
Atualmente, quem trabalha com inteligência artificial pensa frequentemente no ChatGPT ou em serviços online semelhantes. Escreve-se uma pergunta, espera-se alguns segundos - e recebe-se uma resposta como se estivesse do outro lado da linha um interlocutor paciente e muito culto. Mas o que é facilmente esquecido: Cada entrada, cada frase, cada palavra viaja através da Internet para servidores externos. É aí que o trabalho real é feito - em computadores enormes que nunca chegamos a ver.
Em princípio, um modelo de língua local funciona exatamente da mesma forma - mas sem a Internet. O modelo é armazenado como um ficheiro no próprio computador do utilizador, é carregado na memória de trabalho no arranque e responde a perguntas diretamente no dispositivo. A tecnologia subjacente é a mesma: uma rede neuronal que compreende a linguagem, gera textos e reconhece padrões. A única diferença é que todo o cálculo é efectuado internamente. Pode dizer-se: ChatGPT sem a nuvem.
O que é especial neste caso é o facto de a tecnologia se ter desenvolvido a tal ponto que já não depende de grandes centros de dados. Os computadores Apple modernos com processadores M (como o M3 ou M4) têm uma enorme capacidade de computação, ligações de memória rápidas e um motor neural especializado para aprendizagem automática. Como resultado, muitos modelos podem agora ser operados diretamente num Mac Mini ou Mac Studio - sem um parque de servidores, sem uma configuração complicada e sem qualquer ruído significativo.



Isto abre uma nova porta, não só para os programadores, mas também para empresários, autores, advogados, médicos, professores e comerciantes. Todos podem agora ter a sua própria pequena IA - na sua secretária, sob controlo total, pronta a ser utilizada em qualquer altura. Um modelo linguístico local pode:
- Textos resumir ou corrigir,
- Emails formular ou estruturar,
- Perguntas responder a perguntas e analisar conhecimentos,
- Processos apoio nos programas,
- Documentos pesquisar ou classificar,
- ou simplesmente como assistente pessoal sem nunca divulgar dados ao mundo exterior.
Esta abordagem está a tornar-se cada vez mais importante, especialmente numa altura em que a proteção de dados e a soberania digital estão novamente no centro das atenções. Não é necessário ser um programador para o utilizar - basta um Mac moderno. Os modelos podem ser simplesmente iniciados através de uma aplicação ou de uma janela de terminal e respondem quase tão naturalmente como uma janela de chat no browser.
Este artigo mostra quais os modelos que podem ser executados em que Mac atualmente, o que o hardware precisa de fazer e porque é que os computadores Apple Silicon são particularmente adequados para isso. Resumindo, trata-se de saber como colocar o poder da IA de volta nas suas próprias mãos - de forma silenciosa, eficiente e local.
Modelos de linguagem local no Mac - Porque é que isto faz sentido agora
Executar um modelo linguístico "localmente" significa que este é operado inteiramente no seu próprio computador - sem ligação a um serviço de nuvem. O cálculo, a análise das entradas, a geração de textos ou respostas - tudo acontece diretamente no seu próprio dispositivo. O modelo é, portanto, armazenado como um ficheiro no SSD, é carregado na RAM no arranque e funciona aí com todo o desempenho do sistema.
A principal diferença em relação à variante de nuvem é a independência. Não há fluxos de dados na Internet, não são utilizados servidores externos e ninguém pode localizar o que está a ser processado internamente. Isto proporciona um grau considerável de proteção e controlo dos dados - especialmente numa época em que os movimentos de dados se tornam cada vez mais difíceis de rastrear.
No passado, era impensável executar tais modelos localmente. Era necessário um computador mainframe ou um parque de GPUs para manter uma rede neural desta dimensão a funcionar. Atualmente, com o poder de computação dos modernos chips Apple-Silicon, isto pode ser realizado num dispositivo de secretária - de forma eficiente, silenciosa e com baixo consumo de energia.
Porque é que o Apple Silicon é ideal
Com a mudança do Apple para o Silicon, o Apple baralhou as cartas. Em vez da arquitetura clássica da Intel com CPU e GPU separados, o Apple baseia-se no chamado design de memória unificada: processador, gráficos e motor neural acedem à mesma memória principal rápida. Isto elimina a necessidade de cópias de dados entre componentes individuais - uma vantagem decisiva para cálculos de IA.
O motor neural propriamente dito é um núcleo de computação especializado para a aprendizagem automática, integrado diretamente nos chips. Permite biliões de operações de computação por segundo - com um consumo de energia muito baixo. Juntamente com a biblioteca MLX (Machine Learning for Apple Silicon) e estruturas modernas como o OLaMA, os modelos podem agora ser executados diretamente no macOS sem controladores GPU complexos ou dependências CUDA.
Um chip M4 no Mac Mini já é suficiente para executar modelos de linguagem compactos (por exemplo, 3-7 mil milhões de parâmetros) sem problemas. Num Mac Studio com M4 Max ou M3 Ultra, pode até executar modelos com 30 mil milhões de parâmetros - completamente localmente.
