
Nella prima parte di questa serie di articoli, abbiamo visto che l'esportazione dei dati di ChatGPT è molto più di una semplice funzione tecnica. I dati esportati contengono una raccolta di pensieri, idee, analisi e conversazioni accumulate in un lungo periodo di tempo. Ma finché questi dati vengono memorizzati solo come archivio sul disco rigido, rimangono solo questo: un archivio. Il passo cruciale è rendere queste informazioni nuovamente utilizzabili. È proprio qui che inizia lo sviluppo di un'intelligenza artificiale personale.
L'idea è in realtà sorprendentemente semplice: un'intelligenza artificiale non deve solo lavorare con conoscenze generali, ma anche essere in grado di accedere ai dati dell'utente. Deve cercare nelle conversazioni precedenti, trovare i contenuti adatti e incorporarli nelle nuove risposte. In questo modo, una normale IA si trasforma in una sorta di memoria digitale. Questa è la seconda parte della serie di articoli, che ora si occupa dell'aspetto pratico.



Parte 1 della serie: Il tesoro sottovalutato dell'esportazione dei dati ChatGPT
Mentre in questa seconda parte ci addentriamo nell'aspetto pratico, vale la pena di dare un'occhiata al primo articolo di questa serie. L'articolo affronta la questione fondamentale del perché l'esportazione dei dati di ChatGPT sia così interessante e perché molti utenti ne sottovalutano ancora il potenziale. L'articolo mostra quali dati sono effettivamente contenuti nell'esportazione, come possono essere utilizzati per creare un archivio di conoscenze personali e perché questo passaggio costituisce la base per la vostra AI con memoria. Se volete capire perché stiamo costruendo questa pipeline e quale valore strategico hanno le vostre cronologie di chat, dovreste iniziare con la prima parte.
Prima di iniziare l'implementazione vera e propria nel prossimo capitolo, diamo prima un'occhiata a come è strutturato fondamentalmente un sistema di questo tipo.
L'idea di base di un sistema RAG
La base tecnica del nostro sistema è un concetto ormai ampiamente diffuso nel mondo dell'intelligenza artificiale: RAG, ovvero Retrieval Augmented Generation. Dietro questo termine si nasconde un principio molto pratico.
Normalmente, un modello linguistico risponde alle domande esclusivamente con le conoscenze apprese durante l'addestramento. Sebbene questa conoscenza sia ampia, presenta due limiti decisivi:
- In primo luogo, il modello non conosce alcuna informazione individuale sui vostri progetti o pensieri.
- In secondo luogo, non può accedere a nuovi dati creati dopo l'addestramento.
È proprio qui che entra in gioco un sistema RAG. Invece di generare direttamente una risposta, il sistema cerca in un database i contenuti che corrispondono alla domanda posta. Questi contenuti vengono poi trasferiti al modello linguistico come contesto. Solo a questo punto l'intelligenza artificiale formula la sua risposta. In termini semplici, il processo è il seguente:
- Fai una domanda →
- il sistema cerca in un database di conoscenze →
- si trovano i contenuti rilevanti →
- Questo contenuto viene trasferito all'IA come contesto →
- l'IA genera una risposta.
Il vantaggio decisivo è evidente: l'IA può utilizzare informazioni che non facevano parte del suo addestramento originale.
Ed è qui che entrano in gioco i dati di ChatGPT. Se integriamo queste conversazioni in un database di conoscenze, l'IA può accedervi in seguito. Può trovare idee precedenti, utilizzare argomenti di vecchi dialoghi o prendere in considerazione analisi di conversazioni passate. Il sistema inizia quindi a „ricordare“ i vostri pensieri.
Gli elementi costitutivi del nostro sistema
Perché questo funzioni, abbiamo bisogno di diversi componenti che lavorino insieme. Fortunatamente, oggi l'infrastruttura tecnica è molto più facile da raggiungere rispetto a qualche anno fa. Il nostro sistema è costituito da quattro componenti centrali.
- Il primo blocco di costruzione è il Esportazione dei dati ChatGPT. Ecco i nostri dati grezzi. Contiene tutte le conversazioni che abbiamo avuto in precedenza con l'IA.
- Il secondo blocco di costruzione è un Modello di incorporazione. Questo modello traduce il testo in vettori matematici. In questo modo è possibile confrontare i testi in base al loro significato.
- Il terzo blocco di costruzione è un Database vettoriale. Nel nostro caso, utilizziamo Qdrant. Questo database memorizza le rappresentazioni matematiche dei testi e consente una rapida ricerca semantica.
- Il quarto blocco di costruzione è un modello linguistico locale, che funziona tramite Ollama. Questo modello formulerà in seguito le risposte effettive.
Questi quattro componenti lavorano a stretto contatto.
- L'esportazione dei dati fornisce il contenuto.
- Il modello di incorporazione li rende leggibili dalla macchina.
- Il database vettoriale li salva e li ricerca.
- Il modello linguistico genera infine risposte comprensibili.
Insieme, costituiscono la base di un'intelligenza artificiale personale.
Il flusso di dati in sintesi
Affinché il sistema funzioni, i dati devono passare attraverso diverse fasi. Il primo passo è l'esportazione dei dati di ChatGPT, che abbiamo già creato nel primo articolo. Le conversazioni che contiene vengono prima estratte dai file JSON. Questi testi devono poi essere preparati. Le cronologie di chat di grandi dimensioni vengono suddivise in sezioni più piccole, note come pezzi di testo. Questo rende la ricerca successiva molto più efficiente.
Nella fase successiva, generiamo embeddings da queste sezioni di testo. Ogni testo viene descritto matematicamente. Ai testi con un significato simile vengono assegnati vettori simili. Questi vettori vengono poi salvati nel nostro database vettoriale Qdrant.
Ciò significa che la parte più importante dell'infrastruttura è già pronta. Se la domanda viene posta in un secondo momento, si verifica quanto segue:
- Anche la domanda viene convertita in un vettore.
- Il database cerca testi con un significato simile.
- Questi passaggi di testo vengono trasferiti al modello linguistico come contesto.
- Il modello utilizza queste informazioni per formulare una risposta.
Questo processo garantisce che l'IA non solo utilizzi le conoscenze generali, ma possa anche accedere ai dati dell'utente.
Cosa sarà possibile fare alla fine
Una volta impostato il sistema, il rapporto con l'IA cambia notevolmente. Non si lavora più solo con un modello linguistico generico, ma con un'intelligenza artificiale che può accedere ai vostri dati. Questo apre possibilità completamente nuove. Ad esempio, è possibile porre domande come:
„Ho mai parlato di questo argomento con l'IA?“.“
„Quali idee avevo prima di questo progetto?“.“
„Quali argomenti ho sviluppato nelle conversazioni precedenti?“.“
L'intelligenza artificiale cerca quindi nelle conversazioni dell'utente e trova i contenuti adatti. Invece di dare una risposta generica, può fare riferimento a pensieri precedenti, riassumere vecchie analisi o riconoscere connessioni tra conversazioni diverse.
In altre parole, l'intelligenza artificiale inizia a lavorare con il vostro archivio di conoscenze. Questo trasforma un semplice strumento di chat in un sistema in grado di supportare il vostro pensiero a lungo termine. È proprio questo sistema che costruiremo passo dopo passo nei prossimi capitoli. Nella prossima sezione, inizieremo con il lavoro pratico e daremo un'occhiata più da vicino all'esportazione dei dati di ChatGPT. Perché prima di costruire un database della conoscenza, dobbiamo capire come sono strutturati i nostri dati.
Indagine in corso sull'uso dei sistemi di intelligenza artificiale locali
Preparazione: Comprendere l'esportazione dei dati di ChatGPT
Nel primo articolo di questa serie, abbiamo già creato l'esportazione dei dati di ChatGPT e l'abbiamo scaricata come file ZIP. A prima vista, questo file può sembrare poco spettacolare: un archivio con alcuni file tecnici che inizialmente sembra più un backup che un prezioso set di dati. Tuttavia, questo archivio contiene la base del nostro intero sistema di conoscenze.
Prima di iniziare a caricare questi dati in un database o a collegarli a un'intelligenza artificiale, dobbiamo innanzitutto capire come è strutturato l'export. Infatti, solo se sappiamo quali informazioni sono contenute e come sono strutturate possiamo elaborarle in seguito in modo significativo. In questo capitolo vedremo quindi come è strutturata l'esportazione dei dati, quali sono i file veramente rilevanti e come possiamo trasformare questo archivio tecnico in una base utile per il nostro sistema di conoscenza dell'IA.
