
V první části této série článků jsme si ukázali, že export dat ChatGPT je mnohem víc než jen technická funkce. Vaše exportovaná data obsahují soubor myšlenek, nápadů, analýz a konverzací, které se nahromadily za dlouhou dobu. Dokud jsou však tato data uložena pouze jako archiv na vašem pevném disku, zůstávají pouze archivem. Zásadním krokem je, aby tyto informace byly opět použitelné. Právě zde začíná vývoj osobní znalostní umělé inteligence.
Myšlenka je vlastně překvapivě jednoduchá: umělá inteligence by měla pracovat nejen s obecnými znalostmi, ale také by měla mít přístup k vašim vlastním datům. Měla by být schopna prohledat předchozí konverzace, najít vhodný obsah a začlenit jej do nových odpovědí. Tím se z obyčejné umělé inteligence stane jakási digitální paměť. Toto je druhá část série článků, která se nyní zabývá praktickou stránkou věci.




1. část seriálu: Podceňovaný poklad v exportu dat ChatGPT
Zatímco v této druhé části se budeme zabývat praktickou stránkou věci, stojí za to podívat se na to. první článek této série. Zabývá se základní otázkou, proč je export dat ChatGPT vůbec tak zajímavý - a proč mnoho uživatelů stále podceňuje jeho potenciál. Článek ukazuje, jaká data jsou vlastně v exportu obsažena, jak je lze využít k vytvoření osobního znalostního archivu a proč tento krok tvoří základ pro vlastní UI s pamětí. Pokud chcete pochopit, proč vůbec tento pipeline vytváříme a jakou strategickou hodnotu má vaše vlastní historie chatu, měli byste začít 1. částí.
Než se v následující kapitole pustíme do vlastní implementace, podívejme se nejprve, jak je takový systém v zásadě strukturován.
Základní myšlenka systému RAG
Technickým základem našeho systému je koncept, který se dnes ve světě umělé inteligence hojně používá: RAG neboli Retrieval Augmented Generation. Za tímto pojmem se skrývá velmi praktický princip.
Obvykle jazykový model odpovídá na otázky výhradně na základě znalostí, které se naučil během svého tréninku. Přestože jsou tyto znalosti rozsáhlé, mají dvě rozhodující omezení:
- Za prvé, model nezná žádné individuální informace o vašich vlastních projektech nebo myšlenkách.
- Za druhé, nemá přístup k novým datům vytvořeným po tréninku.
Právě zde přichází na řadu systém RAG. Namísto přímého generování odpovědi se nejprve stane něco jiného: systém vyhledá v databázi obsah, který odpovídá položené otázce. Tento obsah je pak přenesen do jazykového modelu jako kontext. Teprve poté umělá inteligence formuluje odpověď. Zjednodušeně řečeno, proces vypadá následovně:
- Položíte otázku →
- systém prohledává databázi znalostí →
- je nalezen relevantní obsah →
- Tento obsah se přenáší do UI jako kontext →
- UI vygeneruje odpověď.
Rozhodující výhoda je zřejmá: umělá inteligence může využívat informace, které nebyly součástí jejího původního tréninku.
A právě tady vstupují do hry vaše údaje z ChatGPT. Pokud tyto konverzace integrujeme do znalostní databáze, může k nim umělá inteligence přistupovat později. Může najít předchozí nápady, použít argumenty ze starých dialogů nebo zohlednit analýzy z minulých konverzací. Systém si tedy začne „pamatovat“ vaše vlastní myšlenky.
Stavební kameny našeho systému
Aby to fungovalo, potřebujeme několik komponent, které budou spolupracovat. Naštěstí je dnes technická infrastruktura pro tyto účely mnohem snáze dostupná než před několika lety. V jádru se náš systém skládá ze čtyř ústředních komponent.
- Prvním stavebním prvkem je Export dat ChatGPT. Zde se nacházejí naše nezpracovaná data. Obsahují všechny konverzace, které jsme s umělou inteligencí dříve vedli.
- Druhým stavebním prvkem je Model vkládání. Tento model převádí text na matematické vektory. To umožňuje porovnávat texty podle jejich významu.
- Třetím stavebním prvkem je Databáze vektorů. V našem případě používáme Qdrant. Tato databáze uchovává matematické reprezentace textů a umožňuje rychlé sémantické vyhledávání.
- Čtvrtým stavebním prvkem je místní jazykový model, který běží přes Ollama. Tento model bude později formulovat skutečné odpovědi.
Tyto čtyři složky spolu úzce spolupracují.
- Export dat poskytuje obsah.
- Model vkládání je činí strojově čitelnými.
- Vektorová databáze je ukládá a vyhledává.
- Jazykový model nakonec generuje srozumitelné odpovědi.
Společně tvoří základ osobní znalostní UI.
Přehled toku dat
Aby systém fungoval, musí data projít několika kroky. Prvním krokem je export dat ChatGPT, který jsme již vytvořili v prvním článku. Konverzace, které obsahuje, jsou nejprve extrahovány ze souborů JSON. Tyto texty je pak třeba připravit. Rozsáhlé historie konverzací se rozdělí na menší úseky, tzv. kusy textu. Díky tomu je následné vyhledávání mnohem efektivnější.
V dalším kroku z těchto textových úseků vytvoříme vložené texty. Každý text je popsán matematicky. Textům s podobným významem jsou přiřazeny podobné vektory. Tyto vektory pak uložíme do naší vektorové databáze Qdrant.
To znamená, že nejdůležitější část infrastruktury již existuje. Když je otázka položena později, stane se následující:
- Otázka je rovněž převedena na vektor.
- Databáze vyhledává texty s podobným významem.
- Tyto textové pasáže se přenášejí do jazykového modelu jako kontext.
- Model na základě těchto informací formuluje odpověď.
Tento proces zajišťuje, že umělá inteligence využívá nejen obecné znalosti, ale má přístup i k vašim vlastním datům.
Co bude nakonec možné
Po nastavení systému se práce s umělou inteligencí výrazně změní. Už nepracujete jen s obecným jazykovým modelem, ale s umělou inteligencí, která má přístup k vašim vlastním datům. To otevírá zcela nové možnosti. Můžete například klást otázky, jako např:
„Mluvil jsem někdy o tomto tématu s UI?“
„Jaké představy jsem měl o tomto projektu předtím?“
„Jaké argumenty jsem uvedl v předchozích rozhovorech?“
Umělá inteligence pak prohledá vaše vlastní konverzace a najde vhodný obsah. Namísto obecné odpovědi může odkázat na předchozí myšlenky, shrnout staré analýzy nebo rozpoznat souvislosti mezi různými konverzacemi.
Jinými slovy, umělá inteligence začne pracovat s vaším vlastním archivem znalostí. Z jednoduchého chatovacího nástroje se tak stane systém, který může dlouhodobě podporovat vaše myšlení. A právě tento systém budeme v několika následujících kapitolách krok za krokem budovat. V následující části začneme s praktickou prací a nejprve se blíže podíváme na export dat ChatGPT. Než totiž začneme budovat znalostní databázi, musíme pochopit, jak jsou naše data vlastně strukturována.
Aktuální průzkum používání místních systémů umělé inteligence
Příprava: Porozumění exportu dat ChatGPT
V prvním článku této série jsme již vytvořili export dat ChatGPT a stáhli jej jako soubor ZIP. Na první pohled se tento soubor může zdát poněkud nenápadný - archiv s několika technickými soubory, který zpočátku vypadá spíše jako záloha než jako hodnotný soubor dat. Tento archiv však obsahuje základ celého našeho znalostního systému.
Než začneme tato data načítat do databáze nebo je připojovat k UI, musíme nejprve pochopit, jak je export strukturován. Protože pouze pokud víme, jaké informace obsahuje a jak jsou strukturovány, můžeme je později smysluplně zpracovat. V této kapitole se proto podíváme na to, jak je export dat strukturován, které soubory jsou skutečně důležité a jak můžeme tento technický archiv proměnit v užitečný základ pro náš znalostní systém UI.
Rozbalení souboru ZIP
První krok je triviální, ale přesto důležitý: musíme rozbalit stažený archiv. Soubor je obvykle k dispozici jako klasický soubor ZIP. Jeho velikost se může lišit v závislosti na rozsahu předchozího použití. Někteří uživatelé obdrží archiv o velikosti několika set megabajtů, jiní několik gigabajtů.
Po rozbalení souboru se vytvoří složka s několika soubory a podsložkami. Přesná struktura se může mírně lišit, ale obvykle v ní najdete několik souborů JSON a případně další soubory s dalšími informacemi.
