Quiconque travaille aujourd'hui avec l'IA est presque automatiquement poussé vers le cloud : OpenAI, Microsoft, Google, des interfaces web quelconques, des jetons, des limites, des conditions générales. Cela semble moderne - mais c'est en fait un retour à la dépendance : d'autres déterminent quels modèles tu peux utiliser, à quelle fréquence, avec quels filtres et à quel coût. Je choisis délibérément l'autre voie : je suis en train de construire mon propre petit studio d'IA à la maison. Avec mon propre matériel, mes propres modèles et mes propres flux de travail.
Mon objectif est clair : IA de texte en local, IA d'image en local, apprentissage de mes propres modèles (LoRA, réglage fin) et tout cela de manière à ce que je ne dépende pas, en tant qu'indépendant et plus tard aussi en tant que client de PME, de l'humeur du jour d'un quelconque fournisseur de cloud. On pourrait dire qu'il s'agit d'un retour à une ancienne attitude qui était autrefois tout à fait normale : „Les choses importantes, on les fait soi-même“. Sauf que cette fois, il ne s'agit pas de son propre établi, mais de la puissance de calcul et de la souveraineté des données.




La vitesse reste imbattable localement
Les modèles de cloud computing sont impressionnants - tant que la ligne est en place, que les serveurs ne sont pas surchargés et que l'API n'est pas en train d'être à nouveau étranglée. Mais tous ceux qui travaillent sérieusement avec l'IA se rendent vite compte que la forme la plus honnête de vitesse est locale. Lorsqu'un modèle fonctionne sur son propre Mac Studio ou son propre GPU, c'est valable :
- Pas de latence du réseau
- Pas d'attente jusqu'à ce que „les autres“ aient fini
- Pas de pannes horaires
- Pas de „Rate limit reached“ au milieu du workflow
J'en fais l'expérience tous les jours : sur mon Mac Studio un modèle 120B (GPT-OSS) et, en parallèle, un modèle 27B Gemma - ainsi qu'un serveur FileMaker et toutes mes bases de données. Malgré cela, le système reste si réactif que je travaille à un rythme difficilement atteignable avec les systèmes cloud. C'est justement lorsque tu effectues de nombreuses petites opérations à la suite - traductions, reformulations, analyses, tampons d'images - que les retards s'accumulent rapidement. L'IA locale ne donne pas l'impression de „fonctionner comme un serveur“, mais comme un outil direct : tu appuies, ça se passe.
Souveraineté des données : quand les informations sensibles n'ont pas leur place sur le web
Un point que l'on a tendance à balayer du revers de la main, mais qui est crucial pour les entrepreneurs : les données. Dès que tu utilises l'IA en nuage, tu te poses inévitablement des questions :
- Est-ce que je peux y mettre des données clients ?
- Que se passe-t-il avec les documents internes ?
- Combien de temps les logs sont-ils conservés ?
- Qui a théoriquement accès - aujourd'hui et dans deux ans ?
- Quelles seraient les conséquences juridiques d'une fuite ?
Bien sûr, les grands fournisseurs ont des promesses de protection des données. Mais à la fin de la journée, tu donnes ton contenu. Et c'est précisément ce que l'on voulait éviter autrefois dans sa propre entreprise : L'interne restait interne. Dans un studio d'IA local, la situation est différente :
- Les données restent sur son propre réseau.
- Aucun requérant ne quitte la maison.
- Les modèles fonctionnent sans accès à Internet.
- Les logs, les données d'entraînement et les résultats intermédiaires se trouvent sur tes propres disques.
Si à l'avenir, je fais passer mes livres, articles, notes, textes RP, documents stratégiques internes ou données clients par mon IA, je veux être sûr que rien de tout cela ne finira dans un quelconque kit d'entraînement étranger. Je n'obtiendrai cette confiance que si l'infrastructure m'appartient.
Contrôle des coûts au lieu d'abonnements insidieux
Les IA en nuage semblent bon marché à première vue : quelques centimes par 1.000 tokens, un abonnement mensuel par-ci, un petit tarif par-là. Le problème, c'est que les coûts augmentent avec ton succès. Plus tu deviens productif, plus l'infrastructure coûte cher - et ce, chaque mois. L'IA locale fonctionne différemment :
- Tu investis une fois dans le matériel.
- Ensuite, les modèles fonctionnent autant et aussi souvent que tu le souhaites.
- Aucun „doigt de commande ne tremble“, car chaque appel coûte de l'argent.
- Tu peux expérimenter plus librement, sans avoir à calculer chaque entrée.
J'ai acheté ma RTX 3090 d'occasion pour environ 750 euros - pratiquement comme neuve. J'ai obtenu mon Mac Studio avec 128 Go de RAM pour environ 2 750 euros, dans son emballage d'origine et jamais ouvert. C'est de l'argent, oui - mais :
- Ces machines m'accompagneront pendant de nombreuses années.
- Ils génèrent des actifs directement exploitables : livres, articles, images, LoRAs, workflows.