Decomprimere il file ZIP
Il primo passo è banale, ma comunque importante: dobbiamo decomprimere l'archivio scaricato. Il file è normalmente disponibile come un classico file ZIP. A seconda dell'entità dell'utilizzo precedente, le dimensioni possono variare. Alcuni utenti ricevono un archivio di poche centinaia di megabyte, altri di diversi gigabyte.
Dopo aver scompattato il file, viene creata una cartella con diversi file e sottocartelle. La struttura esatta può variare leggermente, ma in genere si trovano diversi file JSON ed eventualmente altri file con informazioni aggiuntive.
Per molti utenti, questa struttura appare inizialmente un po' tecnica. Ma se ci si sofferma un attimo, si riconosce subito uno schema: i dati sono organizzati in modo relativamente ordinato e seguono una struttura chiara. È una buona notizia, perché è proprio questa struttura che consente di elaborare i contenuti in modo automatico.
Struttura dei dati della chat
La parte più importante dell'esportazione è costituita dai dati della chat. Queste conversazioni sono solitamente memorizzate in uno o più file JSON. JSON è un formato di dati molto diffuso, spesso utilizzato per memorizzare informazioni strutturate.
Un file di questo tipo non contiene semplicemente un lungo testo. Un dialogo è invece suddiviso in singoli elementi. In genere, un dialogo è composto da diversi messaggi. Ogni messaggio contiene informazioni quali
- il testo effettivo del messaggio
- il ruolo del mittente (utente o AI)
- una marcatura temporale
- in parte ulteriori metadati
In questo modo è possibile ricostruire l'intero corso del dialogo. Ad esempio, un dialogo inizia con una domanda dell'utente. A questa segue una risposta dell'IA. Possono poi seguire altre domande e risposte. Ognuno di questi messaggi viene salvato singolarmente.
Questo ha un grande vantaggio: possiamo riconoscere in seguito chi ha detto cosa e come si è sviluppata una conversazione. Questo è particolarmente importante per il nostro sistema di conoscenza, in quanto vogliamo cercare e analizzare in seguito proprio questi contenuti.
Quali dati ci servono davvero
Sebbene l'esportazione contenga molte informazioni, non tutte sono necessarie per il nostro sistema di conoscenza. Il componente più importante è costituito dai testi delle conversazioni. Questi testi contengono il contenuto vero e proprio: idee, analisi, domande e risposte. È proprio questo contenuto che vogliamo cercare in seguito.
Anche alcuni metadati possono essere utili. Questi includono, ad esempio
- Timestamp
- Titolo della conversazione
- Possibilmente numeri di identificazione interna
Queste informazioni ci aiutano a ordinare meglio i contenuti in un secondo momento o a classificare una conversazione in termini di tempo. Altri componenti dell'esportazione sono meno rilevanti per il nostro progetto. Si tratta, ad esempio, di alcuni metadati tecnici che sono interessanti solo per il funzionamento interno della piattaforma.
Per costruire la nostra base di conoscenza, ci concentriamo quindi deliberatamente sull'essenziale: i testi delle conversazioni e alcune informazioni contestuali di base. Quanto più chiaramente strutturiamo questi dati, tanto meglio la nostra IA potrà lavorarci in seguito.
Prima revisione dei dati
Prima di iniziare a lavorare con gli script automatici, vale la pena dare una rapida occhiata ai dati stessi. A tale scopo, aprite uno dei file JSON con un semplice editor di testo o con un programma in grado di visualizzare bene i file JSON. Molti editor di codice come Visual Studio Code sono molto adatti a questo scopo, ma anche semplici editor di testo funzionano.
Quando si guarda il file per la prima volta, probabilmente si vedrà una quantità relativamente grande di dati strutturati. I file JSON sono costituiti da elementi annidati, ossia campi di dati che a loro volta contengono altri campi. All'inizio può sembrare un po' complesso, ma con un po' di pazienza si riconoscerà rapidamente la struttura di base. Ad esempio, si vedrà che una conversazione è composta da diversi messaggi e che ogni messaggio rappresenta un oggetto separato. Il testo vero e proprio si trova di solito in un campo chiaramente riconoscibile.
Questo primo screening ha uno scopo importante: aiuta a capire come sono strutturati i dati. Nel prossimo capitolo, infatti, utilizzeremo proprio questa struttura per leggere automaticamente le conversazioni e prepararle per il nostro sistema di conoscenza. In altre parole: Stiamo trasformando passo dopo passo un archivio di dati tecnici in una base di conoscenza utilizzabile. Ed è proprio da qui che partiamo nel prossimo capitolo. L'obiettivo è quello di estrarre i dati delle chat e prepararli in modo tale da poterli ricercare in seguito in modo efficiente.
Preparare i dati: Dalle conversazioni ai testi analizzabili
Dopo aver scompattato l'esportazione dei dati di ChatGPT nel capitolo precedente e aver ottenuto una prima panoramica della struttura, ora inizia la parte tecnica del nostro progetto. Sebbene i dati esportati siano completi, non sono ancora adatti al nostro sistema di conoscenza in questa forma.
Il motivo è semplice: le cronologie delle chat sono solitamente lunghe, contengono molti argomenti e sono memorizzate in una struttura leggibile per gli esseri umani, ma non ideale per le ricerche semantiche o i database vettoriali. Per consentire alla nostra IA di trovare contenuti rilevanti in un secondo momento, dobbiamo prima elaborare questi dati grezzi. Questo significa essenzialmente tre cose:
- Estrarre le conversazioni dai file JSON
- strutturare i testi in modo sensato
- dividere i contenuti in sezioni più piccole
Questo processo è una fase del tutto normale nei moderni sistemi di intelligenza artificiale e viene spesso definito preelaborazione.
Perché i dati grezzi non sono direttamente adatti
Se si dà un'occhiata a uno dei file JSON, si noterà che una singola chat è spesso composta da molti messaggi. Un dialogo tipico può apparire come questo, ad esempio:
- Domanda
- Risposta
- Richiesta
- nuova dichiarazione
- ulteriori dettagli
- Sintesi
Alcune conversazioni possono contenere centinaia o addirittura migliaia di parole. Questo non è un problema per gli esseri umani. Noi leggiamo semplicemente un dialogo dall'inizio alla fine.
Tuttavia, questo funziona meno bene per una ricerca AI. Il motivo è che una singola chat spesso contiene diversi argomenti. Se in seguito effettuiamo una ricerca semantica, il sistema deve trovare passaggi di testo il più precisi possibile, non intere conversazioni con molti contenuti diversi.
Per questo motivo i testi di grandi dimensioni vengono suddivisi in sezioni più piccole. Queste sezioni sono chiamate "chunks". Un pezzo è semplicemente un piccolo blocco di testo che contiene un pensiero coerente. Questo metodo migliora notevolmente la qualità della ricerca in seguito.
Estrarre la cronologia delle chat
Il primo passo pratico consiste nel leggere il contenuto dei file JSON. A tale scopo utilizziamo un piccolo script Python. Python è particolarmente adatto a questo tipo di compiti perché contiene molte librerie per l'elaborazione dei dati e l'intelligenza artificiale.
Creare prima un nuovo file, ad esempio:
extract_chats.py
Poi aggiungiamo un semplice script che carica i dati della chat.
import json
with open("conversations.json", "r", encoding="utf-8") as f:
data = json.load(f)
print("Anzahl der Gespräche:", len(data))Quando si esegue questo script, si dovrebbe vedere quante conversazioni sono contenute nell'esportazione. Ora estraiamo i testi veri e propri.
texts = []
for conversation in data:
if "mapping" in conversation:
for node in conversation["mapping"].values():
message = node.get("message")
if message:
content = message.get("content")
if content and "parts" in content:
text = " ".join(content["parts"])
texts.append(text)
print("Extrahierte Textabschnitte:", len(texts))Questo script scorre la struttura JSON e raccoglie tutte le parti di testo delle conversazioni. Questo significa che abbiamo già completato la parte più importante: abbiamo estratto il contenuto dal formato tecnico di esportazione.
Creare pezzi di testo
Ora viene il prossimo passo importante: il chunking. Invece di salvare conversazioni complete, dividiamo i testi in sezioni più piccole.
