
Hoewel MLX oorspronkelijk werd gelanceerd als een experimenteel framework door Apple Research, heeft er de afgelopen maanden een stille maar belangrijke ontwikkeling plaatsgevonden: Met de release van FileMaker 2025 heeft Claris MLX stevig geïntegreerd in de server als een native AI-infrastructuur voor Apple Silicon. Dit betekent dat iedereen die met een Mac werkt en Apple Silicon gebruikt, MLX-modellen niet alleen lokaal kan uitvoeren, maar ze ook direct in FileMaker kan gebruiken - met native functies, zonder tussenlagen.



De grenzen tussen lokaal MLX-experiment en professionele FileMaker toepassing beginnen te vervagen - ten gunste van een volledig geïntegreerde, traceerbare en controleerbare AI-workflow.
Het nieuwe AI-gebied in de FileMaker server: "AI Services".
De kern van deze nieuwe architectuur is het "AI Services" gebied in de Admin Console van FileMaker Server 2025, waar ontwikkelaars en beheerders kunnen:
- de AI Model Server activeren,
- Modellen beheren (downloaden, beschikbaar stellen, afstemmen),
- API-sleutels toewijzen aan geautoriseerde klanten,
- en de lopende AI-operaties gericht monitoren.
Als de FileMaker server draait op een Mac met Apple Silicon, gebruikt de geïntegreerde AI Model Server automatisch MLX als de inference backend. Dit brengt alle voordelen met zich mee die MLX biedt op Apple apparaten: hoge geheugenefficiëntie, native GPU-gebruik via Metal en een duidelijke scheiding van model en infrastructuur - net als in de Apple wereld.
Levering van MLX-modellen rechtstreeks via de serverconsole
Het implementeren van een MLX-model is eenvoudiger dan verwacht: In de AI beheerconsole kunnen ondersteunde modellen direct worden geselecteerd uit een groeiende lijst van Claris-compatibele taalmodellen en worden ingezet op de install server. Dit zijn open source modellen (bijvoorbeeld varianten van Mistral, LLaMA of Phi) die beschikbaar zijn in .npz formaat en speciaal zijn geconverteerd voor MLX. Op dit moment (vanaf september 2025) is het aantal beschikbare modellen echter nog vrij beperkt.
Je kunt ook je eigen modellen voorbereiden, bijvoorbeeld door modellen van omhelzende gezichten te converteren met het mlx-lm gereedschap. Met één commando kun je een model downloaden, kwantiseren en converteren naar het juiste formaat. Dit kan dan beschikbaar worden gemaakt in de server directory - volgens hetzelfde schema dat Claris intern gebruikt. Zodra installiert, zijn deze modellen onmiddellijk beschikbaar voor alle ondersteunde AI-functies binnen FileMaker.
Native AI-functies in FileMaker Pro: scripting in plaats van omwegen
Wat vroeger werd uitgevoerd via externe API's, REST-oproepen en handmatig gebouwde JSON-routines is nu beschikbaar in FileMaker 2025 in de vorm van speciale scriptopdrachten. Zodra een AI-account is ingesteld - met de naam van het model en de verbinding met de server - kunnen AI-taken naadloos worden geïntegreerd in de gebruikersinterface en bedrijfslogica.
