
Wer heute mit KI arbeitet, wird fast automatisch in die Cloud gedrückt: OpenAI, Microsoft, Google, irgendwelche Web-UIs, Tokens, Limits, AGBs. Das wirkt modern – ist im Kern aber eine Rückkehr in die Abhängigkeit: Andere bestimmen, welche Modelle Du nutzen darfst, wie oft, mit welchen Filtern und zu welchen Kosten. Ich gehe bewusst den anderen Weg: Ich baue mir gerade mein eigenes kleines KI-Studio zu Hause auf. Mit eigener Hardware, eigenen Modellen und eigenen Workflows.
Mein Ziel ist klar: Text-KI lokal, Bild-KI lokal, eigene Modelle anlernen (LoRA, Feintuning) und all das so, dass ich als Selbständiger und später auch KMU-Kunden nicht von der Tageslaune irgendeines Cloud-Anbieters abhängig bin. Man könnte sagen: Es ist eine Rückkehr zu einer alten Haltung, die früher ganz normal war: „Wichtige Dinge macht man selbst“. Nur dass es diesmal nicht um die eigene Werkbank geht, sondern um Rechenleistung und Datenhoheit.




Geschwindigkeit bleibt lokal unschlagbar
Cloud-Modelle sind beeindruckend – solange die Leitung steht, die Server nicht überlastet sind und die API nicht gerade wieder gedrosselt wird. Aber jeder, der ernsthaft mit KI arbeitet, merkt sehr schnell: Die ehrlichste Form von Geschwindigkeit ist lokal. Wenn ein Modell auf dem eigenen Mac Studio oder einer eigenen GPU läuft, dann gilt:
- Keine Netzwerklatenz
- Keine Wartezeit, bis „die anderen“ fertig sind
- Keine stundenweise Ausfälle
- Kein „Rate limit reached“ mitten im Workflow
Ich erlebe das täglich: Auf meinem Mac Studio läuft ein 120B-Modell (GPT-OSS) und parallel ein 27B-Gemma-Modell – dazu FileMaker Server und all meine Datenbanken. Trotzdem bleibt das System so reaktionsschnell, dass ich in einem Tempo arbeite, das mit Cloud-Systemen kaum erreichbar ist. Gerade wenn Du viele kleine Operationen hintereinander machst – Übersetzungen, Umformulierungen, Analysen, Bildprompts – summieren sich Verzögerungen schnell. Lokale KI fühlt sich nicht wie „Serverbetrieb“ an, sondern wie ein direktes Werkzeug: Du drückst, es passiert.
Datensouveränität: Wenn sensible Informationen nicht ins Netz gehören
Ein Punkt, der gern weggewischt wird, aber für Unternehmer entscheidend ist: Daten. Sobald Du Cloud-KI nutzt, stellst Du Dir zwangsläufig Fragen:
- Darf ich Kundendaten dort hineingeben?
- Was passiert mit internen Dokumenten?
- Wie lange werden Logs aufbewahrt?
- Wer hat theoretisch Zugriff – heute und in zwei Jahren?
- Welche juristischen Folgen hätte ein Leak?
Natürlich haben die großen Anbieter Datenschutz-Versprechen. Aber am Ende des Tages gibst Du Deine Inhalte aus der Hand. Und genau das wollte man früher im eigenen Betrieb vermeiden: Internes blieb intern. In einem lokalen KI-Studio ist die Situation eine andere:
- Die Daten bleiben im eigenen Netzwerk.
- Kein Request verlässt das Haus.
- Modelle laufen ohne Internetzugriff.
- Logs, Trainingsdaten und Zwischenstände liegen auf Deinen eigenen Platten.
Wenn ich in Zukunft meine Bücher, Artikel, Notizen, PR-Texte, interne Strategiepapiere oder Kundendaten durch meine KI jage, dann will ich sicher sein, dass nichts davon in irgendeinem fremden Trainingsset landet. Dieses Vertrauen bekomme ich nur, wenn die Infrastruktur mir gehört.
Kostenkontrolle statt schleichender Abos
Cloud-KIs wirken auf den ersten Blick günstig: ein paar Cent pro 1.000 Tokens, ein Monatsabo hier, ein kleiner Tarif dort. Das Problem ist: Die Kosten steigen mit Deinem Erfolg. Je produktiver Du wirst, desto teurer wird die Infrastruktur – und zwar jeden Monat. Lokale KI funktioniert anders:
- Du investierst einmal in Hardware.
- Danach laufen die Modelle, so viel und so oft Du willst.
- Kein „Bestellfinger zittert“, weil jeder Aufruf Geld kostet.
- Du kannst freier experimentieren, ohne jede Eingabe durchzurechnen.
Ich habe meine RTX 3090 gebraucht für rund 750 Euro gekauft – praktisch neuwertig. Meinen Mac Studio mit 128 GB RAM habe ich für rund 2.750 Euro bekommen, originalverpackt und noch nie geöffnet. Das ist Geld, ja – aber:
- Diese Maschinen werden mich viele Jahre begleiten.