Le dimensioni tipiche di queste sezioni di testo sono comprese tra 300 e 800 parole o circa 500 token. Di seguito è riportato un semplice esempio di come suddividere i testi in parti.
def split_text(text, chunk_size=500):
words = text.split()
chunks = []
for i in range(0, len(words), chunk_size):
chunk = " ".join(words[i:i+chunk_size])
chunks.append(chunk)
return chunksOra possiamo applicare questa funzione ai nostri testi.
all_chunks = []
for text in texts:
chunks = split_text(text)
all_chunks.extend(chunks)
print("Gesamtzahl der Chunks:", len(all_chunks))Abbiamo creato molte sezioni di testo più piccole dalle nostre cronologie di chat. Questi blocchi di testo sono ideali per una successiva ricerca in un database vettoriale.
Aggiungere metadati
Oltre al testo vero e proprio, possono essere molto utili ulteriori informazioni. Questi cosiddetti metadati ci aiutano a ordinare o filtrare meglio i contenuti in un secondo momento. I metadati tipici possono essere
- Data della conversazione
- Titolo della conversazione
- Fonte (esportazione ChatGPT)
- ID della chiamata
Possiamo salvare queste informazioni insieme al testo, ad esempio in questo modo:
documents = []
for conversation in data:
title = conversation.get("title", "Unbekannt")
if "mapping" in conversation:
for node in conversation["mapping"].values():
message = node.get("message")
if message:
content = message.get("content")
if content and "parts" in content:
text = " ".join(content["parts"])
chunks = split_text(text)
for chunk in chunks:
documents.append({
"text": chunk,
"title": title
})Questo ha già dato ai nostri dati una struttura molto migliore. Invece di un confuso archivio di chat, ora abbiamo una raccolta di tante piccole sezioni di testo, ognuna delle quali è corredata di informazioni contestuali.
È proprio questa struttura che sarà cruciale nella fase successiva. Perché ora possiamo iniziare a generare embeddings da questi testi, cioè rappresentazioni matematiche del contenuto che saranno poi salvate nel nostro database vettoriale. Ed è proprio questo l'obiettivo del prossimo capitolo.
Creare le incorporazioni
Nel capitolo precedente, abbiamo già messo i dati di ChatGPT in una forma utilizzabile. Abbiamo estratto le conversazioni dai file JSON, ripulito i testi e li abbiamo suddivisi in sezioni più piccole, i cosiddetti chunks.
Tuttavia, manca ancora un passaggio cruciale prima che la nostra IA possa davvero cercare contenuti in modo significativo. I testi devono essere tradotti in una forma che le macchine possano confrontare. È qui che entrano in gioco le incorporazioni.
Le incorporazioni sono rappresentazioni matematiche dei testi. Consentono ai computer di confrontare il significato dei testi. Due testi con contenuti simili ricevono vettori simili, anche se usano parole diverse. Questa è proprio la proprietà di cui abbiamo bisogno per il nostro sistema di conoscenza. Dopo tutto, la nostra IA non deve solo cercare parole identiche, ma anche testi con contenuti simili.
Cosa sono le incorporazioni
Un embedding è fondamentalmente un elenco di numeri. Questi numeri descrivono il significato di un testo in uno spazio matematico. Ogni testo viene convertito in un cosiddetto vettore. Un vettore di questo tipo può apparire, ad esempio, come segue:
[0.134, -0.876, 0.442, 0.921, -0.223, ...]
Un singolo vettore può contenere diverse centinaia o addirittura migliaia di numeri. Questi numeri, ovviamente, non sono direttamente comprensibili per gli esseri umani. Per le macchine, tuttavia, sono ideali per calcolare le somiglianze tra i testi. Se due testi hanno contenuti simili, i loro vettori sono più vicini nello spazio matematico. Un esempio:
- Testo A„Come posso esportare i miei dati ChatGPT?“.“
- Testo B: „Come faccio a scaricare le mie conversazioni ChatGPT?“.“
Sebbene la formulazione sia diversa, entrambi i testi descrivono fondamentalmente lo stesso argomento. Un buon modello di incorporazione riconosce questa somiglianza. I due testi ricevono quindi vettori simili. In seguito utilizzeremo proprio questo principio per la nostra ricerca semantica.
Modelli di integrazione con Ollama
Abbiamo bisogno di un modello speciale per creare le incorporazioni. Fortunatamente, non è necessario ricorrere a servizi cloud esterni. Molti modelli di embedding possono essere gestiti localmente, ed è qui che entra in gioco l'Ollama.
Dato che l'Ollama è già in esecuzione sul sistema, possiamo incorporare un modello install. Un ottimo modello è, ad esempio, il seguente:
nomic-embed-text
È possibile addomesticarlo con il seguente comando 1TP12:
ollama pull nomic-embed-text
Altri modelli popolari sono
- mxbai-embed-grande
- bge-grande
- tutti i film
Per i nostri scopi testo incorporato nomico è un ottimo punto di partenza. Questo modello genera embeddings di alta qualità e funziona localmente senza problemi.
Creare le incorporazioni localmente
Ora vogliamo estendere il nostro script Python in modo che possa generare embeddings. Per prima cosa 1TP12Creiamo una libreria con cui Python possa comunicare con Ollama.
pip install ollama
Ora è possibile utilizzare il modello di incorporazione direttamente da Python. Il seguente è un semplice esempio:
import ollama
response = ollama.embeddings(
model="nomic-embed-text",
prompt="Wie exportiere ich meine ChatGPT-Daten?"
)
print(len(response["embedding"]))Se tutto ha funzionato, si otterrà un vettore con diverse centinaia di numeri.
Ora applichiamo questo metodo ai nostri chunk di chat.
embeddings = []
for doc in documents:
text = doc["text"]
result = ollama.embeddings(
model="nomic-embed-text",
prompt=text
)
vector = result["embedding"]
embeddings.append({
"text": text,
"embedding": vector,
"title": doc["title"]
})Questo viene utilizzato per creare un vettore per ogni sezione di testo. Questi vettori vengono poi salvati nel nostro database.
Perché questa fase è fondamentale
Gli embeddings sono il cuore dei moderni sistemi di conoscenza. Senza embedding, potremmo cercare nei testi solo con la classica ricerca per parole chiave. Ciò significa che il sistema troverebbe solo contenuti che contengono esattamente le stesse parole. Ma il linguaggio raramente funziona in modo così semplice. Ad esempio, un utente potrebbe chiedere:
„Come ho elaborato i miei dati ChatGPT?“.“
Tuttavia, la conversazione originale potrebbe essere formulata come:
„Come posso analizzare l'esportazione dei dati di ChatGPT?“.“
Una semplice ricerca potrebbe non riconoscere questo collegamento. Con le incorporazioni è diverso. Poiché i due testi hanno significati simili, i loro vettori sono vicini nello spazio matematico. Il nostro database può quindi trovare contenuti corrispondenti, anche se la formulazione è diversa. È proprio questa capacità che rende la ricerca semantica così potente. Permette a un'intelligenza artificiale di cercare non solo le parole, ma anche il significato.
Ed è proprio per questo che le incorporazioni sono l'elemento centrale del nostro sistema. Nel prossimo capitolo, ci baseremo su questo e installiereneremo il nostro database di vettori. In esso memorizzeremo i vettori generati, creando così la base per la nostra IA della conoscenza personale.
Qdrant 1TP12Aggiungi e configura
Dopo aver creato le incorporazioni per i nostri dati di chat nel capitolo precedente, abbiamo ora una collezione di sezioni di testo e vettori associati. Questi vettori descrivono matematicamente il significato dei testi e costituiscono quindi la base per una ricerca semantica. Tuttavia, questi dati sono attualmente disponibili solo nella memoria di lavoro del nostro script o in semplici elenchi. Abbiamo bisogno di una memoria specializzata in modo che la nostra IA possa accedervi in modo efficiente in seguito.
È proprio qui che entra in gioco un database vettoriale. Un database vettoriale è ottimizzato per memorizzare grandi quantità di tali incorporazioni e cercare rapidamente vettori simili. Per il nostro progetto utilizziamo Qdrant, un moderno database open-source sviluppato appositamente per le applicazioni di intelligenza artificiale.
In questo capitolo 1TP12 installeremo Qdrant, avvieremo il server e prepareremo il database in modo da poter importare facilmente i dati della chat in seguito.
Cos'è Qdrant
Qdrant è un database specializzato per le cosiddette ricerche vettoriali. Mentre i database tradizionali memorizzano le informazioni in tabelle, come nomi, numeri o testi, un database vettoriale lavora con rappresentazioni matematiche dei dati.
