
Kdybys se mě před pár lety zeptal, jak bude vypadat vývoj softwaru za deset let, pravděpodobně bych mluvil o nových programovacích jazycích, lepších frameworkách nebo výkonnějších vývojových prostředích. Dnes by moje odpověď zněla úplně jinak. Největší změna se neodehrává v oblasti nástrojů, ale ve způsobu, jakým my vývojáři přemýšlíme a pracujeme.
Zatímco píšu tyto řádky, sám pracuji na novém softwarovém systému. Již několik týdnů při tom intenzivně využívám moderní nástroje umělé inteligence, jako je Codex a další jazykové modely. Zpočátku jsem byl zvědavý, nyní jsem především ohromen. Ne proto, že by AI najednou zvládala vše sama, ale proto, že některé úkoly zvládá překvapivě dobře a tím umožňuje nové způsoby práce.




Mnohé diskuse o umělé inteligenci se točí kolem otázky, zda se vývojáři jednou stanou zbytečnými. Na základě mých dosavadních zkušeností považuji tuto otázku za málo přínosnou. Mnohem zajímavější je pozorování, že se mění role vývojáře. Skutečnou výzvou je stále méně psaní jednotlivých řádků kódu. Místo toho je stále důležitější analyzovat problémy, rozumět systémům, dokumentovat souvislosti a poskytovat umělé inteligenci správné informace.
Vývojář jako architekt
V klasickém vývoji softwaru trávili vývojáři často velkou část své pracovní doby samotnou realizací. Programovaly se funkce, budovaly se databáze a opravovaly se chyby. Tyto úkoly existují i dnes. Systémy umělé inteligence však dnes mohou mnoho z těchto činností podporovat nebo částečně převzít.
Tím se posouvá těžiště. Kdo chce úspěšně vyvíjet s využitím umělé inteligence, musí především vědět, co vlastně chce vytvořit. Na první pohled to zní jako samozřejmost, ale není tomu tak.
V mnoha projektech nevzniká většina problémů kvůli špatnému programování, ale kvůli nejasným požadavkům. Pokud je cíl nejasný, nepomůže ani ta nejlepší umělá inteligence. Ve skutečnosti umělá inteligence takové nedostatky často ještě více odhalí, protože systémy pracují velmi důsledně na základě informací, které dostanou.
Moderní vývojář se proto stále více stává architektem. Navrhuje strukturu systému, definuje procesy, popisuje souvislosti a dbá na to, aby všichni zúčastnění – ať už lidé, nebo systémy umělé inteligence – měli o projektu stejnou představu. Čím větší projekt je, tím důležitější je tato schopnost.
Od programátora k vedoucímu projektu
Z mých vlastních projektů vyplývá zajímavý postřeh, že komunikace má dnes mnohem větší význam než dříve. Kdo pracuje s umělou inteligencí, tráví často více času popisy, dokumentací a návrhy než samotným programováním.
To neznamená, že technické znalosti přestávají být důležité. Naopak. Kdo nerozumí základům databází, softwarové architektury nebo obchodních procesů, nedosáhne dobrých výsledků ani s umělou inteligencí. Těžiště se však přesouvá od pouhé implementace k řízení.
Dalo by se říci, že se vývojář stále více stává vedoucím svého vlastního virtuálního vývojářského týmu. Tento tým již netvoří výhradně lidští kolegové, ale různé systémy umělé inteligence, které mohou převzít různé úkoly. Jedna umělá inteligence pomáhá s architekturou, další vytváří dokumentaci, další analyzuje chyby a ještě jiná vyvíjí uživatelská rozhraní.
Odpovědnost však zůstává na člověku. Umělá inteligence poskytuje návrhy. Nečiní však žádná obchodní rozhodnutí, nezná cíle společnosti a nenese ani žádnou odpovědnost za důsledky své práce.
Proč jsou zkušenosti stále důležitější
Někteří lidé se obávají, že umělá inteligence učiní odborné znalosti zbytečnými. Podle mých zkušeností je tomu spíše naopak. Čím větší jsou možnosti těchto nástrojů, tím důležitější jsou zkušenosti. Zkušený vývojář rychleji rozpozná, zda je řešení smysluplné. Vidí souvislosti, které umělá inteligence možná nezohlednila. Zná typické zdroje chyb a dokáže výsledky kriticky zpochybnit.
Právě proto projekty v oblasti umělé inteligence často fungují obzvláště dobře, když se spojí odborné znalosti s umělou inteligencí. Nejlepších výsledků se málokdy dosáhne slepou důvěrou v technologii. Vznikají tam, kde směr udává zkušený člověk a umělá inteligence ho při realizaci podporuje.
V jistém smyslu mi to připomíná zavádění moderních strojů v mnoha řemeslných oborech. Nástroje se staly výkonnějšími, ale zkušený řemeslník zůstal nepostradatelný. Musel se pouze naučit nové nástroje smysluplně využívat.
Nový způsob uvažování
Kdo dnes vyvíjí software s využitím umělé inteligence, neměl by se proto nejprve zamýšlet nad tím, jaký kód má umělá inteligence napsat. Důležitější otázkou je: Jak mohu svůj projekt popsat tak, aby mu umělá inteligence porozuměla co nejlépe?
Právě tady začíná ta skutečná práce. O úspěchu či neúspěchu nerozhoduje samotný příkaz. Rozhodující jsou znalosti, které za tímto příkazem stojí. Kdo zná své procesy, rozumí svým datovým strukturám a dokáže jasně formulovat své cíle, ten poskytuje umělé inteligenci základ pro dobré výsledky.
Tím se vývoj softwaru zásadně mění. Hodnota vývojáře se v budoucnu bude stále méně odvíjet od toho, jak rychle dokáže psát kód. Mnohem důležitější bude schopnost analyzovat složité systémy, strukturovat znalosti a srozumitelně komunikovat.
Dobrá zpráva zní: Tyto schopnosti byly cenné už odjakživa. Umělá inteligence je pouze zviditelňuje. A právě proto úspěšný vývoj softwaru s využitím umělé inteligence nezačíná programováním, ale porozuměním.

Nejprve pochopit, pak programovat
Kdo poprvé pracuje s výkonnou umělou inteligencí, často zažívá malý nával nadšení. Najednou lze během několika minut vytvořit věci, které dříve vyžadovaly hodiny nebo dokonce dny. Struktura databáze je rychle navržena, uživatelské rozhraní vznikne stisknutím tlačítka a i složitější programové funkce se často objeví na obrazovce překvapivě rychle.
Právě zde však číhá jedna z největších pastí moderního vývoje softwaru. Rychlost nástrojů svádí k tomu, aby se s realizací začalo příliš brzy. Mnoho vývojářů, podnikatelů a projektových manažerů se vrhá přímo do programování, ačkoli ještě vůbec nepromysleli skutečný problém. Umělá inteligence pak sice produkuje působivé výsledky, ale nakonec pracuje na nejistém základě.
Problémem zde není umělá inteligence. Problémem je neúplný popis projektu. Pokud umělá inteligence obdrží nesprávné nebo neúplné informace, pokusí se přesto vygenerovat řešení. Výsledek často na první pohled vypadá věrohodně. Teprve později se ukáže, že chybí důležité souvislosti nebo že základní předpoklady byly nesprávné.
Podle mého názoru je to jeden z nejčastějších důvodů, proč projekty zbytečně ztrácejí čas.
Pokušení rychlého startu
Mnozí vývojáři ten pocit znají. Člověk má nápad na novou aplikaci, otevře chat s umělou inteligencí a hned začne psát první zadání.
- „Vytvoř mi systém CRM.“
- „Naprogramuj systém pro správu skladu.“
- „Vytvořte systém pro správu projektů s evidencí odpracované doby.“
Takové pokyny jsou pochopitelné. Koneckonců, každý chce vidět výsledky co nejdříve. Právě tento přístup však často vede k tomu, že se později musí velká část systému přepracovávat.
Umělá inteligence nemůže vědět, jaké specifika má tvoje firma. Nezná tvé zákazníky. Nezná tvé pracovní postupy. Neví, jaká rozhodnutí byla v minulosti přijata a jaké rámcové podmínky je třeba zohlednit.
Zkušený vývojář softwaru by zákazníkovi obvykle položil řadu otázek, než by se pustil do samotné realizace. Přesně stejný postup je vhodný i u projektů v oblasti umělé inteligence.
Místo toho, abychom se hned pustili do programování, měli bychom si nejprve ujasnit situaci.
Co z toho vlastně má vzniknout?
Tato otázka zní banálně, ale překvapivě často na ni není poskytnuta dostatečná odpověď. Téměř každý softwarový projekt má za sebou různé cíle. Někdy jde o zrychlení pracovního postupu. V jiných případech se jedná o lepší vyhodnocování, snížení chybovosti nebo vyšší automatizaci.
Umělá inteligence může činit smysluplná rozhodnutí pouze tehdy, zná-li tyto cíle. Vezměme si jako příklad správu zákazníků. Na první pohled se to jeví jako relativně jednoduché. Už po několika minutách však vyvstává řada otázek.
Jedná se pouze o správu adresářů, nebo o komplexní CRM systém? Jsou k dispozici kontaktní osoby? Spravují se nabídky a faktury? Má být software vícejazyčný? Máte terénní pracovníky? Je třeba zohlednit požadavky na ochranu osobních údajů?
Čím přesněji budou tyto otázky zodpovězeny, tím lépe umělá inteligence pochopí skutečný účel systému. Cílem by proto mělo být vždy nejen popsat software, ale také obchodní souvislosti, které za ním stojí.
Procesy jsou důležitější než funkce
Další častou chybou je zaměření se výhradně na funkce. Mnohé popisy projektů obsahují formulace jako:
- „Měla by existovat maska pro zákazníky.“
- „Měla by tam být funkce vyhledávání.“
- „Měl by umět vytvářet soubory PDF.“
Jde sice o důležité informace, ale popisují pouze nástroje. Skutečně zajímavé jsou procesy, které za nimi stojí.
- Proč je potřeba zákaznická maska?
- Jaké kroky následují poté?
- Kdo tyto údaje využívá?
- Jaké informace budou později vyhodnoceny?
Moderní systémy umělé inteligence dokážou procesy překvapivě dobře pochopit, jsou-li dostatečně popsány. Proto se často vyplatí zdokumentovat celé pracovní postupy. V centru pozornosti by neměla být otázka „Jakou masku potřebuji?“, ale otázka:
„Jak bude uživatel se systémem později pracovat?“
Čím podrobněji je tento postup popsán, tím lépe může umělá inteligence vypracovat vhodné návrhy.
Význam dat
Kromě procesů tvoří základu každého softwaru data. Mnoho vývojářů podceňuje, jak důležitý je podrobný popis datových struktur pro úspěch projektu v oblasti umělé inteligence.
Pokud umělá inteligence ví pouze to, že existují zákazníci, není to příliš užitečné. Tato informace má mnohem větší hodnotu, pokud je navíc popsáno, jaká pole existují, jaké vztahy jsou mezi nimi a jak budou data později využita.
V mých projektech se osvědčilo poskytovat konkrétní příklady co nejdříve. Ukázkové datové soubory jsou často výmluvnější než dlouhé teoretické popisy.
Konkrétní záznam o zákazníkovi obsahující jméno, adresu, kontaktní osoby a historii komunikace často poskytne umělé inteligenci lepší přehled než několik odstavců abstraktních vysvětlení. Totéž platí pro kmenová data o produktech, projekty, faktury nebo jakékoli jiné informace.
Čím více se popis blíží budoucí realitě, tím lepší jsou výsledky.
Fáze analýzy šetří čas
Mnoho lidí vnímá analýzu a dokumentaci jako nepříjemnou přípravnou práci. Koneckonců, každý chce vidět produktivní výsledky co nejdříve. Paradoxně právě tato netrpělivost často vede k prodloužení doby vývoje.
Každá hodina, kterou na začátku věnujete důkladné analýze, vám později často ušetří mnoho hodin oprav. Tento princip platil již dlouho před érou umělé inteligence a dnes má ještě větší význam.
Umělá inteligence pracuje velmi rychle. To však znamená, že dokáže velmi rychle rozmnožit i nesprávné výsledky. Kdo vyvine systém s nejasným popisem, může během několika minut získat stovky řádků kódu pro nesprávné řešení.
Kdo však nejprve přesně definuje požadavky, vytvoří pevný základ pro všechny další kroky.
Porozumění jako základ všeho dalšího
Nejdůležitější poznatek proto zní: Dobrý software nevzniká pouze díky dobrým zadáním. Vzniká díky hlubokému pochopení problému.
Čím lépe znáš cíle, procesy, data a souvislosti projektu, tím efektivněji můžeš spolupracovat s umělou inteligencí. Kvalita výsledků nakonec závisí méně na inteligenci nástroje než na kvalitě informací, které mu poskytneš.
Úspěšný vývoj softwaru s využitím umělé inteligence proto nezačíná prvním řádkem kódu. Začíná snahou pochopit problém tak důkladně, aby jej mohla pochopit a vyřešit jiná osoba – nebo právě umělá inteligence.

Ideální zavedení projektu v oblasti umělé inteligence
Když do firmy nastoupí nový zaměstnanec, obvykle ho jen tak neposadí na pracoviště a neřeknou mu: „Dej se do toho.“ Místo toho ho seznámí s firmou. Seznámí se s cíli firmy, dostane důležité podklady, pochopí pracovní postupy a promluví si s lidmi, kteří už mají zkušenosti.
Přesně stejná logika platí i pro spolupráci s umělou inteligencí. Mnoho vývojářů přesto stále zachází se svou AI jako s vyhledávačem. Kladou jednotlivé otázky, zadávají krátké pokyny a poté se diví, že výsledky jsou neúplné nebo nevhodné. Praxe však opakovaně ukazuje, že kvalita odpovědí silně závisí na tom, jak dobře byla AI do projektu zavedena. Dobře připravené zavedení projektu může znamenat rozdíl mezi průměrnými a mimořádně dobrými výsledky.
Z vlastní praxe jsem se naučil, že první informace, které umělá inteligence o projektu získá, mají často překvapivě velký vliv na celý jeho další průběh. Čím lépe je tento základ vybudován, tím produktivnější je spolupráce.
