
Im ersten Teil dieser Artikelserie haben wir gesehen, dass der ChatGPT-Datenexport weit mehr ist als nur eine technische Funktion. In Deinen exportierten Daten steckt eine Sammlung aus Gedanken, Ideen, Analysen und Gesprächen, die sich über längere Zeit angesammelt haben. Doch solange diese Daten nur als Archiv auf der Festplatte liegen, bleiben sie genau das: ein Archiv. Der entscheidende Schritt besteht darin, diese Informationen wieder nutzbar zu machen. Genau hier beginnt der Aufbau einer persönlichen Wissens-KI.
Die Idee ist eigentlich erstaunlich einfach: Eine KI soll nicht nur mit allgemeinem Wissen arbeiten, sondern auch auf Deine eigenen Daten zugreifen können. Sie soll frühere Gespräche durchsuchen, passende Inhalte finden und diese in neue Antworten einbeziehen. Damit wird aus einer gewöhnlichen KI eine Art digitales Gedächtnis. Dies ist der zweite Teil der Artikelserie, in dem es nun um die Praxis geht.




Teil 1 der Serie: Der unterschätzte Schatz im ChatGPT-Datenexport
Während wir in diesem zweiten Teil konkret in die Praxis einsteigen, lohnt sich ein Blick auf den ersten Artikel dieser Serie. Dort geht es um die grundlegende Frage, warum der ChatGPT-Datenexport überhaupt so interessant ist – und weshalb viele Nutzer sein Potenzial noch unterschätzen. Der Artikel zeigt, welche Daten tatsächlich im Export enthalten sind, wie daraus ein persönliches Wissensarchiv entstehen kann und warum genau dieser Schritt die Grundlage für eine eigene KI mit Gedächtnis bildet. Wenn Du verstehen möchtest, warum wir diese Pipeline überhaupt aufbauen und welchen strategischen Wert Deine eigenen Chatverläufe haben, solltest Du mit Teil 1 beginnen.
Bevor wir im nächsten Kapitel mit der konkreten Umsetzung beginnen, schauen wir uns zunächst an, wie ein solches System grundsätzlich aufgebaut ist.
Die Grundidee eines RAG-Systems
Die technische Grundlage unseres Systems ist ein Konzept, das in der KI-Welt inzwischen weit verbreitet ist: RAG, also Retrieval Augmented Generation. Hinter diesem Begriff verbirgt sich ein sehr praktisches Prinzip.
Normalerweise beantwortet ein Sprachmodell Fragen ausschließlich mit dem Wissen, das während seines Trainings gelernt wurde. Dieses Wissen ist zwar umfangreich, aber es hat zwei entscheidende Einschränkungen:
- Erstens kennt das Modell keine individuellen Informationen über Deine eigenen Projekte oder Gedanken.
- Zweitens kann es nicht auf neue Daten zugreifen, die nach dem Training entstanden sind.
Genau hier setzt ein RAG-System an. Statt eine Antwort direkt zu generieren, passiert zunächst etwas anderes: Das System durchsucht eine Datenbank nach Inhalten, die zur gestellten Frage passen. Diese Inhalte werden anschließend als Kontext an das Sprachmodell übergeben. Erst danach formuliert die KI ihre Antwort. Der Ablauf sieht vereinfacht so aus:
- Du stellst eine Frage →
- das System durchsucht eine Wissensdatenbank →
- relevante Inhalte werden gefunden →
- diese Inhalte werden der KI als Kontext übergeben →
- die KI erzeugt eine Antwort.
Der entscheidende Vorteil liegt auf der Hand: Die KI kann Informationen nutzen, die nicht Teil ihres ursprünglichen Trainings waren.
Und genau hier kommen Deine ChatGPT-Daten ins Spiel. Wenn wir diese Gespräche in eine Wissensdatenbank integrieren, kann die KI später darauf zugreifen. Sie kann frühere Ideen wiederfinden, Argumente aus alten Dialogen nutzen oder Analysen aus vergangenen Gesprächen berücksichtigen. Das System beginnt also, sich an Deine eigenen Gedanken zu „erinnern“.
Die Bausteine unseres Systems
Damit das funktioniert, benötigen wir mehrere Komponenten, die zusammenarbeiten. Zum Glück ist die technische Infrastruktur dafür heute deutlich einfacher zugänglich als noch vor wenigen Jahren. Unser System besteht im Kern aus vier zentralen Bausteinen.
- Der erste Baustein ist der ChatGPT-Datenexport. Hier liegen unsere Rohdaten. Diese enthalten alle Gespräche, die wir zuvor mit der KI geführt haben.
- Der zweite Baustein ist ein Embedding-Modell. Dieses Modell übersetzt Text in mathematische Vektoren. Dadurch wird es möglich, Texte nach ihrer Bedeutung zu vergleichen.
- Der dritte Baustein ist eine Vektordatenbank. In unserem Fall verwenden wir Qdrant. Diese Datenbank speichert die mathematischen Repräsentationen der Texte und ermöglicht eine schnelle semantische Suche.
- Der vierte Baustein ist ein lokales Sprachmodell, das über Ollama läuft. Dieses Modell formuliert später die eigentlichen Antworten.
Diese vier Komponenten arbeiten eng zusammen.
- Der Datenexport liefert die Inhalte.
- Das Embedding-Modell macht sie maschinenlesbar.
- Die Vektordatenbank speichert und durchsucht sie.
- Das Sprachmodell erzeugt schließlich verständliche Antworten.
Zusammen bilden sie die Grundlage für eine persönliche Wissens-KI.
Der Datenfluss im Überblick
Damit das System funktioniert, müssen die Daten mehrere Schritte durchlaufen. Am Anfang steht der ChatGPT-Datenexport, den wir bereits im ersten Artikel erstellt haben. Die darin enthaltenen Gespräche werden zunächst aus den JSON-Dateien extrahiert. Diese Texte müssen anschließend vorbereitet werden. Große Chatverläufe werden in kleinere Abschnitte zerlegt, sogenannte Text-Chunks. Dadurch wird die spätere Suche deutlich effizienter.
Im nächsten Schritt erzeugen wir aus diesen Textabschnitten Embeddings. Dabei wird jeder Text mathematisch beschrieben. Texte mit ähnlicher Bedeutung erhalten ähnliche Vektoren. Diese Vektoren speichern wir anschließend in unserer Vektordatenbank Qdrant.
Damit ist der wichtigste Teil der Infrastruktur bereits aufgebaut. Wenn später eine Frage gestellt wird, passiert Folgendes:
- Die Frage wird ebenfalls in einen Vektor umgewandelt.
- Die Datenbank sucht nach Texten mit ähnlicher Bedeutung.
- Diese Textstellen werden als Kontext an das Sprachmodell übergeben.
- Das Modell nutzt diese Informationen und formuliert daraus eine Antwort.
Dieser Ablauf sorgt dafür, dass die KI nicht nur allgemeines Wissen verwendet, sondern auch auf Deine eigenen Daten zugreifen kann.
Was am Ende möglich sein wird
Wenn das System einmal eingerichtet ist, verändert sich der Umgang mit KI spürbar. Du arbeitest dann nicht mehr nur mit einem allgemeinen Sprachmodell, sondern mit einer KI, die auf Deine eigenen Daten zugreifen kann. Das eröffnet völlig neue Möglichkeiten. Du kannst zum Beispiel Fragen stellen wie:
„Habe ich über dieses Thema schon einmal mit der KI gesprochen?“
„Welche Ideen hatte ich früher zu diesem Projekt?“
„Welche Argumente habe ich in früheren Gesprächen entwickelt?“
Die KI durchsucht dann Deine eigenen Gespräche und findet passende Inhalte. Statt nur eine allgemeine Antwort zu geben, kann sie auf frühere Gedanken Bezug nehmen, alte Analysen zusammenfassen oder Zusammenhänge zwischen verschiedenen Gesprächen erkennen.
Mit anderen Worten: Die KI beginnt, mit Deinem eigenen Wissensarchiv zu arbeiten. Damit wird aus einem einfachen Chatwerkzeug ein System, das Dich langfristig beim Denken unterstützen kann. Und genau dieses System werden wir in den nächsten Kapiteln Schritt für Schritt aufbauen. Im nächsten Abschnitt beginnen wir mit der praktischen Arbeit und schauen uns zuerst den ChatGPT-Datenexport genauer an. Denn bevor wir eine Wissensdatenbank aufbauen können, müssen wir verstehen, wie unsere Daten eigentlich aufgebaut sind.
Aktuelle Umfrage zur Nutzung lokaler KI-Systeme
Vorbereitung: ChatGPT-Datenexport verstehen
Im ersten Artikel dieser Serie haben wir den ChatGPT-Datenexport bereits erstellt und als ZIP-Datei heruntergeladen. Auf den ersten Blick wirkt diese Datei vielleicht etwas unspektakulär – ein Archiv mit einigen technischen Dateien, das zunächst eher wie ein Backup aussieht als wie ein wertvoller Datensatz. Doch genau in diesem Archiv steckt die Grundlage für unser gesamtes Wissenssystem.
Bevor wir damit beginnen können, diese Daten in eine Datenbank zu laden oder mit einer KI zu verbinden, müssen wir zunächst verstehen, wie der Export aufgebaut ist. Denn nur wenn wir wissen, welche Informationen enthalten sind und wie sie strukturiert sind, können wir sie später sinnvoll weiterverarbeiten. In diesem Kapitel schauen wir uns deshalb an, wie der Datenexport aufgebaut ist, welche Dateien wirklich relevant sind und wie wir aus diesem technischen Archiv eine brauchbare Grundlage für unser KI-Wissenssystem machen.
