Hafızalı yerel yapay zeka - bulut olmadan, abonelik olmadan, saptırma olmadan
Bir önceki makaleler Mac install üzerinde Ollama'nin nasıl yapılandırılacağını anlattım. Bu adımı zaten tamamladıysanız, artık Mistral, LLaMA3 veya REST API aracılığıyla adreslenebilen başka bir uyumlu model gibi güçlü bir yerel dil modeline sahipsiniz demektir.
Ancak, model yalnızca mevcut istemde ne olduğunu "bilir". Önceki konuşmaları hatırlamaz. Eksik olan şey bir hafıza.




Modern bir semantik vektör veritabanı olan Qdrant'ı kullanmamızın nedeni de tam olarak budur.
Bu yazıda size adım adım göstereceğim:
- Mac'te installier Qdrant nasıl kullanılır (Docker aracılığıyla)
- Python ile katıştırmalar nasıl oluşturulur
- içeriğin nasıl kaydedileceği, aranacağı ve Ollama iş akışına nasıl entegre edileceği
- ve tam bir istem→bellek→yanıt dizisinin neye benzediğini
Neden Qdrant?
Qdrant geleneksel metinleri değil, bir metnin anlamını sayısal bir kod olarak temsil eden vektörleri depolar. Bu, içeriğin yalnızca tam olarak değil, aynı zamanda anlamsal olarak da benzer şekilde bulunabileceği anlamına gelir - kelimeler değişse bile.
Ollama + Qdrant bu nedenle sonuçlanır:
Uzun süreli belleğe sahip yerel bir dil modeli - güvenli, kontrol edilebilir ve genişletilebilir.
Ön Koşullar
- Ollama, installiert'tir ve çalışır (→ örn. ollama run mistral)
- Docker installiert: https://www.docker.com/products/docker-desktop
- Python 3.9+
Qdrant'tan Paketinstallation:
pip install qdrant-client sentence-transformers
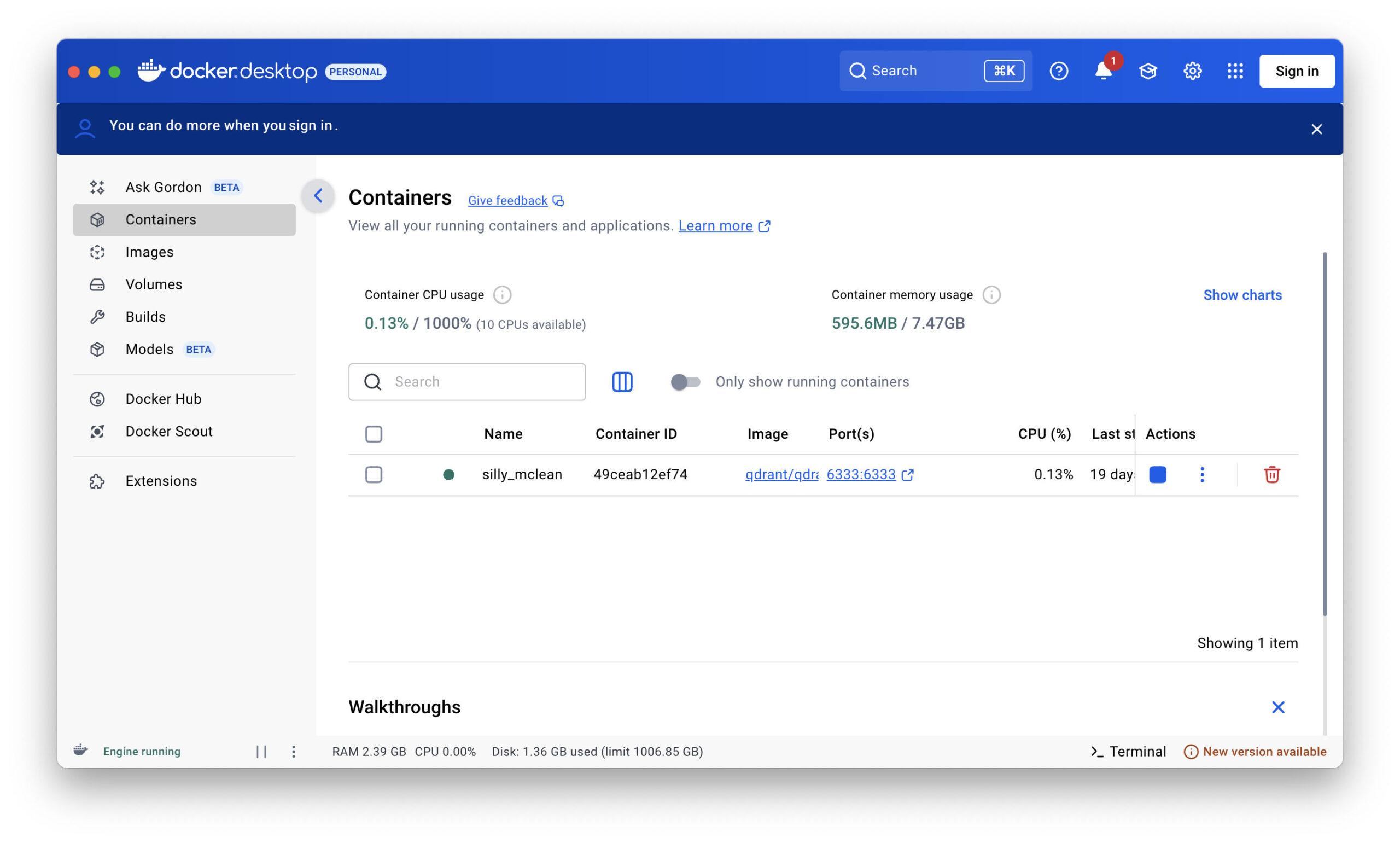
Qdrant'ı başlatın (Docker)
docker run -p 6333:6333 -p 6334:6334 qdrant/qdrant
Qdrant sonra koşar:
http://localhost:6333 (REST API)
http://localhost:6334 (gRPC, bu makale için gerekli değildir)
Ollama + Qdrant için Python örneği
Şimdi basit bir temel komut dosyası yazıyoruz:
- kullanıcı istemini kabul eder
- bu vektörden bir gömme vektörü üretir
- Qdrant'ta anlamsal olarak benzer anılar arar
- yanıt Ollama aracılığıyla bağlamla birlikte oluşturulur
- yeni görüşmeyi hatırlatma olarak kaydeder
Python-Script: ollama_memory.py
import requests