Srozumitelně vysvětlit projekt
Prvním krokem je popsat projekt jako celek. Mnoho vývojářů přitom dělá tu chybu, že se hned pouštějí do technických detailů. Mluví o databázích, programovacích jazycích nebo rozhraních, ještě než je vůbec jasné, jaký problém se má řešit. Pro umělou inteligenci je však nejdříve důležitý odborný kontext.
Představ si, že chceš vyvinout ERP systém. Místo toho, abys hned začal s tabulkami a názvy polí, měl bys nejprve popsat, pro koho je software určen, jaké úkoly má plnit a jaké cíle má sledovat. Dobrý úvod do projektu odpovídá na základní otázky:
- Kdo bude se systémem později pracovat?
- Jaké procesy by měly být podporovány?
- Jaké problémy je třeba vyřešit?
- Jaké jsou jeho zvláštnosti?
Teprve až budou tyto souvislosti jasné, má smysl zabývat se technickými detaily. Lze si to představit jako stavbu domu. Než se začne hovořit o zásuvkách nebo vodovodním potrubí, mělo by být jasné, zda má vůbec vzniknout rodinný dům, kancelářská budova nebo sklad.
Technický rámec
Po vysvětlení odborných základů přichází na řadu technické prostředí. Zde jde o to, aby se umělé inteligenci sdělily rámcové podmínky, v nichž má pracovat. Patří sem například použité programovací jazyky, databázové systémy, frameworky nebo cílové platformy.
Tento krok je důležitější, než by se na první pohled mohlo zdát. Řešení, které je vhodné pro webovou aplikaci, nemusí být automaticky vhodné i pro desktopovou aplikaci. Stejně tak se možnosti různých databázových systémů mohou částečně značně lišit.
Čím konkrétněji jsou popsány rámcové podmínky, tím cíleněji může umělá inteligence pracovat. Při tom by se neměla dokumentovat pouze aktuální technická rozhodnutí, ale také stávající předpisy. Možná již existují starší systémy, stávající rozhraní nebo určité firemní standardy. I tyto informace pomáhají umělé inteligenci vypracovat realistické návrhy.
Datový model jako základ
Nejpozději v tomto okamžiku je zřejmé, proč je dobrá příprava tak důležitá. V téměř každém větším softwarovém projektu hrají data klíčovou roli. Zákazníci, položky, projekty, faktury, dokumenty nebo uživatelské účty tvoří základ budoucí aplikace.
Proto se vyplatí poskytnout umělé inteligenci přehled o datovém modelu co nejdříve. Nejde přitom zpočátku o dokonalou technickou dokumentaci. Důležité je spíše to, aby umělá inteligence pochopila základní souvislosti.
- Jaké tabulky existují?
- Které objekty jsou vzájemně propojené?
- Jaké informace se ukládají?
- Které údaje jsou obzvláště důležité?
Čím jasněji je tato struktura popsána, tím snazší je pro umělou inteligenci správně zařadit pozdější požadavky. V mnoha projektech se ukazuje, že kvalita pozdějších návrhů programů přímo souvisí s porozuměním datovému modelu. Kdo tuto oblast zanedbá, často se potýká s nedorozuměními a zbytečnými opravami.
Proč jsou vzorové údaje tak cenné
Jednou z nejúčinnějších metod, jak umělé inteligenci vysvětlit fungování systému, je poskytnout jí konkrétní příklady. Lidé se často učí na příkladech. Systémy umělé inteligence fungují v mnoha situacích podobně.
Teoretický popis zákaznické databáze může být užitečný. Skutečný vzorový datový soubor však často poskytuje mnohem více informací. Umělá inteligence najednou rozpozná typický obsah, konvence pojmenování, formáty dat a souvislosti. Lépe pochopí, které informace jsou skutečně relevantní a jak budou později využity. Totéž platí pro kmenová data článků, faktury, projekty nebo jakékoli jiné objekty v rámci systému.
Samozřejmě je třeba při tom brát ohled na ochranu osobních údajů a důvěrnost. V mnoha případech zcela postačí anonymizované vzorové údaje. Rozhodující není skutečnost, zda se jedná o skutečné osoby či společnosti, ale struktura informací.
Naučit se jazyk umělé inteligence
Zajímavým vedlejším efektem práce s umělou inteligencí je to, že se vývojáři učí jasněji popisovat své vlastní systémy. Mnohé souvislosti, které se v jejich hlavách zdají samozřejmé, musí najednou formulovat. Tím se odhalí nejasnosti, kterých si předtím téměř nevšimli.
Tento proces se podobá tvorbě technické dokumentace. Jakmile se člověk pokusí něco přesně vysvětlit, často si uvědomí, že některé aspekty ještě nebyly zcela promyšleny.
Právě proto je představení projektu užitečné nejen pro umělou inteligenci, ale často i pro samotného vývojáře. Kdo dokáže svůj projekt srozumitelně vysvětlit umělé inteligenci, ten mu většinou sám rozumí mnohem lépe.
Investice, která se mnohonásobně vyplatí
Někteří vývojáři zpočátku vnímají podrobné seznámení s projektem jako zbytečnou zátěž. Ve skutečnosti se však jedná o jednu z nejvýnosnějších investic v rámci projektu umělé inteligence.
Každá hodina, kterou na začátku věnujete popisu cílů, procesů, dat a technických podmínek, může později ušetřit mnoho hodin dodatečné práce. Umělá inteligence pak již nepracuje naslepo, ale na základě společného chápání projektu.
Právě toto společné porozumění tvoří základ všeho, co následuje. Rozhoduje o tom, zda umělá inteligence pouze plní jednotlivé úkoly, nebo zda se stane skutečným partnerem v oblasti vývoje.
Z tohoto důvodu by se zahájení projektu nemělo nikdy považovat za nepříjemnou povinnost. Je to okamžik, kdy se vytváří základ pro veškerou budoucí spolupráci. Čím pevnější je tento základ, tím lepší jsou zpravidla i výsledky.
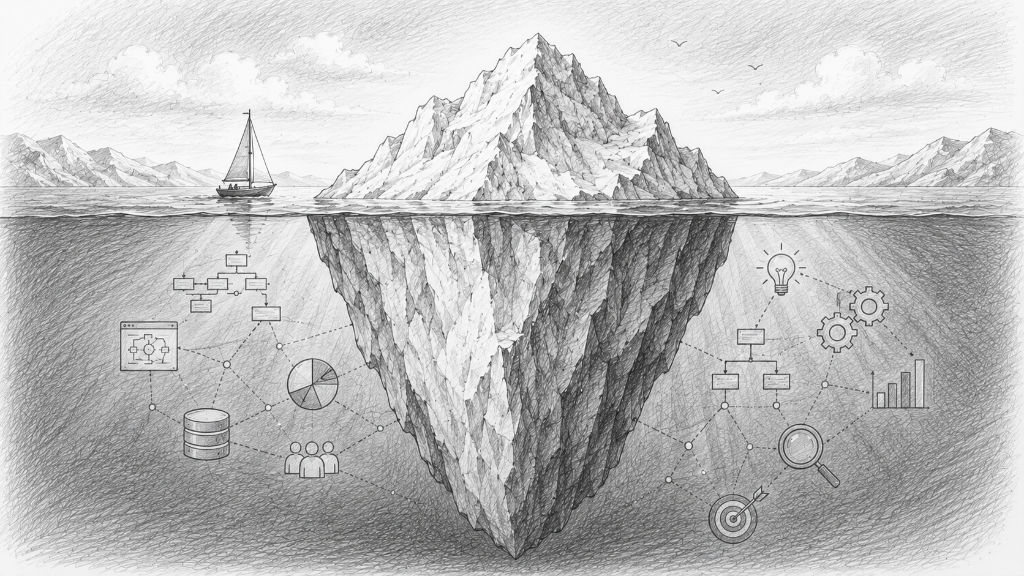
Kontext je důležitější než kód
Mnoho vývojářů zpočátku předpokládá, že moderní systémy umělé inteligence umí především velmi dobře programovat. Nej působivější příklady se totiž často předvádějí právě pomocí kódu. Umělá inteligence vytvoří webovou stránku, napíše dotaz do databáze nebo během několika vteřin napíše kompletní funkci.
Po získání určitých praktických zkušeností se však často ukazuje, že skutečnost je jiná. Skutečná síla moderní umělé inteligence nespočívá primárně v psaní kódu. Její největší předností je propojování informací, rozpoznávání souvislostí a aplikace znalostí na nové situace.
Právě proto je kontext tak důležitý. Pokud umělá inteligence pochopí souvislosti, často to vede k překvapivě dobrým výsledkům. Chybí-li však tento kontext, sice nadále generuje odpovědi a kód, ale pracuje na nejistém základě. Kvalita výsledků pak často výrazně klesá, i když se programování jeví jako technicky správné.
V praxi se opakovaně ukazuje, že rozhodujícím základem umělé inteligence není samotný kód, ale kontext, v němž tento kód vzniká.
Proč krátké pokyny často vedou ke špatným výsledkům
Ti, kdo s umělou inteligencí začínají, mají často sklon formulovat úkoly velmi stručně. Typický příkaz by mohl znít:
„Vytvořte systém pro správu zákazníků.“
Z technického hlediska není tento pokyn nesprávný. Nicméně téměř všechny důležité informace zůstávají nevyjasněné.
- Pro jaké odvětví?
- Pro kolik uživatelů?
- Jaké údaje se mají ukládat?
- Jaké procesy by měly být podporovány?
- Jaké výstupy jsou potřeba?
- Jaké systémy již existují?
Umělá inteligence musí na všechny tyto otázky odpovědět sama a nevyhnutelně přitom vychází z určitých předpokladů. Některé z nich budou náhodou správné, jiné nikoli. Výsledek je srovnatelný s architektem, kterému se pouze řekne:
„Postav mi dům.“
Samozřejmě, že dokáže navrhnout dům. Pravděpodobnost, že bude přesně odpovídat vašim představám, je však malá. Čím více relevantních informací chybí, tím větší je prostor pro interpretaci. A právě tento prostor pro interpretaci často vede k zbytečným opravám.
Rozdíl mezi informací a kontextem
V mnoha diskusích o umělé inteligenci se přehlíží jedna důležitá věc. Informace a kontext nejsou totéž. Informace jsou jednotlivé skutečnosti, například:
- Systém využívá databázi PostgreSQL.
- Existuje tabulka zákazníků.
- Aplikace běží v prohlížeči.
Tyto údaje jsou užitečné, ale většinou nestačí. Kontext vzniká teprve tehdy, když se zviditelní souvislosti mezi těmito informacemi.
- Proč se používá PostgreSQL?
- Jakou roli hraje tabulka zákazníků v celém systému?
- Kteří uživatelé s touto aplikací pracují?
- Jaké obchodní procesy s tím souvisejí?
Umělá inteligence potřebuje nejen fakta, ale i jejich význam. Teprve díky tomu může činit rozhodnutí, která jsou pro daný projekt vhodná. Čím je projekt složitější, tím důležitější je tento rozdíl.
Umělá inteligence by měla rozumět podniku
Z praxe vyplývá zajímavý postřeh, že nejlepších výsledků se často dosahuje tehdy, když umělá inteligence rozumí nejen softwaru, ale i společnosti, která za ním stojí.
Vezměme si opět příklad ERP systému. Je velký rozdíl v tom, zda je tento systém vyvíjen pro řemeslnou firmu, velkoobchod, lékařskou ordinaci nebo internetový obchod. Mnoho technických požadavků přímo vyplývá z obchodního modelu.
Kdo umělé inteligenci vysvětlí pouze technickou strukturu, ponechává jí velkou část interpretace na starosti. Kdo naopak navíc popíše firemní procesy, poskytne podstatně cennější kontext. Proto se často vyplatí umělé inteligenci nejprve představit organizaci.
- Jak společnost vydělává peníze?
- Které procesy jsou obzvláště důležité?
- Kde obvykle vznikají problémy?
- Jaké cíle si tento software klade?
Na první pohled se může zdát, že tyto informace nemají s programováním moc společného. Ve skutečnosti však často výrazně zlepšují kvalitu technických výsledků.
Nová filozofie vývoje: gFM-NEXT a SchallOS jako praktický příklad
 Spolupráce mezi Codexem, ChatGPT a jasně strukturovanou architekturou, popsaná v této praktické příručce, se již nyní uplatňuje v reálném softwarovém projektu. S gFM-NEXT vzniká na základě systému SchallOS nová vývojová platforma založená na webovém prohlížeči, která propojuje klasický ERP software, moderní webové technologie a vývoj podporovaný umělou inteligencí.
Spolupráce mezi Codexem, ChatGPT a jasně strukturovanou architekturou, popsaná v této praktické příručce, se již nyní uplatňuje v reálném softwarovém projektu. S gFM-NEXT vzniká na základě systému SchallOS nová vývojová platforma založená na webovém prohlížeči, která propojuje klasický ERP software, moderní webové technologie a vývoj podporovaný umělou inteligencí.
Cílem není pouze portování stávajícího řešení FileMaker, ale vybudování platformy, na které bude možné v budoucnu výrazně rychleji vyvíjet, migrovat a rozšiřovat aplikace. Umělá inteligence se dabei nezabývá pouze generováním kódu, ale podporuje také architekturu, dokumentaci, testování a postupný další vývoj platformy. Díky adaptérům pro různé databázové systémy, serverové konzoli, funkčním kontejnerům a rozsáhlé znalostní vrstvě vzniká infrastruktura, která je důsledně navržena s ohledem na opětovnou použitelnost. gFM-NEXT tak názorně ukazuje, jak umělá inteligence nejen urychluje jednotlivé programátorské úkoly, ale může zásadně změnit celý vývojový proces.
Kontext omezuje počet chybných rozhodnutí
Jednou z největších předností kvalitního projektového kontextu je to, že se výrazně snižuje počet chybných rozhodnutí. Představme si, že má umělá inteligence vyvinout novou funkci. Bez kontextu zná pouze aktuální úkol. Snaží se jej vyřešit co nejefektivněji.