- Ils n'entraînent pas de frais mensuels supplémentaires autres que l'électricité.
Pour un éditeur, un consultant, un développeur ou une petite entreprise, cela peut faire la différence entre „nous devons calculer si nous pouvons nous le permettre“ et „nous utilisons simplement l'IA lorsque nous en avons besoin“.
Anciennes vertus, nouvelle utilité : Pourquoi il vaut à nouveau la peine d'avoir ses propres machines
Autrefois, il allait de soi qu'un artisan devait disposer de bons outils dans sa propre entreprise. Un atelier de menuiserie sans rabot et sans scies dignes de ce nom aurait été impensable. Aujourd'hui, nous nous sommes habitués à l'inverse : au lieu de posséder nos propres machines, nous louons des services. Un propre studio d'IA n'est en fait rien d'autre qu'une variante moderne de l'atelier classique :
- Le site Mac Studio est le moteur central des modèles linguistiques.
- Le site Carte graphique RTX est la fraiseuse pour les images et les formations.
- Un ordinateur supplémentaire (par ex. Mac mini) prend en charge des tâches spéciales comme la voix ou les petits modèles.
- Un logiciel comme FileMaker sert de pupitre de commande : il orchestre, enregistre, documente.
C'est exactement le genre d'installation que je suis en train de mettre en place, car je veux pouvoir tout faire moi-même à long terme :
- Écrire et traduire des livres,
- Générer des séries d'images,
- s'entraîner à utiliser ses propres modèles LoRA,
- Automatiser les flux de travail,
- et, plus tard, proposer des solutions clients pouvant fonctionner entièrement en local.
Ce n'est pas de la nostalgie, c'est une décision sobre : plus l'IA s'immisce dans la vie quotidienne, plus il est judicieux de garder le contrôle de la technique. L'IA locale n'est pas l'alternative „bricolée“ au cloud chic, mais un retour conscient à l'autonomie :
- Tu gagnes en vitesse.
- Tu conserves tes données.
- Tu contrôles tes coûts.
- Tu construis une infrastructure qui t'appartient.
Si l'on va jusqu'au bout de la logique, un studio d'IA à domicile ressemble de plus en plus à un atelier classique bien équipé : On ne se fie pas à ce que les autres font quelque part en arrière-plan, mais on se construit une base propre et stable.
Dernière enquête sur les systèmes d'IA locaux
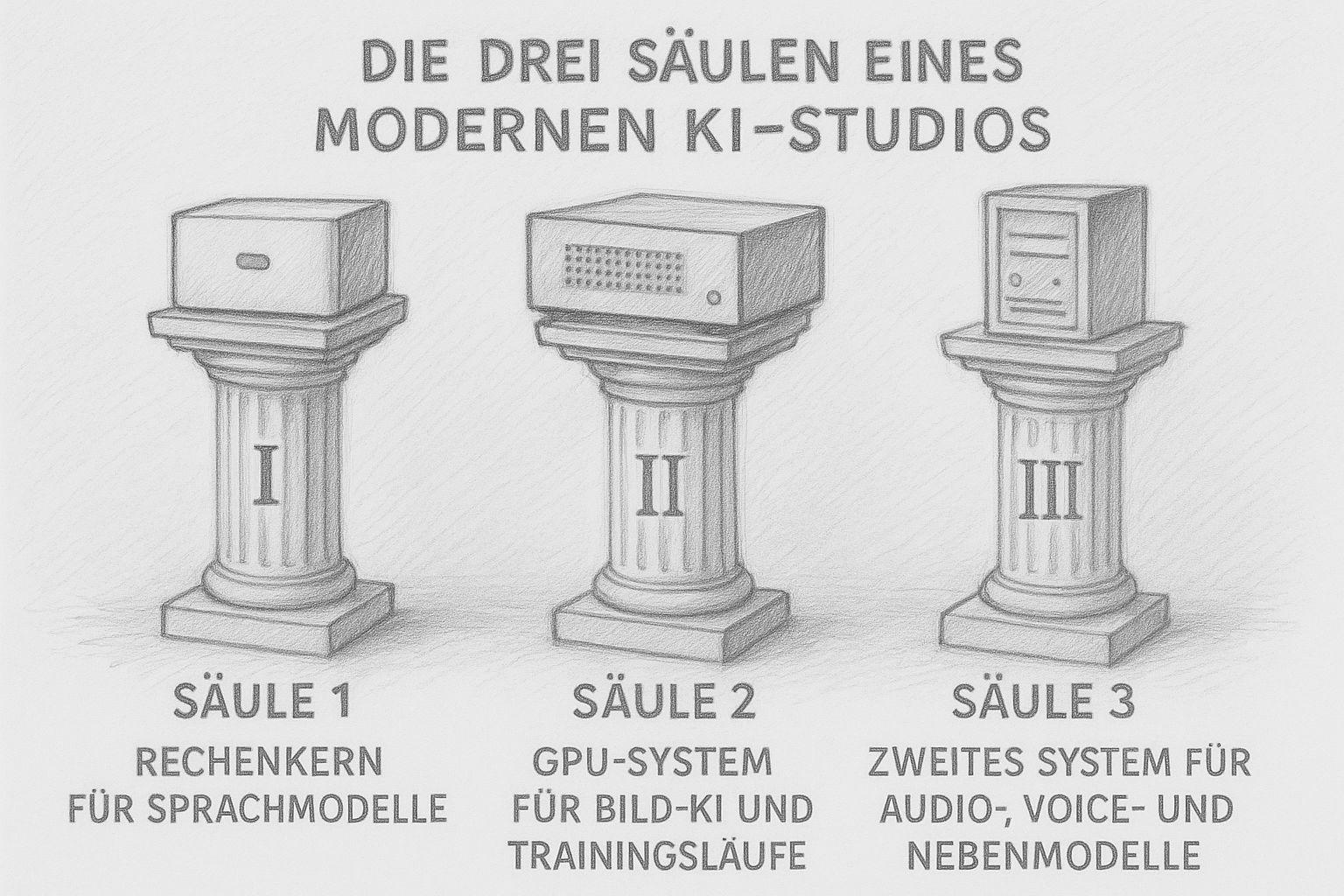
Les trois piliers d'un studio d'IA moderne
Aujourd'hui, un studio d'IA n'est plus constitué d'un seul gros ordinateur qui fait tout. Les flux de travail modernes ont besoin de différentes forces : une puissance de calcul pour les textes, beaucoup de VRAM pour les images et les cycles d'entraînement, et à côté de cela, de petits systèmes qui se chargent des tâches secondaires. Le résultat n'est pas un parc d'appareils chaotique, mais une petite infrastructure bien pensée - comme autrefois une entreprise artisanale bien équipée, dans laquelle chaque machine remplit sa fonction.
