
W pierwszej części tej serii artykułów zobaczyliśmy, że eksport danych ChatGPT to znacznie więcej niż tylko funkcja techniczna. Eksportowane dane zawierają zbiór myśli, pomysłów, analiz i rozmów, które gromadziły się przez długi czas. Ale dopóki dane te są przechowywane tylko jako archiwum na dysku twardym, pozostają tylko tym: archiwum. Kluczowym krokiem jest ponowne wykorzystanie tych informacji. To właśnie tutaj zaczyna się rozwój osobistej sztucznej inteligencji.
Pomysł jest w rzeczywistości zaskakująco prosty: sztuczna inteligencja powinna nie tylko pracować z wiedzą ogólną, ale także mieć dostęp do własnych danych. Powinna przeszukiwać poprzednie rozmowy, znajdować odpowiednie treści i włączać je do nowych odpowiedzi. W ten sposób zwykła sztuczna inteligencja staje się rodzajem cyfrowej pamięci. Jest to druga część serii artykułów, w której przyjrzymy się teraz praktycznej stronie rzeczy.




Część 1 serii: Niedoceniany skarb w eksporcie danych ChatGPT
Podczas gdy w drugiej części zajmiemy się praktyczną stroną rzeczy, warto spojrzeć na Pierwszy artykuł z tej serii. Zajmuje się fundamentalnym pytaniem, dlaczego eksport danych ChatGPT jest tak interesujący - i dlaczego wielu użytkowników wciąż nie docenia jego potencjału. Artykuł pokazuje, jakie dane są faktycznie zawarte w eksporcie, w jaki sposób można je wykorzystać do stworzenia osobistego archiwum wiedzy i dlaczego ten krok stanowi podstawę własnej sztucznej inteligencji z pamięcią. Jeśli chcesz zrozumieć, dlaczego w ogóle budujemy ten potok i jaką wartość strategiczną mają twoje własne historie czatów, powinieneś zacząć od części 1.
Zanim rozpoczniemy faktyczną implementację w następnym rozdziale, przyjrzyjmy się najpierw, jak taki system jest zasadniczo zbudowany.
Podstawowa idea systemu RAG
Podstawą techniczną naszego systemu jest koncepcja, która jest obecnie szeroko stosowana w świecie sztucznej inteligencji: RAG, czyli Retrieval Augmented Generation. Za tym terminem kryje się bardzo praktyczna zasada.
Zwykle model językowy odpowiada na pytania wyłącznie na podstawie wiedzy zdobytej podczas szkolenia. Chociaż wiedza ta jest rozległa, ma ona dwa decydujące ograniczenia:
- Po pierwsze, model nie zna żadnych indywidualnych informacji na temat projektów lub myśli użytkownika.
- Po drugie, nie może uzyskać dostępu do nowych danych utworzonych po treningu.
Dokładnie w tym miejscu pojawia się system RAG. Zamiast bezpośrednio generować odpowiedź, najpierw dzieje się coś innego: system przeszukuje bazę danych w poszukiwaniu treści pasujących do zadanego pytania. Treść ta jest następnie przekazywana do modelu językowego jako kontekst. Dopiero wtedy sztuczna inteligencja formułuje odpowiedź. W uproszczeniu proces ten wygląda następująco:
- Zadajesz pytanie →
- system przeszukuje bazę wiedzy →
- znaleziono odpowiednią zawartość →
- Zawartość ta jest przekazywana do sztucznej inteligencji jako kontekst →
- SI generuje odpowiedź.
Decydująca zaleta jest oczywista: sztuczna inteligencja może wykorzystywać informacje, które nie były częścią jej pierwotnego szkolenia.
I tu właśnie do gry wkraczają dane z ChatGPT. Jeśli zintegrujemy te rozmowy z bazą wiedzy, sztuczna inteligencja będzie mogła uzyskać do nich dostęp później. Może znaleźć poprzednie pomysły, użyć argumentów ze starych dialogów lub wziąć pod uwagę analizy z poprzednich rozmów. W ten sposób system zaczyna „zapamiętywać“ myśli użytkownika.
Elementy składowe naszego systemu
Aby to zadziałało, potrzebujemy kilku współpracujących ze sobą komponentów. Na szczęście infrastruktura techniczna jest dziś znacznie łatwiej dostępna niż kilka lat temu. Nasz system składa się z czterech głównych komponentów.
- Pierwszym elementem składowym jest Eksport danych ChatGPT. To tutaj znajdują się nasze surowe dane. Zawierają one wszystkie rozmowy, które wcześniej przeprowadziliśmy ze sztuczną inteligencją.
- Drugim elementem składowym jest Model osadzania. Model ten tłumaczy tekst na wektory matematyczne. Umożliwia to porównywanie tekstów zgodnie z ich znaczeniem.
- Trzecim elementem składowym jest Wektorowa baza danych. W naszym przypadku używamy Qdrant. Ta baza danych przechowuje matematyczne reprezentacje tekstów i umożliwia szybkie wyszukiwanie semantyczne.
- Czwartym elementem składowym jest lokalny model językowy, który działa przez Ollama. Model ten będzie później formułował rzeczywiste odpowiedzi.
Te cztery elementy ściśle ze sobą współpracują.
- Eksport danych zapewnia zawartość.
- Model osadzania sprawia, że można je odczytać maszynowo.
- Baza danych wektorów zapisuje je i przeszukuje.
- Model językowy ostatecznie generuje zrozumiałe odpowiedzi.
Razem tworzą one podstawę osobistej wiedzy AI.
Przepływ danych w skrócie
Aby system działał, dane muszą przejść przez kilka etapów. Pierwszym krokiem jest eksport danych ChatGPT, który stworzyliśmy już w pierwszym artykule. Zawarte w nim konwersacje są najpierw wyodrębniane z plików JSON. Następnie teksty te muszą zostać przygotowane. Duże historie czatów są dzielone na mniejsze sekcje, znane jako fragmenty tekstu. Dzięki temu późniejsze wyszukiwanie jest znacznie wydajniejsze.
W następnym kroku generujemy osadzenia z tych fragmentów tekstu. Każdy tekst jest opisany matematycznie. Teksty o podobnym znaczeniu otrzymują podobne wektory. Następnie zapisujemy te wektory w naszej bazie danych wektorów Qdrant.
Oznacza to, że najważniejsza część infrastruktury jest już na miejscu. Gdy pytanie jest zadawane później, dzieje się co następuje:
- Pytanie jest również konwertowane na wektor.
- Baza danych wyszukuje teksty o podobnym znaczeniu.
- Te fragmenty tekstu są przenoszone do modelu językowego jako kontekst.
- Model wykorzystuje te informacje do sformułowania odpowiedzi.
Proces ten zapewnia, że sztuczna inteligencja nie tylko wykorzystuje wiedzę ogólną, ale może również uzyskać dostęp do własnych danych.
Co ostatecznie będzie możliwe
Po skonfigurowaniu systemu praca ze sztuczną inteligencją wyraźnie się zmienia. Nie pracujesz już tylko z ogólnym modelem językowym, ale ze sztuczną inteligencją, która może uzyskać dostęp do twoich własnych danych. Otwiera to zupełnie nowe możliwości. Można na przykład zadawać pytania takie jak:
„Czy kiedykolwiek rozmawiałem z SI na ten temat?“.“
„Jakie pomysły miałem wcześniej w związku z tym projektem?“.“
„Jakie argumenty rozwinąłem w poprzednich rozmowach?“.“
Następnie sztuczna inteligencja przeszukuje rozmowy użytkownika i znajduje odpowiednie treści. Zamiast udzielać tylko ogólnej odpowiedzi, może odnosić się do poprzednich myśli, podsumowywać stare analizy lub rozpoznawać powiązania między różnymi rozmowami.
Innymi słowy, sztuczna inteligencja zaczyna pracować z Twoim własnym archiwum wiedzy. Zmienia to proste narzędzie do czatowania w system, który może wspierać twoje myślenie w dłuższej perspektywie. I to właśnie ten system będziemy budować krok po kroku w kolejnych rozdziałach. W następnej sekcji zaczniemy od praktycznej pracy i najpierw przyjrzymy się bliżej eksportowi danych ChatGPT. Ponieważ zanim będziemy mogli zbudować bazę wiedzy, musimy zrozumieć, w jaki sposób nasze dane są ustrukturyzowane.
Aktualne badanie dotyczące korzystania z lokalnych systemów AI
Przygotowanie: Zrozumienie eksportu danych ChatGPT
W pierwszym artykule z tej serii utworzyliśmy już eksport danych ChatGPT i pobraliśmy go jako plik ZIP. Na pierwszy rzut oka plik ten może wydawać się mało spektakularny - archiwum z kilkoma plikami technicznymi, które początkowo wygląda bardziej jak kopia zapasowa niż cenny zestaw danych. Jednak to archiwum zawiera podstawę całego naszego systemu wiedzy.
Zanim zaczniemy ładować te dane do bazy danych lub podłączać je do sztucznej inteligencji, musimy najpierw zrozumieć strukturę eksportu. Ponieważ tylko wtedy, gdy wiemy, jakie informacje są zawarte i jak są ustrukturyzowane, możemy je później przetwarzać w znaczący sposób. W tym rozdziale przyjrzymy się zatem strukturze eksportu danych, które pliki są naprawdę istotne i jak możemy przekształcić to archiwum techniczne w użyteczną podstawę dla naszego systemu wiedzy AI.
