
Wer heute mit Künstlicher Intelligenz arbeitet, denkt oft zuerst an ChatGPT oder ähnliche Online-Dienste. Man tippt eine Frage ein, wartet ein paar Sekunden – und erhält eine Antwort, als säße ein sehr belesener, geduldiger Gesprächspartner am anderen Ende der Leitung. Doch was dabei leicht vergessen wird: Jede Eingabe, jeder Satz, jedes Wort wandert über das Internet zu fremden Servern. Dort wird die eigentliche Arbeit erledigt – auf riesigen Rechnern, die man selbst nie zu Gesicht bekommt.
Ein lokales Sprachmodell funktioniert im Prinzip genauso – nur eben ohne Internet. Das Modell liegt als Datei auf dem eigenen Computer, wird beim Start in den Arbeitsspeicher geladen und beantwortet Fragen direkt auf dem Gerät. Die Technik dahinter ist dieselbe: ein neuronales Netz, das Sprache versteht, Texte generiert und Muster erkennt. Nur dass die gesamte Berechnung im eigenen Haus bleibt. Man könnte sagen: ChatGPT ohne Cloud.
Das Besondere daran ist, dass sich die Technologie inzwischen so weit entwickelt hat, dass sie nicht mehr auf riesige Rechenzentren angewiesen ist. Moderne Apple-Computer mit M-Prozessoren (wie M3 oder M4) verfügen über enorme Rechenleistung, schnelle Speicheranbindung und eine spezialisierte Neural Engine für maschinelles Lernen. Dadurch lassen sich viele Modelle heute direkt auf einem Mac Mini oder Mac Studio betreiben – ganz ohne Serverfarm, ohne komplizierte Einrichtung und ohne nennenswerte Geräuschentwicklung.



Aktuelle Nachrichten zu Apple MLX und NVIDIA
26.03.2026: Apple treibt sein KI-Framework MLX strategisch weiter voran und öffnet es zunehmend für andere Plattformen. Ursprünglich ausschließlich für Apple Silicon optimiert, unterstützt MLX nun auch CUDA-GPUs und damit klassische Nvidia-Hardware. Damit fällt eine zentrale Hürde für Entwickler: Bisher mussten Modelle oft auf dem Mac entwickelt und anschließend auf separaten Hochleistungssystemen trainiert werden. Durch die Öffnung wird MLX zu einer flexibleren Entwicklungsplattform, die sowohl lokale KI auf Apple-Geräten als auch skalierbares Training auf externer Hardware ermöglicht. Gleichzeitig bleibt der Vorteil der engen Integration mit Apples eigener Architektur erhalten, etwa durch effiziente Speicherverwaltung und direkte GPU-Nutzung. Die Entwicklung deutet auf einen strategischen Kurswechsel hin: Apple verlässt schrittweise sein geschlossenes Ökosystem und positioniert MLX als ernstzunehmende Alternative zu etablierten KI-Frameworks – mit potenziellen Auswirkungen auf die gesamte KI-Entwicklung.
Damit öffnet sich eine neue Tür, nicht nur für Entwickler, sondern auch für Unternehmer, Autoren, Anwälte, Ärzte, Lehrer oder Handwerksbetriebe. Jeder kann nun seine eigene kleine KI besitzen – auf dem Schreibtisch, unter voller Kontrolle, jederzeit einsatzbereit. Ein lokales Sprachmodell kann:
- Texte zusammenfassen oder korrigieren,
- E-Mails formulieren oder strukturieren,
- Fragen beantworten und Wissen auswerten,
- Prozesse in Programmen unterstützen,
- Dokumente durchsuchen oder klassifizieren,
- oder einfach als persönlicher Assistent dienen – ohne dass jemals Daten nach außen gehen.
Gerade in einer Zeit, in der Datenschutz und digitale Souveränität wieder stärker in den Vordergrund rücken, gewinnt dieser Ansatz an Bedeutung. Man muss kein Programmierer sein, um ihn zu nutzen – ein moderner Mac genügt. Die Modelle können einfach über eine App oder ein Terminalfenster gestartet werden und reagieren danach fast so selbstverständlich wie ein Chatfenster im Browser.
Dieser Artikel zeigt, welche Modelle sich heute auf welchem Mac sinnvoll betreiben lassen, was die Hardware leisten muss und warum Apple Silicon-Rechner dafür besonders geeignet sind. Kurz gesagt: Es geht darum, wie man die Macht der KI wieder in die eigenen Hände nimmt – leise, effizient und lokal.
Lokale Sprachmodelle auf dem Mac – Warum das jetzt sinnvoll ist
Ein Sprachmodell „lokal“ auszuführen bedeutet, dass es vollständig auf dem eigenen Rechner betrieben wird – ohne Verbindung zu einem Cloud-Dienst. Die Berechnung, die Analyse von Eingaben, das Generieren von Texten oder Antworten – alles geschieht direkt auf dem eigenen Gerät. Das Modell liegt also als Datei auf der SSD, wird beim Start in den Arbeitsspeicher geladen und arbeitet dort mit der vollen Leistung des Systems.
Der entscheidende Unterschied zur Cloud-Variante ist die Unabhängigkeit. Es fließen keine Daten über das Internet, es werden keine externen Server beansprucht, und niemand kann nachvollziehen, was intern verarbeitet wird. Das bringt ein erhebliches Maß an Datenschutz und Kontrolle – vor allem in Zeiten, in denen Datenbewegungen immer schwerer nachvollziehbar sind.
Früher war das lokale Ausführen solcher Modelle undenkbar. Ein Großrechner oder eine GPU-Farm war nötig, um überhaupt ein neuronales Netzwerk dieser Größenordnung am Laufen zu halten. Heute, mit der Rechenleistung moderner Apple-Silicon-Chips, lässt sich das auf einem Schreibtischgerät umsetzen – effizient, leise und stromsparend.
