
Gdybyś kilka lat temu zapytał mnie, jak będzie wyglądało tworzenie oprogramowania za dziesięć lat, prawdopodobnie wspomniałbym o nowych językach programowania, lepszych frameworkach lub wydajniejszych środowiskach programistycznych. Dzisiaj moja odpowiedź brzmiałaby zupełnie inaczej. Największa zmiana nie dotyczy narzędzi, ale sposobu, w jaki my, programiści, myślimy i pracujemy.
W chwili, gdy piszę te słowa, sam pracuję nad nowym systemem oprogramowania. Od kilku tygodni intensywnie korzystam z nowoczesnych narzędzi sztucznej inteligencji, takich jak Codex i inne modele językowe. Początkowo byłem ciekawy, a teraz jestem przede wszystkim pod wrażeniem. Nie dlatego, że sztuczna inteligencja nagle wszystko robi sama, ale dlatego, że zadania te wykonuje zaskakująco dobrze, umożliwiając w ten sposób nowe sposoby pracy.




Wiele dyskusji na temat sztucznej inteligencji skupia się na pytaniu, czy programiści staną się kiedyś zbędni. Z mojego dotychczasowego doświadczenia wynika, że uważam to pytanie za mało konstruktywne. O wiele ciekawsza jest obserwacja, że rola programisty się zmienia. Prawdziwym wyzwaniem coraz rzadziej jest pisanie pojedynczych linii kodu. Zamiast tego coraz ważniejsze staje się analizowanie problemów, rozumienie systemów, dokumentowanie powiązań i dostarczanie sztucznej inteligencji odpowiednich informacji.
Programista jako architekt
W tradycyjnym tworzeniu oprogramowania programiści często poświęcali znaczną część czasu pracy na konkretną realizację zadań. Programowano funkcje, tworzono bazy danych i korygowano błędy. Zadania te nadal istnieją. Jednak obecnie systemy sztucznej inteligencji mogą wspierać wiele z tych czynności lub częściowo je przejąć.
W ten sposób zmienia się punkt ciężkości. Kto chce z powodzeniem tworzyć oprogramowanie z wykorzystaniem sztucznej inteligencji, musi przede wszystkim wiedzieć, co właściwie chce stworzyć. Na pierwszy rzut oka wydaje się to oczywiste, ale tak nie jest.
W wielu projektach większość problemów wynika nie ze złego kodowania, ale z niejasnych wymagań. Jeśli cel jest nieprecyzyjny, nawet najlepsza sztuczna inteligencja nie pomoże. W rzeczywistości sztuczna inteligencja często jeszcze bardziej uwidacznia takie słabości, ponieważ systemy działają bardzo konsekwentnie w oparciu o otrzymane informacje.
W związku z tym współczesny programista coraz częściej pełni rolę architekta. Projektuje strukturę systemu, definiuje procesy, opisuje powiązania i dba o to, by wszyscy uczestnicy – niezależnie od tego, czy są to ludzie, czy systemy sztucznej inteligencji – mieli takie samo wyobrażenie o projekcie. Im większy jest projekt, tym ważniejsza staje się ta umiejętność.
Od programisty do kierownika projektu
Ciekawą obserwacją wynikającą z moich własnych projektów jest to, że komunikacja ma obecnie znacznie większe znaczenie niż kiedyś. Osoby pracujące z AI często poświęcają więcej czasu na tworzenie opisów, dokumentacji i koncepcji niż na samo programowanie.
Nie oznacza to jednak, że wiedza techniczna traci na znaczeniu. Wręcz przeciwnie. Kto nie rozumie podstaw baz danych, architektury oprogramowania czy procesów biznesowych, ten nie osiągnie dobrych wyników nawet przy wykorzystaniu sztucznej inteligencji. Jednak punkt ciężkości przesuwa się z samego wdrażania w kierunku zarządzania.
Można by powiedzieć, że programista staje się coraz bardziej kierownikiem projektu własnego wirtualnego zespołu programistów. Zespół ten nie składa się już wyłącznie z ludzkich współpracowników, lecz z różnych systemów sztucznej inteligencji, które mogą przejmować różne zadania. Jedna sztuczna inteligencja pomaga w projektowaniu architektury, kolejna tworzy dokumentację, inna analizuje błędy, a jeszcze inna opracowuje interfejsy użytkownika.
Odpowiedzialność spoczywa jednak na człowieku. Sztuczna inteligencja przedstawia propozycje, ale nie podejmuje decyzji biznesowych, nie zna celów firmy i nie ponosi odpowiedzialności za skutki swojej pracy.
Dlaczego doświadczenie staje się coraz ważniejsze
Niektórzy obawiają się, że sztuczna inteligencja sprawi, że wiedza specjalistyczna stanie się zbędna. Z mojego doświadczenia wynika, że jest raczej odwrotnie. Im większe możliwości oferują narzędzia, tym ważniejsze staje się doświadczenie. Doświadczony programista szybciej rozpoznaje, czy dane rozwiązanie ma sens. Dostrzega powiązania, których sztuczna inteligencja mogła nie uwzględnić. Zna typowe źródła błędów i potrafi krytycznie podchodzić do wyników.
Właśnie dlatego projekty oparte na sztucznej inteligencji często sprawdzają się szczególnie dobrze, gdy łączą się w nich wiedza specjalistyczna i sztuczna inteligencja. Najlepsze wyniki rzadko osiąga się dzięki ślepemu zaufaniu do technologii. Powstają one tam, gdzie kierunek wyznacza doświadczony człowiek, a sztuczna inteligencja wspiera go w realizacji.
W pewnym sensie przypomina mi to wprowadzenie nowoczesnych maszyn w wielu zawodach rzemieślniczych. Narzędzia stały się wydajniejsze, ale doświadczony rzemieślnik pozostał niezastąpiony. Musiał jedynie nauczyć się sensownie korzystać z nowych narzędzi.
Nowy sposób myślenia
Kto dziś tworzy oprogramowanie z wykorzystaniem sztucznej inteligencji, nie powinien więc najpierw zastanawiać się, jaki kod ma napisać sztuczna inteligencja. Ważniejsze pytanie brzmi: jak opisać swój projekt tak, aby sztuczna inteligencja zrozumiała go jak najlepiej?
Właśnie tutaj zaczyna się prawdziwa praca. Nie sama komenda decyduje o sukcesie lub porażce. Kluczowa jest wiedza, która stoi za tą komendą. Kto zna swoje procesy, rozumie struktury danych i potrafi jasno sformułować swoje cele, ten zapewnia sztucznej inteligencji podstawę do osiągnięcia dobrych wyników.
To powoduje zasadniczą zmianę w dziedzinie tworzenia oprogramowania. W przyszłości wartość programisty będzie w coraz mniejszym stopniu zależała od tego, jak szybko potrafi on pisać kod. Znacznie ważniejsza stanie się umiejętność analizowania złożonych systemów, porządkowania wiedzy oraz jasnego przekazywania informacji.
Dobra wiadomość jest taka: te umiejętności zawsze były cenne. Sztuczna inteligencja jedynie sprawia, że stają się one bardziej widoczne. I właśnie dlatego skuteczne tworzenie oprogramowania z wykorzystaniem sztucznej inteligencji nie zaczyna się od programowania, ale od zrozumienia.

Najpierw zrozumieć, potem programować
Kto po raz pierwszy pracuje z zaawansowaną sztuczną inteligencją, często odczuwa niewielki przypływ entuzjazmu. Nagle w ciągu kilku minut można stworzyć rzeczy, na które wcześniej potrzeba było godzin, a nawet dni. Struktura bazy danych jest szybko zaprojektowana, interfejs użytkownika powstaje za naciśnięciem przycisku, a nawet bardziej złożone funkcje programu często pojawiają się na ekranie zaskakująco szybko.
Właśnie w tym miejscu czai się jednak jedna z największych pułapek współczesnego tworzenia oprogramowania. Szybkość działania narzędzi skłania do zbyt wczesnego rozpoczęcia realizacji. Wielu programistów, przedsiębiorców i kierowników projektów od razu zabiera się za programowanie, mimo że nie przemyśleli jeszcze w pełni rzeczywistego problemu. Sztuczna inteligencja generuje wtedy wprawdzie imponujące wyniki, ale ostatecznie działa na niepewnych podstawach.
Problem nie leży w samej sztucznej inteligencji. Problemem jest niekompletny opis projektu. Jeśli sztuczna inteligencja otrzyma błędne lub niekompletne informacje, i tak spróbuje wygenerować rozwiązanie. Wynik często na pierwszy rzut oka wydaje się wiarygodny. Dopiero później okazuje się, że brakuje ważnych powiązań lub że podstawowe założenia były błędne.
Moim zdaniem jest to jedna z najczęstszych przyczyn, dla których projekty tracą niepotrzebnie czas.
Pokusa szybkiego startu
Wielu programistów zna to uczucie. Masz pomysł na nową aplikację, otwierasz czat z AI i od razu zaczynasz od pierwszego polecenia.
- „Stwórz mi system CRM.“
- „Napisz program do zarządzania magazynem.“
- „Stwórz system zarządzania projektami z funkcją rejestracji czasu pracy“.“
Takie wytyczne są zrozumiałe. W końcu każdy chce jak najszybciej zobaczyć rezultaty. Jednak właśnie takie podejście często prowadzi do tego, że później trzeba ponownie przerabiać znaczne części systemu.
Sztuczna inteligencja nie może wiedzieć, jakie specyficzne cechy ma Twoja firma. Nie zna Twoich klientów. Nie zna Twoich procesów. Nie wie, jakie decyzje zostały już podjęte w przeszłości i jakie uwarunkowania należy wziąć pod uwagę.
Doświadczony programista zazwyczaj zadaje klientowi wiele pytań, zanim przystąpi do właściwej realizacji projektu. Dokładnie takie samo podejście sprawdza się również w przypadku projektów związanych ze sztuczną inteligencją.
Zamiast od razu przystępować do programowania, należy najpierw wyjaśnić wszystkie kwestie.
Co właściwie ma powstać?
To pytanie brzmi banalnie, ale zaskakująco często nie udziela się na nie wystarczającej odpowiedzi. Niemal każdy projekt oprogramowania ma inne cele. Czasami chodzi o usprawnienie procesu pracy. W innych przypadkach chodzi o lepsze analizy, zmniejszenie liczby błędów lub większą automatyzację.
Sztuczna inteligencja może podejmować trafne decyzje tylko wtedy, gdy zna te cele. Weźmy na przykład system zarządzania klientami. Na pierwszy rzut oka wydaje się to stosunkowo proste. Jednak już po kilku minutach pojawia się wiele pytań.
Czy chodzi o zwykłe zarządzanie adresami, czy o kompletny system CRM? Czy są wyznaczeni osoby kontaktowe? Czy oprogramowanie służy do zarządzania ofertami i fakturami? Czy oprogramowanie powinno być wielojęzyczne? Czy firma zatrudnia przedstawicieli handlowych? Czy należy uwzględnić wymogi dotyczące ochrony danych?
Im dokładniejsze będą odpowiedzi na te pytania, tym lepiej sztuczna inteligencja zrozumie rzeczywisty cel systemu. Dlatego też celem powinno być zawsze nie tylko opisanie oprogramowania, ale także kontekstu biznesowego, który za nim stoi.
Procesy są ważniejsze niż funkcje
Kolejnym częstym błędem jest skupianie się wyłącznie na funkcjach. Wiele opisów projektów zawiera sformułowania takie jak:
- „Ma być dostępna maska klienta“.“
- „Powinna być dostępna funkcja wyszukiwania.“
- „Powinien umieć tworzyć pliki PDF.“
To co prawda ważne informacje, ale opisują one jedynie narzędzia. Naprawdę interesujące są procesy, które się za nimi kryją.
- Dlaczego potrzebny jest profil klienta?
- Jakie kolejne czynności należy wykonać?
- Kto korzysta z tych danych?
- Jakie informacje będą później analizowane?
Nowoczesne systemy sztucznej inteligencji zadziwiająco dobrze rozumieją procesy, o ile są one odpowiednio opisane. Dlatego często warto dokumentować całe procedury robocze. W centrum uwagi nie powinno znajdować się pytanie „Jakiej maski potrzebuję?“, ale pytanie:
„W jaki sposób użytkownik będzie później korzystał z systemu?“
Im dokładniej opisze się ten proces, tym lepiej sztuczna inteligencja będzie w stanie opracować odpowiednie propozycje.
Znaczenie danych
Oprócz procesów dane stanowią fundament każdego oprogramowania. Wielu programistów nie docenia, jak ważny dla powodzenia projektu związanego ze sztuczną inteligencją jest szczegółowy opis struktur danych.
Jeśli sztuczna inteligencja wie jedynie, że istnieją klienci, nie ma to większego znaczenia. Informacja ta staje się znacznie cenniejsza, gdy dodatkowo opisuje się, jakie pola istnieją, jakie powiązania są przewidziane i w jaki sposób dane będą później wykorzystywane.
W moich projektach sprawdziło się przedstawianie rzeczywistych przykładów na jak najwcześniejszym etapie. Przykładowe zbiory danych są często bardziej wymowne niż długie opisy teoretyczne.
Konkretny rekord danych klienta zawierający imię i nazwisko, adres, osoby kontaktowe oraz historię komunikacji często pozwala sztucznej inteligencji lepiej zrozumieć sytuację niż kilka akapitów abstrakcyjnych wyjaśnień. To samo dotyczy danych katalogowych produktów, projektów, faktur czy jakichkolwiek innych informacji.
Im bardziej opis jest zbliżony do przyszłej rzeczywistości, tym lepsze będą wyniki.
Faza analizy pozwala zaoszczędzić czas
Wiele osób uważa analizę i dokumentację za uciążliwe prace przygotowawcze. W końcu każdy chce jak najszybciej zobaczyć konkretne wyniki. Paradoksalnie to właśnie ta niecierpliwość często wydłuża czas trwania prac rozwojowych.
Każda godzina poświęcona na początku na dokładną analizę często pozwala później zaoszczędzić wiele godzin pracy związanej z poprawkami. Zasada ta obowiązywała już na długo przed erą sztucznej inteligencji, a dziś ma jeszcze większe znaczenie.
Sztuczna inteligencja działa niezwykle szybko. Jednak dzięki temu może również bardzo szybko powielać błędne rozwiązania. Kto opracowuje system opisany w sposób niejasny, może w ciągu kilku minut otrzymać setki wierszy kodu prowadzącego do niewłaściwego rozwiązania.
Kto natomiast najpierw precyzyjnie określi wymagania, ten stworzy solidną podstawę dla wszystkich kolejnych kroków.
Zrozumienie jako podstawa wszelkich dalszych działań
Najważniejszy wniosek jest zatem taki: dobre oprogramowanie nie powstaje wyłącznie dzięki dobrym poleceniom. Powstaje ono dzięki dogłębnemu zrozumieniu problemu.
Im lepiej znasz cele, procesy, dane i powiązania w ramach projektu, tym skuteczniej możesz współpracować z AI. Jakość wyników zależy ostatecznie nie tyle od inteligencji narzędzia, co od jakości dostarczanych przez Ciebie informacji.
Dlatego skuteczne tworzenie oprogramowania opartego na sztucznej inteligencji nie zaczyna się od napisania pierwszego fragmentu kodu. Zaczyna się od próby tak dogłębnego zrozumienia problemu, aby inna osoba – lub właśnie sztuczna inteligencja – mogła go pojąć i rozwiązać.

Idealne wdrożenie projektu z wykorzystaniem sztucznej inteligencji
Kiedy nowy pracownik dołącza do firmy, zazwyczaj nie siada się go po prostu przy biurku i nie mówi: „Zabierz się do pracy“. Zamiast tego przechodzi szkolenie wprowadzające. Poznaje cele firmy, otrzymuje ważne dokumenty, zapoznaje się z procedurami i rozmawia z osobami, które mają już doświadczenie.
Ta sama logika ma zastosowanie również w przypadku współpracy ze sztuczną inteligencją. Mimo to wielu programistów nadal traktuje swoją sztuczną inteligencję jak wyszukiwarkę. Zadają pojedyncze pytania, wydają krótkie polecenia, a potem dziwią się, że wyniki są niekompletne lub nieadekwatne. Tymczasem praktyka wielokrotnie pokazuje, że jakość odpowiedzi w dużym stopniu zależy od tego, jak dobrze sztuczna inteligencja została wdrożona do projektu. Dobrze przygotowane wdrożenie projektu może stanowić różnicę między przeciętnymi a wyjątkowo dobrymi wynikami.
