De wereld van kunstmatige intelligentie is in beweging. Bijna elke week duiken er nieuwe modellen, nieuwe methoden en vooral nieuwe mogelijkheden op - en toch blijft één besef constant: niet elke technische innovatie leidt automatisch tot een beter dagelijks leven. Veel dingen blijven experimenteel, complex of gewoon te duur voor productief gebruik. Dit is vooral duidelijk bij de zogenaamde fine-tuning van grote taalmodellen - een methode om generatieve AI te specialiseren naar eigen inhoud, termen en toonaarden.
Ik heb dit proces de afgelopen maanden intensief begeleid - eerst in de klassieke vorm, met Python, terminal, foutmeldingen en zenuwslopende instellussen. En toen: met FileMaker 2025, een stap die me verraste - omdat het niet luid was, maar duidelijk. En omdat het liet zien dat er een andere manier is.
In een gedetailleerd Gespecialiseerde artikelen over gofilemaker.de Ik heb precies deze verandering gedocumenteerd: de overgang van een open, flexibele maar instabiele PEFT-LoRA-training (bijvoorbeeld met Axolotl, LLaMA-Factory of kohya_ss) naar de geïntegreerde oplossing van Claris - via een script, lokaal, traceerbaar.



Wat is LoRA eigenlijk - en waarom is het zo belangrijk?
LoRA staat voor Low-Rank Adaptation. Achter deze technisch klinkende term gaat een eenvoudig maar krachtig principe schuil: in plaats van een heel AI-model opnieuw te trainen, worden alleen heel specifieke onderdelen aangepast - met behulp van zogenaamde adaptergewichten, die worden ingevoegd en gericht worden getraind. In de afgelopen jaren heeft deze methode zich gevestigd als de gouden standaard voor domeinspecifieke fijnafstemming, omdat er weinig rekenkracht voor nodig is en het toch uitstekende resultaten oplevert.
De klassieke aanpak vereist een arsenaal aan hulpmiddelen:
- een werkende Python-omgeving,
- geschikte CUDA- en PyTorch-versies,
- een trainingsengine zoals Axolotl of kohya_ss,
- GPU-bronnen om het geheel aan te kunnen,
- en last but not least: Geduld. Heel veel geduld.
Tussen YAML-bestanden, tokeniserconflicten en formaatconversies (van safetensors naar GGUF naar MLX en terug) duurt het vaak dagen voordat een bruikbaar resultaat is bereikt. Het werkt - maar het is niet iets om als bijbaantje te doen.
En toen kwam FileMaker 2025.
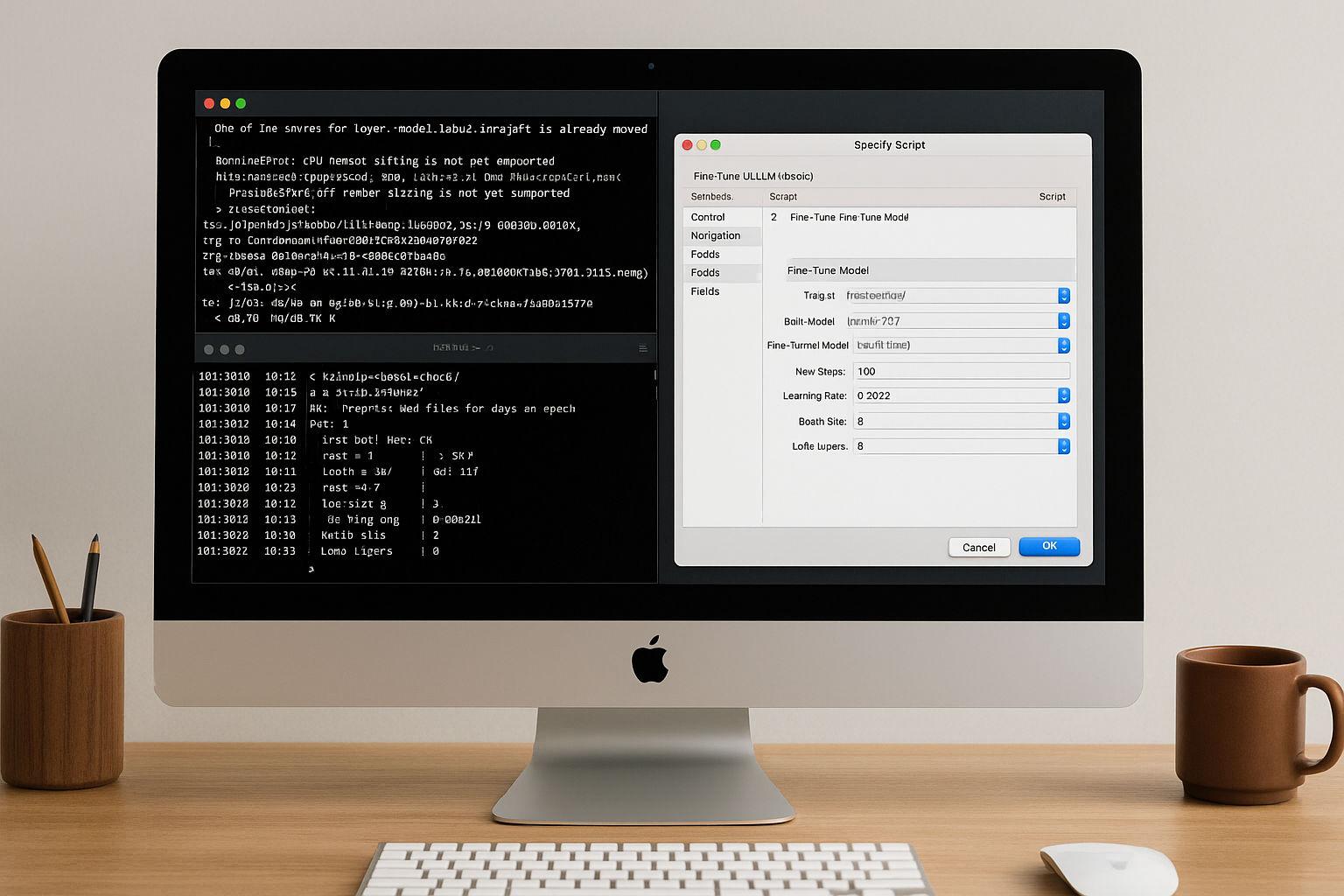
Met de introductie van de AI Model Server en een nieuwe scriptstap genaamd Fine-Tune Model, brengt Claris deze methode naar een omgeving waarin dit niet verwacht zou worden: een relationele database.