- Sie erzeugen direkt verwertbare Assets: Bücher, Artikel, Bilder, LoRAs, Workflows.
- Sie verursachen keine monatlichen Zusatzkosten außer Strom.
Für einen Verlag, einen Berater, einen Entwickler oder ein kleines Unternehmen kann das der Unterschied sein zwischen „Wir müssen rechnen, ob wir uns das leisten können“ und „Wir nutzen KI einfach, wenn wir sie brauchen“.
Alte Tugenden, neuer Nutzen: Warum sich eigene Maschinen wieder lohnen
Früher war es selbstverständlich, dass ein Handwerker gutes Werkzeug im eigenen Betrieb hatte. Eine Tischlerwerkstatt ohne ordentliche Hobelbank und Sägen wäre undenkbar gewesen. Heute haben wir uns an das Gegenteil gewöhnt: Statt eigener Maschinen mieten wir Dienste. Ein eigenes KI-Studio ist im Grunde nichts anderes als eine moderne Variante der klassischen Werkstatt:
- Der Mac Studio ist die zentrale Maschine für Sprachmodelle.
- Die RTX-Grafikkarte ist die Fräsmaschine für Bilder und Trainings.
- Ein zusätzlicher Rechner (z. B. Mac mini) übernimmt Spezialaufgaben wie Voice oder kleine Modelle.
- Eine Software wie FileMaker dient als Steuerpult: Sie orchestriert, speichert, dokumentiert.
Ich baue mir genau so ein Setup auf, weil ich langfristig alles selbst machen können will:
- Bücher schreiben und übersetzen,
- Bildserien generieren,
- eigene LoRA-Modelle trainieren,
- Workflows automatisieren,
- und später auch Kundenlösungen anbieten, die komplett lokal laufen können.
Das ist keine Nostalgie, das ist eine nüchterne Entscheidung: Je tiefer KI in den Alltag eingreift, desto sinnvoller ist es, die Kontrolle über die Technik zu behalten. Lokale KI ist nicht die „Bastler-Alternative“ zur schicken Cloud, sondern eine bewusste Rückkehr zu Eigenständigkeit:
- Du gewinnst Geschwindigkeit.
- Du behältst Deine Daten.
- Du kontrollierst Deine Kosten.
- Du baust Dir eine Infrastruktur auf, die Dir gehört.
Wenn man das konsequent zu Ende denkt, ähnelt ein KI-Studio zu Hause immer mehr der klassischen, gut ausgestatteten Werkstatt: Man verlässt sich nicht auf das, was andere irgendwo im Hintergrund erledigen, sondern baut sich eine eigene, stabile Basis auf.
Aktuelle Umfrage zu lokalen KI-Systemen
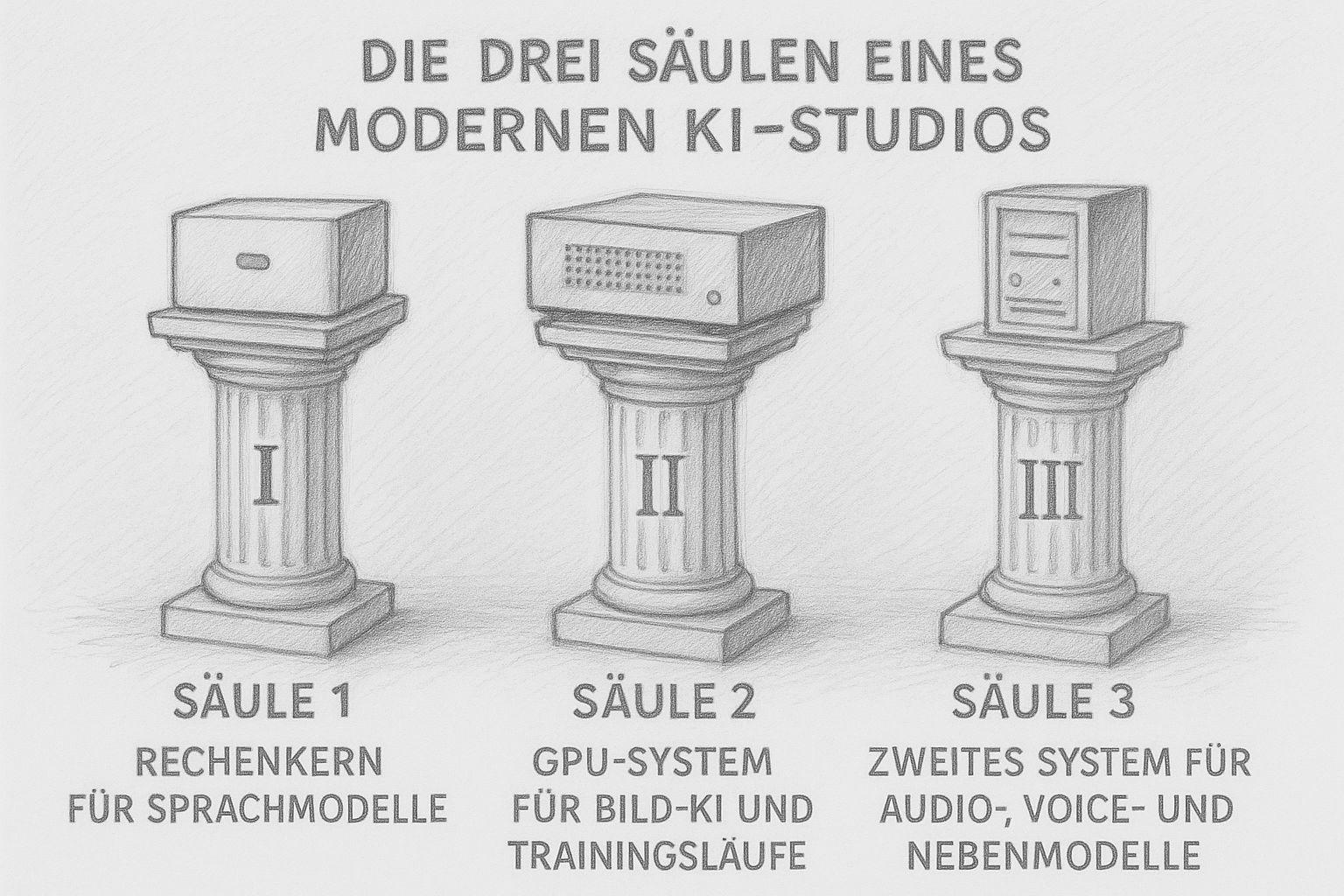
Die drei Säulen eines modernen KI-Studios
Ein KI-Studio besteht heute nicht mehr aus „dem einen großen Rechner“, der alles macht. Moderne Workflows brauchen unterschiedliche Stärken: Rechenleistung für Texte, viel VRAM für Bilder und Trainingsläufe, und daneben kleinere Systeme, die die Nebenjobs übernehmen. Das Ergebnis ist kein chaotischer Gerätepark, sondern eine durchdachte kleine Infrastruktur — wie früher ein gut bestückter Handwerksbetrieb, in dem jede Maschine ihren Zweck erfüllt.