Warum gerade Apple Silicon ideal ist
Mit dem Wechsel auf Apple Silicon hat Apple die Karten neu gemischt. Statt klassischer Intel-Architektur mit getrennter CPU und GPU setzt Apple auf ein sogenanntes Unified Memory-Design: Prozessor, Grafik und Neural Engine greifen auf denselben schnellen Arbeitsspeicher zu. Dadurch entfallen Datenkopien zwischen einzelnen Komponenten – ein entscheidender Vorteil für KI-Berechnungen.
Die Neural Engine selbst ist ein spezialisierter Rechenkern für maschinelles Lernen, der direkt in die Chips integriert ist. Sie ermöglicht Milliarden Rechenoperationen pro Sekunde – bei sehr niedrigem Energieverbrauch. Gemeinsam mit der MLX-Bibliothek (Machine Learning for Apple Silicon) und modernen Frameworks wie OLaMA können Modelle heute direkt auf macOS laufen, ohne aufwendige GPU-Treiber oder CUDA-Abhängigkeiten.
Ein M4-Chip im Mac Mini reicht bereits, um kompakte Sprachmodelle (z. B. 3–7 Milliarden Parameter) flüssig zu betreiben. Auf einem Mac Studio mit M4 Max oder M3 Ultra lassen sich sogar Modelle mit 30 Milliarden Parametern ausführen – völlig lokal.
Vergleich: Apple Silicon vs. NVIDIA-Hardware
Traditionell gilt NVIDIA mit seinen RTX-Grafikkarten als Goldstandard für KI-Berechnungen. Eine aktuelle RTX 5090 beispielsweise bietet enorme Rohleistung und ist für viele Trainingssysteme weiterhin erste Wahl. Dennoch lohnt sich der Vergleich im Detail – denn die Prioritäten unterscheiden sich.
| Aspekt | Apple Silicon (M4 / M4 Max / M3 Ultra) | NVIDIA GPU (5090 & Co.) |
|---|---|---|
| Energieverbrauch | Sehr effizient – meist unter 100 W Gesamtverbrauch | Bis 450 W allein für die GPU |
| Geräuschentwicklung | Nahezu lautlos | Deutlich hörbar bei Last |
| Software-Stack | MLX / Core ML / Metal | CUDA / cuDNN / PyTorch |
| Wartung | Treiberarm und stabil | Häufige Updates und Kompatibilitätsfragen |
| Preis-Leistung | Hohe Effizienz bei moderatem Preis | Bessere Spitzenleistung, aber teurer |
| Ideal für | Lokale Inferenz und Dauerbetrieb | Training und Großmodelle |
Kurz gesagt: NVIDIA ist die Wahl für Rechenzentren und extremes Training. Apple Silicon dagegen eignet sich hervorragend für lokale, dauerhafte Nutzung – ohne Lärm, ohne Hitzestau, mit stabiler Softwarebasis und überschaubarem Strombedarf.
Apple Silicon im Vergleich mit NVIDIA für Inferenz
Der M3 Ultra markiert für Apple Silicon einen bedeutenden Schritt nach vorne: Neben einem hoch integrierten Chipdesign mit CPU, GPU und Neural Engine in einem Package setzt sie auf eine Unified Memory Architektur, bei der Arbeitsspeicher von allen Recheneinheiten gleichzeitig genutzt wird – ohne klassische Trennung von RAM und GPU-VRAM. Laut Benchmarks erreicht dieser Ansatz bei local-Inference-Tasks bereits in einigen Fällen eine vergleichbare oder sogar bessere Performance als High-End-Grafikkarten von NVIDIA. Ein Beispiel: Im Test lag die M3 Ultra bei einem Qwen3-30B-4bit-Modell bei ca. 2.320 tokens/s gegenüber der RTX 3090 bei 2.157 tokens/s.
Zusätzlich spricht ein Vergleich von Apple Silicon vs NVIDIA bei KI-Lasten davon, dass ein M3/M4 Max-System unter Last zwischen etwa 40-80 W Verbrauch erreicht, während eine RTX 4090 typischerweise bis zu 450 W zieht.
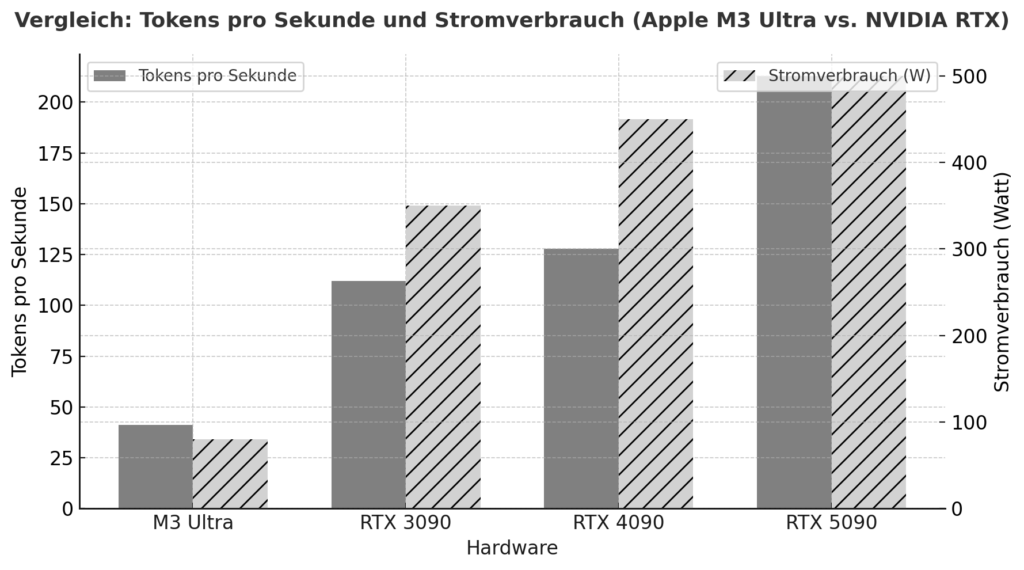
Damit zeigt sich: Wenn man nicht nur auf Spitzenleistung schaut, sondern auf Effizienz pro Watt, liegt Apple Silicon hervorragend im Rennen. Auf der anderen Seite stehen die NVIDIA-Karten (z. B. 3090, 4090, 5090) mit ihrer enormen parallelisierten GPU-Architektur, sehr hoher CUDA-/Tensor-Core-Dichte und spezialisierten Bibliotheken (CUDA, cuDNN, TensorRT). Dort liegt die rohe Spitzen-Flops-Leistung oft vorne – allerdings mit entscheidenden Einschränkungen für lokale Sprachmodelle: Der verfügbare VRAM (z. B. 24-32 GB bei Gaming-Karten) wird schnell zum Engpass, wenn Modelle mit 20-30 Milliarden Parametern oder mehr geladen werden sollen. Ein Nutzerbericht etwa nennt, dass mit einer RTX 5090 bei ca. 32 GB VRAM ein Modell über 20-22 Milliarden Parameter bereits schwer unterzubringen sei.