Pro mnoho uživatelů se tato struktura zpočátku jeví jako poněkud technická. Pokud se však na chvíli zastavíte, rychle rozpoznáte určitý vzorec: data jsou uspořádána poměrně přehledně a mají jasnou strukturu. To je dobrá zpráva, protože právě tato struktura umožňuje pozdější automatické zpracování obsahu.
Struktura dat chatu
Nejdůležitější částí exportu jsou skutečná data chatu. Tyto konverzace jsou obvykle uloženy v jednom nebo více souborech JSON. JSON je rozšířený datový formát, který se často používá k ukládání strukturovaných informací.
Takový soubor neobsahuje pouze dlouhý text. Místo toho je dialog rozdělen na jednotlivé prvky. Obvykle se dialog skládá z několika zpráv. Každá zpráva obsahuje informace, jako např.
- skutečný text zprávy
- roli odesílatele (uživatele nebo UI).
- časové razítko
- částečně další metadata
To umožňuje rekonstruovat celý průběh dialogu. Například dialog začíná otázkou uživatele. Po ní následuje odpověď umělé inteligence. Poté mohou následovat další otázky a odpovědi. Každá z těchto zpráv se ukládá samostatně.
To má jednu velkou výhodu: později můžeme přesně rozpoznat, kdo co řekl a jak se rozhovor vyvíjel. To je pro náš znalostní systém obzvlášť důležité, protože chceme později vyhledávat a analyzovat právě tento obsah.
Jaké údaje skutečně potřebujeme
Přestože export obsahuje mnoho informací, nepotřebujeme je všechny pro náš znalostní systém. Nejdůležitější složkou jsou texty konverzací. Tyto texty obsahují skutečný obsah: Obsahují myšlenky, analýzy, otázky a odpovědi. Právě tento obsah chceme později prohledávat.
Užitečná mohou být i některá metadata. Patří sem např.
- Časové razítko
- Název konverzace
- Možná interní identifikační čísla
Tyto informace nám pomáhají později lépe třídit obsah nebo kategorizovat konverzaci z časového hlediska. Ostatní složky exportu jsou pro náš projekt méně důležité. Patří sem například některá technická metadata, která jsou zajímavá pouze pro vnitřní fungování platformy.
Při vytváření znalostní báze se proto záměrně soustředíme na to nejdůležitější: texty rozhovorů a některé základní kontextové informace. Čím přehledněji tato data strukturujeme, tím lépe s nimi naše umělá inteligence může později pracovat.
První přehled údajů
Než začneme pracovat s automatizovanými skripty, je vhodné se krátce podívat na samotná data. Za tímto účelem otevřete jeden ze souborů JSON pomocí jednoduchého textového editoru nebo programu, který umí dobře zobrazovat soubory JSON. K tomu se velmi dobře hodí mnohé editory kódu, například Visual Studio Code, ale fungují i jednoduché textové editory.
Při prvním pohledu na soubor pravděpodobně uvidíte poměrně velké množství strukturovaných dat. Soubory JSON se skládají z vnořených prvků - tj. datových polí, která následně obsahují další pole. Zpočátku se to může zdát poněkud složité, ale s trochou trpělivosti základní strukturu rychle rozpoznáte. Uvidíte například, že konverzace se skládá z několika zpráv a že každá zpráva představuje samostatný objekt. Vlastní text se obvykle nachází v jasně rozpoznatelném poli.
Tato první kontrola má důležitý účel: pomůže vám pochopit, jak jsou vaše data strukturovaná. Protože v následující kapitole využijeme právě tuto strukturu k automatickému načítání konverzací a jejich přípravě pro náš znalostní systém. Jinými slovy: Nyní krok za krokem přeměňujeme archiv technických dat na použitelnou znalostní bázi. A právě s tím začneme v následující kapitole. Tam je cílem extrahovat data z rozhovorů a připravit je tak, aby v nich bylo možné později efektivně vyhledávat.
Příprava dat: Od rozhovorů k analyzovatelným textům
Po rozbalení exportu dat ChatGPT v předchozí kapitole a získání prvotního přehledu o jeho struktuře začíná vlastní technická část našeho projektu. Exportovaná data jsou sice kompletní, ale v této podobě ještě nejsou optimálně vhodná pro náš znalostní systém.
Důvod je jednoduchý: historie chatu jsou obvykle dlouhé, obsahují mnoho témat a jsou uloženy ve struktuře, která je pro člověka čitelná, ale není ideální pro sémantické vyhledávání nebo vektorové databáze. Abychom naší umělé inteligenci umožnili později najít relevantní obsah, musíme tato surová data nejprve zpracovat. To v podstatě znamená tři věci:
- Extrakce konverzací ze souborů JSON
- rozumně strukturovat texty
- rozdělit obsah na menší části
Tento proces je v moderních systémech umělé inteligence zcela běžným krokem a často se označuje jako předzpracování.
Proč nejsou nezpracovaná data přímo vhodná
Pokud se podíváte na jeden ze souborů JSON, zjistíte, že jeden chat se často skládá z mnoha zpráv. Typický dialog může vypadat například takto:
- Otázka
- Odpověď
- Poptávka
- nové prohlášení
- další podrobnosti
- Souhrn
Některé konverzace mohou obsahovat stovky nebo dokonce tisíce slov. Pro člověka to není problém. Jednoduše čteme dialog odshora dolů.
Pro vyhledávání pomocí umělé inteligence to však funguje hůře. Důvodem je to, že jeden chat často obsahuje několik témat. Pokud později provádíme sémantické vyhledávání, měl by systém najít co nejpřesnější textové pasáže - nikoli celé konverzace s množstvím různého obsahu.
Proto se rozsáhlé texty člení na menší části. Tyto části se nazývají chunks. Oddíl je jednoduše malý blok textu, který obsahuje souvislou myšlenku. Tato metoda výrazně zlepšuje kvalitu pozdějšího vyhledávání.
Výpis historie chatu
Prvním praktickým krokem je načtení obsahu ze souborů JSON. K tomu použijeme malý skript v jazyce Python. Jazyk Python je pro tyto úlohy obzvláště vhodný, protože obsahuje mnoho knihoven pro zpracování dat a umělou inteligenci.
Nejprve vytvořte nový soubor, například:
extract_chats.py
Poté přidáme jednoduchý skript, který načte data chatu.
import json
with open("conversations.json", "r", encoding="utf-8") as f:
data = json.load(f)
print("Anzahl der Gespräche:", len(data))
Po spuštění tohoto skriptu byste měli vidět, kolik konverzací je obsaženo v exportu. Nyní vyextrahujeme skutečné texty.
texts = []
for conversation in data:
if "mapping" in conversation:
for node in conversation["mapping"].values():
message = node.get("message")
if message:
content = message.get("content")
if content and "parts" in content:
text = " ".join(content["parts"])
texts.append(text)
print("Extrahierte Textabschnitte:", len(texts))
Tento skript prochází strukturu JSON a shromažďuje všechny části textu z konverzací. To znamená, že jsme již dokončili nejdůležitější část: extrahovali jsme obsah z technického formátu exportu.
Vytváření částí textu
Nyní přichází na řadu další důležitý krok: rozdělení na části. Místo ukládání celých konverzací rozdělíme texty na menší úseky.
Typická velikost takových textových oddílů je 300 až 800 slov nebo přibližně 500 tokenů. Následuje jednoduchý příklad rozdělení textu na části.
def split_text(text, chunk_size=500):
words = text.split()
chunks = []
for i in range(0, len(words), chunk_size):
chunk = " ".join(words[i:i+chunk_size])
chunks.append(chunk)
return chunks
Nyní můžeme tuto funkci použít na naše texty.
all_chunks = []
for text in texts:
chunks = split_text(text)
all_chunks.extend(chunks)
print("Gesamtzahl der Chunks:", len(all_chunks))
Nyní jsme z historie chatu vytvořili mnoho menších textových sekcí. Tyto textové bloky jsou ideální pro pozdější vyhledávání ve vektorové databázi.
Přidání metadat
Kromě vlastního textu mohou být velmi užitečné i další informace. Tato takzvaná metadata nám později pomáhají lépe třídit nebo filtrovat obsah. Typickými metadaty mohou být
- Datum rozhovoru
- Název konverzace
- Zdroj (ChatGPT Export)
- ID hovoru
Tyto informace můžeme uložit společně s textem, například takto:
documents = []
for conversation in data:
title = conversation.get("title", "Unbekannt")
if "mapping" in conversation:
for node in conversation["mapping"].values():
message = node.get("message")
if message:
content = message.get("content")
if content and "parts" in content:
text = " ".join(content["parts"])
chunks = split_text(text)
for chunk in chunks:
documents.append({
"text": chunk,
"title": title
})
Díky tomu již mají naše data mnohem lepší strukturu. Namísto nepřehledného archivu chatů máme nyní soubor mnoha malých textových oddílů, z nichž každý je opatřen kontextovými informacemi.