Ciò significa che, invece di salvare solo il testo, Qdrant salva le incorporazioni associate. Il grande vantaggio sta nella ricerca. Se in seguito viene posta una domanda, il nostro sistema converte anche questa domanda in un vettore. Qdrant può quindi calcolare alla velocità della luce quali sono i testi memorizzati più simili a questo vettore. In questo modo è possibile scoprire, ad esempio, quali sono i testi più simili a questo vettore:
- quali passaggi della chat corrispondono tematicamente alla domanda
- quali conversazioni precedenti contengono contenuti simili
- quali idee potrebbero essere rilevanti nel vostro archivio
Proprio per questo motivo Qdrant è oggi utilizzato in molti moderni sistemi di intelligenza artificiale, dalla ricerca di documenti a complessi assistenti alla conoscenza. Un altro vantaggio: Qdrant è open source, viene rapidamente 1TP12alizzato e funziona senza problemi su una normale macchina locale.
Installazione di Qdrant
Il modo più semplice per installieren Qdrant è tramite Docker. Se Docker è disponibile sul vostro computer, potete avviare il server con un solo comando. Qui è possibile Scaricare Docker, se non è ancora stato installato sul computer installiert.
docker run -p 6333:6333 qdrant/qdrant
Questo comando avvia il server Qdrant e apre la porta standard 6333. I nostri script possono successivamente comunicare con il database attraverso questa porta.
Se non si desidera utilizzare Docker, esistono anche altri modi per installiere Qdrant, ad esempio tramite un binario locale o un gestore di pacchetti. In molti progetti pratici, tuttavia, Docker si è dimostrato l'opzione più semplice e stabile.
Dopo l'avvio del server, Qdrant viene eseguito in background e attende le richieste. È ora possibile verificare se il server è accessibile. A tal fine, aprire il seguente indirizzo nel browser:
http://localhost:6333
Se tutto ha funzionato, dovrebbe apparire un semplice messaggio di stato. Il server è ora pronto per le fasi successive.
Primi passi con Qdrant
Prima di importare i dati della chat, è necessario creare una cosiddetta raccolta. In Qdrant, una collezione è paragonabile a una tabella in un database classico. Contiene i nostri vettori e i dati corrispondenti.
Per prima cosa, abbiamo installiere la libreria Python per Qdrant:
pip install qdrant-client
Ora possiamo stabilire una connessione al database nel nostro script Python.
from qdrant_client import QdrantClient
client = QdrantClient("localhost", port=6333)Se questo codice viene eseguito senza un messaggio di errore, la connessione è riuscita. Ora creiamo una collezione per i dati della chat.
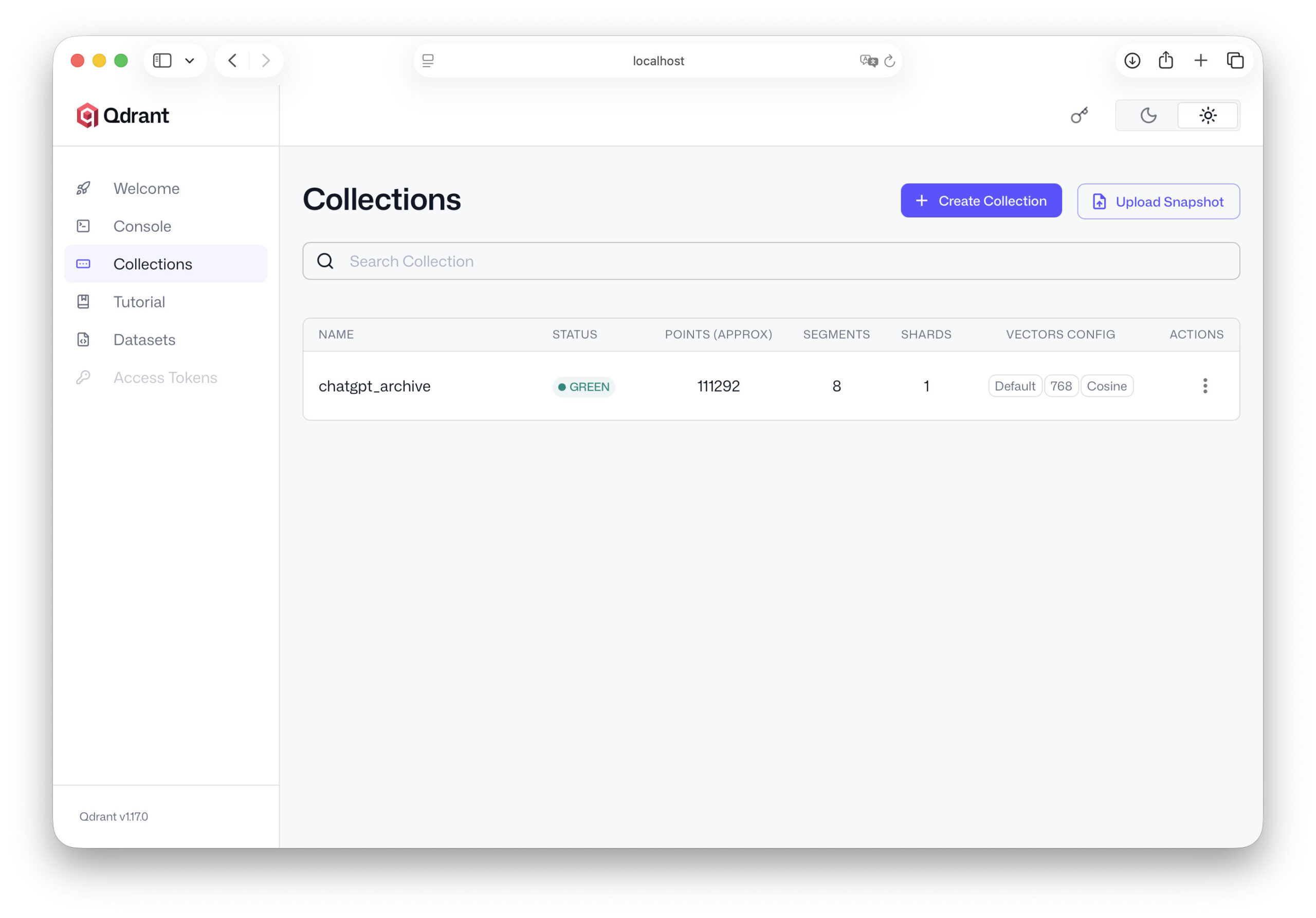
from qdrant_client.models import VectorParams, Distance client.recreate_collection( collection_name="chatgpt_archive", vectors_config=VectorParams(size=768, distance=Distance.COSINE), )
I parametri più importanti sono
- nome_raccolta - il nome del nostro database
- dimensione - la lunghezza dei vettori di incorporazione
- distanza - il metodo di calcolo della somiglianza
La dimensione del vettore dipende dal modello di incorporazione utilizzato. Molti modelli lavorano con vettori di 768 o 1024 dimensioni. La funzione di distanza coseno è uno dei metodi più comuni per calcolare le somiglianze tra i testi. Il nostro database è ora pronto per l'uso.
Struttura dei dati del piano
Prima di importare i dati, è opportuno dare una rapida occhiata alla struttura che vogliamo salvare. Ogni voce del nostro database vettoriale sarà costituita da diversi componenti:
- ID - un identificatore unico
- Incorporazione - il vettore del testo
- Carico utile - Informazioni aggiuntive sul testo
Il carico utile può contenere, ad esempio
- il testo originale
- il titolo della conversazione
- la data
- altri metadati
Un esempio di record di dati potrebbe essere il seguente:
{
"id": 1,
"vector": [0.123, -0.452, 0.889, ...],
"payload": {
"text": "Wie kann ich meinen ChatGPT-Datenexport analysieren?",
"title": "Datenanalyse"
}
}
Questa struttura presenta un grande vantaggio. I vettori sono utilizzati per la ricerca semantica, mentre il payload contiene tutte le informazioni che vogliamo visualizzare o analizzare in seguito. Ciò significa che il nostro sistema rimane flessibile e può essere facilmente ampliato in seguito.
Ciò significa che la parte più importante dell'infrastruttura è già pronta. Il nostro server Qdrant è in funzione, il database è configurato e sappiamo quale struttura avranno i nostri dati. Nel prossimo capitolo, inizieremo con il passo cruciale: importare i dati di ChatGPT nel database e trasformare il nostro archivio di conversazioni in una base di conoscenza reale e ricercabile.