Comparação: Apple Silicon vs. hardware NVIDIA
Tradicionalmente, as placas gráficas RTX da NVIDIA têm sido o padrão de ouro para cálculos de IA. Uma RTX 5090 atual, por exemplo, oferece um enorme desempenho bruto e continua a ser a primeira escolha para muitos sistemas de treino. No entanto, vale a pena fazer uma comparação detalhada - porque as prioridades são diferentes.
| Aspeto | Apple Silicon (M4 / M4 Max / M3 Ultra) | GPU NVIDIA (5090 & Co.) |
|---|---|---|
| Consumo de energia | Muito eficiente - normalmente menos de 100 W de consumo total | Até 450 W só para a GPU |
| Desenvolvimento do ruído | Praticamente silencioso | Claramente audível sob carga |
| Pilha de software | MLX / Núcleo ML / Metal | CUDA / cuDNN / PyTorch |
| Manutenção | Sem condutor e estável | Actualizações frequentes e problemas de compatibilidade |
| Relação preço/desempenho | Alta eficiência a um preço moderado | Melhor desempenho de pico, mas mais caro |
| Ideal para | Inferência local e funcionamento contínuo | Formação e grandes modelos |
Resumindo: a NVIDIA é a escolha para centros de dados e formação extrema. O Apple Silicon, por outro lado, é ideal para utilização local e a longo prazo - sem ruído, sem acumulação de calor, com uma base de software estável e um consumo de energia controlável.
Apple Silicon comparado com NVIDIA para inferência
O M3 Ultra representa um avanço significativo para o Apple Silicon: para além de um design de chip altamente integrado com CPU, GPU e motor neural num único pacote, baseia-se numa arquitetura de memória unificada em que a RAM é utilizada por todas as unidades de computação em simultâneo - sem a clássica separação da RAM e da VRAM da GPU. De acordo com os testes de referência, esta abordagem já atinge um desempenho comparável ou mesmo melhor em tarefas de inferência local do que as placas gráficas topo de gama da NVIDIA em alguns casos. Um exemplo: No teste, o M3 Ultra alcançou aproximadamente 2.320 tokens/s com um modelo Qwen3-30B de 4 bits, em comparação com o RTX 3090 com 2.157 tokens/s.
Além disso, uma comparação entre Apple Silicon e NVIDIA sob cargas de IA sugere que um sistema M3/M4 Max atingirá cerca de 40-80W sob carga, enquanto uma RTX 4090 consumirá normalmente até 450W.
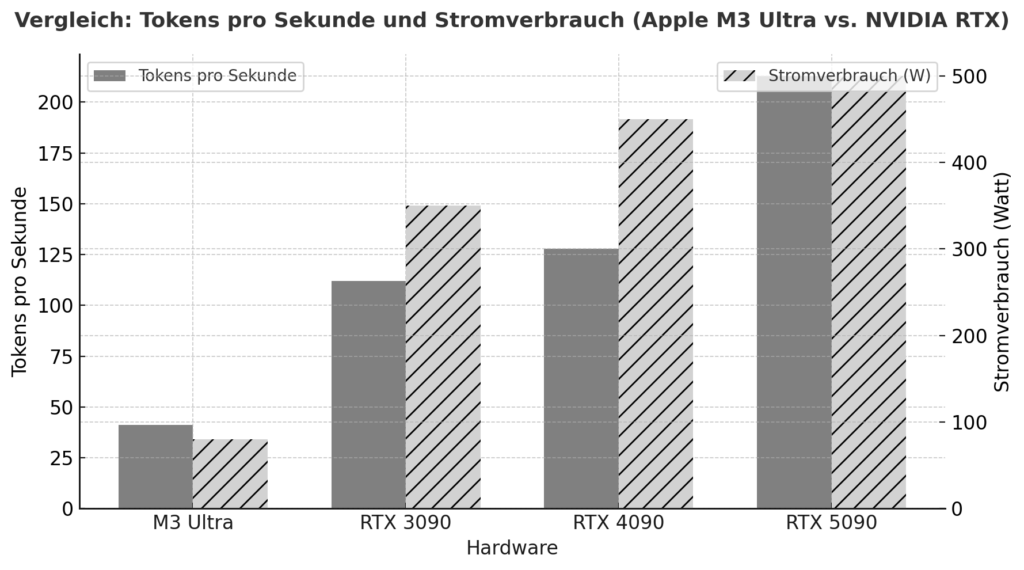
Isto mostra que, se olharmos não só para o desempenho máximo, mas também para a eficiência por watt, o Apple Silicon está numa posição excelente. Por outro lado, existem as placas NVIDIA (por exemplo, 3090, 4090, 5090) com a sua enorme arquitetura de GPU paralelizada, uma densidade muito elevada de núcleos CUDA/tensor e bibliotecas especializadas (CUDA, cuDNN, TensorRT). É aqui que o desempenho bruto dos top-flops está muitas vezes à frente - mas com limitações decisivas para os modelos de linguagem local: a VRAM disponível (por exemplo, 24-32 GB para placas de jogos) torna-se rapidamente um estrangulamento se forem carregados modelos com 20-30 mil milhões de parâmetros ou mais. Um relatório de utilizador, por exemplo, afirma que com uma RTX 5090 com aproximadamente 32 GB de VRAM, um modelo com 20-22 mil milhões de parâmetros já é difícil de acomodar.