ZIP-Datei entpacken
Der erste Schritt ist trivial, aber dennoch wichtig: Wir müssen das heruntergeladene Archiv entpacken. Die Datei liegt normalerweise als klassische ZIP-Datei vor. Je nach Umfang Deiner bisherigen Nutzung kann sie unterschiedlich groß sein. Manche Nutzer erhalten ein Archiv von wenigen hundert Megabyte, andere mehrere Gigabyte.
Nachdem Du die Datei entpackt hast, entsteht ein Ordner mit mehreren Dateien und Unterordnern. Die genaue Struktur kann sich leicht unterscheiden, doch typischerweise findest Du darin eine Reihe von JSON-Dateien sowie eventuell weitere Dateien mit ergänzenden Informationen.
Für viele Nutzer wirkt diese Struktur zunächst etwas technisch. Doch wenn man sich einen Moment Zeit nimmt, erkennt man schnell ein Muster: Die Daten sind relativ sauber organisiert und folgen einer klaren Struktur. Das ist eine gute Nachricht, denn genau diese Struktur macht es später möglich, die Inhalte automatisiert zu verarbeiten.
Aufbau der Chatdaten
Der wichtigste Bestandteil des Exports sind die eigentlichen Chatdaten. Diese Gespräche sind in der Regel in einer oder mehreren JSON-Dateien gespeichert. JSON ist ein weit verbreitetes Datenformat, das häufig verwendet wird, um strukturierte Informationen zu speichern.
Eine solche Datei enthält nicht einfach nur einen langen Text. Stattdessen ist ein Gespräch in einzelne Elemente aufgeteilt. Typischerweise besteht ein Dialog aus mehreren Nachrichten. Jede Nachricht enthält Informationen wie:
- den eigentlichen Text der Nachricht
- die Rolle des Absenders (Nutzer oder KI)
- einen Zeitstempel
- teilweise weitere Metadaten
Dadurch lässt sich der gesamte Gesprächsverlauf rekonstruieren. Ein Dialog beginnt beispielsweise mit einer Frage des Nutzers. Darauf folgt eine Antwort der KI. Anschließend können weitere Rückfragen und Antworten folgen. Jede dieser Nachrichten wird einzeln gespeichert.
Das hat einen großen Vorteil: Wir können später genau erkennen, wer was gesagt hat und wie sich ein Gespräch entwickelt hat. Für unser Wissenssystem ist das besonders wichtig, denn wir wollen später genau diese Inhalte durchsuchen und analysieren.
Welche Daten wir wirklich brauchen
Obwohl der Export viele Informationen enthält, benötigen wir für unser Wissenssystem nicht alles. Der wichtigste Bestandteil sind die Texte der Gespräche. Diese Texte enthalten die eigentlichen Inhalte: Ideen, Analysen, Fragen und Antworten. Genau diese Inhalte wollen wir später durchsuchen.
Zusätzlich können einige Metadaten sinnvoll sein. Dazu gehören zum Beispiel:
- Zeitstempel
- Gesprächstitel
- eventuell interne Identifikationsnummern
Diese Informationen helfen uns später dabei, Inhalte besser zu sortieren oder ein Gespräch zeitlich einzuordnen. Andere Bestandteile des Exports sind für unser Projekt weniger relevant. Dazu gehören beispielsweise bestimmte technische Metadaten, die nur für die interne Funktionsweise der Plattform interessant sind.
Für den Aufbau unserer Wissensbasis konzentrieren wir uns deshalb bewusst auf das Wesentliche: die Texte der Gespräche und einige grundlegende Kontextinformationen. Je klarer wir diese Daten strukturieren, desto besser kann unsere KI später damit arbeiten.
Erste Sichtung der Daten
Bevor wir mit automatisierten Skripten arbeiten, lohnt sich ein kurzer Blick in die Daten selbst. Öffne dazu eine der JSON-Dateien mit einem einfachen Texteditor oder einem Programm, das JSON-Dateien gut darstellen kann. Viele Codeeditoren wie Visual Studio Code eignen sich dafür sehr gut, aber auch einfache Texteditoren funktionieren.
Beim ersten Blick in die Datei wirst Du vermutlich eine relativ große Menge strukturierter Daten sehen. JSON-Dateien bestehen aus verschachtelten Elementen – also Datenfeldern, die wiederum andere Felder enthalten. Das wirkt zunächst etwas komplex, doch mit etwas Geduld erkennt man schnell die grundlegende Struktur. Du wirst beispielsweise sehen, dass ein Gespräch aus mehreren Nachrichten besteht und dass jede Nachricht ein eigenes Objekt darstellt. Der eigentliche Text steht meist in einem klar erkennbaren Feld.
Diese erste Sichtung hat einen wichtigen Zweck: Sie hilft Dir zu verstehen, wie Deine Daten aufgebaut sind. Denn im nächsten Kapitel werden wir genau diese Struktur nutzen, um die Gespräche automatisiert auszulesen und für unser Wissenssystem aufzubereiten. Mit anderen Worten: Wir verwandeln jetzt ein technisches Datenarchiv Schritt für Schritt in eine nutzbare Wissensbasis. Und genau damit beginnen wir im nächsten Kapitel. Dort geht es darum, die Chatdaten zu extrahieren und so aufzubereiten, dass sie später effizient durchsucht werden können.
Daten aufbereiten: Von Gesprächen zu analysierbaren Texten
Nachdem wir im vorherigen Kapitel den ChatGPT-Datenexport entpackt und uns einen ersten Überblick über die Struktur verschafft haben, beginnt nun der eigentliche technische Teil unseres Projekts. Die exportierten Daten sind zwar vollständig vorhanden – aber in dieser Form noch nicht optimal für unser Wissenssystem geeignet.
Der Grund ist einfach: Chatverläufe sind meist lang, enthalten viele Themen und sind in einer Struktur gespeichert, die für Menschen lesbar ist, aber nicht ideal für semantische Suche oder Vektordatenbanken. Damit unsere KI später gezielt relevante Inhalte finden kann, müssen wir diese Rohdaten zuerst aufbereiten. Das bedeutet im Kern drei Dinge:
- die Gespräche aus den JSON-Dateien extrahieren
- die Texte sinnvoll strukturieren
- die Inhalte in kleinere Abschnitte aufteilen
Dieser Prozess ist ein ganz normaler Schritt in modernen KI-Systemen und wird häufig als Preprocessing bezeichnet.
Warum Rohdaten nicht direkt geeignet sind
Wenn Du einen Blick in eine der JSON-Dateien wirfst, wirst Du feststellen, dass ein einzelner Chat oft aus vielen Nachrichten besteht. Ein typischer Dialog kann zum Beispiel so aussehen:
- Frage
- Antwort
- Rückfrage
- neue Erklärung
- weiteres Detail
- Zusammenfassung
Manche Gespräche können hunderte oder sogar tausende Wörter enthalten. Für Menschen ist das kein Problem. Wir lesen einen Dialog einfach von oben nach unten.
Für eine KI-Suche funktioniert das jedoch schlechter. Der Grund liegt darin, dass ein einzelner Chat oft mehrere Themen enthält. Wenn wir später eine semantische Suche durchführen, soll das System möglichst präzise Textstellen finden – nicht ganze Gespräche mit vielen unterschiedlichen Inhalten.
Deshalb werden große Texte in kleinere Abschnitte zerlegt. Diese Abschnitte nennt man Chunks. Ein Chunk ist einfach ein kleiner Textblock, der einen zusammenhängenden Gedanken enthält. Diese Methode verbessert später die Qualität der Suche erheblich.
Chatverläufe extrahieren
Der erste praktische Schritt besteht darin, die Inhalte aus den JSON-Dateien auszulesen. Dafür verwenden wir ein kleines Python-Skript. Python eignet sich besonders gut für solche Aufgaben, weil es viele Bibliotheken für Datenverarbeitung und KI enthält.
Erstelle zunächst eine neue Datei, zum Beispiel:
extract_chats.py
Dann fügen wir ein einfaches Skript hinzu, das die Chatdaten lädt.
import json
with open("conversations.json", "r", encoding="utf-8") as f:
data = json.load(f)
print("Anzahl der Gespräche:", len(data))
Wenn Du dieses Skript ausführst, solltest Du sehen, wie viele Gespräche in Deinem Export enthalten sind. Jetzt wollen wir die eigentlichen Texte extrahieren.
texts = []
for conversation in data:
if "mapping" in conversation:
for node in conversation["mapping"].values():
message = node.get("message")
if message:
content = message.get("content")
if content and "parts" in content:
text = " ".join(content["parts"])
texts.append(text)
print("Extrahierte Textabschnitte:", len(texts))
Dieses Skript durchläuft die JSON-Struktur und sammelt alle Textteile aus den Gesprächen. Damit haben wir bereits den wichtigsten Teil geschafft: Wir haben die Inhalte aus dem technischen Exportformat herausgelöst.
Text-Chunks erzeugen
Nun kommt der nächste wichtige Schritt: das Chunking. Statt komplette Gespräche zu speichern, teilen wir die Texte in kleinere Abschnitte.
