'il peut même être exécuté sur un système donné.
GGUF (GPT-Generated Unified Format)
Ce format a été développé pour une utilisation pratique dans des outils tels que Ollama, LM Studio ou Llama.cpp. Il est compact, portable et hautement optimisé pour l'inférence locale. Les modèles GGUF sont généralement quantifiés, ce qui signifie qu'ils utilisent beaucoup moins de mémoire, car les valeurs numériques internes sont stockées de manière réduite (par exemple 4 bits ou 8 bits). Il est ainsi possible de comprimer des modèles d'une taille initiale de 30 à 50 Go en 5 à 10 Go, avec une perte de qualité minime.
- Avantage: Fonctionne sur presque tous les systèmes (macOS, Windows, Linux), aucun GPU spécifique n'est nécessaire.
- InconvénientPas destiné à l'entraînement ou au réglage fin - pure inférence (donc utilisation).
MLX (apprentissage automatique pour Apple Silicon)
MLX est le propre framework open source de Apple pour l'apprentissage automatique sur Apple Silicon. Il a été spécialement conçu pour exploiter toute la puissance du CPU, du GPU et du moteur neuronal des puces M. Les modèles MLX existent généralement au format MLX natif ou sont convertis à partir d'autres formats.
- Avantage: Performance et efficacité énergétique maximales sur le matériel Apple.
- Inconvénient: écosystème encore relativement jeune, moins de modèles communautaires disponibles que chez GGUF ou PyTorch.
Safetensors (.safetensors)
Ce format provient du monde PyTorch (et est fortement encouragé par Hugging Face). Il s'agit d'un format de stockage binaire sécurisé pour les grands modèles, qui ne permet pas l'exécution de code - d'où son nom de „safe“.
- Avantage: Chargement très rapide, économie de mémoire, standardisé.
- InconvénientPrincipalement destiné à des frameworks comme PyTorch ou TensorFlow - donc plus courant dans les environnements de développement et pour les processus de formation.
| Format | Plate-forme | Objectif | Avantages | Inconvénients |
|---|---|---|---|---|
| GGUF | macOS, Windows, Linux | Inférence | Compact, rapide, universel | Pas de formation possible |
| MLX | macOS (Apple Silicon) | Inférence + formation | Optimisé pour les puces M, haute efficacité | Moins de modèles disponibles |
| Capteurs de sécurité | Multiplateforme (PyTorch / TensorFlow) | Formation et recherche | Sûr, standardisé, rapide | Pas directement compatible avec Ollama / MLX |
Hugging Face - la source centrale d'approvisionnement
Hugging Face est aujourd'hui en quelque sorte la "bibliothèque" du monde de l'IA. Sur huggingface.co on trouve des dizaines de milliers de modèles, de jeux de données et d'outils - dont beaucoup sont librement utilisables. On peut y filtrer par nom, architecture, type de licence ou format de fichier. Qu'il s'agisse de Mistral, LLaMA, Falcon, Gemma ou Phi-3 - presque tous les modèles renommés y sont représentés. Pour une utilisation locale avec GGUF ou MLX, de nombreux développeurs proposent déjà des versions adaptées.
Hugging Face est ainsi le premier point de contact pour la plupart des utilisateurs lorsqu'ils souhaitent essayer un modèle ou trouver une variante adaptée à macOS.

Modèles typiques et leurs domaines d'application
Il est désormais difficile de se faire une idée du nombre de modèles disponibles. On peut néanmoins citer quelques grandes familles qui ont particulièrement fait leurs preuves pour une utilisation locale :
- Famille LLaMA (Meta): Un des modèles open source les plus connus. Il constitue la base d'innombrables dérivés (p. ex. Vicuna, WizardLM, Open-Hermes). Points forts : compréhension de la parole, dialogue, utilisation polyvalente. Domaine d'application : applications générales de chat, génération de contenu, systèmes d'assistance.
- Mistral & Mixtral (Mistral AI): Réputé pour sa grande efficacité et sa bonne qualité avec une petite taille de modèle. Mixtral 8x7B combine plusieurs modèles experts (architecture Mixture-of-Experts). Points forts : réponses rapides et précises, peu gourmand en ressources. Domaine d'application : Assistants internes à l'entreprise, analyse de texte, préparation de données.