A este respeito, não se deve olhar apenas para os núcleos GPU, mas também para o tamanho da memória disponível, a largura de banda e a arquitetura da memória. O M3 Ultra com até 512 GB de memória unificada (nas configurações de topo), por exemplo, oferece vantagens em muitos cenários de implementação local - especialmente se os modelos não forem executados na nuvem, mas permanentemente localmente.
| Hardware | Modelo / Configuração | Tokens por segundo (aproximado) | Observação |
|---|---|---|---|
| Apple M3 Ultra (Mac Studio) | z. por exemplo, Gemma-3-27B-Q4 em M3 Ultra | ≈ 41 tok/s :contentReference[oaicite:2]{index=2} | Inferência LLM, contexto 4k tokens, quantificado |
| NVIDIA RTX 5090 | 8 Modelo B (quantificado) de acordo com o estudo | ≈ 213 tok/s :contentReference[oaicite:3]{index=3} | Modelo 8 B, 4 bits, ambiente RLHF |
| NVIDIA RTX 4090 | 8 B Referência do modelo | ≈ 128 tok/s :contentReference[oaicite:4]{index=4} | 24 GB VRAM Ambiente |
| NVIDIA RTX 3090 | Orçamento HighEnd em comparação | ≈ 112 tok/s :contentReference[oaicite:5]{index=5} | Mercado em segunda mão, 24 GB VRAM |
Relevância prática: Onde os modelos linguísticos locais fazem sentido
Atualmente, as aplicações possíveis da IA local são quase ilimitadas. Sempre que os dados têm de permanecer confidenciais ou os processos têm de ser executados em tempo real, a versão local vale a pena. Exemplos da prática:
- Sistemas ERPAnálise automática de texto, sugestões, previsões ou ajudas à comunicação - diretamente a partir do software.
- Produção de livros e de suportesVerificação de estilo, tradução, resumo, expansão de texto - tudo localmente, sem dependência da nuvem.
- Advogados e notáriosAnálise de documentos, projectos de peças processuais, pesquisas - sob a mais estrita confidencialidade.
- Médicos e terapeutasAvaliação de casos, documentação ou relatórios automatizados - sem que os dados do doente saiam do sistema.
- Gabinetes de engenharia e arquitectosAssistentes de texto, projeto e cálculo que também funcionam sem Internet.
- Empresa em geralGestão de conhecimentos, assistentes de conversação interna, análise de protocolos, classificação de correio eletrónico - tudo dentro da sua própria rede.
Este é um grande passo, especialmente no sector comercial: em vez de pagar por serviços externos de IA e enviar dados para a nuvem, pode agora executar modelos personalizados nas suas próprias máquinas. Estes podem ser personalizados, ajustados e expandidos com os conhecimentos da própria empresa - totalmente sob controlo.
O resultado é um cenário informático moderno, mas tradicionalmente soberano, que utiliza a tecnologia sem renunciar à soberania sobre os seus próprios dados. Uma abordagem que nos recorda as velhas virtudes: manter as coisas nas nossas próprias mãos.
Inquérito atual sobre sistemas locais de IA
Descrição geral: Mac Mini e Mac Studio - o que está atualmente disponível
Se quisermos executar modelos linguísticos locais num Mac, há duas classes de computadores de secretária que são particularmente importantes: o Mac mini e o Mac Studio.
- Mac MiniA última geração oferece o chip Apple M4 ou, opcionalmente, o M4 Pro. De acordo com as especificações técnicas, estão disponíveis variantes com 24 GB ou 32 GB de memória unificada; a variante Pro é oferecida com memória unificada configurável de até 48 GB ou 64 GB. Isto torna o Mac Mini adequado para muitas aplicações - especialmente se o modelo não for extremamente grande ou não tiver de executar várias tarefas muito grandes em paralelo.
- Estúdio MacAqui vamos um passo mais além. Equipado, por exemplo, com o chip Apple M4 Max ou o chip M3 Ultra - consoante o modelo. Com a versão M4 Max, são possíveis 48 GB, 64 GB ou até 128 GB de memória unificada. A versão M3 Ultra do Mac Studio pode ser equipada com até 512 GB de memória unificada. O tamanho dos SSDs e a largura de banda da memória também aumentam consideravelmente. Isto torna o Mac Studio adequado para modelos mais exigentes ou processos paralelos.
Como nota breve: O Mac Pro também existe e muitas vezes oferece „mais chassis“ ou ranhuras PCI-e no exterior - mas em termos de modelos linguísticos, não oferece grande vantagem sobre o Mac Studio para a versão local se não tiver quaisquer placas de expansão adicionais ou requisitos PCIe especiais.
Também Cadernos de notas (por exemplo, MacBook Pro) podem certamente ser utilizados - mas com restrições: Os sistemas de arrefecimento são mais pequenos, o desempenho térmico é mais limitado e o orçamento de RAM é frequentemente inferior. A utilização prolongada (como nos modelos com IA) pode reduzir o desempenho.

IA: Apple é melhor do que a Nvidia! 😮 | c't 3003
Porque é que a RAM / memória unificada é tão importante
Quando um modelo de linguagem é executado localmente, não é apenas o desempenho da CPU ou da GPU que é necessário - a RAM (ou no caso do Apple: "memória unificada") é crucial. Porquê?