Eine typische Größe für solche Textabschnitte liegt zwischen 300 und 800 Wörtern oder ungefähr 500 Tokens. Im folgenden ein einfaches Beispiel, wie man Texte in Chunks aufteilen kann.
def split_text(text, chunk_size=500):
words = text.split()
chunks = []
for i in range(0, len(words), chunk_size):
chunk = " ".join(words[i:i+chunk_size])
chunks.append(chunk)
return chunks
Jetzt können wir diese Funktion auf unsere Texte anwenden.
all_chunks = []
for text in texts:
chunks = split_text(text)
all_chunks.extend(chunks)
print("Gesamtzahl der Chunks:", len(all_chunks))
Jetzt haben wir aus unseren Chatverläufen viele kleinere Textabschnitte erzeugt. Diese Textblöcke sind ideal für die spätere Suche in einer Vektordatenbank.
Metadaten ergänzen
Neben dem eigentlichen Text können zusätzliche Informationen sehr hilfreich sein. Diese sogenannten Metadaten helfen uns später dabei, Inhalte besser zu sortieren oder zu filtern. Typische Metadaten könnten sein:
- Datum des Gesprächs
- Gesprächstitel
- Quelle (ChatGPT Export)
- ID des Gesprächs
Wir können diese Informationen gemeinsam mit dem Text speichern, zum Beispiel so:
documents = []
for conversation in data:
title = conversation.get("title", "Unbekannt")
if "mapping" in conversation:
for node in conversation["mapping"].values():
message = node.get("message")
if message:
content = message.get("content")
if content and "parts" in content:
text = " ".join(content["parts"])
chunks = split_text(text)
for chunk in chunks:
documents.append({
"text": chunk,
"title": title
})
Damit haben wir unsere Daten bereits in eine deutlich bessere Struktur gebracht. Statt eines unübersichtlichen Chatarchivs besitzen wir nun eine Sammlung aus vielen kleinen Textabschnitten, die jeweils mit Kontextinformationen versehen sind.
Genau diese Struktur wird im nächsten Schritt entscheidend sein. Denn jetzt können wir beginnen, aus diesen Texten Embeddings zu erzeugen – also mathematische Repräsentationen der Inhalte, die später in unserer Vektordatenbank gespeichert werden. Und genau darum geht es im nächsten Kapitel.
Embeddings erzeugen
Im vorherigen Kapitel haben wir unsere ChatGPT-Daten bereits in eine brauchbare Form gebracht. Wir haben die Gespräche aus den JSON-Dateien extrahiert, die Texte bereinigt und in kleinere Abschnitte – sogenannte Chunks – aufgeteilt.
Doch damit unsere KI später wirklich sinnvoll nach Inhalten suchen kann, fehlt noch ein entscheidender Schritt. Die Texte müssen in eine Form übersetzt werden, die Maschinen vergleichen können. Hier kommen Embeddings ins Spiel.
Embeddings sind mathematische Repräsentationen von Texten. Sie ermöglichen es Computern, die Bedeutung von Texten zu vergleichen. Zwei Texte mit ähnlichem Inhalt erhalten ähnliche Vektoren – selbst wenn sie unterschiedliche Worte verwenden. Genau diese Eigenschaft brauchen wir für unser Wissenssystem. Denn unsere KI soll später nicht nur nach identischen Wörtern suchen, sondern nach inhaltlich passenden Texten.
Was Embeddings sind
Ein Embedding ist im Grunde eine Liste von Zahlen. Diese Zahlen beschreiben die Bedeutung eines Textes in einem mathematischen Raum. Jeder Text wird in einen sogenannten Vektor umgewandelt. Ein solcher Vektor kann zum Beispiel so aussehen:
[0.134, -0.876, 0.442, 0.921, -0.223, ...]
Ein einzelner Vektor kann mehrere hundert oder sogar tausend Zahlen enthalten. Diese Zahlen sind für Menschen natürlich nicht direkt verständlich. Für Maschinen sind sie jedoch ideal geeignet, um Ähnlichkeiten zwischen Texten zu berechnen. Wenn zwei Texte ähnliche Inhalte haben, liegen ihre Vektoren im mathematischen Raum näher beieinander. Ein Beispiel:
- Text A: „Wie kann ich meine ChatGPT-Daten exportieren?“
- Text B: „Wie lade ich meine ChatGPT-Gespräche herunter?“
Obwohl die Formulierungen unterschiedlich sind, beschreiben beide Texte im Grunde dasselbe Thema. Ein gutes Embedding-Modell erkennt diese Ähnlichkeit. Die beiden Texte erhalten daher ähnliche Vektoren. Genau dieses Prinzip nutzen wir später für unsere semantische Suche.
Embedding-Modelle mit Ollama
Für die Erzeugung von Embeddings benötigen wir ein spezielles Modell. Zum Glück müssen wir dafür keine externen Cloud-Dienste verwenden. Viele Embedding-Modelle lassen sich heute lokal betreiben – und genau hier kommt Ollama ins Spiel.
Da Ollama bereits auf Deinem System läuft, können wir dort ein Embedding-Modell installieren. Ein sehr gutes Modell ist zum Beispiel:
nomic-embed-text
Du kannst es mit folgendem Befehl installieren:
ollama pull nomic-embed-text
Weitere beliebte Modelle sind:
- mxbai-embed-large
- bge-large
- all-minilm
Für unsere Zwecke ist nomic-embed-text ein sehr guter Startpunkt. Dieses Modell erzeugt hochwertige Embeddings und läuft problemlos lokal.
Embeddings lokal erzeugen
Jetzt wollen wir unser Python-Skript erweitern, damit es Embeddings erzeugen kann. Zuerst installieren wir eine Bibliothek, mit der Python mit Ollama kommunizieren kann.
pip install ollama
Jetzt können wir das Embedding-Modell direkt aus Python ansprechen. Im folgenden ein einfaches Beispiel:
import ollama
response = ollama.embeddings(
model="nomic-embed-text",
prompt="Wie exportiere ich meine ChatGPT-Daten?"
)
print(len(response["embedding"]))
Wenn alles funktioniert hat, erhältst Du einen Vektor mit mehreren hundert Zahlen.
Jetzt wenden wir das auf unsere Chat-Chunks an.
embeddings = []
for doc in documents:
text = doc["text"]
result = ollama.embeddings(
model="nomic-embed-text",
prompt=text
)
vector = result["embedding"]
embeddings.append({
"text": text,
"embedding": vector,
"title": doc["title"]
})
Damit erzeugen wir für jeden Textabschnitt einen Vektor. Diese Vektoren werden später in unserer Datenbank gespeichert.
Warum dieser Schritt entscheidend ist
Embeddings sind das Herzstück moderner Wissenssysteme. Ohne Embeddings könnten wir Texte nur über klassische Stichwortsuche durchsuchen. Das würde bedeuten, dass das System nur Inhalte findet, die exakt dieselben Wörter enthalten. Doch Sprache funktioniert selten so einfach. Ein Nutzer könnte zum Beispiel fragen:
„Wie habe ich meine ChatGPT-Daten verarbeitet?“
Die ursprüngliche Unterhaltung könnte jedoch formuliert sein als:
„Wie kann ich meinen ChatGPT-Datenexport analysieren?“
Eine einfache Suche würde diese Verbindung möglicherweise nicht erkennen. Mit Embeddings ist das anders. Da beide Texte ähnliche Bedeutungen haben, liegen ihre Vektoren im mathematischen Raum nahe beieinander. Unsere Datenbank kann deshalb passende Inhalte finden, selbst wenn die Formulierungen unterschiedlich sind. Genau diese Fähigkeit macht semantische Suche so leistungsfähig. Sie erlaubt es einer KI, nicht nur nach Worten zu suchen, sondern nach Bedeutung.
Und genau deshalb sind Embeddings der zentrale Baustein unseres Systems. Im nächsten Kapitel bauen wir darauf auf und installieren unsere Vektordatenbank. Dort werden wir die erzeugten Vektoren speichern – und damit die Grundlage für unsere persönliche Wissens-KI schaffen.
Qdrant installieren und konfigurieren
Nachdem wir im vorherigen Kapitel die Embeddings für unsere Chatdaten erzeugt haben, besitzen wir nun eine Sammlung von Textabschnitten und zugehörigen Vektoren. Diese Vektoren beschreiben die Bedeutung der Texte mathematisch und bilden damit die Grundlage für eine semantische Suche. Doch aktuell liegen diese Daten nur im Arbeitsspeicher unseres Skripts oder in einfachen Listen vor. Damit unsere KI später effizient darauf zugreifen kann, benötigen wir einen spezialisierten Speicher.
Genau hier kommt eine Vektordatenbank ins Spiel. Eine Vektordatenbank ist darauf optimiert, große Mengen solcher Embeddings zu speichern und schnell nach ähnlichen Vektoren zu suchen. Für unser Projekt verwenden wir Qdrant, eine moderne Open-Source-Datenbank, die speziell für KI-Anwendungen entwickelt wurde.
In diesem Kapitel installieren wir Qdrant, starten den Server und bereiten die Datenbank so vor, dass wir unsere Chatdaten später problemlos importieren können.
Was Qdrant ist
Qdrant ist eine spezialisierte Datenbank für sogenannte Vektorsuchen. Während klassische Datenbanken Informationen in Tabellen speichern – etwa Namen, Zahlen oder Texte – arbeitet eine Vektordatenbank mit mathematischen Repräsentationen von Daten.