Importare i dati di ChatGPT in Qdrant
Dopo aver creato Qdrant installiert e una collezione nel capitolo precedente, è stata creata la base tecnica per il nostro database della conoscenza. I nostri embeddings esistono già - li abbiamo creati dai dati di ChatGPT - e Qdrant è in esecuzione come server di database sulla nostra macchina.
Ora arriva la fase cruciale: carichiamo i nostri dati nel database. Non salviamo solo i vettori stessi, ma anche i testi e i metadati associati. Questa combinazione permette alla nostra IA di trovare in seguito i contenuti rilevanti e di utilizzarli nelle risposte. In questo capitolo costruiamo la base di conoscenza del nostro sistema.
Salvare le incorporazioni
In primo luogo, dobbiamo trasferire le nostre incorporazioni generate nel database. Ogni voce di Qdrant è composta da tre componenti:
- un ID
- un vettore (incorporazione)
- un carico utile con dati aggiuntivi
Nel nostro caso, ad esempio, il payload contiene
- la sezione testo
- il titolo della conversazione
- Eventualmente ulteriori metadati
In Python, possiamo preparare questa struttura in modo relativamente semplice. Un esempio:
points = []
for idx, item in enumerate(embeddings):
points.append({
"id": idx,
"vector": item["embedding"],
"payload": {
"text": item["text"],
"title": item["title"]
}
})Questo genera un elenco di punti dati che possiamo salvare in Qdrant. Ogni punto dati contiene quindi una sezione di testo, il vettore corrispondente e informazioni aggiuntive sul contesto. Questa struttura costituirà in seguito la base della nostra ricerca semantica.
Creare uno script di importazione
Ora colleghiamo il nostro script Python a Qdrant e trasferiamo i dati. Per farlo, utilizziamo il client Qdrant Python, che abbiamo analizzato nel precedente capitolo 1TP12. L'importazione può assomigliare a questa, ad esempio:
from qdrant_client import QdrantClient
from qdrant_client.models import PointStruct
client = QdrantClient("localhost", port=6333)
points = []
for idx, item in enumerate(embeddings):
point = PointStruct(
id=idx,
vector=item["embedding"],
payload={
"text": item["text"],
"title": item["title"]
}
)
points.append(point)
client.upsert(
collection_name="chatgpt_archive",
points=points
)
print("Import abgeschlossen:", len(points), "Datensätze gespeichert.")Il comando upsert assicura il salvataggio dei dati nella raccolta. Se un ID esiste già, la voce viene aggiornata. Altrimenti, viene creato un nuovo record di dati. A seconda delle dimensioni dell'esportazione di ChatGPT, questa importazione può richiedere alcuni secondi o minuti. Questo è del tutto normale per i set di dati più grandi, come ad esempio diverse migliaia di sezioni di testo.
Database di prova
Una volta completata l'importazione, occorre verificare che i dati siano stati salvati correttamente. Il test più semplice consiste nell'eseguire una ricerca vettoriale. Per farlo, si crea innanzitutto un embedding per una domanda di prova.
query = "Wie kann ich ChatGPT-Daten analysieren?" query_vector = ollama.embeddings( model="nomic-embed-text", prompt=query )["embedding"]
Ora possiamo cercare in Qdrant vettori simili.
search_result = client.search( collection_name="chatgpt_archive", query_vector=query_vector, limit=3 )
Questo comando restituisce le tre sezioni di testo più simili del nostro database. Ad esempio, si può ottenere un risultato come questo:
for result in search_result:
print(result.payload["text"])
print("---")Se tutto ha funzionato, ora appariranno le sezioni di chat del vostro archivio che corrispondono alla query di ricerca. Ora lo sappiamo: Il nostro database funziona.
Prima valutazione delle prestazioni
Questo momento è uno degli aspetti più emozionanti dell'intero progetto. Per la prima volta, diventa evidente che il nostro archivio di chat può essere utilizzato come fonte di conoscenza. È ora possibile provare diverse query di ricerca. Ad esempio:
- „Articolo di AI“
- „Sistema RAG“
- „Esportazione dati ChatGPT“
- „Idea di strategia“
A seconda del contenuto della cronologia delle chat, Qdrant troverà i passaggi di testo adatti. A volte sarete sorpresi dal contenuto che riemerge. Conversazioni dimenticate da tempo possono improvvisamente diventare di nuovo rilevanti. Questo dimostra chiaramente perché questo approccio è così interessante. Le vostre vecchie conversazioni AI non sono più solo un archivio. Diventano una base di conoscenza ricercabile.
Abbiamo così raggiunto un importante traguardo. I nostri dati ChatGPT sono ora completamente memorizzati nel database vettoriale e possono essere ricercati semanticamente. Nel prossimo capitolo faremo un ulteriore passo avanti: collegheremo il nostro database di conoscenze con l'IA stessa. Questo permetterà al modello linguistico di accedere a questi dati in futuro e di incorporarli direttamente nelle risposte.
Collegare l'IA con la banca dati della conoscenza
Fino a questo punto, abbiamo già costruito gran parte dell'infrastruttura. I nostri dati ChatGPT sono stati estratti dall'esportazione, suddivisi in sezioni di testo più piccole, incorporati e infine archiviati nel database vettoriale Qdrant.
Tuttavia, la nostra IA non lavora ancora con questi dati. Anche se possiamo eseguire una ricerca vettoriale con Python e trovare passaggi di testo adatti, l'IA stessa non ne è ancora consapevole. Quando le poniamo una domanda, utilizza ancora solo le sue conoscenze linguistiche generali.
Il passo successivo è quindi quello di collegare questi due mondi. Stiamo costruendo un processo in cui l'IA riceve prima i contenuti rilevanti dal database della conoscenza e poi li incorpora nella sua risposta. È proprio questo il cuore di un sistema RAG.
Procedura di richiesta
Il processo di una richiesta di informazioni cambia leggermente grazie al nostro sistema di conoscenza. Finora, una conversazione con un'intelligenza artificiale si svolgeva generalmente in questo modo:
- Fai una domanda →
- L'intelligenza artificiale elabora la domanda →
- l'IA genera una risposta.
Un database di conoscenze è un passo ulteriore. Il nuovo processo si presenta come segue:
- Fai una domanda →
- la domanda viene convertita in un incorporamento →
- il database vettoriale cerca testi simili →
- Questi testi vengono trasferiti all'IA come contesto →
l'IA formula una risposta. Ciò significa che l'IA non lavora più solo con le sue conoscenze addestrate, ma anche con i dati dell'utente. Questo contesto rende spesso le risposte molto più precise e personalizzate.
Fase di recupero
La prima parte di questo processo è nota come retrieval. Recupero significa semplicemente „recuperare“. In questa fase, il nostro sistema cerca nel database i contenuti che corrispondono all'argomento della domanda. Per prima cosa, creiamo un altro incorporamento per la domanda corrente.
query = "Welche Ideen hatte ich zur Nutzung meines ChatGPT-Datenexports?" query_vector = ollama.embeddings( model="nomic-embed-text", prompt=query )["embedding"]
Questo incorporamento descrive il significato della domanda in forma matematica. Qdrant può ora cercare vettori simili.
results = client.search( collection_name="chatgpt_archive", query_vector=query_vector, limit=5 )
Il database restituisce ora i cinque brani di testo che meglio corrispondono alla domanda. Questi passaggi di testo costituiscono il contesto dell'IA. Li raccogliamo in un elenco.
context_texts = [] for r in results: context_texts.append(r.payload["text"])
Ora abbiamo una raccolta di contenuti rilevanti dal nostro archivio di chat.
Trasferimento del contesto all'Ollama
Ora arriva il passo decisivo. Passiamo questo contesto, insieme alla domanda originale, al nostro modello linguistico. Il modello può ora utilizzare queste informazioni per formulare una risposta.
Per prima cosa, costruiamo un cosiddetto prompt. Un prompt è semplicemente il testo che inviamo all'intelligenza artificiale.
context = "\n\n".join(context_texts)
prompt = f"""
Du bist ein KI-Assistent, der mit meinem persönlichen Wissensarchiv arbeitet.
Nutze die folgenden Textausschnitte als Kontext:
{context}
Beantworte nun diese Frage:
{query}
"""Ora inviamo questa richiesta al nostro modello linguistico in Ollama.
response = ollama.chat(
model="llama3",
messages=[
{"role": "user", "content": prompt}
]
)
print(response["message"]["content"])L'intelligenza artificiale riceve ora sia la domanda che i passaggi di testo rilevanti dal nostro database. Questo le consente di generare risposte basate sui nostri dati.