In dieser Hinsicht darf man also nicht nur nach GPU-Kernen schauen, sondern nach verfügbarer Speichergröße, Bandbreite und Speicherarchitektur. Die M3 Ultra mit z. B. bis zu 512 GB Unified Memory (in den Top-Konfigurationen) bietet hier in vielen lokalen Einsatzszenarien Vorteile – insbesondere dann, wenn Modelle nicht in der Cloud laufen sollen, sondern dauerhaft lokal.
| Hardware | Modell / Setup | Tokens pro Sekunde (ungefähr) | Bemerkung |
|---|---|---|---|
| Apple M3 Ultra (Mac Studio) | z. B. Gemma-3-27B-Q4 auf M3 Ultra | ≈ 41 tok/s :contentReference[oaicite:2]{index=2} | LLM-Inference, Kontext 4k-Tokens, quantisiert |
| NVIDIA RTX 5090 | 8 B Modell (Quantized) laut Studie | ≈ 213 tok/s :contentReference[oaicite:3]{index=3} | 8 B Modell, 4-bit, RLHF Umgebung |
| NVIDIA RTX 4090 | 8 B Modell Referenz | ≈ 128 tok/s :contentReference[oaicite:4]{index=4} | 24 GB VRAM Umgebung |
| NVIDIA RTX 3090 | Budget-HighEnd im Vergleich | ≈ 112 tok/s :contentReference[oaicite:5]{index=5} | Gebrauchtmarkt, 24 GB VRAM |
Praxisbezug: Wo lokale Sprachmodelle sinnvoll sind
Die Einsatzmöglichkeiten lokaler KI sind heute nahezu unbegrenzt. Immer dann, wenn Daten vertraulich bleiben müssen oder Prozesse in Echtzeit ablaufen sollen, lohnt sich die lokale Variante. Beispiele aus der Praxis:
- ERP-Systeme: Automatische Textanalyse, Vorschläge, Prognosen oder Kommunikationshilfen – direkt aus der Software heraus.
- Buch- und Medienproduktion: Stilprüfung, Übersetzung, Zusammenfassung, Texterweiterung – alles lokal, ohne Cloud-Abhängigkeit.
- Rechtsanwälte und Notare: Dokumentenanalyse, Schriftsatz-Entwürfe, Recherche – unter strengster Vertraulichkeit.
- Ärzte und Therapeuten: Fallauswertung, Dokumentation oder automatisierte Berichte – ohne dass Patientendaten je das System verlassen.
- Ingenieurbüros und Architekten: Text-, Projekt- und Berechnungsassistenten, die auch ohne Internet funktionieren.
- Unternehmen allgemein: Wissensmanagement, interne Chat-Assistenten, Protokollauswertung, E-Mail-Klassifizierung – alles im eigenen Netzwerk.
Gerade im gewerblichen Bereich ist das ein großer Schritt: Statt externe KI-Dienste zu bezahlen und Daten in die Cloud zu senden, kann man heute auf eigenen Maschinen maßgeschneiderte Modelle betreiben. Diese lassen sich anpassen, feintunen und mit firmeneigenem Wissen erweitern – vollständig unter Kontrolle.
So entsteht eine moderne, aber traditionell souveräne IT-Landschaft, die Technologie nutzt, ohne die Hoheit über die eigenen Daten aufzugeben. Ein Ansatz, der wieder an alte Tugenden erinnert: Dinge selbst in der Hand zu behalten.
Aktuelle Umfrage zu lokalen KI-Systemen
Überblick: Mac Mini und Mac Studio – was aktuell verfügbar ist
Wenn wir heute lokal Sprachmodelle auf einem Mac betreiben wollen, dann stehen zwei Desktop-Klassen besonders im Fokus: der Mac mini und der Mac Studio.
- Mac Mini: Die neueste Generation bietet den Apple M4-Chip oder optional den M4 Pro. Laut den technischen Spezifikationen sind Varianten mit 24 GB oder 32 GB Unified Memory verfügbar; die Pro-Variante wird konfigurierbar mit bis zu 48 GB bzw. 64 GB Unified Memory angeboten. Damit ist der Mac Mini für viele Anwendungen gut geeignet – gerade, wenn das Modell nicht extrem groß ist oder nicht mehrere sehr große Aufgaben parallel laufen müssen.
- Mac Studio: Hier geht es eine Stufe höher. Ausgestattet z. B. mit dem Apple M4 Max-Chip oder dem M3 Ultra-Chip – je nach Modell. Bei der M4 Max-Version sind 48 GB, 64 GB oder bis zu 128 GB Unified Memory möglich. Als M3 Ultra kann der Mac Studio mit bis zu 512 GB Unified Memory ausgestattet werden. Auch SSD-Größen und Speicherbandbreiten steigen erheblich. Damit eignet sich der Mac Studio für anspruchsvollere Modelle oder parallele Abläufe.