S dostatečným kontextem zná navíc:
- architektura celého systému
- stávající principy designu
- předchozí rozhodnutí
- technické podmínky
- dlouhodobé cíle
Díky tomu dokáže mnoho návrhů automaticky přizpůsobit stávající struktuře. Kvalita výsledků se často nezvyšuje postupně, ale skokově. Z tohoto důvodu zkušení vývojáři často věnují více času vysvětlování kontextu než formulování jednotlivých zadání.
Dokumentace jako úložiště kontextu
Zde se ukazuje, jak nesmírně důležitá je kvalitní projektová dokumentace. Žádný vývojář nechce stále dokola vysvětlovat ty samé informace. To platí i pro spolupráci se systémy umělé inteligence.
Centrální dokumentace proto slouží jako trvalý úložiště kontextu. Tam lze shromažďovat důležité informace:
Cíle projektu, datové modely, architektonická rozhodnutí, konvence pro pojmenování, technické specifikace a otevřené otázky.
Nové chatovací systémy nebo nové systémy umělé inteligence pak mohou k této dokumentaci přistupovat a seznámit se s projektem. Čím rozsáhlejší projekt je, tím důležitější je tento postup. V jistém smyslu tak vzniká jakási kolektivní paměť projektu. Z toho mají prospěch nejen lidé, ale i umělá inteligence.
Více kontextu neznamená více textu
V tomto bodě často dochází k nedorozumění. Více kontextu neznamená automaticky napsat co nejvíce stránek textu.
Rozhodující je relevance informací. Pětistránkový přesný popis může mít mnohem větší hodnotu než padesát stránek nestrukturovaného textu. Umění spočívá v tom, poskytnout informace, které jsou pro pochopení projektu skutečně důležité. Patří sem zejména:
- Cíle
- Procesy
- Datové struktury
- technické podmínky
- Architektonická rozhodnutí
- skutečné příklady
Kdo tyto oblasti řádně zdokumentuje, vytvoří si tím většinou již vynikající základ.
Proč bude kontext v dlouhodobém horizontu důležitější než programování
Čím výkonnější jsou systémy umělé inteligence, tím více se těžiště přesouvá od samotného programování k předávání znalostí.
Kód se stále více stává zdrojem, který lze generovat automaticky. Kontext však zůstává úkolem pro člověka. Pouze lidé znají cíle podniku. Pouze lidé rozumějí politickým, organizačním či ekonomickým souvislostem. Pouze lidé mohou určit, jakým směrem by se měl projekt v dlouhodobém horizontu ubírat.
Umělá inteligence dokáže tyto znalosti využít, rozšiřovat a převádět do technických řešení. Nedokáže je však vytvářet sama. Proto se kontext v budoucnu pravděpodobně stane jedním z nejcennějších zdrojů v oblasti vývoje softwaru.
Kdo poskytne umělé inteligenci správný kontext, často dosáhne překvapivě dobrých výsledků. Kdo tento krok vynechá, naopak často zjistí, že ani dokonale napsaný kód automaticky nevede k dobrému softwaru. Úspěšný software totiž nakonec nevzniká díky jednotlivým řádkům kódu, ale díky pochopení souvislostí, z nichž tyto řádky vycházejí.

Rozdělení velkých projektů do specializovaných chatů
Kdo začíná s vývojem pomocí softwaru s umělou inteligencí, obvykle pracuje v jediném chatu. To je logické. Začíná se nápadem, popíše se požadavky a projekt se postupně rozvíjí.
U menších projektů tento postup často skvěle funguje. Jednotlivou aplikaci, skript nebo přehlednou databázi lze bez problémů řešit v chatu.
S rostoucím rozsahem projektu se však mění i požadavky. Najednou se objeví spousta tabulek, různé uživatelské role, několik rozhraní, rozsáhlá dokumentace a stovky rozhodnutí, která byla v průběhu vývoje učiněna. Zároveň vznikají nové požadavky, zatímco starší informace ustupují stále více do pozadí.
Nejpozději v tomto okamžiku se ukazuje důležitý poznatek: Velké softwarové projekty by měly být strukturovány stejně jako velké podniky.
Nikdo by od jednoho zaměstnance neočekával, že bude zároveň jednatelem, účetním, obchodníkem, vývojářem, designérem a pracovníkem technické podpory. Právě proto se i při práci s umělou inteligencí vyplatí oddělit jednotlivé oblasti odpovědnosti od sebe.
Představa, že jediný dialog bude trvale provázet celý rozsáhlý projekt, je sice lákavá, s rostoucí složitostí se však stává stále méně praktickou.
Myšlenka specializovaných chatů
Jednou z nejúčinnějších metod při realizaci rozsáhlejších projektů v oblasti umělé inteligence je zřízení několika chatových skupin s jasně vymezenými úkoly. Každá z těchto skupin se zaměřuje na konkrétní oblast a v průběhu času si vybuduje určitou specializaci.
Tento princip připomíná klasické vývojářské týmy. V podniku často pracují specialisté na databáze, uživatelská rozhraní, infrastrukturu, dokumentaci nebo zajištění kvality. Nikdo nemusí dělat všechno najednou.
Stejný přístup lze překvapivě dobře aplikovat i na systémy umělé inteligence. Místo toho, aby se všechny dotazy psaly do jediného chatu, rozdělí se jednotlivá témata cíleně do několika sekcí. Díky tomu zůstávají konverzace přehlednější a umělá inteligence se může lépe soustředit na svou konkrétní oblast působnosti. Zároveň se tím snižuje riziko, že se důležité informace ztratí mezi mnoha různými tématy.
Architektonický chat
Architektonický chat často představuje strategické jádro projektu. Právě zde se přijímají zásadní rozhodnutí.
- Jaké datové struktury by se měly použít?
- Jak vypadá architektura systému?
- Jaké moduly existují?
- Jaké konvence pro pojmenování platí?
- Jaké technické zásady je třeba dodržovat?
Tento chat se nezabývá tolik jednotlivými řádky kódu, ale spíše celkovým kontextem.
V mnoha projektech se osvědčilo dokumentovat architektonická rozhodnutí pokud možno na jednom centrálním místě a neupravovat je neustále v různých chatech. Tím se vytvoří stabilní základ pro veškerou další práci.
Architektonický chat se tak v jistém smyslu stává technickou pamětí projektu.
Chat na serverové straně
Zatímco chat o architektuře se zabývá základními otázkami, chat o backendu se soustředí na samotnou obchodní logiku. Zde vznikají databázové dotazy, rozhraní, automatizace a složité procesy.
Umělá inteligence se v této oblasti může plně soustředit na technické požadavky, aniž by ji neustále rozptylovaly otázky týkající se designu nebo dokumentace.
Zejména u větších projektů vede toto oddělení často k výrazně lepším výsledkům. Backendový chat se postupem času stává specialistou na interní postupy a technické procesy. Díky tomu je spolupráce efektivnější a přehlednější.
Chat v uživatelském rozhraní
Uživatelská rozhraní se často řídí zcela odlišnými pravidly než backendové systémy. V popředí zde stojí uživatelská přívětivost, navigace, rozvržení a pracovní postupy. Frontendový chat se může těmito tématy cíleně zabývat.
- Jaké informace musí být viditelné?
- Jaká vstupní pole jsou potřebná?
- Jak by měla být maska konstruována?
- Jaké kroky uživatel při své práci provádí?
Jelikož tento chat nemusí současně zpracovávat složitou logiku databáze ani otázky týkající se architektury, může se mnohem více soustředit na pohled uživatele.
Právě vývojáři mají občas sklon upřednostňovat technické aspekty před uživatelskou přívětivostí. Vlastní chat v uživatelském rozhraní pomáhá tuto rovnováhu zlepšit.
Chat pro dokumentaci
Mnoho projektů selže nikoli kvůli technickým problémům, ale kvůli nedostatečné dokumentaci. Zpočátku se vše jeví jako logické a samozřejmé. O několik měsíců později si však už nikdo nevzpomene, proč byla určitá rozhodnutí přijata.
V tomto případě může mít vlastní dokumentační chat obrovské výhody. Jeho úkolem je zaznamenávat technická rozhodnutí, vytvářet přehledy projektů, dokumentovat změny a zajistit dlouhodobou dostupnost znalostí.
Tento chat by měl co nejtěsněji spolupracovat s ostatními částmi projektu. Kdykoli vzniknou nové funkce nebo budou přijata architektonická rozhodnutí, lze dokumentaci aktualizovat.
Tímto způsobem tak krok za krokem vzniká cenná příručka pro celý projekt.
Chat o zajištění kvality
Zvláště zajímavým přístupem je přidělit umělé inteligenci další roli – roli kontrolora. Namísto vývoje nových funkcí tento chatbot kontroluje práci jiných chatbotů. Analyzuje:
- možné chyby
- Problémy s bezpečností
- Nesrovnalosti
- Rizika související s výkonností
- Mezery v dokumentaci
Tento postup připomíná klasické revize kódu v týmech vývojářů. Jeho velkou výhodou je, že se tak objevují různé úhly pohledu.
Zatímco vývojový chat se často soustředí na co nejrychlejší realizaci úkolu, chat zaměřený na zajištění kvality toto řešení kriticky posuzuje a cíleně hledá slabá místa. Tato dodatečná kontrolní instance může výrazně zvýšit kvalitu projektu.
Společná znalostní základna
Několik specializovaných chatů však funguje dobře pouze tehdy, pokud čerpají ze stejné znalostní základny. Právě proto hraje centrální projektová dokumentace tak důležitou roli. Všechny chaty by měly vycházet ze stejných základních informací:
Cíle projektu, architektonická rozhodnutí, datové modely, konvence pro pojmenování a technické rámcové podmínky.
Tímto způsobem nevzniká směsice navzájem nesouvisejících dílčích projektů, ale společný systém s jasnou strukturou. Dalo by se říci, že dokumentace představuje společný jazyk všech chatů.
Bez tohoto společného jazyka hrozí nedorozumění a protichůdné výsledky.
Umělá inteligence jako virtuální tým vývojářů
Čím déle se tímto způsobem pracuje, tím jasněji se vynořuje jedna zajímavá myšlenka. Moderní systémy umělé inteligence se chovají stále více jako virtuální tým vývojářů.
Samozřejmě se nejedná o skutečné lidi. Přesto lze mnoho osvědčených organizačních principů klasických softwarových projektů překvapivě dobře aplikovat. Místo toho, aby se využíval jediný všestranný pracovník, vzniká několik specializovaných rolí s jasně vymezenými odpovědnostmi.
Díky tomu jsou projekty přehlednější, srozumitelnější a často i kvalitnější. Zejména u rozsáhlejších projektů může tento přístup znamenat obrovský rozdíl. Úspěšný vývoj softwaru totiž nespočívá pouze v programování. Zahrnuje také plánování, architekturu, dokumentaci, zajištění kvality a komunikaci.
Čím lépe jsou tyto oblasti od sebe odděleny a zároveň propojeny, tím úspěšnější je zpravidla celý projekt. A právě v tomto ohledu se naplno projevuje největší síla specializovaných chatů.
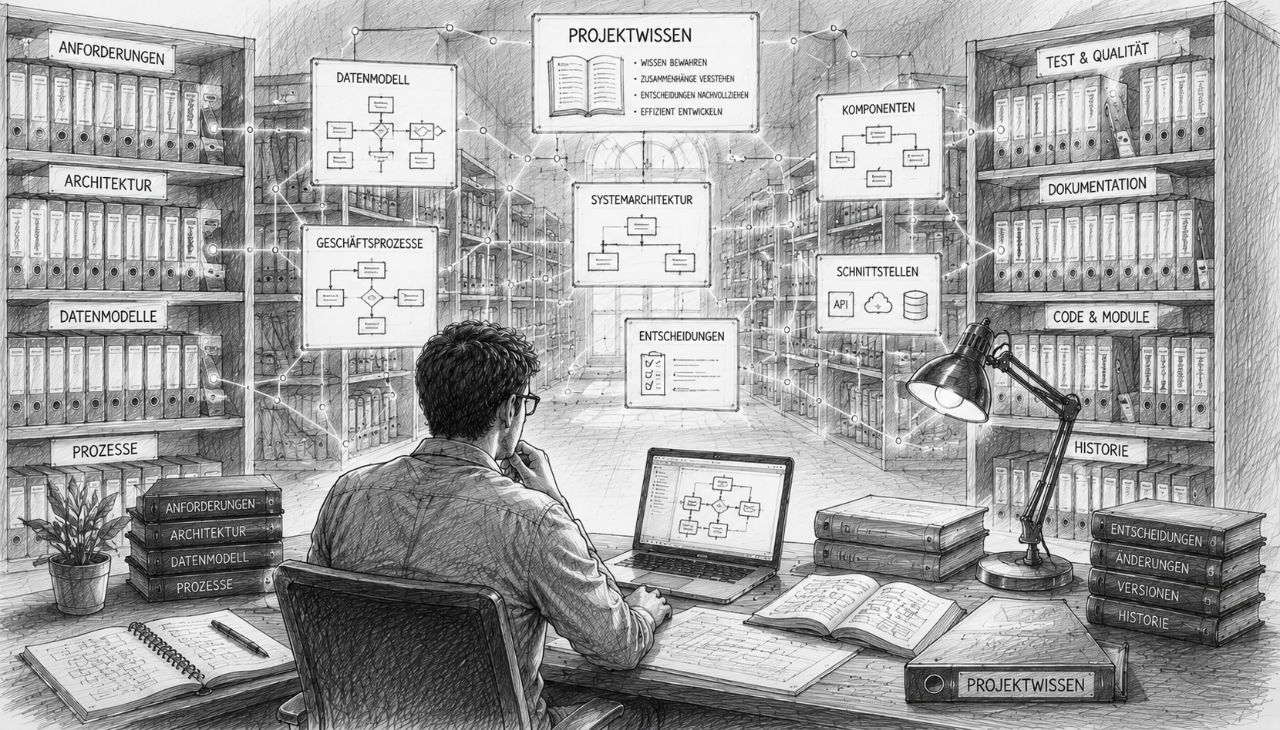
Centrální projektová dokumentace
Téměř každý větší softwarový projekt začíná jasnou představou. Cíle jsou známé, požadavky se zdají přehledné a nejdůležitější rozhodnutí jsou všem zúčastněným jasná. V této rané fázi často vzniká dojem, že rozsáhlá dokumentace vlastně není vůbec nutná. Koneckonců, každý sám ví, proč byla určitá rozhodnutí učiněna. Datové struktury jsou známé, procesy srozumitelné a architektura se jeví jako logická.