Rozpakuj plik ZIP
Pierwszy krok jest banalny, ale niemniej ważny: musimy rozpakować pobrane archiwum. Plik jest zwykle dostępny jako klasyczny plik ZIP. W zależności od stopnia jego wcześniejszego wykorzystania, może on różnić się rozmiarem. Niektórzy użytkownicy otrzymują archiwum o rozmiarze kilkuset megabajtów, inni kilku gigabajtów.
Po rozpakowaniu pliku tworzony jest folder z kilkoma plikami i podfolderami. Dokładna struktura może się nieznacznie różnić, ale zazwyczaj znajduje się tam kilka plików JSON i ewentualnie inne pliki z dodatkowymi informacjami.
Dla wielu użytkowników struktura ta początkowo wydaje się nieco techniczna. Ale jeśli poświęcisz chwilę, szybko rozpoznasz wzór: dane są zorganizowane stosunkowo schludnie i mają jasną strukturę. To dobra wiadomość, ponieważ to właśnie ta struktura umożliwia późniejsze automatyczne przetwarzanie treści.
Struktura danych czatu
Najważniejszą częścią eksportu są rzeczywiste dane czatu. Rozmowy te są zwykle przechowywane w jednym lub kilku plikach JSON. JSON to szeroko stosowany format danych, który jest często używany do przechowywania ustrukturyzowanych informacji.
Taki plik nie zawiera po prostu długiego tekstu. Zamiast tego dialog jest podzielony na poszczególne elementy. Zazwyczaj dialog składa się z kilku wiadomości. Każda wiadomość zawiera informacje takie jak
- rzeczywisty tekst wiadomości
- rola nadawcy (użytkownik lub sztuczna inteligencja)
- znacznik czasu
- częściowo dalsze metadane
Pozwala to na odtworzenie całego przebiegu dialogu. Na przykład dialog rozpoczyna się od pytania użytkownika. Po nim następuje odpowiedź ze strony sztucznej inteligencji. Następnie mogą pojawić się kolejne pytania i odpowiedzi. Każda z tych wiadomości jest zapisywana indywidualnie.
Ma to jedną ważną zaletę: możemy później dokładnie rozpoznać, kto co powiedział i jak rozwinęła się rozmowa. Jest to szczególnie ważne dla naszego systemu wiedzy, ponieważ chcemy później wyszukiwać i analizować dokładnie te treści.
Jakich danych naprawdę potrzebujemy
Chociaż eksport zawiera wiele informacji, nie potrzebujemy ich wszystkich do naszego systemu wiedzy. Najważniejszym komponentem są teksty rozmów. Teksty te zawierają rzeczywistą treść: Pomysły, analizy, pytania i odpowiedzi. To właśnie te treści chcemy później przeszukiwać.
Przydatne mogą być również niektóre metadane. Obejmują one na przykład
- Znacznik czasu
- Tytuł rozmowy
- Możliwe wewnętrzne numery identyfikacyjne
Informacje te pomagają nam później lepiej sortować treści lub kategoryzować rozmowę pod względem czasu. Inne elementy eksportu są mniej istotne dla naszego projektu. Obejmuje to na przykład pewne metadane techniczne, które są interesujące tylko dla wewnętrznego funkcjonowania platformy.
Aby zbudować naszą bazę wiedzy, celowo koncentrujemy się na najważniejszych elementach: tekstach rozmów i podstawowych informacjach kontekstowych. Im bardziej przejrzyście ustrukturyzujemy te dane, tym lepiej nasza sztuczna inteligencja będzie mogła z nimi później pracować.
Pierwszy przegląd danych
Zanim zaczniemy pracę z automatycznymi skryptami, warto przyjrzeć się samym danym. Aby to zrobić, otwórz jeden z plików JSON za pomocą prostego edytora tekstu lub programu, który może dobrze wyświetlać pliki JSON. Wiele edytorów kodu, takich jak Visual Studio Code, jest do tego bardzo odpowiednich, ale proste edytory tekstu również działają.
Kiedy po raz pierwszy spojrzysz na plik, prawdopodobnie zobaczysz stosunkowo dużą ilość ustrukturyzowanych danych. Pliki JSON składają się z zagnieżdżonych elementów - tj. pól danych, które z kolei zawierają inne pola. Na początku może się to wydawać nieco skomplikowane, ale przy odrobinie cierpliwości szybko rozpoznasz podstawową strukturę. Na przykład można zauważyć, że konwersacja składa się z kilku wiadomości, a każda wiadomość reprezentuje oddzielny obiekt. Rzeczywisty tekst znajduje się zwykle w wyraźnie rozpoznawalnym polu.
To pierwsze badanie ma ważny cel: pomaga zrozumieć strukturę danych. Ponieważ w następnym rozdziale użyjemy właśnie tej struktury, aby automatycznie odczytać konwersacje i przygotować je dla naszego systemu wiedzy. Innymi słowy: Przekształcamy teraz krok po kroku archiwum danych technicznych w użyteczną bazę wiedzy. I właśnie od tego zaczynamy w następnym rozdziale. Celem jest wyodrębnienie danych czatu i przygotowanie ich w taki sposób, aby można je było później efektywnie przeszukiwać.
Przygotowywanie danych: Od rozmów do tekstów nadających się do analizy
Po rozpakowaniu eksportu danych ChatGPT w poprzednim rozdziale i uzyskaniu wstępnego przeglądu struktury, rozpoczyna się właściwa techniczna część naszego projektu. Chociaż wyeksportowane dane są kompletne, nie są jeszcze optymalnie dostosowane do naszego systemu wiedzy w tej formie.
Powód jest prosty: historie czatów są zwykle długie, zawierają wiele tematów i są przechowywane w strukturze, która jest czytelna dla ludzi, ale nie jest idealna do wyszukiwania semantycznego lub wektorowych baz danych. Aby nasza sztuczna inteligencja mogła później znaleźć odpowiednie treści, musimy najpierw przetworzyć te surowe dane. Zasadniczo oznacza to trzy rzeczy:
- Wyodrębnianie konwersacji z plików JSON
- rozsądna struktura tekstu
- podzielić zawartość na mniejsze sekcje
Proces ten jest całkowicie normalnym krokiem w nowoczesnych systemach sztucznej inteligencji i jest często określany jako przetwarzanie wstępne.
Dlaczego surowe dane nie są bezpośrednio odpowiednie
Jeśli spojrzysz na jeden z plików JSON, zauważysz, że pojedynczy czat często składa się z wielu wiadomości. Typowy dialog może wyglądać na przykład tak:
- Pytanie
- Odpowiedź
- Zapytanie
- nowa deklaracja
- dalsze szczegóły
- Podsumowanie
Niektóre rozmowy mogą zawierać setki, a nawet tysiące słów. Dla ludzi nie stanowi to problemu. Po prostu czytamy dialog od góry do dołu.
Działa to jednak gorzej w przypadku wyszukiwania AI. Powodem tego jest fakt, że pojedynczy czat często zawiera kilka tematów. Jeśli później przeprowadzimy wyszukiwanie semantyczne, system powinien znaleźć fragmenty tekstu tak dokładnie, jak to możliwe - a nie całe rozmowy z wieloma różnymi treściami.
Dlatego duże teksty są dzielone na mniejsze sekcje. Sekcje te nazywane są fragmentami. Fragment to po prostu mały blok tekstu, który zawiera spójną myśl. Metoda ta znacznie poprawia jakość późniejszego wyszukiwania.
Wyodrębnianie historii czatów
Pierwszym praktycznym krokiem jest odczytanie zawartości z plików JSON. Używamy do tego małego skryptu Pythona. Python jest szczególnie odpowiedni do takich zadań, ponieważ zawiera wiele bibliotek do przetwarzania danych i sztucznej inteligencji.
Najpierw utwórz nowy plik, na przykład:
extract_chats.py
Następnie dodajemy prosty skrypt, który ładuje dane czatu.
import json
with open("conversations.json", "r", encoding="utf-8") as f:
data = json.load(f)
print("Anzahl der Gespräche:", len(data))Po uruchomieniu tego skryptu powinieneś zobaczyć, ile konwersacji zawiera eksport. Teraz wyodrębnijmy rzeczywiste teksty.
texts = []
for conversation in data:
if "mapping" in conversation:
for node in conversation["mapping"].values():
message = node.get("message")
if message:
content = message.get("content")
if content and "parts" in content:
text = " ".join(content["parts"])
texts.append(text)
print("Extrahierte Textabschnitte:", len(texts))Ten skrypt przechodzi przez strukturę JSON i zbiera wszystkie części tekstowe z konwersacji. Oznacza to, że zakończyliśmy już najważniejszą część: wyodrębniliśmy zawartość z technicznego formatu eksportu.
Tworzenie fragmentów tekstu
Teraz nadchodzi kolejny ważny krok: dzielenie na fragmenty. Zamiast zapisywać całe rozmowy, dzielimy teksty na mniejsze sekcje.