Právě tato struktura bude v dalším kroku klíčová. Nyní totiž můžeme z těchto textů začít generovat embeddingy - tedy matematické reprezentace obsahu, které budou později uloženy v naší vektorové databázi. A právě o tom bude následující kapitola.
Vytvoření vložených položek
V předchozí kapitole jsme již uvedli naše data z ChatGPT do použitelné podoby. Ze souborů JSON jsme extrahovali konverzace, vyčistili texty a rozdělili je na menší úseky - tzv. chunky.
K tomu, aby naše umělá inteligence mohla skutečně smysluplně vyhledávat obsah, však stále chybí jeden zásadní krok. Texty je třeba přeložit do podoby, kterou mohou stroje porovnávat. Zde přicházejí ke slovu vložené texty.
Vložené texty jsou matematickou reprezentací textů. Umožňují počítačům porovnávat význam textů. Dva texty s podobným obsahem dostávají podobné vektory - i když používají různá slova. Právě tuto vlastnost potřebujeme pro náš znalostní systém. Naše umělá inteligence by přece neměla vyhledávat pouze shodná slova, ale také texty se shodným obsahem.
Co jsou to vložená data
Vložení je v podstatě seznam čísel. Tato čísla popisují význam textu v matematickém prostoru. Každý text je převeden na tzv. vektor. Takový vektor může vypadat například takto:
[0.134, -0.876, 0.442, 0.921, -0.223, ...]
Jeden vektor může obsahovat několik set nebo dokonce tisíc čísel. Tato čísla samozřejmě nejsou pro člověka přímo srozumitelná. Pro stroje jsou však ideální pro výpočet podobností mezi texty. Pokud mají dva texty podobný obsah, jsou si jejich vektory v matematickém prostoru blíže. Příklad:
- Text A„Jak mohu exportovat data ChatGPT?“
- Text B: „Jak stáhnu své konverzace z ChatGPT?“
Ačkoli se formulace liší, oba texty v podstatě popisují stejné téma. Dobrý vkládací model tuto podobnost rozpozná. Oba texty proto dostanou podobné vektory. Přesně tento princip využijeme později pro naše sémantické vyhledávání.
Vkládání modelů s Ollama
K vytvoření vnoření potřebujeme speciální model. Naštěstí k tomu nemusíme používat externí cloudové služby. Mnoho modelů pro vkládání lze nyní provozovat lokálně - a právě zde přichází ke slovu Ollama.
Protože v systému již běží Ollama, můžeme do něj vložit model install. Velmi dobrým modelem je např:
nomic-embed-text
Můžete jej zkrotit pomocí následujícího příkazu 1TP12:
ollama pull nomic-embed-text
Další oblíbené modely jsou
- mxbai-embed-large
- bge-large
- all-minilm
Pro naše účely nomic-embed-text je velmi dobrým výchozím bodem. Tento model generuje vysoce kvalitní embeddingy a běží lokálně bez jakýchkoli problémů.
Vytvoření lokálních vložení
Nyní chceme rozšířit náš skript v jazyce Python tak, aby mohl generovat vložené soubory. Nejprve 1TP12Vytvoříme knihovnu, pomocí které může Python komunikovat s Ollama.
pip install ollama
Nyní se můžeme zabývat modelem vkládání přímo z jazyka Python. Následuje jednoduchý příklad:
import ollama
response = ollama.embeddings(
model="nomic-embed-text",
prompt="Wie exportiere ich meine ChatGPT-Daten?"
)
print(len(response["embedding"]))
Pokud vše fungovalo, získáte vektor s několika stovkami čísel.
Nyní to aplikujme na naše chatovací chunky.
embeddings = []
for doc in documents:
text = doc["text"]
result = ollama.embeddings(
model="nomic-embed-text",
prompt=text
)
vector = result["embedding"]
embeddings.append({
"text": text,
"embedding": vector,
"title": doc["title"]
})
Pomocí něj vytvoříme vektor pro každou část textu. Tyto vektory se později uloží do naší databáze.
Proč je tento krok klíčový
Základem moderních znalostních systémů jsou embeddings. Bez embeddingů bychom mohli v textech vyhledávat pouze pomocí klasického vyhledávání klíčových slov. To by znamenalo, že by systém našel pouze obsah, který obsahuje přesně stejná slova. Jazyk však málokdy funguje takto jednoduše. Uživatel se může například zeptat:
„Jak jsem zpracovával data ChatGPT?“
Původní rozhovor by se však dal formulovat takto:
„Jak mohu analyzovat export dat z aplikace ChatGPT?“
Jednoduché vyhledávání by tuto souvislost nemuselo rozpoznat. S vloženými slovy je to jinak. Protože oba texty mají podobný význam, jejich vektory jsou si v matematickém prostoru blízké. Naše databáze proto dokáže najít shodný obsah, i když se jejich znění liší. Právě tato schopnost činí sémantické vyhledávání tak mocným. Umožňuje umělé inteligenci vyhledávat nejen slova, ale i významy.
A právě proto jsou embeddingy ústředním stavebním prvkem našeho systému. V příští kapitole na něj navážeme a installieren naši databázi vektorů. V ní budeme ukládat vygenerované vektory - a vytvoříme tak základ pro naši osobní znalostní UI.
Qdrant 1TP12Přidání a konfigurace
Poté, co jsme v předchozí kapitole vytvořili vložená data pro náš chat, máme nyní k dispozici kolekci textových úseků a souvisejících vektorů. Tyto vektory matematicky popisují význam textů a tvoří tak základ pro sémantické vyhledávání. Tato data jsou však v současné době k dispozici pouze v pracovní paměti našeho skriptu nebo v jednoduchých seznamech. Potřebujeme specializovanou paměť, aby k nim naše umělá inteligence mohla později efektivně přistupovat.
Právě zde přichází ke slovu vektorová databáze. Vektorová databáze je optimalizována pro ukládání velkého množství takových vložených dat a rychlé vyhledávání podobných vektorů. Pro náš projekt používáme Qdrant, moderní open-source databázi, která byla vyvinuta speciálně pro aplikace umělé inteligence.
V této kapitole 1TP12 nainstalujeme Qdrant, spustíme server a připravíme databázi, abychom mohli později snadno importovat data chatu.
Co je Qdrant
Qdrant je specializovaná databáze pro tzv. vektorové vyhledávání. Zatímco tradiční databáze ukládají informace v tabulkách - například jména, čísla nebo texty - vektorová databáze pracuje s matematickou reprezentací dat.
To znamená, že Qdrant neukládá pouze text, ale i související vložené soubory. Velká výhoda spočívá ve vyhledávání. Pokud je otázka položena později, náš systém převede i tuto otázku na vektor. Qdrant pak dokáže bleskovou rychlostí vypočítat, které uložené texty jsou tomuto vektoru nejpodobnější. Díky tomu je možné zjistit např:
- které pasáže chatu tematicky odpovídají otázce
- které předchozí konverzace obsahují podobný obsah
- které myšlenky by mohly být relevantní ve vašem archivu
Právě proto se dnes Qdrant používá v mnoha moderních systémech umělé inteligence - od vyhledávání dokumentů až po komplexní znalostní asistenty. Další výhoda: Qdrant je open source, je rychle 1TP12izován a běží bez problémů na běžném lokálním počítači.
Instalace systému Qdrant
Nejjednodušší způsob, jak installieren Qdrant používat, je prostřednictvím nástroje Docker. Pokud je na vašem počítači k dispozici Docker, můžete server spustit jediným příkazem. Zde můžete Stáhnout Docker, pokud jste jej ještě nenainstalovali do svého počítače installiert.
docker run -p 6333:6333 qdrant/qdrant
Tento příkaz spustí server Qdrant a otevře standardní port 6333. Naše skripty mohou později komunikovat s databází prostřednictvím tohoto portu.
Pokud nechcete používat Docker, existují i jiné způsoby, jak installiere Qdrant spustit, například prostřednictvím místní binárky nebo správce balíčků. V mnoha praktických projektech se však Docker ukázal jako nejjednodušší a nejstabilnější možnost.