Ich selbst baue mein Studio nach genau diesem Prinzip. Und je tiefer ich in diese Materie einsteige, desto klarer wird: Drei Säulen reichen aus, um eine komplette KI-Produktion lokal zu betreiben.
Säule 1: Der Rechenkern für Sprachmodelle (LLMs)
Für große Sprachmodelle braucht man heute keinen Rechenzentrumsserver mehr, sondern vor allem eines: viel, sehr schnellen Arbeitsspeicher. Genau das leisten moderne Apple-Silicon-Systeme oder vergleichbar ausgestattete Linux-Maschinen mit viel RAM. Der Rechenkern ist das Herzstück des Studios. Hier laufen:
- Große LLMs (20B, 30B, 70B, 120B MoE …)
- Analyse-Modelle
- Übersetzungsmodelle
- Internes Wissenssysteme (neo4j, RAG)
- langfristig auch ein KI-gestütztes Gedächtnis
- Steuerungssysteme wie z.B. n8n
- FileMaker-Automatisierungen und Server-Prozesse
In meinem Setup übernimmt der Mac Studio M1 Ultra mit 128 GB RAM diese Rolle. Und das tut er erstaunlich souverän. Ich betreibe darauf:
- GPT-OSS 120B MoE (für tiefes Denken, lange Texte und Analysen)
- Gemma-3 27B (für technische Arbeit wie FileMaker-Kram, Code, präzise Strukturierung)
- FileMaker Server + Datenbanken
- plus die gesamte Shell- und Webserver-Infrastruktur
Das Unglaubliche daran: Selbst mit zwei großen Modellen gleichzeitig bleiben 10–15 GB RAM frei. Das ist der Vorteil einer Architektur, die komplett auf Unified Memory ausgelegt ist. Wenn man es auf den Punkt bringt: Der Rechenkern ist das Gehirn des KI-Studios. Alles, was Texte versteht, erzeugt oder transformiert, passiert hier.
Säule 2: Das GPU-System für Bild-KI und Trainingsläufe
Die zweite Säule ist eine GPU-Workstation, optimiert für Stable Diffusion, ComfyUI, ControlNet und LoRA-Training. Während Textmodelle vor allem RAM benötigen, braucht Bild-KI VRAM. Und zwar viel. Warum? Weil Bildmodelle pro Frame gigantische Mengen an Daten durch den Speicher schaufeln. Und dafür sind Grafikkarten gebaut. In meinem Studio erledigt das eine NVIDIA RTX 3090 mit 24 GB VRAM — und diese 24 GB sind Gold wert. Sie erlauben:
- SDXL mit vernünftiger Batchgröße
- ComfyUI-Workflows
- Videosynthese
- Bildserien
- Material- und Stil-Training
- LoRA-Training mit 896×896 oder sogar 1024×1024
Für Bild-KI ist VRAM wichtiger als der allerneueste Chip. Eine solide 3090 kann heute mehr leisten als teure Mittelklassekarten von 2025. Die GPU-Säule ist also das „schwere Gerät“ im Studio — die Fräsmaschine, die alles wegsägt, was Rechenlast bedeutet. Ohne sie ist eine ernsthafte Bildproduktion kaum möglich.