from sentence_transformers import SentenceTransformer
from qdrant_client import QdrantClient
from qdrant_client.models import Distance, VectorParams, PointStruct
# Einstellungen
OLLAMA_URL = "http://localhost:11434/api/generate"
COLLECTION_NAME = "memory"
VECTOR_SIZE = 384 # für 'all-MiniLM-L6-v2'
# Lade Embedding-Modell
embedder = SentenceTransformer("all-MiniLM-L6-v2")
# Verbinde mit Qdrant
qdrant = QdrantClient(host="localhost", port=6333)
# Erstelle Collection (einmalig)
def create_collection():
if COLLECTION_NAME not in qdrant.get_collections().collections:
qdrant.recreate_collection(
collection_name=COLLECTION_NAME,
vectors_config=VectorParams(size=VECTOR_SIZE, distance=Distance.COSINE)
)
# Füge Eintrag ins Gedächtnis hinzu
def add_to_memory(text: str):
vector = embedder.encode(text).tolist()
point = PointStruct(id=hash(text), vector=vector, payload={"text": text})
qdrant.upsert(collection_name=COLLECTION_NAME, points=[point])
# Suche im Gedächtnis
def search_memory(query: str, top_k=3):
vector = embedder.encode(query).tolist()
hits = qdrant.search(
collection_name=COLLECTION_NAME,
query_vector=vector,
limit=top_k
)
return [hit.payload["text"] for hit in hits]
# Sende Anfrage an Ollama
def query_ollama(context: list[str], user_prompt: str):
prompt = "\n\n".join(context + [user_prompt])
response = requests.post(OLLAMA_URL, json={
"model": "mistral",
"prompt": prompt,
"stream": False
})
return response.json()["response"]
# Ablauf
def main():
create_collection()
print("Frage an die KI:")
user_prompt = input("> ")
context = search_memory(user_prompt)
answer = query_ollama(context, user_prompt)
print("\nAntwort von Ollama:")
print(answer.strip())
# Speichern der Konversation
full_entry = f"Frage: {user_prompt}\nAntwort: {answer.strip()}"
add_to_memory(full_entry)
if __name__ == "__main__":
main()Uygulamaya ilişkin notlar
Kendi gömme modellerinizi de kullanabilirsiniz, örneğin Ollama (örn. nomic-embed-text) veya Hugging Face modelleri aracılığıyla
Qdrant yük filtrelerini, zaman aralıklarını ve alanları destekler (daha sonra genişletmek için çok kullanışlıdır!)