Situace se však s každým dalším dnem vývoje mění. Přibývají nové funkce. Požadavky se mění. Dřívější rozhodnutí se rozšiřují nebo upravují. K projektu se přidávají další vývojáři. Otevírají se nové chatové kanály s umělou inteligencí. Vznikají výjimky a zvláštní případy. To, co bylo ještě před pár týdny zcela samozřejmé, pomalu ztrácí na významu.
Právě v tomto okamžiku se projevuje skutečná hodnota kvalitní projektové dokumentace. Jejím primárním účelem není plnit papíry nebo zaplňovat pořadače. Jejím nejdůležitějším úkolem je zajistit trvalou dostupnost znalostí. Dalo by se říci, že dokumentace se stává pamětí projektu.
Proč jsou projekty v oblasti umělé inteligence obzvláště náročné na dokumentaci
Je zajímavé, že díky moderním systémům umělé inteligence dokumentace neztrácí na významu, ale naopak se stává mnohem důležitější. V klasických projektech bylo možné si mnoho informací zapamatovat nebo je sdělit ústně. Při spolupráci se systémy umělé inteligence to však funguje jen omezeně.
- Každý nový chat začíná zpočátku bez znalosti projektu.
- Každý nový dialog zná pouze informace, které mu jsou poskytnuty.
- Každá další umělá inteligence potřebuje kontext, aby mohla smysluplně fungovat.
Z toho vyplývá nový požadavek: znalosti je třeba systematicky ukládat. Dokumentace tak přestává být pouze pomůckou pro lidi, ale stává se zároveň zdrojem znalostí pro systémy umělé inteligence. Čím rozsáhlejší je projekt, tím větší je tato výhoda.
Díky kvalitní dokumentaci lze nové chatové skupiny zprovoznit během několika minut, místo aby bylo nutné neustále znovu vysvětlovat důležité informace.
Co by mělo být zdokumentováno
Často se klade otázka, jaké informace je vlastně třeba dokumentovat. Odpověď je jednodušší, než by se mnohým mohlo zdát. Dokumentovat by se měly především rozhodnutí. Zdrojový kód lze kdykoli znovu vygenerovat nebo analyzovat. Složitější je to s úvahami, které za tímto kódem stojí.
- Proč byla zvolena právě tato architektura?
- Proč byla tabulka sestavena právě tímto způsobem?
- Proč bylo rozhraní implementováno právě takto a ne jinak?
- Proč bylo alternativní řešení zamítnuto?
Právě takové informace se bez dokumentace často ztratí. Pokud je o několik měsíců později třeba něco změnit, ani zkušení vývojáři si často nevzpomínají na všechny souvislosti dřívějších rozhodnutí. Dobrá dokumentace tyto znalosti trvale uchovává.
Přehled projektů jako výchozí bod
Každá dokumentace by měla začínat jasným přehledem projektu. Tato část slouží jako úvod pro všechny zúčastněné. Zde se vysvětluje:
- Jaký je cíl projektu?
- Jaké problémy je třeba vyřešit?
- Jaké jsou hlavní moduly?
- Jaké technologie se používají?
- Jaká je dlouhodobá vize?
Tato část nemusí být nijak rozsáhlá. Často stačí jen pár stránek. Důležité je spíše to, aby nový vývojář nebo nový chatbot s umělou inteligencí v krátké době pochopil, o co vlastně jde.
Přehled projektu představuje v jistém smyslu mapu celého záměru. Bez této mapy se i dobře zdokumentované jednotlivé detaily rychle stanou nepřehlednými.
Dokumentace datového modelu
Podle přehledu projektu patří datový model k nejdůležitějším součástem dokumentace. Téměř každá aplikace je založena na datech. Zákazníci, položky, projekty, faktury, uživatelé nebo dokumenty jsou vzájemně propojeny a tvoří základ systému. Proto by mělo být zdokumentováno:
- Jaké tabulky existují?
- Která pole jsou obzvláště důležitá?
- Jaké vztahy mezi nimi existují?
- Jaká obchodní pravidla platí?
Nejde přitom jen o technické informace. Stejně důležitý je i odborný význam těchto údajů. Samotný název pole často mnoho neříká. Teprve popis jeho funkce objasní, proč existuje a jak by se mělo používat.
Pro systémy umělé inteligence je tento kontext obzvláště cenný. Čím lépe jsou datové struktury popsány, tím přesnější mohou být následné návrhy.
Aktuální průzkum používání místních systémů umělé inteligence
Zaznamenávání architektonických rozhodnutí
Jednou z největších slabin mnoha projektů je to, že architektonická rozhodnutí se přijímají pouze ústně. V okamžiku rozhodnutí se vše jeví jako logické. O několik měsíců později však často není jasné, proč byla zvolena právě tato cesta.
Právě proto se vyplatí zaznamenávat důležitá rozhodnutí. Zaznamenat by se nemělo jen samotné rozhodnutí, ale i jeho odůvodnění.
- Jaké alternativy byly zvažovány?
- Proč byly zamítnuty?
- Jaké výhody nabízí zvolené řešení?
Tento přístup často ušetří v budoucnu spoustu času. Místo toho, aby se musely znovu vést staré diskuse, mohou vývojáři a systémy umělé inteligence čerpat z již existujících informací.
Neuzavřené úkoly a známé problémy
Dobrá dokumentace popisuje nejen aktuální stav, ale i to, co ještě není hotové. Mnoho projektů trpí tím, že nedokončené úkoly jsou roztříštěné na různých místech. Část z nich se nachází v e-mailech, další na poznámkových lístcích a další v záznamech z chatu.
Tím dochází ke ztrátě důležitých informací. Osvědčilo se shromažďovat nevyřešené záležitosti na jednom místě. Patří sem například: plánovaná rozšíření, technický dluh, známé chyby, požadavky na vylepšení a nápady do budoucna.
Zejména u dlouhodobých projektů to poskytuje cenný přehled. Noví vývojáři nebo systémy umělé inteligence tak okamžitě rozpoznají, které oblasti jsou již známé a jaké práce je ještě čekají.
Dokumentace jako živý systém
Častou chybou je vnímat dokumentaci jako jednorázový úkol. Na začátku projektu se vytvoří několik dokumentů, které se poté téměř neaktualizují. Dokumentace tak rychle ztrácí svou hodnotu. Dobrá projektová dokumentace je živá. Roste spolu s projektem. Doplňují se do ní nová rozhodnutí. Zaznamenávají se změny. Zastaralé informace se aktualizují nebo odstraňují.
V ideálním případě k tomu dochází průběžně během vývoje. Moderní systémy umělé inteligence mohou v tomto ohledu dokonce aktivně pomáhat. Umí vytvářet souhrny, dokumentovat změny nebo aktualizovat stávající obsah. Díky tomu se výrazně snižuje pracovní náročnost.
Nejdůležitější investice v rámci projektu
Mnoho vývojářů investuje značné částky do hardwaru, softwarových licencí nebo externích služeb. Přitom se často podceňuje jeden z nejcennějších zdrojů: znalost vlastního projektu.
Právě tyto znalosti dokumentace uchovává. Zajišťuje, aby se zkušenosti neztratily. Zabraňuje tomu, aby se na stejné otázky muselo stále znovu odpovídat. A vytváří společný základ pro lidi i systémy umělé inteligence.
Čím větší je projekt, tím důležitější je tato funkce. Kdo zanedbává dokumentaci, ušetří sice krátkodobě čas, ale dlouhodobě ho často ztratí mnohonásobně více. Kdo naopak včas vybuduje centrální systém znalostí, vytvoří základ, který může přinášet užitek po celá léta.
Proto je projektová dokumentace mnohem víc než jen soubor technických informací. Je to kolektivní paměť projektu – a tím pádem jeden z nejdůležitějších předpokladů pro úspěšný vývoj softwaru s využitím umělé inteligence.
Vibe Coding, struktura a nová generace vývoje softwaru
Přiložené video zajímavým způsobem doplňuje obsah tohoto článku a ukazuje, jak lze již dnes využívat moderní nástroje umělé inteligence k vývoji vlastních aplikací s relativně malým programátorským úsilím. Zvláště je třeba zdůraznit důraz na strukturovaný postup. Místo toho, aby se AI nechala jednoduše „programovat naslepo“, je ukázáno, jak se nejprve pečlivě naplánují nápady, vytvoří se databázové struktury a definují se rozhraní.

Vývoj softwaru s využitím umělé inteligence: správná cesta (namísto chaosu) | Sebastian Claes
Právě tento přístup se shoduje s jedním z hlavních poselství tohoto článku: Úspěšný vývoj softwaru nezačíná u kódu, ale u pochopení požadavků a procesů. Video se dále zabývá aktuálními nástroji, jako jsou n8n, Supabase a MCP, a také možnostmi automatizovaných pracovních postupů. Obzvláště cenné jsou poznámky k typickým chybám při takzvaném „Vibe Coding“ a doporučení pro stabilní, škálovatelné a dlouhodobě udržovatelné aplikace. Video tak poskytuje praktický vhled do moderní spolupráce mezi vývojáři a umělou inteligencí.
Úvodní zprávy pro nové chaty
Jednou z největších předností moderních systémů umělé inteligence je to, že se dokážou v krátké době zorientovat v komplexních tématech. Zároveň však právě tento bod patří i k jejich největším slabostem.
Každý nový chat začíná bez znalosti tvého projektu. Moderní modely samozřejmě disponují rozsáhlými všeobecnými znalostmi. Znají programovací jazyky, databáze, frameworky a mnoho technických pojmů. Co však neznají, jsou specifika tvého projektu.
Neví, jaká architektonická rozhodnutí již byla učiněna. Neznají vaše konvence pro pojmenování. Nevědí nic o předchozích diskusích ani o cílech, které stojí za určitými funkcemi.
Mnoho vývojářů tento bod podceňuje. Otevřou nový chat, položí technickou otázku a pak se diví, že odpověď není pro daný projekt zcela vhodná. Příčinou však často není kvalita umělé inteligence, ale nedostatečné seznámení s projektem. Právě v tomto bodě přicházejí ke slovu startovací podněty.
Co je to vlastně výzva k zadání příkazu
Úvodní výzva není v podstatě nic jiného než standardizovaný úvod pro nové chaty. Obsahuje nejdůležitější informace, které systém umělé inteligence potřebuje, aby se v projektu co nejrychleji zorientoval. Dalo by se to přirovnat k zaškolovacímu balíčku pro nového zaměstnance. Namísto toho, aby se pokaždé znovu vysvětlovaly stejné informace, obdrží AI již na začátku nejdůležitější rámcové podmínky. Tím vzniká společné porozumění způsobu práce ještě předtím, než začne samotný úkol.
Dobrý úvodní pokyn nejen šetří čas. Zajišťuje také, aby různé chatové skupiny fungovaly jednotně a přijímaly podobná rozhodnutí. Čím větší je projekt, tím cennější je tento efekt.
Jasně definovat roli umělé inteligence
Jednou z nejúčinnějších metod je přiřadit umělé inteligenci hned na začátku konkrétní roli. Mnoho vývojářů do svých pokynů uvádí pouze technické požadavky. Často však vede k lepším výsledkům, pokud se navíc popíše i požadovaný úhel pohledu.
Umělá inteligence může například pracovat jako softwarový architekt, senior vývojář, databázový specialista, tester nebo autor dokumentace. Díky tomu se často mění kvalita odpovědí. Umělá inteligence tak získá jasný referenční rámec a může své návrhy lépe přizpůsobit danému úkolu.
V chatu věnovaném architektuře bude klást důraz na jiné aspekty než v chatu věnovaném testování nebo dokumentaci. Tato jasná definice rolí vytváří strukturu a omezuje nedorozumění.
Projektová dokumentace jako povinná četba
Zvláště důležitou součástí mnoha úvodních pokynů by měla být hlavní dokumentace projektu. V ideálním případě by měla být umělá inteligence instruována, aby se nejprve seznámila s dostupnými informacemi, než začne navrhovat změny nebo podávat návrhy.
Tento krok se překvapivě často opomíjí. Mnoho problémů však vzniká právě proto, že nové chatové skupiny pracují bez znalosti stávajících rozhodnutí. Pokud se dokumentace důsledně zapojí do procesu, kvalita spolupráce se často výrazně zlepší.
Umělá inteligence rozpoznává souvislosti rychleji. Lépe chápe stávající struktury a automaticky zohledňuje předchozí rozhodnutí. Díky tomu je v rámci projektu zajištěna podstatně vyšší konzistence.
Dalo by se říci: Dokumentace poskytuje znalosti, zatímco výzva k akci zajišťuje, že tyto znalosti budou skutečně využity.
Vytvořit jednotná pravidla
S rostoucím rozsahem projektu často vzniká potřeba stanovit pevná pravidla.
- Jak se mají pojmenovávat pole?
- Jaké standardy pro dokumentaci platí?
- Jaké architektonické zásady je třeba dodržovat?
- Které programovací směrnice jsou závazné?
Dobrá úvodní výzva může tato pravidla trvale zakotvit. Díky tomu je není nutné při každém novém úkolu znovu vysvětlovat. Umělá inteligence již zná zadání a může své návrhy odpovídajícím způsobem přizpůsobit.
Tento efekt nelze podceňovat. Mnoho drobných nesrovnalostí vzniká jednoduše proto, že pravidla nejsou důsledně sdělována. Úvodní pokyny pomáhají právě tento problém omezit.
Různé úvodní výzvy pro různé úkoly
V průběhu projektu se často ukáže, že ne všechny chaty mají stejné požadavky. Chat zaměřený na architekturu vyžaduje jiné informace než chat zaměřený na dokumentaci. Testovací chat funguje jinak než chat zaměřený na frontend.
Proto se často vyplatí vytvořit několik úvodních pokynů. Jejich společný základ přitom zůstává stejný. Všechny chaty mají stejný přehled projektu, stejnou dokumentaci a stejná základní pravidla.