Als kurze Anmerkung: Der Mac Pro existiert ebenfalls und bietet äußerlich oft „mehr Gehäuse“ oder PCI-e-Steckplätze – aber im Hinblick auf Sprachmodelle bringt er für die lokale Ausführung kein großer Vorteil gegenüber dem Mac Studio, wenn man keine zusätzlichen Erweiterungskarten oder spezielle PCIe-Anforderungen hat.
Auch Notebooks (z. B. MacBook-Pro) können durchaus genutzt werden – aber mit Einschränkungen: Die Kühlsysteme sind kleiner, die Thermik begrenzter und häufig ist das RAM-Budget geringer. Lang-andauernde Auslastung (wie bei KI-Modellen) kann die Leistung drosseln.

KI: Apple besser als Nvidia! 😮 | c’t 3003
Warum RAM / Unified Memory so wichtig ist
Wenn ein Sprachmodell lokal läuft, dann wird nicht nur die CPU- oder GPU-Leistung gebraucht – ganz massgeblich ist der Arbeitsspeicher (RAM bzw. bei Apple: „Unified Memory“). Warum?
Das Modell selbst (Gewichte, Aktivierungen, Zwischenergebnisse) muss im Speicher gehalten werden. Je grösser das Modell, desto mehr Speicher wird benötigt. Apple-Silicon-Chips nutzen „Unified Memory“, d. h. CPU, GPU und Neural Engine greifen auf denselben Speicherpool zu. Dadurch entfallen Datenkopien zwischen Komponenten, was Effizienz und Geschwindigkeit erhöht.
Wenn nicht genug RAM vorhanden ist, muss das System auslagern oder Modelle werden nicht vollständig geladen – was Leistungseinbrüche, Instabilität oder Abbruch bedeuten kann. Gerade bei inferenziellen Anwendungen (Antwortgenerierung, Texteingabe, Modellerweiterung) kommt es auf Reaktionszeit und Durchsatz an – hier hilft ausreichend Speicher erheblich. Ein traditioneller Desktop-PC dachte früher in „CPU-RAM“ und „separate GPU-RAM“ – bei Apple Silicon ist es elegant vereint, was das Ausführen von Sprachmodellen besonders attraktiv macht.
Schätzwerte: Welche Größenordnung ist realistisch?
Damit man einschätzen kann, welche Hardware man benötigt, hier einige Faustwerte:
- Für kleinere Modelle (z. B. wenige Milliarden Parameter) könnten 16 GB bis 32 GB RAM ausreichen – insbesondere wenn nur Einzelanfragen verarbeitet werden sollen. Ein Mac Mini mit 16/32 GB wäre also Einstieg.
- Für mittlere Modelle (z. B. 3-10 Milliarden Parameter) oder Aufgaben mit mehreren Parallel-Chats bzw. größeren Textmengen sollte man 32 GB RAM oder mehr ins Auge fassen – z. B. Mac Studio mit 32 oder 48 GB.
- Für große Modelle (>20 Mrd Parameter) oder wenn mehrere Modelle parallel laufen sollen, könnte man 64 GB oder mehr wählen – hier kommen Mac mini- und Mac Studio Varianten mit 64 GB oder höher in Betracht.
Wichtig: Bedenken Sie etwas Puffer einzuplanen – nicht nur das Modell, sondern auch der Betrieb (z. B. das Betriebssystem, Datei-I/O, andere Applikationen) benötigt Speicher-Reserven.
| Kategorie | Typische Modellgröße | Empfohlenes RAM-Budget | Einsatzbeispiel |
|---|---|---|---|
| Klein | 1–3 Mrd Parameter | 16–32 GB | Einfacher Assistent, Texterkennung |
| Mittel | 7–13 Mrd Parameter | 32–64 GB | Chat, Analyse, Texterstellung |
| Groß | 30–70 Mrd Parameter | 64 GB + | Fachtexte, juristische Dokumente |
Traditionelle „Server-vs-Desktop“ Denkweise hinterfragen
Traditionell dachte man: Für KI braucht man Server-farmen, viele GPUs, viel Strom, ein Rechenzentrum. Doch das Bild wandelt sich: Desktop-Rechner wie Mac Mini oder Mac Studio bieten heute ausreichend Leistung für viele lokal betriebene Sprachmodelle – ohne riesige Infrastruktur. Statt hoher Stromkosten, starker Kühlung und aufwändiger Wartung gewinnen Sie ein leises, effektives Gerät auf dem Schreibtisch.
Natürlich: Wenn Sie Modelle trainieren wollen in großem Stil oder sehr viele Parameter nutzen, dann bleiben Server-lösungen weiterhin sinnvoll. Aber für Inferenz, Anpassung und Nutzung im Alltag genügt oftmals Desktop-Hardware. Damit verbindet sich eine traditionelle Haltung: Technik nutzen, aber nicht überdimensionieren – lieber gezielt und effizient. Wer heute eine solide lokale Basis baut, schafft die Grundlage für das, was morgen möglich sein wird.

M3 Ultra vs RTX 5090 | The Final Battle (Englisch)
Technische Charakterisierung von Sprachmodellen
Sprachmodelle unterscheiden sich heute nicht nur durch ihre Fähigkeiten, sondern auch durch das technische Format, in dem sie vorliegen. Diese Formate bestimmen, wie das Modell gespeichert, geladen und genutzt wird – und ob es überhaupt auf einem bestimmten System lauffähig ist.
GGUF (GPT-Generated Unified Format)
Dieses Format wurde für den praktischen Einsatz in Tools wie Ollama, LM Studio oder Llama.cpp entwickelt. Es ist kompakt, portabel und hochgradig optimiert für lokale Inferenz. GGUF-Modelle werden meist quantisiert, das heißt: Sie verbrauchen deutlich weniger Speicher, weil die internen Zahlenwerte reduziert gespeichert werden (z. B. 4-bit oder 8-bit). Dadurch lassen sich Modelle, die ursprünglich 30–50 GB groß waren, auf 5–10 GB komprimieren – bei nur geringem Qualitätsverlust.
