Bu yazı dizisinin ilk bölümünde ChatGPT veri aktarımının teknik bir işlevden çok daha fazlası olduğunu gördük. Dışa aktarılan verileriniz, uzun bir süre boyunca biriken düşünceler, fikirler, analizler ve konuşmalardan oluşan bir koleksiyon içerir. Ancak bu veriler sabit diskinizde yalnızca bir arşiv olarak saklandığı sürece, yalnızca bir arşiv olarak kalır. Önemli olan adım, bu bilgileri tekrar kullanılabilir hale getirmektir. Kişisel bilgi yapay zekasının geliştirilmesi tam da bu noktada başlar.
Fikir aslında şaşırtıcı derecede basit: bir yapay zeka yalnızca genel bilgilerle çalışmamalı, aynı zamanda kendi verilerinize de erişebilmelidir. Önceki konuşmalar arasında arama yapabilmeli, uygun içeriği bulabilmeli ve bunu yeni cevaplara dahil edebilmelidir. Bu, sıradan bir YZ'yi bir tür dijital belleğe dönüştürür. Bu, yazı dizisinin ikinci bölümüdür ve şimdi işin pratik yönüne bakmaktadır.




Serinin 1. Bölümü: ChatGPT veri dışa aktarımında hafife alınan hazine
Bu ikinci bölümde işin pratik yönüne girerken, şu konulara bir göz atmakta fayda var bu serinin ilk makalesi. ChatGPT veri aktarımının ilk etapta neden bu kadar ilginç olduğu ve birçok kullanıcının neden hala potansiyelini hafife aldığı temel sorusuyla ilgileniyor. Makale, dışa aktarımda gerçekte hangi verilerin bulunduğunu, kişisel bir bilgi arşivi oluşturmak için nasıl kullanılabileceğini ve bu adımın neden hafızalı kendi yapay zekanız için temel oluşturduğunu göstermektedir. Bu boru hattını neden oluşturduğumuzu ve kendi sohbet geçmişlerinizin ne gibi bir stratejik değere sahip olduğunu anlamak istiyorsanız, Bölüm 1 ile başlamalısınız.
Bir sonraki bölümde gerçek uygulamaya başlamadan önce, böyle bir sistemin temelde nasıl yapılandırıldığına bir göz atalım.
RAG sisteminin temel fikri
Sistemimizin teknik temeli, artık yapay zeka dünyasında yaygın olarak kullanılan bir kavramdır: RAG veya Retrieval Augmented Generation. Bu terimin arkasında çok pratik bir ilke yatmaktadır.
Normalde bir dil modeli soruları yalnızca eğitimi sırasında öğrendiği bilgilerle yanıtlar. Bu bilgi kapsamlı olmasına rağmen, iki belirleyici sınırlaması vardır:
- İlk olarak, model kendi projeleriniz veya düşünceleriniz hakkında herhangi bir bireysel bilgi sahibi değildir.
- İkinci olarak, eğitimden sonra oluşturulan yeni verilere erişemez.
RAG sistemi tam da bu noktada devreye girer. Doğrudan bir yanıt üretmek yerine, önce başka bir şey olur: sistem, sorulan soruyla eşleşen içerik için bir veritabanı arar. Bu içerik daha sonra bağlam olarak dil modeline aktarılır. Yapay zeka ancak bundan sonra cevabını formüle eder. Basit bir ifadeyle, süreç şu şekildedir:
- Sen bir soru sor →
- sistem bir bilgi veritabanında arama yapar →
- ilgili içerik bulunur →
- Bu içerik YZ'ye bağlam olarak aktarılır →
- yapay zeka bir cevap üretir.
Belirleyici avantaj açıktır: YZ, orijinal eğitiminin bir parçası olmayan bilgileri kullanabilir.
İşte ChatGPT verilerinizin devreye girdiği yer burasıdır. Bu konuşmaları bir bilgi veritabanına entegre edersek, yapay zeka bunlara daha sonra erişebilir. Önceki fikirleri bulabilir, eski diyaloglardaki argümanları kullanabilir veya geçmiş konuşmalardaki analizleri dikkate alabilir. Böylece sistem kendi düşüncelerinizi „hatırlamaya“ başlar.
Sistemimizin yapı taşları
Bunun için birlikte çalışan birkaç bileşene ihtiyacımız var. Neyse ki bunun için gerekli teknik altyapıya ulaşmak bugün birkaç yıl öncesine göre çok daha kolay. Sistemimiz özünde dört merkezi bileşenden oluşuyor.
- İlk yapı taşı ChatGPT veri aktarımı. İşte ham verilerimiz. Bu, daha önce yapay zeka ile yaptığımız tüm konuşmaları içeriyor.
- İkinci yapı taşı ise bir Gömme modeli. Bu model metni matematiksel vektörlere çevirir. Bu da metinleri anlamlarına göre karşılaştırmayı mümkün kılar.
- Üçüncü yapı taşı ise bir Vektör veritabanı. Bizim durumumuzda Qdrant kullanıyoruz. Bu veri tabanı metinlerin matematiksel temsillerini depolar ve hızlı bir semantik arama sağlar.
- Dördüncü yapı taşı bir yerel dil modeli, Ollama üzerinden çalışır. Bu model daha sonra gerçek cevapları formüle edecektir.
Bu dört bileşen birlikte yakın bir şekilde çalışır.
- Veri aktarımı içeriği sağlar.
- Gömme modeli bunları makine tarafından okunabilir hale getirir.
- Vektör veritabanı bunları kaydeder ve arar.
- Dil modeli nihayetinde anlaşılabilir cevaplar üretir.
Birlikte, kişisel bilgi yapay zekasının temelini oluştururlar.
Bir bakışta veri akışı
Sistemin çalışması için verilerin birkaç adımdan geçmesi gerekir. İlk adım, ilk makalede zaten oluşturduğumuz ChatGPT veri aktarımıdır. İçerdiği konuşmalar önce JSON dosyalarından çıkarılır. Daha sonra bu metinler hazırlanmalıdır. Büyük sohbet geçmişleri, metin parçaları olarak bilinen daha küçük bölümlere ayrılır. Bu, sonraki aramayı çok daha verimli hale getirir.
Bir sonraki adımda, bu metin bölümlerinden gömüler oluşturuyoruz. Her metin matematiksel olarak tanımlanır. Benzer anlama sahip metinlere benzer vektörler verilir. Daha sonra bu vektörleri vektör veritabanımız Qdrant'a kaydediyoruz.
Bu, altyapının en önemli kısmının zaten mevcut olduğu anlamına gelir. Daha sonra bir soru sorulursa, aşağıdakiler gerçekleşir:
- Soru ayrıca bir vektöre dönüştürülür.
- Veritabanı benzer anlama sahip metinleri arar.
- Bu metin pasajları dil modeline bağlam olarak aktarılır.
- Model bu bilgiyi bir cevap formüle etmek için kullanır.
Bu süreç, yapay zekanın yalnızca genel bilgiyi kullanmasını değil, aynı zamanda kendi verilerinize de erişebilmesini sağlar.
Sonunda ne mümkün olacak
Sistem kurulduktan sonra, yapay zeka ile çalışmak gözle görülür şekilde değişir. Artık sadece genel bir dil modeliyle değil, kendi verilerinize erişebilen bir yapay zeka ile çalışıyorsunuz. Bu tamamen yeni olasılıkların önünü açar. Örneğin, aşağıdaki gibi sorular sorabilirsiniz:
„Yapay zeka ile bu konu hakkında hiç konuştum mu?“
„Bu proje hakkında daha önce hangi fikirlere sahiptim?“
„Önceki görüşmelerde hangi argümanları geliştirdim?“
Yapay zeka daha sonra kendi konuşmalarınız arasında arama yapar ve uygun içeriği bulur. Sadece genel bir cevap vermek yerine, önceki düşüncelere atıfta bulunabilir, eski analizleri özetleyebilir veya farklı konuşmalar arasındaki bağlantıları tanıyabilir.
Başka bir deyişle, yapay zeka kendi bilgi arşivinizle çalışmaya başlar. Bu da basit bir sohbet aracını uzun vadede düşüncelerinizi destekleyebilecek bir sisteme dönüştürür. Ve önümüzdeki birkaç bölümde adım adım inşa edeceğimiz şey de tam olarak bu sistemdir. Bir sonraki bölümde, pratik çalışmalarla başlıyoruz ve ilk olarak ChatGPT veri aktarımına daha yakından bakıyoruz. Çünkü bir bilgi veritabanı oluşturmadan önce, verilerimizin gerçekte nasıl yapılandırıldığını anlamamız gerekir.
Yerel yapay zeka sistemlerinin kullanımına ilişkin güncel anket
Hazırlık: ChatGPT veri dışa aktarımını anlama
Bu serinin ilk makalesinde ChatGPT veri dışa aktarımını oluşturmuş ve bir ZIP dosyası olarak indirmiştik. İlk bakışta, bu dosya biraz dikkat çekici görünmeyebilir - başlangıçta değerli bir veri setinden çok bir yedekleme gibi görünen bazı teknik dosyalar içeren bir arşiv. Ancak, bu arşiv tüm bilgi sistemimizin temelini içermektedir.
Bu verileri bir veritabanına yüklemeye veya bir yapay zekaya bağlamaya başlamadan önce, dışa aktarımın nasıl yapılandırıldığını anlamamız gerekir. Çünkü ancak hangi bilgilerin içerildiğini ve nasıl yapılandırıldığını bilirsek daha sonra bunları anlamlı bir şekilde işleyebiliriz. Bu nedenle bu bölümde, veri aktarımının nasıl yapılandırıldığına, hangi dosyaların gerçekten ilgili olduğuna ve bu teknik arşivi YZ bilgi sistemimiz için nasıl yararlı bir temele dönüştürebileceğimize bakacağız.
