
Dans la première partie de cette série d'articles, nous avons vu que l'exportation des données ChatGPT est bien plus qu'une simple fonction technique. Dans tes données exportées se trouve une collection de pensées, d'idées, d'analyses et de conversations qui se sont accumulées au fil du temps. Mais tant que ces données ne sont qu'une archive sur le disque dur, elles restent exactement cela : une archive. L'étape décisive consiste à rendre ces informations à nouveau utilisables. C'est précisément ici que commence la construction d'une IA de la connaissance personnelle.
L'idée est en fait étonnamment simple : une IA ne doit pas seulement travailler avec des connaissances générales, mais aussi avoir accès à tes propres données. Elle doit rechercher des conversations antérieures, trouver des contenus appropriés et les intégrer dans de nouvelles réponses. Ainsi, une IA ordinaire devient une sorte de mémoire numérique. Il s'agit de la deuxième partie de la série d'articles, dans laquelle il est maintenant question de la pratique.



Première partie de la série : le trésor sous-estimé de l'exportation de données ChatGPT
Alors que nous entrons concrètement dans la pratique dans cette deuxième partie, il vaut la peine de jeter un coup d'œil sur le premier article de cette série. Il y est question de la question fondamentale de savoir pourquoi l'exportation de données ChatGPT est si intéressante - et pourquoi de nombreux utilisateurs sous-estiment encore son potentiel. L'article montre quelles données sont effectivement contenues dans l'exportation, comment une archive personnelle de connaissances peut en résulter et pourquoi cette étape constitue précisément la base d'une IA propre avec mémoire. Si tu veux comprendre pourquoi nous construisons ce pipeline et quelle est la valeur stratégique de tes propres historiques de chat, tu devrais commencer par la partie 1.
Avant de passer à la mise en œuvre concrète dans le chapitre suivant, voyons d'abord comment un tel système est fondamentalement structuré.
L'idée de base d'un système RAG
La base technique de notre système est un concept désormais très répandu dans le monde de l'IA : RAG, c'est-à-dire Retrieval Augmented Generation. Derrière ce terme se cache un principe très pratique.
Normalement, un modèle linguistique répond aux questions en utilisant uniquement les connaissances apprises au cours de son entraînement. Ces connaissances sont certes vastes, mais elles présentent deux limites essentielles :
- Premièrement, le modèle ne connaît aucune information individuelle sur tes propres projets ou pensées.
- Deuxièmement, il ne peut pas accéder aux nouvelles données créées après la formation.
C'est précisément là qu'intervient un système RAG. Au lieu de générer directement une réponse, il se passe d'abord autre chose : le système recherche dans une base de données les contenus qui correspondent à la question posée. Ces contenus sont ensuite transmis au modèle linguistique en tant que contexte. Ce n'est qu'ensuite que l'IA formule sa réponse. Le processus se présente de manière simplifiée comme suit :
- Tu poses une question →
- le système recherche dans une base de connaissances →
- les contenus pertinents sont trouvés →
- ces contenus sont transmis à l'IA comme contexte →
- l'IA génère une réponse.
L'avantage décisif est évident : l'IA peut utiliser des informations qui ne faisaient pas partie de sa formation initiale.
Et c'est là que tes données ChatGPT entrent en jeu. Si nous intégrons ces conversations dans une base de connaissances, l'IA pourra y accéder plus tard. Elle peut retrouver des idées antérieures, utiliser des arguments d'anciens dialogues ou prendre en compte des analyses de conversations passées. Le système commence donc à se „souvenir“ de tes propres pensées.
Les éléments constitutifs de notre système
Pour que cela fonctionne, nous avons besoin de plusieurs composants qui travaillent ensemble. Heureusement, l'infrastructure technique nécessaire est aujourd'hui beaucoup plus facile d'accès qu'il y a quelques années. Notre système se compose essentiellement de quatre éléments centraux.
- Le premier élément est le Exportation des données ChatGPT. C'est ici que se trouvent nos données brutes. Elles contiennent toutes les conversations que nous avons eues auparavant avec l'IA.
- Le deuxième élément est un Modèle d'intégration. Ce modèle traduit le texte en vecteurs mathématiques. Il est ainsi possible de comparer les textes en fonction de leur signification.
- Le troisième élément est une Base de données de vecteurs. Dans notre cas, nous utilisons Qdrant. Cette base de données stocke les représentations mathématiques des textes et permet une recherche sémantique rapide.
- Le quatrième élément est un modèle linguistique local, qui passe par Ollama. Ce modèle formulera plus tard les réponses proprement dites.
Ces quatre composantes travaillent en étroite collaboration.
- L'exportation de données fournit le contenu.
- Le modèle d'intégration les rend lisibles par une machine.
- La base de données vectorielles les stocke et effectue des recherches.
- Le modèle linguistique produit finalement des réponses compréhensibles.
Ensemble, ils constituent la base d'une IA de la connaissance personnelle.
Aperçu du flux de données
Pour que le système fonctionne, les données doivent passer par plusieurs étapes. Au début, il y a l'exportation des données ChatGPT, que nous avons déjà créée dans le premier article. Les conversations qu'il contient sont d'abord extraites des fichiers JSON. Ces textes doivent ensuite être préparés. Les grandes séquences de chat sont décomposées en sections plus petites, appelées "text-chunks". Cela rend la recherche ultérieure nettement plus efficace.
Dans l'étape suivante, nous créons des embeddings à partir de ces sections de texte. Chaque texte est décrit mathématiquement. Les textes ayant une signification similaire reçoivent des vecteurs similaires. Nous enregistrons ensuite ces vecteurs dans notre base de données vectorielles Qdrant.
Ainsi, la partie la plus importante de l'infrastructure est déjà en place. Lorsqu'une question est posée ultérieurement, voici ce qui se passe :
- La question est également transformée en vecteur.
- La base de données recherche les textes ayant une signification similaire.
- Ces passages sont transmis au modèle linguistique en tant que contexte.
- Le modèle utilise ces informations pour formuler une réponse.
Ce processus fait en sorte que l'IA n'utilise pas seulement des connaissances générales, mais qu'elle puisse aussi accéder à tes propres données.
Ce qui sera possible à la fin
Une fois le système mis en place, l'utilisation de l'IA change sensiblement. Tu ne travailles plus seulement avec un modèle linguistique général, mais avec une IA qui peut accéder à tes propres données. Cela ouvre de toutes nouvelles possibilités. Tu peux par exemple poser des questions comme
„Ai-je déjà parlé de ce sujet avec l'IA ?“
„Quelles étaient mes idées antérieures sur ce projet ?“
„Quels sont les arguments que j'ai développés lors de mes précédents entretiens ?“
L'IA parcourt alors tes propres conversations et trouve des contenus appropriés. Au lieu de se contenter de donner une réponse générale, elle peut se référer à des pensées antérieures, résumer d'anciennes analyses ou identifier des liens entre différentes conversations.
En d'autres termes, l'IA commence à travailler avec ta propre archive de connaissances. Ainsi, un simple outil de chat devient un système capable de t'aider à réfléchir sur le long terme. Et c'est précisément ce système que nous allons construire pas à pas dans les prochains chapitres. Dans le prochain paragraphe, nous commencerons par les travaux pratiques et nous verrons d'abord de plus près l'exportation des données ChatGPT. Car avant de pouvoir construire une base de connaissances, nous devons comprendre comment nos données sont en fait structurées.
Dernière enquête sur l'utilisation des systèmes d'IA locaux
Préparation : Comprendre l'exportation des données ChatGPT
Dans le premier article de cette série, nous avons déjà créé l'export de données ChatGPT et l'avons téléchargé sous forme de fichier ZIP. Au premier abord, ce fichier peut paraître peu spectaculaire - une archive contenant quelques fichiers techniques, qui ressemble d'abord plus à une sauvegarde qu'à un précieux ensemble de données. Mais c'est précisément dans cette archive que se trouve la base de tout notre système de connaissances.
Avant de pouvoir commencer à charger ces données dans une base de données ou à les relier à une IA, nous devons d'abord comprendre comment l'exportation est structurée. En effet, ce n'est que si nous savons quelles informations sont contenues et comment elles sont structurées que nous pourrons les traiter ultérieurement de manière judicieuse. Dans ce chapitre, nous allons donc voir comment l'exportation de données est structurée, quels sont les fichiers réellement pertinents et comment nous pouvons faire de ces archives techniques une base utilisable pour notre système de connaissances en IA.