Das bedeutet: Statt nur Text zu speichern, speichert Qdrant die zugehörigen Embeddings. Der große Vorteil liegt in der Suche. Wenn später eine Frage gestellt wird, wandelt unser System diese Frage ebenfalls in einen Vektor um. Qdrant kann dann blitzschnell berechnen, welche gespeicherten Texte diesem Vektor am ähnlichsten sind. Damit lässt sich beispielsweise herausfinden:
- welche Chatpassagen thematisch zur Frage passen
- welche früheren Gespräche ähnliche Inhalte enthalten
- welche Ideen in Deinem Archiv relevant sein könnten
Genau deshalb wird Qdrant heute in vielen modernen KI-Systemen eingesetzt – von Dokumentensuchen bis hin zu komplexen Wissensassistenten. Ein weiterer Vorteil: Qdrant ist Open Source, schnell installiert und läuft problemlos auf einer normalen lokalen Maschine.
Installation von Qdrant
Der einfachste Weg, Qdrant zu installieren, führt über Docker. Falls Docker auf Deiner Maschine vorhanden ist, kannst Du den Server mit einem einzigen Befehl starten. Hier kannst Du Docker herunterladen, falls Du es noch nicht auf Deinem Computer installiert haben solltest.
docker run -p 6333:6333 qdrant/qdrant
Dieser Befehl startet den Qdrant-Server und öffnet den Standard-Port 6333. Über diesen Port können später unsere Skripte mit der Datenbank kommunizieren.
Falls Du Docker nicht verwenden möchtest, gibt es auch andere Möglichkeiten, Qdrant zu installieren, etwa über ein lokales Binary oder über Paketmanager. In vielen Praxisprojekten hat sich jedoch Docker als die einfachste und stabilste Variante erwiesen.
Nachdem der Server gestartet wurde, läuft Qdrant im Hintergrund und wartet auf Anfragen. Du kannst nun testen, ob der Server erreichbar ist. Öffne dazu im Browser folgende Adresse:
http://localhost:6333
Wenn alles funktioniert hat, sollte eine einfache Statusmeldung erscheinen. Damit ist der Server bereit für die nächsten Schritte.
Erste Schritte mit Qdrant
Bevor wir unsere Chatdaten importieren können, müssen wir eine sogenannte Collection erstellen. Eine Collection ist in Qdrant vergleichbar mit einer Tabelle in einer klassischen Datenbank. Sie enthält unsere Vektoren und die dazugehörigen Daten.
Zuerst installieren wir die Python-Bibliothek für Qdrant:
pip install qdrant-client
Jetzt können wir in unserem Python-Skript eine Verbindung zur Datenbank herstellen.
from qdrant_client import QdrantClient
client = QdrantClient("localhost", port=6333)
Wenn dieser Code ohne Fehlermeldung ausgeführt wird, ist die Verbindung erfolgreich. Nun erstellen wir eine Collection für unsere Chatdaten.
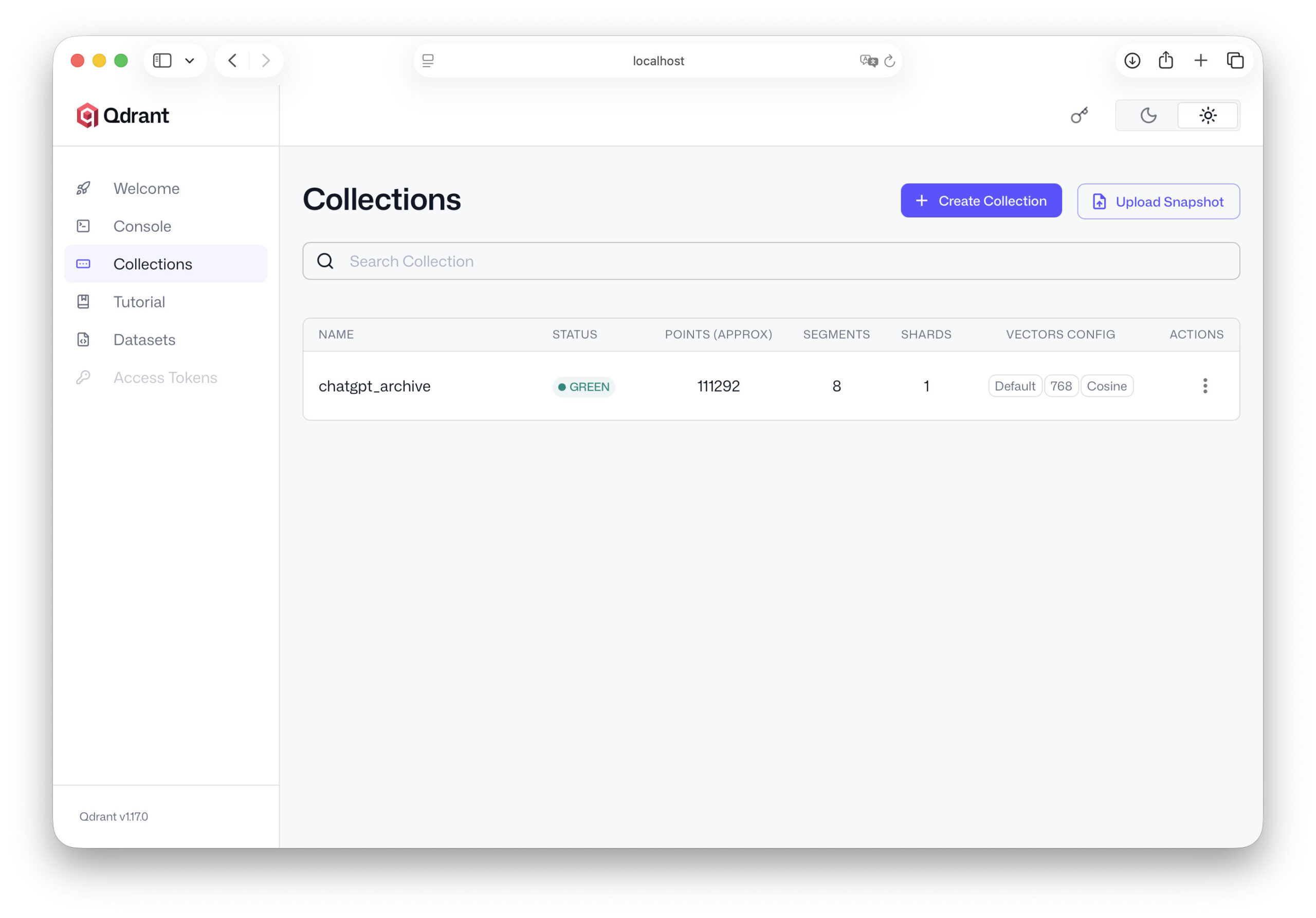
from qdrant_client.models import VectorParams, Distance client.recreate_collection( collection_name="chatgpt_archive", vectors_config=VectorParams(size=768, distance=Distance.COSINE), )
Die wichtigsten Parameter sind hier:
- collection_name – der Name unserer Datenbank
- size – die Länge der Embedding-Vektoren
- distance – die Methode zur Ähnlichkeitsberechnung
Die Vektorgröße hängt vom verwendeten Embedding-Modell ab. Viele Modelle arbeiten mit Vektoren von 768 oder 1024 Dimensionen. Die Distanzfunktion Cosine ist eine der gängigsten Methoden, um Ähnlichkeiten zwischen Texten zu berechnen. Damit ist unsere Datenbank bereits einsatzbereit.
Datenstruktur planen
Bevor wir unsere Daten importieren, lohnt sich ein kurzer Blick auf die Struktur, die wir speichern wollen. Jeder Eintrag in unserer Vektordatenbank wird aus mehreren Bestandteilen bestehen:
- ID – eine eindeutige Kennung
- Embedding – der Vektor des Textes
- Payload – zusätzliche Informationen über den Text
Die Payload kann zum Beispiel enthalten:
- den Originaltext
- den Titel des Gesprächs
- das Datum
- andere Metadaten
Ein Beispiel für einen Datensatz könnte so aussehen:
{
"id": 1,
"vector": [0.123, -0.452, 0.889, ...],
"payload": {
"text": "Wie kann ich meinen ChatGPT-Datenexport analysieren?",
"title": "Datenanalyse"
}
}
Diese Struktur hat einen großen Vorteil. Die Vektoren werden für die semantische Suche verwendet, während die Payload alle Informationen enthält, die wir später anzeigen oder analysieren möchten. Dadurch bleibt unser System flexibel und lässt sich später leicht erweitern.
Damit ist der wichtigste Teil der Infrastruktur bereits vorbereitet. Unser Qdrant-Server läuft, die Datenbank ist eingerichtet und wir wissen, welche Struktur unsere Daten haben werden. Im nächsten Kapitel beginnen wir mit dem entscheidenden Schritt: Wir importieren unsere ChatGPT-Daten in die Datenbank und verwandeln unser Archiv aus Gesprächen in eine echte, durchsuchbare Wissensbasis.
ChatGPT-Daten in Qdrant importieren
Nachdem wir im vorherigen Kapitel Qdrant installiert und eine Collection angelegt haben, ist die technische Grundlage für unsere Wissensdatenbank geschaffen. Unsere Embeddings existieren bereits – wir haben sie aus den ChatGPT-Daten erzeugt – und Qdrant läuft als Datenbankserver auf unserer Maschine.