ZIP dosyasını açın
İlk adım önemsizdir, ancak yine de önemlidir: indirilen arşivi açmamız gerekir. Dosya normalde klasik bir ZIP dosyası olarak mevcuttur. Önceki kullanımınızın kapsamına bağlı olarak, boyut olarak değişebilir. Bazı kullanıcılar birkaç yüz megabaytlık bir arşiv alırken, diğerleri birkaç gigabaytlık bir arşiv alır.
Dosyayı paketinden çıkardıktan sonra, birkaç dosya ve alt klasör içeren bir klasör oluşturulur. Tam yapı biraz değişebilir, ancak genellikle bir dizi JSON dosyası ve muhtemelen ek bilgiler içeren başka dosyalar bulacaksınız.
Birçok kullanıcı için bu yapı başlangıçta biraz teknik görünmektedir. Ancak bir an durup düşünürseniz, bir örüntüyü hemen fark edersiniz: veriler nispeten düzgün bir şekilde düzenlenmiştir ve net bir yapı izler. Bu iyi bir haber, çünkü içeriği daha sonra otomatik olarak işlemeyi mümkün kılan tam da bu yapıdır.
Sohbet verilerinin yapısı
Dışa aktarmanın en önemli kısmı gerçek sohbet verileridir. Bu sohbetler genellikle bir veya daha fazla JSON dosyasında saklanır. JSON, genellikle yapılandırılmış bilgileri depolamak için kullanılan yaygın olarak kullanılan bir veri formatıdır.
Böyle bir dosya sadece uzun bir metin içermez. Bunun yerine, bir diyalog tek tek öğelere ayrılır. Tipik olarak, bir diyalog birkaç mesajdan oluşur. Her mesaj aşağıdaki gibi bilgiler içerir
- mesajın gerçek metni
- gönderenin rolü (kullanıcı veya yapay zeka)
- bir zaman damgası
- kısmen daha fazla meta veri
Bu, diyaloğun tüm seyrinin yeniden oluşturulmasına olanak tanır. Örneğin, bir diyalog kullanıcıdan gelen bir soru ile başlar. Bunu yapay zekadan gelen bir cevap takip eder. Daha sonra başka sorular ve cevaplar gelebilir. Bu mesajların her biri ayrı ayrı kaydedilir.
Bunun önemli bir avantajı vardır: daha sonra kimin ne söylediğini ve bir konuşmanın nasıl geliştiğini tam olarak anlayabiliriz. Daha sonra bu içeriği tam olarak aramak ve analiz etmek istediğimizden, bu özellikle bilgi sistemimiz için önemlidir.
Gerçekten hangi verilere ihtiyacımız var
Dışa aktarım çok fazla bilgi içermesine rağmen, bilgi sistemimiz için hepsine ihtiyacımız yok. En önemli bileşen konuşmaların metinleridir. Bu metinler gerçek içeriği içerir: Fikirler, analizler, sorular ve cevaplar. Daha sonra aramak istediğimiz de tam olarak bu içeriktir.
Bazı meta veriler de faydalı olabilir. Bu, örneğin şunları içerir
- Zaman Damgası
- Konuşma başlığı
- Muhtemelen dahili kimlik numaraları
Bu bilgi, içeriği daha sonra daha iyi sıralamamıza veya bir konuşmayı zaman açısından kategorize etmemize yardımcı olur. Dışa aktarımın diğer bileşenleri projemiz için daha az önemlidir. Örneğin, yalnızca platformun dahili işleyişini ilgilendiren belirli teknik meta veriler buna dahildir.
Bu nedenle bilgi tabanımızı oluşturmak için kasıtlı olarak temel bilgilere odaklanıyoruz: konuşma metinleri ve bazı temel bağlamsal bilgiler. Bu verileri ne kadar net bir şekilde yapılandırırsak, yapay zekamız daha sonra bu verilerle o kadar iyi çalışabilir.
Verilerin ilk incelemesi
Otomatik komut dosyalarıyla çalışmaya başlamadan önce, verilerin kendisine hızlıca bir göz atmakta fayda var. Bunu yapmak için, JSON dosyalarından birini basit bir metin düzenleyici veya JSON dosyalarını iyi görüntüleyebilen bir programla açın. Visual Studio Code gibi birçok kod düzenleyici bunun için çok uygundur, ancak basit metin düzenleyiciler de işe yarar.
Dosyaya ilk baktığınızda, muhtemelen nispeten büyük miktarda yapılandırılmış veri göreceksiniz. JSON dosyaları iç içe geçmiş öğelerden, yani sırayla diğer alanları içeren veri alanlarından oluşur. Bu ilk başta biraz karmaşık görünebilir, ancak biraz sabırla temel yapıyı hızlı bir şekilde tanıyacaksınız. Örneğin, bir görüşmenin birkaç mesajdan oluştuğunu ve her mesajın ayrı bir nesneyi temsil ettiğini göreceksiniz. Asıl metin genellikle açıkça tanınabilir bir alandadır.
Bu ilk taramanın önemli bir amacı vardır: verilerinizin nasıl yapılandırıldığını anlamanıza yardımcı olur. Çünkü bir sonraki bölümde, konuşmaları otomatik olarak okumak ve bilgi sistemimiz için hazırlamak için tam olarak bu yapıyı kullanacağız. Başka bir deyişle: Şu anda teknik bir veri arşivini adım adım kullanılabilir bir bilgi tabanına dönüştürüyoruz. Ve bir sonraki bölümde tam olarak bu noktadan başlayacağız. Buradaki amaç, sohbet verilerini ayıklamak ve daha sonra verimli bir şekilde aranabilecek şekilde hazırlamaktır.
Veri hazırlama: Konuşmalardan analiz edilebilir metinlere
Bir önceki bölümde ChatGPT veri dışa aktarımını açtıktan ve yapı hakkında ilk genel bakışı edindikten sonra, şimdi projemizin asıl teknik kısmı başlıyor. Dışa aktarılan veriler tamamlanmış olmasına rağmen, bu haliyle bilgi sistemimiz için henüz en uygun şekilde uygun değildir.
Nedeni basit: sohbet geçmişleri genellikle uzundur, birçok konu içerir ve insanlar için okunabilir bir yapıda saklanır, ancak semantik aramalar veya vektör veritabanları için ideal değildir. Yapay zekamızın daha sonra ilgili içeriği bulmasını sağlamak için önce bu ham verileri işlememiz gerekir. Bu aslında üç şey anlamına gelir:
- JSON dosyalarından konuşmaları ayıklayın
- metinleri mantıklı bir şekilde yapılandırmak
- içeriği daha küçük bölümlere ayırın
Bu süreç, modern yapay zeka sistemlerinde tamamen normal bir adımdır ve genellikle ön işleme olarak adlandırılır.
Ham veriler neden doğrudan uygun değildir?
JSON dosyalarından birine bakarsanız, tek bir sohbetin genellikle birçok mesajdan oluştuğunu fark edeceksiniz. Örneğin tipik bir diyalog şöyle görünebilir:
- Soru
- Cevap
- Soruşturma
- yeni beyan
- daha fazla detay
- Özet
Bazı konuşmalar yüzlerce hatta binlerce kelime içerebilir. Bu insanlar için bir sorun değildir. Bir diyaloğu basitçe yukarıdan aşağıya doğru okuruz.
Ancak bu, yapay zeka araması için daha az işe yarar. Bunun nedeni, tek bir sohbetin genellikle birkaç konu içermesidir. Daha sonra semantik bir arama gerçekleştirirsek, sistem metin pasajlarını mümkün olduğunca kesin bir şekilde bulmalıdır - çok sayıda farklı içeriğe sahip tüm konuşmaları değil.
Bu nedenle büyük metinler daha küçük bölümlere ayrılır. Bu bölümlere parça adı verilir. Parça, basitçe tutarlı bir düşünce içeren küçük bir metin bloğudur. Bu yöntem daha sonra arama kalitesini önemli ölçüde artırır.
Sohbet geçmişlerini ayıklayın
İlk pratik adım JSON dosyalarındaki içeriği okumaktır. Bunun için küçük bir Python betiği kullanıyoruz. Python bu tür görevler için özellikle uygundur çünkü veri işleme ve yapay zeka için birçok kütüphane içerir.
Önce yeni bir dosya oluşturun, örneğin:
extract_chats.py
Ardından sohbet verilerini yükleyen basit bir komut dosyası ekliyoruz.
import json
with open("conversations.json", "r", encoding="utf-8") as f:
data = json.load(f)
print("Anzahl der Gespräche:", len(data))Bu betiği çalıştırdığınızda, dışa aktarımınızda kaç tane konuşma olduğunu görmelisiniz. Şimdi gerçek metinleri çıkaralım.
texts = []
for conversation in data:
if "mapping" in conversation:
for node in conversation["mapping"].values():
message = node.get("message")
if message:
content = message.get("content")
if content and "parts" in content:
text = " ".join(content["parts"])
texts.append(text)
print("Extrahierte Textabschnitte:", len(texts))Bu komut dosyası JSON yapısı üzerinden çalışır ve konuşmalardan tüm metin parçalarını toplar. Bu, en önemli kısmı zaten tamamladığımız anlamına gelir: içeriği teknik dışa aktarma biçiminden çıkardık.
Metin parçaları oluşturma
Şimdi bir sonraki önemli adım geliyor: parçalara ayırma. Konuşmaların tamamını kaydetmek yerine, metinleri daha küçük bölümlere ayırıyoruz.