Säule 3: Ein zweites System für Audio, Voice & Nebenmodelle
Die dritte Säule wirkt unscheinbar, ist aber entscheidend: Ein kleineres, energieeffizientes System, das Nebenjobs übernimmt. Dazu gehören:
- TTS (Text-to-Speech)
- STT (Transkription)
- kleinere Modelle (4B, 7B, 8B, 14B)
- statische Hintergrundprozesse
- kleine Agentensysteme
- Tools, die man separat vom Hauptsystem betreiben möchte
Bei mir übernimmt das ein kleiner Mac mini M4 mit 32 GB RAM. Perfekt geeignet für:
- Whisper-Transkription
- Voice-Modelle
- leichte Optimierungsmodelle
- schnell reagierende Assistenten
- Experimente und Testläufe
- parallele Model-Container
Das entlastet das Hauptsystem enorm. Denn es ist sinnvoll, große Modelle nicht für jeden kleinen Job zu belasten. So wie man früher in der Werkstatt nicht für jeden Schnitt die große Kreissäge angeschmissen hat, sondern eine kleine Maschine genutzt hat. Die dritte Säule sorgt für Ordnung und Stabilität.
Sie trennt die großen Modelle von den kleinen Aufgaben – und das macht das ganze Studio langlebig, flexibel und ausfallsicher.
Intelligente Verteilung der Workloads
Ein KI-Studio lebt davon, dass jede Maschine das macht, wofür sie gebaut wurde. So ergibt sich eine logische Ordnung:
- Rechenkern → Denken, Schreiben, Übersetzen, Analysieren
- GPU-System → Bilder, Trainingsmodelle, ComfyUI, Video
- Nebensystem → Audio, Voice, kleine Modelle, Agenten
Wenn zusätzliche Software dazukommt — wie bei mir FileMaker als zentrale Steuerung — entsteht daraus eine echte Produktionspipeline. Nicht mehr Chaos, nicht mehr „mal gucken, wo noch Platz ist“, sondern ein geordnetes System, das jeden Tag stabil läuft.
Die drei Säulen sind das Fundament — nicht die Kür
Viele glauben, man bräuchte ein KI-Studio erst, wenn man ein „KI-Unternehmen“ ist. In Wahrheit ist es umgekehrt: Ein solides KI-Studio IST die Grundlage dafür, eines zu werden. Mit diesen drei Säulen hast Du alles, was Du brauchst, um:
- Content zu produzieren (Text & Bild)
- eigene Modelle anzulernen
- Workflows zu automatisieren
- unabhängig von der Cloud zu arbeiten
- eigene Lösungen für Kunden aufzubauen
- langfristig digital „workbenches“ zu betreiben
Für Unternehmer, Kreative, Self-Publisher und Entwickler ist das heute eine strategische Entscheidung, die Freiheit, Geschwindigkeit und Kontrolle langfristig sichert.
Sinnvolle Einstiegs-Hardware für ein kleines KI-Studio
Wenn man heute die Werbung verfolgt, könnte man glauben, man müsse ständig die allerneueste Hardware kaufen, um lokal mit KI arbeiten zu können. Doch das Gegenteil ist häufig der Fall: Nicht die neuesten Modelle sind entscheidend, sondern die richtige Kombination aus RAM, VRAM und Stabilität. Viele ältere Geräte – vor allem im GPU-Bereich – sind heute echte Preis-Leistungs-Monster. Und wer bereit ist, über den Tellerrand zu schauen, kann sich ein KI-Studio aufbauen, das einer kleinen Firma gerecht wird, ohne sich finanziell zu übernehmen. Genau das mache ich selbst gerade, und es funktioniert erstaunlich gut. Dieses Kapitel zeigt Dir drei Hardware-Klassen: Einsteiger, Standard und Profi. Und natürlich erkläre ich dabei auch, warum bestimmte ältere Systeme heute wertvoller sind als man denkt.
1. Einsteigerklasse (1500–2500 €)
Für alle, die lokal starten wollen – ohne große Investitionen. In dieser Klasse geht es darum, erste solide Schritte zu machen:
- Mac mini M2 oder M4 mit 16–32 GB RAM
- oder ein PC mit RTX 3060/3070 (12–16 GB VRAM)
- plus optional eine kleine NAS oder externe SSD
Damit lassen sich gut:
- 7B bis 14B Modelle betreiben
- lokale Übersetzungen durchführen
- Whisper laufen lassen
- kleinere Bildmodelle wie SD 1.5/2.1 nutzen
- ComfyUI in reduzierter Form ausprobieren
- eigene Agenten oder Workflows testen
Für viele Kreative oder Selbständige ist das mehr als genug, um produktiv zu werden. Wichtig ist, dass man den Einstieg nicht überkompliziert. Die größte Gefahr ist nicht, zu wenig Leistung zu haben – sondern sich in zu viele technische Details zu verrennen. Mit einem Mac mini M4 beispielsweise kann man wahnsinnig viel machen: Übersetzungen, Recherche, Struktur, sogar kleinere Schreibmodelle – und das bei minimalem Stromverbrauch.