Z własnego doświadczenia nauczyłem się, że pierwsze informacje, jakie sztuczna inteligencja otrzymuje na temat projektu, często mają zaskakująco duży wpływ na cały jego dalszy przebieg. Im solidniejsze są te podstawy, tym bardziej owocna jest współpraca.
Prosty opis projektu
Pierwszym krokiem jest opisanie projektu jako całości. Wielu programistów popełnia przy tym błąd, od razu podając szczegóły techniczne. Mówią o bazach danych, językach programowania czy interfejsach, zanim jeszcze stanie się jasne, jaki problem należy rozwiązać. Dla sztucznej inteligencji najważniejszy jest jednak na początku kontekst merytoryczny.
Wyobraź sobie, że chcesz stworzyć system ERP. Zamiast od razu zaczynać od tabel i nazw pól, powinieneś najpierw opisać, dla kogo przeznaczone jest to oprogramowanie, jakie zadania ma realizować i jakie cele ma osiągnąć. Dobry opis projektu odpowiada na podstawowe pytania:
- Kto będzie później korzystał z tego systemu?
- Jakie procesy należy wspierać?
- Jakie problemy należy rozwiązać?
- Jakie są cechy szczególne?
Dopiero gdy te zależności staną się jasne, warto zagłębiać się w szczegóły techniczne. Można to porównać do budowy domu. Zanim zaczniemy rozmawiać o gniazdkach elektrycznych czy instalacjach wodociągowych, należy ustalić, czy w ogóle ma powstać dom jednorodzinny, budynek biurowy, czy też magazyn.
Ramy techniczne
Po wyjaśnieniu podstaw merytorycznych przechodzimy do omówienia środowiska technicznego. Chodzi tu o określenie warunków ramowych, w których ma działać sztuczna inteligencja. Obejmują one na przykład używane języki programowania, systemy baz danych, frameworki czy platformy docelowe.
Ten krok jest ważniejszy, niż wielu mogłoby się początkowo wydawać. Rozwiązanie, które sprawdza się w przypadku aplikacji internetowej, niekoniecznie musi być odpowiednie dla aplikacji desktopowej. Również możliwości poszczególnych systemów baz danych różnią się między sobą, niekiedy nawet znacznie.
Im dokładniej opisane zostaną warunki ramowe, tym bardziej precyzyjnie będzie mogła działać sztuczna inteligencja. Należy przy tym dokumentować nie tylko bieżące decyzje techniczne, ale także istniejące wytyczne. Być może istnieją już starsze systemy, istniejące interfejsy lub określone standardy firmowe. Takie informacje również pomagają sztucznej inteligencji w opracowywaniu realistycznych propozycji.
Model danych jako podstawa
Najpóźniej w tym momencie staje się jasne, dlaczego dobre przygotowanie jest tak cenne. W niemal każdym większym projekcie programistycznym dane odgrywają kluczową rolę. Klienci, artykuły, projekty, faktury, dokumenty czy konta użytkowników stanowią fundament przyszłej aplikacji.
Dlatego warto jak najwcześniej przedstawić sztucznej inteligencji ogólny zarys modelu danych. Nie chodzi tu na razie o idealną dokumentację techniczną. Znacznie ważniejsze jest, aby sztuczna inteligencja zrozumiała podstawowe zależności.
- Jakie tabele są dostępne?
- Jakie obiekty są ze sobą powiązane?
- Jakie informacje są przechowywane?
- Jakie dane są szczególnie ważne?
Im dokładniej opisana jest ta struktura, tym łatwiej sztucznej inteligencji będzie prawidłowo klasyfikować późniejsze wymagania. Wiele projektów pokazuje, że jakość późniejszych propozycji programowych jest bezpośrednio związana ze zrozumieniem modelu danych. Kto zaniedbuje ten obszar, często spotyka się z nieporozumieniami i niepotrzebnymi poprawkami.
Dlaczego przykładowe dane są tak cenne
Jedną z najskuteczniejszych metod wyjaśnienia systemowi sztucznej inteligencji danego zagadnienia jest przedstawienie mu rzeczywistych przykładów. Ludzie często uczą się na przykładach. Systemy sztucznej inteligencji działają w wielu sytuacjach w podobny sposób.
Teoretyczny opis bazy klientów może być pomocny. Jednak prawdziwy przykładowy zestaw danych często dostarcza znacznie więcej informacji. Nagle sztuczna inteligencja rozpoznaje typowe treści, konwencje nazewnictwa, formaty danych i powiązania. Lepiej rozumie, które informacje są faktycznie istotne i jak zostaną one wykorzystane w przyszłości. To samo dotyczy danych katalogowych artykułów, faktur, projektów lub dowolnych innych obiektów w systemie.
Oczywiście należy przy tym uwzględnić kwestie ochrony danych i poufności. W wielu przypadkach w zupełności wystarczą zanonimizowane dane przykładowe. Decydujące znaczenie ma nie autentyczność osób lub przedsiębiorstw, lecz struktura informacji.
Nauka języka sztucznej inteligencji
Ciekawym efektem ubocznym pracy z AI jest to, że programiści uczą się jaśniej opisywać swoje systemy. Wiele powiązań, które w ich głowach wydają się oczywiste, nagle trzeba sformułować. Dzięki temu ujawniają się niejasności, których wcześniej prawie nie zauważano.
Proces ten przypomina tworzenie dokumentacji technicznej. Gdy tylko próbuje się coś dokładnie wyjaśnić, często dostrzega się obszary, które nie zostały jeszcze w pełni przemyślane.
Właśnie dlatego przedstawienie projektu jest pomocne nie tylko dla sztucznej inteligencji, ale często także dla samego programisty. Kto potrafi wyjaśnić swój projekt w sposób zrozumiały dla sztucznej inteligencji, zazwyczaj sam rozumie go znacznie lepiej.
Inwestycja, która wielokrotnie się opłaca
Niektórzy programiści początkowo postrzegają szczegółowe wprowadzenie do projektu jako dodatkowy wysiłek. W rzeczywistości jest to jednak jedna z najbardziej opłacalnych inwestycji w ramach projektu związanego ze sztuczną inteligencją.
Każda godzina poświęcona na początku na opisanie celów, procesów, danych i warunków technicznych może później zaoszczędzić wiele godzin dodatkowej pracy. Dzięki temu sztuczna inteligencja nie działa już na ślepo, lecz w oparciu o wspólne rozumienie projektu.
Właśnie to wspólne zrozumienie stanowi podstawę wszystkiego, co nastąpi później. To od niego zależy, czy sztuczna inteligencja będzie jedynie wykonywać pojedyncze zadania, czy też stanie się prawdziwym partnerem w rozwoju.
Dlatego też rozpoczęcie projektu nie powinno być nigdy traktowane jako uciążliwy obowiązek. Jest to moment, w którym kładzie się podwaliny pod całą przyszłą współpracę. Im solidniejsze są te podstawy, tym lepsze są zazwyczaj wyniki.
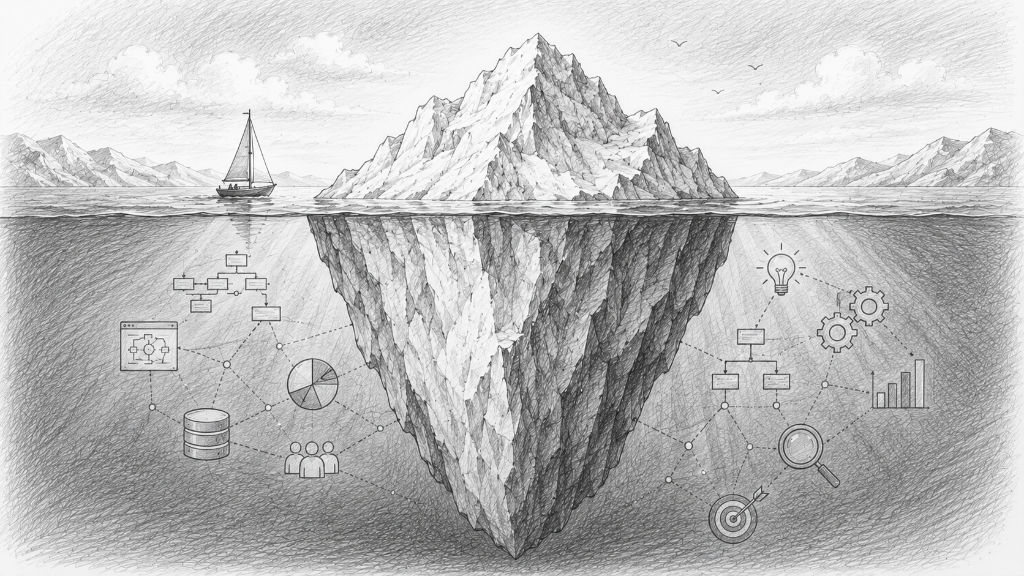
Kontekst jest ważniejszy niż kod
Wielu programistów początkowo zakłada, że nowoczesne systemy sztucznej inteligencji potrafią przede wszystkim bardzo dobrze programować. W końcu najbardziej imponujące przykłady często prezentuje się za pomocą kodu. Sztuczna inteligencja tworzy stronę internetową, opracowuje zapytanie do bazy danych lub w ciągu kilku sekund pisze kompletną funkcję.
Jednak po zdobyciu pewnego doświadczenia praktycznego często okazuje się, że rzeczywistość wygląda inaczej. Prawdziwą siłą współczesnej sztucznej inteligencji nie jest przede wszystkim pisanie kodu. Jej największym atutem jest łączenie informacji, rozpoznawanie powiązań oraz stosowanie wiedzy w nowych sytuacjach.
Właśnie dlatego kontekst jest tak ważny. Gdy sztuczna inteligencja rozumie kontekst, często uzyskuje się zaskakująco dobre wyniki. Jeśli jednak brakuje tego kontekstu, sztuczna inteligencja nadal generuje odpowiedzi i kod, ale działa na niepewnych podstawach. Jakość wyników często wtedy znacznie spada, nawet jeśli kod wydaje się poprawny pod względem technicznym.
W praktyce wielokrotnie okazuje się, że to nie kod jest kluczowym surowcem sztucznej inteligencji, lecz kontekst, w którym ten kod powstaje.
Dlaczego krótkie instrukcje często przynoszą słabe wyniki
Osoby, które dopiero zaczynają pracę z AI, często mają tendencję do formułowania zadań w bardzo zwięzły sposób. Typowy prompt mógłby brzmieć:
„Stwórz system zarządzania klientami.“
Z technicznego punktu widzenia to stwierdzenie nie jest błędne. Niemniej jednak pominięto w nim niemal wszystkie istotne informacje.
- Dla jakiej branży?
- Dla ilu użytkowników?
- Jakie dane należy zapisać?
- Jakie procesy należy wspierać?
- Jakie analizy są potrzebne?
- Jakie systemy już istnieją?
Sztuczna inteligencja musi sama odpowiedzieć na wszystkie te pytania i nieuchronnie przyjmuje pewne założenia. Niektóre z nich będą przypadkowo trafne, inne nie. Wynik można porównać do sytuacji, w której architektowi powie się jedynie:
„Zbuduj mi dom.“
Oczywiście, potrafi zaprojektować dom. Prawdopodobieństwo, że będzie on dokładnie odpowiadał naszym wyobrażeniom, jest jednak niewielkie. Im więcej brakuje istotnych informacji, tym większa jest swoboda interpretacji. I właśnie ta swoboda interpretacji często prowadzi później do niepotrzebnych poprawek.
Różnica między informacją a kontekstem
W wielu dyskusjach na temat sztucznej inteligencji pomija się jedną ważną kwestię. Informacja i kontekst to nie to samo. Informacje to pojedyncze fakty, na przykład:
- System korzysta z bazy danych PostgreSQL.
- Istnieje tabela klientów.
- Aplikacja działa w przeglądarce.
Informacje te są przydatne, ale zazwyczaj nie wystarczają. Kontekst powstaje dopiero wtedy, gdy uwidaczniają się powiązania między tymi informacjami.
- Dlaczego korzysta się z PostgreSQL?
- Jaką rolę odgrywa tabela klientów w całym systemie?
- Którzy użytkownicy korzystają z tej aplikacji?
- Jakie procesy biznesowe są z tym związane?
Sztuczna inteligencja potrzebuje nie tylko faktów, ale także ich znaczenia. Tylko dzięki temu może podejmować decyzje dostosowane do projektu. Im bardziej złożone staje się przedsięwzięcie, tym ważniejsza staje się ta różnica.
Sztuczna inteligencja powinna rozumieć firmę
Ciekawą obserwacją wynikającą z praktyki jest to, że najlepsze wyniki osiąga się często wtedy, gdy sztuczna inteligencja rozumie nie tylko oprogramowanie, ale także firmę, która za nim stoi.
Weźmy ponownie za przykład system ERP. Istnieje znaczna różnica w zależności od tego, czy system ten jest tworzony dla zakładu rzemieślniczego, hurtowni, gabinetu lekarskiego czy sklepu internetowego. Wiele wymagań technicznych wynika bezpośrednio z modelu biznesowego.
Kto wyjaśnia sztucznej inteligencji jedynie strukturę techniczną, pozostawia jej znaczną część interpretacji. Kto natomiast dodatkowo opisuje procesy biznesowe, dostarcza znacznie cenniejszy kontekst. Dlatego często warto najpierw zapoznać sztuczną inteligencję z organizacją.
- W jaki sposób firma zarabia pieniądze?
- Które procesy są szczególnie ważne?
- Gdzie najczęściej pojawiają się problemy?
- Jakie cele realizuje to oprogramowanie?
Na pierwszy rzut oka informacje te mogą wydawać się mało związane z programowaniem. W rzeczywistości jednak często znacznie poprawiają one jakość wyników technicznych.
Nowa filozofia rozwoju: gFM-NEXT i SchallOS jako przykład praktyczny
 Współpraca między Codexem, ChatGPT i jasno ustrukturyzowaną architekturą, opisana w niniejszym przewodniku praktycznym, jest już obecnie wykorzystywana w rzeczywistym projekcie oprogramowania. Dzięki gFM-NEXT powstaje w oparciu o system SchallOS nowa platforma programistyczna oparta na przeglądarce, łącząca w sobie klasyczne oprogramowanie ERP, nowoczesne technologie internetowe oraz programowanie oparte na sztucznej inteligencji.
Współpraca między Codexem, ChatGPT i jasno ustrukturyzowaną architekturą, opisana w niniejszym przewodniku praktycznym, jest już obecnie wykorzystywana w rzeczywistym projekcie oprogramowania. Dzięki gFM-NEXT powstaje w oparciu o system SchallOS nowa platforma programistyczna oparta na przeglądarce, łącząca w sobie klasyczne oprogramowanie ERP, nowoczesne technologie internetowe oraz programowanie oparte na sztucznej inteligencji.
Celem nie jest po prostu przeniesienie istniejącego rozwiązania FileMaker, ale stworzenie platformy, na której w przyszłości będzie można znacznie szybciej tworzyć, migrować i rozbudowywać aplikacje. Sztuczna inteligencja nie tylko generuje kod, ale także wspiera architekturę, dokumentację, testy oraz stopniowy rozwój platformy. Dzięki adapterom dla różnych systemów baz danych, konsoli serwerowej, kontenerom funkcji oraz rozbudowanej warstwie wiedzy powstaje infrastruktura konsekwentnie zaprojektowana z myślą o ponownym wykorzystaniu. W ten sposób gFM-NEXT stanowi doskonały przykład tego, jak sztuczna inteligencja nie tylko przyspiesza poszczególne zadania programistyczne, ale może również zasadniczo zmienić cały proces rozwoju oprogramowania.
Kontekst ogranicza liczbę błędnych decyzji
Jedną z największych zalet dobrego kontekstu projektowego jest to, że znacznie rzadziej dochodzi do błędnych decyzji. Wyobraźmy sobie, że sztuczna inteligencja ma opracować nową funkcję. Bez kontekstu zna ona jedynie bieżące zadanie. Stara się je rozwiązać w możliwie najbardziej efektywny sposób.