Bu tür metin bölümleri için tipik bir boyut 300 ila 800 kelime veya yaklaşık 500 belirteçtir. Aşağıda metinlerin parçalara nasıl bölüneceğine dair basit bir örnek verilmiştir.
def split_text(text, chunk_size=500):
words = text.split()
chunks = []
for i in range(0, len(words), chunk_size):
chunk = " ".join(words[i:i+chunk_size])
chunks.append(chunk)
return chunksŞimdi bu fonksiyonu metinlerimize uygulayabiliriz.
all_chunks = []
for text in texts:
chunks = split_text(text)
all_chunks.extend(chunks)
print("Gesamtzahl der Chunks:", len(all_chunks))Artık sohbet geçmişlerimizden birçok küçük metin bölümü oluşturduk. Bu metin blokları daha sonra bir vektör veritabanında arama yapmak için idealdir.
Meta veri ekleyin
Gerçek metne ek olarak, ek bilgiler de çok yararlı olabilir. Bu sözde meta veriler, içeriği daha sonra daha iyi sıralamamıza veya filtrelememize yardımcı olur. Tipik meta veriler şunlar olabilir
- Görüşme tarihi
- Konuşma başlığı
- Kaynak (ChatGPT Export)
- Çağrı kimliği
Bu bilgiyi metinle birlikte, örneğin şu şekilde kaydedebiliriz:
documents = []
for conversation in data:
title = conversation.get("title", "Unbekannt")
if "mapping" in conversation:
for node in conversation["mapping"].values():
message = node.get("message")
if message:
content = message.get("content")
if content and "parts" in content:
text = " ".join(content["parts"])
chunks = split_text(text)
for chunk in chunks:
documents.append({
"text": chunk,
"title": title
})Bu, verilerimize şimdiden çok daha iyi bir yapı kazandırdı. Kafa karıştırıcı bir sohbet arşivi yerine, artık her biri bağlamsal bilgilerle sağlanan birçok küçük metin bölümünden oluşan bir koleksiyonumuz var.
Bir sonraki adımda çok önemli olacak olan tam da bu yapıdır. Çünkü artık bu metinlerden gömüler oluşturmaya başlayabiliriz - yani daha sonra vektör veritabanımıza kaydedilecek olan içeriğin matematiksel temsilleri. Ve bir sonraki bölüm tam olarak bununla ilgili.
Yerleştirmeler oluşturun
Bir önceki bölümde ChatGPT verilerimizi kullanılabilir bir forma sokmuştuk. Konuşmaları JSON dosyalarından çıkardık, metinleri temizledik ve daha küçük bölümlere ayırdık - sözde parçalar.
Bununla birlikte, yapay zekamızın içeriği gerçekten anlamlı bir şekilde arayabilmesi için hala çok önemli bir adım eksik. Metinlerin makinelerin karşılaştırabileceği bir forma çevrilmesi gerekiyor. İşte bu noktada embeddings devreye giriyor.
Gömüler, metinlerin matematiksel temsilleridir. Bilgisayarların metinlerin anlamlarını karşılaştırmasını sağlarlar. Benzer içeriğe sahip iki metin, farklı kelimeler kullansalar bile benzer vektörler alırlar. Bu tam da bilgi sistemimiz için ihtiyaç duyduğumuz özelliktir. Sonuçta, yapay zekamız yalnızca aynı kelimeleri değil, aynı zamanda eşleşen içeriğe sahip metinleri de aramalıdır.
Yerleştirmeler nedir
Gömme temel olarak bir sayı listesidir. Bu sayılar bir metnin matematiksel bir uzaydaki anlamını tanımlar. Her metin sözde bir vektöre dönüştürülür. Böyle bir vektör örneğin şöyle görünebilir:
[0.134, -0.876, 0.442, 0.921, -0.223, ...]
Tek bir vektör birkaç yüz hatta binlerce sayı içerebilir. Bu sayılar elbette insanlar için doğrudan anlaşılabilir değildir. Ancak makineler için, metinler arasındaki benzerlikleri hesaplamak için idealdirler. İki metin benzer içeriğe sahipse, vektörleri matematiksel uzayda birbirine daha yakındır. Bir örnek:
- Metin A„ChatGPT verilerimi nasıl dışa aktarabilirim?“
- Metin B: „ChatGPT konuşmalarımı nasıl indirebilirim?“
İfadeler farklı olsa da her iki metin de temelde aynı konuyu anlatmaktadır. İyi bir gömme modeli bu benzerliği tanır. Bu nedenle iki metin benzer vektörler alır. Bu prensibi daha sonra anlamsal aramamız için kullanacağız.
Ollama ile gömme modelleri
Yerleştirmeler oluşturmak için özel bir modele ihtiyacımız var. Neyse ki bunun için harici bulut hizmetlerini kullanmak zorunda değiliz. Birçok gömme modeli artık yerel olarak çalıştırılabiliyor - ve Ollama burada devreye giriyor.
Sisteminizde Ollama zaten çalıştığından, oraya bir install modeli yerleştirebiliriz. Örneğin çok iyi bir model:
nomic-embed-text
Aşağıdaki 1TP12 komutu ile onu evcilleştirebilirsiniz:
ollama pull nomic-embed-text
Diğer popüler modeller şunlardır
- mxbai-embed-large
- bge-large
- hepsi-minilm
Bizim amaçlarımız için nomic-embed-text çok iyi bir başlangıç noktasıdır. Bu model yüksek kalitede gömüler üretir ve yerel olarak sorunsuz çalışır.
Yerel olarak katıştırmalar oluşturun
Şimdi Python betiğimizi gömme oluşturabilecek şekilde genişletmek istiyoruz. İlk olarak 1TP12Python'un Ollama ile iletişim kurabileceği bir kütüphane oluşturuyoruz.
pip install ollama
Artık gömme modelini doğrudan Python'dan ele alabiliriz. Aşağıda basit bir örnek verilmiştir:
import ollama
response = ollama.embeddings(
model="nomic-embed-text",
prompt="Wie exportiere ich meine ChatGPT-Daten?"
)
print(len(response["embedding"]))Her şey yolunda gittiyse, birkaç yüz sayı içeren bir vektör elde edeceksiniz.
Şimdi bunu sohbet parçalarımıza uygulayalım.
embeddings = []
for doc in documents:
text = doc["text"]
result = ollama.embeddings(
model="nomic-embed-text",
prompt=text
)
vector = result["embedding"]
embeddings.append({
"text": text,
"embedding": vector,
"title": doc["title"]
})Bunu her metin bölümü için bir vektör oluşturmak için kullanırız. Bu vektörler daha sonra veritabanımıza kaydedilir.
Bu adım neden çok önemlidir?
Gömüler modern bilgi sistemlerinin kalbinde yer alır. Gömüler olmadan, metinleri yalnızca klasik anahtar kelime aramaları kullanarak arayabilirdik. Bu da sistemin yalnızca tamamen aynı kelimeleri içeren içerikleri bulacağı anlamına gelirdi. Ancak dil nadiren bu kadar basit çalışır. Örneğin, bir kullanıcı şöyle sorabilir:
„ChatGPT verilerimi nasıl işledim?“
Bununla birlikte, orijinal konuşma şu şekilde formüle edilebilir:
„ChatGPT veri dışa aktarımımı nasıl analiz edebilirim?“
Basit bir arama bu bağlantıyı tanımayabilir. Yerleştirmelerde durum farklıdır. Her iki metin de benzer anlamlara sahip olduğundan, vektörleri matematiksel uzayda birbirine yakındır. Bu nedenle veritabanımız, ifadeler farklı olsa bile eşleşen içeriği bulabilir. Semantik aramayı bu kadar güçlü kılan da tam olarak bu yetenektir. Yapay zekanın yalnızca sözcükleri değil, anlamı da aramasını sağlar.
İşte tam da bu yüzden gömülendirmeler sistemimizin temel yapı taşıdır. Bir sonraki bölümde, bunun üzerine inşa edeceğiz ve vektör veritabanımızı installieren. Üretilen vektörleri orada saklayacağız - ve böylece kişisel bilgi yapay zekamızın temelini oluşturacağız.
Qdrant 1TP12Ekleme ve yapılandırma
Önceki bölümde sohbet verilerimiz için katıştırmaları oluşturduktan sonra, artık bir metin bölümleri ve ilişkili vektörler koleksiyonuna sahibiz. Bu vektörler metinlerin anlamını matematiksel olarak tanımlar ve bu nedenle anlamsal bir arama için temel oluşturur. Ancak, bu veriler şu anda yalnızca senaryomuzun çalışma belleğinde veya basit listelerde mevcuttur. Yapay zekamızın daha sonra bu verilere verimli bir şekilde erişebilmesi için özel bir belleğe ihtiyacımız var.
İşte tam da bu noktada bir vektör veritabanı devreye girer. Bir vektör veritabanı, bu tür gömülmelerin büyük miktarlarını depolamak ve benzer vektörleri hızlı bir şekilde aramak için optimize edilmiştir. Projemiz için, yapay zeka uygulamaları için özel olarak geliştirilmiş modern bir açık kaynak veritabanı olan Qdrant'ı kullanıyoruz.
Bu bölümde 1TP12 Qdrant'ı kuracağız, sunucuyu başlatacağız ve sohbet verilerimizi daha sonra kolayca içe aktarabilmemiz için veritabanını hazırlayacağız.
Qdrant nedir
Qdrant, vektör aramaları için özelleşmiş bir veritabanıdır. Geleneksel veritabanları bilgileri isimler, sayılar veya metinler gibi tablolarda depolarken, bir vektör veritabanı verilerin matematiksel gösterimleriyle çalışır.