Décompresser le fichier ZIP
La première étape est triviale, mais néanmoins importante : nous devons décompresser l'archive téléchargée. Le fichier se présente généralement sous la forme d'un fichier ZIP classique. Sa taille peut varier en fonction de l'ampleur de ton utilisation antérieure. Certains utilisateurs reçoivent une archive de quelques centaines de mégaoctets, d'autres plusieurs gigaoctets.
Après avoir décompressé le fichier, tu obtiens un dossier contenant plusieurs fichiers et sous-dossiers. La structure exacte peut varier légèrement, mais tu y trouveras généralement une série de fichiers JSON et éventuellement d'autres fichiers contenant des informations complémentaires.
Pour de nombreux utilisateurs, cette structure semble d'abord un peu technique. Mais si l'on prend le temps de réfléchir un instant, on reconnaît rapidement un modèle : les données sont organisées de manière relativement propre et suivent une structure claire. C'est une bonne nouvelle, car c'est précisément cette structure qui permet ensuite de traiter les contenus de manière automatisée.
Structure des données de chat
L'élément le plus important de l'exportation sont les données de discussion proprement dites. Ces conversations sont généralement enregistrées dans un ou plusieurs fichiers JSON. JSON est un format de données très répandu, souvent utilisé pour stocker des informations structurées.
Un tel fichier ne contient pas simplement un long texte. Au lieu de cela, un dialogue est divisé en éléments individuels. Typiquement, un dialogue se compose de plusieurs messages. Chaque message contient des informations telles que
- le texte proprement dit du message
- le rôle de l'expéditeur (utilisateur ou IA)
- un horodatage
- parfois d'autres métadonnées
Il est ainsi possible de reconstituer l'ensemble du déroulement de la conversation. Un dialogue commence par exemple par une question de l'utilisateur. Elle est suivie d'une réponse de l'IA. D'autres questions et réponses peuvent ensuite suivre. Chacun de ces messages est enregistré individuellement.
Cela présente un grand avantage : nous pouvons plus tard reconnaître exactement qui a dit quoi et comment s'est déroulée une conversation. C'est particulièrement important pour notre système de connaissances, car nous voulons ensuite rechercher et analyser précisément ces contenus.
Les données dont nous avons vraiment besoin
Bien que l'exportation contienne beaucoup d'informations, nous n'avons pas besoin de tout pour notre système de connaissances. Les textes des entretiens en sont l'élément le plus important. Ces textes contiennent les contenus proprement dits : Idées, analyses, questions et réponses. C'est précisément dans ces contenus que nous voulons effectuer des recherches par la suite.
En outre, certaines métadonnées peuvent être utiles. Il s'agit par exemple
- Horodatage
- Titre de la conversation
- éventuellement des numéros d'identification internes
Ces informations nous aideront plus tard à mieux trier les contenus ou à situer un entretien dans le temps. D'autres éléments de l'export sont moins pertinents pour notre projet. Il s'agit par exemple de certaines métadonnées techniques qui ne sont intéressantes que pour le fonctionnement interne de la plateforme.
Pour construire notre base de connaissances, nous nous concentrons donc délibérément sur l'essentiel : les textes des entretiens et quelques informations contextuelles de base. Plus nous structurons ces données de manière claire, mieux notre IA pourra les utiliser par la suite.
Premier examen des données
Avant de travailler avec des scripts automatisés, il vaut la peine de jeter un coup d'œil aux données elles-mêmes. Pour ce faire, ouvre l'un des fichiers JSON à l'aide d'un simple éditeur de texte ou d'un programme qui peut bien afficher les fichiers JSON. De nombreux éditeurs de code, tels que Visual Studio Code, s'y prêtent très bien, mais les éditeurs de texte simples fonctionnent également.
En regardant le fichier pour la première fois, tu verras probablement une quantité relativement importante de données structurées. Les fichiers JSON sont constitués d'éléments imbriqués, c'est-à-dire de champs de données qui contiennent à leur tour d'autres champs. Cela semble un peu complexe au premier abord, mais avec un peu de patience, on reconnaît rapidement la structure de base. Tu verras par exemple qu'une conversation se compose de plusieurs messages et que chaque message représente un objet distinct. Le texte proprement dit se trouve généralement dans un champ clairement identifiable.
Ce premier tri a un but important : il t'aide à comprendre comment tes données sont structurées. En effet, dans le chapitre suivant, nous utiliserons précisément cette structure pour lire les entretiens de manière automatisée et les préparer pour notre système de connaissances. En d'autres termes, cela signifie : Nous transformons maintenant pas à pas une archive de données techniques en une base de connaissances utilisable. Et c'est précisément ce que nous commençons à faire dans le chapitre suivant. Il s'agit ici d'extraire les données des conversations et de les préparer de manière à ce qu'elles puissent être recherchées efficacement par la suite.
Préparer les données : Des entretiens aux textes analysables
Après avoir décompressé l'export de données ChatGPT dans le chapitre précédent et obtenu un premier aperçu de sa structure, nous entamons maintenant la partie technique proprement dite de notre projet. Les données exportées sont certes disponibles dans leur intégralité - mais sous cette forme, elles ne sont pas encore parfaitement adaptées à notre système de connaissances.
La raison est simple : les historiques de chat sont généralement longs, contiennent de nombreux sujets et sont stockés dans une structure qui est lisible pour les humains, mais qui n'est pas idéale pour la recherche sémantique ou les bases de données vectorielles. Pour que notre IA puisse trouver plus tard des contenus pertinents et ciblés, nous devons d'abord préparer ces données brutes. Cela signifie essentiellement trois choses :
- extraire les conversations des fichiers JSON
- structurer les textes de manière pertinente
- diviser le contenu en sections plus petites
Ce processus est une étape tout à fait normale dans les systèmes d'IA modernes et est souvent appelé prétraitement.
Pourquoi les données brutes ne sont pas directement appropriées
Si tu jettes un coup d'œil à l'un des fichiers JSON, tu constateras qu'un seul chat est souvent composé de nombreux messages. Un dialogue typique peut par exemple ressembler à ceci :
- Question
- Réponse
- Demande de renseignements
- nouvelle déclaration
- autre détail
- Résumé
Certaines conversations peuvent contenir des centaines, voire des milliers de mots. Pour les humains, ce n'est pas un problème. Nous lisons simplement un dialogue de haut en bas.
Cependant, cela fonctionne moins bien pour une recherche par IA. La raison en est qu'une seule conversation contient souvent plusieurs sujets. Lorsque nous effectuons une recherche sémantique par la suite, le système doit trouver des passages de texte aussi précis que possible - et non des conversations entières avec de nombreux contenus différents.
C'est pourquoi les grands textes sont découpés en sections plus petites. Ces sections sont appelées chunks. Un chunk est tout simplement un petit bloc de texte qui contient une pensée cohérente. Cette méthode améliore considérablement la qualité de la recherche par la suite.
Extraire les historiques de chat
La première étape pratique consiste à extraire le contenu des fichiers JSON. Pour cela, nous utilisons un petit script Python. Python se prête particulièrement bien à ce genre de tâches, car il contient de nombreuses bibliothèques pour le traitement des données et l'IA.
Crée d'abord un nouveau fichier, par exemple :
extract_chats.py
Ensuite, nous ajoutons un script simple qui charge les données de chat.
import json
with open("conversations.json", "r", encoding="utf-8") as f:
data = json.load(f)
print("Anzahl der Gespräche:", len(data))Si tu exécutes ce script, tu devrais voir combien de conversations sont contenues dans ton exportation. Maintenant, nous voulons extraire les textes proprement dits.
texts = []
for conversation in data:
if "mapping" in conversation:
for node in conversation["mapping"].values():
message = node.get("message")
if message:
content = message.get("content")
if content and "parts" in content:
text = " ".join(content["parts"])
texts.append(text)
print("Extrahierte Textabschnitte:", len(texts))Ce script parcourt la structure JSON et rassemble tous les éléments de texte issus des entretiens. Nous avons ainsi déjà réalisé la partie la plus importante : nous avons extrait les contenus du format d'exportation technique.
Créer des chunks de texte
Voici maintenant la prochaine étape importante : le chunking. Au lieu de sauvegarder des conversations complètes, nous divisons les textes en sections plus petites.