2. Standardklasse (2500–4000 €)
Der Sweet Spot für ernsthaftes Arbeiten mit Texten und Bildern. Hier beginnt das, was ich als “echtes KI-Studio“ bezeichnen würde: Ein Setup, das sowohl große Textmodelle als auch solide Bildmodelle bedienen kann. Typische Kombination:
- Mac Studio M1 Ultra oder M2 Max mit 64 GB RAM
- PC/GPU-Workstation mit RTX 3080, 3090 oder 3090 Ti
- optional ein kleiner zusätzlicher Rechner für Audio oder Voice
Mit dieser Klasse lassen sich:
- 20–40B Modelle zuverlässig fahren
- Stable Diffusion XL in guter Qualität nutzen
- LoRA-Training im mittleren Datensatzbereich durchführen
- parallele Workloads auf mehreren Geräten verteilen
- Automatisierungen aufbauen (z. B. via FileMaker)
Und hier zeigt sich eine interessante Wahrheit: Ältere GPUs wie die RTX 3090 schmettern viele neue Mittelklassekarten noch immer in Grund und Boden. Warum? Sie haben mehr VRAM (24 GB), während neue Karten oft kastriert wurden. Sie besitzen ein breites Speicherinterface, ideal für breite Diffusion-Modelle. Sie haben reife und stabile CUDA-Treiber. Sie werden gebraucht oft für erstaunliche Preise verkauft. Eine 3090 kann für 700–900 € gebraucht mehr leisten als eine aktuelle 4070 oder 4070 Ti für 1100 € – einfach, weil VRAM und Speicheranbindung wichtiger sind als ein paar Prozent Rohleistung.
3. Profi-Klasse (4000–8000 €)
Für alle, die ernsthaft produzieren – und vollständige Unabhängigkeit anstreben. In dieser Klasse steht echte Produktionspower zur Verfügung. Typisches Setup:
- Mac Studio M1 / M2 / M3 Ultra mit 128 GB RAM oder mehr
- PC-GPU-System mit RTX 3090 oder 4090
- ein zweiter Rechner für Audio/Agenten
- optional FileMaker Server als Automationszentrale
Damit lassen sich:
- 70B Modelle flüssig nutzen
- MoE-Modelle wie GPT-OSS 120B stabil betreiben
- parallele KI-Agenten koordinieren
- SDXL, Video-KI, ComfyUI in Vollauslastung betreiben
- LoRA-Trainings mit 896×896 oder 1024×1024 fahren
- eigene Datenbanken für Trainings vorbereiten
- vollständige Pipelines (Prompts → Bilder → PDFs → Bücher) abbilden
Und genau hier sieht man das Spannendste: Die beste KI-Hardware 2025 ist oft gebrauchte Premium-Hardware der Jahre 2020–2022. Warum? Sie war damals für High-End-Workloads entwickelt. Sie hat heute einen Bruchteil des Preises. Die Technik ist ausgereift. Keine Beta-Treiber-Probleme. Sie besitzt genau die Eigenschaften, die KI braucht: viel VRAM, breite Speicherbusse, stabile Tensor-Kerne.
Warum man mit zu wenig VRAM scheitert – und nicht mit zu wenig GPU-Power
Das ist ein Punkt, den viele unterschätzen: VRAM ist für Bild-KI der entscheidende Faktor, nicht reine Leistung. Beispiele:
- Eine RTX 4060 (8 GB VRAM) ist praktisch unbrauchbar für SDXL.
- Eine RTX 4070 Ti (12 GB VRAM) reicht nur unzuverlässig fürs Training.
- Eine RTX 3090 (24 GB VRAM) läuft dagegen jahrelang souverän.
Kurz gesagt: Große Modelle brauchen Speicher – kein Marketing. Und Speicher ist das, was ältere High-End-Karten haben und neue Mittelklassekarten nicht.
Wie man ein KI-Studio modular ausbauen kann
Der größte Vorteil eines Studios in drei Säulen ist die Modularität:
- Man kann die GPU-Workstation unabhängig upgraden.
- Man kann den Mac Studio über Jahre behalten.
- Man kann den Nebenrechner tauschen, ohne das System zu stören.
- Man kann die Festplatten oder SSDs getrennt erweitern.
- Man kann FileMaker, Python oder Bash als Orchestrierung nutzen.
Das ist wie bei einer Werkstatt: Man baut nicht alles gleichzeitig um, sondern immer nur das, was gerade nötig ist.