Jetzt folgt der entscheidende Schritt: Wir laden unsere Daten in die Datenbank. Dabei speichern wir nicht nur die Vektoren selbst, sondern auch die zugehörigen Texte und Metadaten. Diese Kombination erlaubt es unserer KI später, relevante Inhalte zu finden und sie in Antworten zu verwenden. In diesem Kapitel bauen wir also die eigentliche Wissensbasis unseres Systems auf.
Embeddings speichern
Zunächst müssen wir unsere erzeugten Embeddings in die Datenbank übertragen. Jeder Eintrag in Qdrant besteht aus drei Bestandteilen:
- einer ID
- einem Vektor (Embedding)
- einer Payload mit zusätzlichen Daten
Die Payload enthält in unserem Fall beispielsweise:
- den Textabschnitt
- den Titel des Gesprächs
- eventuell weitere Metadaten
In Python können wir diese Struktur relativ einfach vorbereiten. Ein Beispiel:
points = []
for idx, item in enumerate(embeddings):
points.append({
"id": idx,
"vector": item["embedding"],
"payload": {
"text": item["text"],
"title": item["title"]
}
})
Damit erzeugen wir eine Liste von Datenpunkten, die wir anschließend in Qdrant speichern können. Jeder Datenpunkt enthält also einen Textabschnitt, den zugehörigen Vektor und zusätzliche Kontextinformationen. Diese Struktur bildet später die Grundlage unserer semantischen Suche.
Import-Skript erstellen
Jetzt verbinden wir unser Python-Skript mit Qdrant und übertragen die Daten. Dazu nutzen wir den Qdrant Python Client, den wir im vorherigen Kapitel installiert haben. Der Import kann beispielsweise so aussehen:
from qdrant_client import QdrantClient
from qdrant_client.models import PointStruct
client = QdrantClient("localhost", port=6333)
points = []
for idx, item in enumerate(embeddings):
point = PointStruct(
id=idx,
vector=item["embedding"],
payload={
"text": item["text"],
"title": item["title"]
}
)
points.append(point)
client.upsert(
collection_name="chatgpt_archive",
points=points
)
print("Import abgeschlossen:", len(points), "Datensätze gespeichert.")
Der Befehl upsert sorgt dafür, dass die Daten in der Collection gespeichert werden. Falls eine ID bereits existiert, wird der Eintrag aktualisiert. Andernfalls wird ein neuer Datensatz angelegt. Je nach Größe Deines ChatGPT-Exports kann dieser Import einige Sekunden oder Minuten dauern. Bei größeren Datensätzen – etwa mehreren tausend Textabschnitten – ist das völlig normal.
Datenbank testen
Nachdem der Import abgeschlossen ist, sollten wir überprüfen, ob unsere Daten korrekt gespeichert wurden. Der einfachste Test besteht darin, eine Vektorsuche durchzuführen. Dazu erzeugen wir zunächst ein Embedding für eine Testfrage.
query = "Wie kann ich ChatGPT-Daten analysieren?" query_vector = ollama.embeddings( model="nomic-embed-text", prompt=query )["embedding"]
Jetzt können wir Qdrant nach ähnlichen Vektoren durchsuchen.
search_result = client.search( collection_name="chatgpt_archive", query_vector=query_vector, limit=3 )
Dieser Befehl gibt uns die drei ähnlichsten Textabschnitte aus unserer Datenbank zurück. Wir können sie beispielsweise so ausgeben:
for result in search_result:
print(result.payload["text"])
print("---")
Wenn alles funktioniert hat, erscheinen jetzt Chatabschnitte aus Deinem Archiv, die thematisch zur Suchanfrage passen. Damit wissen wir: Unsere Datenbank funktioniert.
Erste Erfolgskontrolle
Dieser Moment ist einer der spannendsten Punkte des gesamten Projekts. Zum ersten Mal wird sichtbar, dass unser Chatarchiv tatsächlich als Wissensquelle genutzt werden kann. Du kannst jetzt verschiedene Suchanfragen ausprobieren. Zum Beispiel:
- „KI Artikel“
- „RAG System“
- „ChatGPT Datenexport“
- „Strategie Idee“
Je nach Inhalt Deiner Chatverläufe wird Qdrant passende Textstellen finden. Manchmal wirst Du überrascht sein, welche Inhalte wieder auftauchen. Gespräche, die Du längst vergessen hast, können plötzlich wieder relevant werden. Das zeigt sehr deutlich, warum ein solcher Ansatz so interessant ist. Deine alten KI-Gespräche sind nicht mehr nur ein Archiv. Sie werden zu einer durchsuchbaren Wissensbasis.
Damit haben wir einen wichtigen Meilenstein erreicht. Unsere ChatGPT-Daten sind jetzt vollständig in der Vektordatenbank gespeichert und können semantisch durchsucht werden. Im nächsten Kapitel gehen wir noch einen Schritt weiter: Wir verbinden unsere Wissensdatenbank mit der KI selbst. Dadurch kann das Sprachmodell künftig auf diese Daten zugreifen und sie direkt in Antworten einbauen.
Die KI mit der Wissensdatenbank verbinden
Bis hierhin haben wir bereits einen großen Teil der Infrastruktur aufgebaut. Unsere ChatGPT-Daten wurden aus dem Export extrahiert, in kleinere Textabschnitte zerlegt, mit Embeddings versehen und schließlich in der Vektordatenbank Qdrant gespeichert.
Doch bisher arbeitet unsere KI noch nicht mit diesen Daten. Wir können zwar über Python eine Vektorsuche durchführen und passende Textabschnitte finden – aber die KI selbst weiß davon noch nichts. Wenn wir ihr eine Frage stellen, nutzt sie weiterhin nur ihr allgemeines Sprachwissen.
Der nächste Schritt besteht also darin, diese beiden Welten zu verbinden. Wir bauen jetzt einen Ablauf, bei dem die KI zuerst relevante Inhalte aus der Wissensdatenbank erhält und diese anschließend in ihre Antwort einbezieht. Genau das ist der Kern eines RAG-Systems.
Anfrageprozess
Der Ablauf einer Anfrage verändert sich durch unser Wissenssystem leicht. Bisher lief ein Gespräch mit einer KI normalerweise so ab:
- Du stellst eine Frage →
- die KI verarbeitet die Frage →
- die KI erzeugt eine Antwort.
Mit einer Wissensdatenbank kommt ein zusätzlicher Schritt hinzu. Der neue Ablauf sieht so aus:
- Du stellst eine Frage →
- die Frage wird in ein Embedding umgewandelt →
- die Vektordatenbank sucht nach ähnlichen Texten →
- diese Texte werden der KI als Kontext übergeben →
die KI formuliert eine Antwort. Das bedeutet: Die KI arbeitet nicht mehr nur mit ihrem trainierten Wissen, sondern zusätzlich mit Deinen eigenen Daten. Dieser Kontext macht Antworten oft deutlich präziser und persönlicher.
Retrieval-Schritt
Der erste Teil dieses Prozesses wird als Retrieval bezeichnet. Retrieval bedeutet einfach „Abrufen“. In diesem Schritt sucht unser System in der Datenbank nach Inhalten, die thematisch zur Frage passen. Zuerst erzeugen wir wieder ein Embedding für die aktuelle Frage.
query = "Welche Ideen hatte ich zur Nutzung meines ChatGPT-Datenexports?" query_vector = ollama.embeddings( model="nomic-embed-text", prompt=query )["embedding"]
Dieses Embedding beschreibt die Bedeutung der Frage in mathematischer Form. Nun kann Qdrant nach ähnlichen Vektoren suchen.
results = client.search( collection_name="chatgpt_archive", query_vector=query_vector, limit=5 )
Die Datenbank gibt jetzt die fünf Textabschnitte zurück, die am besten zur Frage passen. Diese Textstellen bilden den Kontext für die KI. Wir sammeln sie in einer Liste.
context_texts = [] for r in results: context_texts.append(r.payload["text"])
Jetzt besitzen wir eine Sammlung relevanter Inhalte aus unserem Chatarchiv.
Kontext an Ollama übergeben
Nun kommt der entscheidende Schritt. Wir übergeben diesen Kontext gemeinsam mit der ursprünglichen Frage an unser Sprachmodell. Das Modell kann diese Informationen nun nutzen, um eine Antwort zu formulieren.
Zuerst bauen wir einen sogenannten Prompt. Ein Prompt ist einfach der Text, den wir an die KI senden.
context = "\n\n".join(context_texts)
prompt = f"""
Du bist ein KI-Assistent, der mit meinem persönlichen Wissensarchiv arbeitet.
Nutze die folgenden Textausschnitte als Kontext:
{context}
Beantworte nun diese Frage:
{query}
"""
Jetzt senden wir diesen Prompt an unser Sprachmodell in Ollama.
response = ollama.chat(
model="llama3",
messages=[
{"role": "user", "content": prompt}
]
)
print(response["message"]["content"])
Die KI erhält nun sowohl die Frage als auch die relevanten Textstellen aus unserer Datenbank. Dadurch kann sie Antworten erzeugen, die auf unseren eigenen Daten basieren.