Une taille typique pour de telles sections de texte se situe entre 300 et 800 mots ou environ 500 tokens. Voici un exemple simple de la manière dont on peut diviser un texte en chunks.
def split_text(text, chunk_size=500):
words = text.split()
chunks = []
for i in range(0, len(words), chunk_size):
chunk = " ".join(words[i:i+chunk_size])
chunks.append(chunk)
return chunksNous pouvons maintenant appliquer cette fonction à nos textes.
all_chunks = []
for text in texts:
chunks = split_text(text)
all_chunks.extend(chunks)
print("Gesamtzahl der Chunks:", len(all_chunks))Nous avons maintenant créé de nombreux petits blocs de texte à partir de nos historiques de chat. Ces blocs de texte sont idéaux pour une recherche ultérieure dans une base de données vectorielles.
Compléter les métadonnées
Outre le texte proprement dit, des informations supplémentaires peuvent s'avérer très utiles. Ces "métadonnées" nous aident ensuite à mieux trier ou filtrer les contenus. Des métadonnées typiques pourraient être
- Date de l'entretien
- Titre de la conversation
- Source (ChatGPT Export)
- ID de la conversation
Nous pouvons enregistrer ces informations en même temps que le texte, par exemple de cette manière :
documents = []
for conversation in data:
title = conversation.get("title", "Unbekannt")
if "mapping" in conversation:
for node in conversation["mapping"].values():
message = node.get("message")
if message:
content = message.get("content")
if content and "parts" in content:
text = " ".join(content["parts"])
chunks = split_text(text)
for chunk in chunks:
documents.append({
"text": chunk,
"title": title
})Cela nous a déjà permis d'améliorer considérablement la structure de nos données. Au lieu d'une archive de chat confuse, nous possédons maintenant une collection de nombreuses petites sections de texte, chacune étant accompagnée d'informations contextuelles.
C'est précisément cette structure qui sera déterminante dans la prochaine étape. En effet, nous pouvons maintenant commencer à créer des embeddings à partir de ces textes - c'est-à-dire des représentations mathématiques des contenus qui seront ensuite stockées dans notre base de données vectorielles. Et c'est précisément l'objet du prochain chapitre.
Créer des embeddings
Dans le chapitre précédent, nous avons déjà transformé nos données ChatGPT en une forme utilisable. Nous avons extrait les conversations des fichiers JSON, nettoyé les textes et les avons divisés en sections plus petites, appelées chunks.
Mais pour que notre IA puisse plus tard rechercher des contenus de manière vraiment utile, il manque encore une étape décisive. Les textes doivent être traduits dans une forme que les machines peuvent comparer. C'est là que les embeddings entrent en jeu.
Les embeddings sont des représentations mathématiques de textes. Ils permettent aux ordinateurs de comparer la signification des textes. Deux textes au contenu similaire obtiennent des vecteurs similaires - même s'ils utilisent des mots différents. C'est précisément cette propriété dont nous avons besoin pour notre système de connaissances. En effet, plus tard, notre IA ne devra pas seulement chercher des mots identiques, mais aussi des textes dont le contenu correspond.
Ce que sont les embeddings
Un embedding est en fait une liste de chiffres. Ces chiffres décrivent la signification d'un texte dans un espace mathématique. Chaque texte est converti en ce que l'on appelle un vecteur. Un tel vecteur peut par exemple ressembler à ceci :
[0.134, -0.876, 0.442, 0.921, -0.223, ...]
Un seul vecteur peut contenir plusieurs centaines, voire plusieurs milliers de chiffres. Ces nombres ne sont évidemment pas directement compréhensibles pour les humains. Pour les machines, ils sont toutefois idéaux pour calculer les similitudes entre les textes. Si deux textes ont des contenus similaires, leurs vecteurs sont plus proches dans l'espace mathématique. Un exemple :
- Texte A: „Comment exporter mes données ChatGPT ?“
- Texte B: „Comment télécharger mes conversations ChatGPT ?“
Bien que les formulations soient différentes, les deux textes décrivent en fait le même sujet. Un bon modèle d'intégration reconnaît cette similitude. Les deux textes reçoivent donc des vecteurs similaires. C'est exactement ce principe que nous utiliserons plus tard pour notre recherche sémantique.
Modèles d'encastrement avec Ollama
Pour la création d'embeddings, nous avons besoin d'un modèle spécial. Heureusement, nous n'avons pas besoin d'utiliser des services cloud externes pour cela. De nombreux modèles d'embedding peuvent aujourd'hui être exploités localement - et c'est là qu'intervient Ollama.
Comme Ollama fonctionne déjà sur ton système, nous pouvons y créer un modèle d'embedding 1TP12. Un très bon modèle est par exemple
nomic-embed-text
Tu peux le faire avec la commande suivante installieren :
ollama pull nomic-embed-text
D'autres modèles populaires sont
- mxbai-embed-large
- bge-large
- all-minilm
Pour nos besoins, est nomic-embed-text un très bon point de départ. Ce modèle génère des embeddings de haute qualité et fonctionne sans problème en local.
Créer des embeddings localement
Nous voulons maintenant étendre notre script Python pour qu'il puisse créer des embeddings. Tout d'abord, nous install créons une bibliothèque qui permet à Python de communiquer avec Ollama.
pip install ollama
Nous pouvons maintenant aborder le modèle d'intégration directement depuis Python. Voici un exemple simple :
import ollama
response = ollama.embeddings(
model="nomic-embed-text",
prompt="Wie exportiere ich meine ChatGPT-Daten?"
)
print(len(response["embedding"]))Si tout a bien fonctionné, tu obtiens un vecteur de plusieurs centaines de chiffres.
Maintenant, nous appliquons cela à nos chunks de chat.
embeddings = []
for doc in documents:
text = doc["text"]
result = ollama.embeddings(
model="nomic-embed-text",
prompt=text
)
vector = result["embedding"]
embeddings.append({
"text": text,
"embedding": vector,
"title": doc["title"]
})Nous créons ainsi un vecteur pour chaque section de texte. Ces vecteurs seront ensuite enregistrés dans notre base de données.
Pourquoi cette étape est décisive
Les embeddings sont au cœur des systèmes de connaissances modernes. Sans les embeddings, nous ne pourrions rechercher des textes qu'à l'aide d'une recherche classique par mots-clés. Cela signifierait que le système ne trouverait que des contenus contenant exactement les mêmes mots. Or, le langage fonctionne rarement de manière aussi simple. Un utilisateur pourrait par exemple demander
„Comment ai-je traité mes données ChatGPT ?“
Cependant, la conversation initiale pourrait être formulée comme suit :
„Comment puis-je analyser mon exportation de données ChatGPT ?“
Une simple recherche pourrait ne pas détecter ce lien. Avec les embeddings, c'est différent. Comme les deux textes ont des significations similaires, leurs vecteurs sont proches dans l'espace mathématique. Notre base de données peut donc trouver des contenus correspondants, même si les formulations sont différentes. C'est précisément cette capacité qui rend la recherche sémantique si puissante. Elle permet à une IA de rechercher non seulement des mots, mais aussi des significations.
Et c'est précisément pour cette raison que les embeddings sont la pierre angulaire de notre système. Dans le chapitre suivant, nous nous appuierons sur cette base pour créer notre base de données de vecteurs. Nous y stockerons les vecteurs générés - et créerons ainsi la base de notre IA de la connaissance personnelle.
Qdrant 1TP12Enregistrer et configurer
Après avoir créé les embeddings pour nos données de chat dans le chapitre précédent, nous disposons maintenant d'une collection de sections de texte et des vecteurs correspondants. Ces vecteurs décrivent mathématiquement la signification des textes et constituent ainsi la base d'une recherche sémantique. Mais actuellement, ces données ne sont disponibles que dans la mémoire de travail de notre script ou dans de simples listes. Pour que notre IA puisse y accéder efficacement par la suite, nous avons besoin d'une mémoire spécialisée.
C'est précisément là qu'une base de données vectorielles entre en jeu. Une base de données de vecteurs est optimisée pour stocker de grandes quantités de tels embeddings et pour rechercher rapidement des vecteurs similaires. Pour notre projet, nous utilisons Qdrant, une base de données open source moderne, spécialement conçue pour les applications d'IA.
Dans ce chapitre 1TP12, nous lançons Qdrant, démarrons le serveur et préparons la base de données de manière à pouvoir importer nos données de chat sans problème par la suite.
Ce qu'est Qdrant
Qdrant est une base de données spécialisée dans ce que l'on appelle les recherches vectorielles. Alors que les bases de données classiques stockent des informations dans des tableaux - par exemple des noms, des chiffres ou des textes - une base de données vectorielle travaille avec des représentations mathématiques de données.
