
Chiunque lavori con l'IA oggi è quasi automaticamente spinto nel cloud: OpenAI, Microsoft, Google, qualsiasi interfaccia web, token, limiti, termini e condizioni. Questo sembra moderno, ma è essenzialmente un ritorno alla dipendenza: altri determinano quali modelli si possono usare, con quale frequenza, con quali filtri e a quale costo. Io sto deliberatamente andando nella direzione opposta: attualmente sto costruendo il mio piccolo studio di IA a casa. Con il mio hardware, i miei modelli e i miei flussi di lavoro.
Il mio obiettivo è chiaro: IA locale per i testi, IA locale per le immagini, apprendimento dei miei modelli (LoRA, fine-tuning) e tutto questo in modo tale che io, come libero professionista e in seguito anche cliente di una PMI, non dipenda dai capricci quotidiani di qualche fornitore di cloud. Si potrebbe dire che è un ritorno a un vecchio atteggiamento che una volta era abbastanza normale: „Le cose importanti le fai da solo“. Solo che questa volta non si tratta del proprio banco di lavoro, ma della potenza di calcolo e della sovranità dei dati.




Ultime notizie sull'intelligenza artificiale e sull'hardware locale
06.05.2026Apple sta apparentemente riducendo ulteriormente la selezione dei suoi Mac desktop più potenti. Come riferisce Heise, diverse configurazioni di RAM precedentemente disponibili per il Mac mini Apple e il Mac Studio Apple stanno scomparendo dalla gamma o sono ora difficilmente disponibili. I modelli con elevate capacità di memoria, che di recente sono diventati particolarmente interessanti per le applicazioni AI locali, sono particolarmente colpiti. Secondo quanto riportato, le varianti di Mac mini con 32 GB e 64 GB di RAM e le configurazioni di Mac Studio con 128 GB o 256 GB di RAM saranno eliminate. Apple aveva già cancellato in precedenza l'opzione con 512 GB di RAM per il Mac Studio. Allo stesso tempo, i tempi di consegna per le altre varianti stanno aumentando in modo significativo. Gli osservatori sospettano che si tratti di un mix tra l'elevata domanda di carichi di lavoro AI, la possibile carenza di memoria e la preparazione dei nuovi modelli M5. Soprattutto nel settore dei modelli di IA locali, sta diventando sempre più chiaro quanto le strategie hardware siano fortemente orientate ai crescenti requisiti dei moderni software di IA.
04.05.2026Apple ha cancellato l'ingresso più economico nel mondo dei Mac desktop fino ad oggi: Il Il modello di Mac mini con SSD da 256 GB non è più disponibile. In futuro, la configurazione partirà solo da 512 GB di memoria, aumentando il prezzo entry-level a circa 949 euro. A prima vista, questa decisione sembra un aggiustamento minore del prodotto, ma mostra una chiara linea strategica: Apple sta spostando la base verso l'alto e si concentra maggiormente su configurazioni minime più potenti.
Per gli utenti che operano nel settore dell'intelligenza artificiale, ad esempio quando lavorano localmente con modelli, embeddings o strumenti come MLX, questo è perfettamente comprensibile, poiché 16 GB di memoria unificata e 256 GB di storage raggiungono rapidamente i loro limiti. Allo stesso tempo, però, si elimina il punto di ingresso nell'ecosistema Mac che prima era a bassa soglia. La mossa si inserisce in un quadro più ampio: l'aumento dei requisiti hardware dovuto ai carichi di lavoro dell'intelligenza artificiale e la crescente attenzione verso sistemi più potenti invece che verso prezzi minimi entry-level. Per gli utenti, questo significa maggiori riserve di prestazioni a lungo termine, ma maggiori costi di investimento a breve termine.
11.04.2026Un recente episodio di „Inside AI“ del Fraunhofer IEM fornisce una panoramica compatta dei principali sviluppi nel campo dell'IA. L'esperto di IA Tommy Falkowski analizza i nuovi approcci ai modelli linguistici di grandi dimensioni, come i cosiddetti modelli linguistici ricorsivi, e i progressi nella generazione di video IA. Un'altra attenzione sarà rivolta ai sistemi basati su agenti e ai metodi più efficienti per l'elaborazione di grandi quantità di dati. Di particolare rilevanza pratica è la crescente importanza delle infrastrutture locali di IA, che diventano sempre più potenti e aprono nuove possibilità di applicazione - un aspetto che gioca un ruolo decisivo anche nella scelta dell'hardware adatto.

Alimentazione a pressione dell'AI: le tendenze, gli strumenti e i modelli più importanti dell'AI per il 2026 | INSIDE AI #33 | Fraunhofer IEM
Inoltre, vengono presentati gli strumenti, i modelli e le tecnologie attuali che stanno cambiando l'ingegneria e l'applicazione dell'IA nel lungo periodo. Allo stesso tempo, viene mostrato il dinamismo con cui il campo si sta sviluppando: I nuovi modelli open source e gli annunci recenti sottolineano che le tendenze principali continuano a cambiare in un breve lasso di tempo.
La velocità rimane imbattibile a livello locale
I modelli cloud sono impressionanti - finché la linea è attiva, i server non sono sovraccarichi e l'API non viene strozzata di nuovo. Ma chiunque lavori seriamente con l'intelligenza artificiale si rende subito conto che la forma più onesta di velocità è quella locale. Se un modello gira sul vostro Mac Studio o sulla vostra GPU, allora è vero:
- Nessuna latenza di rete
- Nessun tempo di attesa in attesa che „gli altri“ siano pronti.