Kromě toho lze však definovat doplňky specifické pro daný úkol.
- Architektonický chat se zaměřuje na dlouhodobá rozhodnutí.
- Technická realizace backendového chatu.
- Dokumentační chat zaměřený na sledovatelnost a uchovávání znalostí.
- Chat o zajišťování kvality zaměřený na analýzu chyb a kritické posouzení.
Díky této specializaci se často dosahuje výrazně lepších výsledků než při použití univerzálního standardního dotazu.
Úvodní výzvy se vyvíjejí spolu s projektem
Častou chybou je, že se úvodní obrazovka vytvoří jednou a poté se už nikdy neupravuje. V praxi se však každý větší projekt neustále mění.
Vznikají nové moduly. Procesy se mění. Přibývají technická rozhodnutí. Proto by se měly pravidelně kontrolovat i úvodní výzvy. To, co před několika měsíci ještě stačilo, může být dnes již neúplné.
Osvědčilo se považovat úvodní pokyny za živé dokumenty. Rostou spolu s projektem a odrážejí jeho aktuální stav. Díky tomu jsou nové chaty trvale v souladu s nejnovějšími poznatky.
Umělá inteligence má přemýšlet, ne jen plnit příkazy
Zajímavým aspektem moderních systémů umělé inteligence je to, že neumí pouze provádět pokyny. Umí také klást otázky, analyzovat a navrhovat zlepšení. Dobrý úvodní dotaz by proto neměl obsahovat pouze příkazy.
Často se vyplatí výslovně požádat umělou inteligenci, aby upozorňovala na možné problémy. Lze například nastavit, aby hlásila nesrovnalosti nebo aby aktivně upozorňovala na porušení architektonických pravidel. Díky tomu se umělá inteligence mění z pouhého nástroje na dalšího partnera v dialogu.
Samozřejmě nenahrazuje lidské rozhodnutí. Může však pomoci včas odhalit rizika.
Cesta k profesionálnímu přístupu k práci
Mnoho vývojářů začíná s umělou inteligencí pracovat spontánně a intuitivně. To je zcela normální. S rostoucím rozsahem projektu se však ukazuje, že strukturované procesy přinášejí obrovské výhody.
Mezi tyto procesy patří úvodní pokyny. Vytvářejí společný základ pro všechny chaty, omezují opakování a zajišťují konzistentní výsledky. Především však umožňují systematické předávání znalostí.
Právě tento aspekt bude v budoucnu pravděpodobně nabývat na významu. Čím větší budou projekty a čím výkonnější budou systémy umělé inteligence, tím více bude o úspěchu daného projektu rozhodovat kvalita přípravy.
Dobrý úvodní podnět je proto mnohem víc než jen pár úvodních vět. Je to vstupenka do projektu. A často právě tato vstupenka rozhoduje o tom, jak produktivní bude následná spolupráce.
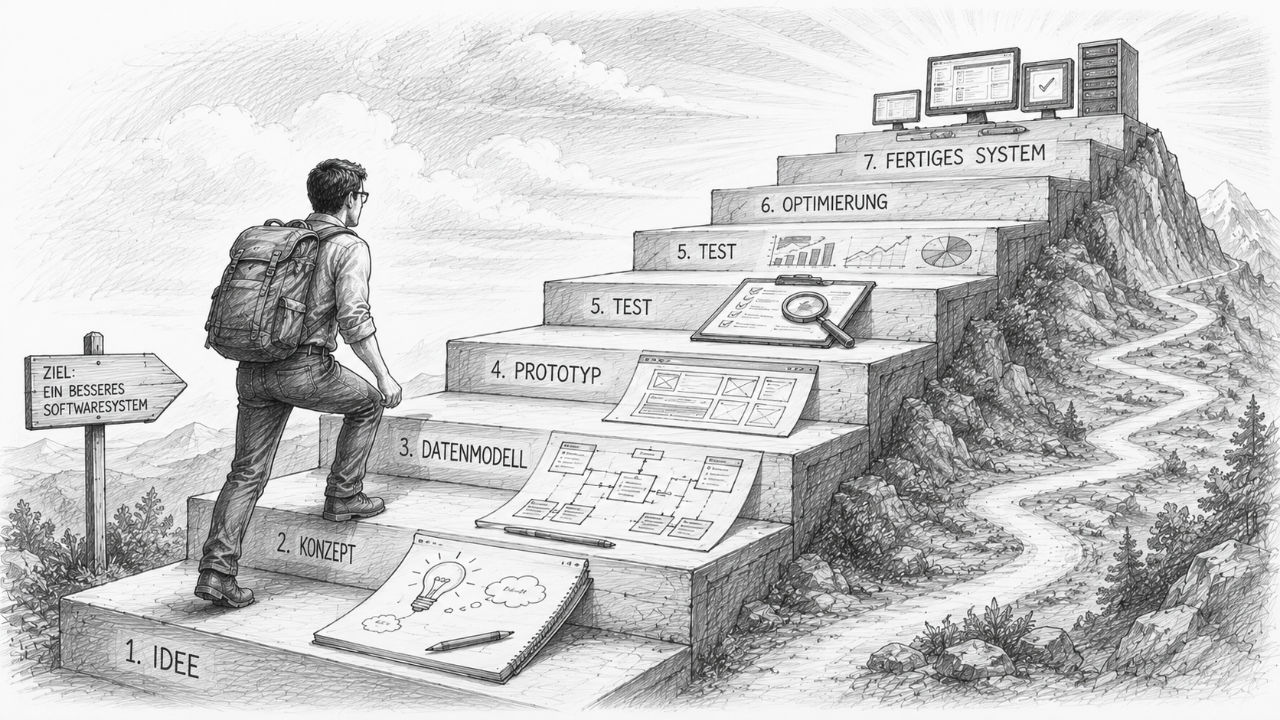
Iterativní vývoj namísto obřích promptů
Kdo poprvé pracuje s moderní umělou inteligencí, často hledá ten jeden zázračný příkaz, který vyřeší všechny problémy. Je to lákavá představa. Člověk co nejpodrobněji popíše svůj projekt, klikne na „Odeslat“ a o chvíli později dostane hotový návrh, kompletní strukturu databáze nebo dokonce celý softwarový systém.
Na první pohled se tento přístup jeví jako logický. Moderní systémy umělé inteligence totiž disponují působivými schopnostmi. Proč by se tedy nemělo zkusit nechat je vyřídit co nejvíce práce najednou?
Praxe však ukazuje něco jiného. Čím větší a složitější je daný úkol, tím důležitější je strukturovaný přístup. Nejlepších výsledků se málokdy dosáhne pomocí jediného obřího příkazu. Vznikají totiž na základě mnoha navazujících kroků.
Stejně jako dům nevzniká v jediném kroku, ale skládá se z plánování, základů, hrubé stavby, vnitřních úprav a dokončovacích prací, i úspěšný software se vyvíjí postupně. Umělá inteligence tento proces urychluje, ale nenahrazuje ho.
Proč jsou rozsáhlé úkoly problematické
Mnoho vývojářů se zpočátku setkává s podobným jevem. Formulují velmi rozsáhlý požadavek a obdrží působivou odpověď. Při bližším prozkoumání však zjistí, že chybí důležité detaily nebo že některé předpoklady k projektu nesedí.
To není tím, že by umělá inteligence fungovala špatně. Spíše se s každým dalším požadavkem zvyšuje složitost úkolu. Čím rozsáhlejší je zadání, tím více souvislostí je třeba zohlednit najednou. Zároveň roste pravděpodobnost, že budou některé body přehlédnuty nebo nesprávně interpretovány.
Zejména u rozsáhlejších softwarových projektů to může rychle vést k problémům. I malá chyba v datovém modelu může mít dopad na celou řadu dalších oblastí. Nejasný požadavek může později způsobit rozsáhlé dodatečné práce. Proto je většinou rozumnější rozdělit velké projekty na menší, lépe zvládnutelné kroky.
Síla malých kroků
Zajímavým rysem moderních systémů umělé inteligence je to, že dokážou na nové informace reagovat mimořádně rychle. Díky tomu je iterativní způsob práce obzvláště atraktivní.
Místo toho, abychom se snažili vyvinout celý systém najednou, se nejprve zaměříme na malou část. Tu otestujeme, vylepšíme a zdokumentujeme. Teprve poté přejdeme k dalšímu kroku.
Tento přístup připomíná moderní agilní metody vývoje. Namísto toho, aby se měsíce pracovalo na jednom velkém konečném výsledku, vzniká mnoho malých průběžných výsledků. Každý z těchto výsledků lze vyhodnotit a v případě potřeby opravit. Tím se riziko výrazně snižuje. Chyby se odhalí dříve a úpravy lze provádět snáze.
Od obecného k detailu
Osvědčeným postupem je nejprve definovat širší souvislosti. Na začátku stojí otázky jako:
- Jaký problém je třeba vyřešit?
- Jaké hlavní moduly jsou potřebné?
- Kteří uživatelé systém používají?
- Jaké údaje je třeba spravovat?
Teprve až budou tyto základy vyjasněny, přejdeme k další úrovni.
- Nyní se podíváme na podrobnější popis jednotlivých modulů.
- Na základě toho vznikají datové modely, procesy a uživatelská rozhraní.
- Následují technické podrobnosti a konkrétní implementace.
Tento postupný přechod od obecného k konkrétnímu má velkou výhodu. Umělá inteligence může každou úroveň rozvíjet na základě již ověřených rozhodnutí. Tím vzniká podstatně stabilnější struktura.
Význam průběžných zkoušek
Častou chybou je, že se výsledky přijímají okamžitě, aniž by se dostatečně zpochybňovaly. Právě proto, že umělá inteligence pracuje tak rychle, vzniká někdy pokušení přejít ihned k dalšímu kroku. Z dlouhodobého hlediska je však často rozumnější po každé důležité fázi vědomě se zastavit.
- Odpovídá výsledek cílům projektu?
- Byly zohledněny všechny požadavky?
- Existují nějaké možné slabiny?
- Jsou rozhodnutí srozumitelně zdokumentována?
Takové průběžné kontroly sice zabírají trochu času, ale často ušetří značné úsilí v pozdějších fázích projektu. Čím dříve se problémy odhalí, tím levněji se dají napravit.
Iterace jako proces učení
Další výhodou iterativního vývoje je to, že se učí nejen umělá inteligence, ale i samotný vývojář. Mnohé požadavky se skutečně projeví až v průběhu práce.
- Proces, který se zpočátku jevil jako smysluplný, se může ukázat jako nepraktický.
- Je třeba rozšířit datovou strukturu.
- Uživatelské rozhraní vyžaduje další informace.
Takové poznatky jsou nedílnou součástí každého projektu. Díky iterativnímu přístupu se nestávají překážkou, ale přirozenou součástí vývoje. Každá iterace přispívá k lepšímu společnému porozumění systému. Díky tomu se kvalita postupně zvyšuje.
Proč je dokonalost na začátku málokdy smysluplná
Mnoho vývojářů se snaží najít dokonalá řešení již během prvních jednání. Je to pochopitelné, ale často to není nutné. V praxi se ty nejlepší systémy většinou vyvíjejí prostřednictvím mnoha drobných vylepšení.
První verze datového modelu nemusí být dokonalá. Stejně tak ani první uživatelské rozhraní. Důležitější je, aby vznikl funkční základ, který bude možné dále rozvíjet.
Právě v tomto ohledu se naplno projevují přednosti umělé inteligence. Umožňuje rychlé úpravy a podporuje neustálé zlepšování. Díky tomu je mnohem snazší nápady vyzkoušet a postupně je vylepšovat.
Umělá inteligence jako sparringpartner
 Kdo pracuje iterativně, nepoužívá umělou inteligenci pouze jako nástroj k provádění úkolů. Stává se z ní partner pro dialog. Lze s ní diskutovat o nových nápadech. Lze porovnávat alternativy. Lze analyzovat rizika. K tématu „Umělá inteligence jako sparingpartner“ o tom jsem již v minulosti napsal podrobný článek.
Kdo pracuje iterativně, nepoužívá umělou inteligenci pouze jako nástroj k provádění úkolů. Stává se z ní partner pro dialog. Lze s ní diskutovat o nových nápadech. Lze porovnávat alternativy. Lze analyzovat rizika. K tématu „Umělá inteligence jako sparingpartner“ o tom jsem již v minulosti napsal podrobný článek.
Díky tomu je vývoj dynamičtější. Namísto toho, aby se muselo dlouho čekat na realizaci nápadu, vznikají během krátké doby konkrétní návrhy, které lze následně vyhodnotit a vylepšit.
Tento dialog často vede k lepším výsledkům než striktní plánování na několik měsíců dopředu.
Cesta k lepším výsledkům
Čím větší je projekt, tím jasněji se projevuje výhoda iterativního způsobu práce. Velké systémy málokdy vznikají na základě jediného geniálního návrhu. Vznikají na základě mnoha rozhodnutí, která na sebe navazují.
- Každý krok přináší nové poznatky.
- Každá iterace přispívá k lepšímu porozumění.
- Každá kontrola zvyšuje kvalitu.
Moderní systémy umělé inteligence tento proces výrazně urychlují. Nenahrazují ho však. Vývojáři by proto měli odolat pokušení řešit vše v jediném obřím příkazu.
Nejúspěšnější projekty většinou nevznikají díky nejambicióznějšímu zadání. Vznikají díky mnoha promyšleným malým krokům, které dohromady tvoří velký celek. A právě v tom spočívá jedna z nejdůležitějších pouček moderního vývoje softwaru založeného na umělé inteligenci.

Umělá inteligence jako virtuální tým vývojářů
Mnoho lidí stále vnímá umělou inteligenci jako mimořádně výkonný nástroj. Tento pohled není mylný, často však není dostatečně komplexní. Kdo delší dobu pracuje s moderními systémy umělé inteligence, dříve či později zažije zajímavou zkušenost. Spolupráce se čím dál méně jeví jako používání nástroje a čím dál více jako spolupráce s týmem.
Umělá inteligence samozřejmě nemá žádné vědomí, žádné vlastní zájmy ani osobní odpovědnost. Přesto však může zastávat různé role, přinášet různé úhly pohledu a zpracovávat úkoly, které by dříve byly rozděleny mezi několik zaměstnanců.