Bu, Qdrant'ın sadece metni kaydetmek yerine, ilişkili gömülmeleri de kaydettiği anlamına gelir. En büyük avantaj aramada yatmaktadır. Daha sonra bir soru sorulursa, sistemimiz bu soruyu da bir vektöre dönüştürür. Qdrant daha sonra hangi kayıtlı metinlerin bu vektöre en çok benzediğini yıldırım hızıyla hesaplayabiliyor. Bu, örneğin, bulmayı mümkün kılar:
- hangi sohbet pasajlarının tematik olarak soruyla eşleştiği
- hangi önceki konuşmaların benzer içerik içerdiği
- hangi fikirlerin arşivinizle ilgili olabileceği
İşte tam da bu nedenle Qdrant bugün belge aramadan karmaşık bilgi asistanlarına kadar birçok modern yapay zeka sisteminde kullanılmaktadır. Bir başka avantaj: Qdrant açık kaynak kodludur, hızlı bir şekilde 1TP12'leştirilmiştir ve normal bir yerel makinede sorunsuz çalışır.
Qdrant'ın Kurulumu
installieren Qdrant'ı kullanmanın en kolay yolu Docker kullanmaktır. Makinenizde Docker mevcutsa, sunucuyu tek bir komutla başlatabilirsiniz. Burada şunları yapabilirsiniz Docker'ı İndirin, henüz bilgisayarınıza yüklemediyseniz installiert.
docker run -p 6333:6333 qdrant/qdrant
Bu komut Qdrant sunucusunu başlatır ve standart port 6333'ü açar. Kodlarımız daha sonra bu port üzerinden veritabanı ile iletişim kurabilir.
Docker kullanmak istemiyorsanız, Qdrant'ı installiere etmenin başka yolları da vardır, örneğin yerel bir ikili veya paket yöneticisi aracılığıyla. Bununla birlikte, birçok pratik projede Docker'ın en basit ve en istikrarlı seçenek olduğu kanıtlanmıştır.
Sunucu başlatıldıktan sonra Qdrant arka planda çalışır ve istekleri bekler. Şimdi sunucunun erişilebilir olup olmadığını test edebilirsiniz. Bunu yapmak için tarayıcınızda aşağıdaki adresi açın:
http://localhost:6333
Her şey çalıştıysa, basit bir durum mesajı görünmelidir. Sunucu artık sonraki adımlar için hazırdır.
Qdrant ile ilk adımlar
Sohbet verilerimizi içe aktarmadan önce, bir koleksiyon oluşturmamız gerekir. Qdrant'ta bir koleksiyon, klasik bir veritabanındaki bir tablo ile karşılaştırılabilir. Vektörlerimizi ve ilgili verileri içerir.
İlk olarak Qdrant için Python kütüphanesini installiere ediyoruz:
pip install qdrant-client
Şimdi Python betiğimizde veritabanına bir bağlantı kurabiliriz.
from qdrant_client import QdrantClient
client = QdrantClient("localhost", port=6333)Bu kod bir hata mesajı olmadan çalıştırılırsa, bağlantı başarılı olur. Şimdi sohbet verilerimiz için bir koleksiyon oluşturuyoruz.
from qdrant_client.models import VectorParams, Distance client.recreate_collection( collection_name="chatgpt_archive", vectors_config=VectorParams(size=768, distance=Distance.COSINE), )
Buradaki en önemli parametreler şunlardır
- collection_name - veritabanımızın adı
- boyut - gömme vektörlerinin uzunluğu
- mesafe - benzerlik hesaplama yöntemi
Vektör boyutu kullanılan gömme modeline bağlıdır. Birçok model 768 veya 1024 boyutlu vektörlerle çalışır. Kosinüs mesafe fonksiyonu, metinler arasındaki benzerlikleri hesaplamak için kullanılan en yaygın yöntemlerden biridir. Bu, veritabanımızın zaten kullanıma hazır olduğu anlamına gelir.
Plan veri yapısı
Verilerimizi içe aktarmadan önce, kaydetmek istediğimiz yapıya hızlıca bir göz atmakta fayda var. Vektör veritabanımızdaki her giriş birkaç bileşenden oluşacaktır:
- KIMLIK - benzersiz bir tanımlayıcı
- Yerleştirme - metnin vektörü
- Yük - Metin hakkında ek bilgiler
Yük, örneğin şunları içerebilir
- orijinal metin
- konuşmanın başlığı
- tarih
- diğer meta veriler
Örnek bir veri kaydı şu şekilde olabilir:
{
"id": 1,
"vector": [0.123, -0.452, 0.889, ...],
"payload": {
"text": "Wie kann ich meinen ChatGPT-Datenexport analysieren?",
"title": "Datenanalyse"
}
}
Bu yapının önemli bir avantajı vardır. Vektörler semantik arama için kullanılırken, yük daha sonra görüntülemek veya analiz etmek istediğimiz tüm bilgileri içerir. Bu da sistemimizin esnek kaldığı ve daha sonra kolayca genişletilebileceği anlamına geliyor.
Bu, altyapının en önemli kısmının zaten hazır olduğu anlamına geliyor. Qdrant sunucumuz çalışıyor, veritabanı kuruldu ve verilerimizin nasıl bir yapıya sahip olacağını biliyoruz. Bir sonraki bölümde, en önemli adımla başlıyoruz: ChatGPT verilerimizi veritabanına aktarıyoruz ve konuşma arşivimizi gerçek, aranabilir bir bilgi tabanına dönüştürüyoruz.
ChatGPT verilerini Qdrant'a aktarma
Önceki bölümde Qdrant installiert ve bir koleksiyon oluşturduğumuza göre, bilgi veritabanımız için teknik temel oluşturulmuş oldu. Yerleştirmelerimiz zaten mevcut - bunları ChatGPT verilerinden oluşturduk - ve Qdrant makinemizde bir veritabanı sunucusu olarak çalışıyor.
Şimdi en önemli adım geliyor: verilerimizi veritabanına yüklüyoruz. Yalnızca vektörleri değil, aynı zamanda ilişkili metinleri ve meta verileri de kaydediyoruz. Bu kombinasyon, yapay zekamızın daha sonra ilgili içeriği bulmasına ve cevaplarda kullanmasına olanak tanır. Bu bölümde, sistemimizin gerçek bilgi tabanını oluşturuyoruz.
Yerleştirmeleri kaydet
İlk olarak, oluşturduğumuz katıştırmaları veritabanına aktarmamız gerekiyor. Qdrant'taki her bir girdi üç bileşenden oluşur:
- bir kimlik
- bir vektör (gömme)
- ek veri içeren bir yük
Bizim durumumuzda, örneğin, yük şunları içerir
- metin bölümü
- konuşmanın başlığı
- Muhtemelen daha fazla meta veri
Python'da bu yapıyı nispeten kolay bir şekilde hazırlayabiliriz. Bir örnek:
points = []
for idx, item in enumerate(embeddings):
points.append({
"id": idx,
"vector": item["embedding"],
"payload": {
"text": item["text"],
"title": item["title"]
}
})Bu, daha sonra Qdrant'a kaydedebileceğimiz bir veri noktaları listesi oluşturur. Dolayısıyla her veri noktası bir metin bölümü, ilgili vektör ve ek bağlam bilgisi içerir. Bu yapı daha sonra anlamsal aramamızın temelini oluşturacaktır.
İçe aktarma komut dosyası oluşturma
Şimdi Python betiğimizi Qdrant'a bağlıyoruz ve verileri aktarıyoruz. Bunu yapmak için, önceki bölüm 1TP12'de analiz ettiğimiz Qdrant Python istemcisini kullanıyoruz. Örneğin içe aktarma şu şekilde görünebilir:
from qdrant_client import QdrantClient
from qdrant_client.models import PointStruct
client = QdrantClient("localhost", port=6333)
points = []
for idx, item in enumerate(embeddings):
point = PointStruct(
id=idx,
vector=item["embedding"],
payload={
"text": item["text"],
"title": item["title"]
}
)
points.append(point)
client.upsert(
collection_name="chatgpt_archive",
points=points
)
print("Import abgeschlossen:", len(points), "Datensätze gespeichert.")Upsert komutu, verilerin koleksiyona kaydedilmesini sağlar. Bir ID zaten mevcutsa, giriş güncellenir. Aksi takdirde, yeni bir veri kaydı oluşturulur. ChatGPT dışa aktarımınızın boyutuna bağlı olarak, bu içe aktarma birkaç saniye veya dakika sürebilir. Bu, birkaç bin metin bölümü gibi daha büyük veri setleri için tamamen normaldir.
Test veritabanı
İçe aktarma işlemi tamamlandıktan sonra, verilerimizin doğru kaydedilip kaydedilmediğini kontrol etmeliyiz. En basit test bir vektör araması gerçekleştirmektir. Bunu yapmak için, önce bir test sorusu için bir gömme oluştururuz.
query = "Wie kann ich ChatGPT-Daten analysieren?" query_vector = ollama.embeddings( model="nomic-embed-text", prompt=query )["embedding"]
Şimdi benzer vektörler için Qdrant'ta arama yapabiliriz.
search_result = client.search( collection_name="chatgpt_archive", query_vector=query_vector, limit=3 )
Bu komut, veritabanımızdan en benzer üç metin bölümünü döndürür. Bunların çıktısını örneğin şu şekilde alabiliriz:
for result in search_result:
print(result.payload["text"])
print("---")Her şey yolunda gittiyse, arşivinizdeki arama sorgusuyla eşleşen sohbet bölümleri artık görünecektir. Artık biliyoruz: Veritabanımız çalışıyor.