Basit testler için hash(text)-ID yeterlidir, profesyonel uygulamalar için UUID'leri kullanmalısınız
Hafızalı yerel yapay zeka - ve onunla yapabilecekleriniz
Önceki bölümlerde size Ollama ve Qdrant ile Mac üzerinde gerçek, yerel bir yapay zeka belleğinin nasıl oluşturulacağını gösterdim. Bulut olmadan, abonelik olmadan ve harici sunucular olmadan çalışan bir kurulum - hızlı, güvenli, özel.
Ama şimdi ne olacak?
Bu teknoloji gerçekte ne için kullanılabilir? Bugün, yarın, yarından sonraki gün bununla neler mümkün?
Cevap: oldukça fazla.
Çünkü burada sahip olduğunuz şey bir sohbet robotundan çok daha fazlası. Uzun süreli hafızaya sahip, platformdan bağımsız bir düşünme makinesi. Ve bu da kapıları açar.
🔍 1. kişisel bilgi veritabanı
Ollama + Qdrant'ı kişisel uzun süreli belleğiniz olarak kullanabilirsiniz.
Belgeler, konuşmalardan notlar, fikirler - ona söylediğiniz her şey semantik olarak saklanabilir ve geri alınabilir.
Örnek:
"Geçen Perşembe günkü iş fikrim neydi?"
"Mart ayında hangi müşteriler yükseltme istedi?"
Klasörler arasında arama yapmak yerine, sisteminize sormanız yeterlidir. Özellikle heyecan verici olan şey, kesin olmayan sorularla da çalışmasıdır, çünkü Qdrant sadece anahtar kelimeler için değil, semantik olarak arama yapar.
📄 2. otomatik günlük kaydı ve özetleme
Ses veya metin girişi ile birlikte, sistem çalışan bir günlük tutabilir:
- Toplantı notları
- Müşterilerle yapılan görüşmeler
- Günlük kayıtlar veya proje geçmişleri
Bu veriler otomatik olarak Qdrant belleğine aktarılır ve böylece daha sonra bir asistan gibi sorgulanabilir:
"Bay Meier teslimat hakkında ne demişti?"
"XY projesinde süreç nasıldı?"
🧠 3. Kişisel koç veya günlük asistanı
Düşüncelerinizi, ruh halinizi veya kararlarınızı düzenli olarak not ederek, yansıtıcı bir arkadaş oluşturabilirsiniz:
"Bu ay en büyük ilerlemem ne oldu?"
"O zamanlar aksiliklere nasıl tepki verirdim?"
Sistem zamanla sizi tanır ve sadece bir sohbet robotu değil, gerçek bir ayna haline gelir.
💼 4. FileMaker ile iş uygulamaları
Eğer siz de benim gibi FileMaker kullanıyorsanız, bu kurulumu doğrudan bağlayabilirsiniz:
- FileMaker'den komut istemi gönderme
- Cevapları otomatik olarak alma ve kaydetme
- REST API veya kabuk komut dosyası aracılığıyla doğrudan bellek erişimini kontrol edin
Bu, son derece güçlü bir kombinasyon oluşturur:
- FileMaker = Ön uç, kullanıcı arayüzü, kontrol merkezi
- Ollama = Dil zekası
- Qdrant = semantik uzun süreli bellek
Sonuç: FileMaker çözümleri için gerçek bir yapay zeka bileşeni - yerel, güvenli ve özelleştirilmiş.
🛠️ 5. Günlük yaşamda destek: hatırlatmalar, fikirler, öneriler
"Bu fikri bana gelecek hafta hatırlatın."
"Size daha önce hangi kitapları tavsiye etmiştim?"
"Bay Müller'e bundan sonra ne önerebilirim?"