Antwortgenerierung
Der letzte Schritt ist die eigentliche Antwortgenerierung. Das Sprachmodell kombiniert jetzt zwei Wissensquellen:
sein eigenes trainiertes Wissen
den Kontext aus unserer Wissensdatenbank
Diese Kombination ist besonders leistungsfähig. Das Modell kann allgemeine Zusammenhänge erklären und gleichzeitig konkrete Inhalte aus unserem Archiv einbeziehen. Ein Beispiel: Wenn Du fragst:
„Welche Ideen hatte ich zur Nutzung meines ChatGPT-Datenexports?“
kann die KI jetzt auf frühere Gespräche zugreifen und daraus eine strukturierte Zusammenfassung erstellen. Sie könnte beispielsweise antworten:
- Du hast darüber gesprochen, ein persönliches Wissensarchiv aufzubauen
- Du wolltest eine lokale KI mit RAG-System entwickeln
- Du hast die Idee einer Artikelserie entwickelt
Ohne den Retrieval-Schritt hätte die KI diese Informationen gar nicht gekannt. Mit unserem System wird Dein Chatarchiv zu einer echten Wissensquelle. Damit ist der wichtigste Teil unseres Systems vollständig aufgebaut. Wir haben jetzt:
- eine lokale KI über Ollama
- eine Vektordatenbank mit unseren Chatdaten
- eine semantische Suche
- einen RAG-Workflow
Im nächsten Kapitel werden wir dieses System in der Praxis testen und sehen, wie gut unsere persönliche Wissens-KI tatsächlich funktioniert.
Erste Abfragen mit Deiner persönlichen Wissens-KI
Nachdem wir im vorherigen Kapitel die Verbindung zwischen unserer KI und der Wissensdatenbank hergestellt haben, ist das System technisch vollständig aufgebaut. Unsere ChatGPT-Daten befinden sich in der Vektordatenbank, die KI kann relevante Inhalte abrufen, und der gesamte Ablauf eines RAG-Systems funktioniert.
Jetzt kommt der spannendste Teil des Projekts: die ersten echten Abfragen. Denn erst jetzt zeigt sich, ob unser System tatsächlich das tut, was wir uns erhofft haben – nämlich frühere Gespräche zu finden, Inhalte zu analysieren und daraus sinnvolle Antworten zu erzeugen. In diesem Kapitel testen wir unsere Wissens-KI, schauen uns typische Anwendungsfälle an und werfen einen Blick auf mögliche Optimierungen.
Beispielabfragen
Beginnen wir mit einigen einfachen Fragen. Eine gute Strategie besteht darin, zunächst Fragen zu stellen, von denen Du weißt, dass sie in Deinem Chatarchiv vorkommen. Zum Beispiel:
„Welche Ideen hatte ich zur Nutzung meines ChatGPT-Datenexports?“
„Was habe ich über RAG-Systeme geschrieben?“
„Welche Strategien habe ich zur Nutzung von KI diskutiert?“
Diese Fragen enthalten bewusst offene Formulierungen. Das Ziel ist nicht, einen bestimmten Text wiederzufinden, sondern thematisch passende Inhalte zu entdecken. Wenn Du nun eine solche Frage an Dein System stellst, passiert im Hintergrund der Ablauf, den wir im vorherigen Kapitel aufgebaut haben:
- Die Frage wird in ein Embedding umgewandelt.
- Die Vektordatenbank sucht nach ähnlichen Textabschnitten.
- Diese Textstellen werden als Kontext an die KI übergeben.
- Die KI erzeugt eine Antwort auf Basis dieses Kontextes.
Das Ergebnis kann überraschend sein. Oft tauchen dabei Gespräche auf, die Du längst vergessen hast. Alte Ideen erscheinen plötzlich wieder auf dem Bildschirm – manchmal sogar in einem völlig neuen Zusammenhang.
Genau darin liegt die Stärke dieses Ansatzes. Dein Chatarchiv wird zu einer durchsuchbaren Wissensquelle.
Qualität der Antworten
Wenn Du einige Abfragen ausprobierst, wirst Du feststellen, dass die Qualität der Antworten variieren kann. Das ist völlig normal. Die Qualität eines solchen Systems hängt von mehreren Faktoren ab. Ein wichtiger Faktor ist die Größe der Text-Chunks. Wenn die Abschnitte zu groß sind, enthalten sie möglicherweise mehrere Themen. Dadurch wird die Suche ungenauer.
Sind die Chunks hingegen zu klein, fehlt manchmal der notwendige Kontext. Ein weiterer Faktor ist das Embedding-Modell. Verschiedene Modelle erkennen Bedeutungszusammenhänge unterschiedlich gut. Manche sind besonders gut für technische Texte geeignet, andere für allgemeine Sprache.
Auch die Anzahl der abgerufenen Ergebnisse spielt eine Rolle. Wenn Du beispielsweise nur zwei Textstellen abrufst, kann es sein, dass wichtige Informationen fehlen. Werden hingegen zu viele Texte geladen, kann die KI Schwierigkeiten haben, den relevanten Kontext zu erkennen.
Diese Parameter lassen sich später leicht anpassen. Das Wichtigste ist zunächst, ein funktionierendes Grundsystem zu besitzen.
Typische Probleme
Wie bei jedem technischen System können auch hier einige Schwierigkeiten auftreten. Ein häufiges Problem besteht darin, dass die Datenbank Texte findet, die nur teilweise relevant sind. Das liegt daran, dass semantische Suche immer mit Wahrscheinlichkeiten arbeitet.
Ein anderes Problem kann entstehen, wenn Texte zu stark fragmentiert wurden. Wenn ein Gedanke auf mehrere Chunks verteilt ist, kann die KI Schwierigkeiten haben, den Zusammenhang zu erkennen.
Auch der Prompt spielt eine Rolle. Wenn der Prompt unklar formuliert ist, nutzt die KI den Kontext möglicherweise nicht optimal. Ein Beispiel für einen besseren Prompt könnte so aussehen:
Nutze die folgenden Textausschnitte aus meinem Wissensarchiv,
um die Frage möglichst präzise zu beantworten.
Wenn relevante Inhalte vorhanden sind, fasse sie zusammen.
Solche kleinen Anpassungen können die Qualität der Antworten deutlich verbessern.
Feintuning
Sobald das System grundsätzlich funktioniert, beginnt der interessanteste Teil: das Feintuning. Hier kannst Du experimentieren und Dein Wissenssystem Schritt für Schritt verbessern. Einige typische Optimierungen sind:
- Anpassung der Chunk-Größe
Manchmal liefern kleinere Textabschnitte bessere Ergebnisse. In anderen Fällen ist mehr Kontext sinnvoll. - Verwendung eines anderen Embedding-Modells
Ein Wechsel des Modells kann die Qualität der semantischen Suche erheblich verbessern. - Mehr Kontext für die KI
Du kannst mehr Ergebnisse aus der Datenbank abrufen, zum Beispiel statt fünf gleich zehn Textstellen. - Metadaten nutzen
Wenn Du zusätzliche Informationen speicherst – etwa Datum oder Gesprächstitel – kannst Du die Suche später genauer filtern.
Diese Anpassungen sind Teil jedes realen RAG-Systems. Es gibt selten eine perfekte Einstellung für alle Situationen. Doch genau darin liegt auch der Reiz solcher Systeme: Sie lassen sich kontinuierlich verbessern.
Mit diesem Kapitel haben wir den ersten vollständigen Test unseres Systems durchgeführt. Wir haben gesehen, dass unsere persönliche Wissens-KI tatsächlich in der Lage ist, alte Gespräche zu durchsuchen und relevante Inhalte wiederzufinden.
Damit ist der Kern unseres Projekts bereits erreicht. Doch das System lässt sich noch erheblich erweitern. Im nächsten Kapitel schauen wir uns deshalb an, wie Du weitere Datenquellen integrieren und Dein persönliches Wissensarchiv Schritt für Schritt ausbauen kannst.



Erweiterungen für Dein persönliches KI-Wissenssystem
Mit dem bisherigen Aufbau hast Du bereits ein funktionierendes System geschaffen. Deine ChatGPT-Daten wurden extrahiert, in Embeddings umgewandelt, in Qdrant gespeichert und schließlich mit einer lokalen KI verbunden. Das Ergebnis ist eine Wissens-KI, die auf frühere Gespräche zugreifen kann.
Doch genau genommen stehen wir erst am Anfang. Die Architektur, die Du aufgebaut hast, ist nicht auf ChatGPT-Daten beschränkt. Sie funktioniert mit jeder Art von Text. Alles, was sich in Dokumente oder Textdateien umwandeln lässt, kann Teil dieses Wissenssystems werden. Genau hier liegt das eigentliche Potenzial solcher Systeme.
Was wir im Grunde gebaut haben, ist eine persönliche Wissensmaschine. Und diese Maschine lässt sich Schritt für Schritt erweitern. In diesem Kapitel schauen wir uns an, welche Möglichkeiten sich daraus ergeben und wie Du Dein System langfristig ausbauen kannst.