Cela signifie qu'au lieu de ne stocker que du texte, Qdrant stocke les embeddings correspondants. Le grand avantage réside dans la recherche. Si une question est posée ultérieurement, notre système convertit également cette question en un vecteur. Qdrant peut alors calculer en un clin d'œil quels sont les textes enregistrés qui ressemblent le plus à ce vecteur. Cela permet par exemple de trouver
- quels passages de chat correspondent thématiquement à la question
- quelles conversations antérieures contiennent des contenus similaires
- quelles idées pourraient être pertinentes dans tes archives
C'est précisément pour cette raison que Qdrant est aujourd'hui utilisé dans de nombreux systèmes d'IA modernes, de la recherche de documents aux assistants de connaissances complexes. Autre avantage : Qdrant est open source, rapidement installé et fonctionne sans problème sur une machine locale normale.
Installation de Qdrant
Le moyen le plus simple de faire fonctionner Qdrant 1TP12 est de passer par Docker. Si Docker est présent sur ta machine, tu peux démarrer le serveur avec une seule commande. Ici, tu peux Docker télécharger, Si tu ne l'as pas encore installé sur ton ordinateur, install.
docker run -p 6333:6333 qdrant/qdrant
Cette commande démarre le serveur Qdrant et ouvre le port standard 6333. C'est par ce port que nos scripts pourront ensuite communiquer avec la base de données.
Si tu ne souhaites pas utiliser Docker, il existe d'autres possibilités de installier Qdrant, par exemple via un binaire local ou des gestionnaires de paquets. Cependant, dans de nombreux projets pratiques, Docker s'est avéré être l'option la plus simple et la plus stable.
Une fois le serveur démarré, Qdrant s'exécute en arrière-plan et attend les requêtes. Tu peux maintenant tester si le serveur est accessible. Pour cela, ouvre l'adresse suivante dans ton navigateur :
http://localhost:6333
Si tout a fonctionné, un simple message d'état devrait apparaître. Le serveur est alors prêt pour les étapes suivantes.
Premiers pas avec Qdrant
Avant de pouvoir importer nos données de chat, nous devons créer ce que l'on appelle une collection. Dans Qdrant, une collection est comparable à une table dans une base de données classique. Elle contient nos vecteurs et les données correspondantes.
Tout d'abord, installieren la bibliothèque Python pour Qdrant :
pip install qdrant-client
Nous pouvons maintenant établir une connexion avec la base de données dans notre script Python.
from qdrant_client import QdrantClient
client = QdrantClient("localhost", port=6333)Si ce code est exécuté sans message d'erreur, la connexion est réussie. Nous allons maintenant créer une collection pour nos données de chat.
from qdrant_client.models import VectorParams, Distance client.recreate_collection( collection_name="chatgpt_archive", vectors_config=VectorParams(size=768, distance=Distance.COSINE), )
Les paramètres les plus importants sont ici
- nom_collection - le nom de notre base de données
- size - la longueur des vecteurs d'intégration
- distance - la méthode de calcul de la similarité
La taille des vecteurs dépend du modèle d'intégration utilisé. De nombreux modèles travaillent avec des vecteurs de 768 ou 1024 dimensions. La fonction de distance Cosine est l'une des méthodes les plus courantes pour calculer les similitudes entre les textes. Notre base de données est donc déjà prête à l'emploi.
Planifier la structure des données
Avant d'importer nos données, il vaut la peine de jeter un coup d'œil à la structure que nous voulons enregistrer. Chaque entrée de notre base de données vectorielles sera composée de plusieurs éléments :
- ID - un identifiant unique
- Intégrer - le vecteur du texte
- Charge utile - informations supplémentaires sur le texte
La charge utile peut par exemple contenir
- le texte original
- le titre de l'entretien
- la date
- autres métadonnées
Un exemple d'ensemble de données pourrait ressembler à ceci :
{
"id": 1,
"vector": [0.123, -0.452, 0.889, ...],
"payload": {
"text": "Wie kann ich meinen ChatGPT-Datenexport analysieren?",
"title": "Datenanalyse"
}
}
Cette structure présente un grand avantage. Les vecteurs sont utilisés pour la recherche sémantique, tandis que la charge utile contient toutes les informations que nous souhaitons afficher ou analyser ultérieurement. Cela permet à notre système de rester flexible et d'être facilement étendu par la suite.
La partie la plus importante de l'infrastructure est donc déjà prête. Notre serveur Qdrant fonctionne, la base de données est configurée et nous savons quelle sera la structure de nos données. Dans le chapitre suivant, nous entamons l'étape décisive : nous importons nos données ChatGPT dans la base de données et transformons nos archives de conversations en une véritable base de connaissances consultable.
Importer les données ChatGPT dans Qdrant
Après avoir créé Qdrant install et une collection dans le chapitre précédent, la base technique de notre base de connaissances est en place. Nos embeddings existent déjà - nous les avons créés à partir des données ChatGPT - et Qdrant fonctionne comme serveur de base de données sur notre machine.
Vient maintenant l'étape décisive : nous chargeons nos données dans la base de données. Ce faisant, nous ne stockons pas seulement les vecteurs eux-mêmes, mais aussi les textes et les métadonnées qui leur sont associés. Cette combinaison permettra plus tard à notre IA de trouver des contenus pertinents et de les utiliser dans des réponses. Dans ce chapitre, nous construisons donc la base de connaissances proprement dite de notre système.
Enregistrer les embeddings
Tout d'abord, nous devons transférer les embeddings que nous avons créés dans la base de données. Chaque entrée dans Qdrant se compose de trois éléments :
- d'un identifiant
- un vecteur (embedding)
- d'une charge utile contenant des données supplémentaires
Dans notre cas, la charge utile contient par exemple
- la section de texte
- le titre de l'entretien
- éventuellement d'autres métadonnées
En Python, nous pouvons préparer cette structure assez facilement. Un exemple :
points = []
for idx, item in enumerate(embeddings):
points.append({
"id": idx,
"vector": item["embedding"],
"payload": {
"text": item["text"],
"title": item["title"]
}
})Nous créons ainsi une liste de points de données que nous pouvons ensuite enregistrer dans Qdrant. Chaque point de données contient donc une section de texte, le vecteur correspondant et des informations contextuelles supplémentaires. Cette structure constituera plus tard la base de notre recherche sémantique.
Créer un script d'importation
Nous allons maintenant connecter notre script Python à Qdrant et transférer les données. Pour cela, nous utilisons le client Qdrant Python que nous avons présenté dans le chapitre précédent install. L'importation peut par exemple ressembler à ceci
from qdrant_client import QdrantClient
from qdrant_client.models import PointStruct
client = QdrantClient("localhost", port=6333)
points = []
for idx, item in enumerate(embeddings):
point = PointStruct(
id=idx,
vector=item["embedding"],
payload={
"text": item["text"],
"title": item["title"]
}
)
points.append(point)
client.upsert(
collection_name="chatgpt_archive",
points=points
)
print("Import abgeschlossen:", len(points), "Datensätze gespeichert.")La commande upsert veille à ce que les données soient enregistrées dans la collection. Si un identifiant existe déjà, l'enregistrement est mis à jour. Dans le cas contraire, un nouvel enregistrement est créé. Selon la taille de ton exportation ChatGPT, cette importation peut prendre quelques secondes ou minutes. Pour les grands ensembles de données - par exemple plusieurs milliers de sections de texte - c'est tout à fait normal.
Tester la base de données
Une fois l'importation terminée, nous devons vérifier si nos données ont été correctement enregistrées. Le test le plus simple consiste à effectuer une recherche vectorielle. Pour ce faire, nous commençons par créer un embedding pour une question test.
query = "Wie kann ich ChatGPT-Daten analysieren?" query_vector = ollama.embeddings( model="nomic-embed-text", prompt=query )["embedding"]
Nous pouvons maintenant rechercher des vecteurs similaires dans Qdrant.
search_result = client.search( collection_name="chatgpt_archive", query_vector=query_vector, limit=3 )
Cette commande nous renvoie les trois sections de texte les plus similaires de notre base de données. Nous pouvons par exemple les afficher ainsi :
for result in search_result:
print(result.payload["text"])
print("---")Si tout a bien fonctionné, des parties de chat de tes archives correspondant à la requête de recherche apparaissent maintenant. Ainsi, nous savons : Notre base de données fonctionne.