Po spuštění serveru běží Qdrant na pozadí a čeká na požadavky. Nyní můžete otestovat, zda je server přístupný. Za tímto účelem otevřete v prohlížeči následující adresu:
http://localhost:6333
Pokud vše funguje, měla by se zobrazit jednoduchá stavová zpráva. Server je nyní připraven k dalším krokům.
První kroky s Qdrant
Než budeme moci importovat data chatu, musíme vytvořit tzv. kolekci. V Qdrantu je kolekce srovnatelná s tabulkou v klasické databázi. Obsahuje naše vektory a odpovídající data.
Nejprve jsme installiere knihovnu Python pro Qdrant:
pip install qdrant-client
Nyní můžeme v našem skriptu Python navázat spojení s databází.
from qdrant_client import QdrantClient
client = QdrantClient("localhost", port=6333)
Pokud se tento kód provede bez chybové zprávy, je připojení úspěšné. Nyní vytvoříme kolekci pro naše data chatu.
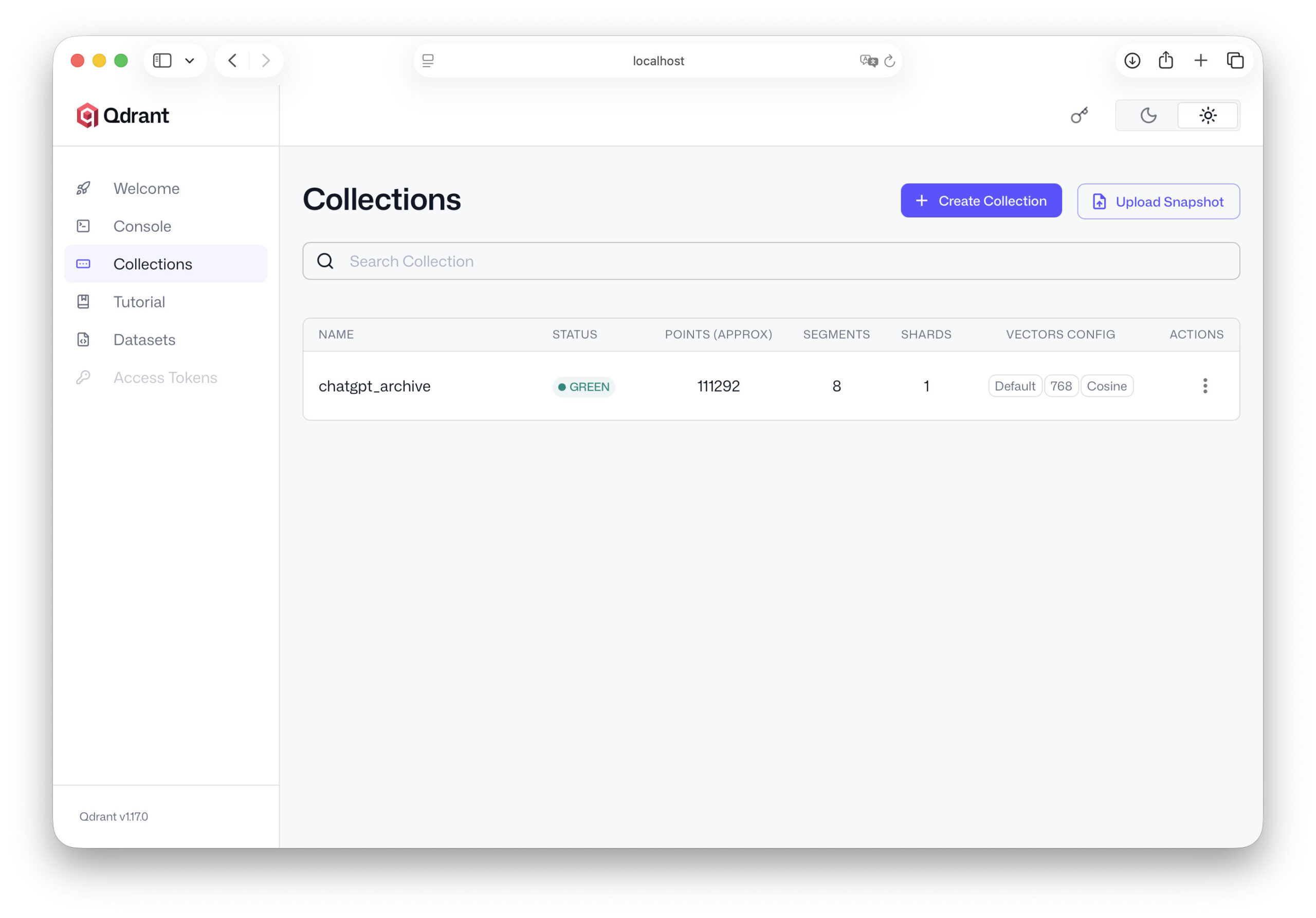
from qdrant_client.models import VectorParams, Distance client.recreate_collection( collection_name="chatgpt_archive", vectors_config=VectorParams(size=768, distance=Distance.COSINE), )
Nejdůležitějšími parametry jsou
- collection_name - název naší databáze
- velikost - délka vektorů vložení
- vzdálenost - metoda výpočtu podobnosti
Velikost vektoru závisí na použitém modelu vkládání. Mnoho modelů pracuje s vektory o rozměrech 768 nebo 1024. Funkce kosinové vzdálenosti je jednou z nejběžnějších metod pro výpočet podobností mezi texty. To znamená, že naše databáze je již připravena k použití.
Struktura dat plánu
Než začneme importovat data, je vhodné se rychle podívat na strukturu, kterou chceme uložit. Každá položka v naší vektorové databázi se bude skládat z několika složek:
- ID - jedinečný identifikátor
- Vkládání - vektor textu
- Užitečné zatížení - Další informace o textu
Užitečné zatížení může obsahovat například
- původní text
- název rozhovoru
- datum
- další metadata
Příklad datového záznamu může vypadat takto:
{
"id": 1,
"vector": [0.123, -0.452, 0.889, ...],
"payload": {
"text": "Wie kann ich meinen ChatGPT-Datenexport analysieren?",
"title": "Datenanalyse"
}
}
Tato struktura má jednu velkou výhodu. Vektory slouží k sémantickému vyhledávání, zatímco užitečné zatížení obsahuje všechny informace, které chceme později zobrazit nebo analyzovat. To znamená, že náš systém zůstává flexibilní a může být později snadno rozšířen.
To znamená, že nejdůležitější část infrastruktury je již připravena. Náš server Qdrant běží, databáze je nastavena a víme, jakou strukturu budou mít naše data. V následující kapitole začneme s klíčovým krokem: importujeme naše data ChatGPT do databáze a přeměníme náš archiv konverzací na skutečnou znalostní databázi, ve které lze vyhledávat.
Import dat ChatGPT do Qdrant
Nyní, když jsme v předchozí kapitole vytvořili Qdrant installiert a kolekci, byl vytvořen technický základ naší znalostní databáze. Naše embeddings již existují - vytvořili jsme je z dat ChatGPT - a Qdrant běží jako databázový server na našem počítači.
Nyní přichází klíčový krok: načteme naše data do databáze. Uložíme nejen samotné vektory, ale také související texty a metadata. Tato kombinace umožní naší umělé inteligenci později najít relevantní obsah a použít ho v odpovědích. V této kapitole vytvoříme vlastní znalostní bázi našeho systému.
Uložení vložených souborů
Nejprve je třeba přenést naše vygenerovaná vložení do databáze. Každý záznam v Qdrantu se skládá ze tří složek:
- ID
- vektor (vložení)
- užitečné zatížení s dalšími údaji
V našem případě například užitečné zatížení obsahuje
- textová část
- název rozhovoru
- Případně další metadata
V jazyce Python můžeme tuto strukturu připravit poměrně snadno. Příklad:
points = []
for idx, item in enumerate(embeddings):
points.append({
"id": idx,
"vector": item["embedding"],
"payload": {
"text": item["text"],
"title": item["title"]
}
})
Tím se vygeneruje seznam datových bodů, které pak můžeme uložit do Qdrantu. Každý datový bod tedy obsahuje textovou část, příslušný vektor a další kontextové informace. Tato struktura bude později tvořit základ našeho sémantického vyhledávání.