O modelo propriamente dito (pesos, activações, resultados intermédios) deve ser armazenado na memória. Quanto maior for o modelo, mais memória é necessária. Os chips Apple-Silicon utilizam "memória unificada", ou seja, a CPU, a GPU e o motor neural acedem ao mesmo conjunto de memória. Isto elimina a necessidade de cópias de dados entre componentes, o que aumenta a eficiência e a velocidade.
Se não houver memória RAM suficiente, o sistema tem de ser trocado ou os modelos não são totalmente carregados - o que pode significar uma queda no desempenho, instabilidade ou cancelamento. Especialmente no caso de aplicações inferenciais (geração de respostas, introdução de texto, extensão de modelos), o tempo de resposta e o rendimento são cruciais - uma memória suficiente ajuda consideravelmente neste domínio. Um PC de secretária tradicional costumava pensar em termos de "RAM da CPU" e "RAM da GPU separada" - com o Apple Silicon, tudo é elegantemente combinado, o que torna a execução de modelos de linguagem particularmente atractiva.
Valores estimados: Que ordem de grandeza é realista?
Para o ajudar a estimar o hardware de que vai precisar, eis alguns valores de referência aproximados:
- Para modelos mais pequenos (por exemplo, alguns milhares de milhões de parâmetros), 16 GB a 32 GB de RAM podem ser suficientes - especialmente se apenas forem processadas consultas individuais. Um Mac Mini com 16/32 GB seria, portanto, um bom começo.
- Para modelos médios (por exemplo, 3-10 mil milhões de parâmetros) ou tarefas com várias conversas paralelas ou grandes quantidades de texto, deve considerar 32 GB de RAM ou mais - por exemplo, Mac Studio com 32 ou 48 GB.
- Para modelos grandes (>20 mil milhões de parâmetros) ou se vários modelos tiverem de ser executados em paralelo, pode escolher 64 GB ou mais - as variantes Mac mini e Mac Studio com 64 GB ou mais são possíveis aqui.
Importante: Não se esqueça de planear alguma memória intermédia - não só o modelo, mas também o funcionamento (por exemplo, o sistema operativo, E/S de ficheiros, outras aplicações) requerem reservas de memória.
| Categoria | Tamanho típico do modelo | Orçamento de RAM recomendado | Exemplo de utilização |
|---|---|---|---|
| Pequeno | 1-3 mil milhões de parâmetros | 16-32 GB | Assistente simples, reconhecimento de texto |
| Médio | 7-13 mil milhões Parâmetros | 32-64 GB | Chat, análise, criação de texto |
| Grande | 30-70 mil milhões de parâmetros | 64 GB + | Textos especializados, documentos jurídicos |
Questionar a mentalidade tradicional "servidor vs. desktop"
Tradicionalmente, pensava-se que a IA exigia parques de servidores, muitas GPUs, muita energia e um centro de dados. Mas o cenário está a mudar: os computadores de secretária, como o Mac Mini ou o Mac Studio, oferecem agora desempenho suficiente para muitos modelos de linguagem operados localmente - sem uma enorme infraestrutura. Em vez de custos elevados de eletricidade, arrefecimento potente e manutenção complexa, o utilizador ganha um dispositivo silencioso e eficaz na sua secretária.
É claro que, se quiser treinar modelos em grande escala ou utilizar um grande número de parâmetros, as soluções de servidor continuam a fazer sentido. No entanto, o hardware de secretária é muitas vezes suficiente para a inferência, a personalização e a utilização quotidiana. Este facto está associado a uma atitude tradicional: utilizar a tecnologia, mas sem a sobredimensionar - em vez disso, utilizá-la de forma direcionada e eficiente. Se construir uma base local sólida hoje, estará a criar os alicerces para o que será possível amanhã.

M3 Ultra vs RTX 5090 | A Batalha Final (Inglês)
Caracterização técnica dos modelos linguísticos
Atualmente, os modelos linguísticos diferem não só nas suas capacidades, mas também no formato técnico em que estão disponíveis. Estes formatos determinam a forma como o modelo é guardado, carregado e utilizado - e se pode ser executado num determinado sistema.
GGUF (Formato Unificado Gerado por GPT)
Este formato foi desenvolvido para utilização prática em ferramentas como o Ollama, o LM Studio ou o Llama.cpp. É compacto, portátil e altamente optimizado para a inferência local. Os modelos GGUF são geralmente quantificados, o que significa que consomem muito menos memória porque os valores numéricos internos são armazenados numa forma reduzida (por exemplo, 4 ou 8 bits). Como resultado, os modelos que originalmente tinham 30-50 GB de tamanho podem ser comprimidos para 5-10 GB - apenas com uma ligeira perda de qualidade.
- VantagemFunciona em quase todos os sistemas (macOS, Windows, Linux), sem necessidade de GPU especial.
- DesvantagemNão se destina a treino ou afinação - pura inferência (ou seja, utilização).
MLX (Aprendizagem automática para Apple Silicon)
MLX é a própria estrutura de código aberto do Apple para aprendizado de máquina no Apple Silicon. Foi especialmente desenvolvido para utilizar todo o poder da CPU, GPU e Neural Engine em M-Chips. Os modelos MLX estão normalmente disponíveis no formato MLX nativo ou são convertidos de outros formatos.
- VantagemMáximo desempenho e eficiência energética em hardware Apple.
- DesvantagemEcossistema ainda relativamente jovem, menos modelos comunitários disponíveis do que com o GGUF ou o PyTorch.