Wat op het eerste gezicht ongebruikelijk klinkt, is bij nader inzien heel logisch. Want wat heeft een goede fijnafstelling nodig?
- Gestructureerde gegevens,
- een stabiele omgeving,
- duidelijke parameters,
- en een gedefinieerde toepassingscontext.
FileMaker biedt dit allemaal en daarom lijkt de integratie van LoRA in deze omgeving geen vreemde eend in de bijt, maar eerder een logische uitbreiding.

Training zonder terminal - maar niet zonder controle
In mijn artikel beschrijf ik in detail hoe het trainingsproces in FileMaker aanvoelt:
- Gegevens rechtstreeks invoeren vanuit bestaande tabellen of JSONL-bestanden,
- Hyperparameters zoals leersnelheid of laagdiepte kunnen rechtstreeks in het script worden ingesteld,
- Volledige lokale bediening op Apple-Silicon - zonder cloud, zonder upload,
- en vooral: resultaten die reproduceerbaar zijn en geschikt voor dagelijks gebruik.
Natuurlijk zijn er beperkingen. FileMaker staat (nog) geen multi-model serving, layer freeze strategieën of export naar andere formaten zoals GGUF of ONNX toe. Het is geen onderzoekstool, maar een tool voor duidelijke use cases - zoals het aanpassen van taalmodellen aan bedrijfsspecifieke termen, reacties, productbeschrijvingen of interne dialoogstructuren.
En daar ligt de charme: het werkt. Stabiel. Herhaalbaar. En sneller dan ik ooit voor mogelijk had gehouden.
Huidig onderzoek naar de toekomst van FileMaker en AI
Wie moet er beter kijken - en waarom?
Dit artikel is bedoeld voor iedereen die niet alleen verstand heeft van AI, maar het ook wil gebruiken:
- Algemeen directeurdie gegevensbescherming en efficiëntie willen harmoniseren.
- Ontwikkelaardie niet elke keer opnieuw willen beginnen.
- Strategendie zich realiseren dat AI niet alleen extern kan worden "ingekocht", maar ook intern kan worden getraind.
In FileMaker 2025 zal het finetunen van taalmodellen deel uitmaken van de workflow - niet als een vreemde eend in de bijt, maar als een echt hulpmiddel. Dit is een stille maar blijvende verandering die laat zien hoe ver we zijn gekomen in de geschiktheid van AI voor dagelijks gebruik.
Naar het artikel:
Van terminal naar script: FileMaker 2025 maakt LoRA-fijnafstelling geschikt voor dagelijks gebruik
In het volgende artikel zal ik beschrijven hoe een taalmodel in de praktijk getraind kan worden met FileMaker en zal ik ook een bijbehorend voorbeeldscript geven.