- Phi-3 (Microsoft Research): Modèle compact, optimisé pour une qualité vocale élevée malgré un nombre de paramètres réduit. Points forts : efficacité, bonne grammaire, réponses structurées. Domaine d'application : petits systèmes, modèles de connaissances locaux, assistants intégrés.
- Gemma (Google)Publié par Google Research en tant que modèle ouvert. Bon pour les tâches sommaires et explicatives. Points forts : cohérence, explications contextuelles. Domaine d'application : préparation des connaissances, formation, systèmes de consultation.
- Modèles GPT-OSS / OpenHermesLes modèles open-source et les fonctionnalités des systèmes commerciaux sont ainsi reliés. Points forts : Large base linguistique, utilisation flexible. Domaine d'application : création de contenus, tâches de chat et d'analyse, assistance interne en matière d'IA.
- Claude / Command R / Falcon / Yi / ZephyrCes modèles et bien d'autres (généralement issus de projets de recherche ou de communautés ouvertes) offrent des fonctions spéciales, telles que la récupération de connaissances, la génération de code ou le multilinguisme.
Le point le plus important est qu'aucun modèle ne peut tout faire parfaitement. Chacun a ses points forts et ses points faibles - et selon le cas d'utilisation, il vaut la peine de faire une comparaison ciblée.
Quel modèle convient le mieux ?
Afin d'obtenir une estimation réaliste, on peut grossièrement répartir les modèles en classes de performance et d'utilisation :
Pour la plupart des applications de bureau réalistes - comme les résumés, la correspondance, la traduction, l'analyse - des modèles moyens (7-13 B) sont tout à fait suffisants. Ils donnent des résultats étonnamment bons, fonctionnent de manière fluide sur un Mac Mini M4 Pro avec 32-48 Go de RAM et ne nécessitent pratiquement pas de réajustement.
Grands modèles déploient leurs atouts lorsqu'une compréhension approfondie ou des contextes plus longs sont importants - par exemple pour le traitement de textes juridiques ou de documentations techniques. Pour cela, il faut toutefois avoir au moins un Mac Studio de 64 à 128 Go Utiliser la mémoire de travail.
| Famille de modèles | Origine | Points forts | Domaine d'application |
|---|---|---|---|
| LLaMA | Meta | Compréhension de la langue, dialogue | Applications générales de chat |
| Mistral / Mixtral | Mistral AI | Efficacité, haute précision | Assistants d'entreprise, analyse |
| Phi-3 | Microsoft Research | Compact, linguistiquement fort | Petits systèmes, IA locale |
| Gemma | Recherche Google | Cohérence, capacité d'explication | Conseil, enseignement, explication de texte |
Possibilités d'exploiter des modèles linguistiques en local
Celui qui souhaite aujourd'hui utiliser un modèle de langage sur son propre Mac dispose de plusieurs voies praticables - en fonction des exigences techniques et de l'utilisation souhaitée. Ce qui est bien, c'est qu'il n'est plus nécessaire de disposer d'un environnement de développement complexe pour s'y mettre.
Ollama - l'entrée en matière facile
Ollama est devenu en peu de temps un outil standard pour les modèles d'IA locaux. Il fonctionne nativement sur macOS, exploite de manière optimale la puissance de Apple Silicon et permet de lancer un modèle avec une seule commande :
ollama run mistral
Ainsi, le modèle souhaité est automatiquement chargé, préparé et ensuite disponible dans le terminal ou via des interfaces locales. Ollama supporte le format GGUF, permet le téléchargement de modèles depuis Hugging Face et peut être intégré via des API REST ou directement dans d'autres programmes.
Comment utiliser Ollama un modèle de langage local installiert et les autres possibilités qu'il offre, je l'ai décrit en détail dans un autre article. Il existe des articles complémentaires sur la manière d'utiliser Qdrant une mémoire flexible pour son IA locale.
LM Studio - interface graphique et gestion
LM Studio s'adresse à tous ceux qui préfèrent une interface graphique. Elle offre des téléchargements de modèles, des fenêtres de discussion, des régulateurs de température, des invites système et une gestion de la mémoire dans une seule application. C'est idéal pour les débutants : on peut essayer différents modèles, les comparer, les enregistrer et en changer sans devoir travailler avec la ligne de commande. Le logiciel fonctionne de manière stable sur les modèles Apple et Silicon et supporte également les modèles GGUF.