Právě v tom spočívá jeden z nejzajímavějších trendů v oblasti moderního vývoje softwaru. Skutečná síla často nespočívá v tom, že by jedna konkrétní umělá inteligence byla obzvláště inteligentní. Vzniká spíše kombinací několika specializovaných postupů.
Vývojáře to nenahradí. Jeho role se spíše posouvá směrem ke koordinaci, řízení a kontrole kvality.
Proč často nestačí jediný úhel pohledu
V klasických softwarových projektech málokdy všichni účastníci sdílejí stejný úhel pohledu. Architekt uvažuje jinak než programátor. Tester se zaměřuje na jiné aspekty než designér. Projektový manažer klade jiné otázky než databázový specialista. Tyto odlišné úhly pohledu mají velkou výhodu: chyby se odhalí dříve a řešení se posuzují z více úhlů pohledu.
Právě tento princip se dá překvapivě dobře aplikovat na systémy umělé inteligence. Místo toho, aby se umělá inteligence využívala výhradně jako programátor, lze jí přiřadit různé role a nechat ji nahlížet na stejný problém z různých úhlů pohledu.
Díky tomu se často dosahuje výrazně lepších výsledků. Například chat zaměřený na architekturu může navrhnout řešení, zatímco chat zaměřený na kontrolu kvality toto řešení kriticky prověří.
Diskuse sice probíhá v rámci různých útvarů zabývajících se umělou inteligencí, řídí se však stejnými zásadami jako v klasických vývojářských týmech.
Virtuální softwarový architekt
Zvláště důležitou roli hraje softwarový architekt. Tento chat se nezabývá tolik jednotlivými funkcemi, ale spíše dlouhodobými dopady rozhodnutí.
- Jaká struktura je vhodná?
- Které moduly by se měly oddělit?
- Jak lze zohlednit budoucí rozšíření?
- Jaká rizika vyplývají z určitých rozhodnutí ohledně designu?
Zatímco vývojáři se pochopitelně často soustředí na aktuální úkol, virtuální architekt nahlíží na systém jako na celek. Tím vzniká další úroveň zabezpečení.
Mnoha pozdějším problémům lze předejít, pokud se základní architektonické otázky promyslí včas. Zejména u větších projektů může mít tento přístup obrovský přínos.
Virtuální vývojář
Nejviditelnější rolí zůstává samozřejmě role vývojáře. Právě zde vznikají konkrétní řešení, dotazy do databází, rozhraní, uživatelská rozhraní a obchodní logika. Produktivita moderních systémů umělé inteligence je v této oblasti impozantní. Úkoly, které dříve trvaly několik hodin či dnů, lze často připravit během několika minut.
Při tom by však neměl být opomenut jeden důležitý bod. Rychlost realizace nesmí vést k tomu, že se upustí od analýzy a kontroly. I ten nejlepší virtuální vývojář potřebuje jasné zadání, srozumitelné cíle a kvalitní dokumentaci.
Čím lepší je tento základ, tím lepší jsou zpravidla výsledky.
Virtuální tester
V mnoha projektech je stále podceňována jedna role: role testera. Vývojáři se pochopitelně soustředí na vytváření řešení. Testeři se soustředí na hledání problémů.
Tento přístup se zásadně liší. Testovací chat dokáže cíleně vyhledávat slabá místa. Může simulovat chybové situace, zkoumat mezní podmínky a klást kritické otázky.
- Co se stane v případě neplatného zadání?
- Jak se systém chová v případě chybějících údajů?
- Jaké bezpečnostní problémy by mohly nastat?
- Jaké výjimky byly opomenuty?
Tento pohled často vede k poznatkům, které během samotného vývoje nebyly patrné. Proto se často vyplatí nechat nové funkce prověřit samostatnou rolí umělé inteligence.
Virtuální autor dokumentace
Dokumentace patří jen málokdy k nejoblíbenějším úkolům v rámci projektu. Zároveň však patří k těm nejdůležitějším. Virtuální dokumentarista může pomoci systematicky uchovávat znalosti. Vytváří popisy projektů, dokumentuje rozhodnutí, shrnuje jednání a spravuje technickou dokumentaci.
Zvláštní výhodou je, že tuto práci lze provádět souběžně s vývojem. Namísto toho, aby se dokumentace doplňovala až na konci, stává se nedílnou součástí celého projektu.
Díky tomu zůstávají znalosti trvale dostupné a noví členové týmu – ať už lidé, nebo umělá inteligence – se mohou do práce zapracovat podstatně rychleji.
Virtuální kritik
Zvláště zajímavou roli hraje kritický hodnotitel. Tento chat sleduje jiný cíl než ostatní účastníci.
Neměl by jen souhlasit. Měl by věci zpochybňovat.
Analyzuje předpoklady, hledá slabá místa a prověřuje, zda jsou rozhodnutí skutečně smysluplná. Právě vývojáři mají někdy sklon „zamilovat se“ do určitého řešení. To je lidské. Kritický chat s umělou inteligencí může pomoci odhalit alternativní úhly pohledu.
- Možná existuje jednodušší řešení.
- Možná byl přehlédnut nějaký důležitý požadavek.
- Možná z toho vyplynou dlouhodobá rizika.
Takové rady jsou často velmi cenné.
Člověk zůstává vedoucím projektu
Přes veškeré nadšení z moderních systémů umělé inteligence by však jedna věc měla zůstat jasná. Odpovědnost leží na člověku. Umělá inteligence může předkládat návrhy. Může analyzovat, prověřovat a dokumentovat. Dokonce dokáže simulovat různé scénáře. Konečná rozhodnutí však i nadále činí vývojář, podnikatel nebo vedoucí projektu.
To dává smysl. Pouze lidé znají obchodní cíle projektu. Pouze lidé dokážou komplexně posoudit ekonomické, právní či strategické aspekty.
Umělá inteligence rozšiřuje možnosti. Nenahrazuje však odpovědnost.
Budoucnost týmové práce
Čím déle s umělou inteligencí pracujeme, tím jasnější je, že úspěšné projekty se stále více podobají spolupráci mezi lidmi a odborníky na digitální technologie. Vývojář již nepracuje sám. Zároveň však není nahrazen. Místo toho vzniká nová forma týmové práce.
Člověk udává směr, přijímá rozhodnutí a nese odpovědnost za výsledek. Řada specializovaných rolí umělé inteligence mu pomáhá s analýzou, vývojem, dokumentací, testováním a zajišťováním kvality.
Právě v tom by mohla spočívat jedna z největších změn nadcházejících let. Rozhodující nebude otázka, zda umělá inteligence nahradí lidi. Rozhodující bude otázka, jak dobře se lidé naučí spolupracovat s virtuálním týmem vývojářů.
Kdo tuto spolupráci zvládne, bude v budoucnu schopen realizovat softwarové projekty často rychleji, strukturovaněji a s vyšší kvalitou než kdykoli předtím.
AI agenti, dovednosti a další fáze vývoje softwaru
Video Fraunhofer IEM, které je zde vloženo, se zabývá myšlenkou, která se v tomto článku několikrát objevuje: Budoucnost vývoje softwaru by mohla být méně ovlivněna jednotlivými aplikacemi a mnohem více znalostmi, kontextem a specializovanými agenty umělé inteligence. V centru pozornosti jsou takzvané „skills“ – strukturované moduly znalostí a úkolů, které umožňují systémům umělé inteligence samostatně provádět složité činnosti.

AI agenti a dovednosti: Znamená to konec klasického vývoje softwaru? | Fraunhofer IEM
Zvláště zajímavá je zde paralela s moderním vývojem softwaru založeným na umělé inteligenci: v popředí již nestojí jednotlivé řádky kódu, ale popis procesů, pravidel a souvislostí. Video srozumitelně vysvětluje, jak mohou technologie jako MCP (Model Context Protocol), agentní systémy a centrální zdroje znalostí spolupracovat. Diskutuje se také otázka, zda bude klasický software v dlouhodobém horizontu doplněn nebo částečně nahrazen flexibilními agentními systémy. Bez ohledu na to, jak rychle tento vývoj postupuje, video působivě ukazuje, proč by kontext, dokumentace a znalostní management mohly v budoucnu patřit k nejdůležitějším zdrojům moderních softwarových projektů.
Typické chyby při vývoji s využitím umělé inteligence
Historie techniky se opakuje podle podobného vzorce. Jakmile se objeví nové nástroje, mnoho lidí se nejprve soustředí na jejich možnosti a mnohem méně na rizika. Tak tomu bylo u prvních počítačů, u databází, při zavádění internetu a dnes u umělé inteligence.
Toto nadšení je pochopitelné. Moderní systémy umělé inteligence dokážou během několika minut zvládnout úkoly, které dříve trvaly hodiny či dny. Analyzují požadavky, vytvářejí návrhy, píší kód a pomáhají s dokumentací.
Právě tato rychlost však někdy vede k problémům. Mnoho chyb nevzniká proto, že by umělá inteligence odváděla špatnou práci. Vznikají proto, že lidé nesprávně odhadují způsob fungování umělé inteligence nebo opomíjejí důležité základní principy.
Kdo chce v oblasti vývoje s využitím umělé inteligence dlouhodobě uspět, měl by proto znát nejčastější úskalí.
Chyba číslo 1: Příliš málo kontextu
Pravděpodobně nejčastější chybou je poskytnout umělé inteligenci příliš málo informací. Mnoho vývojářů formuluje velmi stručné zadání a přesto očekává vysoce přesné výsledky.
- Umělá inteligence má vyvinout určitou funkci, ale nezná podrobnosti projektu.
- Má navrhnout strukturu databáze, ale neví nic o obchodních procesech.
- Má navrhnout uživatelské rozhraní, ale nezná budoucí uživatele.
Umělá inteligence samozřejmě může i tak poskytnout odpovědi. Bude se snažit na základě svých obecných znalostí učinit smysluplné předpoklady. Problém spočívá v tom, že tyto předpoklady nemusí nutně odpovídat vašemu projektu. Čím větší je mezera ve znalostech, tím větší je pravděpodobnost nedorozumění.
Proto platí jednoduché pravidlo: Pokud výsledek neodpovídá očekáváním, příčinou často není umělá inteligence, ale chybějící kontext.
Chyba číslo 2: Příliš rozsáhlé úkoly
Další častou chybou je svěřovat umělé inteligenci příliš mnoho úkolů najednou. Zejména začátečníci mají tendenci formulovat velmi rozsáhlé pokyny. Chtějí nechat vyvinout kompletní ERP systém, naplánovat celou platformu nebo vytvořit ucelený podnikový software.
Tento názor je pochopitelný. Koneckonců, výkonnost moderních modelů je skutečně působivá. V praxi však nejlepších výsledků většinou dosáhneme postupným postupem. Velké projekty by se měly rozdělit na menší, jasně definované úkoly.
- Nejprve se vypracuje architektonický návrh.
- A teď datový model.
- Následně jednotlivé moduly.
- A pak uživatelská rozhraní.
- Na závěr testy a optimalizace.
Tento postup nejen zvyšuje kvalitu výsledků, ale také usnadňuje kontrolu. Malé kroky se dají zkontrolovat mnohem snáze než obrovská komplexní řešení.
Chyba číslo 3: Chybějící dokumentace
Mnozí vývojáři tento problém již znají z klasických projektů. Dokud mají vše čerstvě v paměti, zdá se dokumentace zbytečná. O několik týdnů či měsíců později však situace většinou vypadá jinak.
- Proč byla tato tabulka vytvořena?
- Proč bylo přijato právě toto architektonické rozhodnutí?
- Proč bylo upřednostněno právě toto řešení?
Bez dokumentace se takové informace ztratí. U projektů v oblasti umělé inteligence má tato chyba často ještě závažnější dopady. Nové chatovací systémy nemají přehled o předchozích konverzacích. Noví členové projektu neznají souvislosti. Důležitá rozhodnutí je třeba neustále znovu vysvětlovat.
To vede k zbytečným diskusím a zdvojování práce. Důsledná projektová dokumentace proto patří k nejdůležitějším faktorům úspěchu moderního vývoje softwaru.
Chyba číslo 4: Slepá důvěra
Kvalita dnešních systémů umělé inteligence může být ohromující. Právě proto někdy vzniká nebezpečné pokušení. Člověk přestává výsledky dostatečně zpochybňovat. K této chybě dochází obzvláště často u vývojářů, kteří právě zaznamenali své první větší úspěchy s umělou inteligencí.
Najednou fungují složité dotazy. Rozhraní se vytvářejí automaticky. Dokumentace vzniká během několika minut. Přes veškerý pokrok však platí jedna důležitá skutečnost:
- Umělá inteligence může dělat chyby.
- Může nesprávně interpretovat souvislosti.
- Může vycházet ze zastaralých předpokladů.
- Může vyvinout technická řešení, která sice vypadají věrohodně, ale přesto mají své slabiny.
Proto by se každé důležité rozhodnutí mělo pečlivě zvážit. Důvěra má smysl. Slepá důvěra však málokdy.
Chyba číslo 5: Přeskakování mezi chaty bez systému
S rostoucími zkušenostmi s projekty často vzniká mnoho různých chatů. To je v zásadě užitečné. Problém však nastává, pokud neexistuje jednotná struktura. Důležité informace se pak nacházejí na různých místech.
- Architektonická rozhodnutí se přijímají v chatu.
- Dokumentace vznikají v jiném.
- Nové funkce se vyvíjejí ve třetí verzi.
Po několika týdnech už nikdo přesně neví, kde se která informace nachází. Důsledkem jsou rozpory, nesrovnalosti a zbytečná práce navíc. Proto by projekty měly být od samého začátku jasně organizovány.
Specializované chaty jsou užitečné, vyžadují však společnou znalostní základnu a centrální dokumentaci. Pouze tak lze vytvořit ucelený systém.
Chyba číslo 6: Považovat umělou inteligenci za věštce
Dalším omylem je vnímat umělou inteligenci jako neomylnou autoritu. Mnohé odpovědi působí přesvědčivě. Právě v tom někdy spočívá nebezpečí. Umělá inteligence často prezentuje své návrhy s velkou jistotou, i když existují nejistoty. To neznamená, že záměrně klame. Jednoduše pracuje na základě statistických pravděpodobností.