Generazione di risposte
L'ultima fase è la generazione della risposta vera e propria. Il modello linguistico combina ora due fonti di conoscenza:
la propria conoscenza specializzata
il contesto dal nostro database di conoscenze
Questa combinazione è particolarmente potente. Il modello può spiegare relazioni generali e allo stesso tempo incorporare contenuti specifici dal nostro archivio. Un esempio: Se si chiede:
„Quali idee ho avuto per utilizzare l'esportazione dei dati di ChatGPT?“.“
l'intelligenza artificiale può ora accedere alle conversazioni precedenti e creare un riassunto strutturato a partire da esse. Ad esempio, può rispondere:
- Lei ha parlato di costruire un archivio di conoscenze personali
- Si voleva sviluppare un'intelligenza artificiale locale con un sistema RAG
- Avete sviluppato l'idea di una serie di articoli
Senza la fase di recupero, l'IA non avrebbe conosciuto queste informazioni. Con il nostro sistema, l'archivio delle chat diventa una vera e propria fonte di conoscenza. Questo completa la parte più importante del nostro sistema. Ora abbiamo:
- un'intelligenza artificiale locale tramite Ollama
- un database vettoriale con i dati delle nostre chat
- una ricerca semantica
- un flusso di lavoro RAG
Nel prossimo capitolo testeremo questo sistema nella pratica e vedremo quanto funziona effettivamente la nostra IA della conoscenza personale.
Prima interrogazioni con la vostra conoscenza personale AI
Ora che abbiamo stabilito la connessione tra la nostra IA e il database della conoscenza nel capitolo precedente, il sistema è tecnicamente completo. I nostri dati ChatGPT sono nel database vettoriale, l'IA può recuperare i contenuti rilevanti e l'intero processo di un sistema RAG funziona.
Ora arriva la parte più emozionante del progetto: le prime vere interrogazioni. Solo ora, infatti, possiamo verificare se il nostro sistema fa effettivamente ciò che ci auguriamo: trovare conversazioni precedenti, analizzare i contenuti e generare risposte significative. In questo capitolo testiamo la nostra Knowledge AI, esaminiamo casi d'uso tipici e diamo un'occhiata alle possibili ottimizzazioni.
Esempi di query
Cominciamo con alcune semplici domande. Una buona strategia è quella di iniziare a porre le domande che sapete essere presenti nel vostro archivio di chat. Ad esempio:
„Quali idee ho avuto per utilizzare l'esportazione dei dati di ChatGPT?“.“
„Cosa ho scritto sui sistemi RAG?“.“
„Quali strategie ho discusso per utilizzare l'IA?“.“
Queste domande contengono volutamente formulazioni aperte. L'obiettivo non è trovare un testo specifico, ma scoprire un contenuto tematicamente appropriato. Quando si pone una domanda di questo tipo al sistema, il processo che abbiamo impostato nel capitolo precedente avviene in background:
- La domanda viene convertita in un incorporamento.
- Il database vettoriale cerca sezioni di testo simili.
- Questi passaggi di testo vengono trasferiti all'IA come contesto.
- L'IA genera una risposta basata su questo contesto.
Il risultato può essere sorprendente. Spesso saltano fuori conversazioni dimenticate da tempo. Vecchie idee riappaiono improvvisamente sullo schermo, a volte anche in un contesto completamente nuovo.
È proprio questo il punto di forza di questo approccio. Il vostro archivio di chat diventa una fonte di conoscenza ricercabile.
Qualità delle risposte
Se provate a fare qualche domanda, vi accorgerete che la qualità delle risposte può variare. Questo è del tutto normale. La qualità di un sistema di questo tipo dipende da diversi fattori. Un fattore importante è la dimensione delle sezioni di testo. Se le sezioni sono troppo grandi, possono contenere diversi argomenti. Ciò rende la ricerca meno accurata.
Tuttavia, se i pezzi sono troppo piccoli, a volte manca il contesto necessario. Un altro fattore è il modello di incorporazione. I diversi modelli riconoscono i contesti di significato in modo diverso. Alcuni sono particolarmente adatti per i testi tecnici, altri per il linguaggio generale.
Anche il numero di risultati recuperati gioca un ruolo importante. Ad esempio, se si recuperano solo due passaggi di testo, potrebbero mancare informazioni importanti. Se invece vengono caricati troppi testi, l'intelligenza artificiale potrebbe avere difficoltà a riconoscere il contesto rilevante.
Questi parametri possono essere facilmente regolati in seguito. La cosa più importante è avere un sistema di base funzionante.
Problemi tipici
Come per ogni sistema tecnico, anche in questo caso possono verificarsi alcune difficoltà. Un problema comune è che il database trova testi solo parzialmente rilevanti. Questo perché la ricerca semantica lavora sempre con le probabilità.
Un altro problema può sorgere se i testi sono stati frammentati troppo. Se un pensiero è suddiviso in più parti, l'intelligenza artificiale può avere difficoltà a riconoscere il contesto.
Anche la richiesta gioca un ruolo importante. Se la richiesta è poco chiara, l'intelligenza artificiale potrebbe non sfruttare al meglio il contesto. Un esempio di prompt migliore potrebbe essere il seguente:
Utilizzate i seguenti estratti di testo dal mio archivio di conoscenze,
rispondere alla domanda nel modo più preciso possibile.
Se sono disponibili contenuti rilevanti, riassumerli.
Questi piccoli aggiustamenti possono migliorare significativamente la qualità delle risposte.
Sintonizzazione fine
Non appena il sistema è sostanzialmente funzionante, inizia la parte più interessante: la messa a punto. Qui è possibile sperimentare e migliorare il sistema di conoscenza passo dopo passo. Alcune ottimizzazioni tipiche sono
- Regolazione della dimensione dei pezzi
A volte sezioni di testo più piccole forniscono risultati migliori. In altri casi, è utile un contesto più ampio. - Utilizzo di un modello di incorporazione diverso
La modifica del modello può migliorare significativamente la qualità della ricerca semantica. - Più contesto per l'IA
È possibile recuperare più risultati dal database, ad esempio dieci passaggi di testo invece di cinque. - Utilizzare i metadati
Se si salvano informazioni aggiuntive, come la data o il titolo della chiamata, è possibile filtrare la ricerca in modo più preciso in un secondo momento.
Queste regolazioni fanno parte di ogni vero sistema RAG. Raramente esiste un'impostazione perfetta per tutte le situazioni. Ma è proprio questo il fascino di tali sistemi: possono essere continuamente migliorati.
Con questo capitolo abbiamo condotto il primo test completo del nostro sistema. Abbiamo visto che la nostra IA della conoscenza personale è effettivamente in grado di cercare tra le vecchie conversazioni e di recuperare i contenuti rilevanti.
Ciò significa che il nucleo del nostro progetto è già stato realizzato. Ma il sistema può ancora essere ampliato in modo considerevole. Nel prossimo capitolo vedremo quindi come integrare altre fonti di dati e come ampliare passo dopo passo il vostro archivio di conoscenze personali.


Estensioni per il vostro sistema di conoscenza AI personale
Avete già creato un sistema funzionante con la configurazione precedente. I dati di ChatGPT sono stati estratti, convertiti in embeddings, archiviati in Qdrant e infine collegati a un'intelligenza artificiale locale. Il risultato è un'intelligenza artificiale in grado di accedere alle conversazioni precedenti.
Ma, a rigore, siamo solo all'inizio. L'architettura che avete costruito non è limitata ai dati ChatGPT. Funziona con qualsiasi tipo di testo. Tutto ciò che può essere convertito in documenti o file di testo può entrare a far parte di questo sistema di conoscenza. È qui che risiede il vero potenziale di questi sistemi.
In pratica, abbiamo costruito una macchina della conoscenza personale. E questa macchina può essere ampliata passo dopo passo. In questo capitolo analizziamo le possibilità che ne derivano e come è possibile espandere il sistema a lungo termine.