Safetensors (.safetensors)
Este formato tem origem no mundo PyTorch (e é fortemente promovido pelo Hugging Face). É um formato de armazenamento binário seguro para modelos grandes que não permite a execução de código - daí o nome "safe".
- VantagemCarregamento muito rápido, poupança de memória, normalização.
- Desvantagem: Destina-se principalmente a quadros como PyTorch ou TensorFlow - ou seja, mais comuns em ambientes de desenvolvimento e para processos de formação.
| Formato | Plataforma | Objetivo | Vantagens | Desvantagens |
|---|---|---|---|---|
| GGUF | macOS, Windows, Linux | Inferência | Compacto, rápido, universal | Não é possível efetuar formação |
| MLX | macOS (Apple Silicon) | Inferência + Formação | Optimizado para M-Chips, elevada eficiência | Menos modelos disponíveis |
| Sensores de segurança | Plataforma cruzada (PyTorch / TensorFlow) | Formação e investigação | Seguro, normalizado, rápido | Não é diretamente compatível com Ollama / MLX |
Hugging Face - a fonte central de abastecimento
Atualmente, o Hugging Face é algo como a "biblioteca" do mundo da IA. Em huggingface.co encontrará dezenas de milhares de modelos, conjuntos de dados e ferramentas - muitos dos quais são de utilização gratuita. Pode filtrar por nome, arquitetura, tipo de licença ou formato de ficheiro. Quer se trate de Mistral, LLaMA, Falcon, Gemma ou Phi-3 - quase todos os modelos conhecidos estão aí representados. Muitos programadores já oferecem versões personalizadas para utilização local com GGUF ou MLX.
Isto faz com que o Hugging Face seja o primeiro porto de escala para a maioria dos utilizadores se quiserem experimentar um modelo ou encontrar uma variante adequada para o macOS.

Modelos típicos e respectivos domínios de aplicação
O número de modelos disponíveis é atualmente quase impossível de controlar. No entanto, existem algumas famílias principais que se revelaram particularmente bem sucedidas para utilização local:
- Família LLaMA (Meta)Modelo de código aberto: Um dos modelos de código aberto mais conhecidos. Constitui a base de inúmeros derivados (por exemplo, Vicuna, WizardLM, Open-Hermes). Pontos fortes: Compreensão da língua, diálogo, utilização versátil. Domínio de aplicação: Aplicações gerais de conversação, geração de conteúdos, sistemas de assistência.
- Mistral e Mixtral (Mistral AI)Conhecido pela sua elevada eficiência e boa qualidade com um modelo de dimensões reduzidas. O Mixtral 8x7B combina vários modelos de peritos (arquitetura Mixture-of-Experts). Pontos fortes: Respostas rápidas e precisas, economia de recursos. Domínio de aplicação: Assistentes internos de empresas, análise de textos, preparação de dados.
- Phi-3 (Microsoft Research)Modelo compacto, optimizado para uma elevada qualidade de voz apesar de um número reduzido de parâmetros. Pontos fortes: Eficácia, boa gramática, respostas estruturadas. Domínio de aplicação: Sistemas mais pequenos, modelos de conhecimento local, assistentes integrados.
- Gemma (Google): Publicado pelo Google Research como um modelo aberto. Bom para tarefas de síntese e de explicação. Pontos fortes: Coerência, explicações contextualizadas. Domínio de aplicação: processamento de conhecimentos, formação, sistemas de aconselhamento.
- Modelos GPT-OSS / OpenHermesJuntamente com as modificações LLaMA, formam a "ponte" entre os modelos de código aberto e o âmbito funcional dos sistemas comerciais. Pontos fortes: Ampla base linguística, utilização flexível. Domínio de aplicação: Criação de conteúdos, tarefas de conversação e análise, assistência interna de IA.
- Claude / Command R / Falcon / Yi / ZephyrEstes e muitos outros modelos (na sua maioria provenientes de projectos de investigação ou de comunidades abertas) oferecem funções especiais como a recuperação de conhecimentos, a geração de códigos ou o multilinguismo.
O ponto mais importante é que nenhum modelo pode fazer tudo na perfeição. Cada um tem os seus pontos fortes e fracos - e, dependendo da aplicação, vale a pena fazer uma comparação direcionada.
Que modelo é adequado para que fim?
Para obter uma avaliação realista, os modelos podem ser classificados, grosso modo, em classes de desempenho e de aplicação:
Para a maioria das aplicações de secretária realistas - tais como resumos, correspondência, tradução, análise - os modelos médios (7-13 B) são completamente suficientes. Apresentam resultados incrivelmente bons, funcionam sem problemas numa Mac Mini M4 Pro com 32-48 GB de RAM e não requerem praticamente qualquer reajustamento.