Hedefli hafıza mantığı ile (zaman damgaları, kategoriler, kullanıcılar) hafızanızı hedefli bir şekilde yapılandırabilir, hayatın ve işin birçok alanında kullanabilirsiniz.
🤖 6. Bir ajan sistemi için temel
İleriyi düşünürseniz, bu kurulumla ajan benzeri sistemler de oluşturabilirsiniz:
- Yapay zeka basit görevleri devralıyor
- Yapay zeka zaman içindeki kalıpları tanır
- Yapay zeka proaktif ipuçları veriyor
Örnek:
"Bu hafta aynı soruyu dört kez sordunuz - bir not kaydetmek ister misiniz?"
"Çarpıcı sayıda müşteri bu üründen bahsetti - bunu sizin için özetleyeyim mi?"
🌐 7. Diğer araçlarla entegrasyon
Sistem diğer araçlarla kolayca ilişkilendirilebilir:
- Neo4janlamsal ilişkileri grafiksel olarak göstermek için
- Dosyalar & PDF'leriçeriği otomatik olarak dizine eklemek için
- Posta ayrıştırıcıe-postaları analiz etmek ve ezberlemek
- Sesli asistanlarses yoluyla etkileşim kurmak için
🔐 8. her şey yerel kalır - ve kontrol altında
En büyük avantajı: Neyin kaydedileceğine siz karar veriyorsunuz. Ne kadar süre kayıtlı kalacağına siz karar verirsiniz. Ve: siz istemediğiniz sürece bilgisayarınızdan asla çıkmaz. Birçok insanın körü körüne bulut yapay zekasına güvendiği bir dünyada bu, özellikle serbest çalışanlar, geliştiriciler, yazarlar ve girişimciler için güçlü bir denge unsuru.
Yerel yapay zeka sistemlerinin kullanımına ilişkin güncel anket
Tame Ollama + Qdrant: Yerel yapay zekanıza nasıl yapı, kural ve ince ayar kazandırırsınız?
Ollama ve Qdrant'ı Mac'e yerel olarak kurma zahmetine katlanan herkes zaten büyük işler başardı. Artık sahipsiniz:
- Yerel dilde bir yapay zeka
- Anlamsal bir bellek
- Ve İstem → Bellek → Ollama → Yanıt eşleştirmesini yapan işleyen bir boru hattı
Ancak onunla çalışan herkes hemen fark eder: kurallara ihtiyacı vardır. Yapıya. Düzen.
Çünkü kontrol olmazsa asistanınız hızla çok fazla şey hatırlayan, sürekli kendini tekrarlayan veya alakasız anıları gündeme getiren bir gevezeye dönüşecektir.
🧭 Hala eksik olan ne?
Orkestranın da bir şefi vardır. Ve şu anda sizin işiniz de tam olarak bu: sadece kullanmak yerine kontrol etmek.
Modül 1: Bellek mantığı için bir "yönlendirici"
Açıkça her şeyi kaydetmek ya da açıkça her şeyi aramak yerine, herhangi bir şeyin kaydedilip kaydedilmeyeceğine ya da yüklenip yüklenmeyeceğine önceden karar vermelisiniz. Bunu, örneğin, komut istemi ile bellek arasına yerleştireceğiniz basit bir uygunluk yönlendiricisi ile yapabilirsiniz:
ÖrnekOllama'nin kendisine komut istemi aracılığıyla alaka düzeyini kontrol edin
def is_relevant_for_memory(prompt, response):
prüf_prompt = f"""
Nutzer hat gefragt: "{prompt}"
Die KI hat geantwortet: "{response}"
Sollte man sich diesen Dialog langfristig merken? Antworte nur mit 'Ja' oder 'Nein'.
"""
result = query_ollama([], prüf_prompt).strip().lower()
return result.startswith("ja")Böylece Ollama'ye cevabını değerlendirme görevi veriyorsunuz - ve yalnızca ilgili olarak sınıflandırılırsa Qdrant'a kaydediyorsunuz.
Modül 2: Eski mesajları hariç tutma (bağlam sınırlaması)
Özellikle uzun oturumlarda, eski mesajlar bağlam içinde yeniden ortaya çıkmaya devam ederse sorunlu hale gelir. Model unutmaz - tıkanır.