Je construis moi-même mon studio selon ce principe. Et plus j'approfondis le sujet, plus il devient clair : Trois piliers suffisent pour gérer localement une production complète d'IA.
Pilier 1 : le noyau de calcul pour les modèles linguistiques (LLM)
Pour les grands modèles linguistiques, on n'a plus besoin aujourd'hui d'un serveur de centre de calcul, mais surtout d'une chose : beaucoup de mémoire vive, très rapide. C'est exactement ce que font les systèmes modernes Apple-Silicon ou les machines Linux équipées de manière comparable et disposant de beaucoup de RAM. Le noyau de calcul est le cœur du studio. C'est ici que fonctionnent
- Grands LLM (20B, 30B, 70B, 120B MoE ...)
- Modèles d'analyse
- Modèles de traduction
- Interne Systèmes de connaissances (neo4j, RAG)
- à long terme, un Mémoire assistée par IA
- Systèmes de contrôle comme par exemple n8n
- FileMaker-Automatisations et processus de serveur
Dans ma configuration, c'est le Mac Studio M1 Ultra avec 128 Go de RAM qui joue ce rôle. Et il le fait de manière étonnamment souveraine. Je l'utilise :
- GPT-OSS 120B MoE (pour une réflexion profonde, des textes longs et des analyses)
- Gemma-3 27B (pour le travail technique comme les trucs FileMaker, le code, la structuration précise)
- FileMaker Serveur + bases de données
- plus toute l'infrastructure du shell et du serveur web
Le plus incroyable, c'est que même avec deux grands modèles en même temps, 10 à 15 Go de RAM restent disponibles. C'est l'avantage d'une architecture entièrement conçue pour la mémoire unifiée. Si l'on veut aller à l'essentiel : le noyau de calcul est le cerveau du studio d'IA. Tout ce qui comprend, génère ou transforme les textes se passe ici.
Pilier 2 : le système GPU pour l'IA d'image et les courses d'entraînement
Le deuxième pilier est une station de travail GPU, optimisée pour Stable Diffusion, ComfyUI, ControlNet et l'entraînement LoRA. Alors que les modèles de texte ont surtout besoin de RAM, l'IA d'image a besoin de VRAM. Et en grande quantité. Pourquoi ? Parce que les modèles d'images déversent des quantités gigantesques de données dans la mémoire à chaque image. Et c'est pour cela que les cartes graphiques sont conçues. Dans mon studio, c'est une NVIDIA RTX 3090 avec 24 Go de VRAM qui s'en charge - et ces 24 Go valent de l'or. Ils permettent :
- SDXL avec une taille de lot raisonnable
- Flux de travail ComfyUI
- Synthèse vidéo
- Séries d'images
- Entraînement au matériel et au style
- Entraînement LoRA avec 896×896 ou même 1024×1024
Pour l'IA d'image, la VRAM est plus importante que la toute dernière puce. Une solide 3090 peut aujourd'hui faire plus que les cartes milieu de gamme coûteuses de 2025. La colonne GPU est donc „l'équipement lourd“ du studio - la fraiseuse qui scie tout ce qui représente une charge de calcul. Sans elle, une production d'images sérieuse n'est guère possible.