Proto by se člověk měl naučit nahlížet na odpovědi kriticky. Ne každá elegantní formulace je automaticky správná. Ne každé technicky znějící vysvětlení je automaticky správné. Umělá inteligence poskytuje návrhy, nikoli definitivní pravdy.
Čím dříve si tento přístup osvojíte, tím lepší bude spolupráce.
Chyba číslo 7: Nepřizpůsobení procesů
Někteří vývojáři se snaží pracovat s umělou inteligencí přesně tak, jako dříve bez ní. Nové nástroje využívají pouze jako rychlejší generátor kódu.
Tím přicházejí o velkou část potenciálu. Skutečná síla moderní umělé inteligence nespočívá pouze v psaní kódu. Spočívá v analýze, dokumentaci, plánování, zajištění kvality a správě znalostí.
Kdo nepřizpůsobí svůj způsob práce, využívá často jen malou část dostupných možností. Úspěšní vývojáři se proto učí své procesy dále rozvíjet. Systematicky začleňují umělou inteligenci do svých pracovních postupů a vytvářejí nové formy spolupráce.
Chyby jsou součástí procesu učení
Navzdory všem varováním by se nemělo zapomínat na jednu důležitou věc. Chyby jsou normální. Každá nová technologie vyžaduje zkušenosti. Nikdo nevytváří hned od začátku dokonalé pokyny, dokonalou dokumentaci ani dokonalé procesy.
I spolupráce s umělou inteligencí je v konečném důsledku dovednost, kterou si člověk osvojuje prostřednictvím praktických zkušeností. S každým projektem roste pochopení toho, které informace jsou důležité, jaké pracovní postupy fungují a jakých chyb je třeba se vyvarovat.
Právě proto by se neúspěchy neměly považovat za selhání. Často jsou pouze známkou toho, že daný proces lze vylepšit.
Při pohledu na nejčastější chyby se objevuje zajímavý vzorec. Většina problémů má překvapivě málo společného s programováním. Vznikají kvůli chybějícím informacím, nedostatečné struktuře, nedostatečné dokumentaci nebo nesprávným očekáváním.
Technická realizace často nepředstavuje největší výzvu. Skutečnou výzvou je uspořádat znalosti, zprostředkovat souvislosti srozumitelným způsobem a smysluplně zorganizovat spolupráci mezi člověkem a umělou inteligencí.
Kdo tyto základy ovládá, vyvaruje se automaticky mnoha typických chyb. A právě díky tomu vzniká nakonec nejen lepší kód, ale většinou i výrazně lepší software.

Nepoužívejte Codex, dokud si toto video neprohlédnete! (Superaplikace ChatGPT) | Everlast AI
Praktický příklad rozsáhlejšího projektu
Dosud jsme se zabývali především zásadami. Mluvili jsme o tom, proč je kontext důležitější než kód, proč hraje dokumentace klíčovou roli a jak lze větší projekty rozdělit do několika specializovaných chatů.
Jak to ale vypadá v praxi? Odpověď zní: překvapivě nenápadně.
Mnoho lidí si vývoj založený na umělé inteligenci představuje tak, že stačí zadat jediný příkaz a o pár hodin později dostanou hotový softwarový systém. Tyto představy ještě umocňují propagační videa a působivé ukázky.
Skutečnost je jiná. I s využitím umělé inteligence vznikají velké projekty krok za krokem. Rozdíl nespočívá v tom, že by se plánování a struktura staly zbytečnými. Naopak: jsou důležitější než kdykoli předtím.
Abychom to lépe vysvětlili, podíváme se v této kapitole na typický příklad vývoje rozsáhlejšího softwarového systému. Nejde přitom o konkrétní produkt, ale o zobecněný vývojový proces, jaký se může vyskytovat v mnoha projektech.
Myšlenka projektu
Téměř každý projekt začíná nápadem. Člověk si všimne problému, mezery na trhu nebo neefektivního pracovního postupu a na základě toho vytvoří vizi nového softwarového řešení.
Právě v tomto bodě často začíná první spolupráce s umělou inteligencí. Místo toho, abychom hned hovořili o databázích nebo uživatelských rozhraních, nejprve se popíše samotný cíl.
- Jaký problém je třeba vyřešit?
- Kdo bude tento software později používat?
- Jaké výhody by měla přinášet?
- Jaká řešení již existují?
Tento první krok se často jeví jako jednoduchý, má však obrovský význam. Čím jasněji je projektová myšlenka formulována, tím snáze se umělé inteligenci daří zařadit pozdější rozhodnutí do správného kontextu. Dobrý popis projektu se tak stává jakousi kompasem pro všechny další fáze vývoje.
Vzniká datový model
Po definování základních cílů začíná samotná strukturalizace projektu. V mnoha případech se nejprve soustředíme na data.
- Jaké informace je třeba uchovávat?
- Jaké objekty existují?
- Jaké vztahy mezi nimi existují?
Zde se již projevuje jedna z velkých výhod moderních systémů umělé inteligence. Mohou pomoci odhalit souvislosti, které by člověku samému možná unikly.
Zodpovědnost však zůstává na vývojáři. Umělá inteligence může předkládat návrhy, ukazovat alternativy a navrhovat struktury. Zda jsou tyto návrhy skutečně smysluplné, je však třeba i nadále odborně posoudit.
Často vznikne několik návrhů, které se následně projednávají a upřesňují. Cílem není vytvořit datový model co nejrychleji, ale vyvinout datový model, který bude dlouhodobě udržitelný.
Definice architektury
S rostoucí jasností ohledně dat začíná další fáze. Nyní vyvstává otázka, jak by měly jednotlivé součásti systému spolupracovat.
- Jaké moduly jsou potřeba?
- Jaká rozhraní jsou nutná?
- Jak se mají rozšíření integrovat v budoucnu?
Právě v této fázi se projevuje síla specializovaných chatů. Chat zaměřený na architekturu se může soustředit na dlouhodobé strukturální otázky, zatímco jiné chaty již vypracovávají první podrobné návrhy.
Současně s tím se rozšiřuje projektová dokumentace. Každé důležité rozhodnutí se zaznamenává. Nejen výsledek, ale i odůvodnění, které za ním stojí. Tímto způsobem se krok za krokem vytváří přehledná znalostní základna.
První prototypy
Nastane okamžik, kdy se teorie setká s praxí.
- Vznikají první prototypy.
- Navrhují se uživatelská rozhraní.
- Probíhá testování dotazů do databáze.
- Simulují se pracovní postupy.
Mnozí vývojáři zde zaznamenávají zajímavý jev. První viditelné výsledky jsou obrovskou motivací. Zároveň však vyvstávají nové otázky, které během plánování nebyly zřejmé. Možná chybí určitá pole. Možná je třeba upravit procesy. Možná se ukáže, že původní předpoklad není udržitelný.
To je zcela normální. Vývoj softwaru není lineární proces. I v případě umělé inteligence se kvalita dosahuje opakovanými iteracemi a neustálým zlepšováním.
Spolupráce několika rolí umělé inteligence
S rostoucím rozsahem projektu nabývá rozdělení práce na významu. Vývojář již nepracuje s jedinou umělou inteligencí, ale s několika specializovanými rolemi.
- Chat analyzuje architekturu.
- Jiný vyvíjí funkce.
- Třetí dokumentuje rozhodnutí.
- Čtvrtý prověřuje možné slabiny.
Výsledkem je způsob práce, který se překvapivě podobá klasickým vývojářským týmům. Rozhodujícím rozdílem je, že tyto role jsou flexibilní a mohou velmi rychle přecházet mezi různými úkoly.
I přesto zůstává hlavní rozhodovací pravomoc v rukou člověka. On rozhoduje, které návrhy budou přijaty a které ne.
Význam průběžné dokumentace
V průběhu rozsáhlejších projektů se stále více ukazuje, proč hraje dokumentace tak klíčovou roli. Zpočátku se projekt jeví jako přehledný. Po několika měsících však často existují stovky rozhodnutí, četné moduly a množství technických detailů.
Bez dokumentace by značná část těchto znalostí byla ztracena. Proto není dokumentace vnímána jako nepříjemná povinnost, ale jako aktivní součást vývoje. Noví členové týmu se tak mohou rychle zaučit. Dřívější rozhodnutí zůstávají srozumitelná. Celý projekt se tak stává z dlouhodobého hlediska lépe udržovatelným.
Právě v případě vývoje založeného na umělé inteligenci patří tento bod k nejdůležitějším faktorům úspěchu vůbec.
Nevyhnutelné změny
Žádný větší softwarový projekt nezůstává beze změny. Objevují se nové požadavky. Přání zákazníků se mění. Technologie se neustále vyvíjejí. Některé nápady se ukážou jako vynikající, jiné jako méně proveditelné.
Proto by každá architektura měla být dostatečně flexibilní, aby dokázala reagovat na změny. Zde se opět ukazuje význam kvalitní dokumentace a jasné struktury. Čím lepší jsou základy, tím snáze lze provádět pozdější úpravy.
Umělá inteligence může pomoci analyzovat dopady změn a navrhovat alternativy. Strategické rozhodnutí však zůstává i nadále na vývojáři.
Co mají úspěšné projekty společného
Při pohledu na různé projekty v oblasti umělé inteligence se stále opakují podobné vzorce. Úspěšné projekty začínají jasnou vizí. Mají srozumitelnou strukturu. Důležitá rozhodnutí jsou v nich zdokumentována. Rozdělují velké úkoly na menší části.
A AI nepovažují za zázračné řešení, ale za výkonného partnera v rámci širšího vývojového procesu. Skutečná síla moderní AI nespočívá v tom, že by dokázala vytvářet software pouhým stisknutím tlačítka. Její síla spočívá v tom, že podporuje vývojáře při analýze, plánování, realizaci a dokumentaci. Právě tím vznikají nové možnosti.
Cesta je důležitější než první zadání
Kdo s umělou inteligencí programuje poprvé, často hledá ten „dokonalý“ příkaz. Po několika větších projektech se tento pohled většinou změní. Úspěch projektu málokdy závisí na jediném příkazu. Rozhodující je spíše celý proces.
- Myšlenka projektu.
- Analýza.
- Architektura.
- Dokumentace.
- Spolupráce různých rolí.
- Neustálé zlepšování.
Umělá inteligence může být v těchto oblastech nápomocná. Nenahrazuje však nutnost strukturovaného uvažování a systematické práce. Úspěšný vývoj s využitím umělé inteligence se proto v konečném důsledku podobá úspěšnému vývoji softwaru obecně.
Rozdíl spočívá pouze v tom, že dnes máme k dispozici mnohem výkonnější nástroje. A právě proto o úspěchu projektu nerozhodne ten nejlepší prompt, ale kvalita celého vývojového procesu.

Budoucnost vývoje softwaru
Kdo sleduje aktuální diskusi o umělé inteligenci, mohl by snadno nabýt dojmu, že už je vše rozhodnuto. Jedni jsou přesvědčeni, že vývojáři brzy ztratí smysl. Druzí považují umělou inteligenci za krátkodobý fenomén, který za pár let zase zmizí.
Na základě dosavadních zkušeností považuji oba pohledy za příliš zjednodušující. Skutečný vývoj teprve začíná.
Zatímco píšu tento článek, sám pracuji na rozsáhlém softwarovém projektu, který je od samého počátku vyvíjen s podporou umělé inteligence. Nejde přitom jen o to, nechat umělou inteligenci psát kód. Mnohem zajímavější je otázka, jak se změní vývojové procesy, když je najednou trvale k dispozici inteligentní asistent.
Již po několika týdnech se projevují zřetelné rozdíly oproti tradičnímu způsobu práce. Nápady lze ověřovat rychleji. Koncepty vznikají v kratším čase. Dokumentace se rozšiřuje téměř automaticky spolu s projektem. Zároveň je však zřejmé, že dobré výsledky i nadále závisí na jasných strukturách, pečlivém plánování a srozumitelné komunikaci.
Nástroje se mění. Základní principy kvalitního vývoje softwaru však zůstávají překvapivě neměnné.
Od programování k systémovému myšlení
Po mnoho desetiletí stála v centru pozornosti samotná programování. Kdo chtěl vyvíjet software, musel ovládat programovací jazyky, učit se knihovny a sám psát velké množství kódu.
Tato situace se postupně mění. Kód se stále více stává zdrojem, který lze automatizovat. Skutečná výzva se přesouvá směrem k analýze, architektuře a porozumění systému.
Vývojář budoucnosti bude pravděpodobně trávit méně času psaním jednotlivých funkcí a podstatně více času popisem systémů, analýzou požadavků a koordinací souvislostí.
Schopnost srozumitelně formulovat složité souvislosti je proto důležitější než kdykoli předtím. V jistém smyslu se vracíme k samotným základům vývoje softwaru. V centru pozornosti nestojí syntaxe programovacího jazyka, ale pochopení problému.
Dokumentace se stává klíčovým prvkem
Jeden trend je již dnes jasně patrný. Zatímco dokumentace byla dříve často považována za nutné zlo, stává se nyní stále častěji ústředním prvkem mnoha projektů.
Systémy umělé inteligence mohou pracovat pouze s informacemi, které mají k dispozici. Čím lépe je projekt zdokumentován, tím produktivnější může být spolupráce. Tím dochází k zajímavému posunu.
Dokumentace již neslouží výhradně lidem. Stává se zároveň znalostní bází pro digitální asistenty. Dalo by se říci, že moderní projekty se stále častěji skládají ze dvou úrovní. Na jedné straně je samotný software. Na druhé straně je znalostní báze, která popisuje, proč tento software vůbec existuje a jak funguje.
Obě oblasti se v budoucnu pravděpodobně budou stále více propojovat.
Virtuální týmy namísto jednotlivých nástrojů
Také spolupráce s umělou inteligencí se bude dále rozvíjet. V současnosti mnoho vývojářů stále pracuje s jednotlivými chaty nebo jednotlivými modely. V budoucnu budeme pravděpodobně stále častěji pracovat s celými skupinami specializovaných systémů umělé inteligence.
- Architekturu navrhuje systém.
- Další vyvíjí funkce.
- Další vytváří testy.
- Další se stará o dokumentaci.