Typowy rozmiar takich fragmentów tekstu wynosi od 300 do 800 słów lub około 500 tokenów. Poniżej znajduje się prosty przykład podziału tekstu na fragmenty.
def split_text(text, chunk_size=500):
words = text.split()
chunks = []
for i in range(0, len(words), chunk_size):
chunk = " ".join(words[i:i+chunk_size])
chunks.append(chunk)
return chunksTeraz możemy zastosować tę funkcję do naszych tekstów.
all_chunks = []
for text in texts:
chunks = split_text(text)
all_chunks.extend(chunks)
print("Gesamtzahl der Chunks:", len(all_chunks))Stworzyliśmy teraz wiele mniejszych sekcji tekstowych z historii naszych czatów. Te bloki tekstowe są idealne do późniejszego wyszukiwania w wektorowej bazie danych.
Dodaj metadane
Oprócz samego tekstu, bardzo pomocne mogą być dodatkowe informacje. Te tak zwane metadane pomagają nam później lepiej sortować lub filtrować treści. Typowymi metadanymi mogą być
- Data rozmowy
- Tytuł rozmowy
- Źródło (ChatGPT Export)
- Identyfikator połączenia
Możemy zapisać te informacje razem z tekstem, na przykład w następujący sposób:
documents = []
for conversation in data:
title = conversation.get("title", "Unbekannt")
if "mapping" in conversation:
for node in conversation["mapping"].values():
message = node.get("message")
if message:
content = message.get("content")
if content and "parts" in content:
text = " ".join(content["parts"])
chunks = split_text(text)
for chunk in chunks:
documents.append({
"text": chunk,
"title": title
})Dzięki temu nasze dane zyskały znacznie lepszą strukturę. Zamiast zagmatwanego archiwum czatów, mamy teraz zbiór wielu małych sekcji tekstowych, z których każda zawiera informacje kontekstowe.
To właśnie ta struktura będzie kluczowa w następnym kroku. Ponieważ teraz możemy zacząć generować osadzenia z tych tekstów - tj. matematyczne reprezentacje treści, które później zostaną zapisane w naszej wektorowej bazie danych. I o tym właśnie jest następny rozdział.
Tworzenie osadzeń
W poprzednim rozdziale umieściliśmy już nasze dane ChatGPT w użytecznej formie. Wyodrębniliśmy konwersacje z plików JSON, wyczyściliśmy teksty i podzieliliśmy je na mniejsze sekcje - tak zwane chunki.
Jednak wciąż brakuje jednego kluczowego kroku, zanim nasza sztuczna inteligencja będzie mogła naprawdę wyszukiwać treści w znaczący sposób. Teksty muszą zostać przetłumaczone na formę, którą maszyny mogą porównać. W tym miejscu do gry wkraczają osadzenia.
Osadzenia są matematycznymi reprezentacjami tekstów. Umożliwiają one komputerom porównywanie znaczenia tekstów. Dwa teksty o podobnej treści otrzymują podobne wektory - nawet jeśli używają różnych słów. Jest to dokładnie ta właściwość, której potrzebujemy dla naszego systemu wiedzy. W końcu nasza sztuczna inteligencja powinna nie tylko wyszukiwać identyczne słowa, ale także teksty o pasującej treści.
Czym są osadzenia
Osadzenie jest zasadniczo listą liczb. Liczby te opisują znaczenie tekstu w przestrzeni matematycznej. Każdy tekst jest konwertowany na tak zwany wektor. Taki wektor może wyglądać na przykład tak:
[0.134, -0.876, 0.442, 0.921, -0.223, ...]
Pojedynczy wektor może zawierać kilkaset lub nawet tysiące liczb. Liczby te nie są oczywiście bezpośrednio zrozumiałe dla ludzi. Dla maszyn są one jednak idealne do obliczania podobieństw między tekstami. Jeśli dwa teksty mają podobną treść, ich wektory są bliżej siebie w przestrzeni matematycznej. Przykład:
- Tekst A„Jak mogę wyeksportować moje dane ChatGPT?“
- Tekst B„Jak mogę pobrać moje rozmowy ChatGPT?“
Chociaż sformułowania są różne, oba teksty zasadniczo opisują ten sam temat. Dobry model osadzania rozpoznaje to podobieństwo. Oba teksty otrzymują zatem podobne wektory. Dokładnie tę zasadę wykorzystamy później w naszym wyszukiwaniu semantycznym.
Osadzanie modeli z Ollama
Potrzebujemy specjalnego modelu do tworzenia embeddings. Na szczęście nie musimy w tym celu korzystać z zewnętrznych usług w chmurze. Wiele modeli osadzania może być teraz obsługiwanych lokalnie - i właśnie tutaj do gry wkracza Ollama.
Ponieważ Ollama jest już uruchomiony w systemie, możemy osadzić tam model install. Bardzo dobrym modelem jest np:
nomic-embed-text
Można go okiełznać za pomocą następującego polecenia 1TP12:
ollama pull nomic-embed-text
Inne popularne modele to
- mxbai-embed-large
- bge-large
- all-minilm
Dla naszych celów nomic-embed-text jest bardzo dobrym punktem wyjścia. Model ten generuje wysokiej jakości osadzenia i działa lokalnie bez żadnych problemów.
Lokalne tworzenie osadzeń
Teraz chcemy rozszerzyć nasz skrypt Pythona, aby mógł generować osadzenia. Najpierw installworzymy bibliotekę, za pomocą której Python może komunikować się z Ollama.
pip install ollama
Teraz możemy zająć się modelem osadzania bezpośrednio z Pythona. Poniżej znajduje się prosty przykład:
import ollama
response = ollama.embeddings(
model="nomic-embed-text",
prompt="Wie exportiere ich meine ChatGPT-Daten?"
)
print(len(response["embedding"]))Jeśli wszystko zadziałało, otrzymasz wektor z kilkuset liczbami.
Zastosujmy to teraz do naszych fragmentów czatu.
embeddings = []
for doc in documents:
text = doc["text"]
result = ollama.embeddings(
model="nomic-embed-text",
prompt=text
)
vector = result["embedding"]
embeddings.append({
"text": text,
"embedding": vector,
"title": doc["title"]
})Na tej podstawie tworzymy wektor dla każdej sekcji tekstu. Wektory te są później zapisywane w naszej bazie danych.
Dlaczego ten krok jest kluczowy
Osadzenia są sercem nowoczesnych systemów wiedzy. Bez osadzeń moglibyśmy przeszukiwać teksty tylko za pomocą klasycznego wyszukiwania słów kluczowych. Oznaczałoby to, że system znajdowałby tylko treści zawierające dokładnie te same słowa. Ale język rzadko działa w tak prosty sposób. Na przykład, użytkownik może zapytać:
„Jak przetworzyłem moje dane ChatGPT?“
Jednak oryginalna rozmowa mogłaby zostać sformułowana jako:
„Jak mogę przeanalizować mój eksport danych ChatGPT?“
Proste wyszukiwanie może nie rozpoznać tego połączenia. Inaczej jest w przypadku embeddings. Ponieważ oba teksty mają podobne znaczenie, ich wektory są blisko siebie w przestrzeni matematycznej. Nasza baza danych może zatem znaleźć pasującą treść, nawet jeśli sformułowanie jest inne. To właśnie ta zdolność sprawia, że wyszukiwanie semantyczne jest tak potężne. Pozwala ono sztucznej inteligencji wyszukiwać nie tylko słowa, ale i znaczenia.
I właśnie dlatego osadzenia są centralnym elementem naszego systemu. W następnym rozdziale oprzemy się na tym i installieren naszą wektorową bazę danych. Będziemy tam przechowywać wygenerowane wektory - i w ten sposób stworzymy podstawę naszej osobistej wiedzy AI.