Premier contrôle des résultats
Ce moment est l'un des plus passionnants de tout le projet. Pour la première fois, on voit que nos archives de chat peuvent réellement être utilisées comme source de connaissances. Tu peux maintenant essayer différentes requêtes de recherche. Par exemple
- „Article sur l'IA“
- „Système RAG“
- „ChatGPT Exportation de données“
- „Idée de stratégie“
Selon le contenu de ton historique de chat, Qdrant trouvera des passages appropriés. Parfois, tu seras surpris par les contenus qui réapparaissent. Des conversations que tu avais oubliées depuis longtemps peuvent soudain redevenir pertinentes. Cela montre très clairement pourquoi une telle approche est si intéressante. Tes anciennes conversations IA ne sont plus de simples archives. Elles deviennent une base de connaissances sur laquelle il est possible de faire des recherches.
Nous avons ainsi franchi une étape importante. Nos données ChatGPT sont désormais entièrement stockées dans la base de données vectorielle et peuvent faire l'objet d'une recherche sémantique. Dans le chapitre suivant, nous allons encore plus loin : nous relions notre base de connaissances à l'IA elle-même. Cela permettra à l'avenir au modèle linguistique d'accéder à ces données et de les intégrer directement dans les réponses.
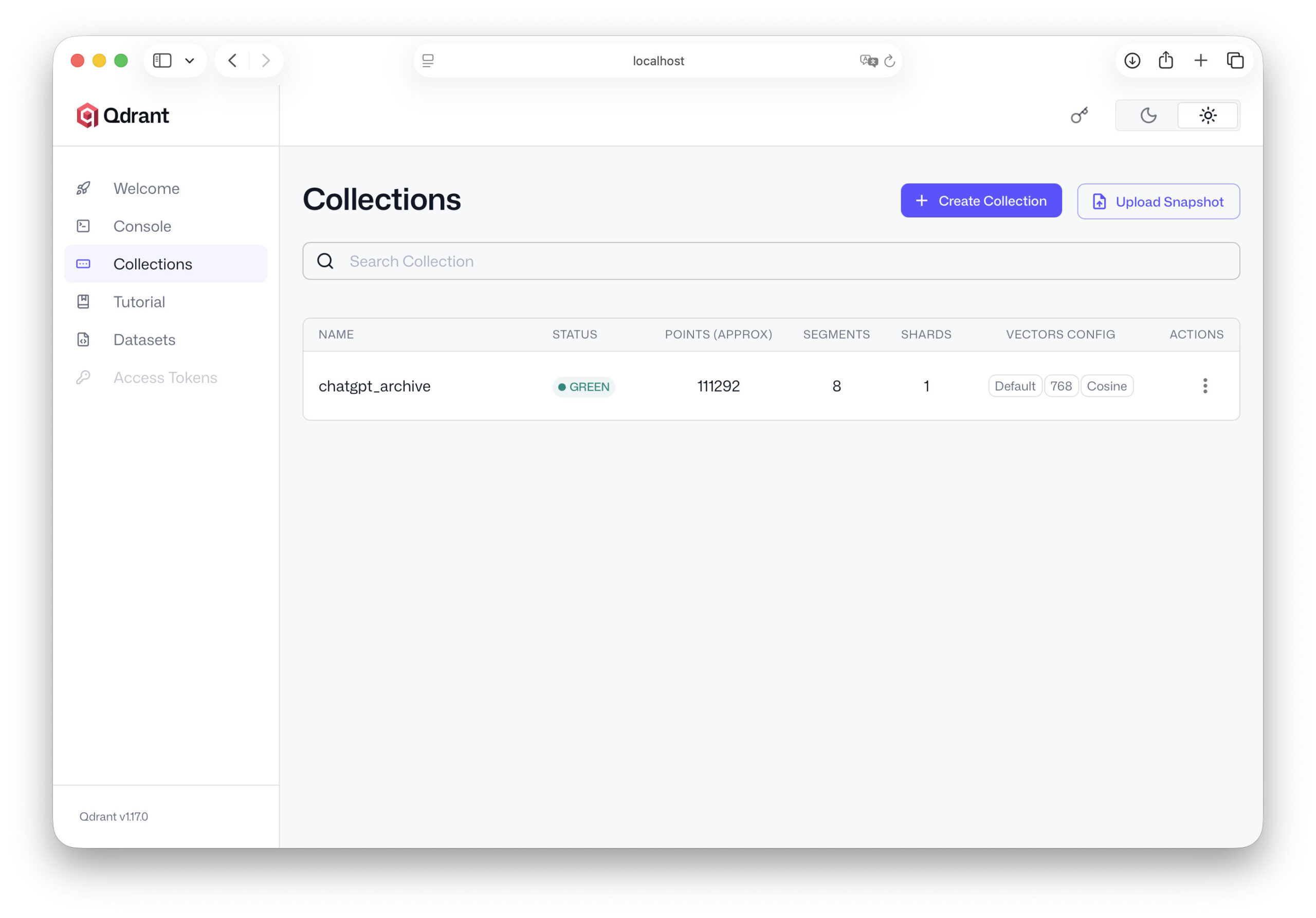
Relier l'IA à la base de connaissances
Jusqu'ici, nous avons déjà mis en place une grande partie de l'infrastructure. Nos données ChatGPT ont été extraites de l'exportation, découpées en sections de texte plus petites, dotées d'embeddings et finalement stockées dans la base de données vectorielles Qdrant.
Mais pour l'instant, notre IA ne travaille pas encore avec ces données. Nous pouvons certes effectuer une recherche vectorielle via Python et trouver des sections de texte correspondantes, mais l'IA elle-même n'en sait encore rien. Lorsque nous lui posons une question, elle continue à utiliser ses connaissances linguistiques générales.
L'étape suivante consiste donc à relier ces deux mondes. Nous construisons maintenant un processus dans lequel l'IA reçoit d'abord le contenu pertinent de la base de connaissances et l'intègre ensuite dans sa réponse. C'est précisément le cœur d'un système RAG.
Processus de demande
Le déroulement d'une demande est légèrement modifié par notre système de connaissances. Jusqu'à présent, une conversation avec une IA se déroulait généralement de la manière suivante :
- Tu poses une question →
- l'IA traite la question →
- l'IA génère une réponse.
Avec une base de connaissances, une étape supplémentaire est ajoutée. La nouvelle procédure se présente comme suit :
- Tu poses une question →
- la question est transformée en un embedding →
- la base de données vectorielle recherche des textes similaires →
- ces textes sont transmis à l'IA en tant que contexte →.
l'IA formule une réponse. Cela signifie que l'IA ne travaille plus seulement avec ses connaissances entraînées, mais en plus avec tes propres données. Ce contexte rend souvent les réponses beaucoup plus précises et personnelles.
Étape de récupération
La première partie de ce processus s'appelle la récupération. Retrieval signifie simplement „récupérer“. Dans cette étape, notre système recherche dans la base de données des contenus qui correspondent thématiquement à la question. Tout d'abord, nous créons à nouveau un embedding pour la question actuelle.
query = "Welche Ideen hatte ich zur Nutzung meines ChatGPT-Datenexports?" query_vector = ollama.embeddings( model="nomic-embed-text", prompt=query )["embedding"]
Cet embedding décrit la signification de la question sous forme mathématique. Qdrant peut maintenant rechercher des vecteurs similaires.
results = client.search( collection_name="chatgpt_archive", query_vector=query_vector, limit=5 )
La base de données renvoie maintenant les cinq passages de texte qui correspondent le mieux à la question. Ces passages de texte constituent le contexte pour l'IA. Nous les rassemblons dans une liste.
context_texts = [] for r in results: context_texts.append(r.payload["text"])
Nous disposons désormais d'une collection de contenus pertinents issus de nos archives de chat.
Transférer le contexte à Ollama
Voici maintenant l'étape décisive. Nous transmettons ce contexte, ainsi que la question initiale, à notre modèle linguistique. Le modèle peut maintenant utiliser ces informations pour formuler une réponse.
Tout d'abord, nous construisons ce que l'on appelle un prompt. Une invite est simplement le texte que nous envoyons à l'IA.
context = "\n\n".join(context_texts)
prompt = f"""
Du bist ein KI-Assistent, der mit meinem persönlichen Wissensarchiv arbeitet.