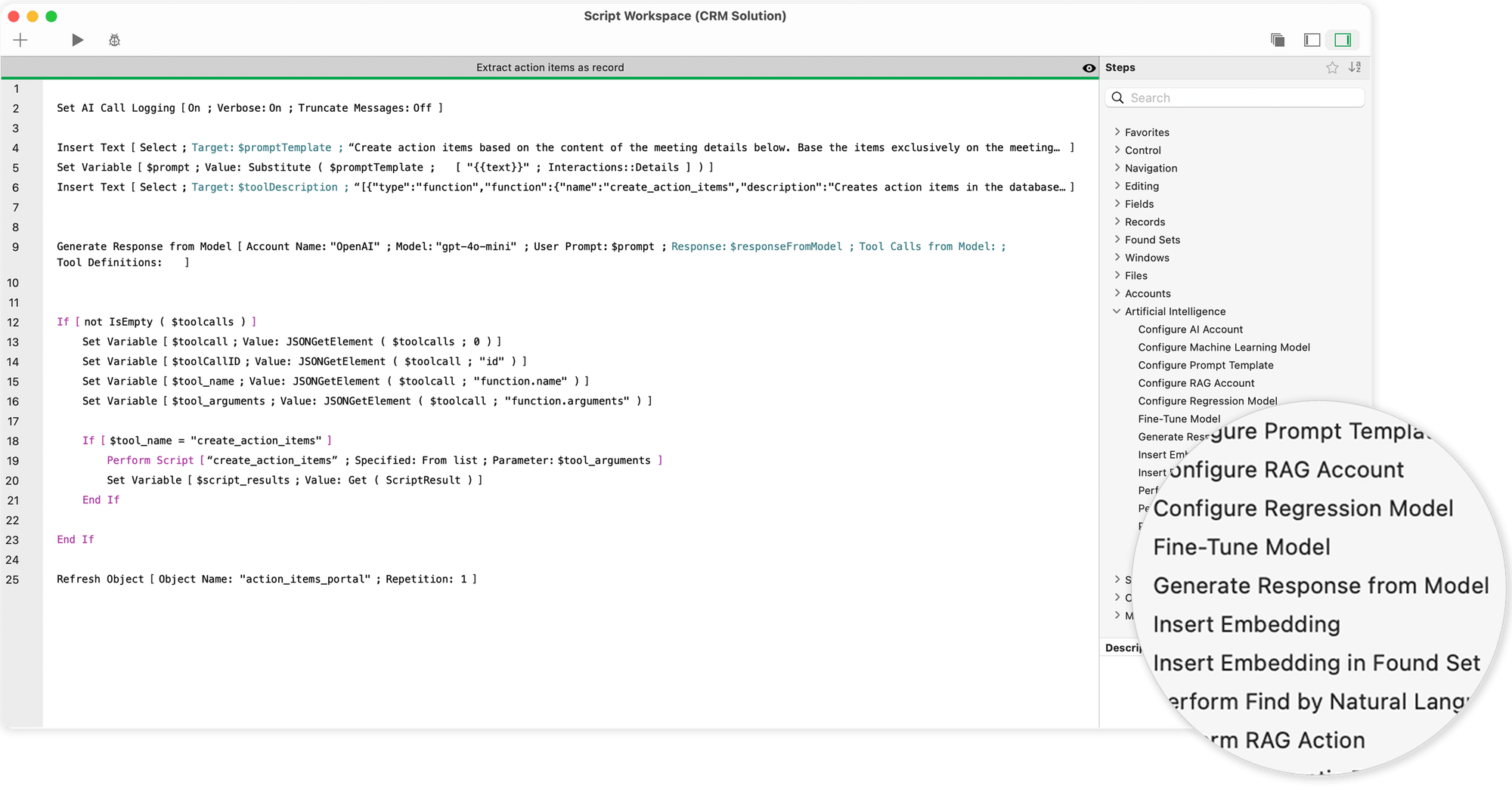
De belangrijkste commando's zijn
- "Genereer reactie van model"., die kunnen worden gebruikt om tekstreacties te genereren - bijvoorbeeld voor automatische tekstsuggesties, chatfuncties of e-mailontwerpen.
- "Zoeken met natuurlijke taal"die een eenvoudige formulering ("Toon me alle klanten uit Berlijn met uitstaande facturen") vertaalt in een precieze databasequery.
- "SQL-query uitvoeren met natuurlijke taal", die ook kan worden gebruikt om complexe SQL-structuren te genereren en te verwerken, inclusief joins en subqueries.
- "Insluiten". en verwante functies die semantische vectoranalyses mogelijk maken - bijvoorbeeld om teksten met vergelijkbare inhoud of vragen van klanten te zoeken.
Al deze commando's hebben toegang tot het op dat moment geselecteerde MLX-model dat op de achtergrond draait op de AI Model Server. De antwoorden zijn direct beschikbaar en kunnen direct worden verwerkt - als tekst, JSON of ingesloten vector.