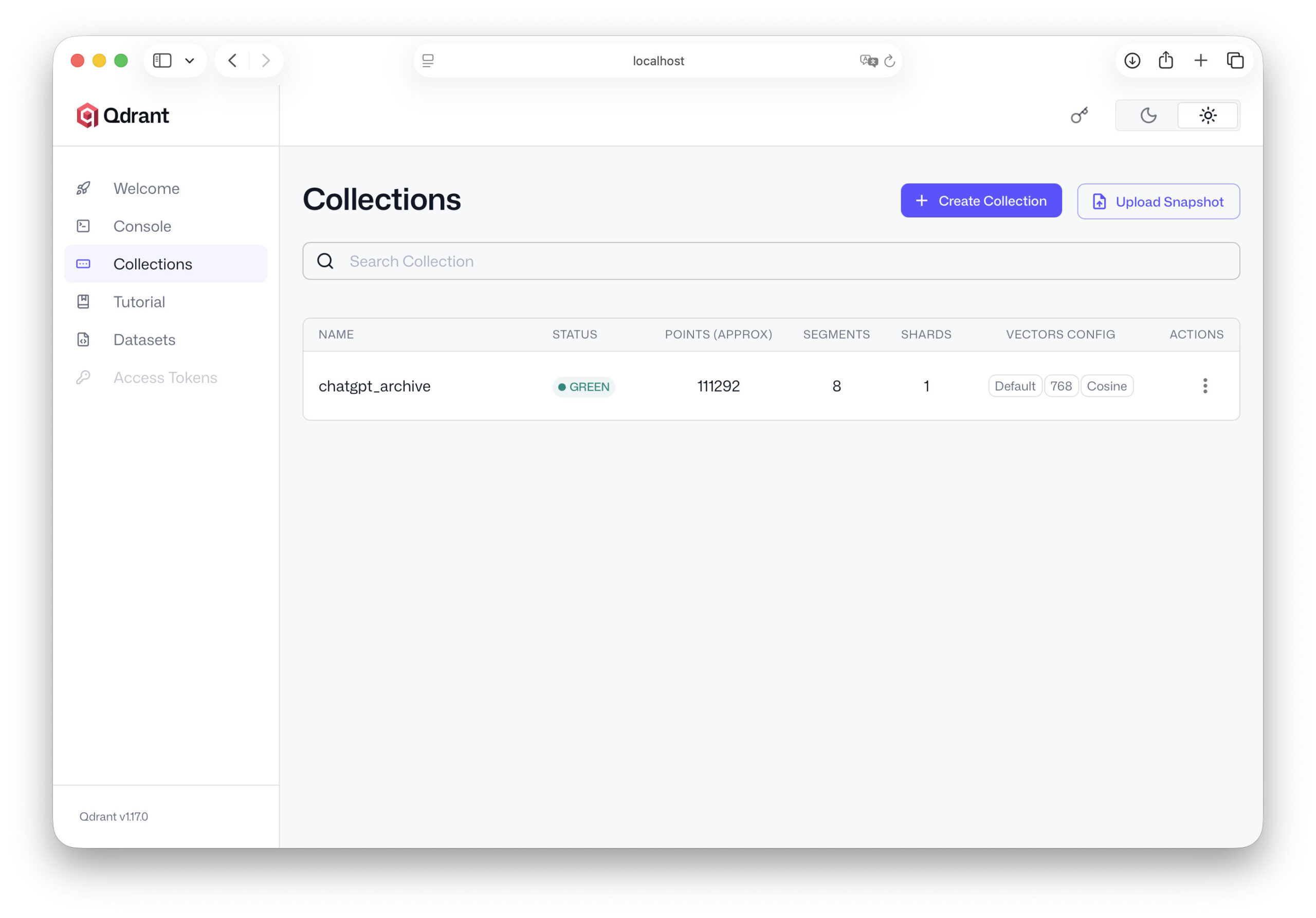
Qdrant 1TP12Dodaj i skonfiguruj
Po utworzeniu osadzeń dla naszych danych czatu w poprzednim rozdziale, mamy teraz zbiór fragmentów tekstu i powiązanych z nimi wektorów. Wektory te opisują matematycznie znaczenie tekstów, a tym samym stanowią podstawę wyszukiwania semantycznego. Dane te są jednak obecnie dostępne tylko w pamięci roboczej naszego skryptu lub na prostych listach. Potrzebujemy wyspecjalizowanej pamięci, aby nasza sztuczna inteligencja mogła później uzyskać do nich skuteczny dostęp.
Właśnie w tym miejscu do gry wkracza wektorowa baza danych. Wektorowa baza danych jest zoptymalizowana do przechowywania dużych ilości takich osadzeń i szybkiego wyszukiwania podobnych wektorów. W naszym projekcie korzystamy z Qdrant, nowoczesnej bazy danych typu open source, która została opracowana specjalnie dla aplikacji AI.
W tym rozdziale 1TP12 zainstalujemy Qdrant, uruchomimy serwer i przygotujemy bazę danych, abyśmy mogli później łatwo zaimportować nasze dane czatu.
Czym jest Qdrant
Qdrant to wyspecjalizowana baza danych do tak zwanego wyszukiwania wektorowego. Podczas gdy tradycyjne bazy danych przechowują informacje w tabelach - takich jak nazwy, liczby lub teksty - wektorowa baza danych działa z matematycznymi reprezentacjami danych.
Oznacza to, że zamiast zapisywać tylko tekst, Qdrant zapisuje powiązane osadzenia. Dużą zaletą jest wyszukiwanie. Jeśli pytanie zostanie zadane później, nasz system konwertuje je również na wektor. Qdrant może następnie błyskawicznie obliczyć, które zapisane teksty są najbardziej podobne do tego wektora. Dzięki temu można na przykład dowiedzieć się:
- które fragmenty czatu pasują tematycznie do pytania
- które poprzednie rozmowy zawierają podobną treść
- które pomysły mogą być istotne w Twoim archiwum
Właśnie dlatego Qdrant jest obecnie wykorzystywany w wielu nowoczesnych systemach sztucznej inteligencji - od wyszukiwania dokumentów po złożonych asystentów wiedzy. Kolejna zaleta: Qdrant jest open source, szybko 1TP12ised i działa płynnie na zwykłej lokalnej maszynie.
Instalacja Qdrant
Najprostszym sposobem na installieren Qdrant jest użycie Dockera. Jeśli Docker jest dostępny na twoim komputerze, możesz uruchomić serwer za pomocą jednego polecenia. Tutaj możesz Pobierz Docker, jeśli nie został jeszcze zainstalowany na komputerze installiert.
docker run -p 6333:6333 qdrant/qdrant
To polecenie uruchamia serwer Qdrant i otwiera standardowy port 6333. Nasze skrypty mogą później komunikować się z bazą danych za pośrednictwem tego portu.
Jeśli nie chcesz korzystać z Dockera, istnieją również inne sposoby na installiere Qdrant, na przykład za pośrednictwem lokalnego pliku binarnego lub menedżera pakietów. W wielu praktycznych projektach Docker okazał się jednak najprostszą i najbardziej stabilną opcją.
Po uruchomieniu serwera Qdrant działa w tle i czeka na żądania. Teraz można sprawdzić, czy serwer jest dostępny. Aby to zrobić, otwórz następujący adres w przeglądarce:
http://localhost:6333
Jeśli wszystko zadziałało, powinien pojawić się prosty komunikat o stanie. Serwer jest teraz gotowy do wykonania kolejnych kroków.
Pierwsze kroki z Qdrant
Zanim będziemy mogli zaimportować nasze dane czatu, musimy utworzyć tak zwaną kolekcję. W Qdrant kolekcja jest porównywalna do tabeli w klasycznej bazie danych. Zawiera ona nasze wektory i odpowiadające im dane.
Najpierw installiere biblioteki Python dla Qdrant:
pip install qdrant-client
Teraz możemy nawiązać połączenie z bazą danych w naszym skrypcie Python.
from qdrant_client import QdrantClient
client = QdrantClient("localhost", port=6333)Jeśli ten kod zostanie wykonany bez komunikatu o błędzie, połączenie się powiedzie. Teraz tworzymy kolekcję dla naszych danych czatu.
from qdrant_client.models import VectorParams, Distance client.recreate_collection( collection_name="chatgpt_archive", vectors_config=VectorParams(size=768, distance=Distance.COSINE), )
Najważniejszymi parametrami są tutaj
- collection_name - nazwa naszej bazy danych
- rozmiar - długość wektorów osadzania
- odległość - metoda obliczania podobieństwa
Rozmiar wektora zależy od używanego modelu osadzania. Wiele modeli działa z wektorami o wymiarach 768 lub 1024. Funkcja odległości kosinusowej jest jedną z najpopularniejszych metod obliczania podobieństw między tekstami. Oznacza to, że nasza baza danych jest już gotowa do użycia.
Struktura danych planu
Zanim zaimportujemy nasze dane, warto przyjrzeć się strukturze, którą chcemy zapisać. Każdy wpis w naszej wektorowej bazie danych będzie składał się z kilku komponentów:
- ID - unikalny identyfikator
- Osadzanie - wektor tekstu
- Ładunek - Dodatkowe informacje o tekście
Ładunek może zawierać na przykład
- tekst oryginalny
- tytuł rozmowy
- data
- inne metadane
Przykładowy rekord danych może wyglądać następująco:
{
"id": 1,
"vector": [0.123, -0.452, 0.889, ...],
"payload": {
"text": "Wie kann ich meinen ChatGPT-Datenexport analysieren?",
"title": "Datenanalyse"
}
}
Struktura ta ma istotną zaletę. Wektory są używane do wyszukiwania semantycznego, podczas gdy ładunek zawiera wszystkie informacje, które chcemy później wyświetlić lub przeanalizować. Oznacza to, że nasz system pozostaje elastyczny i można go później łatwo rozbudować.
Oznacza to, że najważniejsza część infrastruktury jest już przygotowana. Nasz serwer Qdrant działa, baza danych jest skonfigurowana i wiemy, jaką strukturę będą miały nasze dane. W następnym rozdziale zaczynamy od kluczowego kroku: importujemy nasze dane ChatGPT do bazy danych i przekształcamy nasze archiwum rozmów w prawdziwą, przeszukiwalną bazę wiedzy.
Importowanie danych ChatGPT do Qdrant
Teraz, gdy stworzyliśmy Qdrant installiert i kolekcję w poprzednim rozdziale, techniczna podstawa naszej bazy wiedzy została stworzona. Nasze osadzenia już istnieją - utworzyliśmy je z danych ChatGPT - a Qdrant działa jako serwer bazy danych na naszym komputerze.
Teraz nadchodzi kluczowy krok: ładujemy nasze dane do bazy danych. Zapisujemy nie tylko same wektory, ale także powiązane z nimi teksty i metadane. Ta kombinacja pozwala naszej sztucznej inteligencji później znaleźć odpowiednie treści i wykorzystać je w odpowiedziach. W tym rozdziale budujemy faktyczną bazę wiedzy naszego systemu.
