
Alors que MLX a été lancé à l'origine comme cadre expérimental par Apple Research, une évolution silencieuse mais significative a eu lieu ces derniers mois : Avec la sortie de FileMaker 2025, Claris a intégré MLX en tant qu'infrastructure d'IA native pour Apple Silicon de manière permanente dans le serveur. Cela signifie que ceux qui travaillent avec un Mac et misent sur Apple Silicon peuvent non seulement exécuter des modèles MLX en local, mais aussi les utiliser directement dans FileMaker - avec des fonctions natives, sans aucune couche intermédiaire.


Les frontières entre l'expérience MLX locale et l'application professionnelle FileMaker commencent à s'estomper - au profit d'un flux de travail IA entièrement intégré, traçable et contrôlable.
La nouvelle section IA dans le serveur FileMaker : "AI Services
Au cœur de cette nouvelle architecture se trouve la section "AI Services" dans la console d'administration de FileMaker Server 2025. Ici, les développeurs et les administrateurs peuvent :
- activer le serveur de modèles AI,
- Gérer les modèles (télécharger, déployer, peaufiner),
- Attribuer des clés API aux clients autorisés,
- et surveiller de manière ciblée les opérations d'IA en cours.
Lorsque le serveur FileMaker fonctionne sur un Mac équipé de Apple Silicon, le serveur de modèles AI intégré utilise automatiquement MLX comme backend d'inférence. Cela apporte tous les avantages que MLX offre sur les appareils Apple : une grande efficacité de la mémoire, l'utilisation native du GPU via Metal, et une séparation claire entre le modèle et l'infrastructure - dans le style du monde Apple.
Déploiement de modèles MLX directement depuis la console du serveur
Le déploiement d'un modèle MLX est plus simple que prévu : Dans la console de gestion AI, les modèles pris en charge peuvent être sélectionnés directement dans une liste croissante de modèles de langage compatibles avec Claris et être enregistrés sur le serveur install. Il s'agit de modèles open source (par exemple des variantes de Mistral, LLaMA ou Phi), disponibles au format .npz et spécialement convertis pour MLX. Actuellement (septembre 2025), le nombre de modèles disponibles est toutefois encore assez restreint.
Il est également possible de préparer ses propres modèles - par exemple en convertissant des modèles Hugging-Face avec l'outil mlx-lm. Une seule commande permet de télécharger un modèle, de le quantifier et de le mettre au format approprié. Celui-ci peut ensuite être mis à disposition dans le répertoire du serveur - selon le même schéma que celui utilisé en interne par Claris. Une fois installiert, ces modèles sont immédiatement disponibles pour toutes les fonctions d'IA supportées au sein de FileMaker.
Fonctions d'IA natives dans FileMaker Pro : scripter au lieu de faire des détours
Ce qui passait auparavant par des API externes, des appels REST et des routines JSON construites manuellement est aujourd'hui disponible dans FileMaker 2025 sous la forme de commandes de script dédiées. Une fois qu'un compte AI est créé - avec le nom du modèle et la connexion au serveur - les tâches d'IA peuvent être intégrées de manière transparente dans l'interface utilisateur et la logique commerciale.