İlk performans değerlendirmesi
Bu an, tüm projenin en heyecan verici yönlerinden biridir. İlk kez, sohbet arşivimizin aslında bir bilgi kaynağı olarak kullanılabileceği ortaya çıkıyor. Artık farklı arama sorgularını deneyebilirsiniz. Örneğin:
- „Yapay zeka makalesi“
- „RAG Sistemi“
- „ChatGPT veri aktarımı“
- „Strateji fikri“
Sohbet geçmişinizin içeriğine bağlı olarak, Qdrant uygun metin pasajları bulacaktır. Bazen hangi içeriğin yeniden ortaya çıktığına şaşıracaksınız. Uzun zamandır unuttuğunuz sohbetler aniden tekrar alakalı hale gelebilir. Bu, böyle bir yaklaşımın neden bu kadar ilginç olduğunu çok açık bir şekilde göstermektedir. Eski yapay zeka konuşmalarınız artık sadece bir arşiv değildir. Aranabilir bir bilgi tabanı haline gelirler.
Böylece önemli bir dönüm noktasına ulaştık. ChatGPT verilerimiz artık tamamen vektör veritabanında saklanıyor ve semantik olarak aranabiliyor. Bir sonraki bölümde, bir adım daha ileri gidiyoruz: bilgi veritabanımızı yapay zekanın kendisine bağlıyoruz. Bu, dil modelinin gelecekte bu verilere erişmesini ve bunları doğrudan yanıtlara dahil etmesini sağlayacaktır.
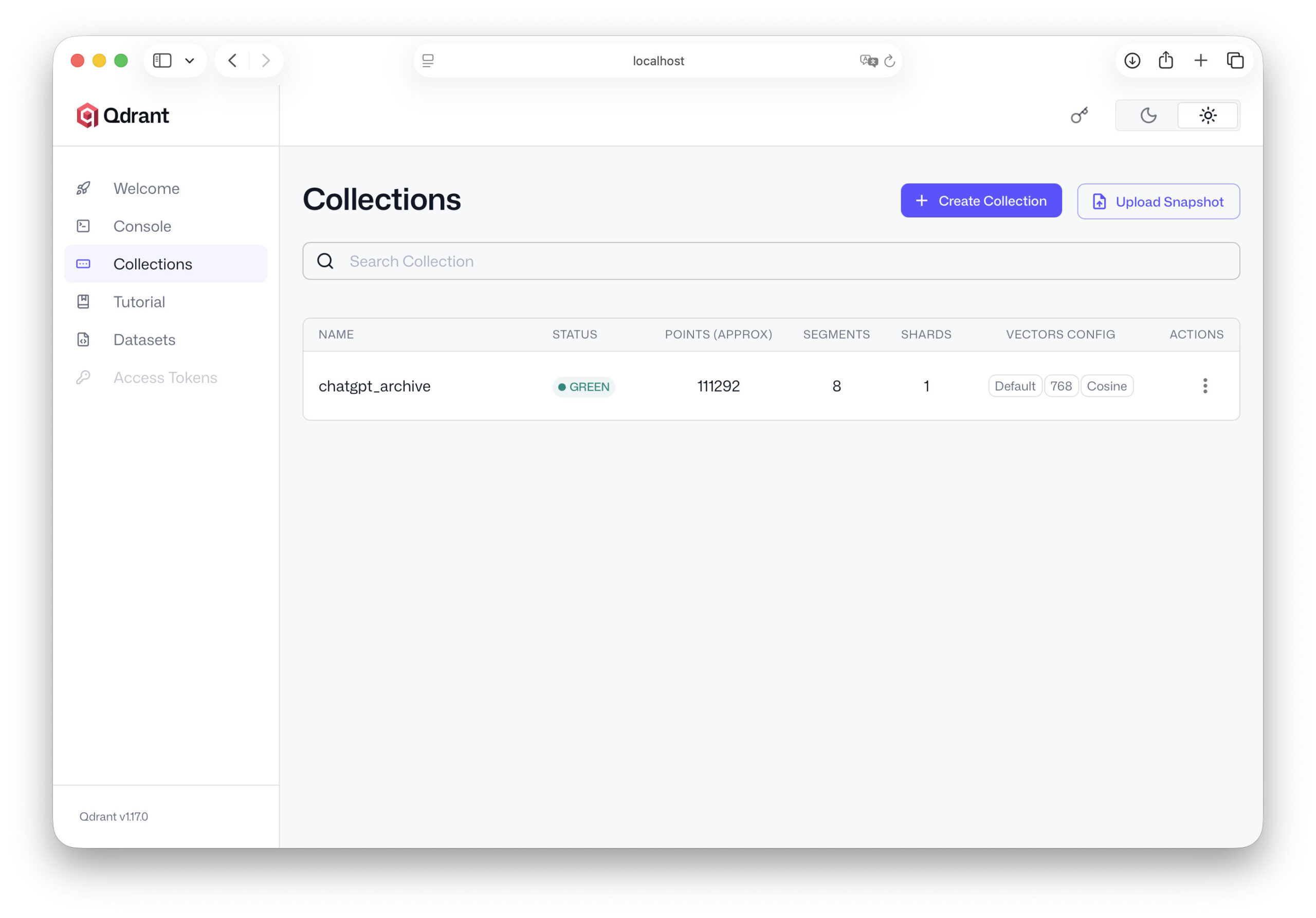
Yapay zekayı bilgi veritabanına bağlama
Bu noktaya kadar, altyapının büyük bir kısmını zaten inşa etmiştik. ChatGPT verilerimiz dışa aktarımdan çıkarıldı, daha küçük metin bölümlerine ayrıldı, gömüldü ve son olarak Qdrant vektör veritabanında saklandı.
Ancak, yapay zekamız henüz bu verilerle çalışmıyor. Python kullanarak bir vektör araması yapabilmemize ve uygun metin pasajlarını bulabilmemize rağmen, YZ'nin kendisi henüz bunun farkında değil. Ona bir soru sorduğumuzda, hala sadece genel dil bilgisini kullanıyor.
Bu nedenle bir sonraki adım bu iki dünyayı birbirine bağlamaktır. Şimdi yapay zekanın önce bilgi veritabanından ilgili içeriği aldığı ve ardından bunu yanıtına dahil ettiği bir süreç inşa ediyoruz. Bu tam olarak bir RAG sisteminin özüdür.
Soruşturma süreci
Bilgi sistemimiz sayesinde bir sorgulama süreci biraz değişiyor. Şimdiye kadar, bir yapay zeka ile konuşma genellikle şu şekilde gerçekleşiyordu:
- Sen bir soru sor →
- Yapay zeka soruyu işler →
- yapay zeka bir cevap üretir.
Bilgi veritabanı ek bir adımdır. Yeni süreç şu şekildedir:
- Sen bir soru sor →
- soru bir gömüye dönüştürülür →
- vektör veritabanı benzer metinleri arar →
- Bu metinler YZ'ye bağlam olarak aktarılır →
YZ bir cevap formüle eder. Bu, YZ'nin artık yalnızca eğitimli bilgisiyle değil, aynı zamanda kendi verilerinizle de çalıştığı anlamına gelir. Bu bağlam genellikle yanıtların çok daha kesin ve kişiselleştirilmiş olmasını sağlar.
Geri alma adımı
Bu sürecin ilk kısmı geri alma olarak bilinir. Retrieval basitçe „geri getirme“ anlamına gelir. Bu adımda, sistemimiz veritabanında sorunun konusuyla eşleşen içeriği arar. İlk olarak, mevcut soru için başka bir gömme oluşturuyoruz.
query = "Welche Ideen hatte ich zur Nutzung meines ChatGPT-Datenexports?" query_vector = ollama.embeddings( model="nomic-embed-text", prompt=query )["embedding"]
Bu gömme, sorunun anlamını matematiksel biçimde tanımlar. Qdrant artık benzer vektörleri arayabilir.
results = client.search( collection_name="chatgpt_archive", query_vector=query_vector, limit=5 )
Veritabanı şimdi soruyla en iyi eşleşen beş metin pasajını döndürür. Bu metin pasajları yapay zeka için bağlamı oluşturur. Bunları bir listede topluyoruz.
context_texts = [] for r in results: context_texts.append(r.payload["text"])
Artık sohbet arşivimizden ilgili içeriklerden oluşan bir koleksiyonumuz var.
Bağlamı Ollama'ye aktarın
Şimdi belirleyici adım geliyor. Bu bağlamı orijinal soruyla birlikte dil modelimize aktarıyoruz. Model artık bu bilgiyi bir cevap formüle etmek için kullanabilir.
İlk olarak, sözde bir komut istemi oluşturuyoruz. Komut istemi basitçe yapay zekaya gönderdiğimiz metindir.
context = "\n\n".join(context_texts)
prompt = f"""
Du bist ein KI-Assistent, der mit meinem persönlichen Wissensarchiv arbeitet.
Nutze die folgenden Textausschnitte als Kontext:
{context}
Beantworte nun diese Frage:
{query}
"""Şimdi bu istemi Ollama'deki dil modelimize gönderiyoruz.
response = ollama.chat(
model="llama3",
messages=[
{"role": "user", "content": prompt}
]
)
print(response["message"]["content"])Yapay zeka şimdi veritabanımızdan hem soruyu hem de ilgili metin pasajlarını alıyor. Bu, kendi verilerimize dayalı yanıtlar üretmesini sağlar.