Zapisywanie osadzeń
Po pierwsze, musimy przenieść nasze wygenerowane osadzenia do bazy danych. Każdy wpis w Qdrant składa się z trzech komponentów:
- identyfikator
- wektor (osadzenie)
- ładunek z dodatkowymi danymi
W naszym przypadku, na przykład, ładunek zawiera
- sekcja tekstowa
- tytuł rozmowy
- Możliwe dalsze metadane
W Pythonie możemy przygotować taką strukturę stosunkowo łatwo. Przykład:
points = []
for idx, item in enumerate(embeddings):
points.append({
"id": idx,
"vector": item["embedding"],
"payload": {
"text": item["text"],
"title": item["title"]
}
})Generuje to listę punktów danych, które możemy następnie zapisać w Qdrant. Każdy punkt danych zawiera zatem fragment tekstu, odpowiedni wektor i dodatkowe informacje kontekstowe. Ta struktura będzie później stanowić podstawę naszego wyszukiwania semantycznego.
Tworzenie skryptu importu
Teraz łączymy nasz skrypt Python z Qdrant i przesyłamy dane. Aby to zrobić, używamy klienta Qdrant Python, który przeanalizowaliśmy w poprzednim rozdziale 1TP12. Import może wyglądać na przykład tak:
from qdrant_client import QdrantClient
from qdrant_client.models import PointStruct
client = QdrantClient("localhost", port=6333)
points = []
for idx, item in enumerate(embeddings):
point = PointStruct(
id=idx,
vector=item["embedding"],
payload={
"text": item["text"],
"title": item["title"]
}
)
points.append(point)
client.upsert(
collection_name="chatgpt_archive",
points=points
)
print("Import abgeschlossen:", len(points), "Datensätze gespeichert.")Polecenie upsert gwarantuje, że dane zostaną zapisane w kolekcji. Jeśli identyfikator już istnieje, wpis jest aktualizowany. W przeciwnym razie tworzony jest nowy rekord danych. W zależności od rozmiaru eksportu ChatGPT, import może zająć kilka sekund lub minut. Jest to całkowicie normalne w przypadku większych zestawów danych - takich jak kilka tysięcy sekcji tekstowych.
Testowa baza danych
Po zakończeniu importu powinniśmy sprawdzić, czy nasze dane zostały poprawnie zapisane. Najprostszym testem jest przeprowadzenie wyszukiwania wektorowego. Aby to zrobić, najpierw tworzymy osadzenie dla pytania testowego.
query = "Wie kann ich ChatGPT-Daten analysieren?" query_vector = ollama.embeddings( model="nomic-embed-text", prompt=query )["embedding"]
Teraz możemy przeszukać Qdrant pod kątem podobnych wektorów.
search_result = client.search( collection_name="chatgpt_archive", query_vector=query_vector, limit=3 )
Polecenie to zwraca trzy najbardziej podobne fragmenty tekstu z naszej bazy danych. Możemy wyświetlić je na przykład w ten sposób:
for result in search_result:
print(result.payload["text"])
print("---")Jeśli wszystko zadziałało, pojawią się sekcje czatu z Twojego archiwum, które pasują do wyszukiwanego hasła. Teraz już wiemy: Nasza baza danych działa.
Pierwsza ocena wyników
Ten moment jest jednym z najbardziej ekscytujących aspektów całego projektu. Po raz pierwszy okazuje się, że nasze archiwum czatów może być faktycznie wykorzystywane jako źródło wiedzy. Możesz teraz wypróbować różne zapytania wyszukiwania. Na przykład:
- „Artykuł AI“
- „System RAG“
- „Eksport danych ChatGPT“
- „Pomysł na strategię“
W zależności od zawartości historii czatu, Qdrant znajdzie odpowiednie fragmenty tekstu. Czasami będziesz zaskoczony, jakie treści pojawią się ponownie. Rozmowy, o których dawno zapomniałeś, mogą nagle znów stać się istotne. To bardzo wyraźnie pokazuje, dlaczego takie podejście jest tak interesujące. Twoje stare konwersacje AI nie są już tylko archiwum. Stają się bazą wiedzy, którą można przeszukiwać.
W ten sposób osiągnęliśmy ważny kamień milowy. Nasze dane ChatGPT są teraz w pełni przechowywane w wektorowej bazie danych i mogą być przeszukiwane semantycznie. W następnym rozdziale pójdziemy o krok dalej: połączymy naszą bazę wiedzy z samą sztuczną inteligencją. Umożliwi to modelowi językowemu dostęp do tych danych w przyszłości i włączenie ich bezpośrednio do odpowiedzi.
Łączenie sztucznej inteligencji z bazą wiedzy
Do tego momentu zbudowaliśmy już dużą część infrastruktury. Nasze dane ChatGPT zostały wyodrębnione z eksportu, podzielone na mniejsze sekcje tekstowe, osadzone i ostatecznie zapisane w wektorowej bazie danych Qdrant.
Jednak nasza sztuczna inteligencja nie pracuje jeszcze z tymi danymi. Chociaż możemy przeprowadzić wyszukiwanie wektorowe za pomocą Pythona i znaleźć odpowiednie fragmenty tekstu, sama sztuczna inteligencja nie jest jeszcze tego świadoma. Kiedy zadajemy jej pytanie, nadal korzysta tylko ze swojej ogólnej wiedzy językowej.
Następnym krokiem jest zatem połączenie tych dwóch światów. Budujemy teraz proces, w którym sztuczna inteligencja najpierw otrzymuje odpowiednie treści z bazy wiedzy, a następnie włącza je do swojej odpowiedzi. To jest właśnie rdzeń systemu RAG.
Proces zapytania
Proces zapytania zmienia się nieco dzięki naszemu systemowi wiedzy. Do tej pory rozmowa ze sztuczną inteligencją zwykle wyglądała następująco:
- Zadajesz pytanie →
- Sztuczna inteligencja przetwarza pytanie →
- SI generuje odpowiedź.
Dodatkowym krokiem jest baza wiedzy. Nowy proces wygląda następująco:
- Zadajesz pytanie →
- pytanie jest przekształcane w osadzenie →
- wektorowa baza danych wyszukuje podobne teksty →
- Teksty te są przenoszone do sztucznej inteligencji jako kontekst →
SI formułuje odpowiedź. Oznacza to, że sztuczna inteligencja pracuje już nie tylko ze swoją wyszkoloną wiedzą, ale także z własnymi danymi. Ten kontekst często sprawia, że odpowiedzi są znacznie bardziej precyzyjne i spersonalizowane.
Etap odzyskiwania
Pierwsza część tego procesu jest znana jako odzyskiwanie. Retrieval oznacza po prostu „pobieranie“. Na tym etapie nasz system przeszukuje bazę danych w poszukiwaniu treści pasujących do tematu pytania. Najpierw tworzymy kolejne osadzenie dla bieżącego pytania.
query = "Welche Ideen hatte ich zur Nutzung meines ChatGPT-Datenexports?" query_vector = ollama.embeddings( model="nomic-embed-text", prompt=query )["embedding"]
To osadzenie opisuje znaczenie pytania w formie matematycznej. Qdrant może teraz wyszukiwać podobne wektory.
results = client.search( collection_name="chatgpt_archive", query_vector=query_vector, limit=5 )
Baza danych zwraca teraz pięć fragmentów tekstu, które najlepiej pasują do pytania. Te fragmenty tekstu tworzą kontekst dla sztucznej inteligencji. Zbieramy je na liście.
context_texts = [] for r in results: context_texts.append(r.payload["text"])
Mamy teraz zbiór odpowiednich treści z naszego archiwum czatów.
Przeniesienie kontekstu do Ollama
Teraz następuje decydujący krok. Przekazujemy ten kontekst wraz z oryginalnym pytaniem do naszego modelu językowego. Model może teraz wykorzystać te informacje do sformułowania odpowiedzi.
Najpierw tworzymy tak zwany monit. Podpowiedź to po prostu tekst, który wysyłamy do sztucznej inteligencji.
context = "\n\n".join(context_texts)
prompt = f"""
Du bist ein KI-Assistent, der mit meinem persönlichen Wissensarchiv arbeitet.
Nutze die folgenden Textausschnitte als Kontext:
{context}
Beantworte nun diese Frage:
{query}
"""Teraz wysyłamy ten monit do naszego modelu językowego w Ollama.
response = ollama.chat(
model="llama3",
messages=[
{"role": "user", "content": prompt}
]
)
print(response["message"]["content"])Sztuczna inteligencja otrzymuje teraz zarówno pytanie, jak i odpowiednie fragmenty tekstu z naszej bazy danych. Umożliwia to generowanie odpowiedzi na podstawie naszych własnych danych.