Pilier 3 : un deuxième système pour l'audio, la voix & les modèles secondaires
Le troisième pilier peut paraître anodin, mais il est crucial : un système plus petit, efficace sur le plan énergétique, qui effectue des tâches secondaires. En font partie
- TTS (Text-to-Speech)
- STT (transcription)
- petits modèles (4B, 7B, 8B, 14B)
- statique Processus d'arrière-plan
- petit Systèmes d'agents
- Outils, les systèmes que l'on souhaite exploiter séparément du système principal
Chez moi, c'est un petit Mac mini M4 avec 32 Go de RAM qui s'en charge. Parfaitement adapté pour :
- Whisper-transcription
- Voix-modèles
- léger Modèles d'optimisation
- à réaction rapide Assistants
- Expériences et Essais
- parallèle Conteneur de modèles
Cela allège énormément la charge du système principal. En effet, il est judicieux de ne pas solliciter les grands modèles pour chaque petit travail. Tout comme autrefois, dans l'atelier, on ne mettait pas en marche la grande scie circulaire pour chaque coupe, mais on utilisait une petite machine. Le troisième pilier assure l'ordre et la stabilité.
Elle sépare les grands modèles des petites tâches - ce qui rend l'ensemble du studio durable, flexible et à l'épreuve des pannes.
Répartition intelligente des charges de travail
Un studio d'IA vit du fait que chaque machine fait ce pour quoi elle a été construite. Il en résulte un ordre logique :
- Noyau de calcul → penser, écrire, traduire, analyser
- Système GPU → images, modèles de formation, ComfyUI, vidéo
- Système secondaire → audio, voix, petits modèles, agents
Si l'on y ajoute un logiciel supplémentaire - comme FileMaker dans mon cas en tant que commande centrale - on obtient un véritable pipeline de production. Ce n'est plus le chaos, ce n'est plus „voir où il y a encore de la place“, mais un système ordonné qui fonctionne de manière stable chaque jour.
Les trois piliers sont la base - pas le programme libre
Nombreux sont ceux qui pensent que l'on n'a besoin d'un studio d'IA qu'une fois que l'on est devenu une „entreprise d'IA“. En réalité, c'est l'inverse : un studio d'IA solide EST la base pour en devenir un. Avec ces trois piliers, tu as tout ce dont tu as besoin pour :
- produire du contenu (texte & image)
- apprendre ses propres modèles
- automatiser les flux de travail
- travailler indépendamment du cloud
- mettre en place des solutions propres pour les clients
- exploiter des „workbenches“ numériques à long terme
Pour les entrepreneurs, les créateurs, les auto-éditeurs et les développeurs, il s'agit aujourd'hui d'une décision stratégique qui garantit la liberté, la vitesse et le contrôle à long terme.
Du matériel d'entrée de gamme judicieux pour un petit studio d'IA
En suivant les publicités d'aujourd'hui, on pourrait croire qu'il faut constamment acheter le tout dernier matériel pour pouvoir travailler localement avec l'IA. Mais c'est souvent le contraire : ce ne sont pas les derniers modèles qui sont décisifs, mais la bonne combinaison de RAM, VRAM et stabilité. De nombreux appareils plus anciens - surtout dans le domaine des GPU - sont aujourd'hui de véritables monstres en termes de rapport qualité-prix. Et si l'on est prêt à voir plus loin que le bout de son nez, on peut créer un studio d'IA digne d'une petite entreprise sans se ruiner. C'est exactement ce que je fais moi-même en ce moment, et cela fonctionne étonnamment bien. Ce chapitre te présente trois classes de matériel : Débutant, Standard et Professionnel. Et bien sûr, j'explique aussi pourquoi certains systèmes plus anciens ont aujourd'hui plus de valeur qu'on ne le pense.
1. entrée de gamme (1500-2500 €)
Pour tous ceux qui veulent démarrer localement - sans gros investissements. Dans cette classe, il s'agit de faire des premiers pas solides :
- Mac mini M2 ou M4 avec 16-32 Go de RAM
- ou un PC avec RTX 3060/3070 (12-16 GB VRAM)
- plus, en option, une petite NAS ou externe SSD
Cela permet de bien :
- Faire fonctionner les modèles 7B à 14B
- effectuer des traductions locales
- Lancer Whisper
- utiliser des modèles d'image plus petits comme SD 1.5/2.1
- Essayer ComfyUI sous forme réduite
- tester ses propres agents ou workflows
Pour beaucoup de créatifs ou d'indépendants, c'est plus que suffisant pour être productif. L'important est de ne pas trop compliquer le démarrage. Le plus grand danger n'est pas d'avoir trop peu de puissance - mais de se perdre dans trop de détails techniques. Avec un Mac mini M4, par exemple, on peut faire énormément de choses : Traduction, recherche, structure, même des modèles d'écriture plus petits - et tout cela avec une consommation d'énergie minimale.