Weitere Datenquellen integrieren
Der offensichtlichste nächste Schritt besteht darin, weitere Inhalte in Deine Wissensdatenbank aufzunehmen. ChatGPT-Gespräche sind ein guter Anfang, aber sie bilden meist nur einen Teil des eigenen Wissens ab. Viele Informationen liegen in anderen Formaten vor. Zum Beispiel:
- eigene Artikel
- Notizen
- PDF-Dokumente
- Forschungsunterlagen
- E-Books
- Protokolle oder Ideenlisten
All diese Inhalte können auf die gleiche Weise verarbeitet werden wie unsere Chatdaten. Der Ablauf bleibt identisch:
- Text extrahieren
- Text in Chunks aufteilen
- Embeddings erzeugen
- Daten in Qdrant speichern
Ein Beispiel: Wenn Du viele eigene Artikel geschrieben hast, kannst Du diese Texte in Deine Wissensdatenbank importieren. Die KI kann später darauf zugreifen und Zusammenhänge erkennen. Du könntest zum Beispiel fragen:
„Welche Artikel habe ich über KI geschrieben?“
oder
„Welche Argumente habe ich früher zu diesem Thema entwickelt?“
Die KI durchsucht dann Dein Artikelarchiv und nutzt die gefundenen Inhalte als Kontext. Auf diese Weise wächst Dein System Schritt für Schritt zu einem umfassenden Wissensarchiv.
Mehrere Wissensdatenbanken
Mit zunehmender Datenmenge kann es sinnvoll sein, verschiedene Bereiche zu trennen. Qdrant erlaubt es, mehrere Collections anzulegen. Jede Collection kann eine eigene Wissensbasis darstellen. Ein mögliches System könnte zum Beispiel so aussehen:
- Collection 1: ChatGPT-Gespräche
- Collection 2: Artikelarchiv
- Collection 3: persönliche Notizen
- Collection 4: technische Dokumentation
Diese Trennung hat mehrere Vorteile. Erstens bleibt die Struktur übersichtlich. Du weißt jederzeit, wo bestimmte Inhalte gespeichert sind. Zweitens lassen sich Abfragen gezielter steuern. Manche Fragen sollen vielleicht nur Dein Artikelarchiv durchsuchen, andere wiederum Dein gesamtes Wissenssystem. Ein Beispiel:
- Eine Frage zur Recherche könnte nur das Artikelarchiv durchsuchen.
- Eine strategische Frage könnte dagegen alle Collections gleichzeitig berücksichtigen.
Solche Strukturen machen größere Wissenssysteme deutlich leistungsfähiger.
Automatische Updates
Ein weiterer sinnvoller Schritt besteht darin, Dein System regelmäßig zu aktualisieren. Im bisherigen Beispiel haben wir den ChatGPT-Datenexport einmal verarbeitet. In der Praxis entstehen jedoch ständig neue Inhalte.
Neue Gespräche, neue Notizen, neue Dokumente – all diese Informationen könnten ebenfalls Teil Deines Wissensarchivs werden.
Deshalb lohnt es sich, über automatische Updates nachzudenken. Eine einfache Lösung besteht darin, regelmäßig neue Daten zu importieren. Zum Beispiel:
- einmal pro Woche neue Chatdaten verarbeiten
- neue Dokumente automatisch einlesen
- neue Artikel sofort in die Datenbank übernehmen
Technisch lässt sich das relativ leicht umsetzen. Ein kleines Skript kann regelmäßig prüfen, ob neue Dateien vorhanden sind, und diese automatisch verarbeiten. Damit wächst Dein Wissenssystem kontinuierlich weiter. Im Laufe der Zeit entsteht so ein immer umfangreicheres Archiv, das Deine Gedanken und Projekte dokumentiert.
Integration in eigene Anwendungen
Die bisherige Nutzung unseres Systems erfolgt über einfache Python-Skripte. Doch langfristig lässt sich dieses System auch in eigene Anwendungen integrieren. Viele Entwickler bauen beispielsweise kleine Weboberflächen, über die sie ihre Wissens-KI direkt nutzen können.
Statt ein Skript zu starten, kannst Du dann einfach eine Frage in ein Eingabefeld schreiben. Im Hintergrund läuft derselbe Prozess:
- Embedding erzeugen
- Datenbank durchsuchen
- Kontext an die KI übergeben
- Antwort generieren
Das Ergebnis erscheint dann direkt in der Oberfläche. Eine solche Anwendung kann sehr unterschiedliche Formen annehmen. Zum Beispiel:
- eine persönliche Recherche-KI
- ein Wissensassistent für Projekte
- eine Ideensuchmaschine
- ein Archiv für Artikel und Notizen
Besonders spannend wird es, wenn man diese Systeme mit anderen Werkzeugen kombiniert. Ein Beispiel: Ein Redaktionssystem könnte automatisch auf Dein Wissensarchiv zugreifen und frühere Artikel als Recherchegrundlage nutzen. Oder ein Notizsystem könnte neue Ideen automatisch in Deine Datenbank integrieren.
Mit anderen Worten: Die KI wird Teil Deiner täglichen Arbeitsumgebung. Damit wird deutlich, dass unser kleines Projekt weit über den ursprünglichen ChatGPT-Datenexport hinausgeht.
Wir haben nicht nur ein Archiv aufgebaut. Wir haben eine Architektur geschaffen, die sich beliebig erweitern lässt. Und genau darin liegt der eigentliche Wert solcher Systeme. Sie sind nicht statisch. Sie wachsen mit Deinem Wissen.
Erweiterte Version der Pipeline zum Download
Das folgende Skript ist eine erweiterte Version der Pipeline aus dem Artikel. Es ist robuster und deutlich näher an einer produktiven Lösung. Drei Dinge wurden verbessert:
- Fortschrittsanzeige: Der Nutzer sieht jederzeit, wie viele Texte bereits verarbeitet wurden.
- Batch-Import: Embeddings werden gesammelt und blockweise in Qdrant geschrieben, was deutlich schneller ist als Einzelimporte.
- schnellere Embedding-Pipeline: Das Skript arbeitet strukturiert mit vorbereiteten Chunks und reduziert unnötige Aufrufe.
Damit eignet sich dieses Skript besonders gut, wenn der ChatGPT-Export größer ist – etwa mehrere tausend Gespräche. Typischer Ablauf:
- ChatGPT-Export laden
- Texte extrahieren
- Text in Chunks teilen
- Embeddings erzeugen
- Batchweise in Qdrant importieren
- Testabfrage durchführen
Wichtige Einstellungen im Skript
Einige Werte müssen durch den Nutzer angepasst werden:
- EXPORT_PFAD
Pfad zu den meist nummerierten Dateien conversations.json aus dem ChatGPT-Export. - COLLECTION_NAME
Name der Vektordatenbank-Collection. - EMBED_MODEL
Embedding-Modell von Ollama, z. B. nomic-embed-text oder mxbai-embed-large - ANSWER_MODEL
Sprachmodell für die Testabfrage, z.B. llama, mistral oder gpt:oss - VECTOR_SIZE
Dimension des Embedding-Modells.
nomic-embed-text → 768
mxbai-embed-large → 1024 - CHUNK_SIZE
Größe der Textabschnitte.
Typisch sind 300–600 Wörter. - BATCH_SIZE
Wie viele Embeddings gleichzeitig in Qdrant geschrieben werden.
Typischer Wert: 50–200.
Bleib auf dem Laufenden – ohne Werbung
Wenn Du über Updates zu diesem Skript oder über neue Downloads informiert bleiben möchtest, kannst Du Dich in meinen monatlichen Newsletter eintragen. Der Newsletter ist bewusst schlank gehalten, komplett werbefrei und erscheint nur einmal im Monat. Darin findest Du eine Auswahl der wichtigsten neuen Artikel, praxisnahe Inhalte rund um KI, Software und Digitalisierung sowie Hinweise auf aktualisierte Skripte oder neue Download-Angebote. Kein Spam, keine täglichen Mails – nur die relevantesten Inhalte in kompakter Form. Wenn Du diese Entwicklungen kontinuierlich verfolgen möchtest, ist der Newsletter die einfachste Möglichkeit, auf dem aktuellen Stand zu bleiben.
Ausblick auf Teil 3: Feinschliff, Analyse und optimale Nutzung der Daten
Im dritten Teil der Serie gehen wir einen Schritt weiter und schauen uns an, was sich konkret aus der aufgebauten Wissensdatenbank herausholen lässt. Nachdem die ChatGPT-Daten nun in Qdrant gespeichert sind, steht die eigentliche Nutzung im Mittelpunkt. Wir werfen einen Blick auf die Qdrant-Weboberfläche, analysieren die gespeicherten Daten und prüfen, wie gut die semantische Suche bereits funktioniert. Darüber hinaus geht es um wichtige Feinjustierungen: Wie sollte das Chunking je nach Anwendungsfall gewählt werden? Wie lässt sich der Kontext optimal an ein lokales Sprachmodell übergeben? Und wie kann man die Qualität der Antworten gezielt verbessern? Der dritte Teil richtet sich an alle, die aus dem System mehr herausholen und es bewusst weiterentwickeln möchten.


Häufig gestellte Fragen
- Was bringt es mir überhaupt, meinen ChatGPT-Datenexport in eine eigene KI zu integrieren?
Der größte Vorteil liegt darin, dass Du Deine eigenen Gespräche und Gedanken dauerhaft nutzbar machst. Viele Menschen führen mit KI-Systemen intensive Gespräche über Projekte, Ideen, Analysen oder persönliche Fragestellungen. Diese Inhalte verschwinden normalerweise im Verlauf der Plattform. Wenn Du sie jedoch exportierst und in eine eigene Wissensdatenbank integrierst, entsteht daraus ein persönliches Archiv. Deine lokale KI kann dann auf diese Inhalte zugreifen, Zusammenhänge erkennen und Dir bei neuen Fragen helfen. Statt immer wieder bei Null anzufangen, baust Du Schritt für Schritt auf Deinem eigenen Denken auf. - Ist das nicht sehr kompliziert für jemanden, der kein Entwickler ist?