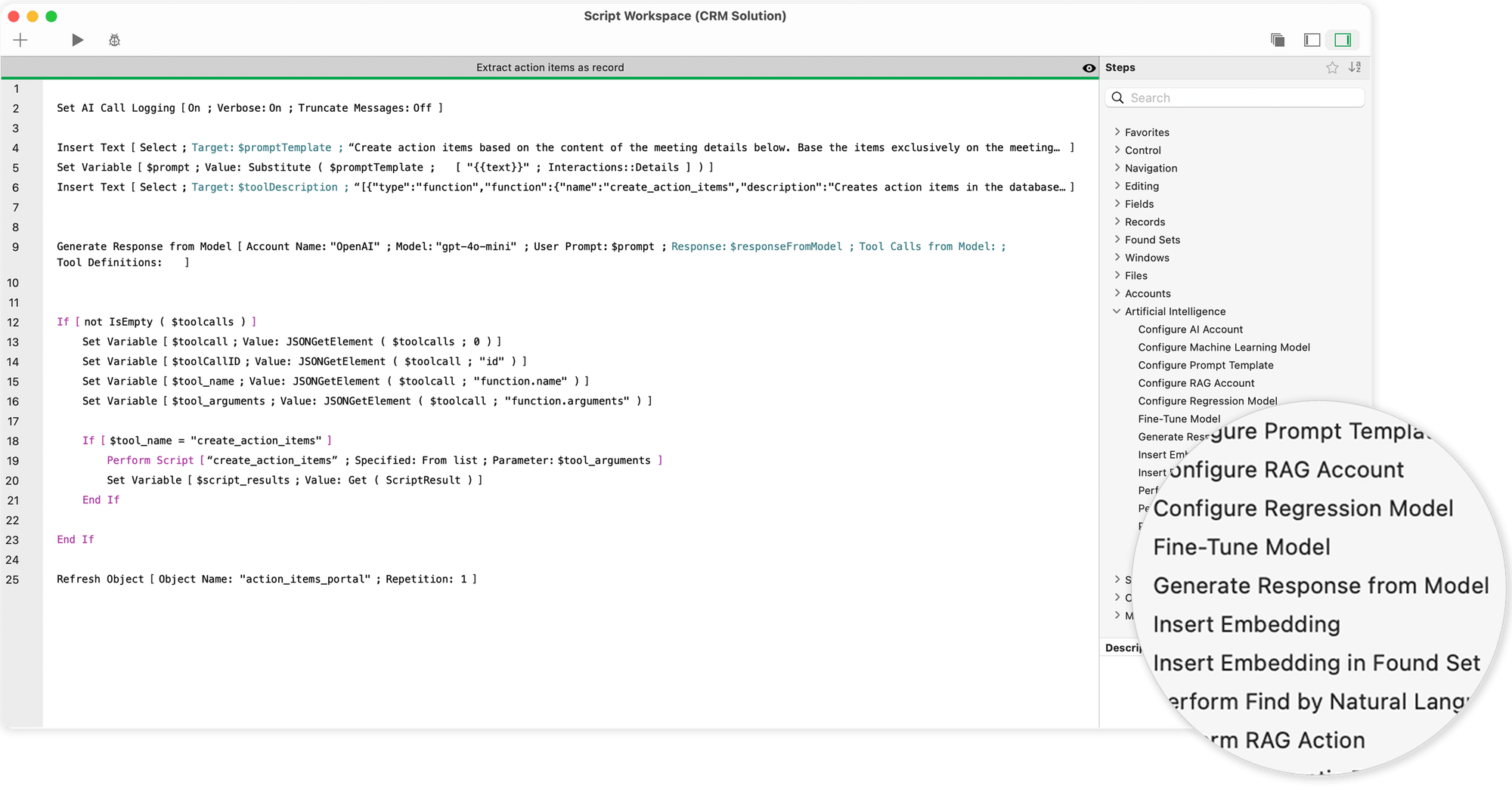
Parmi les commandes les plus importantes, on trouve
- "Générer une réponse à partir du modèle", Le logiciel de gestion de la communication permet de générer des réponses textuelles, par exemple pour des propositions de texte automatiques, des fonctions de chat ou des ébauches d'e-mails.
- "Perform Find par le langage naturel"Il s'agit d'une application qui traduit une formulation simple ("Montrez-moi tous les clients de Berlin avec des factures impayées") en une requête précise dans la base de données.
- "Perform SQL Query by Natural Language" (Réaliser une requête SQL en langage naturel), Il permet de générer et de traiter des structures SQL complexes, y compris des jointures et des sous-requêtes.
- "Get Embedding" et des fonctions connexes qui permettent des analyses vectorielles sémantiques - par exemple pour rechercher des textes ou des demandes de clients au contenu similaire.
Toutes ces commandes font appel en arrière-plan au modèle MLX actuellement sélectionné, qui fonctionne sur le serveur de modèles AI. Les réponses sont immédiatement disponibles et peuvent être traitées directement - sous forme de texte, de JSON ou de vecteur intégré.