- Nessuna cancellazione oraria
- Nessun „Limite di velocità raggiunto“ nel mezzo del flusso di lavoro
Lo sperimento ogni giorno: sul mio Mac Studio gestisce un modello da 120B (GPT-OSS) e un modello Gemma da 27B in parallelo, oltre a un server FileMaker e a tutti i miei database. Ciononostante, il sistema rimane così reattivo che posso lavorare a una velocità quasi impossibile da raggiungere con i sistemi cloud. Soprattutto quando si eseguono molte piccole operazioni di seguito - traduzioni, riformulazioni, analisi, richieste di immagini - i ritardi si accumulano rapidamente. L'intelligenza artificiale locale non è come un „funzionamento del server“, ma come uno strumento diretto: si preme e si fa.
Sovranità dei dati: quando le informazioni sensibili non appartengono all'online
Un punto che spesso viene messo da parte, ma che è fondamentale per gli imprenditori: i dati. Non appena si utilizza l'IA nel cloud, è inevitabile porsi delle domande:
- Posso inserire lì i dati dei clienti?
- Cosa succede ai documenti interni?
- Per quanto tempo vengono conservati i registri?
- Chi ha teoricamente accesso, oggi e tra due anni?
- Quali conseguenze legali avrebbe una fuga di notizie?
Naturalmente, i grandi fornitori promettono di proteggere i dati. Ma alla fine della giornata, state consegnando i vostri contenuti. E questo è esattamente ciò che si voleva evitare in passato nella propria azienda: Le cose interne rimangono interne. In uno studio di AI locale, la situazione è diversa:
- I dati rimangono nella propria rete.
- Nessuna richiesta esce di casa.
- I modelli funzionano senza accesso a Internet.
- I registri, i dati di allenamento e i risultati intermedi vengono memorizzati sui dischi personali.
Quando in futuro farò passare i miei libri, articoli, appunti, testi di PR, documenti strategici interni o dati dei clienti attraverso la mia IA, voglio essere sicuro che nessuno di essi finisca nel set di addestramento di qualcun altro. Posso avere questa fiducia solo se l'infrastruttura appartiene a me.
Controllo dei costi invece di abbonamenti striscianti
Le IA cloud sembrano a prima vista poco costose: pochi centesimi per 1.000 gettoni, un abbonamento mensile qui, una piccola tariffa là. Il problema è che i costi aumentano con il successo. Più si diventa produttivi, più l'infrastruttura diventa costosa, ogni mese. L'intelligenza artificiale locale funziona in modo diverso:
- Si investe una volta sola nell'hardware.
- Poi eseguite i modelli quanto e quanto spesso volete.
- Non c'è „il dito che ordina“ perché ogni chiamata costa.
- Si può sperimentare più liberamente senza dover calcolare ogni input.
Ho acquistato la mia RTX 3090 di seconda mano per circa 750 euro, praticamente come nuova. Ho preso il mio Mac Studio con 128 GB di RAM per circa 2.750 euro, nella sua confezione originale e mai aperto. Sono soldi, sì, ma:
- Queste macchine mi accompagneranno per molti anni.
- Si creano asset direttamente utilizzabili: libri, articoli, immagini, LoRA, flussi di lavoro.
- Non comportano costi mensili aggiuntivi, a parte l'elettricità.
Per un editore, un consulente, uno sviluppatore o una piccola azienda, questo può fare la differenza tra „Dobbiamo calcolare se possiamo permettercelo“ e „Useremo l'IA solo quando ne avremo bisogno“.
Vecchie virtù, nuovi vantaggi: Perché possedere macchine proprie è di nuovo conveniente
In passato si dava per scontato che un artigiano disponesse di buoni strumenti nel proprio laboratorio. Un laboratorio di falegnameria senza un banco da lavoro e delle seghe adeguate sarebbe stato impensabile. Oggi ci siamo abituati al contrario: invece di possedere macchine proprie, noleggiamo servizi. Uno studio di AI interno non è altro che una versione moderna della classica officina:
- Il Mac Studio è il motore centrale per i modelli linguistici.
- Il Scheda grafica RTX è la fresatrice per immagini e formazione.
- A Computer aggiuntivo (ad esempio, Mac mini) si occupa di compiti speciali come la voce o i modelli di piccole dimensioni.
- Un software come FileMaker funge da pannello di controllo: orchestra, salva e documenta.
Sto costruendo un impianto di questo tipo perché voglio essere in grado di fare tutto da solo a lungo termine:
- Scrivere e tradurre libri,
- Generare serie di immagini,
- formare i propri modelli LoRA,
- Automatizzare i flussi di lavoro,
- e in seguito anche offrire ai clienti soluzioni che possono essere eseguite completamente a livello locale.
Non si tratta di nostalgia, ma di una decisione sobria: più l'IA interviene nella vita quotidiana, più è sensato mantenere il controllo sulla tecnologia. L'IA locale non è l„“alternativa hobbistica" al cloud di lusso, ma un ritorno consapevole all'indipendenza:
- Si guadagna velocità.
- I dati vengono conservati.
- Controllate i vostri costi.
- Costruite un'infrastruttura che vi appartiene.
Se ci pensate bene fino in fondo, uno studio di IA a casa diventa sempre più simile a un classico laboratorio ben attrezzato: Non ci si affida a ciò che gli altri fanno sullo sfondo, ma si costruisce una propria base stabile.