- Vorteil: Läuft auf nahezu jedem System (macOS, Windows, Linux), keine spezielle GPU erforderlich.
- Nachteil: Nicht für Training oder Feintuning gedacht – reine Inferenz (also Nutzung).
MLX (Machine Learning for Apple Silicon)
MLX ist Apples eigenes Open-Source-Framework für Machine Learning auf Apple Silicon. Es wurde speziell entwickelt, um die volle Leistung von CPU, GPU und Neural Engine in M-Chips zu nutzen. MLX-Modelle liegen meist im nativen MLX-Format vor oder werden aus anderen Formaten konvertiert.
- Vorteil: Maximale Performance und Energieeffizienz auf Apple-Hardware.
- Nachteil: Noch relativ junges Ökosystem, weniger Community-Modelle verfügbar als bei GGUF oder PyTorch.
Safetensors (.safetensors)
Dieses Format stammt aus der PyTorch-Welt (und wird von Hugging Face stark gefördert). Es ist ein sicheres, binäres Speicherformat für große Modelle, das keine Codeausführung zulässt – daher der Name „safe“.
- Vorteil: Sehr schnell zu laden, speichersparend, standardisiert.
- Nachteil: Hauptsächlich für Frameworks wie PyTorch oder TensorFlow gedacht – also eher in Entwicklerumgebungen und für Trainingsprozesse üblich.
| Format | Plattform | Zweck | Vorteile | Nachteile |
|---|---|---|---|---|
| GGUF | macOS, Windows, Linux | Inferenz | Kompakt, schnell, universell | Kein Training möglich |
| MLX | macOS (Apple Silicon) | Inferenz + Training | Optimiert für M-Chips, hohe Effizienz | Weniger Modelle verfügbar |
| Safetensors | Cross-Plattform (PyTorch / TensorFlow) | Training & Forschung | Sicher, standardisiert, schnell | Nicht direkt mit Ollama / MLX kompatibel |
Hugging Face – die zentrale Bezugsquelle
Hugging Face ist heute so etwas wie die „Bibliothek“ der KI-Welt. Auf huggingface.co finden sich zehntausende Modelle, Datensätze und Werkzeuge – viele davon frei nutzbar. Dort kann man nach Namen, Architekturen, Lizenzarten oder Dateiformaten filtern. Ob Mistral, LLaMA, Falcon, Gemma oder Phi-3 – fast alle namhaften Modelle sind dort vertreten. Für die lokale Nutzung mit GGUF oder MLX bieten zahlreiche Entwickler bereits angepasste Versionen an.
Damit ist Hugging Face für die meisten Anwender der erste Anlaufpunkt, wenn man ein Modell ausprobieren oder eine geeignete Variante für macOS finden möchte.

Typische Modelle und ihre Einsatzgebiete
Die Zahl der verfügbaren Modelle ist inzwischen kaum mehr zu überblicken. Dennoch lassen sich einige Hauptfamilien nennen, die sich für lokale Nutzung besonders bewährt haben:
- LLaMA-Familie (Meta): Eines der bekanntesten Open-Source-Modelle. Es bildet die Basis für unzählige Derivate (z. B. Vicuna, WizardLM, Open-Hermes). Stärken: Sprachverständnis, Dialog, vielseitige Nutzung. Einsatzgebiet: Allgemeine Chat-Anwendungen, Content-Generierung, Assistenzsysteme.
- Mistral & Mixtral (Mistral AI): Bekannt für hohe Effizienz und gute Qualität bei kleiner Modellgröße. Mixtral 8x7B kombiniert mehrere Expertenmodelle (Mixture-of-Experts-Architektur). Stärken: Schnelle, präzise Antworten, ressourcenschonend. Einsatzgebiet: Unternehmensinterne Assistenten, Textanalyse, Datenaufbereitung.
- Phi-3 (Microsoft Research): Kompaktes Modell, optimiert auf hohe Sprachqualität trotz geringer Parameterzahl. Stärken: Effizienz, gute Grammatik, strukturierte Antworten. Einsatzgebiet: Kleinere Systeme, lokale Wissensmodelle, integrierte Assistenten.
- Gemma (Google): Von Google Research als offenes Modell veröffentlicht. Gut für summarische und erklärende Aufgaben. Stärken: Kohärenz, kontextbezogene Erklärungen. Einsatzgebiet: Wissensaufbereitung, Schulung, Beratungssysteme.
- GPT-OSS / OpenHermes-Modelle: Gemeinsam mit LLaMA-Abwandlungen bilden sie die „Brücke“ zwischen Open-Source-Modellen und dem Funktionsumfang kommerzieller Systeme. Stärken: Breite Sprachbasis, flexibel einsetzbar. Einsatzgebiet: Content-Erstellung, Chat- und Analyseaufgaben, interne KI-Assistenz.
- Claude / Command R / Falcon / Yi / Zephyr: Diese und viele andere Modelle (meist aus Forschungsprojekten oder offenen Communities) bieten Spezialfunktionen: etwa Wissensabruf, Code-Erzeugung oder Multilingualität.
Der wichtigste Punkt ist: Kein Modell kann alles perfekt. Jedes hat seine Stärken und Schwächen – und je nach Anwendungsfall lohnt sich ein gezielter Vergleich.
Wofür eignet sich welches Modell?
Damit man eine realistische Einschätzung bekommt, kann man die Modelle grob in Leistungs- und Einsatzklassen einteilen:
Für die meisten realistischen Desktop-Anwendungen – etwa Zusammenfassungen, Korrespondenz, Übersetzung, Analyse – reichen mittlere Modelle (7–13 B) völlig aus. Sie liefern erstaunlich gute Ergebnisse, laufen flüssig auf einem Mac Mini M4 Pro mit 32–48 GB RAM und benötigen kaum Nachjustierung.