Generowanie odpowiedzi
Ostatnim krokiem jest faktyczne generowanie odpowiedzi. Model językowy łączy teraz dwa źródła wiedzy:
jego własna wyszkolona wiedza
kontekst z naszej bazy wiedzy
Ta kombinacja jest szczególnie potężna. Model może wyjaśniać ogólne zależności i jednocześnie uwzględniać konkretne treści z naszego archiwum. Przykład: Jeśli zapytasz:
„Jakie mam pomysły na wykorzystanie eksportu danych ChatGPT?“
Sztuczna inteligencja może teraz uzyskać dostęp do poprzednich rozmów i utworzyć z nich ustrukturyzowane podsumowanie. Może na przykład odpowiedzieć:
- Mówiłeś o budowaniu osobistego archiwum wiedzy
- Chciałeś stworzyć lokalną sztuczną inteligencję z systemem RAG
- Rozwinąłeś pomysł serii artykułów
Bez etapu wyszukiwania sztuczna inteligencja w ogóle nie znałaby tych informacji. Dzięki naszemu systemowi archiwum czatów staje się prawdziwym źródłem wiedzy. Jest to najważniejsza część naszego systemu. Mamy teraz:
- lokalna sztuczna inteligencja przez Ollama
- wektorowa baza danych z naszymi danymi czatu
- wyszukiwanie semantyczne
- przepływ pracy RAG
W następnym rozdziale przetestujemy ten system w praktyce i zobaczymy, jak dobrze działa nasza osobista sztuczna inteligencja.
Pierwsze zapytania z osobistą wiedzą AI
Teraz, gdy ustanowiliśmy połączenie między naszą sztuczną inteligencją a bazą wiedzy w poprzednim rozdziale, system jest technicznie kompletny. Nasze dane ChatGPT znajdują się w wektorowej bazie danych, sztuczna inteligencja może pobierać odpowiednie treści, a cały proces systemu RAG działa.
Teraz nadchodzi najbardziej ekscytująca część projektu: pierwsze prawdziwe zapytania. Ponieważ dopiero teraz możemy sprawdzić, czy nasz system rzeczywiście robi to, na co liczyliśmy - a mianowicie znajduje poprzednie rozmowy, analizuje treść i generuje znaczące odpowiedzi. W tym rozdziale przetestujemy naszą sztuczną inteligencję, przyjrzymy się typowym przypadkom użycia i przyjrzymy się możliwym optymalizacjom.
Przykładowe zapytania
Zacznijmy od kilku prostych pytań. Dobrą strategią jest rozpoczęcie od zadawania pytań, o których wiesz, że znajdują się w archiwum czatu. Na przykład:
„Jakie mam pomysły na wykorzystanie eksportu danych ChatGPT?“
„Co napisałem o systemach RAG?“
„Jakie strategie wykorzystania sztucznej inteligencji omówiłem?“.“
Pytania te celowo zawierają otwarte sformułowania. Celem nie jest znalezienie konkretnego tekstu, ale odkrycie odpowiedniej tematycznie treści. Kiedy zadajesz takie pytanie swojemu systemowi, w tle odbywa się proces, który opisaliśmy w poprzednim rozdziale:
- Pytanie jest konwertowane na osadzenie.
- Wektorowa baza danych wyszukuje podobne fragmenty tekstu.
- Te fragmenty tekstu są przenoszone do SI jako kontekst.
- Sztuczna inteligencja generuje odpowiedź na podstawie tego kontekstu.
Rezultat może być zaskakujący. Często pojawiają się dawno zapomniane rozmowy. Stare pomysły nagle pojawiają się na ekranie - czasem nawet w zupełnie nowym kontekście.
To jest właśnie siła tego podejścia. Twoje archiwum czatów staje się przeszukiwalnym źródłem wiedzy.
Jakość odpowiedzi
Jeśli wypróbujesz kilka zapytań, zdasz sobie sprawę, że jakość odpowiedzi może się różnić. Jest to całkowicie normalne. Jakość takiego systemu zależy od kilku czynników. Jednym z nich jest rozmiar fragmentów tekstu. Jeśli sekcje są zbyt duże, mogą zawierać kilka tematów. Sprawia to, że wyszukiwanie jest mniej dokładne.
Jeśli jednak fragmenty są zbyt małe, czasami brakuje niezbędnego kontekstu. Innym czynnikiem jest model osadzania. Różne modele w różny sposób rozpoznają konteksty znaczeniowe. Niektóre są szczególnie odpowiednie dla tekstów technicznych, inne dla języka ogólnego.
Liczba pobranych wyników również odgrywa rolę. Na przykład, jeśli zostaną pobrane tylko dwa fragmenty tekstu, ważne informacje mogą zostać pominięte. Z drugiej strony, jeśli załadowanych zostanie zbyt wiele tekstów, sztuczna inteligencja może mieć trudności z rozpoznaniem odpowiedniego kontekstu.
Parametry te można później łatwo dostosować. Najważniejszą rzeczą jest przede wszystkim posiadanie działającego systemu podstawowego.
Typowe problemy
Jak w przypadku każdego systemu technicznego, również tutaj mogą wystąpić pewne trudności. Częstym problemem jest to, że baza danych znajduje teksty, które są tylko częściowo istotne. Dzieje się tak, ponieważ wyszukiwanie semantyczne zawsze działa z prawdopodobieństwem.
Inny problem może pojawić się, jeśli tekst został zbytnio rozdrobniony. Jeśli myśl jest rozłożona na kilka fragmentów, sztuczna inteligencja może mieć trudności z rozpoznaniem kontekstu.
Podpowiedź również odgrywa rolę. Jeśli podpowiedź jest niejasna, sztuczna inteligencja może nie wykorzystać kontekstu w optymalny sposób. Przykład lepszej podpowiedzi mógłby wyglądać następująco:
Skorzystaj z poniższych fragmentów tekstu z mojego archiwum wiedzy,
aby jak najdokładniej odpowiedzieć na pytanie.
Jeśli dostępna jest odpowiednia treść, podsumuj ją.
Takie drobne korekty mogą znacznie poprawić jakość odpowiedzi.
Dokładne dostrojenie
Gdy tylko system w zasadzie działa, rozpoczyna się najciekawsza część: dostrajanie. Tutaj możesz eksperymentować i ulepszać swój system wiedzy krok po kroku. Niektóre typowe optymalizacje to
- Dostosowywanie rozmiaru fragmentu
Czasami mniejsze fragmenty tekstu zapewniają lepsze wyniki. W innych przypadkach przydaje się więcej kontekstu. - Zastosowanie innego modelu osadzania
Zmiana modelu może znacząco poprawić jakość wyszukiwania semantycznego. - Więcej kontekstu dla sztucznej inteligencji
Z bazy danych można pobrać więcej wyników, na przykład dziesięć fragmentów tekstu zamiast pięciu. - Używanie metadanych
Jeśli zapiszesz dodatkowe informacje - takie jak data lub tytuł połączenia - możesz później dokładniej filtrować wyszukiwanie.
Te regulacje są częścią każdego prawdziwego systemu RAG. Rzadko istnieje idealne ustawienie dla wszystkich sytuacji. Ale to jest właśnie urok takich systemów: można je stale ulepszać.
W tym rozdziale przeprowadziliśmy pierwszy pełny test naszego systemu. Przekonaliśmy się, że nasza osobista sztuczna inteligencja rzeczywiście jest w stanie przeszukiwać stare konwersacje i pobierać odpowiednie treści.
Oznacza to, że rdzeń naszego projektu został już osiągnięty. Ale system można jeszcze znacznie rozszerzyć. W następnym rozdziale przyjrzymy się zatem, jak krok po kroku zintegrować dodatkowe źródła danych i rozszerzyć osobiste archiwum wiedzy.


Rozszerzenia dla osobistego systemu wiedzy AI
Stworzyłeś już działający system z poprzednią konfiguracją. Dane z ChatGPT zostały wyodrębnione, przekonwertowane na embeddings, zapisane w Qdrant i ostatecznie połączone z lokalną sztuczną inteligencją. Rezultatem jest sztuczna inteligencja, która może uzyskać dostęp do poprzednich rozmów.
Ale ściśle mówiąc, jesteśmy dopiero na początku. Zbudowana architektura nie ogranicza się do danych ChatGPT. Działa ona z każdym rodzajem tekstu. Wszystko, co można przekonwertować na dokumenty lub pliki tekstowe, może stać się częścią tego systemu wiedzy. W tym właśnie tkwi prawdziwy potencjał takich systemów.
Zasadniczo zbudowaliśmy osobistą maszynę wiedzy. Maszynę tę można rozbudowywać krok po kroku. W tym rozdziale przyjrzymy się wynikającym z tego możliwościom i sposobom rozbudowy systemu w dłuższej perspektywie.
Integracja dodatkowych źródeł danych
Najbardziej oczywistym kolejnym krokiem jest dodanie większej ilości treści do bazy wiedzy. Rozmowy na ChatGPT są dobrym początkiem, ale zazwyczaj reprezentują tylko część Twojej wiedzy. Wiele informacji jest dostępnych w innych formatach. Na przykład:
- własne artykuły
- Uwagi
- Dokumenty PDF
- Dokumenty badawcze
- E-booki
- Protokoły lub listy pomysłów
Cała ta zawartość może być przetwarzana w taki sam sposób, jak nasze dane czatu. Proces pozostaje identyczny:
- Wyciąg tekstu
- Dzielenie tekstu na fragmenty
- Tworzenie osadzeń
- Zapisywanie danych w Qdrant
Przykład: Jeśli napisałeś wiele własnych artykułów, możesz zaimportować te teksty do bazy wiedzy. Sztuczna inteligencja może później uzyskać do nich dostęp i rozpoznać korelacje. Na przykład możesz zapytać:
„Jakie artykuły napisałem o sztucznej inteligencji?“.“
lub
„Jakie argumenty opracowałem na ten temat w przeszłości?“.“
Następnie sztuczna inteligencja przeszukuje archiwum artykułów i wykorzystuje znalezione treści jako kontekst. W ten sposób system krok po kroku rozwija się w kompleksowe archiwum wiedzy.