2. classe standard (2500-4000 €)
Le sweet spot pour un travail sérieux avec des textes et des images. C'est ici que commence ce que j'appellerais un “vrai studio d'IA“ : une configuration capable de gérer à la fois de grands modèles de texte et de solides modèles d'image. Une combinaison typique :
- Mac Studio M1 Ultra ou M2 Max avec 64 Go de RAM
- Station de travail PC/GPU avec RTX 3080, 3090 ou 3090 Ti
- en option, un petit ordinateur supplémentaire pour l'audio ou la voix
Cette classe permet de
- Conduire des modèles 20-40B de manière fiable
- Utiliser Stable Diffusion XL de bonne qualité
- Effectuer un entraînement LoRA dans la zone d'enregistrement moyenne
- répartir les charges de travail parallèles sur plusieurs appareils
- Mettre en place des automatisations (par exemple via FileMaker)
Et c'est là que l'on découvre une vérité intéressante : les anciens GPU comme la RTX 3090 continuent d'écraser de nombreuses nouvelles cartes de milieu de gamme. Pourquoi ? Elles ont plus de VRAM (24 Go), alors que les nouvelles cartes ont souvent été castrées. Elles possèdent une large interface mémoire, idéale pour les modèles à large diffusion. Elles ont des pilotes CUDA matures et stables. Elles sont souvent vendues d'occasion à des prix étonnants. Une 3090 peut être plus performante pour 700-900 € d'occasion qu'une 4070 ou 4070 Ti actuelle pour 1100 € - tout simplement parce que la VRAM et la connexion mémoire sont plus importantes que quelques pourcents de puissance brute.
3. classe professionnelle (4000-8000 €)
Pour tous ceux qui produisent sérieusement - et qui aspirent à une indépendance totale. Dans cette catégorie, une véritable puissance de production est disponible. Configuration typique :
- Mac Studio M1 / M2 / M3 Ultra avec 128 Go de RAM ou plus
- Système PC-GPU avec RTX 3090 ou 4090
- un deuxième ordinateur pour audio/agents
- en option, 1 serveur TP9T comme centrale d'automatisation
Cela permet :
- Utiliser les modèles 70B de manière fluide
- Faire fonctionner de manière stable les modèles MoE comme le GPT-OSS 120B
- coordonner des agents IA parallèles
- Faire fonctionner SDXL, Video-KI, ComfyUI à plein régime
- Conduire des entraînements LoRA en 896×896 ou 1024×1024
- préparer ses propres bases de données pour les formations
- reproduire des pipelines complets (prompts → images → PDF → livres)
Et c'est là que l'on voit le plus passionnant : le meilleur matériel d'IA en 2025 est souvent du matériel haut de gamme d'occasion des années 2020-2022. Pourquoi ? Il était alors conçu pour des charges de travail haut de gamme. Son prix est aujourd'hui une fraction de celui d'avant. La technologie est arrivée à maturité. Pas de problèmes de pilotes bêta. Elle possède exactement les caractéristiques dont l'IA a besoin : beaucoup de VRAM, des bus mémoire larges, des cœurs Tensor stables.
Pourquoi on échoue avec trop peu de VRAM - et non avec trop peu de puissance GPU
C'est un point que beaucoup sous-estiment : La VRAM est le facteur décisif pour l'IA d'image, et non la performance pure. Exemples :
- Une RTX 4060 (8 Go VRAM) est pratiquement inutilisable pour SDXL.
- Une RTX 4070 Ti (12 Go de VRAM) ne suffit pas de manière fiable pour l'entraînement.
- Une RTX 3090 (24 Go VRAM) fonctionne en revanche de manière souveraine pendant des années.
En bref, les grands modèles ont besoin de mémoire - pas de marketing. Et la mémoire est ce que les anciennes cartes haut de gamme ont et que les nouvelles cartes de milieu de gamme n'ont pas.
Comment développer un studio d'IA de façon modulaire
Le principal avantage d'un studio en trois colonnes est la modularité :
- On peut mettre à niveau la station de travail GPU de manière indépendante.
- On peut garder son Mac Studio pendant des années.
- On peut changer d'ordinateur secondaire sans perturber le système.
- On peut étendre les disques durs ou les SSD séparément.
- On peut utiliser FileMaker, Python ou Bash comme orchestration.
C'est comme dans un atelier : On ne transforme pas tout en même temps, mais seulement ce qui est nécessaire à un moment donné.

L'IA locale est maintenant VRAIMENT utilisable (et elle fonctionne sur ce matériel) | c't 3003
Recommandations pour 2025 - Ce matériel en vaut vraiment la peine
Dans la jungle des publicités et des spécifications, il est facile de se perdre. Mais pour l'utilisation de l'IA à domicile ou dans un petit studio, il existe des classes de matériel qui seront particulièrement utiles en 2025 - parce qu'elles offrent un bon rapport qualité-prix, sont robustes et suffisent pour les modèles actuels. Ce qui compte aujourd'hui :
- Suffisamment de VRAM (pour les tâches GPU)Pour l'IA d'image, les courses d'entraînement, la diffusion stable et autres, une carte graphique devrait avoir au moins 16 Go, de préférence 24 Go de VRAM. À partir de ce seuil, l'IA visuelle devient confortable et stable.
