
Podczas gdy MLX został pierwotnie uruchomiony jako eksperymentalny framework przez Apple Research, w ostatnich miesiącach nastąpił cichy, ale znaczący rozwój: Wraz z wydaniem FileMaker 2025, Claris mocno zintegrował MLX z serwerem jako natywną infrastrukturę AI dla Apple Silicon. Oznacza to, że każdy, kto pracuje z komputerem Mac i polega na Apple Silicon, może nie tylko uruchamiać modele MLX lokalnie, ale także używać ich bezpośrednio w FileMaker - z natywnymi funkcjami, bez żadnych warstw pośrednich.

Granice między lokalnym eksperymentem MLX a profesjonalną aplikacją FileMaker zaczynają się zacierać - na rzecz w pełni zintegrowanego, identyfikowalnego i kontrolowanego przepływu pracy AI.
Nowy obszar AI na serwerze FileMaker: „Usługi AI“
Centralnym elementem tej nowej architektury jest obszar „Usługi AI“ w konsoli administratora FileMaker Server 2025, w którym programiści i administratorzy mogą:
- aktywować serwer modelu AI,
- Zarządzanie modelami (pobieranie, dostarczanie, dostrajanie),
- Przypisywanie kluczy API dla autoryzowanych klientów,
- i monitorować bieżące operacje AI w ukierunkowany sposób.
Jeśli serwer FileMaker działa na komputerze Mac z Apple Silicon, zintegrowany serwer modeli AI automatycznie wykorzystuje MLX jako zaplecze wnioskowania. Niesie to ze sobą wszystkie zalety, jakie MLX oferuje na urządzeniach Apple: wysoką wydajność pamięci, natywne wykorzystanie GPU poprzez Metal oraz wyraźne oddzielenie modelu od infrastruktury - tak jak w świecie Apple.
Udostępnianie modeli MLX bezpośrednio przez konsolę serwera
Wdrożenie modelu MLX jest łatwiejsze niż oczekiwano: W konsoli administracyjnej AI obsługiwane modele można wybierać bezpośrednio z rosnącej listy modeli językowych zgodnych z Claris i wdrażać je na serwerze install. Są to modele open source (np. warianty Mistral, LLaMA lub Phi), które są dostępne w formacie .npz i zostały specjalnie przekonwertowane dla MLX. Obecnie (stan na wrzesień 2025 r.) liczba dostępnych modeli jest jednak nadal dość ograniczona.
Alternatywnie można przygotować własne modele - na przykład konwertując modele twarzy z uściskiem za pomocą narzędzia mlx-lm. Za pomocą jednego polecenia można pobrać model, skwantyfikować go i przekonwertować do odpowiedniego formatu. Następnie można go udostępnić w katalogu serwera - zgodnie z tym samym schematem, którego Claris używa wewnętrznie. Po zainstalowaniu installiert, modele te są natychmiast dostępne dla wszystkich obsługiwanych funkcji AI w FileMaker.
Natywne funkcje AI w FileMaker Pro: skryptowanie zamiast objazdów
To, co wcześniej działało za pośrednictwem zewnętrznych interfejsów API, wywołań REST i ręcznie budowanych procedur JSON, jest teraz dostępne w FileMaker 2025 w postaci dedykowanych poleceń skryptowych. Po skonfigurowaniu konta AI - z nazwą modelu i połączeniem z serwerem - zadania AI można płynnie zintegrować z interfejsem użytkownika i logiką biznesową.