Jeśli ma wystarczająco dużo kontekstu, zna również:
- architektura całego systemu
- obowiązujące zasady projektowania
- wcześniejsze decyzje
- warunki techniczne
- cele długoterminowe
Dzięki temu może automatycznie dostosować wiele propozycji do istniejącej struktury. Jakość wyników często nie poprawia się stopniowo, lecz skokowo. Z tego powodu doświadczeni programiści często poświęcają więcej czasu na przekazanie kontekstu niż na sformułowanie poszczególnych zadań.
Dokumentacja jako nośnik informacji kontekstowej
Widać tu, jak ogromne znaczenie ma dobra dokumentacja projektowa. Żaden programista nie chce ciągle na nowo wyjaśniać tych samych informacji. Dotyczy to również współpracy z systemami sztucznej inteligencji.
Centralna dokumentacja służy zatem jako trwały magazyn informacji kontekstowych. Można w niej gromadzić ważne informacje:
Cele projektu, modele danych, decyzje dotyczące architektury, konwencje nazewnictwa, wytyczne techniczne i nierozstrzygnięte kwestie.
Nowe czaty lub nowe systemy sztucznej inteligencji mogą następnie korzystać z tej dokumentacji i zapoznać się z projektem. Im większy staje się projekt, tym ważniejsze staje się takie podejście. W pewnym sensie tworzy to swego rodzaju zbiorową pamięć projektu. Korzystają na tym nie tylko ludzie, ale także sztuczna inteligencja.
Więcej kontekstu nie oznacza więcej tekstu
W tym miejscu często pojawia się nieporozumienie. Większy kontekst nie oznacza automatycznie tworzenia jak największej liczby stron tekstu.
Kluczowe znaczenie ma trafność informacji. Precyzyjny, pięciostronicowy opis może być znacznie cenniejszy niż pięćdziesiąt stron nieuporządkowanego tekstu. Sztuka polega na dostarczeniu informacji, które są naprawdę istotne dla zrozumienia projektu. Należą do nich w szczególności:
- Cele
- Procesy
- Struktury danych
- warunki techniczne
- Rozwiązania architektoniczne
- rzeczywiste przykłady
Kto dokładnie dokumentuje te obszary, ten zazwyczaj tworzy już doskonałą podstawę.
Dlaczego w dłuższej perspektywie kontekst staje się ważniejszy niż programowanie
Im większą wydajność osiągają systemy sztucznej inteligencji, tym bardziej punkt ciężkości przesuwa się z samego programowania na przekazywanie wiedzy.
Kod staje się w coraz większym stopniu zasobem, który można generować automatycznie. Natomiast kontekst pozostaje zadaniem dla ludzi. Tylko ludzie znają cele przedsiębiorstwa. Tylko ludzie rozumieją uwarunkowania polityczne, organizacyjne lub gospodarcze. Tylko ludzie mogą określić, w jakim kierunku projekt powinien podążać w perspektywie długoterminowej.
Sztuczna inteligencja może wykorzystywać tę wiedzę, poszerzać ją i przekładać na rozwiązania techniczne. Nie jest jednak w stanie samodzielnie jej generować. Dlatego w przyszłości kontekst stanie się prawdopodobnie jednym z najcenniejszych zasobów w tworzeniu oprogramowania.
Kto dostarczy sztucznej inteligencji odpowiedni kontekst, często uzyskuje zaskakująco dobre wyniki. Kto natomiast pominie ten etap, często przekona się, że nawet idealnie napisany kod nie prowadzi automatycznie do powstania dobrego oprogramowania. W końcu skuteczne oprogramowanie nie powstaje dzięki pojedynczym wierszom kodu, ale dzięki zrozumieniu powiązań, z których te wiersze wynikają.

Podział dużych projektów na czaty specjalistyczne
Kto po raz pierwszy tworzy oprogramowanie z wykorzystaniem sztucznej inteligencji, zazwyczaj pracuje w ramach jednego czatu. To oczywiste. Zaczyna się od pomysłu, opisuje wymagania i krok po kroku rozwija projekt.
W przypadku niewielkich projektów takie podejście często sprawdza się znakomicie. Pojedynczą aplikację, skrypt lub niewielką bazę danych można bez problemu omówić na czacie.
Wraz ze wzrostem skali projektu zmieniają się jednak wymagania. Nagle pojawia się mnóstwo tabel, różne role użytkowników, wiele interfejsów, obszerna dokumentacja oraz setki decyzji podjętych w trakcie rozwoju. Jednocześnie pojawiają się nowe wymagania, podczas gdy starsze informacje schodzą coraz bardziej na dalszy plan.
Najpóźniej w tym momencie staje się jasne, że duże projekty programistyczne powinny być zorganizowane tak samo jak duże przedsiębiorstwa.
Nikt nie oczekiwałby od pojedynczego pracownika, by był jednocześnie dyrektorem zarządzającym, księgowym, handlowcem, programistą, projektantem i pracownikiem pomocy technicznej. Właśnie dlatego również w przypadku pracy z AI warto rozdzielić poszczególne obszary zadań.
Pomysł, że jedna rozmowa może na stałe towarzyszyć całemu dużemu projektowi, jest co prawda kuszący, ale wraz ze wzrostem złożoności staje się coraz mniej praktyczny.
Idea czatów dla specjalistów
Jedną z najskuteczniejszych metod stosowanych w większych projektach związanych ze sztuczną inteligencją jest utworzenie kilku czatów o jasno określonych zakresach zadań. Każdy z tych czatów ma swój własny obszar zainteresowań i z czasem nabiera pewnego rodzaju specjalizacji.
Zasada ta przypomina klasyczne zespoły programistów. W firmie często pracują specjaliści od baz danych, interfejsów użytkownika, infrastruktury, dokumentacji czy zapewnienia jakości. Nikt nie musi zajmować się wszystkim naraz.
To samo podejście zaskakująco dobrze sprawdza się w przypadku systemów sztucznej inteligencji. Zamiast umieszczać wszystkie pytania w jednym czacie, różne tematy są celowo rozdzielane na kilka obszarów. Dzięki temu rozmowy stają się bardziej przejrzyste, a sztuczna inteligencja może lepiej skupić się na swoich konkretnych zadaniach. Jednocześnie zmniejsza się ryzyko, że ważne informacje zagubią się wśród wielu różnych tematów.
Czat o architekturze
Czat architektoniczny często stanowi strategiczne centrum projektu. To właśnie tam podejmowane są kluczowe decyzje.
- Jakie struktury danych należy zastosować?
- Jak wygląda architektura systemu?
- Jakie moduły są dostępne?
- Jakie zasady nazewnictwa obowiązują?
- Jakie zasady techniczne należy przestrzegać?
Ta rozmowa dotyczy nie tyle poszczególnych wierszy kodu, co raczej całościowego obrazu.
W wielu projektach sprawdziło się, że decyzje architektoniczne najlepiej dokumentować w jednym miejscu, zamiast nieustannie wprowadzać zmiany w różnych czatach. Dzięki temu powstaje solidna podstawa dla wszystkich dalszych prac.
Czat architektoniczny staje się w ten sposób swego rodzaju techniczną pamięcią projektu.
Czat backendowy
Podczas gdy czat poświęcony architekturze zajmuje się kwestiami ogólnymi, czat poświęcony backendowi skupia się na samej logice biznesowej. To właśnie tutaj powstają zapytania do baz danych, interfejsy, automatyzacje i złożone procesy.
W tej dziedzinie sztuczna inteligencja może w pełni skupić się na wymaganiach technicznych, nie rozpraszając się ciągle kwestiami związanymi z projektowaniem czy dokumentacją.
Zwłaszcza w przypadku większych projektów takie rozdzielenie zadań często prowadzi do znacznie lepszych wyników. Z czasem specjalista ds. zaplecza staje się ekspertem w zakresie wewnętrznych procedur i procesów technicznych. Dzięki temu współpraca staje się bardziej wydajna i przejrzysta.
Czat w interfejsie użytkownika
Interfejsy użytkownika często podlegają zupełnie innym zasadom niż systemy zaplecza. Na pierwszym planie znajdują się tu łatwość obsługi, nawigacja, układ stron i przebieg procesów. Czat frontendowy może skupiać się właśnie na tych kwestiach.
- Jakie informacje muszą być widoczne?
- Jakie pola wprowadzania danych są wymagane?
- Jak powinna być skonstruowana maska?
- Jakie etapy przechodzi użytkownik podczas pracy?
Ponieważ ten czat nie musi jednocześnie zajmować się złożoną logiką baz danych ani kwestiami architektury, może znacznie bardziej skupić się na perspektywie użytkownika.
Zwłaszcza programiści mają czasem skłonność do przedkładania aspektów technicznych nad wygodę użytkownika. Własny czat w interfejsie użytkownika pomaga poprawić tę równowagę.
Czat dokumentacyjny
Wiele projektów kończy się niepowodzeniem nie z powodu problemów technicznych, ale z powodu braku dokumentacji. Na początku wszystko wydaje się logiczne i oczywiste. Jednak kilka miesięcy później nikt już nie pamięta, dlaczego podjęto określone decyzje.
W tym przypadku osobny czat służący do dokumentacji może przynieść ogromne korzyści. Jego zadaniem jest rejestrowanie decyzji technicznych, tworzenie przeglądów projektów, dokumentowanie zmian oraz zapewnienie długoterminowej dostępności wiedzy.
Ten czat powinien jak najściślej współpracować z pozostałymi obszarami projektu. Dokumentacja może być aktualizowana za każdym razem, gdy pojawiają się nowe funkcje lub podejmowane są decyzje dotyczące architektury.
W ten sposób krok po kroku powstaje cenne kompendium wiedzy dotyczące całego projektu.
Czat dotyczący zapewnienia jakości
Szczególnie interesującym podejściem jest powierzenie sztucznej inteligencji dodatkowej roli kontrolera. Zamiast opracowywać nowe funkcje, ten chatbot weryfikuje pracę innych chatbotów. Analizuje:
- możliwe błędy
- Problemy związane z bezpieczeństwem
- Niespójności
- Ryzyko związane z wynikami
- braki w dokumentacji
Takie podejście przypomina klasyczne przeglądy kodu w zespołach programistów. Jego główną zaletą jest to, że pozwala na uzyskanie różnych punktów widzenia.
Podczas gdy rozmowa dotycząca rozwoju często skupia się na jak najszybszym zrealizowaniu zadania, rozmowa dotycząca zapewnienia jakości poddaje to samo rozwiązanie krytycznej analizie i celowo poszukuje słabych punktów. Ta dodatkowa instancja kontrolna może znacznie podnieść jakość projektu.
Wspólna baza wiedzy
Jednak czaty z udziałem wielu specjalistów działają dobrze tylko wtedy, gdy mają dostęp do tej samej bazy wiedzy. Właśnie dlatego tak ważną rolę odgrywa scentralizowana dokumentacja projektowa. Wszystkie czaty powinny opierać się na tych samych podstawowych informacjach:
Cele projektu, decyzje architektoniczne, modele danych, konwencje nazewnicze oraz warunki techniczne.
W ten sposób nie powstaje zbiór niezależnych od siebie podprojektów, lecz wspólny system o przejrzystej strukturze. Można by powiedzieć, że dokumentacja stanowi wspólny język wszystkich czatów.
Bez tego wspólnego języka grożą nieporozumienia i sprzeczne wyniki.
Sztuczna inteligencja jako wirtualny zespół programistów
Im dłużej stosuje się tę metodę pracy, tym wyraźniej ujawnia się pewna interesująca myśl. Nowoczesne systemy sztucznej inteligencji coraz bardziej przypominają wirtualny zespół programistów.
Oczywiście nie są to prawdziwi ludzie. Niemniej jednak wiele sprawdzonych zasad organizacyjnych stosowanych w klasycznych projektach programistycznych można zaskakująco dobrze przenieść na ten obszar. Zamiast korzystać z jednej osoby, która ma zajmować się wszystkim, powstaje kilka wyspecjalizowanych ról o jasno określonych obowiązkach.
Dzięki temu projekty stają się bardziej przejrzyste, łatwiejsze do zrozumienia, a często także lepszej jakości. Zwłaszcza w przypadku większych przedsięwzięć takie podejście może mieć ogromne znaczenie. Skuteczne tworzenie oprogramowania to bowiem nie tylko programowanie. Obejmuje ono również planowanie, architekturę, dokumentację, zapewnienie jakości oraz komunikację.
Im lepiej te obszary są od siebie oddzielone, a jednocześnie ze sobą powiązane, tym większy sukces odnosi zazwyczaj cały projekt. I właśnie w tym zakresie czaty specjalistyczne wykazują swoją największą zaletę.
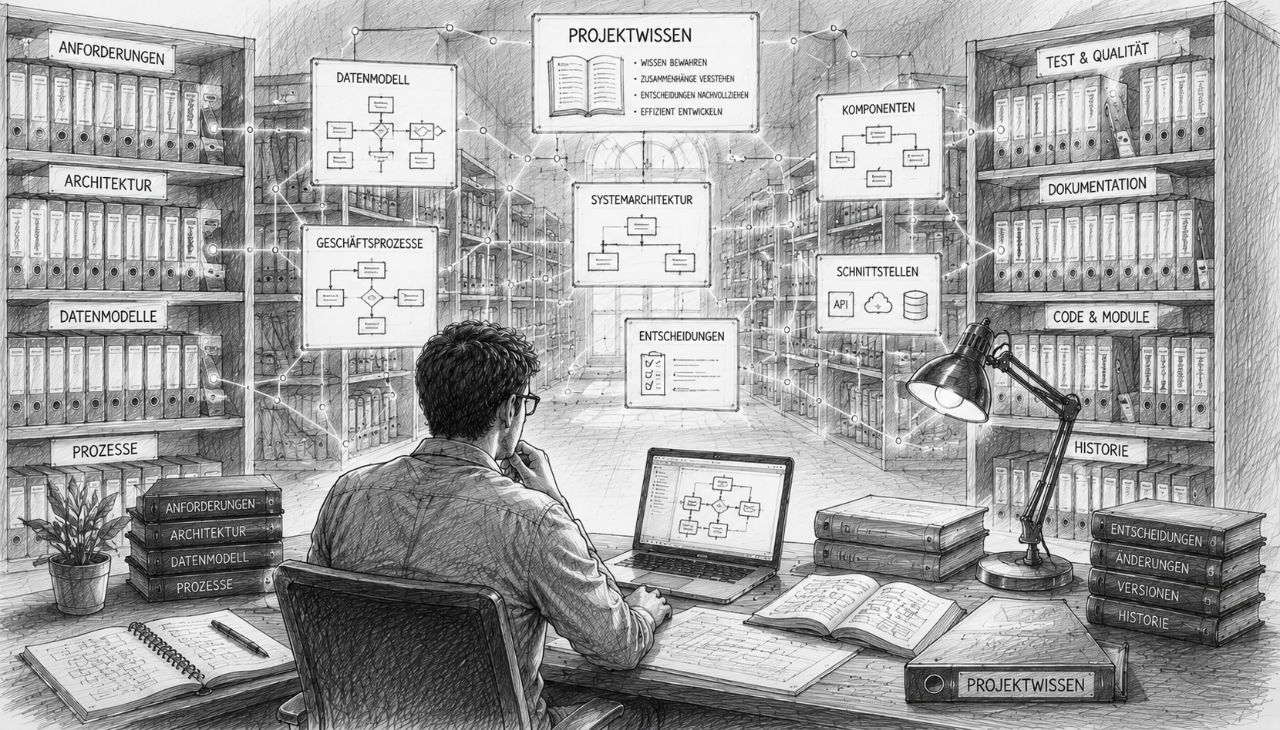
Centralna dokumentacja projektu
Prawie każdy większy projekt programistyczny zaczyna się od jasnej wizji. Cele są znane, wymagania wydają się przejrzyste, a najważniejsze decyzje są znane wszystkim zaangażowanym. Na tym wczesnym etapie często wydaje się, że obszerna dokumentacja wcale nie jest konieczna. W końcu sami wiemy, dlaczego podjęto określone decyzje. Struktury danych są znane, procesy zrozumiałe, a architektura wydaje się logiczna.