Vytvoření importního skriptu
Nyní připojíme náš skript Python ke Qdrantu a přeneseme data. K tomu použijeme klienta Qdrant Python, který jsme rozebrali v předchozí kapitole 1TP12. Import může vypadat například takto:
from qdrant_client import QdrantClient
from qdrant_client.models import PointStruct
client = QdrantClient("localhost", port=6333)
points = []
for idx, item in enumerate(embeddings):
point = PointStruct(
id=idx,
vector=item["embedding"],
payload={
"text": item["text"],
"title": item["title"]
}
)
points.append(point)
client.upsert(
collection_name="chatgpt_archive",
points=points
)
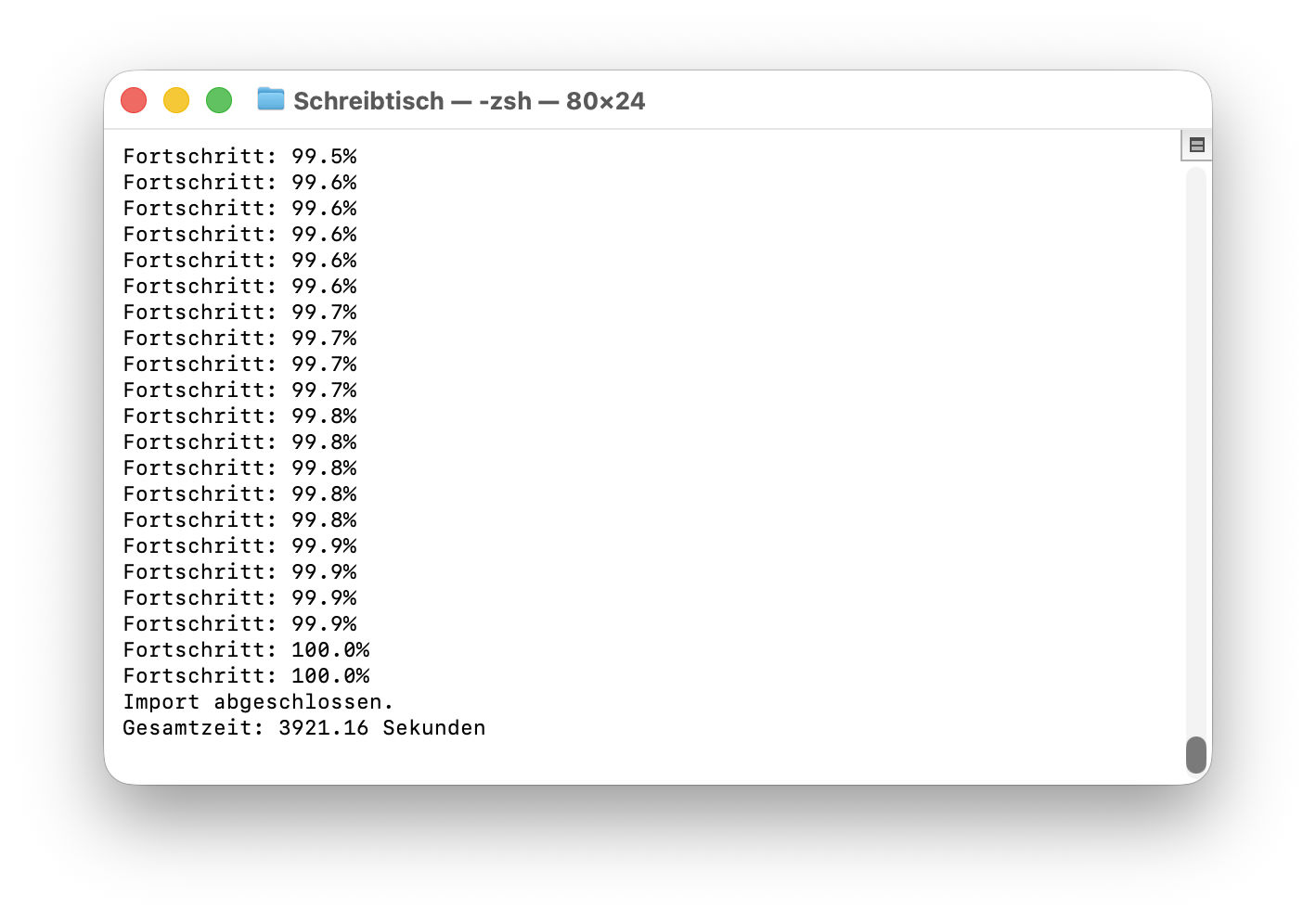
print("Import abgeschlossen:", len(points), "Datensätze gespeichert.")
Příkaz upsert zajistí uložení dat do kolekce. Pokud ID již existuje, položka se aktualizuje. V opačném případě je vytvořen nový datový záznam. V závislosti na velikosti exportu ChatGPT může tento import trvat několik sekund nebo minut. U větších souborů dat - například několika tisíc textových úseků - je to zcela normální.
Testovací databáze
Po dokončení importu bychom měli zkontrolovat, zda byla naše data správně uložena. Nejjednodušším testem je provést vektorové vyhledávání. Za tímto účelem nejprve vytvoříme vložení pro testovací otázku.
query = "Wie kann ich ChatGPT-Daten analysieren?" query_vector = ollama.embeddings( model="nomic-embed-text", prompt=query )["embedding"]
Nyní můžeme v Qdrantu hledat podobné vektory.
search_result = client.search( collection_name="chatgpt_archive", query_vector=query_vector, limit=3 )
Tento příkaz vrátí tři nejpodobnější úseky textu z naší databáze. Můžeme je vypsat například takto:
for result in search_result:
print(result.payload["text"])
print("---")
Pokud vše funguje, zobrazí se nyní části chatu z vašeho archivu, které odpovídají vyhledávacímu dotazu. Nyní víme: Naše databáze funguje.
První hodnocení výkonu
Tento moment je jedním z nejzajímavějších aspektů celého projektu. Poprvé je zřejmé, že náš chatový archiv lze skutečně využít jako zdroj znalostí. Nyní si můžete vyzkoušet různé vyhledávací dotazy. Například
- „Článek o umělé inteligenci“
- „Systém RAG“
- „Export dat ChatGPT“
- „Nápad na strategii“
V závislosti na obsahu historie chatu vyhledá Qdrant vhodné pasáže textu. Někdy budete překvapeni, jaký obsah se znovu objeví. Konverzace, na které jste již dávno zapomněli, mohou být najednou opět důležité. Z toho jasně vyplývá, proč je takový přístup tak zajímavý. Vaše staré konverzace s umělou inteligencí už nejsou jen archivem. Stávají se prohledávatelnou znalostní databází.
Dosáhli jsme tak důležitého milníku. Naše data ChatGPT jsou nyní plně uložena ve vektorové databázi a lze v nich sémanticky vyhledávat. V následující kapitole postoupíme o krok dále: propojíme naši znalostní databázi se samotnou UI. To umožní jazykovému modelu v budoucnu přistupovat k těmto datům a zahrnovat je přímo do odpovědí.
Propojení umělé inteligence s databází znalostí
Do této chvíle jsme již vybudovali velkou část infrastruktury. Naše data ChatGPT byla extrahována z exportu, rozdělena na menší textové úseky, vložena a nakonec uložena do vektorové databáze Qdrant.
Naše umělá inteligence však s těmito daty zatím nepracuje. Ačkoli můžeme provést vektorové vyhledávání pomocí jazyka Python a najít vhodné pasáže textu, samotná UI si toho zatím není vědoma. Když jí položíme otázku, stále používá pouze své obecné jazykové znalosti.
Dalším krokem je tedy propojení těchto dvou světů. Nyní vytváříme proces, v němž umělá inteligence nejprve získá relevantní obsah z databáze znalostí a poté jej zahrne do své odpovědi. Právě to je jádrem systému RAG.
Proces poptávání
Díky našemu znalostnímu systému se průběh dotazování mírně mění. Dosud probíhal rozhovor s umělou inteligencí obvykle takto:
- Položíte otázku →
- UI zpracovává otázku →
- UI vygeneruje odpověď.
Dalším krokem je znalostní databáze. Nový proces vypadá následovně:
- Položíte otázku →
- je otázka převedena na vložení →
- vektorová databáze vyhledává podobné texty →
- Tyto texty jsou přeneseny do UI jako kontext →
UI formuluje odpověď. To znamená, že umělá inteligence již nepracuje pouze se svými vyškolenými znalostmi, ale také s vašimi vlastními daty. Díky tomuto kontextu jsou odpovědi často mnohem přesnější a personalizovanější.