Große Modelle entfalten ihre Stärken, wenn tieferes Verständnis oder längere Kontexte wichtig sind – etwa bei der Verarbeitung juristischer Texte oder technischen Dokumentationen. Dafür sollte man allerdings mindestens einen Mac Studio mit 64–128 GB Arbeitsspeicher nutzen.
| Modellfamilie | Herkunft | Stärken | Einsatzgebiet |
|---|---|---|---|
| LLaMA | Meta | Sprachverständnis, Dialog | Allgemeine Chat-Anwendungen |
| Mistral / Mixtral | Mistral AI | Effizienz, hohe Präzision | Unternehmens-Assistenten, Analyse |
| Phi-3 | Microsoft Research | Kompakt, sprachlich stark | Kleine Systeme, Lokal-KI |
| Gemma | Google Research | Kohärenz, Erklärfähigkeit | Beratung, Lehre, Texterklärung |
Möglichkeiten, Sprachmodelle lokal zu betreiben
Wer heute ein Sprachmodell auf dem eigenen Mac einsetzen möchte, hat mehrere praktikable Wege – je nach technischem Anspruch und gewünschtem Einsatzzweck. Das Schöne ist: Es braucht keine komplexe Entwicklungsumgebung mehr, um damit zu beginnen.
Ollama – der unkomplizierte Einstieg
Ollama hat sich innerhalb kurzer Zeit zu einem Standardwerkzeug für lokale KI-Modelle entwickelt. Es läuft nativ auf macOS, nutzt die Leistung von Apple Silicon optimal aus und erlaubt das Starten eines Modells mit einem einzigen Befehl:
ollama run mistral
Damit wird das gewünschte Modell automatisch geladen, vorbereitet und steht anschließend im Terminal oder über lokale Schnittstellen zur Verfügung. Ollama unterstützt das GGUF-Format, erlaubt Modelldownloads von Hugging Face und kann über REST-APIs oder direkt in andere Programme eingebunden werden.
Wie man mit Ollama ein lokales Sprachmodell installiert und welche weiteren Möglichkeiten man damit hat, habe ich in einem weiteren Artikel detailliert beschrieben. Dazu gibt es weiterführende Artikel, wie man mit Qdrant ein flexibles Gedächtnis für seine lokale KI einrichten kann.
LM Studio – grafische Oberfläche und Verwaltung
LM Studio richtet sich an alle, die eine grafische Oberfläche bevorzugen. Es bietet Modelldownloads, Chat-Fenster, Temperature-Regler, System-Prompts und Speicher-Verwaltung in einer App. Gerade für Einsteiger ist das ideal: Man kann verschiedene Modelle ausprobieren, vergleichen, speichern und wechseln, ohne mit der Kommandozeile zu arbeiten. Die Software läuft stabil auf Apple Silicon und unterstützt ebenso GGUF-Modelle.
MLX / Python – für Entwickler und Integratoren
Wer tiefer einsteigen oder Modelle in eigene Programme integrieren will, kann auf Apples MLX-Framework zurückgreifen. Damit lassen sich Modelle direkt in Python oder Swift-Anwendungen einbetten. Der Vorteil liegt in der maximalen Kontrolle und Integration in bestehende Workflows – etwa wenn ein Unternehmen eine eigene Software um KI-Funktionen erweitern möchte.
FileMaker Server 2025 – KI im Unternehmenskontext
Seit FileMaker Server 2025 lassen sich MLX-basierte Sprachmodelle auch serverseitig ansprechen. Damit wird erstmals möglich, eine zentrale Business-Applikation (z. B. ERP- oder CRM-System) mit eigener lokaler KI auszustatten. Beispielsweise können Support-Tickets automatisch klassifiziert, Kundenanfragen ausgewertet oder Inhalte in Dokumenten analysiert werden – ohne dass Daten die Firma verlassen.
Das ist insbesondere für Branchen interessant, die strenge Datenschutz- oder Compliance-Vorgaben haben (Medizin, Recht, Verwaltung, Industrie).
Typische Stolpersteine und wie man sie vermeidet
Auch wenn die Einstiegshürde niedrig ist, gibt es einige Punkte, auf die man achten sollte:
Speichergrenzen: Wenn das Modell zu groß für den vorhandenen Arbeitsspeicher ist, startet es gar nicht oder wird extrem langsam. Hier hilft Quantisierung (z. B. 4-bit) oder ein kleineres Modell.
- Rechenlast und Wärmeentwicklung: Bei längeren Sitzungen kann der Mac spürbar warm werden. Gute Belüftung und ein Auge auf die Aktivitätsanzeige sind sinnvoll.
- Fehlende GPU-Unterstützung bei Fremdsoftware: Manche älteren Tools oder Ports nutzen die Neural Engine nicht effizient. In solchen Fällen kann MLX bessere Ergebnisse liefern.
- Netzwerk-Ports und Rechte: Wenn mehrere Clients auf dasselbe Modell zugreifen sollen (z. B. innerhalb eines Unternehmensnetzwerks), müssen lokale Ports freigegeben werden – am besten abgesichert per HTTPS oder über einen internen Proxy.
- Datensicherheit: Auch wenn die Modelle lokal laufen, sollte man keine sensiblen Texte in unsicheren Umgebungen speichern. Lokale Logs und Chat-Protokolle lassen sich leicht vergessen, enthalten aber oft wertvolle Informationen.
Wer diese Punkte beachtet, kann mit erstaunlich wenig Aufwand ein leistungsfähiges, lokales KI-System betreiben, das sicher, leise und effizient läuft.
Zeitlicher Ausblick & strategische Überlegungen
Wir stehen erst am Anfang einer Entwicklung, die in den nächsten Jahren den Alltag vieler Berufe verändern wird. Lokale KI-Modelle werden zunehmend kleiner, schneller und effizienter, während ihre Qualität weiter steigt. Was heute noch 30 GB Speicher braucht, wird in einem Jahr vielleicht nur noch 10 GB beanspruchen – bei gleicher Sprachqualität. Parallel dazu entstehen neue Schnittstellen, mit denen man Modelle direkt in Office-Programme, Browser oder Firmensoftware einbinden kann.