Auf den ersten Blick wirken Begriffe wie Embeddings, Vektordatenbanken oder RAG-Systeme komplex. In der Praxis sind die einzelnen Schritte jedoch relativ klar strukturiert. Du benötigst im Grunde nur drei Komponenten: eine lokale KI (zum Beispiel über Ollama), eine Vektordatenbank wie Qdrant und ein kleines Python-Skript, das Deine Daten verarbeitet. Viele der Schritte laufen automatisch ab. Sobald das System einmal eingerichtet ist, funktioniert es wie eine normale Suchmaschine oder ein Chatbot – nur dass er mit Deinem eigenen Wissen arbeitet. - Welche Daten enthält der ChatGPT-Export eigentlich genau?
Der ChatGPT-Export enthält in der Regel alle Gespräche, die Du mit dem System geführt hast. Dazu gehören nicht nur die Textnachrichten selbst, sondern auch Metadaten wie Gesprächstitel, Zeitstempel und Strukturinformationen. Die Daten liegen meistens im JSON-Format vor und lassen sich deshalb relativ einfach mit Skripten verarbeiten. In vielen Fällen umfasst der Export auch Medien oder Sprachdateien, sofern diese in den Gesprächen verwendet wurden. Für den Aufbau einer Wissensdatenbank sind jedoch vor allem die Textinhalte interessant. - Warum verwendet man für solche Systeme eine Vektordatenbank und keine normale Datenbank?
Normale Datenbanken sind hervorragend geeignet, wenn man nach konkreten Begriffen oder IDs sucht. Für semantische Suche sind sie jedoch weniger geeignet. Eine Vektordatenbank speichert Texte nicht nur als Zeichenketten, sondern als mathematische Vektoren, die die Bedeutung eines Textes beschreiben. Dadurch kann das System nach inhaltlicher Ähnlichkeit suchen. Wenn Du zum Beispiel nach „KI-Artikelideen“ fragst, kann die Datenbank auch Inhalte finden, in denen andere Formulierungen wie „Themen für Blogartikel über künstliche Intelligenz“ vorkommen. - Was sind eigentlich Embeddings und warum sind sie so wichtig?
Embeddings sind mathematische Repräsentationen von Texten. Ein Sprachmodell wandelt einen Text in eine Liste von Zahlen um, die die Bedeutung des Textes beschreiben. Texte mit ähnlicher Bedeutung liegen im mathematischen Raum nah beieinander. Dadurch kann eine Vektordatenbank später nach ähnlichen Inhalten suchen. Ohne Embeddings wäre eine semantische Suche kaum möglich. Sie bilden das Fundament moderner RAG-Systeme und sind der Grund, warum solche Systeme viel flexibler sind als klassische Volltextsuche. - Wie groß darf mein ChatGPT-Datenexport sein?
Die Größe spielt grundsätzlich keine große Rolle. Selbst mehrere tausend Gespräche lassen sich problemlos verarbeiten. Entscheidend ist eher die Anzahl der erzeugten Textabschnitte, die sogenannten Chunks. Ein größerer Export führt zu mehr Chunks und damit zu mehr Embeddings. Moderne Vektordatenbanken können jedoch problemlos Millionen solcher Einträge verwalten. Für einen privaten Wissensassistenten reicht selbst ein kleiner Server oder ein leistungsfähiger Desktop völlig aus. - Warum wird der Text vor der Verarbeitung in kleine Abschnitte aufgeteilt?
Wenn man komplette Gespräche oder große Texte direkt als Embeddings speichert, wird die semantische Suche ungenau. Ein einzelner Text könnte mehrere Themen enthalten. Durch das Aufteilen in kleinere Abschnitte kann das System später viel präziser suchen. Jeder Abschnitt beschreibt ein klareres Thema. Dadurch findet die Datenbank genau die Teile eines Gesprächs, die wirklich zur aktuellen Frage passen. - Welche Rolle spielt Ollama in diesem System?
Ollama dient als lokale Plattform für Sprachmodelle. Es erlaubt Dir, KI-Modelle direkt auf Deinem eigenen Rechner auszuführen. In unserem System erfüllt Ollama zwei Aufgaben: Es erzeugt Embeddings für Texte und generiert Antworten auf Fragen. Der Vorteil liegt darin, dass alle Daten lokal bleiben. Deine Gespräche und Dein Wissensarchiv verlassen also nie Deinen eigenen Rechner. - Warum wird Qdrant als Vektordatenbank verwendet?
Qdrant ist eine moderne Vektordatenbank, die speziell für KI-Anwendungen entwickelt wurde. Sie ist schnell, einfach zu installieren und sehr gut dokumentiert. Außerdem lässt sie sich problemlos mit Python und vielen KI-Frameworks verbinden. Für lokale Wissenssysteme ist Qdrant deshalb eine besonders praktische Lösung. Alternativen wären beispielsweise Chroma, Weaviate oder Pinecone. - Was bedeutet der Begriff RAG-System?
RAG steht für „Retrieval-Augmented Generation“. Dabei handelt es sich um eine Architektur, bei der eine KI zunächst relevante Informationen aus einer Datenbank abruft und diese anschließend zur Generierung einer Antwort nutzt. Die KI kombiniert also ihr eigenes Wissen mit externen Daten. Dadurch kann sie sehr präzise Antworten geben und gleichzeitig auf aktuelle oder persönliche Informationen zugreifen. - Kann ich auch andere Datenquellen in dieses System integrieren?
Ja, das ist sogar einer der größten Vorteile dieser Architektur. Das System ist nicht auf ChatGPT-Daten beschränkt. Du kannst auch eigene Artikel, Notizen, PDFs, Forschungsunterlagen oder andere Dokumente integrieren. Solange sich der Inhalt in Textform verarbeiten lässt, kann er Teil der Wissensdatenbank werden. Dadurch wächst Dein System mit der Zeit zu einem umfassenden Wissensarchiv. - Wie aktuell bleibt ein solches Wissenssystem?
Die Aktualität hängt davon ab, wie oft Du neue Daten importierst. Du kannst beispielsweise regelmäßig neue ChatGPT-Exporte verarbeiten oder ein Skript erstellen, das automatisch neue Dokumente erkennt. Viele Systeme werden so eingerichtet, dass sie einmal pro Woche oder einmal pro Monat aktualisiert werden. Dadurch bleibt die Wissensdatenbank stets auf dem neuesten Stand. - Welche Hardware brauche ich für ein solches System?
Für kleinere Projekte reicht bereits ein moderner Desktop-Computer. Wenn Du ein größeres Sprachmodell verwenden möchtest, kann eine GPU hilfreich sein. Viele Nutzer betreiben ihre Wissenssysteme jedoch auch erfolgreich auf einem leistungsfähigen Laptop oder einem Mini-Server. Wichtig ist vor allem genügend Arbeitsspeicher und ausreichend Speicherplatz für die Datenbank. - Wie schnell arbeitet ein solches System in der Praxis?
Die Geschwindigkeit hängt von mehreren Faktoren ab, zum Beispiel von der Größe der Datenbank, der Hardware und dem verwendeten Sprachmodell. In vielen Fällen dauert eine Anfrage nur wenige Sekunden. Die Vektorsuche selbst ist meist extrem schnell. Der größte Zeitanteil entfällt oft auf die Antwortgenerierung des Sprachmodells. - Ist es möglich, mehrere Wissensbereiche zu trennen?
Ja. Vektordatenbanken wie Qdrant erlauben die Verwendung mehrerer Collections. Jede Collection kann ein eigenes Themengebiet darstellen. Du könntest zum Beispiel eine Collection für ChatGPT-Gespräche, eine für Artikel und eine für Notizen anlegen. Dadurch lassen sich Wissensbereiche sauber strukturieren und gezielt durchsuchen. - Wie sicher sind meine Daten in einem lokalen KI-System?
Der große Vorteil eines lokalen Systems besteht darin, dass Deine Daten nicht an externe Dienste übertragen werden müssen. Alle Informationen bleiben auf Deinem eigenen Rechner oder Server. Das ist besonders für sensible Inhalte interessant. Natürlich solltest Du trotzdem regelmäßig Backups erstellen und Dein System gegen unbefugten Zugriff schützen. - Kann ich dieses System auch in eigene Anwendungen integrieren?
Ja. Die meisten Komponenten lassen sich über Programmierschnittstellen ansprechen. Dadurch kannst Du Dein Wissenssystem in eigene Tools integrieren, zum Beispiel in eine Weboberfläche, ein Redaktionssystem oder eine Notiz-App. Viele Entwickler bauen kleine Anwendungen, die ihre Wissensdatenbank direkt über eine Chatoberfläche zugänglich machen. - Wie könnte sich diese Technologie in Zukunft weiterentwickeln?
Persönliche Wissens-KIs stehen vermutlich erst am Anfang ihrer Entwicklung. In Zukunft könnten solche Systeme automatisch neue Inhalte integrieren, Zusammenfassungen erstellen oder sogar eigene Vorschläge für Projekte liefern. Je mehr Daten in ein solches System fließen, desto wertvoller wird es. Es könnte sich langfristig zu einer Art persönlichem digitalen Gedächtnis entwickeln, das Dein Wissen strukturiert und jederzeit abrufbar macht.