Indagine attuale sui sistemi di intelligenza artificiale locali
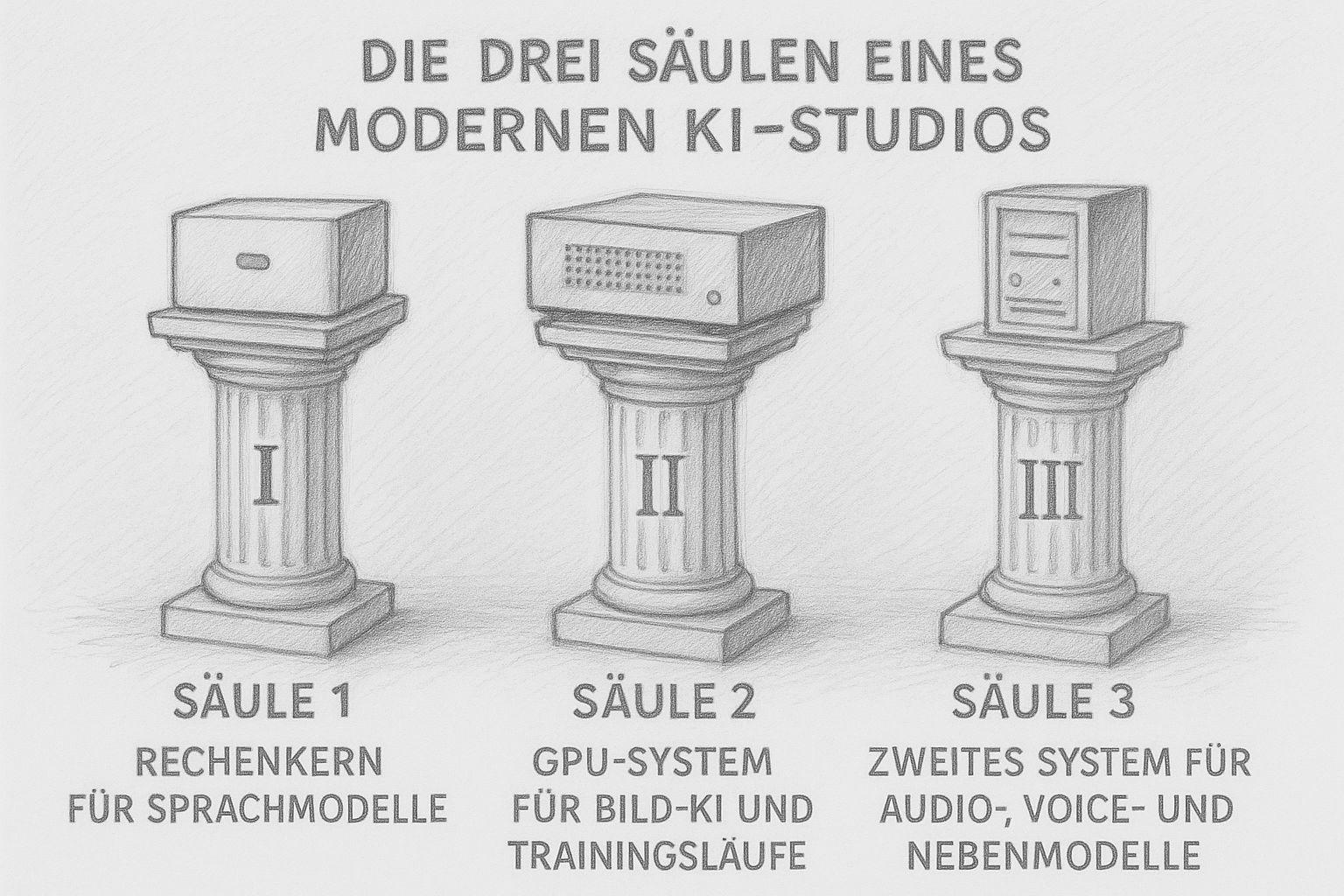
I tre pilastri di un moderno studio di IA
Oggi uno studio di intelligenza artificiale non consiste più in un „grande computer“ che fa tutto. I flussi di lavoro moderni hanno bisogno di forze diverse: potenza di calcolo per i testi, molta VRAM per le immagini e le esercitazioni, e sistemi più piccoli che si occupano di lavori secondari. Il risultato non è una flotta caotica di dispositivi, ma una piccola infrastruttura ben studiata, come un'officina ben attrezzata del passato, dove ogni macchina svolge il suo compito.
Io stesso costruisco il mio studio seguendo esattamente questo principio. E più approfondisco la questione, più diventa chiaro: Tre pilastri sono sufficienti per gestire una produzione AI completa a livello locale.
Pilastro 1: il kernel di calcolo per i modelli linguistici (LLM)
Oggi i modelli linguistici di grandi dimensioni non richiedono più un server di un centro dati, ma soprattutto una cosa: una grande quantità di RAM molto veloce. Questo è esattamente ciò che possono fare i moderni sistemi Apple-Silicon o le macchine Linux con equipaggiamento simile e molta RAM. Il nucleo di calcolo è il fulcro dello studio. È qui che gira:
- LLM di grandi dimensioni (20B, 30B, 70B, 120B MoE ...)
- Modelli di analisi
- Modelli di traduzione
- Interno Sistemi di conoscenza (neo4j, RAG)
- anche a lungo termine Memoria supportata dall'intelligenza artificiale
- Sistemi di controllo come n8n
- FileMaker-Processi di automazione e server
Nella mia configurazione, il Mac Studio M1 Ultra con 128 GB di RAM assume questo ruolo. E lo fa incredibilmente bene. Ci corro sopra:
- GPT-OSS 120B MoE (per riflessioni profonde, testi lunghi e analisi)
- Gemma-3 27B (per il lavoro tecnico come le cose FileMaker, il codice, la strutturazione precisa)
- Server FileMaker + database
- oltre all'intera infrastruttura di shell e web server
La cosa incredibile è che anche con due modelli di grandi dimensioni contemporaneamente, rimangono liberi 10-15 GB di RAM. Questo è il vantaggio di un'architettura completamente progettata per la memoria unificata. In poche parole: il nucleo di calcolo è il cervello dello studio AI. Tutto ciò che comprende, genera o trasforma il testo avviene qui.