MLX / Python - pour les développeurs et les intégrateurs
Ceux qui souhaitent aller plus loin ou intégrer des modèles dans leurs propres programmes peuvent recourir au framework MLX de Apple. Celui-ci permet d'intégrer des modèles directement dans des applications Python ou Swift. L'avantage réside dans le contrôle maximal et l'intégration dans les flux de travail existants - par exemple lorsqu'une entreprise souhaite ajouter des fonctions d'IA à son propre logiciel.
FileMaker Server 2025 - L'IA dans le contexte de l'entreprise
Depuis FileMaker Serveur 2025 les modèles de langage basés sur MLX peuvent également être adressés côté serveur. Il est ainsi possible pour la première fois d'équiper une application commerciale centrale (par exemple un système ERP ou CRM) de sa propre IA locale. Par exemple, les tickets d'assistance peuvent être automatiquement classés, les demandes des clients évaluées ou le contenu des documents analysé - sans que les données ne quittent l'entreprise.
Cela est particulièrement intéressant pour les secteurs qui ont des exigences strictes en matière de protection des données ou de conformité (médecine, droit, administration, industrie).
Les écueils typiques et comment les éviter
Même si la barrière d'entrée est faible, il y a quelques points auxquels il faut faire attention :
Limites de la mémoire : Si le modèle est trop grand pour la mémoire vive disponible, il ne démarre pas du tout ou devient extrêmement lent. Dans ce cas, la quantification (par ex. 4 bits) ou un modèle plus petit peuvent aider.
- Charge de calcul et développement thermique: Lors de sessions prolongées, le Mac peut devenir sensiblement chaud. Une bonne ventilation et un œil sur l'indicateur d'activité sont utiles.
- Absence de support GPU pour les logiciels tiersCertains outils ou ports plus anciens n'utilisent pas efficacement le moteur neuronal. Dans de tels cas, MLX peut donner de meilleurs résultats.
- Ports réseau et droitsSi plusieurs clients doivent accéder au même modèle (par exemple au sein d'un réseau d'entreprise), les ports locaux doivent être libérés, de préférence de manière sécurisée par HTTPS ou via un proxy interne.
- Sécurité des donnéesMême si les modèles fonctionnent en local, il ne faut pas stocker de textes sensibles dans des environnements non sécurisés. Les logs locaux et les journaux de chat sont facilement oubliés, mais ils contiennent souvent des informations précieuses.
En respectant ces points, il est possible d'exploiter un système d'IA local performant, qui fonctionne de manière sûre, silencieuse et efficace, avec étonnamment peu d'efforts.
Perspectives temporelles & réflexions stratégiques
Nous ne sommes qu'au début d'une évolution qui va changer le quotidien de nombreuses professions dans les années à venir. Les modèles d'IA locaux deviennent de plus en plus petits, rapides et efficaces, tandis que leur qualité continue d'augmenter. Ce qui nécessite aujourd'hui 30 Go de mémoire n'en utilisera peut-être plus que 10 dans un an, tout en conservant la même qualité vocale. Parallèlement, de nouvelles interfaces apparaissent, qui permettent d'intégrer les modèles directement dans les programmes Office, les navigateurs ou les logiciels d'entreprise.
Les entreprises qui franchissent aujourd'hui le pas vers une infrastructure IA locale prennent ainsi une longueur d'avance. Elles développent un savoir-faire, assurent la souveraineté de leurs données et s'affranchissent des fluctuations de prix ou des restrictions d'utilisation des fournisseurs externes. Une stratégie judicieuse peut se présenter ainsi :
- Expérimenter d'abord avec un petit modèle (par ex. 3-7 milliards de paramètres, via Ollama ou LM Studio).
- Ensuite, examiner de manière ciblée quelles tâches peuvent être automatisées.
- Si nécessaire, intégrer des modèles plus grands ou mettre en place un Mac Studio central comme "serveur d'IA".
- A moyen terme, réorganiser les processus internes (par ex. documentation, analyse de texte, communication) à l'aide de l'IA.