Kilka baz danych wiedzy
Wraz ze wzrostem ilości danych przydatne może być oddzielenie różnych obszarów. Qdrant umożliwia tworzenie wielu kolekcji. Każda kolekcja może reprezentować własną bazę wiedzy. Możliwy system mógłby wyglądać na przykład tak:
- Kolekcja 1Rozmowy ChatGPT
- Kolekcja 2: Archiwum artykułów
- Kolekcja 3notatki osobiste
- Kolekcja 4Dokumentacja techniczna
Taka separacja ma kilka zalet. Po pierwsze, struktura pozostaje przejrzysta. Zawsze wiadomo, gdzie przechowywana jest określona zawartość. Po drugie, zapytania mogą być bardziej szczegółowo kontrolowane. Niektóre zapytania powinny przeszukiwać tylko archiwum artykułów, inne cały system wiedzy. Przykład:
- Pytanie badawcze może przeszukiwać tylko archiwum artykułów.
- Z drugiej strony, pytanie strategiczne może uwzględniać wszystkie kolekcje jednocześnie.
Takie struktury sprawiają, że większe systemy wiedzy są znacznie bardziej wydajne.
Aktualizacje automatyczne
Kolejnym przydatnym krokiem jest regularna aktualizacja systemu. W poprzednim przykładzie raz przetworzyliśmy eksport danych ChatGPT. W praktyce jednak stale tworzona jest nowa zawartość.
Nowe rozmowy, nowe notatki, nowe dokumenty - wszystkie te informacje mogą również stać się częścią archiwum wiedzy.
Warto więc pomyśleć o automatycznych aktualizacjach. Jednym z prostych rozwiązań jest regularne importowanie nowych danych. Na przykład:
- Przetwarzanie nowych danych czatu raz w tygodniu
- Automatycznie importuj nowe dokumenty
- Natychmiastowe dodawanie nowych artykułów do bazy danych
Z technicznego punktu widzenia jest to stosunkowo łatwe do wdrożenia. Mały skrypt może regularnie sprawdzać dostępność nowych plików i automatycznie je przetwarzać. Pozwala to na ciągły rozwój systemu wiedzy. Z biegiem czasu tworzone jest coraz obszerniejsze archiwum, które dokumentuje Twoje przemyślenia i projekty.
Integracja z własnymi aplikacjami
Do tej pory nasz system był używany za pomocą prostych skryptów Pythona. Jednak w dłuższej perspektywie system ten można również zintegrować z własnymi aplikacjami. Na przykład wielu programistów tworzy małe interfejsy internetowe, które pozwalają im bezpośrednio korzystać z wiedzy AI.
Zamiast uruchamiać skrypt, można po prostu wpisać pytanie w polu wejściowym. Ten sam proces działa w tle:
- Tworzenie osadzania
- Przeszukiwanie bazy danych
- Przesyłanie kontekstu do sztucznej inteligencji
- Generowanie odpowiedzi
Wynik pojawia się wtedy bezpośrednio w interfejsie użytkownika. Taka aplikacja może przybierać bardzo różne formy. Na przykład:
- osobista badawcza sztuczna inteligencja
- asystent wiedzy dla projektów
- wyszukiwarka pomysłów
- archiwum artykułów i notatek
Szczególnie ekscytujące staje się połączenie tych systemów z innymi narzędziami. Na przykład system redakcyjny może automatycznie uzyskiwać dostęp do archiwum wiedzy i wykorzystywać poprzednie artykuły jako podstawę do badań. Z kolei system notatek może automatycznie integrować nowe pomysły z bazą danych.
Innymi słowy, sztuczna inteligencja staje się częścią codziennego środowiska pracy. To jasno pokazuje, że nasz mały projekt wykracza daleko poza oryginalny eksport danych ChatGPT.
Nie stworzyliśmy tylko archiwum. Stworzyliśmy architekturę, którą można rozbudowywać w zależności od potrzeb. I właśnie w tym tkwi prawdziwa wartość takich systemów. Nie są one statyczne. Rosną wraz z wiedzą użytkownika.
Rozszerzona wersja rurociągu do pobrania
Poniższy skrypt jest rozszerzoną wersją potoku z artykułu. Jest on bardziej solidny i znacznie bliższy produktywnemu rozwiązaniu. Poprawione zostały trzy rzeczy:
- Wskaźnik postępuUżytkownik może w każdej chwili sprawdzić, ile tekstów zostało już przetworzonych.
- Import wsadowyOsadzenia są gromadzone i zapisywane w Qdrant w blokach, co jest znacznie szybsze niż importowanie pojedynczych elementów.
- Szybszy potok osadzaniaSkrypt działa w ustrukturyzowany sposób z przygotowanymi fragmentami i redukuje niepotrzebne wywołania.
Skrypt ten jest zatem szczególnie przydatny, jeśli eksport ChatGPT jest większy - na przykład kilka tysięcy rozmów. Typowy proces:
- Załaduj eksport ChatGPT
- Fragmenty tekstów
- Dzielenie tekstu na fragmenty
- Tworzenie osadzeń
- Import wsadowy do Qdrant
- Przeprowadzenie zapytania testowego
Ważne ustawienia w skrypcie
Niektóre wartości muszą zostać dostosowane przez użytkownika:
- EXPORT_PFAD
Ścieżka do najczęściej numerowanych plików conversations.json z eksportu ChatGPT. - COLLECTION_NAME
Nazwa kolekcji wektorowej bazy danych. - EMBED_MODEL
Model osadzania Ollama, np. nomic-embed-text lub mxbai-embed-large - ANSWER_MODEL
Model językowy dla zapytania testowego, np. llama, mistral lub gpt:oss - VECTOR_SIZE
Wymiar modelu osadzania.
nomic-embed-text → 768
mxbai-embed-large → 1024 - CHUNK_SIZE
Rozmiar sekcji tekstowych.
Zazwyczaj 300-600 słów. - BATCH_SIZE
Ile osadzeń jest zapisywanych w Qdrant w tym samym czasie.
Typowa wartość: 50-200.
Bądź na bieżąco - bez reklam
Jeśli chcesz być informowany o aktualizacjach tego skryptu lub nowych plikach do pobrania, możesz zasubskrybować mój comiesięczny biuletyn. Newsletter jest celowo odchudzony, całkowicie pozbawiony reklam i ukazuje się tylko raz w miesiącu. Znajdziesz w nim wybór najważniejszych nowych artykułów, praktyczne treści na temat sztucznej inteligencji, oprogramowania i cyfryzacji, a także informacje o zaktualizowanych skryptach lub nowych ofertach pobierania. Żadnego spamu, żadnych codziennych e-maili - tylko najistotniejsze treści w kompaktowej formie. Jeśli chcesz na bieżąco śledzić rozwój wydarzeń, newsletter to najprostszy sposób, by być na bieżąco.
Perspektywy dla części 3: Dopracowanie, analiza i optymalizacja wykorzystania danych
W trzeciej części serii idziemy o krok dalej i przyglądamy się temu, co faktycznie można uzyskać z utworzonej bazy wiedzy. Teraz, gdy dane ChatGPT zostały zapisane w Qdrant, skupiamy się na ich faktycznym wykorzystaniu. Przyglądamy się interfejsowi internetowemu Qdrant, analizujemy przechowywane dane i sprawdzamy, jak dobrze działa już wyszukiwanie semantyczne. Przyglądamy się również ważnym drobnym korektom: Jak należy wybierać chunking w zależności od przypadku użycia? W jaki sposób można optymalnie przenieść kontekst do lokalnego modelu językowego? I w jaki sposób można konkretnie poprawić jakość odpowiedzi? Trzecia część jest skierowana do wszystkich tych, którzy chcą wyciągnąć więcej z systemu i świadomie go dalej rozwijać.




Często zadawane pytania
- Jaki jest sens integracji eksportu danych ChatGPT z moją własną sztuczną inteligencją?
Największą zaletą jest możliwość wykorzystania własnych rozmów i myśli w dłuższej perspektywie. Wiele osób prowadzi intensywne rozmowy z systemami AI na temat projektów, pomysłów, analiz lub kwestii osobistych. Treści te zazwyczaj znikają w trakcie działania platformy. Jeśli jednak wyeksportujesz je i zintegrujesz z własną bazą wiedzy, staną się one osobistym archiwum. Lokalna sztuczna inteligencja może następnie uzyskać dostęp do tych treści, rozpoznawać korelacje i pomagać w nowych pytaniach. Zamiast zawsze zaczynać od zera, krok po kroku budujesz własne myślenie. - Czy nie jest to zbyt skomplikowane dla kogoś, kto nie jest programistą?