Modelos grandes mostram os seus pontos fortes quando uma compreensão mais profunda ou contextos mais longos são importantes - por exemplo, no tratamento de textos jurídicos ou de documentação técnica. No entanto, deve ter pelo menos um Mac Studio com 64-128 GB Utilizar a memória de trabalho.
| Família de modelos | Origem | Pontos fortes | Domínio de aplicação |
|---|---|---|---|
| LLaMA | Meta | Compreensão da língua, diálogo | Aplicações gerais de conversação |
| Mistral / Mixtral | Mistral AI | Eficiência, alta precisão | Assistentes de empresa, análise |
| Phi-3 | Pesquisa da Microsoft | Compacto, linguisticamente forte | Pequenos sistemas, IA local |
| Gemma | Pesquisa Google | Coerência, explicabilidade | Consultoria, ensino, explicação de textos |
Opções para operar modelos linguísticos localmente
Se quiser utilizar um modelo de linguagem no seu próprio Mac, existem várias opções viáveis - dependendo dos seus requisitos técnicos e do objetivo pretendido. O melhor de tudo é que já não precisa de um ambiente de desenvolvimento complexo para começar.
Ollama - o início sem complicações
Ollama tornou-se rapidamente uma ferramenta padrão para modelos locais de IA. Funciona nativamente no macOS, utiliza de forma óptima o desempenho do Apple Silicon e permite iniciar um modelo com um único comando:
ollama run mistral
Isto carrega e prepara automaticamente o modelo desejado, que fica então disponível no terminal ou através de interfaces locais. O Ollama suporta o formato GGUF, permite descarregar modelos da Hugging Face e pode ser integrado através de APIs REST ou diretamente noutros programas.
Como trabalhar com Ollama um modelo linguístico local installiert e as outras opções que tem à sua disposição são descritas em pormenor noutro artigo. Existem também outros artigos sobre como utilizar o Qdrant uma memória flexível para a sua IA local.
LM Studio - interface gráfica do utilizador e administração
Estúdio LM destina-se a todos os que preferem uma interface gráfica de utilizador. Oferece downloads de modelos, janelas de conversação, controlos de temperatura, avisos de sistema e gestão de memória numa única aplicação. Isto é ideal sobretudo para principiantes: pode experimentar, comparar, guardar e alternar entre diferentes modelos sem ter de trabalhar com a linha de comandos. O software funciona de forma estável em Apple Silicon e também suporta modelos GGUF.
MLX / Python - para programadores e integradores
Se quiser ir mais longe ou integrar modelos nos seus próprios programas, pode utilizar o quadro MLX do Apple. Esta permite que os modelos sejam integrados diretamente em aplicações Python ou Swift. A vantagem reside no controlo máximo e na integração em fluxos de trabalho existentes - por exemplo, se uma empresa quiser adicionar funções de IA ao seu próprio software.
FileMaker Servidor 2025 - IA no contexto empresarial
Desde FileMaker Servidor 2025 Os modelos linguísticos baseados em MLX também podem ser abordados no lado do servidor. Isto torna possível, pela primeira vez, equipar uma aplicação empresarial central (por exemplo, um sistema ERP ou CRM) com a sua própria IA local. Por exemplo, os pedidos de apoio podem ser automaticamente classificados, os pedidos de informação dos clientes avaliados ou o conteúdo dos documentos analisado - sem que os dados saiam da empresa.
Isto é particularmente interessante para sectores que têm requisitos rigorosos de proteção de dados ou de conformidade (medicina, direito, administração, indústria).
Obstáculos típicos e como evitá-los
Mesmo que a barreira de entrada seja baixa, há alguns pontos a que deve estar atento:
Limites de memória: Se o modelo for demasiado grande para a memória disponível, não arrancará de todo ou será extremamente lento. A quantização (por exemplo, 4 bits) ou um modelo mais pequeno pode ajudar neste caso.
- Cálculo da carga e do desenvolvimento de calorO Mac pode ficar visivelmente quente durante sessões mais longas. É aconselhável uma boa ventilação e estar atento ao ecrã de atividade.
- Falta de suporte de GPU para software de terceirosAlgumas ferramentas ou portas mais antigas não utilizam o Neural Engine de forma eficiente. Nesses casos, o MLX pode fornecer melhores resultados.
- Portas e direitos de redeSe vários clientes tiverem de aceder ao mesmo modelo (por exemplo, dentro da rede de uma empresa), as portas locais devem ser libertadas - de preferência protegidas por HTTPS ou através de um proxy interno.
- Segurança dos dadosMesmo que os modelos sejam executados localmente, os textos sensíveis não devem ser armazenados em ambientes inseguros. Os registos locais e os registos de conversação são fáceis de esquecer, mas contêm frequentemente informações valiosas.
Se prestar atenção a estes pontos, pode operar um sistema de IA local poderoso que funciona de forma segura, silenciosa e eficiente com surpreendentemente pouco esforço.
Cronograma e considerações estratégicas
Estamos apenas no início de uma evolução que irá mudar o quotidiano de muitas profissões nos próximos anos. Os modelos locais de IA estão a tornar-se cada vez mais pequenos, mais rápidos e mais eficientes, enquanto a sua qualidade continua a melhorar. O que atualmente ainda requer 30 GB de memória, dentro de um ano poderá requerer apenas 10 GB - com a mesma qualidade de voz. Ao mesmo tempo, estão a surgir novas interfaces que podem ser utilizadas para integrar modelos diretamente em programas do Office, browsers ou software da empresa.
As empresas que dão hoje o passo em direção a uma infraestrutura de IA local estão a criar uma vantagem para si próprias. Desenvolvem conhecimentos especializados, asseguram a soberania dos seus dados e tornam-se independentes das flutuações de preços ou das restrições de utilização impostas por fornecedores externos. Uma estratégia sensata poderia ser a seguinte:
- Primeiro, experimente com um modelo pequeno (por exemplo, 3-7 mil milhões de parâmetros, através do Ollama ou do LM Studio).