Krok vyhledávání
První část tohoto procesu se nazývá vyhledávání. Retrieval znamená jednoduše „načtení“. V tomto kroku náš systém vyhledává v databázi obsah, který odpovídá tématu otázky. Nejprve vytvoříme další vložení pro aktuální otázku.
query = "Welche Ideen hatte ich zur Nutzung meines ChatGPT-Datenexports?" query_vector = ollama.embeddings( model="nomic-embed-text", prompt=query )["embedding"]
Toto vložení popisuje význam otázky v matematické podobě. Qdrant nyní může vyhledávat podobné vektory.
results = client.search( collection_name="chatgpt_archive", query_vector=query_vector, limit=5 )
Databáze nyní vrátí pět úryvků textu, které nejlépe odpovídají otázce. Tyto úryvky tvoří kontext pro umělou inteligenci. Shromažďujeme je v seznamu.
context_texts = [] for r in results: context_texts.append(r.payload["text"])
Nyní máme k dispozici sbírku relevantního obsahu z našeho archivu chatu.
Přenos kontextu do Ollama
Nyní přichází rozhodující krok. Tento kontext spolu s původní otázkou předáme našemu jazykovému modelu. Model nyní může tyto informace použít k formulaci odpovědi.
Nejprve vytvoříme tzv. výzvu. Výzva je jednoduše text, který pošleme umělé inteligenci.
context = "\n\n".join(context_texts)
prompt = f"""
Du bist ein KI-Assistent, der mit meinem persönlichen Wissensarchiv arbeitet.
Nutze die folgenden Textausschnitte als Kontext:
{context}
Beantworte nun diese Frage:
{query}
"""
Nyní tuto výzvu odešleme našemu jazykovému modelu v Ollama.
response = ollama.chat(
model="llama3",
messages=[
{"role": "user", "content": prompt}
]
)
print(response["message"]["content"])
Umělá inteligence nyní obdrží otázku i příslušné pasáže textu z naší databáze. To jí umožňuje generovat odpovědi na základě našich vlastních dat.
Vytváření reakcí
Posledním krokem je vlastní generování odpovědí. Jazykový model nyní kombinuje dva zdroje znalostí:
jeho vlastní vyškolené znalosti
kontext z naší databáze znalostí
Tato kombinace je mimořádně účinná. Model dokáže vysvětlit obecné vztahy a zároveň zahrnout konkrétní obsah z našeho archivu. Příklad: Pokud se zeptáte:
„Jaké jsem měl nápady na využití exportu dat z ChatGPT?“
UI nyní může přistupovat k předchozím konverzacím a vytvářet z nich strukturované shrnutí. Může například odpovědět:
- Mluvil jste o budování osobního znalostního archivu.
- Chtěli jste vyvinout místní umělou inteligenci se systémem RAG.
- Rozvinul jste myšlenku série článků.
Bez kroku vyhledávání by umělá inteligence tyto informace vůbec neznala. S naším systémem se váš archiv chatu stává skutečným zdrojem znalostí. Tím se završuje nejdůležitější část našeho systému. Nyní máme k dispozici:
- místní AI přes Ollama
- vektorovou databázi s našimi daty chatu
- sémantické vyhledávání
- pracovní postup RAG
V příští kapitole si tento systém vyzkoušíme v praxi a zjistíme, jak dobře naše osobní znalostní AI skutečně funguje.
První dotazy s osobními znalostmi AI
Nyní, když jsme v předchozí kapitole vytvořili spojení mezi naší umělou inteligencí a databází znalostí, je systém technicky dokončen. Naše data ChatGPT jsou ve vektorové databázi, UI může načítat relevantní obsah a celý proces systému RAG funguje.
Nyní přichází nejzajímavější část projektu: první skutečné dotazy. Teprve teď totiž můžeme zjistit, zda náš systém skutečně dělá to, v co jsme doufali - tedy vyhledává předchozí konverzace, analyzuje obsah a generuje smysluplné odpovědi. V této kapitole otestujeme naši znalostní umělou inteligenci, podíváme se na typické případy použití a prozkoumáme možné optimalizace.
Příklady dotazů
Začněme několika jednoduchými otázkami. Dobrou strategií je začít otázkami, o kterých víte, že se nacházejí ve vašem chatovém archivu. Například:
„Jaké jsem měl nápady na využití exportu dat z ChatGPT?“
„Co jsem napsal o systémech RAG?“
„O jakých strategiích pro využití umělé inteligence jsem hovořil?“
Tyto otázky záměrně obsahují otevřené formulace. Cílem není najít konkrétní text, ale objevit tematicky vhodný obsah. Když takovou otázku systému položíte, na pozadí probíhá proces, který jsme nastavili v předchozí kapitole:
- Otázka je převedena na vložení.
- Vektorová databáze vyhledává podobné textové úseky.
- Tyto pasáže textu jsou přeneseny do UI jako kontext.
- Umělá inteligence na základě tohoto kontextu vygeneruje odpověď.
Výsledek může být překvapivý. Často se vynoří rozhovory, na které jste už dávno zapomněli. Staré myšlenky se náhle znovu objeví na obrazovce - někdy dokonce ve zcela novém kontextu.
Právě v tom je síla tohoto přístupu. Archiv chatu se stává prohledávatelným zdrojem znalostí.
Kvalita odpovědí
Pokud si vyzkoušíte několik dotazů, zjistíte, že kvalita odpovědí se může lišit. To je zcela normální. Kvalita takového systému závisí na několika faktorech. Jedním z důležitých faktorů je velikost kusů textu. Pokud jsou úseky příliš velké, mohou obsahovat několik témat. Tím se vyhledávání stává méně přesným.
Pokud jsou však kousky příliš malé, někdy chybí potřebný kontext. Dalším faktorem je model vkládání. Různé modely rozpoznávají významové kontexty různě. Některé jsou vhodné zejména pro odborné texty, jiné pro obecný jazyk.
Svou roli hraje také počet vyhledaných výsledků. Pokud například získáte pouze dva úryvky textu, mohou vám chybět důležité informace. Pokud je naopak načteno příliš mnoho textů, může mít umělá inteligence potíže s rozpoznáním relevantního kontextu.
Tyto parametry lze později snadno upravit. Nejdůležitější je mít především funkční základní systém.
Typické problémy
Jako u každého technického systému se i zde mohou vyskytnout určité potíže. Častým problémem je, že databáze najde texty, které jsou relevantní pouze částečně. Je to proto, že sémantické vyhledávání vždy pracuje s pravděpodobnostmi.
Další problém může nastat, pokud jsou texty příliš roztříštěné. Pokud je myšlenka rozdělena do několika částí, může mít umělá inteligence potíže s rozpoznáním kontextu.
Svou roli hraje také výzva. Pokud je výzva nejasná, nemusí umělá inteligence optimálně využít kontext. Příklad lepší výzvy by mohl vypadat takto:
Použijte následující výňatky z mého znalostního archivu,
co nejpřesněji odpovědět na otázku.
Pokud je k dispozici relevantní obsah, shrňte jej.
Takové malé úpravy mohou výrazně zlepšit kvalitu odpovědí.
Jemné ladění
Jakmile systém v podstatě funguje, začíná nejzajímavější část: dolaďování. Zde můžete experimentovat a postupně svůj znalostní systém vylepšovat. Některé typické optimalizace jsou
- Úprava velikosti oddílu
Někdy poskytují lepší výsledky menší úseky textu. V jiných případech je užitečný větší kontext. - Použití jiného modelu vkládání
Změna modelu může výrazně zlepšit kvalitu sémantického vyhledávání. - Další souvislosti pro umělou inteligenci
Z databáze můžete získat více výsledků, například deset textových pasáží místo pěti. - Použití metadat
Pokud si uložíte další informace - například datum nebo název hovoru - můžete později vyhledávání přesněji filtrovat.
Tyto úpravy jsou součástí každého skutečného systému RAG. Málokdy existuje ideální nastavení pro všechny situace. Ale právě v tom je kouzlo takových systémů: lze je neustále zlepšovat.
V této kapitole jsme provedli první úplný test našeho systému. Viděli jsme, že naše osobní znalostní umělá inteligence je skutečně schopna prohledávat staré konverzace a vyhledávat relevantní obsah.
To znamená, že jádro našeho projektu již bylo dosaženo. Systém však lze ještě značně rozšířit. V příští kapitole se proto podíváme na to, jak lze integrovat další zdroje dat a postupně rozšiřovat osobní znalostní archiv.




Rozšíření pro váš osobní znalostní systém AI
V předchozím nastavení jste již vytvořili funkční systém. Vaše data z ChatGPT byla extrahována, převedena na embeddings, uložena v Qdrant a nakonec připojena k místní UI. Výsledkem je znalostní UI, která má přístup k předchozím konverzacím.
Přísně vzato jsme však teprve na začátku. Architektura, kterou jste vytvořili, není omezena na data ChatGPT. Funguje s jakýmkoli druhem textu. Cokoli, co lze převést do dokumentů nebo textových souborů, se může stát součástí tohoto znalostního systému. V tom spočívá skutečný potenciál takových systémů.