ÇözümBağlam penceresini sınırlayın.
Bunu iki şekilde yapabilirsiniz:
Yöntem 1: İsabet sayısını sınırlayın
context = search_memory(user_prompt, top_k=3)
Burada yalnızca anlamsal olarak ilgili olan şeyler yüklenir - her şey değil.
Yöntem 2: Zamanı sınırlayın
# Nur Nachrichten der letzten 7 Tage now = datetime.utcnow() filter = Filter( must=[ FieldCondition(key="timestamp", range=Range(gte=now - timedelta(days=7))) ] )
Bu nedenle, sistem geçmişe çok fazla uzanırsa zamanı "kesebilirsiniz".
Modül 3: Bağlam ağırlıkları ve etiketlerin tanıtılması
Hafızanızdaki her girdi eşit değerde değildir. Onlara ağırlık veya kategoriler verebilirsiniz:
- Sabit (örn. "Kullanıcının adı Markus")
- Geçici (örn. "Bugün Salı")
- Durumsal (örn. "Bugün saat 10:30'dan itibaren sohbet")
Qdrant sözde yükleri destekler - yani giriş başına ek bilgi. Bu, daha sonra filtreleme veya önceliklendirme yapmanızı sağlar.
Modül 4: Komut istemi aracılığıyla ince ayar
Komut isteminin kendisi güçlü bir kontrol ünitesidir.
İşte Ollama'yi daha akıllı hale getirmek için kullanabileceğiniz birkaç numara:
Talimatlarla birlikte örnek istem:
Siz semantik hafızaya sahip yerel bir asistansınız. Birkaç anı bulursanız, yalnızca en alakalı üç tanesini kullanın. Açıkça işaretlenmediği sürece 10 günden daha eski bilgilere atıfta bulunmayın. "Günaydın" veya "Teşekkür ederim" gibi önemsiz hatırlatmaları dikkate almayın. Kesin ve deneyimli bir danışman tarzında cevap verin.
Bu, yeni modeller ve eğitim olmadan doğrudan komut isteminin kendisinde ince ayar yapmanıza olanak tanır.
Ve: İstemi dinamik olarak oluşturabilirsiniz - duruma bağlı olarak.
Modül 5: Depolama hijyeni
Hafıza büyüdükçe kafa karıştırıcı hale gelir.
Alakasız veya yinelenen içeriği silen basit bir bakım betiği, ağırlığınca altın değerindedir.
Örnek:
"Hava durumuyla ilgili her şeyi unutun."
"3 aydan daha eski olan ve hiç geri alınmamış girişleri silin."
Qdrant bunu API aracılığıyla destekler - ve örneğin haftada bir kez otomatikleştirebilirsiniz.
Modül 6: Kontrol paneli olarak FileMaker
Eğer siz de benim gibi FileMaker ile çalışıyorsanız, tüm bunları REST-API aracılığıyla uzaktan kontrol edebilirsiniz:
- Derhal gönderin
- Bağlamı al
- Cevap alındı
- Bir değerleme yaptırın
- Kaydet veya unut
İhtiyacınız olan tek şey FileMaker'de küçük bir REST modülü (JSON ile URL'den ekle) ve birkaç komut dosyası.
Sonuç: Yapay zekanızı canlı bir not defteri gibi kontrol etmenizi sağlayan bir arayüz - ama zeka ile.
🔚 Sonuç: Yapay zeka ancak liderliği kadar iyidir
Ollama güçlüdür. Qdrant esnektir. Ancak net kurallar olmadan her ikisi de yapılandırılmamış bir veri yığınına dönüşür. İşin püf noktası her şeyi saklamak değil, yalnızca ilgili olanları saklamak ve sadece hatırlamak yerine amaca yönelik düşünmektir.