Yanıt oluşturma
Son adım ise gerçek cevap üretimidir. Dil modeli artık iki bilgi kaynağını birleştirmektedir:
kendi eğitimli bilgisi
bilgi veritabanımızdan gelen bağlam
Bu kombinasyon özellikle güçlüdür. Model, genel ilişkileri açıklayabilir ve aynı zamanda arşivimizden belirli içerikleri dahil edebilir. Bir örnek: Eğer sorarsanız:
„ChatGPT veri aktarımımı kullanmak için ne gibi fikirlerim vardı?“
Yapay zeka artık önceki konuşmalara erişebilir ve bunlardan yapılandırılmış bir özet oluşturabilir. Örneğin, cevap verebilir:
- Kişisel bir bilgi arşivi oluşturmaktan bahsettiniz.
- Bir RAG sistemi ile yerel bir yapay zeka geliştirmek istediniz
- Bir dizi makale fikri geliştirdiniz
Geri alma adımı olmasaydı, yapay zeka bu bilgileri hiç bilemeyecekti. Sistemimiz sayesinde sohbet arşiviniz gerçek bir bilgi kaynağı haline geliyor. Bu, sistemimizin en önemli kısmını tamamlıyor. Artık elimizde:
- Ollama aracılığıyla yerel bir AI
- sohbet verilerimizi içeren bir vektör veritabanı
- semantik bir arama
- bir RAG iş akışı
Bir sonraki bölümde, bu sistemi pratikte test edeceğiz ve kişisel bilgi yapay zekamızın gerçekte ne kadar iyi çalıştığını göreceğiz.
Kişisel bilginizle ilk sorgular Yapay Zeka
Önceki bölümde YZ ile bilgi veritabanı arasındaki bağlantıyı kurduğumuza göre, sistem teknik olarak tamamlanmıştır. ChatGPT verilerimiz vektör veritabanındadır, YZ ilgili içeriği alabilir ve bir RAG sisteminin tüm süreci çalışır.
Şimdi projenin en heyecan verici kısmı geliyor: ilk gerçek sorgular. Çünkü ancak şimdi sistemimizin gerçekten umduğumuz şeyi yapıp yapmadığını görebiliriz - yani önceki konuşmaları bulabilir, içeriği analiz edebilir ve anlamlı yanıtlar üretebiliriz. Bu bölümde, bilgi yapay zekamızı test ediyor, tipik kullanım durumlarına bakıyor ve olası optimizasyonlara göz atıyoruz.
Örnek sorgular
Bazı basit sorularla başlayalım. Sohbet arşivinizde olduğunu bildiğiniz soruları sorarak başlamak iyi bir stratejidir. Örneğin:
„ChatGPT veri aktarımımı kullanmak için ne gibi fikirlerim vardı?“
„RAG sistemleri hakkında ne yazmışım?“
„Yapay zekayı kullanmak için hangi stratejileri tartıştım?“
Bu sorular kasıtlı olarak açık formülasyonlar içermektedir. Amaç belirli bir metni bulmak değil, tematik olarak uygun içeriği keşfetmektir. Sisteminize böyle bir soru sorduğunuzda, bir önceki bölümde kurguladığımız süreç arka planda gerçekleşir:
- Soru bir gömme haline dönüştürülür.
- Vektör veritabanı benzer metin bölümlerini arar.
- Bu metin pasajları yapay zekaya bağlam olarak aktarılır.
- Yapay zeka bu bağlama göre bir cevap üretir.
Sonuç şaşırtıcı olabilir. Uzun zamandır unuttuğunuz konuşmalar sık sık ortaya çıkar. Eski fikirler aniden ekranda yeniden belirir - hatta bazen tamamen yeni bir bağlamda.
Bu yaklaşımın gücü de tam olarak budur. Sohbet arşiviniz aranabilir bir bilgi kaynağı haline gelir.
Cevapların kalitesi
Birkaç sorgu denerseniz, cevapların kalitesinin değişebileceğini fark edeceksiniz. Bu tamamen normaldir. Böyle bir sistemin kalitesi çeşitli faktörlere bağlıdır. Önemli faktörlerden biri metin parçalarının boyutudur. Eğer bölümler çok büyükse, birkaç konu içerebilirler. Bu da aramayı daha az doğru yapar.
Ancak, parçalar çok küçükse, gerekli bağlam bazen eksik olabilir. Bir başka faktör de gömme modelidir. Farklı modeller anlam bağlamlarını farklı şekilde tanır. Bazıları özellikle teknik metinler için uygunken, diğerleri genel dil için uygundur.
Alınan sonuçların sayısı da bir rol oynar. Örneğin, yalnızca iki metin pasajı alırsanız, önemli bilgiler eksik olabilir. Öte yandan, çok fazla metin yüklenirse, yapay zeka ilgili bağlamı tanımakta zorluk çekebilir.
Bu parametreler daha sonra kolayca ayarlanabilir. Her şeyden önce en önemli şey işleyen bir temel sisteme sahip olmaktır.
Tipik sorunlar
Her teknik sistemde olduğu gibi burada da bazı zorluklar ortaya çıkabilir. Yaygın bir sorun, veritabanının yalnızca kısmen alakalı olan metinleri bulmasıdır. Bunun nedeni semantik aramanın her zaman olasılıklarla çalışmasıdır.
Metinler çok fazla parçalanmışsa başka bir sorun ortaya çıkabilir. Bir düşünce birkaç parçaya yayılmışsa, yapay zeka bağlamı tanımakta zorluk çekebilir.
Komut istemi de bir rol oynar. Komut istemi net değilse, YZ bağlamı optimum şekilde kullanamayabilir. Daha iyi bir komut istemi örneği şöyle olabilir:
Bilgi arşivimden aşağıdaki metin alıntılarını kullanın,
Soruyu mümkün olduğunca kesin bir şekilde yanıtlamak için.
İlgili içerik mevcutsa, özetleyin.
Bu tür küçük ayarlamalar cevapların kalitesini önemli ölçüde artırabilir.
İnce ayar
Sistem temel olarak çalışır çalışmaz, en ilginç kısım başlar: ince ayar. Burada bilgi sisteminizi adım adım deneyebilir ve geliştirebilirsiniz. Bazı tipik optimizasyonlar şunlardır
- Yığın boyutunu ayarlama
Bazen metnin daha küçük bölümleri daha iyi sonuçlar sağlar. Diğer durumlarda, daha fazla bağlam yararlıdır. - Farklı bir gömme modeli kullanımı
Modelin değiştirilmesi anlamsal aramanın kalitesini önemli ölçüde artırabilir. - Yapay zeka için daha fazla bağlam
Veritabanından daha fazla sonuç alabilirsiniz, örneğin beş yerine on metin pasajı. - Meta verileri kullanın
Tarih veya arama başlığı gibi ek bilgileri kaydederseniz, aramayı daha sonra daha hassas bir şekilde filtreleyebilirsiniz.
Bu ayarlamalar her gerçek RAG sisteminin bir parçasıdır. Tüm durumlar için nadiren mükemmel bir ayar vardır. Ancak bu tür sistemlerin cazibesi de tam olarak budur: sürekli olarak geliştirilebilirler.
Bu bölümle birlikte sistemimizin ilk tam testini gerçekleştirmiş olduk. Kişisel bilgi yapay zekamızın gerçekten de eski konuşmalar arasında arama yapabildiğini ve ilgili içeriği geri getirebildiğini gördük.
Bu, projemizin özünün zaten başarılmış olduğu anlamına geliyor. Ancak sistem hala önemli ölçüde genişletilebilir. Bu nedenle bir sonraki bölümde, ek veri kaynaklarını nasıl entegre edebileceğinizi ve kişisel bilgi arşivinizi adım adım nasıl genişletebileceğinizi inceleyeceğiz.



Kişisel yapay zeka bilgi sisteminiz için uzantılar
Önceki kurulumla zaten işleyen bir sistem oluşturdunuz. ChatGPT verileriniz çıkarıldı, gömülmelere dönüştürüldü, Qdrant'ta depolandı ve son olarak yerel bir yapay zekaya bağlandı. Sonuç, önceki konuşmalara erişebilen bir bilgi yapay zekasıdır.
Ancak açık konuşmak gerekirse, daha işin başındayız. Oluşturduğunuz mimari ChatGPT verileriyle sınırlı değil. Her türlü metinle çalışır. Belgelere veya metin dosyalarına dönüştürülebilen her şey bu bilgi sisteminin bir parçası olabilir. Bu tür sistemlerin gerçek potansiyeli burada yatmaktadır.
Temelde inşa ettiğimiz şey kişisel bir bilgi makinesidir. Ve bu makine adım adım genişletilebilir. Bu bölümde, bundan doğan olasılıklara ve sisteminizi uzun vadede nasıl genişletebileceğinize bakacağız.
Ek veri kaynaklarını entegre edin
Bir sonraki en belirgin adım, bilgi tabanınıza daha fazla içerik eklemektir. ChatGPT konuşmaları iyi bir başlangıçtır, ancak genellikle kendi bilginizin yalnızca bir kısmını temsil ederler. Birçok bilgi diğer formatlarda mevcuttur. Örneğin:
- kendi makaleleri
- Notlar
- PDF belgeleri
- Araştırma belgeleri
- E-Kitaplar
- Protokoller veya fikir listeleri
Tüm bu içerik, sohbet verilerimizle aynı şekilde işlenebilir. Süreç aynı kalır:
- Metin çıkarma
- Metni parçalara ayırma
- Yerleştirmeler oluşturun
- Qdrant'ta veri kaydetme
Bir örnek: Kendi makalelerinizin çoğunu yazdıysanız, bu metinleri bilgi veritabanınıza aktarabilirsiniz. Yapay zeka bunlara daha sonra erişebilir ve korelasyonları tanıyabilir. Örneğin, şunu sorabilirsiniz:
„Yapay zeka hakkında hangi makaleleri yazdım?“
veya
„Geçmişte bu konuda hangi argümanları geliştirdim?“
Yapay zeka daha sonra makale arşivinizi arar ve bulduğu içeriği bağlam olarak kullanır. Bu şekilde sisteminiz adım adım büyüyerek kapsamlı bir bilgi arşivine dönüşür.