Jednak z każdym kolejnym dniem prac sytuacja ulega zmianie. Pojawiają się nowe funkcje. Wymagania się zmieniają. Wcześniejsze decyzje są rozszerzane lub dostosowywane. Do projektu dołączają kolejni programiści. Otwierane są nowe czaty z wykorzystaniem sztucznej inteligencji. Pojawiają się wyjątki i sytuacje szczególne. To, co jeszcze kilka tygodni temu wydawało się całkowicie oczywiste, powoli zaczyna tracić na znaczeniu.
Właśnie w tym momencie ujawnia się prawdziwa wartość dobrej dokumentacji projektowej. Nie służy ona przede wszystkim do wypełniania papierów czy segregatorów. Jej najważniejszym zadaniem jest zapewnienie trwałej dostępności wiedzy. Można by powiedzieć, że dokumentacja staje się pamięcią projektu.
Dlaczego projekty związane ze sztuczną inteligencją wymagają tak dużego nakładu pracy związanego z dokumentacją
Co ciekawe, dzięki nowoczesnym systemom sztucznej inteligencji dokumentacja nie traci na znaczeniu, a wręcz przeciwnie – staje się znacznie ważniejsza. W tradycyjnych projektach wiele informacji można było zapamiętać lub przekazać podczas rozmów. W przypadku współpracy z systemami sztucznej inteligencji jest to możliwe tylko w ograniczonym zakresie.
- Każdy nowy czat rozpoczyna się początkowo bez wiedzy o projekcie.
- Każda nowa rozmowa opiera się wyłącznie na informacjach, które jej przekazano.
- Każda dodatkowa sztuczna inteligencja potrzebuje kontekstu, aby mogła działać w sposób sensowny.
W związku z tym pojawia się nowe wymaganie: wiedza musi być gromadzona w sposób systematyczny. Dzięki temu dokumentacja staje się nie tylko pomocą dla ludzi, ale jednocześnie źródłem wiedzy dla systemów sztucznej inteligencji. Im większy jest projekt, tym większa jest ta korzyść.
Dobra dokumentacja pozwala na szybkie wdrożenie nowych czatów w ciągu kilku minut, zamiast ciągłego wyjaśniania tych samych ważnych informacji.
Co należy udokumentować
Często pojawia się pytanie, jakie treści w ogóle należy dokumentować. Odpowiedź jest prostsza, niż wielu się wydaje. Przede wszystkim należy dokumentować decyzje. Kod źródłowy można w każdej chwili odtworzyć lub przeanalizować. Trudniej jest natomiast z rozważaniami, które stoją za tym kodem.
- Dlaczego wybrano właśnie tę architekturę?
- Dlaczego tabela została skonstruowana w ten sposób?
- Dlaczego interfejs został zaimplementowany właśnie w ten sposób, a nie inaczej?
- Dlaczego odrzucono alternatywne rozwiązanie?
Bez dokumentacji właśnie takie informacje często się gubią. Gdy kilka miesięcy później konieczna staje się zmiana, nawet doświadczeni programiści często nie pamiętają już wszystkich okoliczności, które wpłynęły na wcześniejsze decyzje. Dobra dokumentacja pozwala zachować tę wiedzę na stałe.
Przegląd projektu jako punkt wyjścia
Każda dokumentacja powinna zaczynać się od przejrzystego przeglądu projektu. Ta sekcja stanowi punkt wyjścia dla wszystkich zainteresowanych stron. Wyjaśniono tu:
- Jaki jest cel tego projektu?
- Jakie problemy należy rozwiązać?
- Jakie są główne moduły?
- Jakie technologie są wykorzystywane?
- Jaka jest długoterminowa wizja?
Ta sekcja nie musi być zbyt obszerna. Często wystarczy kilka stron. Ważniejsze jest to, aby nowy programista lub nowa sztuczna inteligencja czatu w krótkim czasie zrozumiała, o co w ogóle chodzi.
Przegląd projektu stanowi niejako mapę całego przedsięwzięcia. Bez tej mapy nawet dobrze udokumentowane poszczególne szczegóły szybko stają się nieprzejrzyste.
Dokumentowanie modelu danych
Zgodnie z przeglądem projektu model danych stanowi jeden z najważniejszych elementów dokumentacji. Niemal każda aplikacja opiera się na danych. Klienci, artykuły, projekty, faktury, użytkownicy czy dokumenty są ze sobą powiązane i stanowią fundament systemu. Dlatego należy udokumentować:
- Jakie tabele są dostępne?
- Które pola są szczególnie ważne?
- Jakie są powiązania?
- Jakie zasady biznesowe obowiązują?
Nie chodzi tu wyłącznie o informacje techniczne. Równie ważne jest merytoryczne znaczenie danych. Sama nazwa pola często niewiele mówi. Dopiero opis jego funkcji wyjaśnia, dlaczego pole to istnieje i w jaki sposób należy z niego korzystać.
W przypadku systemów opartych na sztucznej inteligencji ten kontekst ma szczególne znaczenie. Im dokładniej opisane są struktury danych, tym bardziej precyzyjne mogą być późniejsze propozycje.
Aktualne badanie dotyczące korzystania z lokalnych systemów AI
Dokumentowanie decyzji architektonicznych
Jedną z największych słabości wielu projektów jest to, że decyzje dotyczące architektury podejmowane są wyłącznie ustnie. W momencie podejmowania decyzji wszystko wydaje się logiczne. Jednak kilka miesięcy później często nie jest jasne, dlaczego wybrano właśnie tę drogę.
Właśnie dlatego warto zapisywać ważne decyzje. Należy udokumentować nie tylko samą decyzję, ale także jej uzasadnienie.
- Jakie alternatywy zostały rozważone?
- Dlaczego zostały odrzucone?
- Jakie korzyści oferuje wybrane rozwiązanie?
Takie podejście często pozwala później zaoszczędzić ogromną ilość czasu. Zamiast ponownie podejmować stare dyskusje, programiści i systemy sztucznej inteligencji mogą korzystać z już dostępnych informacji.
Nierozwiązane zadania i znane problemy
Dobra dokumentacja opisuje nie tylko aktualny stan rzeczy, ale także to, co nie zostało jeszcze ukończone. Wiele projektów boryka się z problemem, że zadania do wykonania są rozproszone w różnych miejscach. Część z nich znajduje się w wiadomościach e-mail, część na karteczkach, a jeszcze inna w historii czatów.
W ten sposób tracimy ważne informacje. Sprawdzonym rozwiązaniem jest centralne gromadzenie otwartych kwestii. Należą do nich na przykład: planowane rozszerzenia, dług techniczny, znane błędy, propozycje ulepszeń oraz pomysły na przyszłość.
Dzięki temu uzyskuje się cenny przegląd sytuacji, zwłaszcza w przypadku długoterminowych projektów. Nowi programiści lub systemy sztucznej inteligencji od razu widzą, które zagadnienia są już znane, a jakie prace jeszcze przed nami.
Dokumentacja jako system dynamiczny
Częstym błędem jest postrzeganie dokumentacji jako zadania jednorazowego. Na początku projektu tworzy się kilka dokumentów, a potem prawie ich nie aktualizuje. W ten sposób dokumentacja szybko traci na wartości. Dobra dokumentacja projektowa jest żywa. Rośnie wraz z projektem. Dodaje się nowe decyzje. Wprowadza się zmiany. Przestarzałe informacje są aktualizowane lub usuwane.
Najlepiej, aby proces ten przebiegał w sposób ciągły w trakcie tworzenia oprogramowania. Nowoczesne systemy sztucznej inteligencji mogą w tym zakresie nawet aktywnie wspierać. Potrafią one tworzyć podsumowania, dokumentować zmiany lub aktualizować istniejące treści. Dzięki temu nakład pracy znacznie się zmniejsza.
Najważniejsza inwestycja w ramach projektu
Wielu programistów przeznacza znaczne kwoty na sprzęt, licencje na oprogramowanie lub usługi zewnętrzne. Często jednak pomija się jeden z najcenniejszych zasobów: wiedzę na temat własnego projektu.
Właśnie tę wiedzę przechowuje dokumentacja. Dba o to, by doświadczenia nie poszły na marne. Zapobiega konieczności ciągłego udzielania odpowiedzi na te same pytania. Tworzy też wspólną podstawę dla ludzi i systemów sztucznej inteligencji.
Im większy staje się projekt, tym ważniejsza staje się ta funkcja. Kto zaniedbuje dokumentację, oszczędza czas w perspektywie krótkoterminowej, ale w dłuższej perspektywie często traci go wielokrotnie więcej. Natomiast kto wcześnie stworzy scentralizowany system wiedzy, buduje fundament, który może przynosić korzyści przez wiele lat.
Dlatego dokumentacja projektu to znacznie więcej niż tylko zbiór informacji technicznych. Stanowi ona zbiorową pamięć projektu – a tym samym jeden z najważniejszych warunków udanego tworzenia oprogramowania z wykorzystaniem sztucznej inteligencji.
Vibe Coding, struktura i nowa generacja tworzenia oprogramowania
Załączony film w ciekawy sposób uzupełnia treść tego artykułu i pokazuje, jak już dziś można wykorzystać nowoczesne narzędzia sztucznej inteligencji do tworzenia własnych aplikacji przy stosunkowo niewielkim nakładzie pracy programistycznej. Na szczególną uwagę zasługuje tutaj nacisk na uporządkowane podejście. Zamiast po prostu pozwolić sztucznej inteligencji „programować na oślep“, pokazano, jak najpierw dokładnie zaplanować pomysły, zbudować struktury baz danych i zdefiniować interfejsy.

Tworzenie oprogramowania z wykorzystaniem sztucznej inteligencji: właściwa droga (zamiast chaosu) | Sebastian Claes
Właśnie to podejście pokrywa się z jednym z głównych przesłań tego artykułu: skuteczne tworzenie oprogramowania nie zaczyna się od kodu, ale od zrozumienia wymagań i procesów. Film przedstawia również aktualne narzędzia, takie jak n8n, Supabase i MCP, a także możliwości zautomatyzowanych przepływów pracy. Szczególnie cenne są wskazówki dotyczące typowych błędów w tzw. „Vibe Coding“ oraz zalecenia dotyczące stabilnych, skalowalnych i łatwych w utrzymaniu aplikacji w dłuższej perspektywie. Dzięki temu film dostarcza praktycznego wglądu w nowoczesną współpracę między programistami a sztuczną inteligencją.
Podpowiedzi na początku nowych czatów
Jedną z największych zalet nowoczesnych systemów sztucznej inteligencji jest to, że potrafią one w krótkim czasie przyswoić sobie złożone zagadnienia. Jednocześnie właśnie ta cecha stanowi również jedną z ich największych słabości.
Każda nowa rozmowa rozpoczyna się od zera, bez znajomości Twojego projektu. Oczywiście nowoczesne modele dysponują rozległą wiedzą ogólną. Znają języki programowania, bazy danych, frameworki i wiele pojęć technicznych. Nie znają jednak specyfiki Twojego projektu.
Nie wiedzą, jakie decyzje dotyczące architektury zostały już podjęte. Nie znają twoich konwencji nazewniczych. Nie mają pojęcia o wcześniejszych dyskusjach ani o celach, jakie stoją za poszczególnymi funkcjami.
Wielu programistów nie docenia tego aspektu. Otwierają nowy czat, zadają pytanie techniczne, a potem dziwią się, że odpowiedź nie pasuje idealnie do ich projektu. Często przyczyną nie jest jednak jakość sztucznej inteligencji, lecz brak wprowadzenia do projektu. I właśnie tu do gry wkraczają startprompty.
Czym właściwie jest monit startowy
Komenda startowa to w zasadzie nic innego jak standardowe wprowadzenie do nowych czatów. Zawiera ona najważniejsze informacje, których system AI potrzebuje, aby jak najszybciej zorientować się w projekcie. Można go porównać do pakietu wprowadzającego dla nowego pracownika. Zamiast za każdym razem wyjaśniać te same informacje od nowa, sztuczna inteligencja otrzymuje najważniejsze warunki ramowe już na samym początku. Dzięki temu powstaje wspólne zrozumienie sposobu pracy, jeszcze zanim rozpocznie się właściwe zadanie.
Dobry komunikat startowy nie tylko pozwala zaoszczędzić czas. Zapewnia on również spójność działania różnych czatów i podejmowania podobnych decyzji. Im większy staje się projekt, tym cenniejszy staje się ten efekt.
Jasno zdefiniować rolę sztucznej inteligencji
Jedną z najskuteczniejszych metod jest przypisanie sztucznej inteligencji konkretnej roli już na samym początku. Wielu programistów ogranicza się w swoich poleceniach wyłącznie do wymagań technicznych. Często jednak lepsze wyniki daje dodatkowe opisanie pożądanej perspektywy.
Na przykład sztuczna inteligencja może pełnić rolę architekta oprogramowania, starszego programisty, specjalisty ds. baz danych, testera lub autora dokumentacji. Dzięki temu jakość odpowiedzi często ulega poprawie. Sztuczna inteligencja otrzymuje jasne ramy odniesienia i może lepiej dostosować swoje propozycje do danego zadania.
W czacie poświęconym architekturze będzie kładła nacisk na inne kwestie niż w czacie dotyczącym testów lub dokumentacji. Takie jasne określenie roli zapewnia porządek i ogranicza nieporozumienia.
Dokumentacja projektu jako lektura obowiązkowa
Szczególnie ważnym elementem wielu poleceń początkowych powinna być główna dokumentacja projektu. Najlepiej byłoby, gdyby sztuczna inteligencja otrzymała polecenie zapoznania się najpierw z dostępnymi informacjami, zanim zacznie opracowywać zmiany lub propozycje.
Ten krok jest zaskakująco często pomijany. A przecież wiele problemów wynika właśnie z tego, że nowe czaty działają bez uwzględnienia dotychczasowych ustaleń. Jeśli dokumentacja jest konsekwentnie wdrażana, jakość współpracy często znacznie się poprawia.
Sztuczna inteligencja szybciej dostrzega powiązania. Lepiej rozumie istniejące struktury i automatycznie uwzględnia wcześniejsze decyzje. Dzięki temu w ramach projektu osiąga się znacznie większą spójność.
Można by powiedzieć: dokumentacja dostarcza wiedzy, a monit startowy sprawia, że wiedza ta jest faktycznie wykorzystywana.
Ustanowienie jednolitych zasad
Wraz ze wzrostem skali projektu często pojawia się potrzeba ustalenia jasnych zasad.
- Jak należy nazywać pola?
- Jakie standardy dokumentacji obowiązują?
- Jakie zasady architektoniczne należy przestrzegać?
- Które wytyczne dotyczące programowania mają charakter wiążący?
Dobry komunikat początkowy może trwale utrwalić takie zasady. Dzięki temu nie trzeba ich wyjaśniać od nowa przy każdym nowym zadaniu. Sztuczna inteligencja zna już wytyczne i może odpowiednio dostosować swoje propozycje.
Nie należy lekceważyć tego efektu. Wiele drobnych nieścisłości wynika po prostu z tego, że zasady nie są konsekwentnie przekazywane. Komendy startowe pomagają właśnie w ograniczeniu tego problemu.
Różne komunikaty startowe dla różnych zadań
W trakcie realizacji projektu często okazuje się, że nie wszystkie czaty mają takie same wymagania. Czat poświęcony architekturze wymaga innych informacji niż czat poświęcony dokumentacji. Czat testowy działa inaczej niż czat dotyczący interfejsu użytkownika.
Dlatego często warto opracować kilka szablonów startowych. Ich wspólny rdzeń pozostaje przy tym niezmienny. Wszystkie czaty otrzymują ten sam przegląd projektu, tę samą dokumentację i te same podstawowe zasady.
Dodatkowo można jednak zdefiniować uzupełnienia dostosowane do konkretnych zadań.
- Czat poświęcony architekturze skupia się na długoterminowych decyzjach.
- Czat backendowy – kwestie techniczne.
- Czat dokumentacyjny poświęcony identyfikowalności i zabezpieczaniu wiedzy.
- Czat poświęcony zapewnieniu jakości: analiza błędów i krytyczna ocena.
Dzięki tej specjalizacji często uzyskuje się znacznie lepsze wyniki niż w przypadku uniwersalnego, standardowego komunikatu.