Yeni makale serisi: Yapay zekanız için bir bilgi tabanı olarak ChatGPT geçmişleri
 Ollama ve Qdrant ile kendi yapay zeka belleğinizi oluşturduysanız, tam burada başlayan yeni bir yazı dizisine göz atmanızda fayda var. Bu yazı dizisi ChatGPT veri aktarımını bu sisteme entegre edin sağlar. Birçok kullanıcı tüm sohbet geçmişlerini dışa aktarabileceklerinin ve bu verilerin değerli bir bilgi kaynağı olduğunun farkında bile değil. Bu seride, bu konuşmaları nasıl analiz edeceğinizi, bunları katıştırmalara nasıl dönüştüreceğinizi ve ardından bunları bir vektör veritabanına nasıl aktaracağınızı göstereceğim. Bu, yerel yapay zekanızın önceki konuşmalara daha sonra erişmesine ve bunları yanıtlar için bağlam olarak kullanmasına olanak tanır. Bu şekilde, kişisel bir bilgi arşivi bireysel diyaloglardan adım adım büyür.
Ollama ve Qdrant ile kendi yapay zeka belleğinizi oluşturduysanız, tam burada başlayan yeni bir yazı dizisine göz atmanızda fayda var. Bu yazı dizisi ChatGPT veri aktarımını bu sisteme entegre edin sağlar. Birçok kullanıcı tüm sohbet geçmişlerini dışa aktarabileceklerinin ve bu verilerin değerli bir bilgi kaynağı olduğunun farkında bile değil. Bu seride, bu konuşmaları nasıl analiz edeceğinizi, bunları katıştırmalara nasıl dönüştüreceğinizi ve ardından bunları bir vektör veritabanına nasıl aktaracağınızı göstereceğim. Bu, yerel yapay zekanızın önceki konuşmalara daha sonra erişmesine ve bunları yanıtlar için bağlam olarak kullanmasına olanak tanır. Bu şekilde, kişisel bir bilgi arşivi bireysel diyaloglardan adım adım büyür.




Sıkça sorulan sorular
- Yerel bir yapay zeka neden bir „hafızaya“ ihtiyaç duyar? Dil modeli yeterli değil mi?
Bir dil modeli yalnızca mevcut istemle ve o anda ona verdiğiniz bağlamla çalışır. Bu nedenle önceki konuşmaları, belgeleri veya bilgileri kalıcı olarak hatırlamaz. İşte tam da bu noktada yerel bellek devreye girer. Ek bir veritabanı, yapay zekanın önceki içeriği kaydetmesine ve gerektiğinde geri getirmesine olanak tanır. Model daha sonra cevap verirken yalnızca mevcut sorunuzu değil, aynı zamanda bu bellekten ilgili bilgileri de alır. Bu da çok daha tutarlı ve bilinçli yanıtlar alınmasını sağlar. Böyle bir sistem olmadan, bir dil modeli temelde kendi verileriniz veya projeleriniz hakkında uzun vadeli bilgisi olmayan saf bir metin üreticisi olarak kalır. - Qdrant tam olarak nedir ve neden bu sistemde kullanılmaktadır?
Qdrant, semantik aramalar için özel olarak geliştirilmiş modern bir vektör veritabanıdır. Geleneksel veritabanlarının aksine, bilgileri sadece metin olarak değil, vektörler - anlamın matematiksel temsilleri - olarak depolar. Bu, içeriği yalnızca aynı kelimeler için değil, aynı zamanda içeriğin yakınlığı için de aramasına olanak tanır. Yani bir soru sorduğunuzda Qdrant, tam olarak aynı terimleri içermeseler bile bilgi tabanınızdan uygun metin pasajları bulabilir. Bir dil modeli ile birlikte bu, yapay zeka için bir tür akıllı bellek oluşturur. - Bu bağlamda sıklıkla kullanılan „RAG“ terimi ne anlama gelmektedir?
RAG, „Retrieval Augmented Generation“ anlamına gelir. Bu, bir dil modelinin bir cevap vermeden önce bir veritabanından ek bilgi aldığı bir tekniktir. Bu nedenle model, cevabını yalnızca eğitimden üretmekle kalmaz, aynı zamanda bir bilgi kaynağından uygun bilgilerle tamamlar. Bu yöntem, dil modellerinin tipik bir sorununu çözmektedir: Sadece eğitim sırasında öğrenilenleri bilirler. Bunun yerine RAG, dokümantasyon, web siteleri veya kendi notları gibi güncel veya kişisel verilere erişmelerini sağlar. - Ollama ve Qdrant aslında birlikte nasıl çalışıyor?