Cette approche progressive n'est pas seulement économiquement raisonnable, elle est aussi durable - elle suit le principe suivant : adopter la technique à son propre rythme plutôt que de se laisser porter par les tendances.
Dans un article séparé, j'ai décrit en détail la manière dont le plus récent Le format MLX comparé au GGUF via Ollama sur le Mac.
L'IA locale, une voie silencieuse vers la souveraineté numérique
Les modèles linguistiques locaux marquent un retour à l'autodétermination dans le monde numérique.
Au lieu d'envoyer des données et des idées dans des centres de données en nuage éloignés, on peut aujourd'hui travailler à nouveau avec ses propres outils - directement sur son bureau, sous son propre contrôle.
Que ce soit sur un Mac Mini, un Mac Studio ou un ordinateur portable performant, quiconque possède le matériel adéquat peut aujourd'hui utiliser, entraîner et développer sa propre IA. Qu'il s'agisse d'un assistant personnel, d'une partie d'un système ERP, d'une aide à la recherche dans une maison d'édition ou d'une solution conforme à la protection des données dans un cabinet d'avocats, les possibilités sont étonnamment vastes.
Et le plus beau, c'est qu'il rappelle l'ancienne force de l'ordinateur - à savoir être un outil que l'on maîtrise soi-même, plutôt qu'un service qui nous dicte comment travailler. L'IA locale devient ainsi un symbole d'autonomie moderne - silencieuse, efficace, et pourtant d'un effet impressionnant.
L'IA locale dans l'entreprise déploie sa valeur avec la bonne base système
 La discussion sur l'IA locale tourne souvent autour du matériel, des modèles et de la vitesse - mais la véritable utilité ne se révèle qu'en interaction avec les propres données et processus. Si l'on veut vraiment utiliser l'IA à bon escient, il faut un environnement stable et contrôlé dans lequel les informations ne sont pas dispersées, mais disponibles de manière structurée. C'est précisément là qu'intervient une solution ERP exploitée localement Elle constitue l'épine dorsale des données, des processus et des relations au sein de l'entreprise. En combinaison avec une solution comme gFM Business ERP, il en résulte un circuit fermé dans lequel l'IA locale ne se contente pas de fournir des réponses, mais travaille en fonction du contexte - par exemple en intégrant son propre graphe de connaissances. Les décisions ne sont alors plus basées sur des modèles généraux, mais sur les données réelles de l'entreprise. Le résultat est un pas discret mais efficace vers une véritable souveraineté numérique : plus de contrôle, plus d'efficacité et un système qui s'adapte à l'entreprise - et non l'inverse.
La discussion sur l'IA locale tourne souvent autour du matériel, des modèles et de la vitesse - mais la véritable utilité ne se révèle qu'en interaction avec les propres données et processus. Si l'on veut vraiment utiliser l'IA à bon escient, il faut un environnement stable et contrôlé dans lequel les informations ne sont pas dispersées, mais disponibles de manière structurée. C'est précisément là qu'intervient une solution ERP exploitée localement Elle constitue l'épine dorsale des données, des processus et des relations au sein de l'entreprise. En combinaison avec une solution comme gFM Business ERP, il en résulte un circuit fermé dans lequel l'IA locale ne se contente pas de fournir des réponses, mais travaille en fonction du contexte - par exemple en intégrant son propre graphe de connaissances. Les décisions ne sont alors plus basées sur des modèles généraux, mais sur les données réelles de l'entreprise. Le résultat est un pas discret mais efficace vers une véritable souveraineté numérique : plus de contrôle, plus d'efficacité et un système qui s'adapte à l'entreprise - et non l'inverse.
Sources à recommander
- Profiling Large Language Model Inference sur Apple Silicon: A Quantization Perspective (Benazir & Lin et al., 2025) - Examine en détail les performances d'inférence sur Apple Silicon par rapport aux GPU NVIDIA, en se concentrant plus particulièrement sur la quantification.
- Production-Grade Local LLM Inference on Apple Silicon: A Comparative Study of MLX, MLC-LLM, Ollama, llama.cpp, and PyTorch MPS (Rajesh et al., 2025) - Comparaison de différentes plates-formes sur Apple Silicon y compris MLX, en termes de débit, de latence, de longueur de contexte.