Komendy startowe ewoluują wraz z projektem
Częstym błędem jest utworzenie komunikatu startowego tylko raz, a następnie brak jakichkolwiek późniejszych zmian. W praktyce jednak każdy większy projekt podlega ciągłym zmianom.
Powstają nowe moduły. Procesy ulegają zmianom. Pojawiają się nowe decyzje techniczne. Dlatego też należy regularnie weryfikować komunikaty startowe. To, co jeszcze kilka miesięcy temu było wystarczające, dziś może już być niekompletne.
Dobrze się sprawdziło traktowanie podpowiedzi startowych jako dokumentów dynamicznych. Rozwijają się one wraz z projektem i odzwierciedlają jego aktualny stan. Dzięki temu nowe czaty są zawsze na bieżąco z najnowszym stanem wiedzy.
Sztuczna inteligencja powinna współtworzyć rozwiązania, a nie tylko je wykonywać
Ciekawą cechą współczesnych systemów sztucznej inteligencji jest to, że potrafią one nie tylko wykonywać polecenia. Potrafią również kwestionować, analizować i proponować ulepszenia. Dobry komunikat początkowy nie powinien zatem zawierać wyłącznie poleceń.
Często warto wyraźnie poprosić sztuczną inteligencję o zwracanie uwagi na ewentualne problemy. Można na przykład ustalić, że ma ona zgłaszać niespójności lub aktywnie sygnalizować naruszenia architektury. Dzięki temu sztuczna inteligencja z czystego narzędzia staje się dodatkowym rozmówcą.
Oczywiście nie zastąpi to decyzji podjętej przez człowieka. Może jednak pomóc w wczesnym wykryciu zagrożeń.
Droga do profesjonalnego sposobu pracy
Wielu programistów rozpoczyna pracę z AI spontanicznie i intuicyjnie. To zupełnie normalne. Jednak wraz ze wzrostem skali projektu okazuje się, że ustrukturyzowane procesy niosą ze sobą ogromne korzyści.
Wśród tych procesów znajdują się podpowiedzi startowe. Tworzą one wspólną podstawę dla wszystkich czatów, ograniczają powtarzanie się tych samych treści i zapewniają spójne wyniki. Przede wszystkim jednak umożliwiają one systematyczne przekazywanie wiedzy.
Właśnie ta kwestia będzie prawdopodobnie zyskiwać na znaczeniu w przyszłości. Im większe są projekty i im wydajniejsze stają się systemy sztucznej inteligencji, tym większy wpływ na powodzenie przedsięwzięcia ma jakość przygotowań.
Dobre wprowadzenie to zatem znacznie więcej niż tylko kilka zdania na początek. To przepustka do projektu. I często już ta przepustka decyduje o tym, jak produktywna będzie dalsza współpraca.
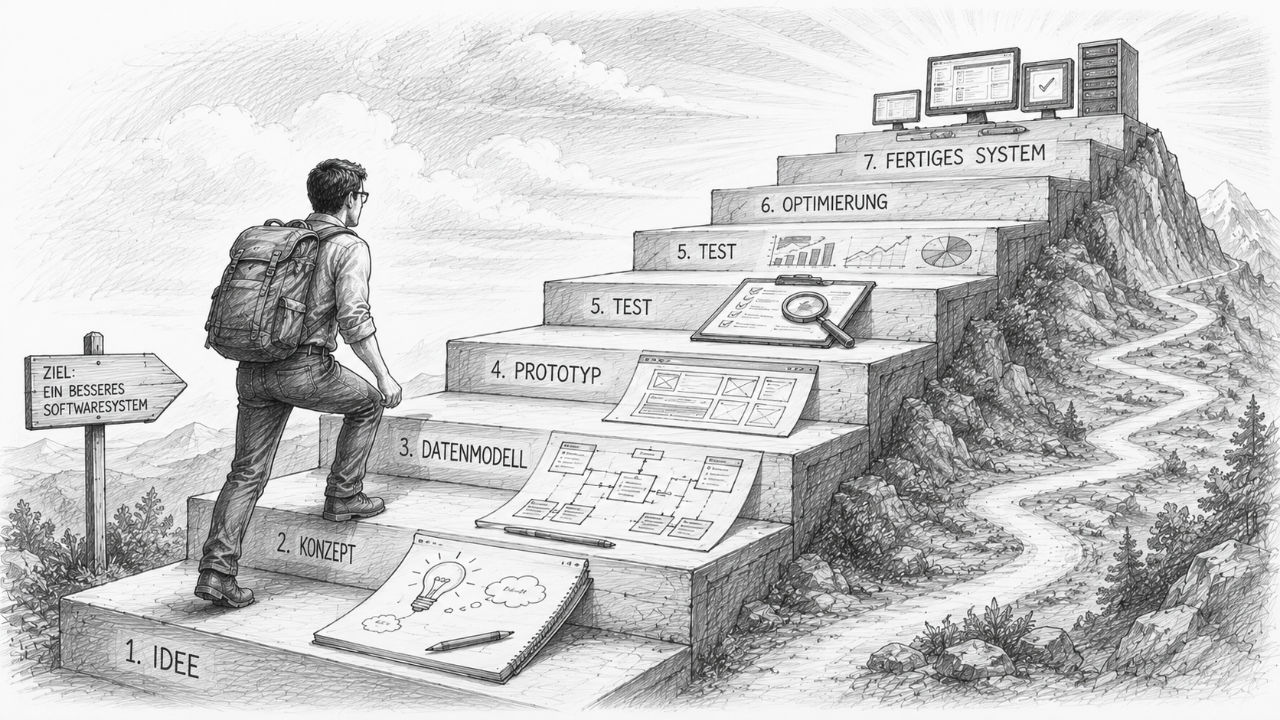
Rozwój iteracyjny zamiast ogromnych poleceń
Kto po raz pierwszy ma do czynienia z nowoczesną sztuczną inteligencją, często szuka tego jednego, idealnego polecenia, które rozwiąże wszystkie problemy. Ta wizja jest kusząca. Opisuje się swój projekt tak szczegółowo, jak to tylko możliwe, klika „Wyślij“ i chwilę później otrzymuje gotową koncepcję, kompletną strukturę bazy danych, a nawet gotowy system oprogramowania.
Na pierwszy rzut oka takie podejście wydaje się logiczne. W końcu nowoczesne systemy sztucznej inteligencji dysponują imponującymi możliwościami. Dlaczego więc nie spróbować zlecić im wykonania jak największej ilości pracy naraz?
Praktyka pokazuje jednak coś innego. Im większe i bardziej złożone staje się zadanie, tym ważniejsze staje się uporządkowane podejście. Najlepsze wyniki rzadko osiąga się dzięki jednemu, ogromnemu poleceniu. Powstają one w wyniku wielu kolejnych kroków, które na sobie opierają.
Tak jak dom nie powstaje w jednym etapie, lecz składa się z etapu planowania, wylewania fundamentów, budowy stanu surowego, wykończenia wnętrz i prac wykończeniowych, tak samo skuteczne oprogramowanie powstaje stopniowo. Sztuczna inteligencja przyspiesza ten proces, ale go nie zastępuje.
Dlaczego duże zadania stanowią problem
Wielu programistów na początku spotyka się z podobnym zjawiskiem. Sformułują bardzo obszerne wymagania i otrzymują imponującą odpowiedź. Jednak po bliższym przyjrzeniu się zauważają, że brakuje ważnych szczegółów lub że niektóre założenia nie pasują do projektu.
Nie wynika to z tego, że sztuczna inteligencja działa źle. Raczej z tym, że wraz z każdym dodatkowym wymaganiem wzrasta złożoność zadania. Im większe jest zadanie, tym więcej powiązań trzeba uwzględnić jednocześnie. Jednocześnie rośnie prawdopodobieństwo, że poszczególne elementy zostaną przeoczone lub błędnie zinterpretowane.
Szczególnie w przypadku większych projektów programistycznych może to szybko doprowadzić do problemów. Nawet niewielki błąd w modelu danych może mieć wpływ na wiele innych obszarów. Niejasne wymagania mogą później spowodować konieczność wykonania znacznej ilości dodatkowej pracy. Dlatego zazwyczaj rozsądniej jest podzielić duże przedsięwzięcia na mniejsze, łatwiejsze do opanowania etapy.
Siła małych kroków
Ciekawą cechą współczesnych systemów sztucznej inteligencji jest to, że potrafią one niezwykle szybko reagować na nowe informacje. Dzięki temu iteracyjny sposób pracy staje się szczególnie atrakcyjny.
Zamiast próbować opracować cały system za jednym zamachem, najpierw zajmujemy się niewielkim jego fragmentem. Jest on następnie sprawdzany, ulepszany i dokumentowany. Dopiero potem przechodzimy do kolejnego etapu.
Podejście to przypomina nowoczesne metody zwinnego tworzenia oprogramowania. Zamiast pracować miesiącami nad jednym dużym efektem końcowym, powstaje wiele małych wyników pośrednich. Każdy z tych wyników można ocenić i w razie potrzeby skorygować. Dzięki temu ryzyko znacznie się zmniejsza. Błędy są wykrywane wcześniej, a wprowadzanie poprawek jest łatwiejsze.
Od ogólnego do szczegółowego
Sprawdzoną metodą jest najpierw zdefiniowanie ogólnych kontekstów. Na początku pojawiają się pytania takie jak:
- Jakie zagadnienie należy rozwiązać?
- Jakie główne moduły są potrzebne?
- Którzy użytkownicy korzystają z systemu?
- Jakie dane należy zarządzać?
Dopiero po wyjaśnieniu tych podstaw można przejść do kolejnego etapu.
- Poniżej przedstawiono szczegółowy opis poszczególnych modułów.
- W ten sposób powstają modele danych, procesy i interfejsy użytkownika.
- Następnie omówimy szczegóły techniczne i konkretne sposoby wdrożenia.
To stopniowe przechodzenie od ogólnego do szczegółowego ma ogromną zaletę. Sztuczna inteligencja może rozwijać każdy poziom w oparciu o już potwierdzone decyzje. Dzięki temu powstaje znacznie stabilniejsza struktura.
Znaczenie egzaminów śródokresowych
Częstym błędem jest natychmiastowe przyjmowanie wyników bez ich wystarczającej weryfikacji. Właśnie dlatego, że sztuczna inteligencja działa tak szybko, czasami pojawia się pokusa, by od razu przejść do kolejnego etapu. Jednak w dłuższej perspektywie często rozsądniej jest świadomie zatrzymać się po każdym ważnym etapie.
- Czy wynik jest zgodny z celami projektu?
- Czy uwzględniono wszystkie wymagania?
- Czy istnieją potencjalne słabe punkty?
- Czy decyzje są odpowiednio udokumentowane?
Takie kontrole pośrednie wymagają wprawdzie nieco czasu, ale często pozwalają zaoszczędzić sporo wysiłku na późniejszych etapach projektu. Im wcześniej wykryje się problemy, tym łatwiej będzie je naprawić.
Iteracje jako proces uczenia się
Kolejną zaletą rozwoju iteracyjnego jest to, że uczy się nie tylko sztuczna inteligencja, ale także sam programista. Wiele wymagań ujawnia się dopiero w trakcie pracy.
- Proces, który początkowo wydawał się sensowny, może okazać się niepraktyczny.
- Należy rozszerzyć strukturę danych.
- Interfejs użytkownika wymaga dodatkowych informacji.
Takie spostrzeżenia są nieodłączną częścią każdego projektu. Dzięki iteracyjnemu podejściu nie stanowią one problemu, lecz naturalny element procesu tworzenia. Każda iteracja pogłębia wspólne zrozumienie systemu. Dzięki temu jakość rośnie krok po kroku.
Dlaczego dążenie do perfekcji na początku rzadko ma sens
Wielu programistów próbuje znaleźć idealne rozwiązania już podczas pierwszych rozmów. Jest to zrozumiałe, ale często nie jest konieczne. W praktyce najlepsze systemy powstają zazwyczaj w wyniku wielu drobnych ulepszeń.
Pierwsza wersja modelu danych nie musi być idealna. Podobnie jak pierwszy interfejs użytkownika. Ważniejsze jest stworzenie działającej podstawy, którą można następnie dalej rozwijać.
Właśnie w tym zakresie sztuczna inteligencja pokazuje swoje mocne strony. Umożliwia ona szybkie wprowadzanie zmian i wspiera ciągłe doskonalenie. Dzięki temu znacznie łatwiej jest testować pomysły i stopniowo je optymalizować.
Sztuczna inteligencja jako partner do ćwiczeń
 Kto pracuje iteracyjnie, nie traktuje sztucznej inteligencji wyłącznie jako narzędzia wykonawczego. Staje się ona partnerem do rozmowy. Można omawiać nowe pomysły. Można porównywać alternatywne rozwiązania. Można analizować ryzyko. Na ten temat „Sztuczna inteligencja jako sparingpartner“ Napisałem już kiedyś szczegółowy artykuł na ten temat.
Kto pracuje iteracyjnie, nie traktuje sztucznej inteligencji wyłącznie jako narzędzia wykonawczego. Staje się ona partnerem do rozmowy. Można omawiać nowe pomysły. Można porównywać alternatywne rozwiązania. Można analizować ryzyko. Na ten temat „Sztuczna inteligencja jako sparingpartner“ Napisałem już kiedyś szczegółowy artykuł na ten temat.
Dzięki temu proces rozwoju nabiera tempa. Zamiast długo czekać na wdrożenie pomysłu, w krótkim czasie powstają konkretne propozycje, które można następnie ocenić i udoskonalić.
Taki dialog często przynosi lepsze rezultaty niż sztywne plany rozplanowane na wiele miesięcy.
Droga do lepszych wyników
Im większy staje się projekt, tym wyraźniej widać zalety pracy iteracyjnej. Duże systemy rzadko powstają w wyniku jednego genialnego projektu. Powstają one w wyniku wielu decyzji, które na sobie opierają.
- Każdy krok przynosi nowe spostrzeżenia.
- Każda iteracja pogłębia zrozumienie.
- Każda kontrola podnosi jakość.
Nowoczesne systemy sztucznej inteligencji znacznie przyspieszają ten proces. Nie zastępują go jednak całkowicie. Dlatego programiści powinni oprzeć się pokusie, by próbować rozwiązać wszystko za pomocą jednego, ogromnego polecenia.
Najbardziej udane projekty rzadko powstają w wyniku jednego wielkiego pomysłu. Powstają one dzięki wielu dobrze przemyślanym, niewielkim krokom, które razem tworzą wielką całość. I właśnie w tym tkwi jedna z najważniejszych lekcji współczesnego tworzenia oprogramowania opartego na sztucznej inteligencji.

Sztuczna inteligencja jako wirtualny zespół programistów
Wiele osób nadal postrzega sztuczną inteligencję jako niezwykle wydajne narzędzie. Pogląd ten nie jest błędny, ale często okazuje się zbyt wąski. Każdy, kto przez dłuższy czas pracuje z nowoczesnymi systemami sztucznej inteligencji, prędzej czy później robi ciekawe doświadczenie. Współpraca coraz mniej przypomina korzystanie z narzędzia, a coraz bardziej przypomina pracę w zespole.
Oczywiście sztuczna inteligencja nie posiada świadomości, własnych interesów ani osobistej odpowiedzialności. Niemniej jednak może ona pełnić różne role, wnosić odmienne perspektywy oraz wykonywać zadania, które wcześniej byłyby rozdzielone między kilku pracowników.
Właśnie w tym tkwi jedna z najciekawszych tendencji we współczesnym tworzeniu oprogramowania. Prawdziwa siła często nie wynika z tego, że pojedyncza sztuczna inteligencja jest wyjątkowo inteligentna. Wynika ona z połączenia kilku wyspecjalizowanych metod działania.
Nie oznacza to jednak, że programista zostanie zastąpiony. Jego rola zmienia się raczej w kierunku koordynacji, zarządzania i kontroli jakości.
Dlaczego jedno spojrzenie często nie wystarcza
W klasycznych projektach programistycznych rzadko zdarza się, by wszyscy uczestnicy mieli takie samo spojrzenie na sprawę. Architekt myśli inaczej niż programista. Tester zwraca uwagę na inne aspekty niż projektant. Kierownik projektu zadaje inne pytania niż specjalista ds. baz danych. Te różne punkty widzenia mają jedną wielką zaletę: błędy są wykrywane wcześniej, a rozwiązania rozpatrywane z wielu perspektyw.