Pilastro 2: il sistema di GPU per l'IA delle immagini e l'esecuzione di training
Il secondo pilastro è una workstation con GPU, ottimizzata per la formazione Stable Diffusion, ComfyUI, ControlNet e LoRA. Mentre i modelli testuali richiedono principalmente RAM, l'IA delle immagini ha bisogno di VRAM. E molto. Perché? Perché i modelli d'immagine scaricano in memoria quantità gigantesche di dati per ogni fotogramma. Ed è per questo che le schede grafiche sono costruite. Nel mio studio, questo compito è svolto da una NVIDIA RTX 3090 con 24 GB di VRAM - e questi 24 GB valgono oro. Permettono:
- SDXL con lotti di dimensioni ragionevoli
- Flussi di lavoro ComfyUI
- Sintesi video
- Serie di immagini
- Formazione sui materiali e sullo stile
- Formazione LoRA con 896×896 o addirittura 1024×1024
Per l'IA delle immagini, la VRAM è più importante del chip più recente. Una solida 3090 può fare di più oggi che le costose schede di fascia media del 2025. La colonna della GPU è quindi l„“equipaggiamento pesante" dello studio, la fresa che taglia via tutto ciò che significa carico di calcolo. Senza di essa, la produzione di immagini serie è difficilmente possibile.
Pilastro 3: un secondo sistema per l'audio, la voce e i modelli secondari
Il terzo pilastro può sembrare poco appariscente, ma è fondamentale: un sistema più piccolo ed efficiente dal punto di vista energetico che si occupa di lavori secondari. Questi includono:
- TTS (Text-to-Speech)
- STT (trascrizione)
- modelli più piccoli (4B, 7B, 8B, 14B)
- statico Processi di base
- piccolo Sistemi ad agenti
- Strumenti, che si desidera far funzionare separatamente dal sistema principale
Utilizzo un piccolo Mac mini M4 con 32 GB di RAM. Perfettamente adatto per:
- Sussurro-Trascrizione
- Voce-Modelli
- luce Modelli di ottimizzazione
- reazione rapida Assistenti
- Esperimenti e Esecuzioni di prova
- parallelo Modello di contenitore
Questo alleggerisce enormemente il sistema principale. Dopo tutto, ha senso non caricare modelli di grandi dimensioni per ogni piccolo lavoro. Proprio come in passato non si accendeva la grande sega circolare per ogni taglio in officina, ma si usava una macchina piccola. Il terzo pilastro garantisce organizzazione e stabilità.
Il sistema separa i grandi modelli dai piccoli compiti e rende l'intero studio resistente, flessibile e a prova di errore.
Distribuzione intelligente dei carichi di lavoro
Uno studio di intelligenza artificiale si basa sul fatto che ogni macchina fa ciò per cui è stata costruita. Ne consegue un ordine logico:
- Nucleo di calcolo → Pensare, scrivere, tradurre, analizzare
- Sistema GPU → Immagini, modelli di formazione, ComfyUI, video
- Sottosistema → Audio, voce, piccoli modelli, agenti
Quando si aggiungono altri software, come FileMaker come sistema di controllo centrale, si crea una vera e propria pipeline di produzione. Niente più caos, niente più „vediamo dove c'è ancora spazio“, ma un sistema organizzato che funziona in modo stabile ogni giorno.
I tre pilastri sono le fondamenta, non lo stile di vita libero.
Molti credono che sia necessario uno studio di IA solo quando si è una „azienda di IA“. In realtà, è vero il contrario: un solido studio di IA è la base per diventarlo. Con questi tre pilastri, avete tutto ciò che vi serve per:
- Produrre contenuti (testo e immagini)
- Insegnare i propri modelli
- Automatizzare i flussi di lavoro
- Lavorare in modo indipendente dal cloud
- sviluppare soluzioni proprie per i clienti
- gestire „banchi di lavoro“ digitali a lungo termine
Per gli imprenditori, i creativi, gli autopubblicatori e gli sviluppatori, questa è ormai una decisione strategica che garantisce libertà, velocità e controllo a lungo termine.
Un hardware di base ragionevole per un piccolo studio di IA
Guardando le pubblicità di oggi, si potrebbe pensare che sia necessario acquistare sempre l'hardware più recente per poter lavorare con l'intelligenza artificiale a livello locale. Tuttavia, spesso è vero il contrario: non sono gli ultimi modelli a essere decisivi, ma la giusta combinazione di RAM, VRAM e stabilità. Molti dispositivi più vecchi, soprattutto nel settore delle GPU, sono ormai dei veri e propri mostri in termini di prezzo e prestazioni. E se si è disposti a pensare fuori dagli schemi, è possibile costruire uno studio di intelligenza artificiale che renda giustizia a una piccola azienda, senza sovraccaricarsi finanziariamente. È esattamente quello che sto facendo io stesso in questo momento e sta funzionando sorprendentemente bene. Questo capitolo mostra tre classi di hardware: Principiante, Standard e Professionale. E, naturalmente, vi spiego anche perché alcuni vecchi sistemi sono oggi più validi di quanto possiate pensare.