Integrare altre fonti di dati
Il passo successivo più ovvio è aggiungere altri contenuti alla vostra base di conoscenze. Le conversazioni di ChatGPT sono un buon inizio, ma di solito rappresentano solo una parte delle vostre conoscenze. Molte informazioni sono disponibili in altri formati. Ad esempio:
- articoli propri
- Note
- Documenti in PDF
- Documenti di ricerca
- Libri elettronici
- Protocolli o elenchi di idee
Tutti questi contenuti possono essere elaborati allo stesso modo dei nostri dati di chat. Il processo rimane identico:
- Estrarre il testo
- Dividere il testo in parti
- Creare le incorporazioni
- Salvataggio dei dati in Qdrant
Un esempio: Se avete scritto molti dei vostri articoli, potete importare questi testi nel vostro database di conoscenze. L'intelligenza artificiale può accedervi in seguito e riconoscere le correlazioni. Ad esempio, si può chiedere:
„Quali articoli ho scritto sull'IA?“.“
o
„Quali argomenti ho sviluppato in passato su questo tema?“.“
L'intelligenza artificiale cerca quindi nel vostro archivio di articoli e utilizza i contenuti che trova come contesto. In questo modo, il sistema cresce passo dopo passo fino a diventare un archivio di conoscenze completo.
Diverse banche dati di conoscenza
Quando la quantità di dati aumenta, può essere utile separare aree diverse. Qdrant consente di creare più raccolte. Ogni raccolta può rappresentare la propria base di conoscenza. Un possibile sistema potrebbe essere così, ad esempio:
- Collezione 1Conversazioni ChatGPT
- Collezione 2: Archivio articoli
- Collezione 3: note personali
- Collezione 4Documentazione tecnica
Questa separazione presenta diversi vantaggi. In primo luogo, la struttura rimane chiara. Si sa sempre dove sono memorizzati determinati contenuti. In secondo luogo, le query possono essere controllate in modo più specifico. Alcune domande dovrebbero cercare solo nell'archivio degli articoli, altre nell'intero sistema di conoscenza. Un esempio:
- Una domanda di ricerca potrebbe essere effettuata solo nell'archivio degli articoli.
- Una domanda strategica, invece, potrebbe prendere in considerazione tutte le collezioni contemporaneamente.
Tali strutture rendono i sistemi di conoscenza di grandi dimensioni molto più efficienti.
Aggiornamenti automatici
Un altro passo utile è quello di aggiornare regolarmente il sistema. Nell'esempio precedente, abbiamo elaborato l'esportazione dei dati di ChatGPT una volta. In pratica, però, vengono creati continuamente nuovi contenuti.
Nuove conversazioni, nuove note, nuovi documenti: tutte queste informazioni potrebbero entrare a far parte del vostro archivio di conoscenze.
È quindi opportuno pensare ad aggiornamenti automatici. Una soluzione semplice consiste nell'importare regolarmente nuovi dati. Ad esempio:
- Elaborare i dati delle nuove chat una volta alla settimana
- Importazione automatica di nuovi documenti
- Aggiungere immediatamente nuovi articoli al database
Tecnicamente è relativamente facile da implementare. Un piccolo script può controllare regolarmente se sono disponibili nuovi file ed elaborarli automaticamente. In questo modo, il vostro sistema di conoscenze può crescere continuamente. Nel corso del tempo, si crea un archivio sempre più ampio che documenta i vostri pensieri e progetti.
Integrazione nelle proprie applicazioni
Finora il nostro sistema è stato utilizzato tramite semplici script Python. Ma a lungo termine, questo sistema può essere integrato anche nelle vostre applicazioni. Ad esempio, molti sviluppatori stanno realizzando piccole interfacce web che consentono di utilizzare direttamente l'intelligenza artificiale.
Invece di avviare uno script, è possibile scrivere semplicemente una domanda in un campo di input. Lo stesso processo viene eseguito in background:
- Creare l'incorporazione
- Ricerca nel database
- Trasferire il contesto all'IA
- Generare la risposta
Il risultato appare direttamente nell'interfaccia utente. Un'applicazione di questo tipo può assumere forme molto diverse. Ad esempio:
- un'intelligenza artificiale di ricerca personale
- un assistente alla conoscenza per i progetti
- un motore di ricerca di idee
- un archivio di articoli e note
La situazione diventa particolarmente interessante quando si combinano questi sistemi con altri strumenti. Ad esempio, un sistema editoriale potrebbe accedere automaticamente all'archivio delle conoscenze e utilizzare gli articoli precedenti come base per la ricerca. Oppure un sistema di note potrebbe integrare automaticamente nuove idee nel vostro database.
In altre parole, l'IA diventa parte del vostro ambiente di lavoro quotidiano. Questo fa capire che il nostro piccolo progetto va ben oltre l'esportazione dei dati originali di ChatGPT.
Non abbiamo creato solo un archivio. Abbiamo creato un'architettura che può essere ampliata in base alle esigenze. Ed è proprio qui che risiede il vero valore di questi sistemi. Non sono statici. Crescono con le vostre conoscenze.
Versione estesa della pipeline da scaricare
Il seguente script è una versione estesa della pipeline dell'articolo. È più robusto e molto più vicino a una soluzione produttiva. Sono stati migliorati tre aspetti:
- Indicatore di progressoL'utente può vedere in qualsiasi momento quanti testi sono già stati elaborati.
- Importazione in batchLe incorporazioni vengono raccolte e scritte su Qdrant in blocchi, il che è significativamente più veloce delle singole importazioni.
- Pipeline di incorporazione più veloceLo script funziona in modo strutturato con pezzi preparati e riduce le chiamate non necessarie.
Questo script è quindi particolarmente adatto se l'esportazione di ChatGPT è di grandi dimensioni, ad esempio diverse migliaia di conversazioni. Processo tipico:
- Caricare l'esportazione di ChatGPT
- Testi estratti
- Dividere il testo in parti
- Creare le incorporazioni
- Importazione in batch in Qdrant
- Eseguire l'interrogazione di prova
Impostazioni importanti nello script
Alcuni valori devono essere regolati dall'utente:
- ESPORTAZIONE_PFAD
Percorso dei file conversations.json, per lo più numerati, dell'esportazione di ChatGPT. - NOME_RACCOLTA
Nome della collezione di database vettoriale. - MODELLO EMBED
Modello di incorporazione di Ollama, ad esempio nomic-embed-text o mxbai-embed-large - RISPOSTA_MODELLO
Modello linguistico per la query di prova, ad esempio llama, mistral o gpt:oss - DIMENSIONE_VETTORE
Dimensione del modello di incorporazione.
nomic-embed-text → 768
mxbai-embed-large → 1024 - DIMENSIONE CHUNK
Dimensione delle sezioni di testo.
In genere 300-600 parole. - DIMENSIONE DEL LOTTO
Quante incorporazioni vengono scritte contemporaneamente su Qdrant.
Valore tipico: 50-200.
Rimanere aggiornati - senza pubblicità
Se desiderate essere informati sugli aggiornamenti di questo script o sui nuovi download, potete iscrivervi alla mia newsletter mensile. La newsletter è volutamente snella, completamente priva di pubblicità e appare solo una volta al mese. In essa troverete una selezione dei nuovi articoli più importanti, contenuti pratici su IA, software e digitalizzazione, nonché informazioni su script aggiornati o nuove offerte di download. Niente spam, niente e-mail quotidiane: solo i contenuti più rilevanti in forma compatta. Se volete seguire costantemente questi sviluppi, la newsletter è il modo più semplice per rimanere aggiornati.
Prospettive per la Parte 3: perfezionamento, analisi e ottimizzazione dell'uso dei dati
Nella terza parte della serie, facciamo un ulteriore passo avanti e diamo un'occhiata a ciò che si può effettivamente ottenere dal database di conoscenze creato. Ora che i dati di ChatGPT sono stati archiviati in Qdrant, l'attenzione si concentra sul loro utilizzo effettivo. Diamo un'occhiata all'interfaccia web di Qdrant, analizziamo i dati memorizzati e verifichiamo il funzionamento della ricerca semantica. Inoltre, ci occupiamo di importanti regolazioni fini: Come selezionare il chunking a seconda del caso d'uso? Come trasferire in modo ottimale il contesto a un modello linguistico locale? E come si può migliorare in modo specifico la qualità delle risposte? La terza parte si rivolge a tutti coloro che vogliono ottenere di più dal sistema e svilupparlo in modo consapevole.




Domande frequenti
- A cosa serve integrare l'esportazione dei dati di ChatGPT nella mia AI?
Il vantaggio maggiore è che si possono utilizzare le proprie conversazioni e i propri pensieri a lungo termine. Molte persone hanno conversazioni intense con i sistemi di intelligenza artificiale su progetti, idee, analisi o questioni personali. Questi contenuti normalmente scompaiono nel corso della piattaforma. Tuttavia, se lo si esporta e lo si integra nel proprio database di conoscenze, diventa un archivio personale. L'intelligenza artificiale locale può quindi accedere a questi contenuti, riconoscere le correlazioni e aiutarvi con nuove domande. Invece di partire sempre da zero, si costruisce il proprio pensiero passo dopo passo. - Non è molto complicato per chi non è uno sviluppatore?