Lokale KI ist jetzt WIRKLICH brauchbar (und auf dieser Hardware läuft sie) | c’t 3003
Empfehlungen für 2025 — Diese Hardware lohnt sich wirklich
Im Dschungel der Werbung und Spezifikationen kann man schnell den Überblick verlieren. Doch für KI-Nutzung im Heimbereich oder kleinen Studio gibt es Hardwareklassen, die 2025 besonders sinnvoll sind — weil sie ein gutes Preis-Leistungs-Verhältnis liefern, robust sind und für aktuelle Modelle ausreichen. Worauf es heute ankommt:
- Genügend VRAM (für GPU-Tasks): Für Bild-KI, Trainingsläufe, Stable Diffusion & Co. sollte eine Grafikkarte mindestens 16 GB, besser 24 GB VRAM haben. Ab dieser Schwelle wird Bild-KI komfortabel und stabil.
- Guter Arbeitsspeicher und RAM-Kapazität (für LLMs): Für große LLMs, Multitasking mit Serverdiensten und parallele Prozesse ist möglichst viel RAM sinnvoll — bei Apple-Silicon idealerweise 64–128 GB.
- Stabile, bewährte Hardware statt neuester Marketing-Ware: Gerade ältere High-End-Karten haben oft hervorragende Spezifikationen (VRAM, Speicherbus, Treiberreife) bei moderatem Preis.
- Modularität und Mischung statt Monoblock: Kombination aus LLM-Rechner, GPU-Workstation und Neben-/Agentensystem ist flexibler und langlebiger als eine einzelne „All-in-one“-Maschine.
| Klasse | Typische Komponenten | Für wen geeignet | Stärken / Kompromisse |
|---|---|---|---|
| Einstieg (ca. 1.500–2.500 €) | Mac mini (16–32 GB RAM) oder PC mit GPU (z. B. RTX 3060 / 3060 Ti / 4060 Ti mit ≥ 12–16 GB VRAM) | Hobby, erste Experimente, kleine Modelle, überschaubare Bild-KI | Günstiger Einstieg, ausreichend für kleinere LLMs, leichte Stable-Diffusion-Workflows und Audio-/Text-KI. Einschränkungen bei großen Modellen, komplexen ComfyUI-Pipelines und LoRA-Training. |
| Standard (ca. 2.500–4.000 €) | Mittelklasse-GPU-Workstation (z. B. mit RTX 3080 oder RTX 3090), Rechner mit 64 GB RAM | Kreative, Self-Publisher, ambitionierte KI-Nutzer, kleine Teams | Solide Leistung für Texte & Bilder, gutes Preis-Leistungs-Verhältnis. Genug VRAM und RAM für vielseitige KI-Nutzung, inkl. SDXL und ersten LoRA-Trainings. Bei extremen Projekten oder vielen parallelen Workflows stößt das System irgendwann an Grenzen. |
| Profi / Studio (ca. 4.000–8.000 €) | Hoch-RAM-System (z. B. Mac Studio mit 128 GB RAM oder starke Linux-Workstation) + GPU mit ≥ 24 GB VRAM (z. B. RTX 3090, 4090) + separates Neben-/Agentensystem | Selbständige, Verlage, Medien-Produktionen, Entwickler mit mehreren Projekten, kleine KI-Studios | Maximale Flexibilität, große Modelle (70B, MoE), Bild- und Text-KI parallel, Automatisierungen und Langläufer-Workflows. Sehr zukunftssicher, aber höhere Anfangsinvestition und etwas mehr Planungsaufwand beim Aufbau. |
Warum gebrauchte und ältere High-End GPUs heute oft besser sind als neue Mittelklassekarten
Viele neuere Karten werden mit begrenztem VRAM angeboten — für KI aber entscheidend. Ältere High-End-Modelle wie die RTX 3090 bringen häufig 24 GB VRAM, was heute für SDXL, LoRA-Training oder Video-KI sehr wertvoll ist. Die Hardware war ursprünglich auf Leistung und Stabilität ausgelegt — mit hochwertigen Komponenten, Speicherbus, Kühlung und guter Treiber-Unterstützung.
Das heißt: Langlebigkeit und robuste Performance sind oft vorhanden. Gebrauchte Karten sind oft deutlich günstiger und damit sehr preis-leistungsstark — ideal für Selbständige oder kleine Studios mit begrenztem Budget.
Meine aktuelle Empfehlung 2025 (und warum)
Wenn ich heute ein Studio aufbauen würde und nicht auf maximale Supercomputer-power abzielen würde, würde ich entscheiden:
- Für Bild-KI: mindestens eine GPU mit 24 GB VRAM — z. B. RTX 3090 oder 4090.
- Für Text/LLM: 128 GB RAM in einem leistungsfähigen Apple-Silicon-System.
- Für Nebenjobs (Audio, Voice, kleine Modelle, Automation): ein kleiner, separater Rechner (z. B. Mini-PC oder günstiger Server).
- Für Koordination: eine Software-Schicht — bei mir ist das FileMaker, bei anderen könnte es eine einfache Shell- oder Python-Pipeline sein.
Dieses Setup ist nicht übertrieben, nicht abhängig von teuren Cloud-Lizenzen — und reicht für fast alles, was man 2025 im Kreativ-, Publishing- oder Entwicklungsbereich mit KI machen kann.