Scriptstappen en mogelijkheden voor AI in FileMaker
Scriptstappen voor kunstmatige intelligentie maken de directe integratie van krachtige AI-modellen - zoals Large Language Models (LLM's) of Core ML - in FileMaker-workflows mogelijk. Ze creëren de technische basis voor het combineren van natuurlijke taal, databasekennis en machinaal leren. De volgende functies zijn beschikbaar:
- Configuratie van een AI-account met naam
Je kunt een specifieke AI-account instellen en benoemen, die vervolgens wordt gebruikt in alle verdere scriptstappen en -functies. Zo behoud je de controle over verificatie en toegang tot externe modellen of diensten. - Een tekstreactie ophalen op basis van een prompt
Een AI-model kan reageren op een prompt die de gebruiker invoert en een bijbehorend tekstantwoord genereren. Dit maakt automatische tekstgeneratie, suggesties of dialoogfuncties mogelijk. - Database query gebaseerd op een prompt en het databaseschema
Door een vraag in natuurlijke taal door te geven, samen met het structurele schema van je database, kan het model relevante inhoud identificeren en een gericht resultaat teruggeven. - SQL-query's genereren
Het model kan ook SQL-query's genereren op basis van een prompt en het onderliggende databaseschema. Hierdoor kunnen complexe queries automatisch worden gegenereerd, die vervolgens kunnen worden gebruikt voor databasebewerkingen. - FileMaker zoekopdrachten gebaseerd op lay-outvelden
Door de velden van de huidige lay-out samen met een vraag in natuurlijke taal door te geven aan het model, kunnen zoekopdrachten automatisch worden geformuleerd en geschikte resultatensets worden opgehaald. - Insluitvectoren invoegen in gegevensrecords
Je hebt de mogelijkheid om semantische inbeddingen - d.w.z. numerieke vectoren die betekenissen weergeven - in te voegen in velden van individuele datarecords of hele resultatensets. Dit vormt de basis voor latere semantische vergelijkingen of AI-analyses. - Een semantische zoekopdracht uitvoeren
Op basis van de betekenis van een zoekopdracht kan het systeem gegevensrecords identificeren waarvan de veldgegevens vergelijkbare betekenissen hebben - zelfs als de woorden niet exact overeenkomen. Dit opent nieuwe mogelijkheden voor intelligente zoekopdrachten. - Sjablonen voor prompts instellen
Je kunt herbruikbare promptsjablonen definiëren die in andere scriptstappen of functies kunnen worden gebruikt. Dit zorgt voor consistentie en bespaart tijd bij het maken van gestructureerde prompts. - Regressiemodel configureren
Een regressiemodel kan worden opgezet voor taken zoals voorspellingen, schattingen of trendanalyses, die dan werken op numerieke gegevenssets. Het is bijvoorbeeld geschikt voor het analyseren van verkoopontwikkelingen of risicobeoordelingen. - Configureer en beheer uw RAG account
Er kan een RAG-account (Retrieval Augmented Generation) op naam worden ingesteld. Hiermee kun je gegevens toevoegen of verwijderen en specifieke prompts naar een RAG-ruimte sturen. RAG-systemen combineren klassieke zoekopdrachten met AI-gegenereerde antwoorden. - Een model verfijnen met trainingsgegevens
Je kunt een bestaand model hertrainen met je eigen dataset om het beter aan te passen aan specifieke vereisten, taalstijlen of taakgebieden. Fijnafstemming verhoogt de relevantie en kwaliteit van de output. - AI-oproepen loggen
Het loggen van alle AI-oproepen kan worden geactiveerd voor tracering en analyse. Dit is handig voor het optimaliseren van prompts, probleemoplossing of documentatie. - Core ML-modellen configureren
Naast cloudgebaseerde LLM's kunnen ook lokaal uitgevoerde Core ML-modellen worden geconfigureerd. Dit is vooral handig voor offline toepassingen of voor gebruik op Apple apparaten met geïntegreerde ML-ondersteuning.