Bu kurulumda, Ollama dil modeli rolünü üstlenirken, Qdrant anlamsal bellek görevi görür. Bir soru sorduğunuzda, Qdrant önce ilgili metin parçalarını arar. Bu sonuçlar daha sonra sorunuzla birlikte dil modeline aktarılır. Model bu ek bilgileri iyi temellendirilmiş bir cevap formüle etmek için kullanır. Bu nedenle tipik sıra şöyledir: Soru sor → Bellekte ara → Bağlamı genişlet → Cevap oluştur. - Bu yapay zeka belleğine ne tür veriler ekleyebilirim?
Temel olarak metne dönüştürülebilen hemen hemen her şey. Buna belgeler, web siteleri, Markdown dosyaları, PDF'ler, veritabanı girişleri ve hatta kişisel notlar dahildir. Önemli olan tek şey, içeriğin veritabanına kaydedilmeden önce daha küçük metin bölümlerine ayrılabilmesidir. Bu sözde „parçalar“ daha sonra semantik aramanın temelini oluşturur. Bu, yapay zekanın tüm belgeleri aramak zorunda kalmak yerine ilgili bölümlere özel olarak erişmesini sağlar. - Neden normal metin araması yerine bir vektör veritabanı kullanılıyor?
Klasik arama motorları genellikle anahtar kelimelerle çalışır. Bu, yalnızca tam olarak aynı terimleri içeren sonuçları buldukları anlamına gelir. Öte yandan bir vektör veritabanı anlam arar. Bu nedenle, farklı kelimeler kullanılmış olsa bile içerik olarak benzer olan metinleri de bulabilir. Bu, yapay zeka sistemleri için çok önemlidir çünkü sorular genellikle orijinal belgelerden farklı şekilde formüle edilir. Anlamsal aramalar soru ve cevap arasındaki bağlantıyı çok daha güvenilir hale getirir. - Metinler gerçekte nasıl vektörlere dönüştürülür?
Sözde gömme modelleri bu amaçla kullanılır. Bu modeller metinleri analiz eder ve anlamlarını temsil eden sayı vektörlerine dönüştürür. Dolayısıyla metnin her bir bölümüne vektör uzayı olarak bilinen matematiksel bir temsil verilir. Benzer içerikler, tamamen farklı konulara göre birbirine daha yakındır. Daha sonra bir soru sorulursa, bu da bir vektöre dönüştürülür. Qdrant daha sonra bellekteki en benzer girdileri çok hızlı bir şekilde bulabilir. - Qdrant neden genellikle Docker installiert aracılığıyla kullanılır?
Docker, karmaşık yazılımların kurulumunu önemli ölçüde basitleştirir. Birçok bağımlılığı manuel olarak kurmak yerine, Qdrant basitçe bir konteyner içinde çalışır. Bu, kurulumun farklı sistemlerde güvenilir bir şekilde çalıştığı ve kolayca başlatılabileceği veya durdurulabileceği anlamına gelir. Bu yöntem özellikle Mac'te pratiktir çünkü sistemi temiz tutar ve aynı zamanda veritabanı için istikrarlı bir ortam sağlar. - Bu sistemi tamamen çevrimdışı çalıştırabilir miyim?
Evet, bu mimarinin en büyük avantajlarından biri de bu. Hem dil modeli hem de vektör veritabanı kendi bilgisayarınızda yerel olarak çalışır. Bu, harici sunuculara hiçbir veri gönderilmediği anlamına gelir. Bu da tamamen özel bir yapay zeka ortamı yaratıyor. Bu, özellikle hassas veriler veya şirket içi belgeler için bulut sistemlerine göre belirleyici bir avantajdır. - Böyle bir yerel yapay zeka belleği ne kadar büyük olabilir?
Bu, her şeyden önce depolama alanınıza ve sistemin performansına bağlıdır. Modern vektör veritabanları milyonlarca metin parçasını kolayca yönetebilir. Ancak birçok kişisel proje için sadece birkaç bin belge çok güçlü bir bilgi sistemi oluşturmak için yeterlidir. Veri yapısının kalitesi, bilgi miktarından daha önemlidir. - Yapay zeka bu sistemle gerçekten „öğrenebilir“ mi?