V podstatě jsme vytvořili osobní stroj na znalosti. A tento stroj lze postupně rozšiřovat. V této kapitole se podíváme na možnosti, které z toho vyplývají, a na to, jak můžete svůj systém dlouhodobě rozšiřovat.
Integrace dalších zdrojů dat
Dalším zřejmým krokem je přidání dalšího obsahu do znalostní báze. Konverzace na ChatGPT jsou dobrým začátkem, ale obvykle představují pouze část vašich vlastních znalostí. Mnoho informací je k dispozici v jiných formátech. Např:
- vlastní články
- Poznámky
- Dokumenty ve formátu PDF
- Výzkumné dokumenty
- Elektronické knihy
- Protokoly nebo seznamy nápadů
Veškerý tento obsah lze zpracovávat stejným způsobem jako naše data chatu. Proces zůstává totožný:
- Výpis textu
- Rozdělení textu na části
- Vytvoření vložených položek
- Uložení dat v Qdrant
Příklad: Pokud jste napsali mnoho vlastních článků, můžete tyto texty importovat do databáze znalostí. Umělá inteligence k nim může později přistupovat a rozpoznávat korelace. Můžete se například zeptat:
„Jaké články jsem napsal o umělé inteligenci?“
nebo
„Jaké argumenty jsem na toto téma v minulosti rozvíjel?“
Umělá inteligence pak prohledá váš archiv článků a nalezený obsah použije jako kontext. Tímto způsobem se váš systém krok za krokem rozrůstá v komplexní znalostní archiv.
Několik znalostních databází
S rostoucím množstvím dat může být užitečné oddělit různé oblasti. Qdrant umožňuje vytvořit více kolekcí. Každá kolekce může představovat vlastní znalostní bázi. Možný systém může vypadat například takto:
- Kolekce 1ChatGPT konverzace
- Kolekce 2: Archiv článků
- Kolekce 3: osobní poznámky
- Kolekce 4Technická dokumentace
Toto oddělení má několik výhod. Za prvé, struktura zůstává jasná. Vždy víte, kde je uložen určitý obsah. Za druhé, dotazy lze řídit konkrétněji. Některé dotazy by třeba měly prohledávat pouze archiv článků, jiné celý znalostní systém. Příklad:
- Výzkumná otázka by mohla vyhledávat pouze v archivu článků.
- Strategická otázka by naopak mohla zohlednit všechny sbírky najednou.
Díky těmto strukturám jsou větší znalostní systémy výrazně efektivnější.
Automatické aktualizace
Dalším užitečným krokem je pravidelná aktualizace systému. V předchozím příkladu jsme export dat ChatGPT zpracovali jednou. V praxi však neustále vzniká nový obsah.
Nové konverzace, nové poznámky, nové dokumenty - všechny tyto informace se mohou stát součástí vašeho znalostního archivu.
Proto se vyplatí uvažovat o automatických aktualizacích. Jedním z jednoduchých řešení je pravidelný import nových dat. Například:
- Jednou týdně zpracovat nová data chatu
- Automatický import nových dokumentů
- Okamžité přidání nových článků do databáze
Technicky je to poměrně snadné. Malý skript může pravidelně kontrolovat, zda jsou k dispozici nové soubory, a automaticky je zpracovávat. Díky tomu může váš znalostní systém neustále růst. Postupem času se vytváří stále rozsáhlejší archiv, který dokumentuje vaše myšlenky a projekty.
Integrace do vlastních aplikací
Náš systém byl dosud používán prostřednictvím jednoduchých skriptů v jazyce Python. Z dlouhodobého hlediska lze však tento systém integrovat i do vlastních aplikací. Mnoho vývojářů například vytváří malá webová rozhraní, která umožňují využívat znalostní AI přímo.
Místo spuštění skriptu pak můžete jednoduše napsat otázku do vstupního pole. Stejný proces běží na pozadí:
- Vytvořit vložení
- Vyhledávací databáze
- Přenos kontextu do UI
- Generování odpovědi
Výsledek se pak zobrazí přímo v uživatelském rozhraní. Taková aplikace může mít velmi různou podobu. Například:
- osobní výzkum AI
- znalostní asistent pro projekty
- vyhledávač nápadů
- archiv článků a poznámek
Zvláště zajímavé je, když tyto systémy zkombinujete s dalšími nástroji. Například redakční systém by mohl automaticky přistupovat k vašemu znalostnímu archivu a používat předchozí články jako základ pro výzkum. Nebo systém poznámek by mohl automaticky integrovat nové nápady do vaší databáze.
Jinými slovy, umělá inteligence se stane součástí vašeho každodenního pracovního prostředí. Z toho je zřejmé, že náš malý projekt dalece přesahuje původní export dat ChatGPT.
Nevytvořili jsme pouze archiv. Vytvořili jsme architekturu, kterou lze podle potřeby rozšiřovat. A právě v tom spočívá skutečná hodnota takových systémů. Nejsou statické. Rostou spolu s vašimi znalostmi.
Rozšířená verze potrubí ke stažení
Následující skript je rozšířenou verzí pipeline z článku. Je robustnější a mnohem blíže produktivnímu řešení. Byly vylepšeny tři věci:
- Ukazatel pokrokuUživatel může kdykoli zjistit, kolik textů již bylo zpracováno.
- Dávkový importVložené soubory jsou shromažďovány a zapisovány do Qdrantu v blocích, což je výrazně rychlejší než jednotlivé importy.
- Rychlejší vkládací potrubíSkript pracuje strukturovaně s připravenými částmi a omezuje zbytečná volání.
Tento skript je proto vhodný zejména v případě, že je export ChatGPT větší - například několik tisíc konverzací. Typický postup:
- Načíst export ChatGPT
- Výpis textů
- Rozdělení textu na části
- Vytvoření vložených položek
- Dávkový import do Qdrant
- Proveďte testovací dotaz
Důležitá nastavení ve skriptu
Některé hodnoty musí uživatel upravit:
- EXPORT_PFAD
Cesta k většinou číslovaným souborům conversations.json z exportu ChatGPT. - COLLECTION_NAME
Název kolekce vektorových databází. - EMBED_MODEL
Vkládací model Ollama, např. nomic-embed-text nebo mxbai-embed-large - ANSWER_MODEL
Jazykový model pro testovací dotaz, např. llama, mistral nebo gpt:oss. - VECTOR_SIZE
Rozměr vkládaného modelu.
nomic-embed-text → 768
mxbai-embed-large → 1024 - CHUNK_SIZE
Velikost textových oddílů.
Obvykle 300-600 slov. - BATCH_SIZE
Kolik vložení je zapsáno do Qdrantu současně.
Typická hodnota: 50-200.
Zůstaňte v obraze - bez reklamy
Pokud chcete být informováni o aktualizacích tohoto skriptu nebo o novinkách ke stažení, můžete se přihlásit k odběru mého měsíčního zpravodaje. Zpravodaj je záměrně úsporný, zcela bez reklam a vychází pouze jednou měsíčně. Najdete v něm výběr nejdůležitějších nových článků, praktický obsah o umělé inteligenci, softwaru a digitalizaci a také informace o aktualizovaných skriptech nebo nových nabídkách ke stažení. Žádný spam, žádné každodenní e-maily - jen ten nejdůležitější obsah v kompaktní podobě. Pokud chcete tento vývoj sledovat průběžně, je newsletter nejjednodušší způsob, jak zůstat v obraze.
Výhled na část 3: Dolaďování, analýza a optimalizace využití dat
Ve třetí části seriálu půjdeme ještě o krok dál a podíváme se na to, co vlastně můžete z vytvořené databáze znalostí získat. Nyní, když jsou data ChatGPT uložena v Qdrant, se zaměříme na jejich skutečné využití. Podíváme se na webové rozhraní Qdrant, analyzujeme uložená data a ověříme, jak dobře již funguje sémantické vyhledávání. Podíváme se také na důležité jemné úpravy: Jak by mělo být chunkování zvoleno v závislosti na případu použití? Jak lze optimálně přenést kontext do lokálního jazykového modelu? A jak konkrétně lze zlepšit kvalitu odpovědí? Třetí část je určena všem, kteří chtějí ze systému vytěžit více a vědomě jej dále rozvíjet.




Často kladené otázky
- Jaký smysl má integrace exportu dat ChatGPT do mého vlastního UI?