A prima vista, termini come embedding, database vettoriali o sistemi RAG appaiono complessi. In pratica, tuttavia, le singole fasi sono strutturate in modo relativamente chiaro. Sono necessari fondamentalmente solo tre componenti: un'IA locale (ad esempio tramite Ollama), un database vettoriale come Qdrant e un piccolo script Python che elabora i dati. Molti dei passaggi vengono eseguiti automaticamente. Una volta configurato, il sistema funziona come un normale motore di ricerca o un chatbot, con la differenza che lavora con le vostre conoscenze. - Quali dati contiene effettivamente l'esportazione di ChatGPT?
L'esportazione di ChatGPT contiene di solito tutte le conversazioni che avete avuto con il sistema. Questo include non solo i messaggi di testo stessi, ma anche metadati come i titoli delle conversazioni, i timestamp e le informazioni strutturali. I dati sono solitamente disponibili in formato JSON e possono quindi essere elaborati con relativa facilità tramite script. In molti casi, l'esportazione include anche file multimediali o linguistici, se sono stati utilizzati nelle conversazioni. Tuttavia, è soprattutto il contenuto testuale che interessa quando si crea un database della conoscenza. - Perché per questi sistemi si usa un database vettoriale e non un normale database?
I database normali sono ideali per la ricerca di termini o ID specifici. Tuttavia, sono meno adatti per le ricerche semantiche. Un database vettoriale memorizza i testi non solo come stringhe di caratteri, ma anche come vettori matematici che descrivono il significato di un testo. Questo permette al sistema di cercare la somiglianza tra i contenuti. Ad esempio, se si chiede „idee per articoli sull'intelligenza artificiale“, il database può trovare anche contenuti che contengono altre frasi come „argomenti per articoli di blog sull'intelligenza artificiale“. - Cosa sono gli embeddings e perché sono così importanti?
Le incorporazioni sono rappresentazioni matematiche dei testi. Un modello linguistico converte un testo in un elenco di numeri che descrivono il significato del testo. I testi con significati simili sono vicini nello spazio matematico. Questo permette a un database vettoriale di cercare successivamente contenuti simili. Senza embeddings, la ricerca semantica non sarebbe possibile. Essi costituiscono la base dei moderni sistemi RAG e sono il motivo per cui tali sistemi sono molto più flessibili delle classiche ricerche full-text. - Quanto può essere grande l'esportazione dei dati di ChatGPT?
Le dimensioni non giocano un ruolo importante. Anche diverse migliaia di conversazioni possono essere elaborate senza problemi. Ciò che è più importante è il numero di sezioni di testo generate, i cosiddetti chunks. Un'esportazione più grande comporta un maggior numero di chunk e quindi di incorporazioni. Tuttavia, i moderni database vettoriali possono facilmente gestire milioni di voci di questo tipo. Anche un piccolo server o un potente desktop sono del tutto sufficienti per un assistente privato alla conoscenza. - Perché il testo è diviso in piccole sezioni prima dell'elaborazione?
Se si salvano conversazioni complete o testi di grandi dimensioni direttamente come embeddings, la ricerca semantica diventa imprecisa. Un singolo testo potrebbe contenere diversi argomenti. Suddividendolo in sezioni più piccole, il sistema può effettuare una ricerca più precisa. Ogni sezione descrive un argomento più chiaro. Di conseguenza, il database trova esattamente le parti di una conversazione che si adattano realmente alla domanda corrente. - Che ruolo svolge l'Ollama in questo sistema?
Ollama funge da piattaforma locale per i modelli linguistici. Permette di eseguire modelli di intelligenza artificiale direttamente sul proprio computer. Nel nostro sistema, Ollama svolge due compiti: Crea embeddings per i testi e genera risposte alle domande. Il vantaggio è che tutti i dati rimangono locali. Ciò significa che le vostre conversazioni e il vostro archivio di conoscenze non lasciano mai il vostro computer. - Perché Qdrant viene utilizzato come database vettoriale?
Qdrant è un moderno database vettoriale sviluppato appositamente per le applicazioni di intelligenza artificiale. È veloce, facile da implementare e molto ben documentato. Inoltre, può essere facilmente collegato a Python e a molti framework di IA. Qdrant è quindi una soluzione particolarmente pratica per i sistemi di conoscenza locale. Le alternative sono Chroma, Weaviate o Pinecone. - Cosa significa il termine sistema RAG?
RAG è l'acronimo di „Retrieval-Augmented Generation“. Si tratta di un'architettura in cui un'IA recupera prima le informazioni rilevanti da un database e poi le utilizza per generare una risposta. L'IA combina quindi le proprie conoscenze con dati esterni. In questo modo può fornire risposte molto precise e allo stesso tempo accedere a informazioni attuali o personali. - Posso integrare in questo sistema anche altre fonti di dati?
In effetti, questo è uno dei maggiori vantaggi di questa architettura. Il sistema non si limita ai dati di ChatGPT. È anche possibile integrare i propri articoli, note, PDF, documenti di ricerca o altri documenti. Finché il contenuto può essere elaborato in forma di testo, può diventare parte della base di conoscenza. Con il tempo, il sistema diventerà un archivio di conoscenze completo. - Quanto rimane aggiornato un tale sistema di conoscenze?
L'aggiornamento dipende dalla frequenza con cui si importano nuovi dati. Ad esempio, è possibile elaborare regolarmente nuove esportazioni di ChatGPT o creare uno script che riconosca automaticamente i nuovi documenti. Molti sistemi sono impostati per essere aggiornati una volta alla settimana o al mese. In questo modo la base di conoscenze è sempre aggiornata. - Di quale hardware ho bisogno per un sistema di questo tipo?
Un moderno computer desktop è sufficiente per i progetti più piccoli. Se si desidera utilizzare un modello linguistico più ampio, può essere utile una GPU. Tuttavia, molti utenti eseguono con successo i loro sistemi di conoscenza anche su un potente computer portatile o un mini-server. Soprattutto, è importante disporre di una memoria sufficiente e di uno spazio di archiviazione sufficiente per il database. - Quanto velocemente funziona un sistema del genere nella pratica?
La velocità dipende da diversi fattori, come ad esempio le dimensioni del database, l'hardware e il modello di linguaggio utilizzato. In molti casi, un'interrogazione richiede solo pochi secondi. La ricerca vettoriale in sé è di solito estremamente veloce. La maggior parte del tempo viene spesso impiegata per generare la risposta dal modello linguistico. - È possibile separare diverse aree di conoscenza?
Sì, i database vettoriali come Qdrant consentono di utilizzare più collezioni. Ogni raccolta può rappresentare un'area tematica separata. Ad esempio, si può creare una raccolta per le conversazioni ChatGPT, una per gli articoli e una per le note. In questo modo le aree di conoscenza possono essere strutturate in modo chiaro e ricercate in modo mirato. - Quanto sono sicuri i miei dati in un sistema di AI locale?
Il grande vantaggio di un sistema locale è che i dati non devono essere trasferiti a servizi esterni. Tutte le informazioni rimangono sul proprio computer o server. Questo è particolarmente interessante per i contenuti sensibili. Naturalmente, è necessario creare backup regolari e proteggere il sistema da accessi non autorizzati. - Posso anche integrare questo sistema nelle mie applicazioni?
Sì, la maggior parte dei componenti è accessibile tramite interfacce di programmazione. Ciò consente di integrare il sistema di conoscenze nei propri strumenti, ad esempio in un'interfaccia web, in un sistema editoriale o in un'applicazione per le note. Molti sviluppatori realizzano piccole applicazioni che rendono il database delle conoscenze direttamente accessibile tramite un'interfaccia di chat. - Come potrebbe svilupparsi questa tecnologia in futuro?
Le IA per la conoscenza personale sono probabilmente solo all'inizio del loro sviluppo. In futuro, tali sistemi potrebbero integrare automaticamente nuovi contenuti, creare sintesi o persino fornire suggerimenti per i progetti. Più dati confluiscono in un sistema di questo tipo, più questo diventa prezioso. A lungo termine, potrebbe diventare una sorta di memoria digitale personale che struttura le vostre conoscenze e le rende accessibili in qualsiasi momento.