Nutze die folgenden Textausschnitte als Kontext:
{context}
Beantworte nun diese Frage:
{query}
"""Nous envoyons maintenant cette invite à notre modèle de langage en Ollama.
response = ollama.chat(
model="llama3",
messages=[
{"role": "user", "content": prompt}
]
)
print(response["message"]["content"])L'IA reçoit maintenant à la fois la question et les passages pertinents de notre base de données. Elle peut ainsi générer des réponses basées sur nos propres données.
Génération de réponses
La dernière étape est la génération de la réponse proprement dite. Le modèle linguistique combine maintenant deux sources de connaissances :
ses propres connaissances entraînées
le contexte de notre base de connaissances
Cette combinaison est particulièrement puissante. Le modèle peut expliquer des relations générales tout en intégrant des contenus concrets de nos archives. Prenons un exemple : Si tu demandes
„Quelles étaient mes idées pour utiliser mon exportation de données ChatGPT ?“
l'IA peut désormais accéder à des conversations antérieures et en faire un résumé structuré. Elle pourrait par exemple répondre
- Tu as parlé de constituer une archive personnelle de connaissances
- Tu voulais développer une IA locale avec un système RAG
- Tu as développé l'idée d'une série d'articles
Sans l'étape de récupération, l'IA n'aurait même pas connu ces informations. Avec notre système, tes archives de chat deviennent une véritable source de connaissances. La partie la plus importante de notre système est ainsi entièrement construite. Nous avons maintenant
- une IA locale via Ollama
- une base de données vectorielle contenant nos données de chat
- une recherche sémantique
- un flux de travail RAG
Dans le prochain chapitre, nous testerons ce système dans la pratique et verrons à quel point notre IA de connaissance personnelle fonctionne réellement.
Premières interrogations avec ton IA de connaissances personnelle
Après avoir établi le lien entre notre IA et la base de connaissances dans le chapitre précédent, le système est techniquement complet. Nos données ChatGPT se trouvent dans la base de données vectorielle, l'IA peut récupérer les contenus pertinents et l'ensemble du processus d'un système RAG fonctionne.
C'est maintenant qu'intervient la partie la plus passionnante du projet : les premières vraies requêtes. En effet, c'est seulement maintenant que l'on peut voir si notre système fait vraiment ce que nous espérions, à savoir trouver des conversations antérieures, analyser leur contenu et générer des réponses pertinentes. Dans ce chapitre, nous testons notre IA de la connaissance, nous examinons des cas d'utilisation typiques et nous jetons un coup d'œil sur les optimisations possibles.
Exemples de requêtes
Commençons par quelques questions simples. Une bonne stratégie consiste à commencer par poser des questions dont tu sais qu'elles se trouvent dans tes archives de chat. Par exemple
„Quelles étaient mes idées pour utiliser mon exportation de données ChatGPT ?“
„Qu'est-ce que j'ai écrit sur les systèmes RAG ?“
„Quelles sont les stratégies dont j'ai discuté pour utiliser l'IA ?“
Ces questions contiennent volontairement des formulations ouvertes. L'objectif n'est pas de retrouver un texte précis, mais de découvrir des contenus thématiquement appropriés. Lorsque tu poses une telle question à ton système, le processus que nous avons mis en place dans le chapitre précédent se déroule en arrière-plan :
- La question est transformée en embedding.
- La base de données vectorielle recherche des sections de texte similaires.
- Ces passages sont transmis à l'IA en tant que contexte.
- L'IA génère une réponse sur la base de ce contexte.
Le résultat peut être surprenant. Souvent, des conversations que tu avais oubliées depuis longtemps refont surface. D'anciennes idées réapparaissent soudain à l'écran - parfois même dans un contexte totalement nouveau.
C'est précisément là que réside la force de cette approche. Tes archives de chat deviennent une source de connaissances consultable.
Qualité des réponses
Si tu essaies quelques interrogations, tu constateras que la qualité des réponses peut varier. C'est tout à fait normal. La qualité d'un tel système dépend de plusieurs facteurs. Un facteur important est la taille des chapitres de texte. Si les sections sont trop grandes, elles peuvent contenir plusieurs sujets. Cela rend la recherche moins précise.
En revanche, si les chunks sont trop petits, le contexte nécessaire fait parfois défaut. Un autre facteur est le modèle d'intégration. Différents modèles reconnaissent plus ou moins bien les contextes de signification. Certains sont particulièrement adaptés aux textes techniques, d'autres au langage général.
Le nombre de résultats consultés joue également un rôle. Si tu ne récupères par exemple que deux passages de texte, il se peut qu'il manque des informations importantes. En revanche, si trop de textes sont chargés, l'IA peut avoir du mal à reconnaître le contexte pertinent.
Ces paramètres peuvent être facilement adaptés par la suite. L'essentiel est d'abord de disposer d'un système de base qui fonctionne.
Problèmes typiques
Comme pour tout système technique, certaines difficultés peuvent survenir. L'un des problèmes les plus fréquents est que la base de données trouve des textes qui ne sont que partiellement pertinents. Cela est dû au fait que la recherche sémantique travaille toujours avec des probabilités.
Un autre problème peut survenir lorsque les textes sont trop fragmentés. Si une pensée est répartie sur plusieurs chunks, l'IA peut avoir des difficultés à reconnaître le contexte.
Le prompt joue également un rôle. Si l'invite n'est pas clairement formulée, il se peut que l'IA n'utilise pas le contexte de manière optimale. Un exemple d'une meilleure invite pourrait ressembler à ceci :
Utilise les extraits de texte suivants issus de mes archives de connaissances,
pour répondre le plus précisément possible à la question.
S'il y a des contenus pertinents, résume-les.
De tels petits ajustements peuvent améliorer considérablement la qualité des réponses.
Réglage fin
Une fois que le système fonctionne en principe, la partie la plus intéressante commence : le peaufinage. Ici, tu peux expérimenter et améliorer ton système de connaissances pas à pas. Voici quelques optimisations typiques :
- Ajustement de la taille des chunk
Parfois, des sections de texte plus petites donnent de meilleurs résultats. Dans d'autres cas, il est préférable d'avoir plus de contexte. - Utilisation d'un autre modèle d'intégration
Un changement de modèle peut améliorer considérablement la qualité de la recherche sémantique. - Plus de contexte pour l'IA
Tu peux extraire plus de résultats de la base de données, par exemple dix passages au lieu de cinq. - Utiliser les métadonnées
Si tu enregistres des informations supplémentaires - comme la date ou le titre de la conversation - tu pourras filtrer la recherche de manière plus précise par la suite.
Ces ajustements font partie de tout système RAG réel. Il existe rarement un réglage parfait pour toutes les situations. Mais c'est aussi ce qui fait l'intérêt de tels systèmes : ils peuvent être améliorés en permanence.
Avec ce chapitre, nous avons réalisé le premier test complet de notre système. Nous avons vu que notre IA de connaissances personnelles est effectivement capable de parcourir d'anciennes conversations et de retrouver des contenus pertinents.
Le cœur de notre projet est donc déjà atteint. Mais le système peut encore être considérablement étendu. Dans le prochain chapitre, nous verrons donc comment intégrer d'autres sources de données et développer petit à petit tes archives personnelles de connaissances.



Extensions pour ton système de connaissances IA personnel
Avec la structure que tu as mise en place jusqu'à présent, tu as déjà créé un système qui fonctionne. Tes données ChatGPT ont été extraites, transformées en embeddings, stockées dans Qdrant et finalement reliées à une IA locale. Le résultat est une IA de connaissance qui peut accéder à des conversations antérieures.
Mais à vrai dire, nous n'en sommes qu'au début. L'architecture que tu as mise en place n'est pas limitée aux données ChatGPT. Elle fonctionne avec tout type de texte. Tout ce qui peut être converti en documents ou en fichiers texte peut faire partie de ce système de connaissances. C'est là que réside le véritable potentiel de tels systèmes.
Ce que nous avons fondamentalement construit, c'est une machine à savoir personnelle. Et cette machine peut être étendue pas à pas. Dans ce chapitre, nous allons voir quelles sont les possibilités qui en découlent et comment tu peux développer ton système à long terme.