Çeşitli bilgi veritabanları
Veri miktarı arttıkça, farklı alanları ayırmak faydalı olabilir. Qdrant birden fazla koleksiyon oluşturmanıza olanak tanır. Her koleksiyon kendi bilgi tabanını temsil edebilir. Örneğin olası bir sistem şöyle görünebilir:
- Koleksiyon 1ChatGPT konuşmaları
- Koleksiyon 2: Makale arşivi
- Koleksiyon 3: kişisel notlar
- Koleksiyon 4Teknik dokümantasyon
Bu ayrımın çeşitli avantajları vardır. İlk olarak, yapı net kalır. Belirli içeriklerin nerede depolandığını her zaman bilirsiniz. İkinci olarak, sorgular daha spesifik olarak kontrol edilebilir. Bazı sorular yalnızca makale arşivinizi, bazıları ise tüm bilgi sisteminizi aramalıdır. Bir örnek:
- Bir araştırma sorusu yalnızca makale arşivinde arama yapabilir.
- Öte yandan stratejik bir soru, tüm koleksiyonları aynı anda dikkate alabilir.
Bu tür yapılar, daha büyük bilgi sistemlerini önemli ölçüde daha verimli hale getirir.
Otomatik güncellemeler
Bir diğer faydalı adım da sisteminizi düzenli olarak güncellemektir. Önceki örnekte ChatGPT veri aktarımını bir kez işledik. Ancak pratikte sürekli olarak yeni içerikler oluşturulmaktadır.
Yeni konuşmalar, yeni notlar, yeni belgeler - tüm bu bilgiler de bilgi arşivinizin bir parçası haline gelebilir.
Bu nedenle otomatik güncellemeler hakkında düşünmeye değer. Basit bir çözüm, düzenli olarak yeni verileri içe aktarmaktır. Örneğin:
- Haftada bir kez yeni sohbet verilerini işleyin
- Yeni belgeleri otomatik olarak içe aktarma
- Veri tabanına hemen yeni makaleler ekleyin
Teknik olarak bunu uygulamak nispeten kolaydır. Küçük bir komut dosyası düzenli olarak yeni dosyaların mevcut olup olmadığını kontrol edebilir ve bunları otomatik olarak işleyebilir. Bu, bilgi sisteminizin sürekli olarak büyümesini sağlar. Zaman içinde, düşüncelerinizi ve projelerinizi belgeleyen daha kapsamlı bir arşiv oluşturulur.
Kendi uygulamalarınıza entegrasyon
Şimdiye kadar sistemimiz basit Python betikleri aracılığıyla kullanıldı. Ancak uzun vadede bu sistem kendi uygulamalarınıza da entegre edilebilir. Örneğin, birçok geliştirici, bilgi yapay zekasını doğrudan kullanmalarına olanak tanıyan küçük web arayüzleri oluşturuyor.
Bir komut dosyası başlatmak yerine, bir giriş alanına basitçe bir soru yazabilirsiniz. Aynı işlem arka planda çalışır:
- Yerleştirme oluşturun
- Veritabanında arama
- Bağlamı yapay zekaya aktarın
- Yanıt oluştur
Sonuç daha sonra doğrudan kullanıcı arayüzünde görünür. Böyle bir uygulama çok farklı şekillerde olabilir. Örneğin:
- kişisel bir araştırma yapay zekası
- projeler için bir bilgi asistanı
- bir fikir arama motoru
- makaleler ve notlar için bir arşiv
Bu sistemleri diğer araçlarla birleştirdiğinizde özellikle heyecan verici hale gelir. Örneğin, bir editoryal sistem bilgi arşivinize otomatik olarak erişebilir ve önceki makaleleri araştırma için bir temel olarak kullanabilir. Ya da bir not sistemi yeni fikirleri otomatik olarak veri tabanınıza entegre edebilir.
Başka bir deyişle, yapay zeka günlük çalışma ortamınızın bir parçası haline gelir. Bu, küçük projemizin orijinal ChatGPT veri aktarımının çok ötesine geçtiğini açıkça ortaya koyuyor.
Biz sadece bir arşiv oluşturmadık. Gerektiğinde genişletilebilecek bir mimari yarattık. İşte bu tür sistemlerin gerçek değeri de tam olarak burada yatıyor. Statik değildirler. Bilginizle birlikte büyürler.
İndirmek için boru hattının genişletilmiş versiyonu
Aşağıdaki komut dosyası, makaledeki boru hattının genişletilmiş bir versiyonudur. Daha sağlamdır ve üretken bir çözüme çok daha yakındır. Üç şey geliştirilmiştir:
- İlerleme göstergesiKullanıcı istediği zaman kaç metnin işlenmiş olduğunu görebilir.
- Toplu içe aktarmaGömüler bloklar halinde toplanır ve Qdrant'a yazılır, bu da tek tek içe aktarımlardan önemli ölçüde daha hızlıdır.
- Daha hızlı gömme işlem hattıKod, hazırlanmış parçalarla yapılandırılmış bir şekilde çalışır ve gereksiz çağrıları azaltır.
Bu nedenle bu komut dosyası, ChatGPT dışa aktarımı daha büyükse (örneğin birkaç bin konuşma) özellikle uygundur. Tipik süreç:
- ChatGPT dışa aktarımını yükle
- Alıntı metinler
- Metni parçalara ayırma
- Yerleştirmeler oluşturun
- Qdrant'a toplu içe aktarma
- Test sorgusu gerçekleştirin
Komut dosyasındaki önemli ayarlar
Bazı değerler kullanıcı tarafından ayarlanmalıdır:
- EXPORT_PFAD
ChatGPT dışa aktarımından çoğunlukla numaralandırılmış conversations.json dosyalarının yolu. - COLLECTION_NAME
Vektör veritabanı koleksiyonunun adı. - EMBED_MODELİ
Ollama'nin gömme modeli, örneğin nomic-embed-text veya mxbai-embed-large - ANSWER_MODEL
Test sorgusu için dil modeli, örneğin llama, mistral veya gpt:oss - VECTOR_SIZE
Gömme modelinin boyutu.
nomic-embed-text → 768
mxbai-embed-large → 1024 - CHUNK_SIZE
Metin bölümlerinin boyutu.
Tipik olarak 300-600 kelime. - BATCH_SIZE
Qdrant'a aynı anda kaç tane gömme yazılır.
Tipik değer: 50-200.
Güncel kalın - reklamsız
Bu betikteki güncellemelerden veya yeni indirmelerden haberdar olmak istiyorsanız, aylık bültenime abone olabilirsiniz. Bülten kasıtlı olarak yalın tutulmuştur, tamamen reklamsızdır ve ayda yalnızca bir kez yayınlanır. İçinde en önemli yeni makalelerden bir seçki, yapay zeka, yazılım ve dijitalleşme hakkında pratik içeriklerin yanı sıra güncellenmiş komut dosyaları veya yeni indirme teklifleri hakkında bilgiler bulacaksınız. Spam yok, günlük e-posta yok - sadece kompakt formda en alakalı içerik. Bu gelişmeleri sürekli takip etmek istiyorsanız, haber bülteni güncel kalmanın en kolay yoludur.
Bölüm 3 için görünüm: Veri kullanımında ince ayar, analiz ve optimizasyon
Serinin üçüncü bölümünde bir adım daha ileri gidiyor ve oluşturduğunuz bilgi veritabanından gerçekte neler elde edebileceğinize bakıyoruz. Artık ChatGPT verileri Qdrant'ta depolandığına göre, odak noktası gerçek kullanımıdır. Qdrant web arayüzüne bir göz atıyoruz, depolanan verileri analiz ediyoruz ve semantik aramanın ne kadar iyi çalıştığını kontrol ediyoruz. Ayrıca önemli ince ayarlara da bakıyoruz: Kullanım durumuna bağlı olarak yığınlama nasıl seçilmelidir? Bağlam yerel bir dil modeline en iyi şekilde nasıl aktarılabilir? Ve cevapların kalitesi özellikle nasıl iyileştirilebilir? Üçüncü bölüm, sistemden daha fazla yararlanmak ve onu bilinçli olarak daha da geliştirmek isteyen herkese yöneliktir.




Sıkça sorulan sorular
- ChatGPT veri aktarımımı kendi yapay zekama entegre etmenin amacı nedir?
En büyük avantajı, kendi konuşmalarınızı ve düşüncelerinizi uzun vadede kullanabilmenizdir. Birçok insan yapay zeka sistemleriyle projeler, fikirler, analizler veya kişisel konular hakkında yoğun görüşmeler yapar. Bu içerik normalde platform boyunca kaybolur. Ancak, bu içeriği dışa aktarır ve kendi bilgi veritabanınıza entegre ederseniz, kişisel bir arşiv haline gelir. Yerel yapay zekanız daha sonra bu içeriğe erişebilir, korelasyonları tanıyabilir ve yeni sorularda size yardımcı olabilir. Her zaman sıfırdan başlamak yerine, kendi düşüncenizi adım adım geliştirirsiniz. - Geliştirici olmayan biri için bu çok karmaşık değil mi?