1a classe di ingresso (1500-2500 €)
Per tutti coloro che vogliono iniziare a lavorare in loco, senza grandi investimenti. Questo corso è dedicato a come muovere i primi solidi passi:
- Mac mini M2 o M4 con 16-32 GB di RAM
- o un PC con RTX 3060/3070 (12-16 GB VRAM)
- e, facoltativamente, un piccolo NAS o esterno SSD
Questo è un buon modo per:
- Funzionamento dei modelli da 7B a 14B
- Eseguire traduzioni locali
- Eseguire il sussurro
- Utilizzare modelli di immagine più piccoli come SD 1.5/2.1
- Provate ComfyUI in forma ridotta
- Testate i vostri agenti o flussi di lavoro
Per molti creativi o lavoratori autonomi, questo è più che sufficiente per diventare produttivi. L'importante è non complicare troppo le cose. Il pericolo maggiore non è avere poca potenza, ma impantanarsi in troppi dettagli tecnici. Con un Mac mini M4, ad esempio, si può fare una quantità incredibile di cose: Traduzioni, ricerche, strutture, anche modelli di scrittura più piccoli - e con un consumo energetico minimo.
2a classe standard (2500-4000 €)
Il punto di forza per un lavoro serio con testi e immagini. È qui che inizia quello che definirei un “vero studio di IA“: una struttura in grado di gestire sia modelli di testo di grandi dimensioni sia modelli di immagini solide. Una combinazione tipica:
- Mac Studio M1 Ultra o M2 Max con 64 GB di RAM
- Stazione di lavoro PC/GPU con RTX 3080, 3090 o 3090 Ti
- facoltativamente un piccolo Computer aggiuntivo per l'audio o la voce
Con questo corso è possibile:
- Azionamento affidabile dei modelli 20-40B
- Utilizzare Stable Diffusion XL di buona qualità
- Eseguire l'addestramento LoRA nella gamma di set di dati medi
- Distribuire i carichi di lavoro paralleli su più dispositivi
- Impostare le automazioni (ad es. tramite FileMaker)
E questo rivela una verità interessante: le vecchie GPU come la RTX 3090 continuano a distruggere molte nuove schede di fascia media. Perché? Hanno più VRAM (24 GB), mentre le nuove schede sono state spesso castrate. Hanno un'interfaccia di memoria ampia, ideale per i modelli ad ampia diffusione. Hanno driver CUDA maturi e stabili. Vengono spesso vendute usate a prezzi incredibili. Una 3090 può fare di più per 700-900 euro usata che una 4070 o 4070 Ti attuale per 1100 euro, semplicemente perché la VRAM e la connettività della memoria sono più importanti di qualche centesimo di prestazioni grezze.
3a classe professionale (4000-8000 €)
Per tutti coloro che fanno sul serio con la produzione e puntano alla completa indipendenza. La vera potenza di produzione è disponibile in questa classe. Configurazione tipica:
- Mac Studio M1 / M2 / M3 Ultra con 128 GB o più di RAM
- Sistema PC-GPU con RTX 3090 o 4090
- a secondo computer per audio/agenti
- Server FileMaker opzionale come centro di automazione
Ciò consente di:
- Utilizzare i modelli 70B in modo fluido
- Funzionamento stabile dei modelli MoE come il GPT-OSS 120B
- Coordinare agenti AI paralleli
- SDXL, video AI, ComfyUI funzionano a pieno regime
- Eseguire le formazioni LoRA con 896×896 o 1024×1024
- Preparare i propri database per la formazione
- Mappare le condotte complete (prompt → immagini → PDF → libri)
Ed è qui che si nota l'aspetto più interessante: il miglior hardware per l'intelligenza artificiale del 2025 è spesso utilizzato come hardware premium del 2020-2022. Perché? È stato sviluppato per carichi di lavoro di fascia alta all'epoca. Il prezzo è una frazione di quello di oggi. La tecnologia è matura. Non ci sono problemi di driver beta. Ha esattamente le caratteristiche di cui l'IA ha bisogno: molta VRAM, bus di memoria ampi, core tensoriali stabili.
Perché si fallisce con poca VRAM e non con poca potenza della GPU
Questo è un punto che molti sottovalutano: La VRAM è il fattore decisivo per l'IA delle immagini, non le prestazioni pure. Esempi:
- Uno RTX 4060 (8 GB di VRAM) è praticamente inutilizzabile per SDXL.
- Uno RTX 4070 Ti (12 GB di VRAM) è solo inaffidabilmente sufficiente per l'allenamento.
- Uno RTX 3090 (24 GB di VRAM), invece, funziona senza problemi per anni.
In breve: i modelli di grandi dimensioni hanno bisogno di memoria, non di marketing. E la memoria è ciò che le vecchie schede di fascia alta hanno e le nuove schede di fascia media no.
Come espandere modularmente uno studio di IA
Il vantaggio principale di uno studio a tre pilastri è la sua modularità:
- La workstation GPU può essere aggiornata in modo indipendente.
- Potete tenere il Mac Studio per anni.
- È possibile scambiare il computer slave senza disturbare il sistema.
- È possibile espandere i dischi rigidi o le unità SSD separatamente.
- È possibile utilizzare FileMaker, Python o Bash come orchestrazione.
È come un'officina: Non si ricostruisce tutto allo stesso tempo, ma solo ciò che serve in quel momento.