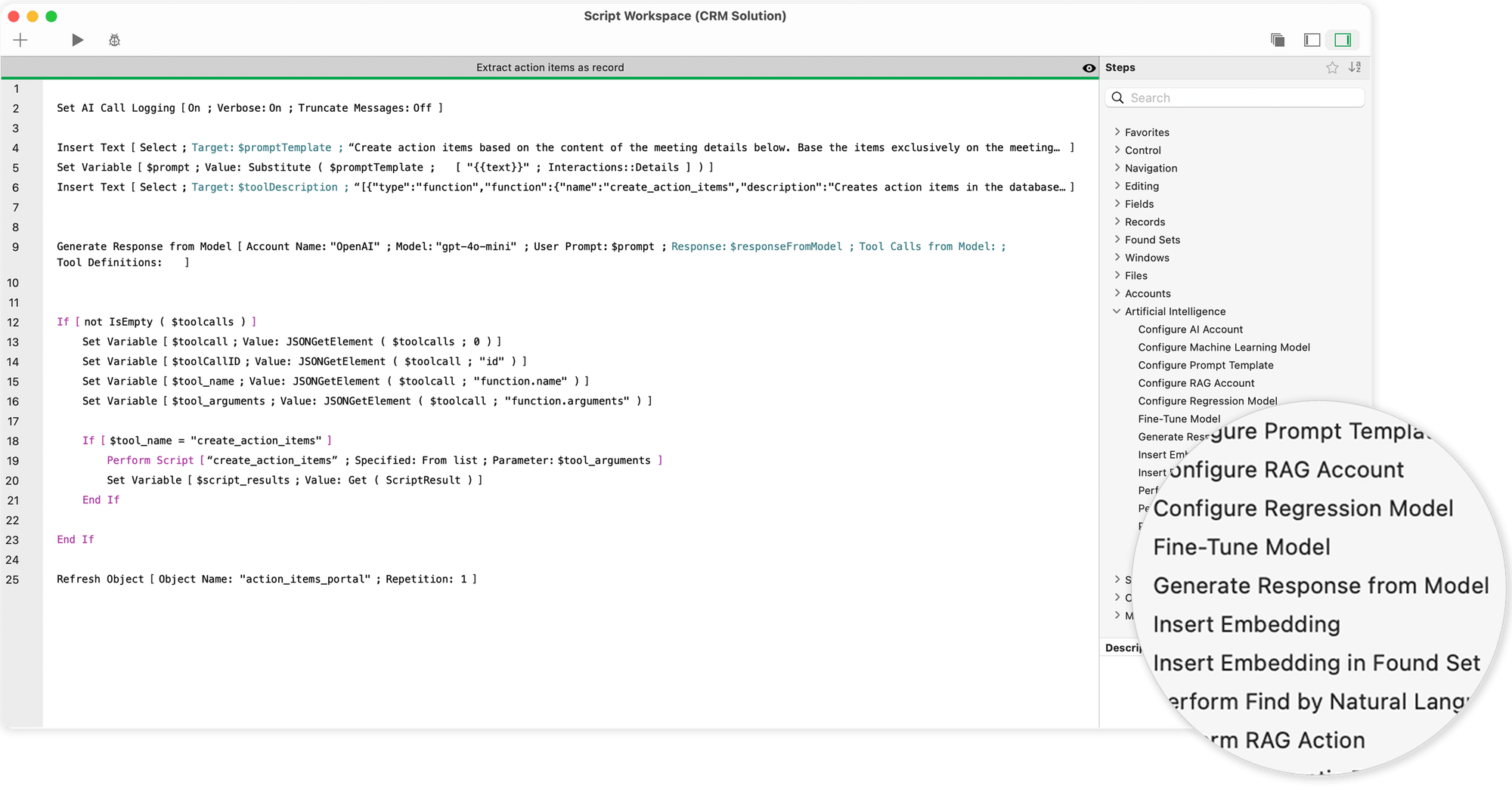
Najważniejsze polecenia obejmują
- „Generuj odpowiedź z modelu“, które mogą być używane do generowania odpowiedzi tekstowych - na przykład do automatycznych sugestii tekstowych, funkcji czatu lub szkiców wiadomości e-mail.
- „Wykonaj wyszukiwanie za pomocą języka naturalnego“, która przekłada proste sformułowanie („Pokaż mi wszystkich klientów z Berlina z otwartymi fakturami“) na precyzyjne zapytanie do bazy danych.
- „Wykonaj zapytanie SQL za pomocą języka naturalnego“, który może być również używany do generowania i przetwarzania złożonych struktur SQL - w tym złączeń i podzapytań.
- „Get Embedding“ i powiązane funkcje, które umożliwiają analizę wektorów semantycznych - na przykład w celu wyszukiwania tekstów o podobnej treści lub zapytań klientów.
Wszystkie te polecenia uzyskują dostęp do aktualnie wybranego modelu MLX działającego w tle na serwerze AI Model Server. Odpowiedzi są natychmiast dostępne i mogą być przetwarzane bezpośrednio - jako tekst, JSON lub osadzony wektor.