Actions de script et possibilités pour l'IA dans FileMaker
Les actions de script d'intelligence artificielle permettent d'intégrer directement de puissants modèles d'intelligence artificielle - tels que les Large Language Models (LLM) ou Core ML - dans les flux de travail FileMaker. Ils créent la base technique permettant de combiner le langage naturel, les connaissances des bases de données et l'apprentissage automatique. Les fonctions suivantes sont disponibles :
- Configuration d'un compte d'IA nommé
Vous pouvez configurer et nommer un compte d'IA spécifique qui sera ensuite utilisé dans toutes les actions de script et fonctions ultérieures. Vous gardez ainsi le contrôle de l'authentification et de l'accès aux modèles ou services externes. - Récupération d'une réponse textuelle à partir d'un prompt
Un modèle d'IA peut réagir à une invite saisie par l'utilisateur et générer une réponse textuelle correspondante. Cela permet d'automatiser la création de texte, les suggestions ou les fonctions de dialogue. - Interrogation de la base de données sur la base d'un prompt et du schéma de la base de données
En transmettant un prompt en langage naturel avec le schéma structurel de votre base de données, le modèle peut identifier le contenu pertinent et renvoyer un résultat ciblé à partir de celui-ci. - Faire générer des requêtes SQL
Le modèle peut également générer des requêtes SQL, sur la base d'une invite et du schéma de base de données sous-jacent. Il est ainsi possible de générer automatiquement des requêtes complexes qui peuvent ensuite être utilisées pour des opérations de base de données. - Requêtes de recherche FileMaker basées sur des rubriques de mise en page
En transmettant au modèle les champs du modèle actuel accompagnés d'une invite en langage naturel, il est possible de formuler automatiquement des requêtes de recherche et de récupérer des ensembles de résultats appropriés. - Insérer des vecteurs d'inclusion dans les jeux de données
Vous avez la possibilité d'insérer des intégrations sémantiques (embeddings) - c'est-à-dire des vecteurs numériques représentant des significations - dans des champs d'enregistrements individuels ou de groupes de résultats entiers. Cela constitue la base de comparaisons sémantiques ou d'analyses IA ultérieures. - Effectuer une recherche sémantique
En se basant sur la signification d'une requête de recherche, le système peut identifier les enregistrements dont les données de champ ont des significations similaires - même si les mots ne correspondent pas exactement. Cela ouvre de nouvelles voies pour la recherche intelligente de données. - Mettre en place des modèles d'invitations
Vous pouvez définir des modèles d'invites réutilisables qui seront utilisés dans d'autres actions de script ou fonctions. Vous assurez ainsi la cohérence et gagnez du temps lors de la création d'invites structurées. - Configurer le modèle de régression
Pour des tâches telles que les prévisions, les estimations ou les analyses de tendances, il est possible de mettre en place un modèle de régression qui opère alors sur des ensembles de données numériques. Il convient par exemple à l'analyse de l'évolution des ventes ou à l'évaluation des risques. - Configurer et gérer le compte RAG
Un compte RAG (Retrieval-Augmented Generation) nommé peut être créé. Il permet d'ajouter ou de supprimer des données et d'envoyer des invites ciblées à un espace RAG. Les systèmes RAG combinent la recherche classique avec des réponses générées par l'IA. - Réglage fin d'un modèle avec des données d'entraînement
Vous pouvez réentraîner un modèle existant avec votre propre jeu de données afin de mieux l'adapter à des exigences, des styles linguistiques ou des domaines d'activité spécifiques. Ce que l'on appelle le "fine tuning" augmente la pertinence et la qualité des sorties. - Consigner les appels à l'IA
Pour le suivi et l'analyse, il est possible d'activer la journalisation de tous les appels à l'IA. Cela est utile pour l'optimisation des invites, la recherche d'erreurs ou la documentation. - Configurer les modèles Core ML
Outre les LLM basés sur le cloud, il est également possible de configurer des modèles Core ML exécutés localement. Cela est particulièrement utile pour les applications hors ligne ou l'utilisation sur des appareils Apple avec support ML intégré.