Na pierwszy rzut oka terminy takie jak zagnieżdżanie, wektorowe bazy danych czy systemy RAG wydają się skomplikowane. W praktyce jednak poszczególne kroki mają stosunkowo przejrzystą strukturę. Zasadniczo potrzebne są tylko trzy komponenty: lokalna sztuczna inteligencja (np. za pośrednictwem Ollama), wektorowa baza danych, taka jak Qdrant i mały skrypt Pythona, który przetwarza dane. Wiele kroków wykonywanych jest automatycznie. Po skonfigurowaniu system działa jak zwykła wyszukiwarka lub chatbot - z wyjątkiem tego, że działa z własną wiedzą. - Jakie dane faktycznie zawiera eksport ChatGPT?
Eksport ChatGPT zazwyczaj zawiera wszystkie rozmowy, które użytkownik przeprowadził z systemem. Obejmuje to nie tylko same wiadomości tekstowe, ale także metadane, takie jak tytuły konwersacji, znaczniki czasu i informacje strukturalne. Dane te są zwykle dostępne w formacie JSON, dzięki czemu można je stosunkowo łatwo przetwarzać za pomocą skryptów. W wielu przypadkach eksport obejmuje również pliki multimedialne lub językowe, jeśli były one używane w konwersacjach. Jednak to przede wszystkim zawartość tekstowa jest interesująca podczas tworzenia bazy wiedzy. - Dlaczego w takich systemach używana jest wektorowa baza danych, a nie zwykła baza danych?
Zwykłe bazy danych są idealne do wyszukiwania określonych terminów lub identyfikatorów. Są one jednak mniej odpowiednie do wyszukiwania semantycznego. Wektorowa baza danych przechowuje teksty nie tylko jako ciągi znaków, ale także jako wektory matematyczne, które opisują znaczenie tekstu. Pozwala to systemowi na wyszukiwanie podobieństw w treści. Na przykład, jeśli zapytasz o „pomysły na artykuły o sztucznej inteligencji“, baza danych może również znaleźć treści zawierające inne frazy, takie jak „tematy artykułów na blogu o sztucznej inteligencji“. - Czym są osadzenia i dlaczego są tak ważne?
Osadzenia są matematycznymi reprezentacjami tekstów. Model językowy konwertuje tekst na listę liczb, które opisują znaczenie tekstu. Teksty o podobnym znaczeniu leżą blisko siebie w przestrzeni matematycznej. Pozwala to wektorowej bazie danych na późniejsze wyszukiwanie podobnych treści. Bez osadzeń wyszukiwanie semantyczne byłoby prawie niemożliwe. Stanowią one podstawę nowoczesnych systemów RAG i są powodem, dla którego takie systemy są znacznie bardziej elastyczne niż klasyczne wyszukiwanie pełnotekstowe. - Jak duży może być mój eksport danych ChatGPT?
Rozmiar nie odgrywa większej roli. Bez problemu można przetworzyć nawet kilka tysięcy rozmów. Ważniejsza jest liczba wygenerowanych fragmentów tekstu, tzw. chunków. Większy eksport prowadzi do większej liczby fragmentów, a tym samym większej liczby osadzeń. Jednak nowoczesne wektorowe bazy danych mogą z łatwością zarządzać milionami takich wpisów. Dla prywatnego asystenta wiedzy, nawet mały serwer lub potężny komputer stacjonarny jest w zupełności wystarczający. - Dlaczego tekst jest podzielony na małe sekcje przed przetworzeniem?
W przypadku zapisywania pełnych konwersacji lub dużych tekstów bezpośrednio jako embeddings, wyszukiwanie semantyczne staje się nieprecyzyjne. Pojedynczy tekst może zawierać kilka tematów. Dzieląc go na mniejsze sekcje, system może później wyszukiwać znacznie precyzyjniej. Każda sekcja opisuje wyraźniejszy temat. Pozwala to bazie danych znaleźć dokładnie te części rozmowy, które naprawdę pasują do bieżącego pytania. - Jaką rolę odgrywa Ollama w tym systemie?
Ollama służy jako lokalna platforma dla modeli językowych. Umożliwia uruchamianie modeli AI bezpośrednio na własnym komputerze. W naszym systemie Ollama spełnia dwa zadania: Tworzy osadzenia dla tekstów i generuje odpowiedzi na pytania. Zaletą jest to, że wszystkie dane pozostają lokalne. Oznacza to, że Twoje rozmowy i archiwum wiedzy nigdy nie opuszczają Twojego komputera. - Dlaczego Qdrant jest używany jako wektorowa baza danych?
Qdrant to nowoczesna wektorowa baza danych, która została opracowana specjalnie dla aplikacji AI. Jest szybka, łatwa do installieren i bardzo dobrze udokumentowana. Można ją również łatwo podłączyć do Pythona i wielu frameworków AI. Qdrant jest zatem szczególnie praktycznym rozwiązaniem dla lokalnych systemów wiedzy. Alternatywy obejmują Chroma, Weaviate lub Pinecone. - Co oznacza termin system RAG?
RAG to skrót od „Retrieval-Augmented Generation“. Jest to architektura, w której sztuczna inteligencja najpierw pobiera odpowiednie informacje z bazy danych, a następnie wykorzystuje je do wygenerowania odpowiedzi. Sztuczna inteligencja łączy zatem własną wiedzę z danymi zewnętrznymi. Umożliwia to udzielanie bardzo precyzyjnych odpowiedzi, a jednocześnie dostęp do aktualnych lub osobistych informacji. - Czy mogę zintegrować inne źródła danych z tym systemem?
W rzeczywistości jest to jedna z największych zalet tej architektury. System nie ogranicza się do danych ChatGPT. Możesz również zintegrować własne artykuły, notatki, pliki PDF, prace badawcze lub inne dokumenty. Tak długo, jak treść może być przetwarzana w formie tekstowej, może stać się częścią bazy wiedzy. Z czasem system stanie się kompleksowym archiwum wiedzy. - Jak aktualny pozostaje taki system wiedzy?
Aktualność zależy od częstotliwości importowania nowych danych. Można na przykład regularnie przetwarzać nowe eksporty ChatGPT lub utworzyć skrypt, który automatycznie rozpoznaje nowe dokumenty. Wiele systemów jest skonfigurowanych do aktualizacji raz w tygodniu lub raz w miesiącu. Dzięki temu baza wiedzy jest zawsze aktualna. - Jakiego sprzętu potrzebuję do takiego systemu?
Do mniejszych projektów wystarczy nowoczesny komputer stacjonarny. Jeśli chcesz użyć większego modelu językowego, pomocny może być procesor graficzny. Jednak wielu użytkowników z powodzeniem uruchamia swoje systemy wiedzy na wydajnym laptopie lub mini-serwerze. Przede wszystkim ważne jest, aby mieć wystarczającą ilość pamięci i wystarczającą przestrzeń dyskową dla bazy danych. - Jak szybko taki system działa w praktyce?
Szybkość zależy od kilku czynników, na przykład rozmiaru bazy danych, sprzętu i używanego modelu językowego. W wielu przypadkach zapytanie zajmuje tylko kilka sekund. Samo wyszukiwanie wektorowe jest zazwyczaj bardzo szybkie. Największa część czasu jest często poświęcana na generowanie odpowiedzi z modelu językowego. - Czy możliwe jest rozdzielenie kilku obszarów wiedzy?
Tak, wektorowe bazy danych, takie jak Qdrant, umożliwiają korzystanie z wielu kolekcji. Każda kolekcja może reprezentować oddzielny obszar tematyczny. Na przykład można utworzyć kolekcję dla rozmów ChatGPT, jedną dla artykułów i jedną dla notatek. Pozwala to na przejrzyste uporządkowanie obszarów wiedzy i przeszukiwanie ich w ukierunkowany sposób. - Jak bezpieczne są moje dane w lokalnym systemie AI?
Dużą zaletą systemu lokalnego jest to, że dane nie muszą być przesyłane do usług zewnętrznych. Wszystkie informacje pozostają na własnym komputerze lub serwerze. Jest to szczególnie interesujące w przypadku wrażliwych treści. Oczywiście nadal należy tworzyć regularne kopie zapasowe i chronić system przed nieautoryzowanym dostępem. - Czy mogę zintegrować ten system z moimi własnymi aplikacjami?
Tak, do większości komponentów można uzyskać dostęp za pośrednictwem interfejsów programistycznych. Pozwala to zintegrować system wiedzy z własnymi narzędziami, na przykład z interfejsem internetowym, systemem redakcyjnym lub aplikacją do notatek. Wielu programistów tworzy małe aplikacje, które sprawiają, że ich baza wiedzy jest bezpośrednio dostępna za pośrednictwem interfejsu czatu. - Jak ta technologia może rozwinąć się w przyszłości?
Sztuczna inteligencja oparta na wiedzy osobistej jest prawdopodobnie dopiero na początku swojego rozwoju. W przyszłości takie systemy mogłyby automatycznie integrować nowe treści, tworzyć podsumowania, a nawet dostarczać własne sugestie dotyczące projektów. Im więcej danych wpływa do takiego systemu, tym bardziej staje się on wartościowy. W dłuższej perspektywie może on przekształcić się w rodzaj osobistej pamięci cyfrowej, która porządkuje wiedzę użytkownika i udostępnia ją w dowolnym momencie.



