Le monde de l'intelligence artificielle est en pleine évolution. De nouveaux modèles, de nouvelles méthodes et surtout de nouvelles possibilités apparaissent aujourd'hui presque chaque semaine - et pourtant, un constat reste constant : toutes les nouveautés techniques ne conduisent pas automatiquement à une amélioration du quotidien. Beaucoup de choses restent expérimentales, complexes ou tout simplement trop coûteuses pour une utilisation productive. C'est particulièrement évident dans le cas de ce que l'on appelle le réglage fin de grands modèles linguistiques - une méthode permettant de spécialiser l'IA générative sur des contenus, des termes et des tonalités propres.
J'ai accompagné ce processus de manière intensive au cours des derniers mois - d'abord de manière classique, avec Python, terminal, messages d'erreur et boucles d'installation épuisantes pour les nerfs. Et puis : avec FileMaker 2025. Une étape qui m'a surpris - parce qu'elle n'était pas bruyante, mais claire. Et parce qu'il a montré qu'il était possible de faire autrement.
Dans un rapport détaillé Article spécialisé sur gofilemaker.de j'ai documenté précisément ce changement : le passage de la formation PEFT-LoRA ouverte, flexible mais instable (par ex. avec Axolotl, LLaMA-Factory ou kohya_ss) à la solution intégrée de Claris - par script, locale, traçable.



Qu'est-ce que la LoRA au juste - et pourquoi est-elle si importante ?
LoRA est l'abréviation de Low-Rank Adaptation. Derrière ce terme à consonance technique se cache un principe simple mais puissant : au lieu de réentraîner un modèle d'IA complet, on n'adapte que des parties bien précises - via des poids adaptateurs qui sont insérés et entraînés de manière ciblée. Cette méthode s'est établie ces dernières années comme l'étalon-or du fine tuning spécifique au domaine - parce qu'elle ne nécessite que peu de puissance de calcul tout en fournissant d'excellents résultats.
Dans l'approche classique, il faut pour cela un arsenal d'outils :
- un environnement Python fonctionnel,
- les versions CUDA et PyTorch correspondantes,
- un moteur d'entraînement comme Axolotl ou kohya_ss,
- ressources GPU pour gérer le tout,
- et enfin et surtout : De la patience. Beaucoup de patience.
En effet, entre les fichiers YAML, les conflits de Tokenizer et les conversions de format (de safetensors à GGUF à MLX et inversement), il faut souvent des jours avant d'obtenir un résultat utilisable. Cela fonctionne - mais ce n'est pas quelque chose à faire en passant.
Puis est arrivé FileMaker 2025.
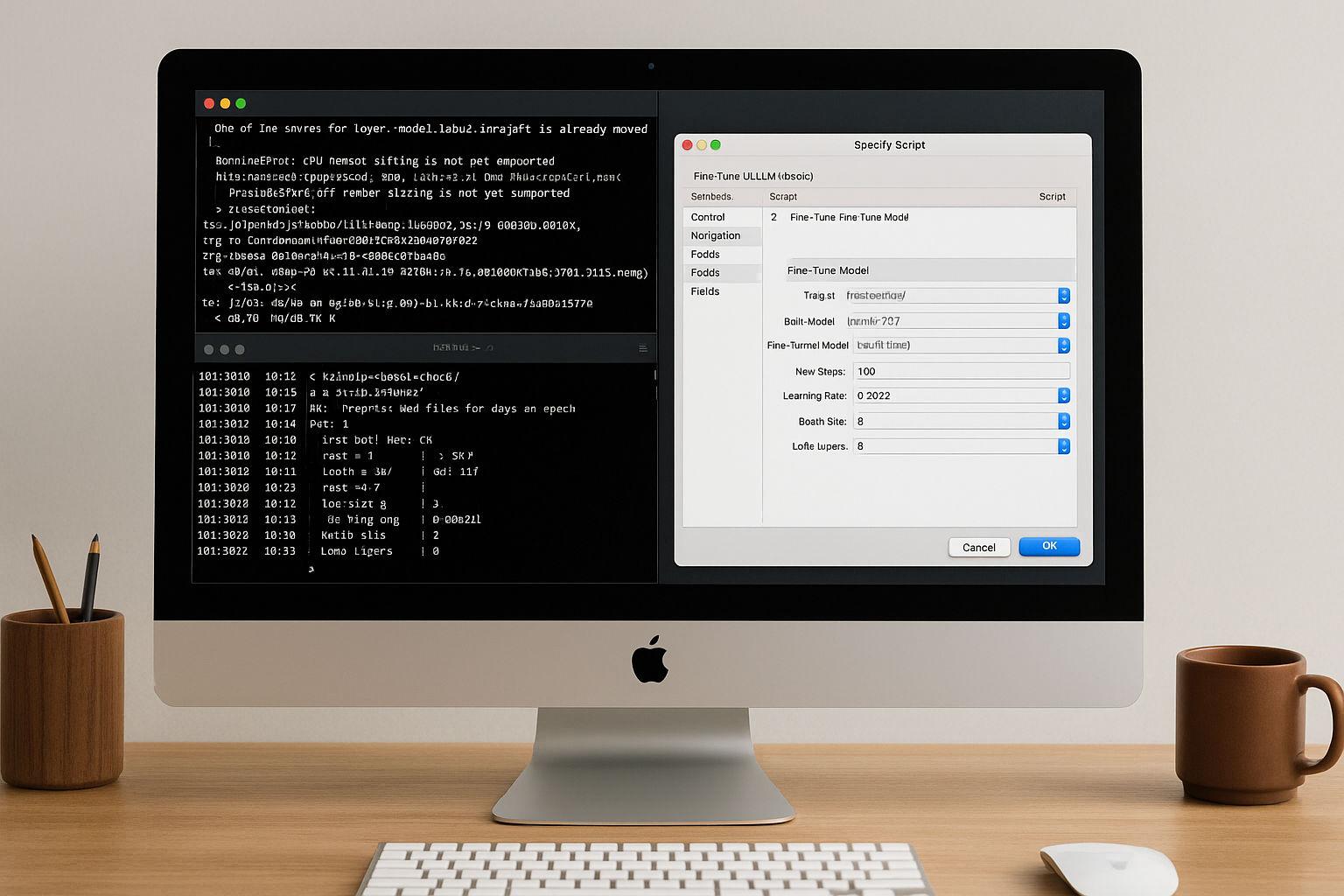
Avec l'introduction de l'AI Model Server et d'une nouvelle scriptstep appelée Fine-Tune Model, Claris introduit précisément cette méthode dans un environnement où on ne l'attendait pas : une base de données relationnelle.