Enquête actuelle sur l'avenir de Claris FileMaker et de l'IA
Ajustement fin directement à partir de FileMaker : LoRA comme nouveau standard
L'une des nouveautés les plus intéressantes est la possibilité de peaufiner ses propres modèles directement dans FileMaker - et ce entièrement dans l'interface habituelle. Il suffit pour cela d'une commande de script : „Fine-Tune Model“.
Ici, des ensembles de données issus de tables FileMaker (par exemple des historiques de support, des dialogues clients, des modèles de texte) peuvent être utilisés comme données d'entraînement. La méthode de réglage fin est basée sur LoRA (Low-Rank Adaptation), un procédé peu gourmand en ressources qui ne modifie qu'une petite partie des paramètres du modèle et permet ainsi des adaptations rapides - même sur des appareils à mémoire vive limitée.
Les données d'entraînement sont soit reprises d'un Found Set actuel, soit importées via un fichier JSONL. Après l'entraînement, un nouveau nom de modèle est attribué - par exemple „fm-mlx-support-v1“ - et le résultat est directement disponible pour d'autres fonctions d'IA. Il est ainsi possible de créer des modèles linguistiques sur mesure, dont le ton, le vocabulaire et le comportement sont exactement adaptés à l'application concernée.
Protection des données et performance - les deux faces d'une même médaille
Ce n'est pas un hasard si FileMaker 2025 mise sur des modèles locaux avec MLX. À une époque où la souveraineté des données, la conformité au RGPD et les politiques de sécurité internes sont de plus en plus importantes, cette approche présente plusieurs avantages :
- Pas de cloud, pas de serveurs externes, pas de coûts d'API: Toutes les demandes restent dans le propre réseau.
- Temps de réponse plus rapides grâce au traitement local - en particulier pour les processus répétitifs.
- Grande transparence et contrôlabilitéChaque réponse peut être vérifiée, chaque modification peut être suivie, chaque étape de la formation peut être documentée.
- Réglage fin sur ses propres donnéesLes connaissances spécifiques à l'entreprise ne sont plus transmises par des fournisseurs externes, mais restent entièrement dans le système de l'entreprise.
En même temps, il est important d'évaluer les ressources de manière réaliste : Les grands modèles nécessitent également une infrastructure solide au niveau local - par exemple un Mac Apple Silicon avec 32 ou 64 Go de RAM, éventuellement avec mise en cache SSD et un profil de serveur dédié. Mais ceux qui suivent cette voie profitent à long terme d'un contrôle maximal avec une flexibilité totale.
MLX et FileMaker - une nouvelle alliance pour les professionnels
Ce qui semblait être un chemin parallèle - d'un côté MLX en tant que framework de recherche de Apple, de l'autre FileMaker en tant que plateforme de base de données classique - a maintenant fusionné en un système fermé.
Claris a compris que les applications commerciales modernes ont besoin de plus que des formulaires, des tableaux et des rapports. Elles ont besoin d'une IA adaptative et compréhensible - intégrée et non pas rattachée. Avec le support natif de MLX, les nouvelles commandes d'IA et la possibilité de peaufiner localement, FileMaker 2025 offre pour la première fois une plateforme complète permettant de construire, de contrôler et d'utiliser de manière productive ses propres processus d'IA - sans dépendre de fournisseurs externes ou de clouds étrangers.
Pour les développeurs qui, comme toi, apprécient une architecture claire, conçue de manière conservatrice et sûre pour les données, c'est plus qu'un progrès - c'est le début d'une nouvelle façon de travailler.
Dans un autre article, je présente un Comparaison entre Apple Silicon et NVIDIA et explique quel matériel est adapté à l'exécution de modèles linguistiques locaux sur un Mac.


Foire aux questions
- Que signifie exactement le fait que FileMaker 2025 "supporte MLX" ?
FileMaker Server 2025 contient pour la première fois un serveur de modèles AI intégré qui - s'il est installé sur un Apple Silicon Mac install - utilise nativement des modèles MLX. Cela signifie que tu peux déployer un modèle compatible MLX (par exemple Mistral ou Phi-2) directement via la console d'administration et l'utiliser dans ta solution FileMaker, sans passer par des services externes ou des appels REST. - De quoi ai-je concrètement besoin en termes de matériel et de logiciels ?