- Benchmarking On-Device Machine Learning sur Apple Silicon avec MLX (Ajayi & Odunayo, 2025) - Se concentre sur MLX et Apple Silicon, avec des données de référence par rapport aux systèmes NVIDIA.



Foire aux questions
- Qu'est-ce exactement qu'un modèle linguistique local ?
Un modèle de langage local est une IA capable de comprendre et de générer des textes, à l'instar de ChatGPT. La différence réside dans le fait qu'il ne fonctionne pas via Internet, mais directement sur son propre ordinateur. Tous les calculs sont effectués localement et aucune donnée n'est envoyée à des serveurs externes. On garde ainsi le contrôle total de ses informations. - Quels sont les avantages d'une IA locale par rapport à une solution en nuage comme ChatGPT ?
Les trois principaux avantages sont la protection des données, l'indépendance et le contrôle des coûts.
- Protection des données : aucun texte ne quitte l'ordinateur.
- Indépendance : pas besoin de connexion Internet, pas de changement de fournisseur ni de risque de panne.
- Coûts : pas de frais courants par demande. On paie une fois pour le matériel - c'est tout. - Faut-il des connaissances en programmation pour utiliser un modèle linguistique en local ?
Non. Avec des outils modernes comme Ollama ou LM Studio, un modèle peut être lancé en quelques clics. Même les débutants peuvent aujourd'hui faire fonctionner une IA locale en quelques minutes, sans écrire une seule ligne de code. - Quels sont les appareils Apple les plus adaptés ?
Pour les débutants, un Mac Mini avec M4 ou M4 Pro et au moins 32 Go de RAM est souvent suffisant. Si l'on veut utiliser des modèles plus grands ou plusieurs simultanément, il vaut mieux opter pour un Mac Studio avec 64 Go ou 128 Go de RAM. Un Mac Pro n'offre guère d'avantages, sauf si l'on a besoin de slots PCI-e. Les ordinateurs portables sont certes adaptés, mais ils atteignent plus rapidement leurs limites sur le plan thermique. - De quelle quantité de mémoire vive (RAM) faut-il disposer au minimum ?
Cela dépend de la taille du modèle.
- Petits modèles (1 à 3 milliards de paramètres) : 16 à 32 Go suffisent.
- Modèles moyens (7-13 milliards) : mieux vaut 48-64 Go.
- Grands modèles (30 milliards+) : 128 Go ou plus.
Il est important de prévoir une certaine réserve - sinon, il y aura des temps d'attente ou des interruptions. - Que signifie "mémoire unifiée" pour Apple Silicon ?
La mémoire unifiée est une mémoire commune à laquelle le CPU, le GPU et le moteur neuronal accèdent simultanément. Cela permet d'économiser du temps et de l'énergie, car aucune copie de données n'est nécessaire entre les différentes zones de mémoire. C'est un avantage énorme, notamment pour les calculs d'IA, car tout fonctionne dans un même flux. - Quelle est la différence entre GGUF, MLX et Safetensors ?
- GGUF : un format compact pour une utilisation locale (par ex. dans Ollama ou LM Studio). Idéal pour l'inférence, c'est-à-dire l'exécution de modèles prêts à l'emploi.
- MLX : format propre à Apple, spécialement conçu pour les puces M. Très efficace, mais encore jeune.
- Safetensors : un format issu du monde PyTorch, destiné principalement à la formation et à la recherche.
Pour une utilisation locale sur Mac, GGUF ou MLX sont optimaux. - Où peut-on se procurer les modèles ?
La plate-forme la plus connue est huggingface.co - une énorme bibliothèque de modèles d'IA. On y trouve des variantes de LLaMA, Mistral, Gemma, Phi-3 et bien d'autres. De nombreux modèles sont déjà disponibles au format GGUF et peuvent être chargés directement dans Ollama. - Quels sont les outils les plus faciles à utiliser pour démarrer ?
Pour commencer, Ollama et LM Studio sont idéaux. Ollama fonctionne dans le terminal et est léger. LM Studio offre une interface graphique avec une fenêtre de discussion. Les deux chargent et lancent automatiquement les modèles et ne nécessitent pas de configuration compliquée. - Est-il possible d'utiliser des modèles linguistiques avec le serveur FileMaker ?