Unternehmen, die heute den Schritt zur lokalen KI-Infrastruktur wagen, schaffen sich damit einen Vorsprung. Sie bauen Know-how auf, sichern ihre Datenhoheit und machen sich unabhängig von Preisschwankungen oder Nutzungsbeschränkungen externer Anbieter. Eine sinnvolle Strategie kann so aussehen:
- Zunächst mit einem kleinen Modell experimentieren (z. B. 3-7 Mrd Parameter, über Ollama oder LM Studio).
- Danach gezielt prüfen, welche Aufgaben sich automatisieren lassen.
- Bei Bedarf größere Modelle einbinden oder einen zentralen Mac Studio als „KI-Server“ aufsetzen.
- Mittelfristig interne Prozesse (z. B. Dokumentation, Textanalyse, Kommunikation) KI-gestützt umgestalten.
Diese schrittweise Herangehensweise ist nicht nur wirtschaftlich vernünftig, sondern auch nachhaltig – sie folgt dem Prinzip: Technik im eigenen Tempo annehmen, statt sich von Trends treiben zu lassen.
In einem separaten Artikel habe ich im Detail beschrieben, wie sich das neuere MLX-Format im Vergleich mit GGUF über Ollama auf dem Mac verhält.
Lokale KI als leiser Weg zur digitalen Souveränität
Lokale Sprachmodelle markieren eine Rückkehr zur Selbstbestimmung in der digitalen Welt.
Statt Daten und Ideen in entfernte Cloud-Rechenzentren zu schicken, kann man heute wieder mit eigenen Werkzeugen arbeiten – direkt auf dem Schreibtisch, unter eigener Kontrolle.
Egal ob auf einem Mac Mini, einem Mac Studio oder einem leistungsfähigen Notebook – wer die passende Hardware besitzt, kann heute seine eigene KI nutzen, trainieren und weiterentwickeln. Ob als persönlicher Assistent, als Teil eines ERP-Systems, als Recherche-Hilfe im Verlag oder als datenschutzkonforme Lösung in einer Kanzlei – die Möglichkeiten sind erstaunlich breit.
Und das Schönste daran: Es erinnert an die alte Stärke des Computers – nämlich ein Werkzeug zu sein, das man selbst beherrscht, statt eines Dienstes, der uns diktiert, wie wir zu arbeiten haben. Damit wird die lokale KI zu einem Symbol moderner Eigenständigkeit – leise, effizient, und doch mit beeindruckender Wirkung.
Empfehlenswerte Quellen
- Profiling Large Language Model Inference on Apple Silicon: A Quantization Perspective (Benazir & Lin et al., 2025) – Untersucht detailliert die Inferenzleistung auf Apple Silicon im Vergleich zu NVIDIA‑GPUs, speziell mit Fokus auf Quantisierung.
- Production‑Grade Local LLM Inference on Apple Silicon: A Comparative Study of MLX, MLC‑LLM, Ollama, llama.cpp, and PyTorch MPS (Rajesh et al., 2025) – Vergleich verschiedener Plattformen auf Apple Silicon inkl. MLX, mit Bezug auf Durchsatz, Latenz, Kontextlänge.
- Benchmarking On‑Device Machine Learning on Apple Silicon with MLX (Ajayi & Odunayo, 2025) – Fokussiert auf MLX und Apple Silicon, mit Benchmarkdaten gegenüber NVIDIA‑Systemen.




Häufig gestellte Fragen
- Was genau ist ein lokales Sprachmodell?
Ein lokales Sprachmodell ist eine KI, die Texte verstehen und erzeugen kann – ähnlich wie ChatGPT. Der Unterschied besteht darin, dass es nicht über das Internet läuft, sondern direkt auf dem eigenen Computer. Alle Berechnungen finden lokal statt, und keine Daten werden an externe Server gesendet. Dadurch behält man die volle Kontrolle über die eigenen Informationen. - Welche Vorteile bietet eine lokale KI gegenüber einer Cloud-Lösung wie ChatGPT?
Die drei größten Vorteile sind Datenschutz, Unabhängigkeit und Kostenkontrolle.
– Datenschutz: Keine Texte verlassen den Rechner.
– Unabhängigkeit: Keine Internetverbindung nötig, kein Anbieterwechsel oder Ausfallrisiko.
– Kosten: Keine laufenden Gebühren pro Anfrage. Man bezahlt einmalig für die Hardware – das war’s. - Benötigt man Programmierkenntnisse, um ein Sprachmodell lokal zu nutzen?
Nein. Mit modernen Tools wie Ollama oder LM Studio lässt sich ein Modell mit wenigen Klicks starten. Selbst Einsteiger können heute in wenigen Minuten eine lokale KI betreiben, ohne eine Zeile Code zu schreiben. - Welche Apple-Geräte sind besonders gut geeignet?
Für Einsteiger genügt oft ein Mac Mini mit M4 oder M4 Pro und mindestens 32 GB RAM. Wer größere Modelle oder mehrere gleichzeitig nutzen will, greift besser zum Mac Studio mit 64 GB oder 128 GB RAM. Ein Mac Pro bietet kaum Vorteile, außer man benötigt PCI-e-Steckplätze. Notebooks sind zwar geeignet, stoßen aber thermisch schneller an Grenzen. - Wie viel Arbeitsspeicher (RAM) sollte man mindestens haben?
Das hängt von der Modellgröße ab.
– Kleine Modelle (1–3 Mrd Parameter): 16–32 GB reichen.
– Mittlere Modelle (7–13 Mrd): besser 48–64 GB.
– Große Modelle (30 Mrd+): 128 GB oder mehr.
Wichtig ist, etwas Reserve einzuplanen – sonst kommt es zu Wartezeiten oder Abbrüchen. - Was bedeutet „Unified Memory“ bei Apple Silicon?