- Bonne mémoire de travail et capacité de RAM (pour les LLM) : Pour les LLM de grande taille, le multitâche avec les services du serveur et les processus parallèles, il est judicieux d'avoir le plus de RAM possible - idéalement 64-128 Go pour le Apple-Silicon.
- Du matériel stable et éprouvé plutôt que du matériel de marketing dernier cri: Les anciennes cartes haut de gamme en particulier ont souvent d'excellentes spécifications (VRAM, bus mémoire, maturité des pilotes) pour un prix modéré.
- Modularité et mélange plutôt que monobloc: la combinaison d'un ordinateur LLM, d'une station de travail GPU et d'un système auxiliaire/agent est plus flexible et plus durable qu'une seule machine „tout-en-un“.
| Classe | Composants typiques | Convient à qui | Points forts / Compromis |
|---|---|---|---|
| Entrée de gamme (environ 1 500-2 500 €) | Mac mini (16-32 Go de RAM) ou PC avec GPU (par ex. RTX 3060 / 3060 Ti / 4060 Ti avec ≥ 12-16 Go de VRAM) | Hobby, premières expériences, petits modèles, IA d'image gérable | Entrée de gamme avantageuse, suffisante pour les petits LLM, les workflows à diffusion stable légers et l'IA audio/texte. Limitations pour les grands modèles, les pipelines ComfyUI complexes et l'apprentissage de la LoRA. |
| Standard (environ 2 500-4 000 €) | Station de travail GPU de milieu de gamme (p. ex. avec RTX 3080 ou RTX 3090), ordinateur avec 64 Go de RAM | Créatifs, auto-éditeurs, utilisateurs d'IA ambitieux, petites équipes | Performance solide pour les textes & images, bon rapport qualité/prix. Assez de VRAM et de RAM pour une utilisation polyvalente de l'IA, y compris SDXL et les premiers entraînements LoRA. Pour les projets extrêmes ou les nombreux flux de travail parallèles, le système atteint un jour ses limites. |
| Professionnel / Studio (env. 4.000-8.000 €) | Système à haute RAM (par ex. Mac Studio avec 128 Go de RAM ou station de travail Linux puissante) + GPU avec ≥ 24 Go de VRAM (par ex. RTX 3090, 4090) + système secondaire/agent séparé | Indépendants, maisons d'édition, productions médiatiques, développeurs avec plusieurs projets, petits studios d'IA | Flexibilité maximale, grands modèles (70B, MoE), IA d'images et de textes en parallèle, automatisations et workflows à long terme. Très sûr pour l'avenir, mais investissement initial plus élevé et un peu plus de planification lors de la mise en place. |
Pourquoi les GPU haut de gamme d'occasion et anciens sont souvent meilleurs que les cartes neuves de milieu de gamme aujourd'hui
De nombreuses cartes récentes sont proposées avec une VRAM limitée - pourtant essentielle pour l'IA. Les anciens modèles haut de gamme comme la RTX 3090 apportent souvent 24 Go de VRAM, ce qui est aujourd'hui très précieux pour le SDXL, l'entraînement LoRA ou l'IA vidéo. Le matériel était à l'origine conçu pour la performance et la stabilité - avec des composants de haute qualité, un bus mémoire, un système de refroidissement et un bon support des pilotes.
Cela signifie que la longévité et les performances robustes sont souvent au rendez-vous. Les cartes d'occasion sont souvent nettement moins chères et donc très performantes en termes de prix - idéal pour les indépendants ou les petits studios avec un budget limité.
Ma recommandation actuelle 2025 (et pourquoi)
Si je construisais un studio aujourd'hui et que je ne visais pas une puissance maximale de supercalculateur, je déciderais :
- Pour l'IA d'image: au moins un GPU avec 24 Go de VRAM - par ex. RTX 3090 ou 4090.
- Pour le texte/LLM: 128 Go de RAM dans un système performant Apple-Silicon.
- Pour les petits boulots (audio, voix, petits modèles, automatisation) : un petit ordinateur séparé (par exemple un mini-PC ou un serveur bon marché).
- Pour la coordination: une couche logicielle - pour moi, c'est FileMaker, pour d'autres, cela pourrait être un simple shell ou un pipeline Python.
Cette configuration n'est pas exagérée, ne dépend pas de licences cloud coûteuses - et suffit pour presque tout ce que l'on peut faire avec l'IA en 2025 dans le domaine de la création, de l'édition ou du développement.