Člověk v tomto případě přebírá roli vedoucího projektu a určuje směr. Tento model se již dnes překvapivě velmi podobá klasickým vývojářským týmům. Rozdíl spočívá pouze v tom, že členové týmu jsou digitální a mohou během několika vteřin přecházet mezi různými úkoly.
Význam lidské zkušenosti
I přes veškerý technický pokrok platí jedna věc: zkušenosti neztrácejí na významu. Naopak. Čím výkonnější jsou nástroje, tím cennější je schopnost činit správná rozhodnutí.
- Umělá inteligence může předkládat návrhy.
- Umí analyzovat.
- Může navrhnout alternativy.
- Dokáže dokonce odhalit chyby.
Odpovědnost za konečná rozhodnutí však zůstává na člověku. Kdo rozumí procesům, dokáže rozpoznat souvislosti a uvažovat v dlouhodobém horizontu, bude mít i v budoucnu obrovskou výhodu.
Skutečná síla nevychází pouze z umělé inteligence. Vzniká spojením lidských zkušeností s umělou inteligencí.
Od chatovacího robota s umělou inteligencí k projektové paměti
 Kdo vyvíjí rozsáhlejší softwarové projekty s využitím umělé inteligence, brzy zjistí, že úzkým hrdlem není kód, ale znalosti o projektu. Požadavky, architektonická rozhodnutí, datové modely a diskuse se často hromadí v průběhu týdnů či měsíců. Právě zde vzniká zajímavá souvislost s tématem exportu dat. Mnohé z těchto informací jsou totiž již k dispozici v dosavadních diskusích o umělé inteligenci. Kdo své Historie chatu je exportována a systematicky archivována, vytváří základ pro dlouhodobou paměť projektu. Namísto toho, aby bylo nutné důležité rozhodnutí neustále znovu vysvětlovat, mohou být dřívější analýzy, koncepce a řešení trvale k dispozici. Z jednotlivých chatů tak krok za krokem vzniká znalostní báze, kterou lze později využít pro dokumentaci, vývoj a dokonce i pro vlastní systémy umělé inteligence. Vývoj softwaru s umělou inteligencí proto neznamená jen rychlejší programování, ale také vědomé budování digitálního archivu znalostí.
Kdo vyvíjí rozsáhlejší softwarové projekty s využitím umělé inteligence, brzy zjistí, že úzkým hrdlem není kód, ale znalosti o projektu. Požadavky, architektonická rozhodnutí, datové modely a diskuse se často hromadí v průběhu týdnů či měsíců. Právě zde vzniká zajímavá souvislost s tématem exportu dat. Mnohé z těchto informací jsou totiž již k dispozici v dosavadních diskusích o umělé inteligenci. Kdo své Historie chatu je exportována a systematicky archivována, vytváří základ pro dlouhodobou paměť projektu. Namísto toho, aby bylo nutné důležité rozhodnutí neustále znovu vysvětlovat, mohou být dřívější analýzy, koncepce a řešení trvale k dispozici. Z jednotlivých chatů tak krok za krokem vzniká znalostní báze, kterou lze později využít pro dokumentaci, vývoj a dokonce i pro vlastní systémy umělé inteligence. Vývoj softwaru s umělou inteligencí proto neznamená jen rychlejší programování, ale také vědomé budování digitálního archivu znalostí.
Můj osobní závěr
Když se ohlédnu za svými dosavadními zkušenostmi s vývojem podporovaným umělou inteligencí, jedna věc mi přijde na mysl především:
Technologie mě nepřiměla k tomu, abych méně přemýšlel. Přiměla mě k tomu, abych přemýšlel jinak. Mnoho úkolů, které mi dříve zabíraly značnou část pracovní doby, lze dnes vyřídit mnohem rychleji. Zároveň vzrostl význam struktury, plánování a dokumentace.
Právě při mém aktuálním projektu se znovu a znovu ukazuje, jak cenný je jasný kontext, centrální znalostní báze a jasně definované procesy. Rozdíl nedělá jednotlivý příkaz. Ani jednotlivý řádek kódu. Ani použitý systém umělé inteligence.
Rozhodujícím faktorem je schopnost strukturovat znalosti a dát projektu jasný směr.
Možná se za několik let budeme na dnešní dobu ohlížet stejně jako na zavedení internetu nebo prvních osobních počítačů. Mnohé možnosti jsou již patrné, ale dlouhodobé dopady lze zatím jen stěží plně odhadnout.
Jedna věc se však již dnes jeví jako pravděpodobná. Vývoj softwaru se změní. Ne proto, že by stroje najednou zvládaly vše samy, ale proto, že lidé získali nové nástroje, které rozšiřují jejich schopnosti. Kdo tyto nástroje smysluplně využívá, může pracovat produktivněji, učit se rychleji a zvládat větší projekty než kdykoli předtím.
Budoucnost proto pravděpodobně nepatří ani člověku samotnému, ani umělé inteligenci samotné. Patří spolupráci obou stran. A právě tato spolupráce nezačíná kódováním.
Začíná to nápadem, jasnou strukturou a ochotou zkoušet nové věci.
Zůstaňte v obraze - bez reklamy
Pokud chcete být informováni o nových článcích, aktualizacích nebo nových souborech ke stažení, můžete se přihlásit k odběru mého měsíčního zpravodaje. Zpravodaj je záměrně úsporný, zcela bez reklam a vychází pouze jednou měsíčně. Najdete v něm výběr nejdůležitějších nových článků, praktický obsah o umělé inteligenci, softwaru a sociálních tématech a také informace o aktualizovaných skriptech nebo nových souborech ke stažení. Žádný spam, žádné každodenní e-maily - jen ten nejdůležitější obsah v kompaktní podobě. Pokud chcete tento vývoj sledovat průběžně, newsletter je nejjednodušší způsob, jak zůstat v obraze.




Často kladené otázky
- Je dnes umělá inteligence schopná sama vyvíjet kompletní softwarové projekty?
Moderní systémy umělé inteligence dokážou převzít značnou část softwarového projektu. Umí navrhovat datové modely, generovat zdrojový kód, vyvíjet rozhraní, psát dokumentaci a dokonce i vytvářet testy. Úspěšný vývoj softwaru však nevzniká pouze psaním kódu. Je třeba porozumět požadavkům, analyzovat obchodní procesy, přijímat rozhodnutí a kontrolovat výsledky. Tyto úkoly zůstávají v odpovědnosti člověka. Umělá inteligence může výrazně zvýšit produktivitu, nenahrazuje však nutnost odborných znalostí, zkušeností a řízení projektů. - Která umělá inteligence se nejlépe hodí pro vývoj softwaru?
Neexistuje jednoznačná odpověď. Různé systémy mají různé silné stránky. Některé modely vynikají zejména v otázkách architektury, jiné zase v generování kódu nebo dokumentaci. Rozhodující je často méně výběr nástroje než kvalita poskytnutých informací. I ta nejvýkonnější umělá inteligence může pracovat pouze s vědomostmi, které jí jsou poskytnuty. Dobré procesy, jasná dokumentace a přehledný kontext jsou většinou důležitější než konkrétní název modelu. - Musím umět programovat, abych mohl vyvíjet software s využitím umělé inteligence?
Základní technické znalosti zůstávají nesmírně cenné. Ačkoli systémy umělé inteligence dokážou převzít mnoho programátorských úkolů, je stále nutné vyhodnocovat výsledky, rozpoznávat chyby a přijímat rozhodnutí. Kdo rozumí databázím, softwarové architektuře a obchodním procesům, dosahuje zpravidla výrazně lepších výsledků. Přestože se vstupní bariéra výrazně snižuje, odborné znalosti zůstávají důležitou konkurenční výhodou. - Proč hraje kontext při vývoji umělé inteligence tak důležitou roli?
Umělá inteligence zpočátku tvůj projekt nezná. Nezná tvé cíle, tvé procesy ani datové struktury. Bez dostatečného kontextu musí vycházet z odhadů. Čím více relevantních informací má k dispozici, tím lépe dokáže vyvinout vhodná řešení. V mnoha projektech závisí kvalita výsledků více na poskytnutém kontextu než na samotném zadání. - Jak rozsáhlá by měla být projektová dokumentace?
Dobrá dokumentace by měla být dostatečně úplná, aby umožňovala pochopit souvislosti, ale neměla by být zbytečně složitá. Důležité jsou cíle projektu, datové modely, architektonická rozhodnutí, konvence pojmenování, otevřené úkoly a technické rámcové podmínky. Cílem není maximální objem textu, ale maximální srozumitelnost. Přehledná dokumentace je často cennější než stovky stránek nestrukturovaných informací. - Proč by se měly větší projekty rozdělit do několika chatů s umělou inteligencí?
S rostoucím rozsahem projektu se zvyšuje jeho složitost i objem informací. Pokud se všechna témata řeší v jediném chatu, důležité informace často zapadnou. Rozdělením do chatů věnovaných architektuře, vývoji, dokumentaci a testování se jasněji vymezí odpovědnosti a zlepší přehlednost. Zároveň lze cíleně využít různé úhly pohledu. - Co je to spouštěcí příkaz a proč je důležitý?
Úvodní výzva slouží jako standardizované úvodní sdělení pro nové konverzace. Popisuje projekt, odkazuje na dokumentaci, definuje pravidla a vysvětluje požadovanou roli umělé inteligence. Díky tomu získají nové konverzace okamžitě potřebný kontext. To šetří čas, omezuje nedorozumění a zajišťuje konzistentní výsledky v rámci celého projektu. - Mělo by se každé rozhodnutí zaznamenat?
Není nutné dokumentovat každou maličkost. Důležité jsou především rozhodnutí, která mohou mít v budoucnu dopad na architekturu, datový model nebo procesy. Obzvláště cenná je dokumentace důvodů, které vedly k danému rozhodnutí. Často není problémem samotné rozhodnutí, ale to, že se později zapomenou původní úvahy. - Jak lze zabránit tomu, aby umělá inteligence navrhovala nesprávná řešení?
Stoprocentní jistota neexistuje. Nejlepší strategie se skládá z několika základních prvků: poskytnout dostatek kontextu, rozdělit úkoly na menší kroky, ověřovat výsledky, provádět testy a dokumentovat důležité rozhodnutí. Umělou inteligenci je třeba vnímat jako podporu, nikoli jako neomylnou autoritu. - Jak důležitá jsou reálná vzorová data?
Ukázková data patří k nejúčinnějším nástrojům vůbec. Pomáhají umělé inteligenci lépe porozumět strukturám, souvislostem a typickým případům použití. Často stačí jen několik realistických datových sad, aby poskytly lepší pochopení než několik stránek teoretických popisů. Samozřejmostí je přitom dodržování ochrany osobních údajů a důvěrnosti. - Může umělá inteligence pomoci i u stávajících softwarových projektů?
Ano. Právě stávající systémy často těží z podpory umělé inteligence. Lze rozšířit dokumentaci, analyzovat starý kód, porozumět datovým strukturám a plánovat nové funkce. Předpokladem však je, aby byly k dispozici dostatečné informace o stávajícím systému. Čím lepší je výchozí dokumentace, tím efektivnější je spolupráce. - Jakou roli bude vývojář hrát v budoucnosti?
Role se stále více přesouvá od čistého programování směrem k analýze, architektuře, komunikaci a kontrole kvality. Vývojáři se stále více stávají projektovými manažery a systémovými architekty. Schopnost srozumitelně popsat složité souvislosti nabývá na významu. Programování zůstává důležité, ale již není nutně v centru pozornosti. - Jak se vypořádat s protichůdnými odpověďmi umělé inteligence?
Rozpory jsou běžné. Různé diskuse nebo modely mohou navrhovat odlišná řešení. Právě proto by se důležitá rozhodnutí měla vždy přijímat na základě srozumitelných kritérií. Architektonická pravidla, dokumentace a testy pomáhají objektivně posoudit kvalitu různých návrhů. - Měli bychom umělé inteligenci umožnit přístup k celé projektové dokumentaci?
V zásadě ano, pokud to umožňují předpisy o ochraně osobních údajů, zásady důvěrnosti a firemní směrnice. Čím lépe umělá inteligence projektu rozumí, tím kvalitnější jsou obvykle výsledky. Zejména u dlouhodobých projektů se vyplatí důsledně zapojovat centrální zdroje znalostí a udržovat je v aktuálním stavu. - Jak umělá inteligence ovlivňuje dobu vývoje softwarových projektů?
Mnoho úkolů lze vyřídit mnohem rychleji než dříve. Návrhy, dokumentace, datové modely a první prototypy vznikají často za zlomek času, který tomu dříve zabíral. Zároveň však zůstává nutnost plánování, testování a zajištění kvality. Dobré projekty se proto nestávají automaticky hektičtějšími, ale často jsou strukturovanější a produktivnější. - Mohou malé podniky těžit z vývoje softwaru založeného na umělé inteligenci?
Zejména menší firmy z toho často těží obzvláště výrazně. Tam, kde dříve byly zapotřebí celé týmy, dnes mohou jednotliví vývojáři nebo malé skupiny realizovat projekty, které by dříve byly z ekonomického hlediska téměř neproveditelné. Umělá inteligence snižuje vstupní bariéry a zvyšuje produktivitu, aniž by vyžadovala vysoké investice do rozsáhlých vývojářských týmů. - Jaké chyby dělají začátečníci nejčastěji?
Mezi nejčastější chyby patří nedostatečný kontext, chybějící dokumentace, příliš rozsáhlé zadání a slepá důvěra ve výsledky umělé inteligence. Mnoho uživatelů se zpočátku soustředí na jednotlivé pokyny a podceňuje význam struktury, správy znalostí a dlouhodobé organizace projektu. - Nahradí umělá inteligence klasický vývoj softwaru úplně?
V současné době se to jeví jako nepravděpodobné. Pravděpodobnější je zásadní změna způsobu práce. Mnoho technických činností bude automatizováno nebo výrazně zrychleno. Zároveň nabývají na významu analýza, komunikace, architektura a strategické myšlení. Budoucnost vývoje softwaru pravděpodobně nespočívá v nahrazení člověka, ale v stále užší spolupráci mezi lidskou zkušeností a umělou inteligencí.