L'intelligenza artificiale locale è ora DAVVERO utilizzabile (e funziona su questo hardware). c't 3003
Raccomandazioni per il 2025 - Questo hardware è veramente utile
È facile perdersi nella giungla di pubblicità e specifiche. Ma per l'uso dell'IA in casa o in un piccolo studio, ci sono classi di hardware che saranno particolarmente utili nel 2025, perché offrono un buon rapporto prezzo-prestazioni, sono robuste e sufficienti per i modelli attuali. Ciò che conta oggi:
- VRAM sufficiente (per le attività della GPU)Per l'IA delle immagini, l'allenamento, la diffusione stabile e così via, una scheda grafica dovrebbe avere almeno 16 GB, preferibilmente 24 GB di VRAM. Al di sopra di questa soglia, l'IA delle immagini diventa comoda e stabile.
- Buona memoria di lavoro e capacità RAM (per gli LLM): Per gli LLM di grandi dimensioni, che operano in multitasking con servizi server e processi paralleli, è opportuno disporre della massima quantità di RAM possibile, idealmente 64-128 GB per Apple-Silicon.
- Hardware stabile e collaudato invece di prodotti di marketing all'avanguardiaLe vecchie schede di fascia alta, in particolare, hanno spesso specifiche eccellenti (VRAM, bus di memoria, maturità dei driver) a un prezzo moderato.
- Modularità e miscelazione al posto del monobloccoLa combinazione di computer LLM, workstation GPU e sistema secondario/agente è più flessibile e duratura di una singola macchina „all-in-one“.
| Classe | Componenti tipici | Adatto a chi | Punti di forza / Compromessi |
|---|---|---|---|
| Livello base (circa 1.500-2.500 €) | Mac mini (16-32 GB di RAM) o PC con GPU (ad es. RTX 3060 / 3060 Ti / 4060 Ti con ≥ 12-16 GB di VRAM) | Hobby, primi esperimenti, modelli piccoli, immagine gestibile AI | Livello di ingresso favorevole, sufficiente per piccoli LLM, flussi di lavoro di diffusione stabili e leggeri e IA audio/testo. Limitazioni con modelli di grandi dimensioni, pipeline ComfyUI complesse e formazione LoRA. |
| Standard (circa € 2.500-4.000) | Workstation con GPU di fascia media (ad es. con RTX 3080 o RTX 3090), computer con 64 GB di RAM | Creativi, editori autonomi, utenti ambiziosi dell'intelligenza artificiale, piccoli team | Prestazioni solide per testo e immagini, buon rapporto qualità-prezzo. VRAM e RAM sufficienti per un uso versatile dell'IA, compresi SDXL e l'addestramento iniziale LoRA. Con progetti estremi o molti flussi di lavoro paralleli, il sistema raggiunge i suoi limiti ad un certo punto. |
| Professionale / Studio (circa 4.000-8.000 €) | Sistema ad alta RAM (ad es. Mac Studio con 128 GB di RAM o potente workstation Linux) + GPU con ≥ 24 GB di VRAM (ad es. RTX 3090, 4090) + sistema secondario/agente separato | Freelance, editori, produzioni multimediali, sviluppatori con progetti multipli, piccoli studi di AI | Massima flessibilità, modelli di grandi dimensioni (70B, MoE), AI di immagini e testi in parallelo, automazione e flussi di lavoro di lunga durata. A prova di futuro, ma con un investimento iniziale più elevato e un maggiore sforzo di pianificazione in fase di installazione. |
Perché oggi le GPU di fascia alta usate e vecchie sono spesso migliori delle nuove schede di fascia media
Molte schede più recenti vengono offerte con una VRAM limitata, ma questa è fondamentale per l'IA. I modelli di fascia alta più vecchi, come la RTX 3090, offrono spesso 24 GB di VRAM, che oggi è molto preziosa per SDXL, training LoRA o video AI. L'hardware è stato originariamente progettato per garantire prestazioni e stabilità, con componenti di alta qualità, bus di memoria, raffreddamento e un buon supporto per i driver.
Ciò significa: durata e prestazioni robuste sono spesso disponibili. Le schede usate sono spesso molto più economiche e quindi molto convenienti: l'ideale per i freelance o i piccoli studi con un budget limitato.
Il mio attuale consiglio per il 2025 (e perché)
Se dovessi costruire uno studio oggi e non puntassi alla massima potenza del supercomputer, deciderei:
- Per l'immagine AIAlmeno una GPU con 24 GB di VRAM, ad esempio RTX 3090 o 4090.
- Per il testo/LLM128 GB di RAM in un potente sistema Apple-Silicon.
- Per i lavori a tempo parziale (audio, voce, piccoli modelli, automazione): un piccolo computer separato (ad esempio un mini PC o un server economico).
- Per il coordinamento: un livello software - per me è FileMaker, per altri potrebbe essere una semplice shell o una pipeline Python.
Questa configurazione non è eccessiva, non dipende da costose licenze cloud ed è sufficiente per quasi tutto ciò che può essere fatto con l'IA nel settore creativo, editoriale o di sviluppo nel 2025.
ERP intelligente: Esecuzione di modelli linguistici locali con il server FileMaker
 La questione dell'hardware giusto per l'IA è giustificata, ma non è sufficiente se viene considerata in modo isolato. Sistemi potenti come un Mac Studio o una workstation basata su RTX si rivelano davvero validi solo quando vengono integrati in una struttura software ben congegnata. Con gli imminenti sviluppi del Claris FileMaker Server, proprio questo passo diventerà più tangibile: per la prima volta, i modelli linguistici locali possono essere utilizzati direttamente sul server e integrati nelle applicazioni esistenti. Ciò significa che anche i modelli Formazione LoRA nell'ambito dell'FileMaker possibile. Tuttavia, questo significa anche che i requisiti per la RAM, la GPU e il sistema complessivo aumentano in modo significativo: il semplice funzionamento del server senza riserve corrispondenti non sarà più sufficiente a lungo termine. In combinazione con un sistema locale Soluzione ERP basata su FileMaker come gFM Business, si ottiene un potente sistema complessivo in cui l'intelligenza artificiale non lavora in modo isolato, ma accede direttamente ai processi aziendali. Questo trasforma la pura potenza di calcolo in un vero e proprio fattore produttivo - strutturato, controllabile e direttamente ancorato al vostro sistema.