İlk bakışta gömme, vektör veritabanları veya RAG sistemleri gibi terimler karmaşık görünmektedir. Ancak pratikte, bireysel adımlar nispeten net bir şekilde yapılandırılmıştır. Temelde yalnızca üç bileşene ihtiyacınız vardır: yerel bir AI (örneğin Ollama aracılığıyla), Qdrant gibi bir vektör veritabanı ve verilerinizi işleyen küçük bir Python betiği. Adımların çoğu otomatiktir. Sistem bir kez kurulduktan sonra normal bir arama motoru ya da sohbet robotu gibi çalışır - tek farkı kendi bilginizle çalışmasıdır. - ChatGPT dışa aktarımı gerçekte hangi verileri içerir?
ChatGPT dışa aktarımı genellikle sistemle yaptığınız tüm konuşmaları içerir. Bu yalnızca metin mesajlarını değil, aynı zamanda konuşma başlıkları, zaman damgaları ve yapısal bilgiler gibi meta verileri de içerir. Veriler genellikle JSON formatında mevcuttur ve bu nedenle komut dosyalarıyla nispeten kolay bir şekilde işlenebilir. Çoğu durumda dışa aktarım, konuşmalarda kullanılmışsa medya veya dil dosyalarını da içerir. Bununla birlikte, bir bilgi veritabanı oluştururken esas olarak metin içeriği ilgi çekicidir. - Neden bu tür sistemler için normal bir veritabanı değil de bir vektör veritabanı kullanılıyor?
Normal veritabanları belirli terimleri veya kimlikleri aramak için idealdir. Ancak anlamsal aramalar için daha az uygundurlar. Bir vektör veritabanı, metinleri yalnızca karakter dizeleri olarak değil, aynı zamanda bir metnin anlamını tanımlayan matematiksel vektörler olarak da depolar. Bu, sistemin içerikte benzerlik aramasına olanak tanır. Örneğin, „yapay zeka makale fikirleri“ sorarsanız, veritabanı „yapay zeka üzerine blog makaleleri için konular“ gibi diğer ifadeleri içeren içeriği de bulabilir. - Yerleştirmeler nedir ve neden bu kadar önemlidir?
Gömüler, metinlerin matematiksel temsilleridir. Bir dil modeli bir metni, metnin anlamını tanımlayan bir sayı listesine dönüştürür. Benzer anlamlara sahip metinler matematiksel uzayda birbirine yakın durur. Bu, bir vektör veritabanının daha sonra benzer içerikleri aramasını sağlar. Gömüler olmadan anlamsal arama yapmak pek mümkün olmazdı. Modern RAG sistemlerinin temelini oluştururlar ve bu tür sistemlerin klasik tam metin aramalardan çok daha esnek olmasının nedenidirler. - ChatGPT veri dışa aktarımım ne kadar büyük olabilir?
Boyut önemli bir rol oynamaz. Birkaç bin konuşma bile sorunsuz bir şekilde işlenebilir. Daha önemli olan, oluşturulan metin bölümlerinin, yani parçaların sayısıdır. Daha büyük bir dışa aktarım daha fazla parçaya ve dolayısıyla daha fazla gömülmeye yol açar. Bununla birlikte, modern vektör veritabanları bu tür milyonlarca girişi kolayca yönetebilir. Küçük bir sunucu veya güçlü bir masaüstü bile özel bir bilgi asistanı için tamamen yeterlidir. - Metin işlenmeden önce neden küçük bölümlere ayrılmıştır?
Konuşmaların tamamını veya büyük metinleri doğrudan gömme olarak kaydederseniz, anlamsal arama kesin olmaz. Tek bir metin birkaç konu içerebilir. Daha küçük bölümlere ayırarak, sistem daha sonra çok daha hassas bir şekilde arama yapabilir. Her bölüm daha net bir konuyu tanımlar. Bu, veritabanının bir konuşmanın mevcut soruya gerçekten uyan kısımlarını tam olarak bulmasını sağlar. - Ollama bu sistemde nasıl bir rol oynamaktadır?
Ollama, dil modelleri için yerel bir platform görevi görür. Yapay zeka modellerini doğrudan kendi bilgisayarınızda çalıştırmanıza olanak tanır. Sistemimizde, Ollama iki görevi yerine getirir: Metinler için yerleştirmeler oluşturur ve sorulara yanıtlar üretir. Avantajı, tüm verilerin yerel kalmasıdır. Bu, konuşmalarınızın ve bilgi arşivinizin asla kendi bilgisayarınızdan çıkmayacağı anlamına gelir. - Qdrant neden bir vektör veritabanı olarak kullanılıyor?
Qdrant, yapay zeka uygulamaları için özel olarak geliştirilmiş modern bir vektör veritabanıdır. Hızlıdır, installieren'i kolaydır ve çok iyi belgelenmiştir. Ayrıca Python'a ve birçok yapay zeka çerçevesine kolayca bağlanabilir. Qdrant bu nedenle yerel bilgi sistemleri için özellikle pratik bir çözümdür. Alternatifleri arasında Chroma, Weaviate veya Pinecone bulunmaktadır. - RAG sistemi terimi ne anlama geliyor?
RAG, „Retrieval-Augmented Generation“ anlamına gelmektedir. Bu, bir YZ'nin önce bir veritabanından ilgili bilgileri aldığı ve daha sonra bir cevap oluşturmak için kullandığı bir mimaridir. YZ böylece kendi bilgisini harici verilerle birleştirir. Bu, çok kesin yanıtlar vermesini ve aynı zamanda güncel veya kişisel bilgilere erişmesini sağlar. - Diğer veri kaynaklarını da bu sisteme entegre edebilir miyim?
Aslında bu mimarinin en büyük avantajlarından biri de budur. Sistem ChatGPT verileriyle sınırlı değildir. Kendi makalelerinizi, notlarınızı, PDF'lerinizi, araştırma kağıtlarınızı veya diğer belgelerinizi de entegre edebilirsiniz. İçerik metin biçiminde işlenebildiği sürece bilgi tabanının bir parçası haline gelebilir. Zamanla sisteminiz kapsamlı bir bilgi arşivine dönüşecektir. - Böyle bir bilgi sistemi ne kadar güncel kalabilir?
Güncelliği, yeni verileri ne sıklıkta içe aktardığınıza bağlıdır. Örneğin, yeni ChatGPT dışa aktarımlarını düzenli olarak işleyebilir veya yeni belgeleri otomatik olarak tanıyan bir komut dosyası oluşturabilirsiniz. Birçok sistem haftada bir veya ayda bir güncellenecek şekilde ayarlanmıştır. Bu, bilgi tabanının her zaman güncel kalmasını sağlar. - Böyle bir sistem için hangi donanıma ihtiyacım var?
Küçük projeler için modern bir masaüstü bilgisayar yeterlidir. Daha büyük bir dil modeli kullanmak istiyorsanız, bir GPU yardımcı olabilir. Bununla birlikte, birçok kullanıcı bilgi sistemlerini güçlü bir dizüstü bilgisayar veya mini sunucu üzerinde de başarıyla çalıştırmaktadır. Her şeyden önce, veritabanı için yeterli belleğe ve yeterli depolama alanına sahip olmak önemlidir. - Böyle bir sistem pratikte ne kadar hızlı çalışır?
Hız, veritabanının boyutu, donanım ve kullanılan dil modeli gibi çeşitli faktörlere bağlıdır. Çoğu durumda, bir sorgu yalnızca birkaç saniye sürer. Vektör aramasının kendisi genellikle son derece hızlıdır. Zamanın en büyük kısmı genellikle dil modelinden yanıt üretmek için harcanır. - Çeşitli bilgi alanlarını ayırmak mümkün mü?
Evet, Qdrant gibi vektör veritabanları birden fazla koleksiyonun kullanılmasına izin verir. Her koleksiyon ayrı bir konu alanını temsil edebilir. Örneğin, ChatGPT konuşmaları için bir koleksiyon, makaleler için bir koleksiyon ve notlar için bir koleksiyon oluşturabilirsiniz. Bu, bilgi alanlarının net bir şekilde yapılandırılmasına ve hedefli bir şekilde aranmasına olanak tanır. - Yerel bir AI sistemindeki verilerim ne kadar güvende?
Yerel bir sistemin en büyük avantajı, verilerinizin harici hizmetlere aktarılmak zorunda olmamasıdır. Tüm bilgiler kendi bilgisayarınızda veya sunucunuzda kalır. Bu özellikle hassas içerikler için ilgi çekicidir. Elbette yine de düzenli yedeklemeler oluşturmalı ve sisteminizi yetkisiz erişime karşı korumalısınız. - Bu sistemi kendi uygulamalarıma da entegre edebilir miyim?
Evet, çoğu bileşene programlama arayüzleri aracılığıyla erişilebilir. Bu, bilgi sisteminizi kendi araçlarınıza, örneğin bir web arayüzüne, bir editoryal sisteme veya bir not uygulamasına entegre etmenize olanak tanır. Birçok geliştirici, bilgi veritabanlarını bir sohbet arayüzü aracılığıyla doğrudan erişilebilir hale getiren küçük uygulamalar oluşturur. - Bu teknoloji gelecekte nasıl gelişebilir?
Kişisel bilgi yapay zekaları muhtemelen gelişimlerinin sadece başlangıcındadır. Gelecekte bu tür sistemler yeni içerikleri otomatik olarak entegre edebilir, özetler oluşturabilir ve hatta projeler için kendi önerilerini sunabilir. Böyle bir sisteme ne kadar çok veri akarsa, o kadar değerli hale gelir. Uzun vadede, bilginizi yapılandıran ve istediğiniz zaman erişilebilir kılan bir tür kişisel dijital hafızaya dönüşebilir.