Huidig onderzoek naar de toekomst van Claris FileMaker en AI
Fijnafstemming rechtstreeks vanaf FileMaker: LoRA als nieuwe standaard
Een van de meest opwindende nieuwe functies is de mogelijkheid om je eigen modellen direct in FileMaker te fine-tunen - volledig binnen de vertrouwde interface. Alles wat je nodig hebt is een scriptcommando: „Fine-Tune Model“.
Gegevensrecords uit FileMaker-tabellen (bijvoorbeeld ondersteuningsgeschiedenis, klantdialogen, tekstvoorbeelden) kunnen worden gebruikt als trainingsgegevens. De fijnafstemmingsmethode is gebaseerd op LoRA (Low-Rank Adaptation), een resourcebesparende procedure die slechts een klein deel van de modelparameters verandert en dus snelle aanpassingen mogelijk maakt, zelfs op apparaten met een beperkt geheugen.
De trainingsgegevens worden gehaald uit een huidige gevonden set of geïmporteerd via een JSONL-bestand. Na de training wordt een nieuwe modelnaam toegewezen - bijvoorbeeld „fm-mlx-support-v1“ - en het resultaat is direct beschikbaar voor verdere AI-functies. Dit maakt het mogelijk om taalmodellen op maat te maken die qua toon, woordenschat en gedrag precies zijn afgestemd op de betreffende toepassing.
Gegevensbescherming en prestaties - twee zijden van dezelfde medaille
Dat FileMaker 2025 vertrouwt op lokale modellen met MLX is geen toeval. In een tijd waarin gegevenssoevereiniteit, GDPR-compliance en interne beveiligingsrichtlijnen steeds belangrijker worden, biedt deze aanpak verschillende voordelen:
- Geen cloud, geen externe servers, geen API-kostenAlle verzoeken blijven binnen je eigen netwerk.
- Snellere responstijden dankzij lokale verwerking - vooral voor terugkerende processen.
- Hoge transparantie en controleerbaarheidElk antwoord kan worden gecontroleerd, elke wijziging kan worden bijgehouden en elke trainingsstap kan worden gedocumenteerd.
- Fijnafstemming op je eigen gegevensBedrijfsspecifieke kennis wordt niet langer via externe leveranciers doorgegeven, maar blijft volledig binnen het eigen systeem van het bedrijf.
Tegelijkertijd is het belangrijk om de middelen realistisch in te schatten: Grote modellen vereisen ook een solide lokale infrastructuur - zoals een Apple Silicon Mac met 32 of 64 GB RAM, mogelijk met SSD caching en een dedicated serverprofiel. Maar wie deze route neemt, profiteert op de lange termijn van maximale controle met volledige flexibiliteit.
MLX en FileMaker - een nieuwe alliantie voor professionals
Wat aanvankelijk leek op een parallel pad - enerzijds MLX als het onderzoekskader van Apple, anderzijds FileMaker als het klassieke databaseplatform - is nu samengegroeid tot een gesloten systeem.
Claris heeft ingezien dat moderne bedrijfsapplicaties meer nodig hebben dan formulieren, tabellen en rapporten. Ze hebben adaptieve, begrijpende AI nodig - geïntegreerd, niet bolt-on. Met native ondersteuning voor MLX, de nieuwe AI-commando's en de mogelijkheid tot lokale fine-tuning, biedt FileMaker 2025 voor het eerst een compleet platform voor het bouwen, controleren en productief gebruiken van uw eigen AI-processen - zonder afhankelijk te zijn van externe leveranciers of externe clouds.
Voor ontwikkelaars die, net als jij, een duidelijke, conservatief doordachte en gegevensveilige architectuur waarderen, is dit meer dan vooruitgang - het is het begin van een nieuwe manier van werken.
In een ander artikel presenteer ik een Vergelijking tussen Apple Silicon en NVIDIA en uitleggen welke hardware geschikt is voor het draaien van lokale taalmodellen op een Mac.



Veelgestelde vragen
- Wat betekent het precies dat FileMaker 2025 "MLX ondersteunt"?
FileMaker Server 2025 bevat voor het eerst een geïntegreerde AI Model Server, die - indien geïnstalleerd op een Apple Silicon Mac install - MLX-modellen natively gebruikt. Dit betekent dat u een MLX-compatibel model (bijv. Mistral of Phi-2) direct kunt implementeren via de Admin Console en gebruiken in uw FileMaker oplossing - zonder omwegen via externe diensten of REST-oproepen. - Welke specifieke hardware en software heb ik hiervoor nodig?