Właśnie tę zasadę można zaskakująco dobrze zastosować w systemach sztucznej inteligencji. Zamiast wykorzystywać sztuczną inteligencję wyłącznie jako programistę, można jej przypisywać różne role i pozwolić jej spojrzeć na to samo zagadnienie z różnych perspektyw.
Dzięki temu często uzyskuje się znacznie lepsze wyniki. Na przykład czat zajmujący się architekturą może opracować rozwiązanie, podczas gdy czat zajmujący się zapewnieniem jakości poddaje to rozwiązanie krytycznej analizie.
Dyskusja ta toczy się wprawdzie w ramach różnych podmiotów zajmujących się sztuczną inteligencją, ale opiera się na tych samych zasadach, co w tradycyjnych zespołach programistów.
Wirtualny architekt oprogramowania
Szczególnie ważną rolę pełni architekt oprogramowania. W tej rozmowie skupiamy się mniej na poszczególnych funkcjach, a bardziej na długoterminowych skutkach podejmowanych decyzji.
- Jaka struktura będzie odpowiednia?
- Które moduły należy odłączyć?
- Jak uwzględnić przyszłe rozbudowy?
- Jakie ryzyko wiąże się z konkretnymi decyzjami projektowymi?
Podczas gdy programiści często, co zrozumiałe, skupiają się na bieżącym zadaniu, wirtualny architekt patrzy na system jako całość. Dzięki temu powstaje dodatkowa warstwa bezpieczeństwa.
Wiele późniejszych problemów można uniknąć, jeśli podstawowe kwestie architektoniczne zostaną przemyślane na wczesnym etapie. Szczególnie w przypadku większych projektów może to przynieść ogromne korzyści.
Wirtualny programista
Najbardziej oczywistą rolą pozostaje oczywiście rola programisty. To właśnie tutaj powstają konkretne rozwiązania, zapytania do baz danych, interfejsy, interfejsy użytkownika oraz logika biznesowa. Wydajność nowoczesnych systemów sztucznej inteligencji w tym obszarze jest imponująca. Zadania, które wcześniej wymagałyby kilku godzin lub dni, często można przygotować w ciągu zaledwie kilku minut.
Nie należy jednak zapominać o jednej ważnej kwestii. Tempo wdrażania nie może skłaniać do rezygnacji z analizy i weryfikacji. Nawet najlepszy wirtualny programista potrzebuje jasnych wytycznych, zrozumiałych celów i rzetelnej dokumentacji.
Im solidniejsza jest ta podstawa, tym lepsze są zazwyczaj wyniki.
Wirtualny tester
W wielu projektach wciąż nie docenia się roli jednej osoby: testera. Programiści, co zrozumiałe, skupiają się na tworzeniu rozwiązań. Testerzy natomiast skupiają się na wykrywaniu problemów.
To podejście różni się zasadniczo. Czat testowy może ukierunkowanie wyszukiwać słabe punkty. Może symulować sytuacje błędów, badać warunki brzegowe i zadawać kluczowe pytania.
- Co się dzieje w przypadku wprowadzenia nieprawidłowych danych?
- Jak system zachowuje się w przypadku brakujących danych?
- Jakie problemy związane z bezpieczeństwem mogą się pojawić?
- Jakie szczególne przypadki zostały pominięte?
Takie spojrzenie często pozwala dostrzec kwestie, które nie były widoczne podczas samego procesu tworzenia. Dlatego często warto zlecić sprawdzenie nowych funkcji oddzielnej roli opartej na sztucznej inteligencji.
Wirtualny autor dokumentacji
Dokumentacja rzadko należy do najpopularniejszych zadań w ramach projektu. Jednocześnie jest to jedno z najważniejszych zadań. Wirtualny autor dokumentacji może pomóc w systematycznym gromadzeniu wiedzy. Tworzy opisy projektów, dokumentuje decyzje, sporządza podsumowania spotkań oraz aktualizuje dokumentację techniczną.
Szczególną zaletą jest to, że prace te mogą być prowadzone równolegle z procesem rozwoju. Zamiast uzupełniać dokumentację dopiero na końcu, staje się ona stałym elementem projektu.
Dzięki temu wiedza pozostaje stale dostępna, a nowi członkowie zespołu – niezależnie od tego, czy są to ludzie, czy sztuczna inteligencja – mogą znacznie szybciej się wdrożyć.
Wirtualny krytyk
Szczególnie interesującą rolą jest rola krytycznego recenzenta. Ten czat ma inny cel niż pozostali uczestnicy.
Nie powinien się zgadzać. Powinien kwestionować.
Analizuje założenia, szuka słabych punktów i sprawdza, czy podjęte decyzje są rzeczywiście uzasadnione. Zwłaszcza programiści mają czasem skłonność do przywiązywania się do konkretnego rozwiązania. To ludzkie. Krytyczna rozmowa z botem opartym na sztucznej inteligencji może pomóc w dostrzeżeniu alternatywnych punktów widzenia.
- Być może istnieje prostsze rozwiązanie.
- Być może przeoczono jakiś ważny wymóg.
- Być może pojawią się długoterminowe zagrożenia.
Takie wskazówki są często niezwykle cenne.
Człowiek pozostaje kierownikiem projektu
Pomimo całego entuzjazmu związanego z nowoczesnymi systemami sztucznej inteligencji należy jednak pamiętać o jednej rzeczy. Odpowiedzialność spoczywa na człowieku. Sztuczna inteligencja może przedstawiać propozycje. Potrafi analizować, weryfikować i dokumentować. Potrafi nawet symulować różne scenariusze. Ostateczne decyzje nadal jednak podejmuje programista, przedsiębiorca lub kierownik projektu.
To ma sens. Tylko ludzie znają cele biznesowe danego projektu. Tylko ludzie potrafią w pełni ocenić aspekty ekonomiczne, prawne lub strategiczne.
Sztuczna inteligencja poszerza możliwości. Nie zastępuje jednak odpowiedzialności.
Przyszłość pracy zespołowej
Im dłużej pracuje się z AI, tym wyraźniej widać, że udane projekty coraz bardziej przypominają współpracę między ludźmi a specjalistami ds. technologii cyfrowych. Programista nie pracuje już samodzielnie. Jednocześnie nie zostaje on jednak zastąpiony. Powstaje natomiast nowa forma pracy zespołowej.
Człowiek wyznacza kierunek, podejmuje decyzje i ponosi odpowiedzialność za wynik. Kilka wyspecjalizowanych funkcji opartych na sztucznej inteligencji wspiera go w zakresie analizy, rozwoju, dokumentacji, testów i zapewnienia jakości.
Właśnie w tym może tkwić jedna z największych zmian nadchodzących lat. Decydujące znaczenie nie będzie miało to, czy sztuczna inteligencja zastąpi ludzi, ale to, jak dobrze ludzie nauczą się współpracować z wirtualnym zespołem programistów.
Kto opanuje tę współpracę, będzie w przyszłości mógł realizować projekty programistyczne często szybciej, w sposób bardziej uporządkowany i z zachowaniem wyższej jakości niż kiedykolwiek wcześniej.
Agenci AI, umiejętności i kolejny etap ewolucji tworzenia oprogramowania
Film udostępniony przez Fraunhofer IEM nawiązuje do myśli, która pojawia się wielokrotnie również w niniejszym artykule: przyszłość tworzenia oprogramowania może w mniejszym stopniu opierać się na poszczególnych aplikacjach, a w znacznie większym – na wiedzy, kontekście i wyspecjalizowanych agentach AI. W centrum uwagi znajdują się tzw. „umiejętności“ – ustrukturyzowane moduły wiedzy i zadań, które umożliwiają systemom AI samodzielne wykonywanie złożonych czynności.

Agenci AI i umiejętności: koniec klasycznego tworzenia oprogramowania? | Fraunhofer IEM
Szczególnie interesujące jest tu podobieństwo do współczesnego tworzenia oprogramowania opartego na sztucznej inteligencji: na pierwszym planie nie stoją już pojedyncze linijki kodu, lecz opis procesów, reguł i powiązań. Film w przystępny sposób wyjaśnia, w jaki sposób technologie takie jak MCP (Model Context Protocol), systemy agentowe i centralne źródła wiedzy mogą ze sobą współdziałać. Omówiono również kwestię, czy klasyczne oprogramowanie zostanie w dłuższej perspektywie uzupełnione lub częściowo zastąpione przez elastyczne systemy agentowe. Niezależnie od tego, jak szybko postępuje ten rozwój, film w imponujący sposób pokazuje, dlaczego kontekst, dokumentacja i zarządzanie wiedzą mogą w przyszłości należeć do najważniejszych zasobów nowoczesnych projektów oprogramowania.
Typowe błędy w procesie tworzenia oprogramowania z wykorzystaniem sztucznej inteligencji
Historia techniki nieustannie powtarza podobny schemat. Gdy tylko pojawiają się nowe narzędzia, wiele osób skupia się najpierw na możliwościach, a znacznie mniej na zagrożeniach. Tak było w przypadku pierwszych komputerów, baz danych, wprowadzenia internetu, a dziś – sztucznej inteligencji.
Ten entuzjazm jest zrozumiały. Nowoczesne systemy sztucznej inteligencji potrafią w ciągu kilku minut wykonać zadania, które wcześniej zajmowałyby godziny lub dni. Analizują wymagania, opracowują koncepcje, piszą kod i pomagają w tworzeniu dokumentacji.
Jednak właśnie ta szybkość bywa czasem źródłem problemów. Wiele błędów nie wynika z tego, że sztuczna inteligencja działa nieprawidłowo. Powstają one dlatego, że ludzie błędnie oceniają sposób działania sztucznej inteligencji lub zaniedbują istotne podstawy.
Kto chce odnosić długoterminowe sukcesy w tworzeniu oprogramowania z wykorzystaniem sztucznej inteligencji, powinien zatem znać najczęstsze pułapki.
Błąd nr 1: Zbyt mało kontekstu
Najprawdopodobniej najczęstszym błędem jest dostarczanie sztucznej inteligencji zbyt małej ilości informacji. Wielu programistów formułuje bardzo krótkie zadania, a mimo to oczekuje niezwykle precyzyjnych wyników.
- Sztuczna inteligencja ma opracować funkcję, ale nie zna szczegółów projektu.
- Ma zaprojektować strukturę bazy danych, ale nie ma pojęcia o procesach biznesowych.
- Ma zaprojektować interfejs użytkownika, ale nie zna przyszłych użytkowników.
Oczywiście sztuczna inteligencja i tak może udzielić odpowiedzi. Będzie próbowała sformułować sensowne hipotezy w oparciu o swoją ogólną wiedzę. Problem polega na tym, że hipotezy te niekoniecznie będą pasowały do Twojego projektu. Im większa luka w wiedzy, tym większe prawdopodobieństwo nieporozumień.
Dlatego obowiązuje prosta zasada: jeśli wynik nie odpowiada oczekiwaniom, przyczyną często nie jest sztuczna inteligencja, lecz brak kontekstu.
Błąd nr 2: Zadania o zbyt dużym zakresie
Kolejnym częstym błędem jest powierzenie sztucznej inteligencji zbyt wielu zadań naraz. Zwłaszcza początkujący użytkownicy mają skłonność do formułowania bardzo obszernych poleceń. Chcą oni stworzyć kompletny system ERP, zaprojektować całą platformę lub zlecić opracowanie kompletnego oprogramowania dla firmy.
To podejście jest zrozumiałe. W końcu wydajność nowoczesnych modeli robi ogromne wrażenie. W praktyce jednak najlepsze wyniki osiąga się zazwyczaj dzięki stopniowemu podejściu. Duże projekty należy podzielić na mniejsze, jasno określone zadania.
- Najpierw opracowuje się architekturę.
- Następnie model danych.
- Następnie poszczególne moduły.
- Następnie interfejsy użytkownika.
- Na koniec testy i optymalizacje.
Takie podejście nie tylko podnosi jakość wyników, ale także ułatwia kontrolę. Małe kroki znacznie łatwiej jest sprawdzić niż ogromne, kompleksowe rozwiązania.
Błąd nr 3: Brak dokumentacji
Wielu programistów zna ten problem już z klasycznych projektów. Dopóki wszystko jest jeszcze świeże w pamięci, dokumentacja wydaje się zbędna. Kilka tygodni lub miesięcy później sytuacja zazwyczaj wygląda zupełnie inaczej.
- Dlaczego utworzono tę tabelę?
- Dlaczego podjęto tę decyzję projektową?
- Dlaczego wybrano właśnie to rozwiązanie?
Bez dokumentacji takie informacje giną. W przypadku projektów opartych na sztucznej inteligencji błąd ten ma często jeszcze poważniejsze konsekwencje. Nowe czaty nie mają wiedzy na temat wcześniejszych rozmów. Nowi członkowie zespołu nie znają kontekstu. Ważne decyzje trzeba ciągle na nowo wyjaśniać.
Powoduje to niepotrzebne dyskusje i powielanie pracy. Dlatego też konsekwentna dokumentacja projektowa należy do najważniejszych czynników decydujących o sukcesie w nowoczesnym tworzeniu oprogramowania.
Błąd nr 4: Ślepa wiara
Jakość współczesnych systemów sztucznej inteligencji może robić ogromne wrażenie. Właśnie dlatego czasami pojawia się niebezpieczna pokusa. Zaczynamy nie poddawać wyników wystarczającej analizie. Błąd ten pojawia się szczególnie często u programistów, którzy właśnie odnieśli swoje pierwsze większe sukcesy w dziedzinie sztucznej inteligencji.
Nagle złożone zapytania zaczynają działać. Interfejsy są tworzone automatycznie. Dokumentacja powstaje w ciągu kilku minut. Jednak pomimo wszystkich tych postępów pozostaje jeden ważny fakt:
- Sztuczna inteligencja może popełniać błędy.
- Może błędnie interpretować zależności.
- Może opierać się na nieaktualnych założeniach.
- Potrafi opracowywać rozwiązania techniczne, które choć wydają się sensowne, mają jednak pewne słabe punkty.
Dlatego każdą ważną decyzję należy dokładnie przeanalizować. Zaufanie ma sens. Ślepe zaufanie natomiast rzadko.
Błąd nr 5: Przełączanie się między czatami bez planu
Wraz z nabywaniem doświadczenia w realizacji projektów często powstaje wiele różnych czatów. Zasadniczo jest to słuszne podejście. Problem pojawia się jednak, gdy brakuje wspólnej struktury. Wówczas ważne informacje są rozproszone w różnych miejscach.
- Decyzje dotyczące architektury są podejmowane na czacie.
- Dokumentacja powstaje w innym miejscu.
- Nowe funkcje są opracowywane w trzeciej wersji.
Po kilku tygodniach nikt już nie wie dokładnie, gdzie znajdują się poszczególne informacje. Skutkiem tego są sprzeczności, niespójności i niepotrzebna dodatkowa praca. Dlatego projekty należy od samego początku jasno zorganizować.
Specjalistyczne czaty są pomocne, ale wymagają wspólnej bazy wiedzy i scentralizowanej dokumentacji. Tylko w ten sposób można stworzyć spójny, całościowy system.
Błąd nr 6: Traktowanie sztucznej inteligencji jak wyroczni
Kolejnym błędem w rozumowaniu jest postrzeganie sztucznej inteligencji jako nieomylnego autorytetu. Wiele odpowiedzi wydaje się sformułowanych w przekonujący sposób. Właśnie w tym tkwi czasem niebezpieczeństwo. Sztuczna inteligencja często przedstawia swoje propozycje z wielką pewnością siebie, nawet jeśli istnieją pewne wątpliwości. Nie oznacza to, że celowo wprowadza w błąd. Po prostu działa w oparciu o prawdopodobieństwa statystyczne.
Dlatego warto nauczyć się krytycznie podchodzić do odpowiedzi. Nie każde eleganckie sformułowanie jest automatycznie prawdziwe. Nie każde wyjaśnienie brzmiące technicznie jest automatycznie poprawne. Sztuczna inteligencja dostarcza sugestii, a nie ostatecznych prawd.