- Un Mac avec Apple Silicon (M1, M2, M3, M4), idéalement avec 32-64 Go de RAM,
- FileMaker Server 2025, sur ce Mac installiert,
- FileMaker Pro 2025 pour la solution proprement dite,
- et un ou plusieurs modèles compatibles MLX - soit mis à disposition par Claris, soit convertis par ses soins (par exemple via mlx-lm). - Comment puis-je intégrer un tel modèle dans ma solution FileMaker ?
La nouvelle fonction „Configure AI Account“ dans FileMaker Scripts te permet de définir le modèle avec lequel tu travailles. Le nom du serveur, le nom du modèle et la clé d'authentification sont définis. Ensuite, tu peux immédiatement utiliser les autres fonctions d'IA - par exemple pour la génération de texte, l'intégration ou la recherche sémantique. Tout se fait via des étapes de script natives, plus besoin de visualiseur web ou de bricolage „Insert from URL“. - Quelles sont alors les fonctions d'IA que je peux utiliser dans FileMaker ?
Les fonctions suivantes sont disponibles (selon le type de modèle) :
- Génération de texte ("Generate Response from Model")
- Recherche naturelle ("Perform Find by Natural Language")
- SQL en langage courant ("Perform SQL Query by Natural Language")
- Vecteurs sémantiques ("Get Embedding", "Cosine Similarity")
- Gestion des modèles d'invites ("Configure Prompt Template")
- Réglage fin de la LoRA via ses propres données ("Fine-Tune Model")
Toutes les fonctions sont basées sur des étapes de script et peuvent être intégrées de manière transparente dans des solutions existantes. - Comment fonctionne le réglage fin directement dans FileMaker ?
Dans FileMaker 2025, tu peux directement affiner un modèle MLX existant par LoRA - c'est-à-dire l'adapter avec tes propres données. Pour cela, tu utilises soit des enregistrements dans une table (par ex. questions + réponses), soit un fichier JSONL. Une seule commande de script („Fine-Tune Model“) suffit pour créer un nouveau modèle adapté - qui est alors immédiatement disponible dans la solution. - Dois-je alors encore m'y connaître en Python, JSON, API ou formats de modèles ?
Non, pas nécessairement. Claris a délibérément veillé à ce que nombre de ces détails techniques soient relégués au second plan. Tu peux travailler avec des commandes de script natives, gérer toi-même les données dans FileMaker, et traiter facilement les retours sous forme de texte ou de vecteur. Ceux qui le souhaitent peuvent aller plus loin - mais il est désormais possible de le faire sans connaissances en programmation. - Quels sont les avantages d'utiliser MLX via FileMaker - par rapport aux API externes ?
Les avantages sont la sécurité des données, le contrôle des coûts et la performance :
- Pas besoin de connexion au cloud, toutes les données restent sur le réseau de l'entreprise.
- Pas de frais d'API ou de limites de jetons - une fois installiert, l'utilisation est libre.
- Temps de réponse très courts, car il n'y a pas de latence du réseau entre les deux.
- Contrôle total des données de formation, du réglage fin et de la version du modèle.
C'est un véritable gamechanger, en particulier pour les applications internes, les solutions sectorielles ou les processus sensibles. - Y a-t-il des restrictions ou des choses auxquelles il faut faire attention ?
Oui - MLX ne fonctionne que sur Apple Silicon, ce qui signifie qu'un serveur Intel est exclu. En outre, tu as besoin de suffisamment de RAM pour que les modèles plus grands fonctionnent de manière fiable. Tous les modèles ne sont pas immédiatement compatibles - certains doivent être convertis. Enfin, bien que beaucoup de choses fonctionnent „automatiquement“, il faut toujours faire un test dédié lors d'une utilisation productive - par exemple avec de petites quantités de données, des définitions claires des objectifs et une bonne stratégie de journalisation.
Images (c) Claris Inc. et Kohji Asakawa sur Pixabay