La questione dell'hardware giusto per l'IA è giustificata, ma non è sufficiente se viene considerata in modo isolato. Sistemi potenti come un Mac Studio o una workstation basata su RTX si rivelano davvero validi solo quando vengono integrati in una struttura software ben congegnata. Con gli imminenti sviluppi del Claris FileMaker Server, proprio questo passo diventerà più tangibile: per la prima volta, i modelli linguistici locali possono essere utilizzati direttamente sul server e integrati nelle applicazioni esistenti. Ciò significa che anche i modelli Formazione LoRA nell'ambito dell'FileMaker possibile. Tuttavia, questo significa anche che i requisiti per la RAM, la GPU e il sistema complessivo aumentano in modo significativo: il semplice funzionamento del server senza riserve corrispondenti non sarà più sufficiente a lungo termine. In combinazione con un sistema locale Soluzione ERP basata su FileMaker come gFM Business, si ottiene un potente sistema complessivo in cui l'intelligenza artificiale non lavora in modo isolato, ma accede direttamente ai processi aziendali. Questo trasforma la pura potenza di calcolo in un vero e proprio fattore produttivo - strutturato, controllabile e direttamente ancorato al vostro sistema.
L'hardware per l'IA non deve essere necessariamente nuovo, ma adeguato.
Oggi, il tempo in cui l'IA era riservata alle grandi aziende o ai laboratori cloud sta per finire. Entro il 2025, quasi chiunque - con un budget gestibile e un po„ di comprensione tecnica - potrà creare il proprio piccolo studio di IA. Questo vi rende indipendenti da costosi abbonamenti mensili, condizioni di protezione dei dati di terze parti, code, colli di bottiglia dei server e l'incertezza sulla durata dei servizi cloud. Invece, si ottiene:
- Controllo completo sui vostri dati e sui vostri flussi di lavoro,
- stabile, veloce e Prestazioni scalabili,
- uno Investimento sostenibile, che dura per anni,
- e il Libertà, di essere creativi quando e come si vuole, senza limitazioni esterne.
Quindi, se state pensando di utilizzare l'IA per i vostri libri, testi, immagini o progetti, vale più che mai la pena di creare un proprio studio. Non è necessario essere un ingegnere hardware. Non serve un budget enorme. Non serve l'hardware più recente.
Soprattutto, è necessario avere un'idea chiara dell'obiettivo che si sta raggiungendo e la volontà di mantenere il controllo sui propri processi.
Mostrerò come configurare un LLM locale con Ollama su un Mac installier in questo articolo.
Qui troverete un confronto tra Apple MLX su Silicon contro NVIDIA.
Come lavorare con Qdrant una memoria locale per la vostra AI locale è disponibile qui.




Domande frequenti
- Perché vale la pena avere un proprio studio di AI quando ci sono così tanti fornitori di cloud?
Avere un proprio studio di intelligenza artificiale vi rende più indipendenti, più stabili e più economici a lungo termine. I servizi cloud sono convenienti, ma costano ogni mese, creano dipendenza e sono spesso limitati da restrizioni d'uso. L'intelligenza artificiale locale è veloce, sempre disponibile e può essere utilizzata senza costi variabili. Inoltre, tutti i dati rimangono all'interno dell'azienda: un enorme vantaggio per i lavoratori autonomi, le aziende, gli editori o le professioni creative. - Di quale hardware minimo ho bisogno per iniziare con l'AI a livello locale?
Per iniziare è sufficiente un Mac mini con 16-32 GB di RAM o un PC con una GPU con almeno 12 GB di VRAM. Questo permette di eseguire piccoli modelli linguistici, leggeri modelli di immagini e le prime automazioni. Se si vuole solo provare, non è necessario investire diverse migliaia di euro. - Ho davvero bisogno di un Mac Studio o è più economico?
È sicuramente più economico. Un Mac Studio vale la pena se si desidera eseguire modelli linguistici di grandi dimensioni (20-120B), lavorare molto in parallelo o avere processi di produzione a lungo termine. Per i primi passi, un Mac mini o un solido PC Windows sono perfettamente adeguati. Uno studio è un investimento per la convenienza e per il futuro, ma non è indispensabile. - Perché la VRAM è più importante per l'IA delle immagini rispetto alla generazione di una scheda grafica moderna?
Perché i modelli di immagine, come la Diffusione Stabile, trasportano enormi quantità di dati nella memoria. Se la VRAM non è sufficiente, il processo si interrompe o diventa estremamente lento. Una scheda più vecchia, come la RTX 3090 con 24 GB di VRAM, spesso batte i nuovi modelli di fascia media con soli 8-12 GB di VRAM, semplicemente perché offre più spazio per i modelli di grandi dimensioni e per le esercitazioni. - È possibile eseguire uno studio AI completamente con hardware Apple senza NVIDIA?
Per i modelli linguistici sì. Per l'IA delle immagini, no. Apple-Silicon è estremamente efficiente per gli LLM, ma per la diffusione stabile, l'addestramento LoRA e molti modelli di immagini, le schede NVIDIA (grazie ai core CUDA/Tensor) sono ancora il riferimento. Molti studi utilizzano quindi un mix di Apple/LLM e Linux+NVIDIA per le immagini. - Una RTX 4080 o 4070 Ti è sufficiente anche per l'AI?