Intégrer d'autres sources de données
L'étape suivante la plus évidente consiste à ajouter d'autres contenus à ta base de connaissances. Les conversations ChatGPT sont un bon début, mais elles ne représentent généralement qu'une partie de tes connaissances. De nombreuses informations sont disponibles sous d'autres formats. Par exemple :
- propres articles
- Notes
- Documents PDF
- Documents de recherche
- Livres électroniques
- Protocoles ou listes d'idées
Tous ces contenus peuvent être traités de la même manière que nos données de chat. Le processus reste identique :
- Extraire du texte
- Diviser le texte en chunks
- Créer des embeddings
- Enregistrer les données dans Qdrant
Voici un exemple : Si tu as écrit de nombreux articles personnels, tu peux importer ces textes dans ta base de connaissances. L'IA pourra y accéder plus tard et reconnaître les liens. Tu pourrais par exemple demander
„Quels articles ai-je écrits sur l'IA ?“
ou
„Quels arguments ai-je développés précédemment sur ce sujet ?“
L'IA recherche ensuite dans tes archives d'articles et utilise les contenus trouvés comme contexte. De cette manière, ton système se développe petit à petit pour devenir une archive de connaissances complète.
Plusieurs bases de connaissances
Lorsque la quantité de données augmente, il peut être utile de séparer différents domaines. Qdrant permet de créer plusieurs collections. Chaque collection peut représenter une base de connaissances propre. Un système possible pourrait par exemple ressembler à ceci :
- Collection 1: Conversations ChatGPT
- Collection 2: Archives des articles
- Collection 3notes personnelles
- Collection 4documentation technique
Cette séparation présente plusieurs avantages. Premièrement, la structure reste claire. Tu sais à tout moment où sont stockés certains contenus. Deuxièmement, les requêtes sont plus ciblées. Certaines questions ne doivent peut-être parcourir que tes archives d'articles, d'autres l'ensemble de ton système de connaissances. Un exemple :
- Une question sur la recherche ne pourrait que consulter les archives des articles.
- En revanche, une question stratégique pourrait prendre en compte toutes les collections en même temps.
De telles structures rendent les grands systèmes de connaissances nettement plus performants.
Mises à jour automatiques
Une autre étape utile consiste à actualiser régulièrement ton système. Dans l'exemple précédent, nous avons traité une fois l'exportation des données ChatGPT. Mais dans la pratique, de nouveaux contenus sont créés en permanence.
Nouvelles conversations, nouvelles notes, nouveaux documents - toutes ces informations pourraient également faire partie de tes archives de connaissances.
Il vaut donc la peine de réfléchir à des mises à jour automatiques. Une solution simple consiste à importer régulièrement de nouvelles données. Par exemple
- traiter les nouvelles données de chat une fois par semaine
- lire automatiquement les nouveaux documents
- intégrer immédiatement les nouveaux articles dans la base de données
Techniquement, cela est relativement facile à mettre en œuvre. Un petit script peut vérifier régulièrement s'il y a de nouveaux fichiers et les traiter automatiquement. Ainsi, ton système de connaissances s'agrandit continuellement. Au fil du temps, il en résulte des archives de plus en plus volumineuses qui documentent tes pensées et tes projets.
Intégration dans des applications propres
Jusqu'à présent, notre système a été utilisé via de simples scripts Python. Mais à long terme, ce système pourra également être intégré dans des applications personnelles. De nombreux développeurs construisent par exemple de petites interfaces web qui leur permettent d'utiliser directement leur IA de la connaissance.
Au lieu de lancer un script, tu peux alors simplement écrire une question dans un champ de saisie. Le même processus s'exécute en arrière-plan :
- Créer un embedding
- Rechercher dans la base de données
- Transmettre le contexte à l'IA
- Générer la réponse
Le résultat apparaît alors directement dans l'interface. Une telle application peut prendre des formes très différentes. Par exemple
- une IC de recherche personnelle
- un assistant de connaissances pour les projets
- un moteur de recherche d'idées
- une archive pour les articles et les notes
Cela devient particulièrement passionnant lorsque l'on combine ces systèmes avec d'autres outils. Par exemple : un système de rédaction pourrait accéder automatiquement à tes archives de connaissances et utiliser des articles antérieurs comme base de recherche. Ou un système de prise de notes pourrait intégrer automatiquement de nouvelles idées dans ta base de données.
En d'autres termes, l'IA fait partie de ton environnement de travail quotidien. Cela montre clairement que notre petit projet va bien au-delà de l'exportation initiale des données ChatGPT.
Nous n'avons pas seulement créé des archives. Nous avons créé une architecture qui peut être étendue à volonté. Et c'est là que réside la véritable valeur de tels systèmes. Ils ne sont pas statiques. Ils évoluent avec tes connaissances.
Version étendue du pipeline à télécharger
Le script suivant est une version étendue du pipeline de l'article. Il est plus robuste et nettement plus proche d'une solution productive. Trois choses ont été améliorées :
- Indicateur de progression: L'utilisateur voit à tout moment combien de textes ont déjà été traités.
- Importation par lotsEmbeddings : Les embeddings sont collectés et écrits en bloc dans Qdrant, ce qui est nettement plus rapide que les importations individuelles.
- pipeline d'intégration plus rapide: Le script fonctionne de manière structurée avec des chunks préparés et réduit les appels inutiles.
Ce script convient donc particulièrement bien lorsque l'exportation ChatGPT est importante - par exemple plusieurs milliers de conversations. Déroulement typique :
- Charger l'exportation ChatGPT
- Extraire des textes
- Diviser le texte en chunks
- Créer des embeddings
- Importer par lots dans Qdrant
- Réaliser une interrogation test
Paramètres importants du script
Certaines valeurs doivent être adaptées par l'utilisateur :
- EXPORT_PFAD
Chemin d'accès aux fichiers conversations.json les plus numérotés de l'exportation ChatGPT. - NOM_COLLECTION
Nom de la collection de la base de données vectorielles. - EMBED_MODEL
Modèle d'intégration de Ollama, par exemple nomic-embed-text ou mxbai-embed-large - ANSWER_MODEL
Modèle de langue pour l'interrogation de test, par exemple llama, mistral ou gpt:oss - VECTOR_SIZE
dimension du modèle d'intégration.
nomic-embed-text → 768
mxbai-embed-large → 1024 - CHUNK_SIZE
Taille des sections de texte.
Typiquement, 300-600 mots. - BATCH_SIZE
Combien d'embeddings sont écrits simultanément dans Qdrant.
Valeur typique : 50-200.
Reste au courant - sans publicité
Si tu souhaites rester informé(e) des mises à jour de ce script ou des nouveaux téléchargements, tu peux t'inscrire à ma newsletter mensuelle. La newsletter est volontairement légère, complètement exempte de publicité et ne paraît qu'une fois par mois. Tu y trouveras une sélection des nouveaux articles les plus importants, des contenus pratiques sur l'IA, les logiciels et la numérisation ainsi que des informations sur les scripts actualisés ou les nouvelles offres de téléchargement. Pas de spam, pas de mails quotidiens - seulement les contenus les plus pertinents sous forme compacte. Si tu souhaites suivre ces développements en continu, la newsletter est le moyen le plus simple de rester à jour.
Perspective de la troisième partie : peaufinage, analyse et utilisation optimale des données
Dans la troisième partie de la série, nous allons faire un pas de plus et voir ce que l'on peut concrètement tirer de la base de connaissances constituée. Maintenant que les données ChatGPT sont stockées dans Qdrant, l'utilisation proprement dite est au centre de nos préoccupations. Nous jetons un coup d'œil à l'interface web de Qdrant, analysons les données stockées et vérifions si la recherche sémantique fonctionne déjà bien. En outre, il s'agit de procéder à d'importants réglages fins : Comment le chunking doit-il être choisi en fonction de l'application ? Comment transmettre de manière optimale le contexte à un modèle linguistique local ? Et comment peut-on améliorer la qualité des réponses de manière ciblée ? La troisième partie s'adresse à tous ceux qui souhaitent tirer davantage du système et le faire évoluer en toute connaissance de cause.




Foire aux questions
- Quel est l'intérêt d'intégrer l'exportation de mes données ChatGPT dans ma propre IA ?
Le principal avantage réside dans le fait que tu peux utiliser tes propres conversations et pensées de manière durable. De nombreuses personnes ont des conversations intensives avec les systèmes d'IA sur des projets, des idées, des analyses ou des questions personnelles. Ces contenus disparaissent généralement au fil de la plateforme. Mais si tu les exportes et les intègres dans ta propre base de connaissances, tu en feras des archives personnelles. Ton IA locale peut alors accéder à ces contenus, reconnaître les liens et t'aider à répondre à de nouvelles questions. Au lieu de toujours repartir de zéro, tu construis petit à petit sur ta propre réflexion. - N'est-ce pas très compliqué pour quelqu'un qui n'est pas développeur ?