Klasik anlamda değil. Dil modelinin kendisi yeniden eğitilmez. Bunun yerine, bilgi modelin dışında saklanır ve gerektiğinde geri alınır. Bu, yapay zekanın öğrenme yeteneğine sahip görünmesini sağlasa da, aslında sadece sürekli büyüyen bir bilgi deposuna erişir. Bu yaklaşımın önemli bir avantajı vardır: modeli yeniden eğitmek zorunda kalmadan herhangi bir zamanda yeni bilgiler eklenebilir. - Böyle bir yerel yapay zeka belleği hangi pratik uygulamalara yol açabilir?
Olasılıklar inanılmaz derecede çeşitlidir. Örneğin, kişisel bir bilgi veritabanı oluşturabilir, teknik belgeleri aranabilir hale getirebilir veya şirket içi belgeleri analiz ettirebilirsiniz. Yazarlar, geliştiriciler veya araştırmacılar da bundan faydalanır çünkü büyük miktarda bilgiyi yapılandırılmış bir şekilde erişilebilir hale getirebilirler. Temel olarak, kendi verilerinizi anlayan bir tür kişisel araştırma asistanı oluşturulur. - Aynı anda birden fazla veri kaynağını entegre edebilir miyim?
Evet, Qdrant her metin parçasına kaynak, kategori veya dil gibi ek meta veriler verilmesine izin verir. Bu, farklı veritabanlarının birlikte yönetilmesine olanak tanır. Hatta bu meta veriler arama sırasında özel olarak filtrelenebilir. Örneğin, yapay zeka yalnızca belirli bir belgedeki veya belirli bir projedeki içeriği dikkate alabilir. - Bu sistemin klasik chatbotlardan farkı nedir?
Çoğu sohbet robotu yalnızca eğitim veri setinin bilgisiyle çalışır. Bu nedenle kendi içeriğiniz hakkında herhangi bir özel bilgi sağlayamazlar. Öte yandan bir RAG sistemi, bir dil modelini bireysel bir bilgi tabanı ile birleştirir. Bu, yapay zekanın doğrudan kendi verilerinize göre uyarlanmış yanıtlar vermesini sağlar. Bu da onu verimli çalışmalar için çok daha kullanışlı hale getirir. - Python bu kurulumda nasıl bir rol oynuyor?
Python genellikle dil modeli ile veritabanı arasındaki bağlantıyı kontrol etmek için kullanılır. Sadece birkaç komut dosyası ile metinler okunabilir, vektörlere dönüştürülebilir ve Qdrant'a kaydedilebilir. Python ayrıca aramayı gerçekleştirebilir ve bulunan sonuçları dil modeline aktarabilir. Bu, kendi gereksinimlerinize göre özelleştirilebilen esnek bir boru hattı oluşturur. - Böyle bir sistem kurmak sadece geliştiricilere yönelik bir şey mi?
Şart değil. Sistemi kurmak belirli bir teknik anlayış gerektirse de, gerekli araçların çoğu artık çok daha basit hale gelmiştir. Biraz sabırla, derinlemesine programlama bilgisi olmadan bile işleyen bir sistem kurulabilir. Bununla bir kez uğraşan herkes, bu tür yerel yapay zeka altyapılarının muazzam potansiyelini hemen fark edecektir. - Yerel bir yapay zeka belleğinin sınırları nelerdir?
En önemli sınırlama kendi bilgisayarınızın işlem gücüdür. Büyük modeller veya büyük bilgi veritabanları daha fazla bellek ve CPU gücü gerektirebilir. Cevapların kalitesi de büyük ölçüde verilerin yapısına bağlıdır. Belgeler kötü hazırlanmışsa, yapay zeka yalnızca sınırlı ölçüde iyi sonuçlar verebilir. - Ollama ve Qdrant'ın bu kombinasyonu neden yerel yapay zeka için özellikle ilginç bir mimari olarak görülüyor?
Çünkü iki önemli bileşeni bir araya getiriyor: güçlü bir dil modeli ve hızlı bir semantik veritabanı. Birlikte, tamamen yerel olarak çalıştırılabilen eksiksiz bir yapay zeka çalışma ortamı oluştururlar. Bu, kişisel bilgi sistemlerinin, akıllı arama motorlarının veya özel asistanların buluta bağımlı olmadan ve kendi verileriniz üzerinde tam kontrol sahibi olarak kurulmasına olanak tanır.