Největší výhodou je, že můžete dlouhodobě využívat své vlastní rozhovory a myšlenky. Mnoho lidí vede intenzivní rozhovory se systémy umělé inteligence o projektech, nápadech, analýzách nebo osobních záležitostech. Tento obsah v průběhu fungování platformy obvykle mizí. Pokud jej však vyexportujete a začleníte do vlastní znalostní databáze, stane se z něj osobní archiv. Vaše místní AI pak může k tomuto obsahu přistupovat, rozpoznávat korelace a pomáhat vám s novými otázkami. Místo toho, abyste vždy začínali od nuly, stavíte krok za krokem na svém vlastním myšlení. - Není to pro někoho, kdo není vývojář, velmi složité?
Na první pohled se pojmy jako embeddingy, vektorové databáze nebo systémy RAG zdají být složité. V praxi jsou však jednotlivé kroky poměrně jasně strukturované. V zásadě potřebujete pouze tři komponenty: lokální UI (např. prostřednictvím Ollama), vektorovou databázi, jako je Qdrant, a malý skript v jazyce Python, který zpracovává vaše data. Mnoho kroků je automatických. Jakmile je systém nastaven, funguje jako běžný vyhledávač nebo chatbot - s tím rozdílem, že pracuje s vašimi vlastními znalostmi. - Jaká data vlastně export ChatGPT obsahuje?
Export ChatGPT obvykle obsahuje všechny konverzace, které jste se systémem vedli. To zahrnuje nejen samotné textové zprávy, ale také metadata, jako jsou názvy konverzací, časové značky a strukturální informace. Data jsou obvykle k dispozici ve formátu JSON, a proto je lze poměrně snadno zpracovat pomocí skriptů. V mnoha případech export obsahuje také mediální nebo jazykové soubory, pokud byly v konverzacích použity. Při vytváření znalostní databáze je však zajímavý především textový obsah. - Proč se pro takové systémy používá vektorová databáze, a ne normální databáze?
Běžné databáze jsou ideální pro vyhledávání konkrétních výrazů nebo ID. Jsou však méně vhodné pro sémantické vyhledávání. Vektorová databáze ukládá texty nejen jako řetězce znaků, ale také jako matematické vektory, které popisují význam textu. To umožňuje systému vyhledávat podobnost obsahu. Pokud například zadáte dotaz na „nápady na články o umělé inteligenci“, databáze dokáže najít i obsah, který obsahuje jiné fráze, například „témata na články na blog o umělé inteligenci“. - Co jsou to embeddings a proč jsou tak důležité?
Vložené texty jsou matematickou reprezentací textů. Jazykový model převádí text na seznam čísel, která popisují význam textu. Texty s podobným významem leží v matematickém prostoru blízko sebe. To umožňuje vektorové databázi později vyhledávat podobný obsah. Bez embeddingů by sémantické vyhledávání bylo stěží možné. Tvoří základ moderních systémů RAG a jsou důvodem, proč jsou tyto systémy mnohem flexibilnější než klasické fulltextové vyhledávání. - Jak velký může být můj export dat z ChatGPT?
Velikost nehraje zásadní roli. Bez problémů lze zpracovat i několik tisíc konverzací. Důležitější je počet vygenerovaných textových úseků, tzv. chunks. Větší export vede k většímu počtu chunků, a tedy i k většímu počtu vložení. Moderní vektorové databáze však bez problémů zvládají miliony takových záznamů. Pro soukromého znalostního asistenta zcela postačí i malý server nebo výkonný stolní počítač. - Proč je text před zpracováním rozdělen na malé části?
Pokud ukládáte celé konverzace nebo rozsáhlé texty přímo jako vložené texty, stává se sémantické vyhledávání nepřesným. Jeden text může obsahovat několik témat. Jeho rozdělením na menší úseky může systém později vyhledávat mnohem přesněji. Každý oddíl popisuje přehlednější téma. Databáze tak dokáže najít přesně ty části konverzace, které skutečně odpovídají aktuální otázce. - Jakou roli hraje Ollama v tomto systému?
Ollama slouží jako místní platforma pro jazykové modely. Umožňuje spouštět modely umělé inteligence přímo na vlastním počítači. V našem systému plní Ollama dvě úlohy: Vytváří osazení textů a generuje odpovědi na otázky. Výhodou je, že všechna data zůstávají lokální. To znamená, že vaše konverzace a archiv znalostí nikdy neopustí váš vlastní počítač. - Proč se Qdrant používá jako vektorová databáze?
Qdrant je moderní vektorová databáze, která byla vyvinuta speciálně pro aplikace umělé inteligence. Je rychlá, snadno installieren a velmi dobře zdokumentovaná. Lze ji také snadno připojit k jazyku Python a mnoha frameworkům pro umělou inteligenci. Qdrant je proto obzvláště praktickým řešením pro lokální znalostní systémy. Mezi alternativy patří Chroma, Weaviate nebo Pinecone. - Co znamená pojem systém RAG?
Zkratka RAG znamená „Retrieval-Augmented Generation“. Jedná se o architekturu, ve které umělá inteligence nejprve vyhledá relevantní informace z databáze a poté je použije k vygenerování odpovědi. UI tedy kombinuje své vlastní znalosti s externími daty. To jí umožňuje poskytovat velmi přesné odpovědi a zároveň získat přístup k aktuálním nebo osobním informacím. - Mohu do tohoto systému integrovat i jiné zdroje dat?
To je vlastně jedna z největších výhod této architektury. Systém není omezen na data ChatGPT. Můžete do něj integrovat i své vlastní články, poznámky, soubory PDF, výzkumné práce nebo jiné dokumenty. Pokud lze obsah zpracovat v textové podobě, může se stát součástí znalostní báze. Časem se váš systém rozroste v komplexní znalostní archiv. - Jak aktuální je takový systém znalostí?
Aktuálnost závisí na tom, jak často importujete nová data. Můžete například pravidelně zpracovávat nové exporty ChatGPT nebo vytvořit skript, který automaticky rozpozná nové dokumenty. Mnoho systémů je nastaveno na aktualizaci jednou týdně nebo jednou měsíčně. Díky tomu je znalostní báze vždy aktuální. - Jaký hardware pro takový systém potřebuji?
Pro menší projekty postačí moderní stolní počítač. Pokud chcete používat větší jazykový model, může se vám hodit grafický procesor. Mnoho uživatelů však své znalostní systémy úspěšně provozuje i na výkonném notebooku nebo miniserveru. Především je důležité mít dostatek paměti a dostatečný úložný prostor pro databázi. - Jak rychle takový systém funguje v praxi?
Rychlost závisí na několika faktorech, například na velikosti databáze, hardwaru a použitém jazykovém modelu. V mnoha případech trvá dotaz jen několik sekund. Samotné vektorové vyhledávání je obvykle extrémně rychlé. Největší část času často zabere generování odpovědi z jazykového modelu. - Je možné oddělit několik oblastí znalostí?
Ano, vektorové databáze, jako je Qdrant, umožňují použití více kolekcí. Každá kolekce může představovat samostatnou tematickou oblast. Můžete například vytvořit kolekci pro konverzace ChatGPT, jednu pro články a jednu pro poznámky. To umožňuje přehledně strukturovat oblasti znalostí a cíleně v nich vyhledávat. - Jak bezpečná jsou moje data v místním systému umělé inteligence?
Velkou výhodou místního systému je, že data nemusíte přenášet do externích služeb. Všechny informace zůstávají ve vašem vlastním počítači nebo serveru. To je zajímavé zejména v případě citlivého obsahu. Samozřejmě byste měli i nadále vytvářet pravidelné zálohy a chránit svůj systém před neoprávněným přístupem. - Mohu tento systém integrovat i do svých vlastních aplikací?
Ano, k většině komponent lze přistupovat prostřednictvím programovacích rozhraní. To vám umožní integrovat znalostní systém do vlastních nástrojů, například do webového rozhraní, redakčního systému nebo aplikace pro poznámky. Mnoho vývojářů vytváří malé aplikace, které zpřístupňují znalostní databázi přímo přes chatovací rozhraní. - Jak by se tato technologie mohla v budoucnu vyvíjet?
Osobní znalostní umělé inteligence jsou pravděpodobně teprve na začátku svého vývoje. V budoucnu by tyto systémy mohly automaticky integrovat nový obsah, vytvářet souhrny nebo dokonce poskytovat vlastní návrhy projektů. Čím více dat do takového systému proudí, tím je cennější. V dlouhodobém horizontu by se mohl vyvinout v jakousi osobní digitální paměť, která strukturuje vaše znalosti a kdykoli je zpřístupní.