Im wcześniej przyswoimy sobie to podejście, tym lepsza będzie współpraca.
Błąd nr 7: Brak dostosowania procesów
Niektórzy programiści próbują pracować z wykorzystaniem sztucznej inteligencji dokładnie tak samo, jak wcześniej bez niej. Używają nowych narzędzi jedynie jako szybszego generatora kodu.
W ten sposób tracą znaczną część swojego potencjału. Prawdziwa siła nowoczesnej sztucznej inteligencji nie polega wyłącznie na pisaniu kodu. Polega ona na analizie, dokumentacji, planowaniu, zapewnianiu jakości i zarządzaniu wiedzą.
Kto nie dostosowuje swojego sposobu pracy, często wykorzystuje jedynie niewielką część dostępnych możliwości. Dlatego programiści odnoszący sukcesy uczą się udoskonalać swoje procesy. Systematycznie włączają sztuczną inteligencję do swoich procedur roboczych i tworzą nowe formy współpracy.
Błędy są nieodłączną częścią procesu uczenia się
Pomimo wszystkich ostrzeżeń nie należy zapominać o jednej ważnej kwestii. Błędy są czymś normalnym. Każda nowa technologia wymaga doświadczenia. Nikt nie tworzy od samego początku idealnych poleceń, idealnej dokumentacji ani idealnych procesów.
Współpraca z AI to w końcu umiejętność, którą rozwija się poprzez praktyczne doświadczenie. Z każdym projektem rośnie zrozumienie tego, jakie informacje są istotne, jakie metody pracy się sprawdzają i jakich błędów należy unikać.
Właśnie dlatego nie należy traktować niepowodzeń jako porażki. Często są one jedynie wskazówką, że dany proces można ulepszyć.
Jeśli przyjrzeć się najczęstszym błędom, można dostrzec interesującą prawidłowość. Zaskakujące jest to, że większość problemów ma niewiele wspólnego z programowaniem. Wynikają one z braku informacji, nieuporządkowania, niedostatecznej dokumentacji lub błędnych oczekiwań.
Realizacja techniczna często nie stanowi największego wyzwania. Prawdziwym wyzwaniem jest uporządkowanie wiedzy, wyjaśnienie powiązań oraz sensowne zorganizowanie współpracy między człowiekiem a sztuczną inteligencją.
Kto opanuje te podstawy, automatycznie uniknie wielu typowych błędów. I właśnie dzięki temu w rezultacie powstaje nie tylko lepszy kod, ale zazwyczaj także znacznie lepsze oprogramowanie.

Nie korzystaj z Codex, dopóki nie obejrzysz tego filmu! (Superaplikacja ChatGPT) | Everlast AI
Praktyczny przykład większego projektu
Do tej pory zajmowaliśmy się przede wszystkim zasadami. Rozmawialiśmy o tym, dlaczego kontekst jest ważniejszy od kodu, dlaczego dokumentacja odgrywa kluczową rolę oraz jak można rozdzielić większe projekty na kilka wyspecjalizowanych czatów.
Ale jak to wszystko wygląda w praktyce? Odpowiedź brzmi: zaskakująco nieciekawie.
Wiele osób wyobraża sobie tworzenie oprogramowania z wykorzystaniem sztucznej inteligencji tak, jakby wystarczyło wpisać jedno polecenie, a kilka godzin później otrzymać gotowy system. Takie wyobrażenia są dodatkowo wzmacniane przez filmy reklamowe i imponujące prezentacje.
Rzeczywistość wygląda inaczej. Nawet przy wykorzystaniu sztucznej inteligencji duże projekty powstają krok po kroku. Różnica nie polega na tym, że planowanie i struktura stają się zbędne. Wręcz przeciwnie: stają się ważniejsze niż kiedykolwiek wcześniej.
Aby to wyjaśnić, w niniejszym rozdziale przyjrzymy się typowemu przykładowi tworzenia większego systemu oprogramowania. Nie chodzi tu o konkretny produkt, lecz o uogólniony proces tworzenia, jaki może mieć miejsce w wielu projektach.
Pomysł na projekt
Prawie każdy projekt zaczyna się od pomysłu. Dostrzega się problem, lukę rynkową lub nieefektywny proces pracy i na tej podstawie tworzy się wizję nowego rozwiązania programowego.
Właśnie w tym momencie często rozpoczyna się pierwsza współpraca z AI. Zamiast od razu mówić o bazach danych czy interfejsach użytkownika, najpierw opisuje się rzeczywisty cel.
- Jakie zagadnienie należy rozwiązać?
- Kto będzie później korzystał z tego oprogramowania?
- Jakie korzyści ma ona zapewnić?
- Jakie rozwiązania są już dostępne?
Ten pierwszy krok wydaje się często prosty, ma jednak ogromne znaczenie. Im jaśniej sformułowana jest koncepcja projektu, tym łatwiej sztucznej inteligencji będzie klasyfikować późniejsze decyzje. Dobry opis projektu staje się w ten sposób swego rodzaju kompasem dla wszystkich kolejnych etapów rozwoju.
Powstaje model danych
Po zdefiniowaniu podstawowych celów rozpoczyna się właściwe opracowywanie struktury projektu. W wielu przypadkach najpierw skupia się uwagę na danych.
- Jakie informacje należy przechowywać?
- Jakie obiekty istnieją?
- Jakie relacje je łączą?
Już w tym miejscu widać jedną z największych zalet nowoczesnych systemów sztucznej inteligencji. Mogą one pomóc w dostrzeżeniu powiązań, które samemu mogłoby się przeoczyć.
Jednocześnie odpowiedzialność spoczywa na programiście. Sztuczna inteligencja może przedstawiać propozycje, wskazywać alternatywy i opracowywać struktury. Jednak to, czy propozycje te są rzeczywiście sensowne, nadal wymaga fachowej weryfikacji.
Często powstaje kilka projektów, które następnie są omawiane i dopracowywane. Celem nie jest jak najszybsze stworzenie modelu danych, lecz opracowanie modelu, który będzie funkcjonalny w dłuższej perspektywie.
Architektura zostaje zdefiniowana
Wraz z rosnącą przejrzystością danych rozpoczyna się kolejny etap. Teraz pojawia się pytanie, w jaki sposób poszczególne elementy systemu powinny ze sobą współpracować.
- Jakie moduły są potrzebne?
- Jakie interfejsy są wymagane?
- W jaki sposób rozszerzenia mają być później zintegrowane?
Właśnie na tym etapie widać zalety wyspecjalizowanych czatów. Czat poświęcony architekturze może skupiać się na długoterminowych kwestiach strukturalnych, podczas gdy inne czaty opracowują już pierwsze szczegółowe koncepcje.
Równolegle powiększa się dokumentacja projektu. Każda ważna decyzja jest rejestrowana. Nie tylko sam wynik, ale także uzasadnienie tej decyzji. W ten sposób krok po kroku powstaje przejrzysta baza wiedzy.
Pierwsze prototypy
W końcu nadchodzi moment, w którym teoria spotyka się z praktyką.
- Powstają pierwsze prototypy.
- Projektuje się interfejsy użytkownika.
- Testowane są zapytania do bazy danych.
- Symulowane są procesy robocze.
W tym momencie wielu programistów dostrzega ciekawy efekt. Pierwsze widoczne rezultaty są ogromną motywacją. Jednocześnie pojawiają się nowe pytania, których nie dało się przewidzieć na etapie planowania. Być może brakuje niektórych pól. Być może trzeba dostosować procesy. Być może okaże się, że pierwotne założenie nie ma racji bytu.
To zupełnie normalne. Tworzenie oprogramowania nie jest procesem liniowym. Nawet w przypadku sztucznej inteligencji jakość osiąga się poprzez iterację i ciągłe doskonalenie.
Współpraca między kilkoma rolami sztucznej inteligencji
Wraz ze wzrostem skali projektu coraz większego znaczenia nabiera podział pracy. Programista nie pracuje już z jednym systemem sztucznej inteligencji, lecz z wieloma wyspecjalizowanymi modułami.
- Czat analizuje architekturę.
- Ktoś inny opracowuje funkcje.
- Trzeci dokumentuje decyzje.
- Czwarty sprawdza ewentualne słabe punkty.
W ten sposób powstaje sposób pracy, który jest zaskakująco podobny do tego stosowanego przez klasyczne zespoły programistów. Kluczowa różnica polega na tym, że osoby pełniące te role są elastyczne i mogą bardzo szybko przechodzić między różnymi zadaniami.
Mimo to to człowiek zachowuje kontrolę. To on decyduje, które propozycje zostaną przyjęte, a które nie.
Znaczenie ciągłej dokumentacji
W trakcie realizacji większych projektów coraz wyraźniej widać, dlaczego dokumentacja odgrywa tak kluczową rolę. Na początku projekt wydaje się jeszcze łatwy do ogarnięcia. Jednak po kilku miesiącach często mamy do czynienia z setkami decyzji, licznymi modułami i mnóstwem szczegółów technicznych.
Bez dokumentacji znaczna część tej wiedzy zostałaby utracona. Dlatego dokumentacja nie jest traktowana jako uciążliwy obowiązek, lecz jako aktywny element procesu rozwoju. Dzięki temu nowi pracownicy mogą szybko się wdrożyć. Wcześniejsze decyzje pozostają zrozumiałe. Cały projekt staje się łatwiejszy w utrzymaniu w dłuższej perspektywie.
Właśnie w przypadku projektowania opartego na sztucznej inteligencji kwestia ta należy do najważniejszych czynników decydujących o sukcesie.
Nieuniknione zmiany
Żaden większy projekt programistyczny nie pozostaje niezmieniony. Pojawiają się nowe wymagania. Zmieniają się oczekiwania klientów. Technologie nieustannie się rozwijają. Niektóre pomysły okazują się znakomite, inne – mniej praktyczne.
Dlatego każda architektura powinna charakteryzować się wystarczającą elastycznością, aby móc dostosowywać się do zmian. Tutaj ponownie widać, jak ważne są przejrzysta dokumentacja i jasna struktura. Im solidniejsze są podstawy, tym łatwiej wprowadzać późniejsze modyfikacje.
Sztuczna inteligencja może pomóc w analizie skutków zmian i opracowaniu alternatywnych rozwiązań. Decyzja strategiczna pozostaje jednak w gestii programisty.
Co łączy udane projekty
Analizując różne projekty związane ze sztuczną inteligencją, można dostrzec powtarzające się podobne wzorce. Projekty zakończone sukcesem zaczynają się od jasnej wizji. Mają przejrzystą strukturę. Dokumentują ważne decyzje. Dzielą duże zadania na mniejsze części.
Nie traktują oni sztucznej inteligencji jako magicznego rozwiązania, lecz jako wydajnego partnera w ramach szerszego procesu rozwoju. Prawdziwą siłą współczesnej sztucznej inteligencji nie jest tworzenie oprogramowania za naciśnięciem przycisku. Jej siła polega na wspieraniu programistów w analizie, planowaniu, wdrażaniu i dokumentacji. Właśnie dzięki temu powstają nowe możliwości.
Droga jest ważniejsza niż pierwsze polecenie
Osoby, które po raz pierwszy zajmują się programowaniem z wykorzystaniem sztucznej inteligencji, często poszukują idealnego polecenia. Po zrealizowaniu kilku większych projektów to podejście zazwyczaj ulega zmianie. Sukces projektu rzadko zależy od pojedynczego polecenia. Decydujące znaczenie ma raczej cały proces.
- Pomysł na projekt.
- Analiza.
- Architektura.
- Dokumentacja.
- Współpraca między różnymi rolami.
- Ciągłe doskonalenie.
Sztuczna inteligencja może wspierać wszystkie te obszary. Nie zastępuje ona jednak konieczności strukturalnego myślenia i systematycznej pracy. Dlatego też skuteczne tworzenie oprogramowania z wykorzystaniem sztucznej inteligencji przypomina w gruncie rzeczy skuteczne tworzenie oprogramowania w ogóle.
Różnica polega jedynie na tym, że obecnie mamy do dyspozycji znacznie wydajniejsze narzędzia. I właśnie dlatego o sukcesie projektu nie zadecyduje najlepszy prompt, lecz jakość całego procesu tworzenia.

Przyszłość tworzenia oprogramowania
Śledząc obecną dyskusję na temat sztucznej inteligencji, można łatwo odnieść wrażenie, że wszystko jest już przesądzone. Jedni są przekonani, że programiści wkrótce staną się zbędni. Inni uważają sztuczną inteligencję za chwilową modę, która za kilka lat przeminie.
Z mojego dotychczasowego doświadczenia wynika, że oba te poglądy są zbyt uproszczone. Prawdziwy rozwój dopiero się zaczyna.
W trakcie pisania tego artykułu sam pracuję nad dużym projektem programistycznym, który od samego początku jest tworzony przy wsparciu sztucznej inteligencji. Nie chodzi tu o to, by po prostu pozwolić sztucznej inteligencji pisać kod. Znacznie ciekawsze jest pytanie, jak zmieniają się procesy programistyczne, gdy nagle staje się dostępny na stałe inteligentny asystent.
Już po kilku tygodniach widać wyraźne różnice w porównaniu z tradycyjnym sposobem pracy. Pomysły można szybciej weryfikować. Koncepcje powstają w krótszym czasie. Dokumentacja rozrasta się niemal automatycznie wraz z projektem. Jednocześnie jednak widać, że dobre wyniki nadal zależą od jasnych struktur, starannego planowania i zrozumiałej komunikacji.
Narzędzia się zmieniają. Podstawowe zasady dobrego tworzenia oprogramowania pozostają zadziwiająco niezmienne.
Od programowania do myślenia systemowego
Przez wiele dziesięcioleci w centrum uwagi znajdowało się samo programowanie. Kto chciał tworzyć oprogramowanie, musiał opanować języki programowania, zapoznać się z bibliotekami i samodzielnie pisać ogromne ilości kodu.
Sytuacja ta ulega coraz większym zmianom. Kod staje się w coraz większym stopniu zasobem, który można zautomatyzować. Prawdziwe wyzwanie przenosi się w kierunku analizy, architektury i zrozumienia systemu.
Programista przyszłości będzie prawdopodobnie poświęcał mniej czasu na pisanie poszczególnych funkcji, a znacznie więcej na opisywanie systemów, analizowanie wymagań i koordynowanie powiązań.
Umiejętność zrozumiałego przedstawiania złożonych zagadnień staje się przez to ważniejsza niż kiedykolwiek wcześniej. W pewnym sensie obserwujemy powrót do podstaw tworzenia oprogramowania. Na pierwszym planie nie znajduje się już składnia języka programowania, lecz zrozumienie problemu.
Dokumentacja staje się kluczowym elementem
Już dziś wyraźnie widać pewną tendencję. Podczas gdy wcześniej dokumentacja była często postrzegana jako zło konieczne, obecnie staje się ona coraz częściej centralnym elementem wielu projektów.
Systemy oparte na sztucznej inteligencji mogą działać wyłącznie w oparciu o wiedzę, którą mają do dyspozycji. Im lepiej udokumentowany jest projekt, tym bardziej produktywna może być współpraca. Powoduje to interesującą zmianę.
Dokumentacja nie służy już wyłącznie ludziom. Staje się ona jednocześnie bazą wiedzy dla asystentów cyfrowych. Można powiedzieć, że współczesne projekty coraz częściej składają się z dwóch poziomów. Z jednej strony mamy samo oprogramowanie. Z drugiej strony mamy bazę wiedzy, która opisuje, dlaczego to oprogramowanie w ogóle istnieje i jak działa.
W przyszłości obie te dziedziny będą prawdopodobnie coraz bardziej się ze sobą zazębiać.
Wirtualne zespoły zamiast pojedynczych narzędzi
Również współpraca z sztuczną inteligencją będzie się dalej rozwijać. Obecnie wielu programistów nadal korzysta z pojedynczych czatów lub pojedynczych modeli. W przyszłości prawdopodobnie coraz częściej będziemy pracować z całymi grupami wyspecjalizowanych systemów sztucznej inteligencji.
- Architekturę projektuje system.
- Inny zajmuje się opracowywaniem funkcji.
- Kolejny tworzy testy.
- Kolejny zajmuje się dokumentacją.