In teoria sì, ma in pratica dipende dall'uso previsto. Per immagini semplici o piccoli flussi di lavoro, è sufficiente. Ma per SDXL, pipeline ComfyUI complesse o formazione LoRA, il limite di 12-16 GB di VRAM raggiunge rapidamente i suoi limiti. Una RTX 3090 o 4090 ha quindi più senso a lungo termine. - Perché i modelli linguistici non vengono eseguiti sulla GPU, ma sulla RAM?
I modelli linguistici sono orientati alla memoria. Devono conservare grandi quantità di testo e di contesto nella RAM, non necessariamente eseguire operazioni grafiche. Le GPU sono costruite per l'elaborazione delle immagini, non per l'analisi del testo. Per questo motivo i sistemi LLM traggono enormi vantaggi da una grande quantità di RAM, ma meno dalla VRAM. - Quanta RAM deve avere un computer per un LLM?
Per i modelli più piccoli sono sufficienti 32-64 GB. Per i modelli di medie dimensioni (20-30B), 64-128 GB sono ideali. Per i modelli di grandi dimensioni, come 70B o MoE, come GPT-OSS 120B, la RAM ideale è 128-192 GB. Maggiore è la RAM, più stabile e veloce è il funzionamento. - È possibile gestire uno studio di AI completamente senza Linux?
MacOS è perfetto per gli LLM, ma per l'intelligenza artificiale manca di alcuni strumenti che esistono solo su Linux/NVIDIA. Windows funziona bene per l'IA delle immagini, ma è meno stabile e più difficile da automatizzare. Il mix pragmatico è quindi spesso: macOS → LLM, Linux → IA per immagini, piccolo computer → audio/script. - Quanto è rumoroso uno studio di AI come questo in funzione?
Meno di quanto si possa pensare. Un Mac Studio è praticamente silenzioso. Un PC Linux dipende dal raffreddamento: le GPU di alta qualità sono silenziose a basso carico, ma possono diventare udibili durante gli allenamenti. Se si preferisce la silenziosità, è possibile utilizzare workstation con GPU raffreddate ad acqua. - Che ruolo ha il Mac mini come terzo componente?
Serve come stazione secondaria per trascrizione, TTS, piccoli modelli AI, processi di background, automazione e lavori secondari per le traduzioni. In questo modo si mantengono libere le due macchine più grandi e si garantisce la stabilità dei flussi di lavoro. Un terzo computer non è assolutamente necessario, ma crea ordine e affidabilità. - Posso espandere gradualmente il mio studio di IA?
Assolutamente sì. In effetti, questo è il caso ideale. Acquistare un sistema LLM, poi aggiungere una workstation con GPU e successivamente un piccolo computer secondario: si tratta di una configurazione molto naturale che può essere estesa per mesi o anni. Gli studi di intelligenza artificiale crescono proprio come i laboratori tradizionali. - Quali sono i sistemi operativi più adatti per uno studio di intelligenza artificiale?
- macOS → ottimale per i modelli LLM e Apple-Silicon
- Linux (Ubuntu, Debian) → la scelta migliore per l'IA delle immagini, ComfyUI, Diffusione Stabile
- Windows → funziona bene per SD/ComfyUI, ma è meno ideale per i processi di automazione.
Molti studi oggi utilizzano configurazioni combinate: ogni sistema fa ciò per cui è più adatto. - Quanta energia consuma uno studio di intelligenza artificiale?
Un Mac Studio è incredibilmente efficiente e di solito si attesta tra i 50 e i 100 W. Una workstation con GPU RTX 3090 può assorbire 250-350 W, a seconda del carico. Un Mac mini consuma circa 10-30 W. Tutto sommato, molto meno di quanto ci si possa aspettare e spesso più economico degli abbonamenti cloud. - È difficile creare uno studio di AI da soli?
Non proprio. È necessaria una certa conoscenza tecnica, ma non una laurea in informatica. Molti strumenti oggi dispongono di interfacce web, script di installazione e configurazioni automatiche. E se si separano chiaramente i sistemi (LLM / GPU / lavori secondari), tutto rimane chiaro. - È davvero possibile coprire tutti i processi di pubblicazione con questo strumento?
Sì, ed è proprio per questo che uno studio di AI è ideale. Dalle idee per il libro ai testi, alle copertine, alle serie di immagini, alle correzioni, alle traduzioni e al file finale per la stampa o l'e-book, molte cose possono essere automatizzate e prodotte internamente. Questa è un'enorme libertà per gli editori autonomi. - Quanto è a prova di futuro uno studio di AI oggi?
Molto. Gli LLM stanno diventando più efficienti, i modelli di immagine più modulari, l'hardware più durevole - e l'IA locale sta tornando a essere importante nel mercato perché le leggi sul cloud, la protezione dei dati e i costi stanno rendendo il cloud meno attraente. Chiunque investa oggi in un piccolo studio di IA sta costruendo un'infrastruttura che diventerà più importante che obsoleta nel 2026-2030. - I modelli di intelligenza artificiale possono essere addestrati o ampliati in seguito?
Sì, un sistema GPU (ad esempio RTX 3090 o 4090) può essere utilizzato per l'addestramento LoRA, l'addestramento dello stile, l'addestramento dei materiali e l'addestramento dei processi. Ciò significa che è possibile addestrare il proprio „linguaggio visivo dell'IA“ o la „direzione del testo dell'IA“ nel tempo. Questo è il più grande vantaggio strategico di uno studio AI: si diventa indipendenti da modelli generici e si crea il proprio stile.