Die Hardware für KI muß nicht neu, sondern passend sein
Heute endet die Zeit, in der „KI“ nur etwas für große Konzerne oder Cloud-Labore war. Mit dem Stand von 2025 kann fast jeder — mit überschaubarem Budget und ein wenig technischem Verständnis — ein eigenes kleines KI-Studio aufbauen. Das macht Dich unabhängig von teuren Monatsabos, fremden Datenschutzbedingungen, Warteschlangen, Serverengpässen und von der Ungewissheit, wie lange Cloud-Dienste noch existieren. Stattdessen bekommst Du:
- volle Kontrolle über Deine Daten und Deine Workflows,
- stabile, schnelle und skalierbare Performance,
- eine nachhaltige Investition, die Jahre hält,
- und die Freiheit, kreativ zu sein, wann und wie Du willst — ohne externe Limitierungen.
Also: Wenn Du mit dem Gedanken spielst, KI für Deine Bücher, Texte, Bilder oder deine Projekte zu nutzen — dann lohnt sich der Aufbau eines eigenen Studios mehr denn je. Man muss kein Hardware-Ingenieur sein. Man braucht kein Riesenbudget. Man braucht nicht die neueste Hardware.
Man braucht vor allem klare Vorstellung, mit welchem Ziel man arbeitet — und den Willen, Kontrolle über die eigenen Prozesse zu behalten.
Wie Du mit Ollama ein lokales LLM auf einem Mac installierst, zeige ich in diesem Artikel.
Hier findest Du einen Vergleich von Apple MLX auf Silicon vs. NVIDIA.
Wie Du mit Qdrant ein lokales Gedächtnis für Deine lokale KI einrichten kannst, findet Du hier.

Häufig gestellte Fragen
- Warum lohnt sich ein eigenes KI-Studio überhaupt, wenn es doch so viele Cloud-Anbieter gibt?
Ein eigenes KI-Studio macht Dich unabhängiger, stabiler und langfristig günstiger. Cloud-Dienste sind bequem, aber sie kosten jeden Monat Geld, erzeugen Abhängigkeit und sind oft durch Nutzungsbeschränkungen limitiert. Lokale KI ist schnell, dauerhaft verfügbar und kann ohne variable Kosten genutzt werden. Außerdem bleiben alle Daten im eigenen Haus – ein enormer Vorteil für Selbständige, Unternehmen, Verlage oder kreative Berufe. - Welche Hardware brauche ich mindestens, um mit KI lokal zu starten?
Für den Einstieg reicht bereits: ein Mac mini mit 16–32 GB RAM oder ein PC mit einer GPU mit mindestens 12 GB VRAM. Damit kannst Du kleine Sprachmodelle, leichte Bildmodelle und erste Automationen ausführen. Wer nur ausprobieren will, muss nicht gleich mehrere Tausend Euro investieren. - Brauche ich zwingend einen Mac Studio oder geht es günstiger?
Es geht definitiv günstiger. Ein Mac Studio lohnt sich, wenn Du große Sprachmodelle (20–120B) betreiben willst, viel parallel arbeitest oder langfristige Produktionsprozesse hast. Für erste Schritte ist ein Mac mini oder ein solider Windows-PC völlig ausreichend. Ein Studio ist eine Komfort- und Zukunftsinvestition – aber kein Muss. - Warum ist VRAM bei Bild-KI wichtiger als eine moderne Grafikkarten-Generation?
Weil Bildmodelle wie Stable Diffusion riesige Datenmengen durch den Speicher schaufeln. Wenn der VRAM nicht ausreicht, bricht der Prozess ab oder wird extrem langsam. Eine ältere Karte wie die RTX 3090 mit 24 GB VRAM schlägt oft neue Mittelklassemodelle mit nur 8–12 GB VRAM – einfach, weil sie mehr Platz für große Modelle und Trainingsläufe bietet. - Kann ich ein KI-Studio komplett mit Apple-Hardware ohne NVIDIA betreiben?
Für Sprachmodelle ja. Für Bild-KI nein. Apple-Silicon ist bei LLMs extrem effizient, aber für Stable Diffusion, LoRA-Training und viele Bildmodelle sind NVIDIA-Karten (wegen CUDA/Tensor-Cores) weiterhin die Referenz. Daher nutzen viele Studios eine Mischform aus Apple/LLM und Linux+NVIDIA für Bilder. - Reicht auch eine RTX 4080 oder 4070 Ti für Bild-KI?
Theoretisch ja – praktisch kommt es auf den Einsatzzweck an. Für einfache Bilder oder kleine Workflows reicht das. Aber für SDXL, komplexe ComfyUI-Pipelines oder LoRA-Training stößt die 12–16 GB VRAM-Grenze schnell an ihre Limits. Eine RTX 3090 oder 4090 ist deshalb langfristig sinnvoller. - Warum betreibt man Sprachmodelle nicht auf der GPU, sondern auf dem RAM?