Człowiek pełni w tym przypadku rolę kierownika projektu i wyznacza kierunek działań. Model ten już dziś jest zaskakująco podobny do klasycznych zespołów programistów. Różnica polega jedynie na tym, że członkowie zespołu są wirtualni i potrafią w ciągu kilku sekund przechodzić od jednego zadania do drugiego.
Znaczenie ludzkiego doświadczenia
Pomimo wszystkich postępów technicznych jedno pozostaje niezmienne. Doświadczenie nie traci na znaczeniu. Wręcz przeciwnie. Im wydajniejsze stają się narzędzia, tym cenniejsza staje się umiejętność podejmowania trafnych decyzji.
- Sztuczna inteligencja może przedstawiać propozycje.
- Potrafi analizować.
- Może wskazać alternatywne rozwiązania.
- Potrafi nawet wykrywać błędy.
Ostateczna odpowiedzialność za decyzje spoczywa jednak na człowieku. Kto rozumie procesy, dostrzega zależności i potrafi myśleć długofalowo, ten będzie miał ogromną przewagę również w przyszłości.
Prawdziwa siła nie wynika wyłącznie z samej sztucznej inteligencji. Wynika ona z połączenia ludzkiego doświadczenia ze sztuczną inteligencją.
Od czatu opartego na sztucznej inteligencji do pamięci projektowej
 Każdy, kto zajmuje się tworzeniem większych projektów oprogramowania z wykorzystaniem sztucznej inteligencji, szybko zauważa, że to nie kod staje się wąskim gardłem, ale wiedza na temat projektu. Wymagania, decyzje dotyczące architektury, modele danych i dyskusje często gromadzą się przez tygodnie lub miesiące. Właśnie w tym miejscu pojawia się interesujący związek z tematem eksportu danych. Wiele z tych informacji jest bowiem już dostępnych w dotychczasowych rozmowach dotyczących sztucznej inteligencji. Kto Historia czatu została wyeksportowana i systematycznie zarchiwizowana, tworzy podstawę dla długoterminowej pamięci projektowej. Zamiast ciągle na nowo wyjaśniać ważne decyzje, wcześniejsze analizy, koncepcje i sposoby rozwiązania mogą pozostawać stale dostępne. W ten sposób z poszczególnych czatów stopniowo powstaje baza wiedzy, którą można później wykorzystać do dokumentacji, rozwoju, a nawet do tworzenia własnych systemów AI. Tworzenie oprogramowania z wykorzystaniem AI oznacza zatem nie tylko szybsze programowanie, ale także świadome budowanie cyfrowego archiwum wiedzy.
Każdy, kto zajmuje się tworzeniem większych projektów oprogramowania z wykorzystaniem sztucznej inteligencji, szybko zauważa, że to nie kod staje się wąskim gardłem, ale wiedza na temat projektu. Wymagania, decyzje dotyczące architektury, modele danych i dyskusje często gromadzą się przez tygodnie lub miesiące. Właśnie w tym miejscu pojawia się interesujący związek z tematem eksportu danych. Wiele z tych informacji jest bowiem już dostępnych w dotychczasowych rozmowach dotyczących sztucznej inteligencji. Kto Historia czatu została wyeksportowana i systematycznie zarchiwizowana, tworzy podstawę dla długoterminowej pamięci projektowej. Zamiast ciągle na nowo wyjaśniać ważne decyzje, wcześniejsze analizy, koncepcje i sposoby rozwiązania mogą pozostawać stale dostępne. W ten sposób z poszczególnych czatów stopniowo powstaje baza wiedzy, którą można później wykorzystać do dokumentacji, rozwoju, a nawet do tworzenia własnych systemów AI. Tworzenie oprogramowania z wykorzystaniem AI oznacza zatem nie tylko szybsze programowanie, ale także świadome budowanie cyfrowego archiwum wiedzy.
Moje osobiste podsumowanie
Kiedy przyglądam się moim dotychczasowym doświadczeniom związanym z programowaniem opartym na sztucznej inteligencji, jedna rzecz rzuca się w oczy:
Technologia nie sprawiła, że zacząłem mniej myśleć. Sprawiła, że zacząłem myśleć inaczej. Wiele zadań, które kiedyś zajmowały mi znaczną część czasu pracy, dziś można wykonać znacznie szybciej. Jednocześnie wzrosło znaczenie struktury, planowania i dokumentacji.
Właśnie w moim obecnym projekcie nieustannie widać, jak cenne są przejrzysty kontekst, scentralizowana baza wiedzy i jasno zdefiniowane procesy. To nie pojedyncze polecenie decyduje o sukcesie. Nie pojedyncza linijka kodu. Nawet nie sam system sztucznej inteligencji.
Kluczowym czynnikiem jest umiejętność uporządkowania wiedzy i nadania projektowi jasnego kierunku.
Być może za kilka lat będziemy patrzeć na dzisiejsze czasy tak samo, jak na pojawienie się internetu czy pierwszych komputerów osobistych. Wiele możliwości jest już widocznych, ale trudno jeszcze w pełni oszacować długoterminowe skutki.
Jedno wydaje się jednak już dziś prawdopodobne. Tworzenie oprogramowania ulegnie zmianie. Nie dlatego, że maszyny nagle zaczną wszystko robić samodzielnie, ale dlatego, że ludzie otrzymali nowe narzędzia, które poszerzają ich możliwości. Kto mądrze wykorzystuje te narzędzia, może pracować wydajniej, szybciej się uczyć i realizować większe projekty niż kiedykolwiek wcześniej.
Przyszłość nie należy więc prawdopodobnie ani wyłącznie do ludzi, ani wyłącznie do sztucznej inteligencji. Należy ona do współpracy obu stron. I właśnie ta współpraca nie zaczyna się od kodu.
Zaczyna się od pomysłu, jasnej struktury i chęci do próbowania nowych rzeczy.
Bądź na bieżąco - bez reklam
Jeśli chcesz być informowany o nowych artykułach, aktualizacjach lub nowych plikach do pobrania, możesz zasubskrybować mój comiesięczny biuletyn. Biuletyn jest celowo odchudzony, całkowicie wolny od reklam i pojawia się tylko raz w miesiącu. Znajdziesz w nim wybór najważniejszych nowych artykułów, praktyczne treści na temat sztucznej inteligencji, oprogramowania i kwestii społecznych, a także informacje o zaktualizowanych skryptach lub nowych plikach do pobrania. Żadnego spamu, żadnych codziennych e-maili - tylko najistotniejsze treści w kompaktowej formie. Jeśli chcesz na bieżąco śledzić rozwój wydarzeń, newsletter jest najprostszym sposobem, aby być na bieżąco.



Często zadawane pytania
- Czy sztuczna inteligencja jest już dziś w stanie samodzielnie opracowywać kompletne projekty oprogramowania?
Nowoczesne systemy sztucznej inteligencji mogą przejąć imponującą część zadań w ramach projektu oprogramowania. Potrafią projektować modele danych, generować kod źródłowy, tworzyć interfejsy, sporządzać dokumentację, a nawet opracowywać testy. Mimo to skuteczne tworzenie oprogramowania nie polega wyłącznie na pisaniu kodu. Należy zrozumieć wymagania, przeanalizować procesy biznesowe, podjąć decyzje i zweryfikować wyniki. Zadania te nadal pozostają w gestii człowieka. Sztuczna inteligencja może znacznie zwiększyć produktywność, ale nie zastępuje konieczności posiadania wiedzy specjalistycznej, doświadczenia i zarządzania projektem. - Która sztuczna inteligencja najlepiej nadaje się do tworzenia oprogramowania?
Nie ma jednej uniwersalnej odpowiedzi. Różne systemy mają różne mocne strony. Niektóre modele sprawdzają się szczególnie dobrze w kwestiach związanych z architekturą, inne w generowaniu kodu lub tworzeniu dokumentacji. Często decydujące znaczenie ma nie tyle wybór narzędzia, co jakość dostarczonych informacji. Nawet najpotężniejsza sztuczna inteligencja może pracować tylko z wiedzą, która jest jej udostępniona. Dobre procesy, przejrzysta dokumentacja i jasny kontekst są zazwyczaj ważniejsze niż konkretna nazwa modelu. - Czy muszę umieć programować, żeby tworzyć oprogramowanie z wykorzystaniem sztucznej inteligencji?
Podstawowa wiedza techniczna pozostaje niezwykle cenna. Chociaż systemy sztucznej inteligencji mogą przejąć wiele zadań programistycznych, nadal konieczne jest ocenianie wyników, wykrywanie błędów i podejmowanie decyzji. Osoby rozumiejące bazy danych, architekturę oprogramowania i procesy biznesowe zazwyczaj osiągają znacznie lepsze wyniki. Chociaż bariera wejścia na rynek znacznie się obniża, wiedza specjalistyczna pozostaje ważną przewagą konkurencyjną. - Dlaczego kontekst odgrywa tak ważną rolę w rozwoju sztucznej inteligencji?
Sztuczna inteligencja początkowo nie zna Twojego projektu. Nie zna ani Twoich celów, ani procesów, ani struktur danych. Bez wystarczającego kontekstu musi opierać się na domysłach. Im więcej dostępnych jest istotnych informacji, tym lepiej może opracować odpowiednie rozwiązania. W wielu projektach jakość wyników zależy w większym stopniu od dostarczonego kontekstu niż od samego zadania. - Jak obszerna powinna być dokumentacja projektu?
Dobra dokumentacja powinna być na tyle kompletna, by umożliwić zrozumienie powiązań, ale nie powinna być niepotrzebnie skomplikowana. Ważne są cele projektu, modele danych, decyzje dotyczące architektury, konwencje nazewnictwa, zadania do wykonania oraz warunki techniczne. Celem nie jest maksymalna ilość tekstu, ale maksymalna zrozumiałość. Przejrzysta dokumentacja jest często cenniejsza niż setki stron nieuporządkowanych informacji. - Dlaczego warto rozdzielić większe projekty na kilka czatów z wykorzystaniem sztucznej inteligencji?
Wraz ze wzrostem skali projektu rośnie jego złożoność i ilość informacji. Gdy wszystkie tematy są omawiane na jednym czacie, ważne informacje często giną w gąszczu innych wiadomości. Podział na czaty poświęcone architekturze, programowaniu, dokumentacji i testowaniu pozwala na jaśniejsze określenie zakresu odpowiedzialności i zapewnia większą przejrzystość. Jednocześnie umożliwia to celowe wykorzystanie różnych punktów widzenia. - Czym jest monit startowy i dlaczego jest ważny?
Komenda startowa służy jako standardowe wprowadzenie do nowych czatów. Opisuje ona projekt, odsyła do dokumentacji, określa zasady i wyjaśnia pożądaną rolę sztucznej inteligencji. Dzięki temu nowe czaty od razu otrzymują niezbędny kontekst. Pozwala to zaoszczędzić czas, ogranicza nieporozumienia i zapewnia spójne wyniki w całym projekcie. - Czy każda decyzja powinna być dokumentowana?
Nie każdą drobnostkę trzeba dokumentować. Najważniejsze są przede wszystkim decyzje, które mogą mieć później wpływ na architekturę, model danych lub procesy. Szczególnie cenna jest dokumentacja uzasadnień danej decyzji. Często problemem nie jest sama decyzja, ale późniejsze zapomnienie o pierwotnych rozważaniach. - Jak zapobiegać sytuacji, w której sztuczna inteligencja opracowuje błędne rozwiązania?
Nie ma czegoś takiego jak stuprocentowe bezpieczeństwo. Najlepsza strategia składa się z kilku elementów: zapewnienia wystarczającego kontekstu, podzielenia zadań na mniejsze etapy, sprawdzania wyników, przeprowadzania testów oraz dokumentowania ważnych decyzji. Sztuczną inteligencję należy traktować jako wsparcie, a nie jako nieomylny autorytet. - Jak ważne są prawdziwe dane przykładowe?
Dane przykładowe należą do najskuteczniejszych narzędzi. Pomagają one sztucznej inteligencji lepiej zrozumieć struktury, zależności i typowe przypadki użycia. Często kilka realistycznych zestawów danych pozwala lepiej zrozumieć zagadnienie niż wiele stron teoretycznych opisów. Oczywiście należy przy tym uwzględnić kwestie ochrony danych i poufności. - Czy sztuczna inteligencja może być pomocna również w przypadku istniejących projektów programistycznych?
Tak. Właśnie istniejące systemy często czerpią korzyści ze wsparcia sztucznej inteligencji. Można uzupełniać dokumentację, analizować stary kod, zrozumieć struktury danych i planować nowe funkcje. Warunkiem jest jednak dostępność wystarczających informacji na temat istniejącego systemu. Im lepsza dokumentacja wyjściowa, tym skuteczniejsza będzie współpraca. - Jaką rolę będzie odgrywał programista w przyszłości?
Rola programisty coraz bardziej przesuwa się od samego programowania w kierunku analizy, architektury, komunikacji i kontroli jakości. Programiści coraz częściej pełnią funkcje kierowników projektów i architektów systemów. Coraz większego znaczenia nabiera umiejętność zrozumiałego opisywania złożonych zależności. Programowanie pozostaje istotne, ale nie jest już koniecznie głównym elementem. - Jak radzić sobie ze sprzecznymi odpowiedziami generowanymi przez sztuczną inteligencję?
Rozbieżności są czymś normalnym. Różne dyskusje lub modele mogą sugerować różne rozwiązania. Właśnie dlatego ważne decyzje należy zawsze podejmować w oparciu o jasne kryteria. Zasady architektury, dokumentacja i testy pomagają w obiektywnej ocenie jakości poszczególnych propozycji. - Czy należy udostępnić sztucznej inteligencji dostęp do całej dokumentacji projektu?
Zasadniczo tak, o ile pozwalają na to przepisy dotyczące ochrony danych, poufności oraz wytyczne firmy. Im lepiej sztuczna inteligencja rozumie projekt, tym zazwyczaj lepsze są wyniki. Szczególnie w przypadku długoterminowych projektów warto konsekwentnie wykorzystywać centralne źródła wiedzy i dbać o ich aktualność. - W jaki sposób sztuczna inteligencja wpływa na czas realizacji projektów oprogramowania?
Wiele zadań można wykonać znacznie szybciej niż kiedyś. Koncepcje, dokumentacja, modele danych i pierwsze prototypy powstają często w ułamku dotychczasowego czasu. Jednocześnie nadal istnieje potrzeba planowania, testowania i zapewnienia jakości. Dobrze realizowane projekty nie stają się więc automatycznie bardziej chaotyczne, ale często bardziej uporządkowane i wydajniejsze. - Czy małe przedsiębiorstwa mogą czerpać korzyści z tworzenia oprogramowania opartego na sztucznej inteligencji?
Szczególnie małe przedsiębiorstwa często odnoszą z tego największe korzyści. Tam, gdzie wcześniej potrzebne były całe zespoły, dziś pojedynczy programiści lub niewielkie grupy mogą realizować projekty, które wcześniej byłyby praktycznie niewykonalne z ekonomicznego punktu widzenia. Sztuczna inteligencja obniża bariery wejścia na rynek i zwiększa wydajność, nie wymagając przy tym wysokich nakładów na duże zespoły programistów. - Jakie błędy popełniają najczęściej początkujący?
Najczęstsze błędy to zbyt mały kontekst, brak dokumentacji, zbyt szerokie zakresy zadań oraz ślepe zaufanie do wyników sztucznej inteligencji. Wielu użytkowników skupia się początkowo na pojedynczych poleceniach i nie docenia znaczenia struktury, zarządzania wiedzą oraz długoterminowej organizacji projektu. - Czy sztuczna inteligencja całkowicie zastąpi tradycyjne tworzenie oprogramowania?
W obecnej sytuacji wydaje się to mało prawdopodobne. Bardziej prawdopodobna jest głęboka zmiana sposobu pracy. Wiele czynności technicznych zostanie zautomatyzowanych lub znacznie przyspieszonych. Jednocześnie na znaczeniu zyskają analiza, komunikacja, architektura i myślenie strategiczne. Przyszłość tworzenia oprogramowania prawdopodobnie będzie polegała nie tyle na zastąpieniu człowieka, co na coraz ściślejszej współpracy między ludzkim doświadczeniem a sztuczną inteligencją.