Oui - depuis FileMaker Server 2025, les modèles MLX peuvent être adressés directement. Cela permet par exemple d'effectuer des analyses de texte, des classifications ou des évaluations automatiques au sein des systèmes ERP ou CRM. Les données commerciales confidentielles peuvent ainsi être traitées localement, sans être envoyées à des fournisseurs externes. - Quelle est la taille typique de ces modèles ?
Les petits modèles sont de l'ordre de quelques gigaoctets, les grands peuvent avoir 20 à 30 Go ou plus. La quantification (par ex. 4 bits) permet de réduire fortement leur taille, souvent avec une perte de qualité minimale. Un modèle 13-B compressé peut par exemple n'occuper que 7 Go - parfait pour un Mac Mini M4 Pro. - Est-il également possible d'entraîner ou d'adapter des modèles locaux ?
En principe oui - mais l'entraînement est très gourmand en temps de calcul. Pour le réglage fin local de petits modèles, on peut utiliser MLX ou des frameworks Python. FileMaker contient aujourd'hui une fonction intégrée pour Ajuster directement les modèles linguistiques de pouvoir le faire. Pour un entraînement de grande envergure (par ex. 50 milliards de paramètres), une ferme de GPU dédiée serait toutefois nécessaire. Pour la plupart des applications, il suffit d'utiliser des modèles existants et de les contrôler de manière ciblée via des invites. - Quelle est la consommation d'énergie d'un Mac lors des calculs d'IA ?
Étonnamment peu. Un Mac Studio se situe souvent en dessous de 100 W en plein fonctionnement, alors qu'une seule carte graphique NVIDIA (par ex. RTX 5090) tire jusqu'à 450 W - sans CPU ni périphériques. Cela signifie que l'IA locale sur du matériel Apple n'est pas seulement plus silencieuse, mais aussi nettement plus efficace sur le plan énergétique. - Un MacBook Pro est-il adapté à l'IA locale ?
Oui, mais avec des restrictions.
Les performances sont certes élevées, mais la capacité de charge thermique est limitée. Lors de sessions prolongées, le processeur ralentit. Un MacBook Pro M3/M4 est parfait pour de courtes discussions, des exercices de texte ou des analyses - mais pas pour une utilisation durable. - Dans quelle mesure les modèles locaux sont-ils vraiment sûrs ?
Aussi sûr que le système sur lequel ils fonctionnent. Étant donné qu'aucune donnée n'est envoyée via Internet, il n'y a pratiquement aucun risque de tiers. Il faut toutefois veiller à ce que les fichiers temporaires, les logs ou les historiques de chat ne se retrouvent pas par inadvertance dans des dossiers cloud (par ex. iCloud Drive). Un stockage local sur le SSD interne est idéal. - Quelles sont les erreurs typiques que font les débutants ?
- Charger des modèles trop grands alors que la RAM n'est pas suffisante.
- Utiliser d'anciennes versions de Ollama ou de LM Studio.
- Ne pas activer l'accélération GPU (par ex. MLX).
- Laisser tourner trop de processus en arrière-plan.
- Charger des modèles provenant de sources douteuses.
Remède : n'utiliser que des sources fiables (p. ex. Hugging Face) et garder un œil sur les ressources du système. - Où évoluera la technologie de l'IA locale dans les prochaines années ?
Les modèles continuent à devenir plus compacts et plus précis. Apple, Mistral et Meta travaillent déjà sur des architectures qui, à qualité égale, nécessitent moins de mémoire et d'énergie. Parallèlement, des interfaces confortables voient le jour - par exemple des plug-ins IA pour le traitement de texte, les programmes de messagerie ou les applications de prise de notes. À long terme, chaque système professionnel devrait contenir une sorte d„“IA locale intégrée". - Pourquoi cela vaut-il la peine de commencer maintenant ?
Parce que c'est maintenant que se forment les bases pour les années à venir. Celui qui apprend aujourd'hui à lancer un modèle localement, à traiter les données de manière structurée et à formuler des invites de manière ciblée, pourra plus tard agir de manière indépendante - sans dépendre de fournisseurs de cloud coûteux. En bref : l'IA locale est la voie tranquille et souveraine vers un avenir numérique dans lequel on garde à nouveau la main sur ses données et ses outils.