Le matériel pour l'IA ne doit pas être nouveau, mais adapté
Aujourd'hui, l'époque où l„“IA" était réservée aux grandes entreprises ou aux laboratoires de cloud computing prend fin. En 2025, presque tout le monde peut - avec un budget raisonnable et un peu de compréhension technique - créer son propre petit studio d'IA. Cela te rend indépendant des abonnements mensuels coûteux, des conditions de protection des données étrangères, des files d'attente, des goulots d'étranglement des serveurs et de l'incertitude quant à la durée d'existence des services cloud. Au lieu de cela, tu obtiens
- contrôle total sur tes données et tes flux de travail,
- stable, rapide et performance évolutive,
- un investissement durable, La qualité de l'eau est un élément essentiel de la vie, qui dure des années,
- et les Liberté, La liberté d'être créatif quand et comme tu le souhaites, sans limites externes.
Donc : si tu envisages d'utiliser l'IA pour tes livres, tes textes, tes images ou tes projets - il vaut plus que jamais la peine de créer ton propre studio. Pas besoin d'être ingénieur en matériel. Pas besoin d'un budget énorme. Il n'est pas nécessaire d'avoir du matériel dernier cri.
Il faut avant tout avoir une idée claire de l'objectif avec lequel on travaille - et la volonté de garder le contrôle sur ses propres processus.
Comment créer un LLM local sur un Mac 1TP12 avec Ollama, je le montre dans cet article.
Tu trouveras ici une comparaison de Apple MLX sur Silicon vs. NVIDIA.
Comment utiliser Qdrant une mémoire locale pour ton IA locale se trouve ici.



Foire aux questions
- Pourquoi cela vaut-il la peine de posséder son propre studio d'IA alors qu'il existe tant de fournisseurs de cloud ?
Un propre studio d'IA te rend plus indépendant, plus stable et moins cher à long terme. Les services cloud sont pratiques, mais ils coûtent de l'argent chaque mois, créent une dépendance et sont souvent limités par des restrictions d'utilisation. L'IA locale est rapide, disponible en permanence et peut être utilisée sans frais variables. De plus, toutes les données restent en interne - un avantage énorme pour les indépendants, les entreprises, les maisons d'édition ou les professions créatives. - De quel matériel informatique ai-je besoin au minimum pour commencer à utiliser l'IA en local ?
Pour commencer, un Mac mini avec 16-32 Go de RAM ou un PC avec un GPU d'au moins 12 Go de VRAM suffit déjà. Tu peux ainsi exécuter de petits modèles vocaux, des modèles d'images légers et des premières automations. Pour ceux qui veulent seulement essayer, il n'est pas nécessaire d'investir plusieurs milliers d'euros. - Ai-je obligatoirement besoin d'un Mac Studio ou puis-je trouver moins cher ?
Il y a certainement moins cher. Un Mac Studio vaut la peine si tu veux exploiter de grands modèles de voix (20-120B), si tu travailles beaucoup en parallèle ou si tu as des processus de production à long terme. Pour les premiers pas, un Mac mini ou un PC Windows solide est largement suffisant. Un studio est un investissement de confort et d'avenir - mais pas une obligation. - Pourquoi la VRAM est-elle plus importante pour l'IA d'image qu'une génération moderne de cartes graphiques ?
Parce que les modèles d'image comme la diffusion stable font passer d'énormes quantités de données à travers la mémoire. Si la VRAM n'est pas suffisante, le processus s'arrête ou devient extrêmement lent. Une carte plus ancienne comme la RTX 3090 avec 24 Go de VRAM bat souvent les nouveaux modèles de milieu de gamme avec seulement 8-12 Go de VRAM - simplement parce qu'elle offre plus d'espace pour les grands modèles et les exécutions d'entraînement. - Puis-je faire fonctionner un studio d'IA complet avec du matériel Apple sans NVIDIA ?
Pour les modèles vocaux, oui. Pour l'IA d'image, non. Apple-Silicon est extrêmement efficace pour les LLM, mais pour la diffusion stable, l'apprentissage LoRA et de nombreux modèles d'image, les cartes NVIDIA restent la référence (à cause des cœurs CUDA/Tensor). C'est pourquoi de nombreux studios utilisent un mélange de Apple/LLM et de Linux+NVIDIA pour les images. - Une RTX 4080 ou 4070 Ti est-elle également suffisante pour l'IA d'image ?
En théorie, oui - en pratique, cela dépend de l'utilisation. Pour de simples images ou de petits workflows, cela suffit. Mais pour SDXL, les pipelines ComfyUI complexes ou l'entraînement LoRA, la limite des 12-16 Go de VRAM se heurte rapidement à ses limites. Une RTX 3090 ou 4090 est donc plus judicieuse à long terme. - Pourquoi n'exploite-t-on pas les modèles linguistiques sur le GPU, mais sur la RAM ?
Les modèles de langage sont orientés vers la mémoire. Ils doivent conserver de grandes quantités de texte et de contexte en mémoire vive, pas nécessairement effectuer des opérations graphiques. Les GPU sont conçus pour le traitement d'images, pas pour l'analyse de texte. C'est pourquoi les systèmes LLM bénéficient énormément de beaucoup de RAM, mais moins de VRAM. - De quelle quantité de RAM un ordinateur LLM doit-il disposer ?