- Een Mac met Apple Silicon (M1, M2, M3, M4), idealiter met 32-64 GB RAM,
- FileMaker Server 2025, op deze Mac installiert,
- FileMaker Pro 2025 voor de werkelijke oplossing,
- en een of meer MLX-compatibele modellen - geleverd door Claris of zelf geconverteerd (bijv. via mlx-lm). - Hoe integreer ik een dergelijk model in mijn FileMaker-oplossing?
Je kunt de nieuwe functie „AI-account configureren“ in FileMaker Scripts gebruiken om aan te geven welk model wordt gebruikt. De servernaam, de modelnaam en de auth key worden gedefinieerd. Je kunt dan meteen de andere AI-functies gebruiken - bijvoorbeeld voor tekstgeneratie, insluiten of semantisch zoeken. Alles wordt uitgevoerd via native scriptstappen, er is geen webviewer of „Invoegen vanaf URL“ meer nodig. - Welke AI-functies kan ik gebruiken in FileMaker?
De volgende functies zijn beschikbaar (afhankelijk van het modeltype):
- Tekst genereren ("Genereer antwoord van model")
- Natuurlijk zoeken ("Zoeken in natuurlijke taal")
- SQL in alledaagse taal ("SQL-query uitvoeren met natuurlijke taal")
- Semantische vectoren ("Get Embedding", "Cosine Similarity")
- Beheer van instructiesjablonen ("Configureer instructiesjabloon")
- LoRA fijntunen via eigen gegevens ("Model fijntunen")
Alle functies zijn gebaseerd op scriptstappen en kunnen naadloos worden geïntegreerd in bestaande oplossingen. - Hoe werkt fijnafstemming direct in FileMaker?
In FileMaker 2025 kun je een bestaand MLX-model direct verfijnen met LoRA - d.w.z. aanpassen met je eigen gegevens. Hiervoor gebruik je datarecords in een tabel (bijv. vragen + antwoorden) of een JSONL-bestand. Een enkele scriptopdracht („Fine-Tune Model“) is voldoende om een nieuw, aangepast model te maken - dat dan onmiddellijk beschikbaar is in de oplossing. - Moet ik nog steeds bekend zijn met Python, JSON, API's of modelformaten?
Nee, niet per se. Claris heeft er bewust voor gezorgd dat veel van deze technische details naar de achtergrond verdwijnen. U kunt werken met native scriptopdrachten, de gegevens zelf beheren in FileMaker en de retouren gewoon verwerken als tekst of vector. Als u wilt, kunt u dieper gaan - maar nu kan het zonder programmeerkennis. - Wat zijn de voordelen van het gebruik van MLX via FileMaker in vergelijking met externe API's?
De voordelen liggen in gegevensbeveiliging, kostenbeheersing en prestaties:
- Geen cloudverbinding nodig, alle gegevens blijven in je eigen netwerk.
- Geen API-kosten of tokenlimieten - eenmaal installiert, is het gratis te gebruiken.
- Zeer korte responstijden, omdat er geen netwerklatentie tussen zit.
- Volledige controle over trainingsgegevens, fijnafstelling en versiebeheer van modellen.
Dit is een echte game changer, vooral voor interne toepassingen, industriële oplossingen of gevoelige processen. - Zijn er beperkingen of dingen waar je op moet letten?
Ja - MLX werkt alleen op Apple Silicon, dus een Intel server is uitgesloten. U hebt ook voldoende RAM nodig om grotere modellen betrouwbaar te laten werken. Niet alle modellen zijn direct compatibel - sommige moeten worden geconverteerd. En tot slot: Hoewel veel dingen „automatisch“ werken, moet je altijd een speciale testrun uitvoeren voor productief gebruik - bijvoorbeeld met kleine hoeveelheden gegevens, duidelijke doeldefinities en een goede logstrategie.
Afbeeldingsmateriaal (c) Claris Inc. en Kohji Asakawa op Pixabay