- Em seguida, verifique especificamente quais as tarefas que podem ser automatizadas.
- Se necessário, integre modelos maiores ou crie um Mac Studio central como "servidor de IA".
- A médio prazo, reorganizar os processos internos (por exemplo, documentação, análise de texto, comunicação) com o apoio da IA.
Esta abordagem passo a passo não é apenas economicamente sensata, mas também sustentável - segue o princípio de adotar a tecnologia ao seu próprio ritmo, em vez de se deixar levar pelas tendências.
Num artigo separado, descrevi em pormenor a forma como os novos Formato MLX comparado com GGUF via Ollama no Mac.
A IA local como via discreta para a soberania digital
Os modelos linguísticos locais marcam o regresso à auto-determinação no mundo digital.
Em vez de enviar dados e ideias para centros de dados remotos na nuvem, pode agora voltar a trabalhar com as suas próprias ferramentas - diretamente na sua secretária, sob o seu próprio controlo.
Quer seja num Mac Mini, num Mac Studio ou num portátil potente - se tiver o hardware certo, pode agora utilizar, treinar e desenvolver a sua própria IA. Quer seja como assistente pessoal, como parte de um sistema ERP, como auxiliar de investigação numa editora ou como solução de proteção de dados num escritório de advogados - as possibilidades são surpreendentemente vastas.
E o melhor de tudo é que nos recorda a antiga força do computador - nomeadamente ser uma ferramenta que se controla a si próprio, em vez de um serviço que dita como devemos trabalhar. Isto faz da IA local um símbolo da autonomia moderna - silenciosa, eficiente e, no entanto, com um efeito impressionante.
Fontes recomendadas
- Criação de perfis de inferência de modelos linguísticos de grande dimensão no Apple SiliconA Quantisation Perspective (Benazir & Lin et al., 2025) - Examina em pormenor o desempenho da inferência no Apple Silicon em comparação com as GPUs NVIDIA, especificamente com foco na quantificação.
- Inferência LLM local de nível de produção em Apple SiliconUm estudo comparativo de MLX, MLC-LLM, Ollama, llama.cpp, e PyTorch MPS (Rajesh et al., 2025) - Comparação de diferentes plataformas em Apple Silicon incl. MLX, no que diz respeito ao débito, latência, comprimento do contexto.
- Avaliação comparativa da aprendizagem automática no dispositivo em Apple Silicon com MLX (Ajayi & Odunayo, 2025) - Centrou-se no MLX e no Apple Silicon, com dados de referência em relação aos sistemas NVIDIA.




Perguntas mais frequentes
- O que é exatamente um modelo de língua local?
Um modelo de língua local é uma IA que pode compreender e gerar textos - semelhante ao ChatGPT. A diferença é que não funciona através da Internet, mas diretamente no seu próprio computador. Todos os cálculos são efectuados localmente e nenhum dado é enviado para servidores externos. Isto significa que o utilizador mantém o controlo total sobre a sua própria informação. - Que vantagens oferece uma IA local em relação a uma solução na nuvem como o ChatGPT?
As três maiores vantagens são a proteção dos dados, a independência e o controlo dos custos.
- Proteção de dados: nenhum texto sai do computador.
- Independência: Não é necessária qualquer ligação à Internet, nem mudança de fornecedor ou risco de falha.
- Custos: Sem taxas contínuas por consulta. Paga uma vez pelo hardware - é só isso. - São necessárias competências de programação para utilizar um modelo linguístico localmente?
Não. Com ferramentas modernas como o Ollama ou o LM Studio, um modelo pode ser iniciado com apenas alguns cliques. Atualmente, mesmo os principiantes podem executar uma IA local em apenas alguns minutos, sem escrever uma única linha de código. - Que dispositivos Apple são particularmente adequados?
Para os principiantes, um Mac Mini com M4 ou M4 Pro e pelo menos 32 GB de RAM é muitas vezes suficiente. Se pretender utilizar modelos maiores ou vários ao mesmo tempo, é melhor optar por um Mac Studio com 64 GB ou 128 GB de RAM. Um Mac Pro não oferece praticamente nenhuma vantagem, exceto se precisar de ranhuras PCI-e. Os computadores portáteis são adequados, mas atingem os seus limites térmicos mais rapidamente. - Qual é a quantidade mínima de RAM que deve ter?
Isto depende do tamanho do modelo.
- Modelos pequenos (1-3 mil milhões de parâmetros): 16-32 GB são suficientes.
- Modelos médios (7-13 mil milhões): melhor 48-64 GB.
- Modelos grandes (mais de 30 mil milhões): 128 GB ou mais.
É importante planear com alguma reserva - caso contrário, haverá tempos de espera ou cancelamentos. - O que significa "Memória Unificada" para Apple Silicon?
A memória unificada é uma memória partilhada que é acedida simultaneamente pela CPU, GPU e motor neural. Isso economiza tempo e energia, pois não há necessidade de copiar dados entre diferentes áreas de memória. Esta é uma enorme vantagem, especialmente para cálculos de IA, porque tudo funciona num único fluxo. - Qual é a diferença entre a GGUF, a MLX e a Safetensors?