Pour les petits modèles, 32-64 Go suffisent. Pour les modèles moyens (20-30B), 64-128 Go sont idéaux. Pour les grands modèles comme le 70B ou les modèles MoE comme le GPT-OSS 120B, 128-192 Go de RAM sont optimaux. Plus la RAM est importante, plus tout fonctionne de manière stable et rapide. - Peut-on faire fonctionner un studio d'IA entièrement sans Linux ?
Oui - mais avec des restrictions. macOS est parfait pour les LLM, mais pour l'IA d'image, il manque certains outils qui n'existent que sous Linux/NVIDIA. Windows fonctionne bien pour l'IA d'image, mais il est moins stable et plus difficile à automatiser. Le mélange pragmatique est donc souvent le suivant : macOS → LLM, Linux → IA image, petit ordinateur → audio/scripts - Quel est le niveau sonore d'un tel studio d'IA en fonctionnement ?
Moins qu'on ne le pense. Un Mac Studio fonctionne pratiquement sans bruit. Un PC Linux dépend du système de refroidissement - les GPU de haute qualité sont silencieux à faible charge, mais peuvent devenir audibles lors des sessions d'entraînement. Ceux qui préfèrent les builds silencieux peuvent utiliser des stations de travail GPU refroidies par eau. - Quel est le rôle du Mac mini en tant que troisième élément ?
Il sert de poste secondaire pour la transcription, la TTS, les petits modèles d'IA, les processus d'arrière-plan, les automatismes ainsi que les tâches secondaires de traduction. Cela permet de garder les deux grosses machines libres et d'assurer des flux de travail stables. Un troisième ordinateur n'est pas indispensable, mais il permet de mettre de l'ordre et de la fiabilité. - Puis-je développer mon studio d'IA au fur et à mesure ?
Absolument, c'est sûr. C'est même le cas idéal. Acheter un système LLM, ajouter ensuite une station de travail GPU et, plus tard, un petit ordinateur secondaire - c'est une construction très naturelle qui peut s'étaler sur des mois ou des années. Les studios d'IA se développent tout autant que les ateliers classiques. - Quels sont les systèmes d'exploitation les mieux adaptés à un studio d'IA ?
- macOS → optimal pour les modèles LLM et Apple-Silicon
- Linux (Ubuntu, Debian) → meilleur choix pour l'IA d'image, ComfyUI, Stable Diffusion
- Windows → fonctionne bien pour SD/ComfyUI, mais moins idéal pour les processus d'automatisation
De nombreux studios utilisent aujourd'hui des configurations combinées - chaque système fait ce pour quoi il est le mieux adapté. - Quelle est la consommation d'électricité d'un studio d'IA ?
Un Mac Studio est étonnamment efficace et se situe généralement entre 50 et 100 W. Une station de travail GPU avec RTX 3090 peut tirer 250-350 W, selon la charge. Un Mac mini se situe aux alentours de 10-30 W. Au total, c'est donc bien moins que ce que l'on pourrait craindre - et souvent moins cher que les abonnements au cloud. - Est-il difficile de mettre en place soi-même un studio d'IA ?
Pas vraiment. Il faut un peu de compréhension technique, mais pas d'études d'informatique. De nombreux outils ont aujourd'hui des interfaces web, des scripts d'installation et des configurations automatiques. Et si l'on sépare clairement les systèmes (LLM / GPU / emplois secondaires), tout reste clair. - Est-ce que je peux vraiment couvrir des processus de publication complets avec cette solution ?
Oui, et c'est précisément pour cela qu'un studio d'IA est idéal. Des idées de livres aux textes, des projets de couverture aux séries d'images, des corrections aux traductions jusqu'au fichier final d'impression ou de livre électronique, beaucoup de choses peuvent être automatisées et produites en interne. Pour les auto-éditeurs, c'est une énorme liberté. - Quelle est la pérennité d'un studio d'IA aujourd'hui ?
Très . Les LLM deviennent plus efficaces, les modèles d'image plus modulaires, le matériel plus durable - et l'IA locale reprend de l'importance sur le marché, car les lois sur le cloud, la protection des données et les coûts rendent le cloud moins attractif. Investir aujourd'hui dans un petit studio d'IA, c'est construire une infrastructure qui aura tendance à devenir plus importante plutôt qu'obsolète en 2026-2030. - Est-il possible d'entraîner ou d'étendre les modèles d'IA par la suite ?
Oui. Avec un système GPU (par ex. RTX 3090 ou 4090), il est possible de réaliser des entraînements LoRA, des entraînements de style, des entraînements de matériel et des entraînements de processus. Cela signifie qu'il est possible de se former au fil du temps à son propre „langage visuel IA“ ou à sa propre „direction de texte IA“. C'est le plus grand avantage stratégique d'un studio d'IA : tu deviens indépendant des modèles génériques et tu crées ton propre style.