Unified Memory ist ein gemeinsamer Speicher, auf den CPU, GPU und Neural Engine gleichzeitig zugreifen. Das spart Zeit und Energie, da keine Datenkopien zwischen verschiedenen Speicherbereichen nötig sind. Gerade für KI-Berechnungen ist das ein enormer Vorteil, weil alles in einem Fluss arbeitet. - Was ist der Unterschied zwischen GGUF, MLX und Safetensors?
– GGUF: Ein kompaktes Format für lokale Nutzung (z. B. in Ollama oder LM Studio). Ideal für Inferenz, also das Ausführen fertiger Modelle.
– MLX: Apples eigenes Format, speziell für M-Chips. Sehr effizient, aber noch jung.
– Safetensors: Ein Format aus der PyTorch-Welt, vor allem für Training und Forschung gedacht.
Für lokale Nutzung auf dem Mac sind GGUF oder MLX optimal. - Woher bekommt man die Modelle überhaupt?
Die bekannteste Plattform ist huggingface.co – eine riesige Bibliothek für KI-Modelle. Dort findet man Varianten von LLaMA, Mistral, Gemma, Phi-3 und vielen anderen. Viele Modelle sind bereits im GGUF-Format verfügbar und lassen sich direkt in Ollama laden. - Welche Tools sind für den Start am einfachsten?
Für den Anfang sind Ollama und LM Studio ideal. Ollama läuft im Terminal und ist leichtgewichtig. LM Studio bietet eine grafische Oberfläche mit Chat-Fenster. Beide laden und starten Modelle automatisch und benötigen keine komplizierte Einrichtung. - Kann man Sprachmodelle auch mit FileMaker Server einsetzen?
Ja – seit FileMaker Server 2025 können MLX-Modelle direkt angesprochen werden. Das ermöglicht z. B. Textanalysen, Klassifizierungen oder automatische Auswertungen innerhalb von ERP- oder CRM-Systemen. Damit lassen sich vertrauliche Geschäftsdaten lokal verarbeiten, ohne sie an externe Anbieter zu senden. - Wie groß sind solche Modelle typischerweise?
Kleine Modelle liegen bei wenigen Gigabyte, große können 20 – 30 GB oder mehr haben. Durch Quantisierung (z. B. 4-bit) lassen sie sich stark verkleinern, oft bei minimalem Qualitätsverlust. Ein komprimiertes 13-B-Modell kann beispielsweise nur 7 GB belegen – perfekt für einen Mac Mini M4 Pro. - Kann man lokale Modelle auch trainieren oder anpassen?
Grundsätzlich ja – aber das Training ist sehr rechenintensiv. Für lokales Feintuning kleinerer Modelle kann man MLX oder Python-Frameworks verwenden. FileMaker enthält heute eine integrierte Funktion, um Sprachmodelle direkt feinabstimmen zu können. Für großes Training (z. B. 50 Mrd Parameter) wäre jedoch eine dedizierte GPU-Farm nötig. Für die meisten Anwendungen genügt es, bestehende Modelle zu nutzen und über Prompts gezielt zu steuern. - Wie viel Strom verbraucht ein Mac bei KI-Berechnungen?
Überraschend wenig. Ein Mac Studio liegt oft bei unter 100 W im Vollbetrieb, während eine einzelne NVIDIA-Grafikkarte (z. B. RTX 5090) bis zu 450 W zieht – ohne CPU und Peripherie. Das bedeutet: Lokale KI auf Apple-Hardware ist nicht nur leiser, sondern auch deutlich energieeffizienter. - Ist ein MacBook Pro für lokale KI geeignet?
Ja, aber mit Einschränkungen.
Die Leistung ist zwar hoch, aber die thermische Belastbarkeit begrenzt. Bei längeren Sessions drosselt der Prozessor. Für kurze Chats, Textaufgaben oder Analysen ist ein MacBook Pro M3/M4 perfekt – für dauerhafte Nutzung eher nicht. - Wie sicher sind lokale Modelle wirklich?
So sicher, wie das System, auf dem sie laufen. Da keine Daten über das Internet gesendet werden, besteht praktisch kein Risiko durch Dritte. Man sollte jedoch darauf achten, dass temporäre Dateien, Logs oder Chat-Verläufe nicht versehentlich in Cloud-Ordnern landen (z. B. iCloud Drive). Eine lokale Speicherung auf der internen SSD ist ideal. - Was sind typische Fehler, die Einsteiger machen?
– Zu große Modelle laden, obwohl der RAM nicht ausreicht.
– Alte Versionen von Ollama oder LM Studio verwenden.
– Keine GPU-Beschleunigung aktivieren (z. B. MLX).
– Im Hintergrund zu viele Prozesse laufen lassen.
– Modelle aus fragwürdigen Quellen laden.
Abhilfe: Nur vertrauenswürdige Quellen (z. B. Hugging Face) nutzen und Systemressourcen im Blick behalten. - Wohin entwickelt sich die lokale KI-Technologie in den nächsten Jahren?
Die Modelle werden weiter kompakter und präziser. Apple, Mistral und Meta arbeiten bereits an Architekturen, die bei gleicher Qualität weniger Speicher und Strom benötigen. Gleichzeitig entstehen komfortable Schnittstellen – etwa KI-Plugins für Textverarbeitung, Mailprogramme oder Notiz-Apps. Langfristig dürfte jedes professionelle System eine Art „eingebaute lokale KI“ enthalten. - Warum lohnt es sich, jetzt damit anzufangen?
Weil sich gerade jetzt die Grundlagen für die nächsten Jahre bilden. Wer heute lernt, ein Modell lokal zu starten, Daten strukturiert zu verarbeiten und Prompts gezielt zu formulieren, wird später unabhängig agieren können – ohne auf teure Cloud-Anbieter angewiesen zu sein. Kurz gesagt: Lokale KI ist der ruhige, souveräne Weg in eine digitale Zukunft, in der man seine Daten und Werkzeuge wieder selbst in der Hand behält.