Sprachmodelle sind speicherorientiert. Sie müssen große Mengen Text und Kontext im RAM halten, nicht unbedingt grafische Operationen durchführen. GPUs sind für Bildverarbeitung gebaut, nicht für Textanalyse. Deshalb profitieren LLM-Systeme enorm von viel RAM, weniger aber von VRAM. - Wie viel RAM sollte ein LLM-Rechner haben?
Für kleinere Modelle reichen 32–64 GB. Für mittlere Modelle (20–30B) sind 64–128 GB ideal. Für große Modelle wie 70B oder MoE-Modelle wie GPT-OSS 120B sind 128–192 GB RAM optimal. Je mehr RAM, desto stabiler und schneller läuft alles. - Kann man ein KI-Studio komplett ohne Linux betreiben?
Ja – aber mit Einschränkungen. macOS ist perfekt für LLMs, aber für Bild-KI fehlen einige Werkzeuge, die nur unter Linux/NVIDIA existieren. Windows funktioniert für Bild-KI gut, ist aber weniger stabil und schwerer zu automatisieren. Die pragmatische Mischung lautet daher oft: macOS → LLM, Linux → Bild-KI, kleiner Rechner → Audio/Skripte - Wie laut ist so ein KI-Studio im Betrieb?
Weniger als man denkt. Ein Mac Studio arbeitet praktisch lautlos. Ein Linux-PC hängt von der Kühlung ab – hochwertige GPUs sind bei geringer Last ruhig, können bei Trainingsläufen aber hörbar werden. Wer Silent-Builds bevorzugt, kann wassergekühlte GPU-Workstations nutzen. - Welche Rolle spielt der Mac mini als dritter Baustein?
Er dient als Nebenstation für Transkription, TTS, kleine KI-Modelle, Hintergrundprozesse, Automationen sowie Nebenjobs bei Übersetzungen. Das hält die beiden großen Maschinen frei und sorgt für stabile Workflows. Ein dritter Rechner ist nicht zwingend nötig, aber er schafft Ordnung und Zuverlässigkeit. - Kann ich mein KI-Studio nach und nach ausbauen?
Unbedingt. Das ist sogar der Idealfall. Ein LLM-System kaufen, anschließend eine GPU-Workstation ergänzen und später einen kleinen Nebenrechner – das ist ein sehr natürlicher Aufbau, der sich über Monate oder Jahre strecken lässt. KI-Studios wachsen genauso wie klassische Werkstätten. - Welche Betriebssysteme sind für ein KI-Studio am besten geeignet?
– macOS → optimal für LLM und Apple-Silicon-Modelle
– Linux (Ubuntu, Debian) → beste Wahl für Bild-KI, ComfyUI, Stable Diffusion
– Windows → funktioniert für SD/ComfyUI gut, aber weniger ideal für Automationsprozesse
Viele Studios nutzen heute kombinierte Setups – jedes System macht das, wofür es am besten geeignet ist. - Wie viel Strom verbraucht ein KI-Studio?
Ein Mac Studio ist erstaunlich effizient und liegt meist zwischen 50–100 W. Eine GPU-Workstation mit RTX 3090 kann 250–350 W ziehen, je nach Last. Ein Mac mini liegt bei rund 10–30 W. Insgesamt also deutlich weniger als man befürchten könnte – und oft günstiger als Cloud-Abos. - Ist es schwierig, ein KI-Studio selbst einzurichten?
Nicht wirklich. Man braucht etwas technisches Verständnis, aber kein Informatikstudium. Viele Tools haben heute Web-Oberflächen, Installationsskripte und automatische Konfigurationen. Und wenn man die Systeme klar trennt (LLM / GPU / Nebenjobs), bleibt alles übersichtlich. - Kann ich damit wirklich komplette Publikationsprozesse abdecken?
Ja – und genau dafür eignet sich ein KI-Studio hervorragend. Von Buchideen über Texte, Cover-Entwürfe, Bildserien, Korrekturen, Übersetzungen bis hin zur finalen Druck- oder E-Book-Datei lässt sich vieles automatisieren und im eigenen Haus produzieren. Für Self-Publisher ist das eine enorme Freiheit. - Wie zukunftssicher ist ein KI-Studio heute?
Sehr. LLMs werden effizienter, Bildmodelle modulares, Hardware langlebiger – und lokale KI wird im Markt wieder wichtiger, weil Cloud-Gesetze, Datenschutz und Kosten die Cloud unattraktiver machen. Wer heute in ein kleines KI-Studio investiert, baut eine Infrastruktur, die 2026–2030 eher wichtiger statt veralteter wird. - Kann man die KI-Modelle später trainieren oder erweitern?
Ja. Mit einem GPU-System (z. B. RTX 3090 oder 4090) lassen sich LoRA-Trainings, Stil-Trainings, Material-Trainings und Prozess-Trainings durchführen. Das bedeutet: Man kann sich über die Zeit seine eigene „KI-Bildsprache“ oder „KI-Textrichtung“ antrainieren. Das ist der größte strategische Vorteil eines KI-Studios: Du wirst unabhängig von generischen Modellen und gestaltest Deinen eigenen Stil.