Ce qui semble d'abord inhabituel prend tout son sens lorsqu'on y regarde de plus près. En effet, de quoi a besoin un bon réglage fin ?
- Données préparées de manière structurée,
- un environnement stable,
- des paramètres clairs,
- et un contexte d'application défini.
Tout cela, FileMaker le propose - et c'est pourquoi l'intégration de LoRA dans cet environnement n'apparaît pas comme un corps étranger, mais comme une extension logique.

Entraînement sans terminal - mais pas sans contrôle
Dans mon article, je décris en détail ce que l'on ressent lors du processus d'entraînement en FileMaker :
- Saisie de données directement à partir de tableaux existants ou de fichiers JSONL,
- Hyperparamètres tels que le taux d'apprentissage ou la profondeur de la couche contrôlables directement dans le script,
- fonctionnement local complet sur Apple-Silicon - sans cloud, sans téléchargement,
- et surtout : des résultats qui sont reproductibles et utilisables au quotidien.
Bien sûr, il y a des limites. FileMaker ne permet pas (encore) le multi-model serving, les stratégies de layer freeze et l'exportation vers d'autres formats comme GGUF ou ONNX. Il ne s'agit pas d'un outil de recherche, mais d'un outil destiné à des cas d'utilisation précis - par exemple, l'adaptation de modèles linguistiques à des termes, des réponses, des descriptions de produits ou des structures de dialogue internes spécifiques à l'entreprise.
Et c'est là que réside son charme : il fonctionne. C'est stable. Répétable. Et plus vite que je ne l'aurais cru possible.
Dernière enquête sur l'avenir du FileMaker et de l'IA
Qui devrait y regarder de plus près - et pourquoi ?
Cet article s'adresse à tous ceux qui ne veulent pas seulement comprendre l'IA, mais l'utiliser :
- Directeur généralLes entreprises qui souhaitent concilier protection des données et efficacité.
- DéveloppeurNous sommes à la disposition de ceux qui ne veulent pas repartir à zéro à chaque fois.
- StratègesLes entreprises qui comprennent que l'IA ne peut pas seulement être "achetée" à l'extérieur, mais qu'elle peut aussi être formée en interne.
Dans FileMaker 2025, le réglage fin des modèles linguistiques fait partie du flux de travail - non pas comme un corps étranger, mais comme un véritable outil. C'est un changement discret mais durable, qui montre à quel point nous avons progressé dans l'aptitude à l'utilisation quotidienne de l'IA.
Vers l'article :
Du terminal au script : FileMaker 2025 rend le réglage fin de la LoRA utilisable au quotidien
Dans un prochain article, je décrirai comment un modèle de langage peut être entraîné dans la pratique avec FileMaker et je mettrai également à disposition un exemple de script correspondant.