Au premier abord, des termes tels que embeddings, bases de données vectorielles ou systèmes RAG semblent complexes. Dans la pratique, les différentes étapes sont toutefois relativement claires. En fait, tu n'as besoin que de trois composants : une IA locale (par exemple via Ollama), une base de données vectorielle comme Qdrant et un petit script Python qui traite tes données. De nombreuses étapes se déroulent automatiquement. Une fois le système mis en place, il fonctionne comme un moteur de recherche normal ou un chatbot - sauf qu'il travaille avec tes propres connaissances. - Quelles sont exactement les données contenues dans l'exportation ChatGPT ?
L'exportation ChatGPT contient en général toutes les conversations que tu as eues avec le système. Cela comprend non seulement les messages de texte eux-mêmes, mais aussi les métadonnées telles que les titres des conversations, l'horodatage et les informations structurelles. La plupart du temps, les données sont disponibles au format JSON et peuvent donc être traitées relativement facilement par des scripts. Dans de nombreux cas, l'exportation comprend également des médias ou des fichiers vocaux, si ceux-ci ont été utilisés dans les entretiens. Toutefois, pour la constitution d'une base de connaissances, ce sont surtout les contenus textuels qui sont intéressants. - Pourquoi utilise-t-on une base de données de vecteurs et non une base de données normale pour de tels systèmes ?
Les bases de données normales conviennent parfaitement lorsque l'on recherche des termes ou des identifiants concrets. Elles sont toutefois moins adaptées à la recherche sémantique. Une base de données vectorielle ne stocke pas seulement les textes sous forme de chaînes de caractères, mais aussi sous forme de vecteurs mathématiques qui décrivent la signification d'un texte. Cela permet au système de rechercher des similitudes de contenu. Par exemple, si tu demandes „idées d'articles sur l'intelligence artificielle“, la base de données peut également trouver des contenus dans lesquels figurent d'autres formulations telles que „sujets d'articles de blog sur l'intelligence artificielle“. - Qu'est-ce que les embeddings et pourquoi sont-ils si importants ?
Les embeddings sont des représentations mathématiques de textes. Un modèle linguistique transforme un texte en une liste de chiffres qui décrivent la signification du texte. Les textes ayant une signification similaire sont proches les uns des autres dans l'espace mathématique. Cela permet à une base de données vectorielle de rechercher ultérieurement des contenus similaires. Sans les embeddings, la recherche sémantique ne serait guère possible. Ils constituent le fondement des systèmes RAG modernes et sont la raison pour laquelle de tels systèmes sont beaucoup plus flexibles que la recherche plein texte classique. - Quelle est la taille maximale de mon exportation de données ChatGPT ?
La taille ne joue en principe pas un grand rôle. Même plusieurs milliers de conversations peuvent être traitées sans problème. Ce qui est déterminant, c'est plutôt le nombre de sections de texte générées, les fameux chunks. Une exportation plus importante entraîne un plus grand nombre de chunks et donc d'embeddings. Les bases de données vectorielles modernes peuvent toutefois gérer sans problème des millions d'entrées de ce type. Pour un assistant de connaissances privé, même un petit serveur ou un ordinateur de bureau performant suffit amplement. - Pourquoi le texte est-il divisé en petites sections avant d'être traité ?
Si l'on enregistre directement des conversations complètes ou de grands textes sous forme d'embeddings, la recherche sémantique devient imprécise. Un seul texte pourrait contenir plusieurs sujets. En le divisant en sections plus petites, le système peut ensuite effectuer une recherche beaucoup plus précise. Chaque section décrit un thème plus clair. Ainsi, la base de données trouve exactement les parties d'une conversation qui correspondent vraiment à la question actuelle. - Quel est le rôle de Ollama dans ce système ?
Ollama sert de plate-forme locale pour les modèles linguistiques. Il te permet d'exécuter des modèles d'IA directement sur ton propre ordinateur. Dans notre système, Ollama remplit deux fonctions : Il crée des embeddings pour les textes et génère des réponses aux questions. L'avantage, c'est que toutes les données restent locales. Tes conversations et tes archives de connaissances ne quittent donc jamais ton propre ordinateur. - Pourquoi Qdrant est-il utilisé comme base de données vectorielles ?
Qdrant est une base de données vectorielle moderne, spécialement conçue pour les applications d'intelligence artificielle. Elle est rapide, facile à installier et très bien documentée. De plus, elle se connecte facilement à Python et à de nombreux frameworks d'IA. Pour les systèmes de connaissances locaux, Qdrant est donc une solution particulièrement pratique. Des alternatives seraient par exemple Chroma, Weaviate ou Pinecone. - Que signifie le terme "système RAG" ?
RAG est l'abréviation de „Retrieval-Augmented Generation“. Il s'agit d'une architecture dans laquelle une IA récupère d'abord des informations pertinentes dans une base de données et les utilise ensuite pour générer une réponse. L'IA combine donc ses propres connaissances avec des données externes. Elle peut ainsi donner des réponses très précises tout en accédant à des informations actuelles ou personnelles. - Puis-je intégrer d'autres sources de données dans ce système ?
Oui, c'est même l'un des plus grands avantages de cette architecture. Le système n'est pas limité aux données ChatGPT. Tu peux aussi intégrer tes propres articles, notes, PDF, documents de recherche ou autres documents. Tant que le contenu peut être traité sous forme de texte, il peut faire partie de la base de connaissances. Ton système se transforme ainsi au fil du temps en une archive de connaissances complète. - Dans quelle mesure un tel système de connaissances reste-t-il actuel ?
L'actualité dépend de la fréquence à laquelle tu importes de nouvelles données. Tu peux par exemple traiter régulièrement de nouvelles exportations ChatGPT ou créer un script qui détecte automatiquement les nouveaux documents. De nombreux systèmes sont configurés pour être mis à jour une fois par semaine ou une fois par mois. Ainsi, la base de connaissances reste toujours à jour. - De quel matériel ai-je besoin pour un tel système ?
Pour les petits projets, un ordinateur de bureau moderne suffit déjà. Si tu souhaites utiliser un modèle linguistique plus important, un GPU peut s'avérer utile. Toutefois, de nombreux utilisateurs exploitent également avec succès leurs systèmes de connaissances sur un ordinateur portable performant ou un mini-serveur. Il est surtout important de disposer de suffisamment de mémoire vive et d'un espace de stockage suffisant pour la base de données. - Quelle est la vitesse de fonctionnement d'un tel système dans la pratique ?
La vitesse dépend de plusieurs facteurs, par exemple de la taille de la base de données, du matériel et du modèle de langage utilisé. Dans de nombreux cas, une requête ne prend que quelques secondes. La recherche vectorielle elle-même est généralement extrêmement rapide. La plus grande partie du temps est souvent consacrée à la génération de la réponse du modèle de langage. - Est-il possible de séparer plusieurs domaines de connaissances ?
Oui, les bases de données vectorielles comme Qdrant permettent d'utiliser plusieurs collections. Chaque collection peut représenter un domaine thématique propre. Tu pourrais par exemple créer une collection pour les conversations ChatGPT, une pour les articles et une pour les notes. Cela permet de structurer proprement les domaines de connaissances et d'effectuer des recherches ciblées. - Dans quelle mesure mes données sont-elles en sécurité dans un système d'IA local ?
Le grand avantage d'un système local est que tes données ne doivent pas être transmises à des services externes. Toutes les informations restent sur ton propre ordinateur ou serveur. C'est particulièrement intéressant pour les contenus sensibles. Bien entendu, tu dois tout de même effectuer des sauvegardes régulières et protéger ton système contre tout accès non autorisé. - Puis-je également intégrer ce système dans mes propres applications ?
Oui, la plupart des composants sont accessibles via des interfaces de programmation. Tu peux ainsi intégrer ton système de connaissances dans tes propres outils, par exemple dans une interface web, un système de rédaction ou une application de prise de notes. De nombreux développeurs construisent de petites applications qui rendent leur base de connaissances directement accessible via une interface de chat. - Comment cette technologie pourrait-elle évoluer à l'avenir ?
Les IA de connaissances personnelles n'en sont probablement qu'au début de leur développement. À l'avenir, de tels systèmes pourraient intégrer automatiquement de nouveaux contenus, créer des résumés ou même fournir leurs propres propositions de projets. Plus les données affluent dans un tel système, plus il devient précieux. À long terme, il pourrait devenir une sorte de mémoire numérique personnelle qui structurerait tes connaissances et les rendrait accessibles à tout moment.