- GGUF: Um formato compacto para utilização local (por exemplo, no Ollama ou no LM Studio). Ideal para a inferência, ou seja, a execução de modelos acabados.
- MLX: formato próprio do Apple, especialmente para chips M. Muito eficiente, mas ainda jovem.
- Safetensors: Um formato do mundo PyTorch, destinado principalmente à formação e à investigação.
GGUF ou MLX são ideais para utilização local no Mac. - Onde é que arranja os modelos?
A plataforma mais conhecida é huggingface.co - uma enorme biblioteca de modelos de IA. Aí pode encontrar variantes de LLaMA, Mistral, Gemma, Phi-3 e muitos outros. Muitos modelos já estão disponíveis no formato GGUF e podem ser carregados diretamente no Ollama. - Quais são as ferramentas mais fáceis de utilizar?
Para começar, o Ollama e o LM Studio são ideais. O Ollama é executado no terminal e é leve. O LM Studio oferece uma interface gráfica de usuário com uma janela de bate-papo. Ambos carregam e iniciam modelos automaticamente e não requerem configuração complicada. - Os modelos linguísticos também podem ser utilizados com o servidor FileMaker?
Sim - desde o FileMaker Server 2025, os modelos MLX podem ser endereçados diretamente. Isso permite análises de texto, classificações ou avaliações automáticas dentro de sistemas ERP ou CRM, por exemplo. Isto permite que os dados comerciais confidenciais sejam processados localmente, sem necessidade de os enviar para fornecedores externos. - Qual é o tamanho normal destes modelos?
Os modelos pequenos têm apenas alguns gigabytes, os grandes podem ter 20 a 30 GB ou mais. O seu tamanho pode ser bastante reduzido através da quantização (por exemplo, 4 bits), muitas vezes com uma perda mínima de qualidade. Um modelo 13-B comprimido, por exemplo, pode ocupar apenas 7 GB - perfeito para um Mac Mini M4 Pro. - É possível treinar ou personalizar modelos locais?
Basicamente sim - mas a formação é muito intensiva em termos de computação. As estruturas MLX ou Python podem ser utilizadas para afinação local de modelos mais pequenos. Atualmente, o FileMaker contém uma função integrada para Afinar diretamente os modelos linguísticos para o poder fazer. No entanto, para um treino em grande escala (por exemplo, 50 mil milhões de parâmetros), seria necessário um parque de GPU dedicado. Para a maioria das aplicações, é suficiente utilizar os modelos existentes e controlá-los especificamente através de avisos. - Quanta energia consome um Mac durante os cálculos de IA?
Surpreendentemente pouco. Um Mac Studio tem frequentemente menos de 100 W em pleno funcionamento, enquanto uma única placa gráfica NVIDIA (por exemplo, RTX 5090) consome até 450 W - sem CPU e periféricos. Isto significa que a IA local em hardware Apple não é apenas mais silenciosa, mas também significativamente mais eficiente em termos energéticos. - Um MacBook Pro é adequado para IA local?
Sim, mas com restrições.
Embora o desempenho seja elevado, a capacidade de carga térmica é limitada. O processador fica estrangulado durante sessões mais longas. Um MacBook Pro M3/M4 é perfeito para conversas curtas, tarefas de texto ou análises - mas não para uma utilização a longo prazo. - Até que ponto os modelos locais são realmente seguros?
Tão seguros como o sistema em que são executados. Uma vez que não são enviados dados através da Internet, não existe praticamente qualquer risco por parte de terceiros. No entanto, deve certificar-se de que os ficheiros temporários, os registos ou os históricos de conversação não vão parar acidentalmente a pastas na nuvem (por exemplo, iCloud Drive). O armazenamento local no SSD interno é o ideal. - Quais são os erros típicos que os principiantes cometem?
- Carregamento de modelos demasiado grandes, apesar de não haver memória RAM suficiente.
- Utilizar versões antigas do Ollama ou do LM Studio.
- Não ativar a aceleração da GPU (por exemplo, MLX).
- Demasiados processos em execução em segundo plano.
- Carregamento de modelos de fontes duvidosas.
Solução: Utilizar apenas fontes fiáveis (por exemplo, Hugging Face) e estar atento aos recursos do sistema. - Como é que a tecnologia local de IA se irá desenvolver nos próximos anos?
Os modelos estão a tornar-se ainda mais compactos e precisos. Apple, Mistral e Meta já estão a trabalhar em arquitecturas que requerem menos memória e energia para a mesma qualidade. Ao mesmo tempo, estão a ser desenvolvidas interfaces convenientes - como plug-ins de IA para processamento de texto, programas de correio ou aplicações de notas. A longo prazo, é provável que cada sistema profissional tenha uma espécie de "IA local incorporada". - Porque é que vale a pena começar agora?
Porque as bases para os próximos anos estão a ser lançadas agora mesmo. Qualquer pessoa que aprenda hoje a iniciar um modelo localmente, a processar dados de forma estruturada e a formular avisos de forma direcionada será capaz de agir de forma independente mais tarde - sem ter de depender de fornecedores de serviços de nuvem dispendiosos. Resumindo: a IA local é o caminho calmo e confiante para um futuro digital em que pode voltar a ter os seus dados e ferramentas nas suas próprias mãos.