Kroki skryptu i możliwości sztucznej inteligencji w FileMaker
Kroki skryptu dla sztucznej inteligencji umożliwiają bezpośrednią integrację potężnych modeli sztucznej inteligencji - takich jak duże modele językowe (LLM) lub Core ML - z przepływami pracy FileMaker. Tworzą one techniczną podstawę do łączenia języka naturalnego, wiedzy bazodanowej i uczenia maszynowego. Dostępne są następujące funkcje:
- Konfiguracja nazwanego konta AI
Można skonfigurować i nazwać konkretne konto AI, które jest następnie używane we wszystkich dalszych krokach skryptu i funkcjach. Pozwala to zachować kontrolę nad uwierzytelnianiem i dostępem do zewnętrznych modeli lub usług. - Pobieranie odpowiedzi tekstowej na podstawie monitu
Model AI może reagować na podpowiedź wprowadzoną przez użytkownika i generować odpowiednią odpowiedź tekstową. Umożliwia to automatyczne generowanie tekstu, sugestii lub funkcji dialogowych. - Zapytanie do bazy danych na podstawie monitu i schematu bazy danych
Przekazując monit w języku naturalnym wraz ze schematem strukturalnym bazy danych, model może zidentyfikować odpowiednią zawartość i zwrócić ukierunkowany wynik. - Generowanie zapytań SQL
Model może również generować zapytania SQL na podstawie podpowiedzi i schematu bazy danych. Pozwala to na automatyczne generowanie złożonych zapytań, które można następnie wykorzystać do operacji na bazie danych. - Zapytania wyszukiwania FileMaker oparte na polach układu
Przekazując pola bieżącego układu do modelu wraz z monitem w języku naturalnym, zapytania wyszukiwania mogą być formułowane automatycznie i pobierane odpowiednie zestawy wyników. - Wstawianie wektorów osadzania do rekordów danych
Użytkownik ma możliwość wstawiania osadzeń semantycznych - tj. wektorów liczbowych reprezentujących znaczenia - do pól poszczególnych rekordów danych lub całych zestawów wyników. Stanowi to podstawę do późniejszych porównań semantycznych lub analiz AI. - Przeprowadzenie wyszukiwania semantycznego
W oparciu o znaczenie zapytania, system może zidentyfikować rekordy danych, których pola mają podobne znaczenie - nawet jeśli słowa nie pasują dokładnie. Otwiera to nowe możliwości inteligentnego wyszukiwania danych. - Konfigurowanie szablonów monitów
Można definiować szablony monitów wielokrotnego użytku, które mogą być używane w innych krokach skryptu lub funkcjach. Zapewnia to spójność i oszczędza czas podczas tworzenia ustrukturyzowanych monitów. - Konfiguracja modelu regresji
Model regresji można skonfigurować do zadań takich jak prognozy, szacunki lub analizy trendów, które następnie działają na zestawach danych liczbowych. Nadaje się na przykład do analizy rozwoju sprzedaży lub oceny ryzyka. - Konfiguracja konta RAG i zarządzanie nim
Można skonfigurować nazwane konto RAG (Retrieval Augmented Generation). Umożliwia to dodawanie lub usuwanie danych oraz wysyłanie określonych monitów do przestrzeni RAG. Systemy RAG łączą klasyczne wyszukiwanie z odpowiedziami generowanymi przez sztuczną inteligencję. - Dostrajanie modelu za pomocą danych treningowych
Można ponownie trenować istniejący model z własnym zestawem danych, aby lepiej dostosować go do określonych wymagań, stylów językowych lub obszarów zadań. Precyzyjne dostrojenie zwiększa trafność i jakość wyników. - Rejestr połączeń AI
Rejestrowanie wszystkich połączeń AI można aktywować w celu śledzenia i analizy. Jest to pomocne w optymalizacji podpowiedzi, rozwiązywaniu problemów lub dokumentacji - Konfiguracja modeli Core ML
Oprócz modeli LLM opartych na chmurze, można również skonfigurować lokalnie wykonywane modele Core ML. Jest to szczególnie przydatne w przypadku aplikacji offline lub do użytku na urządzeniach Apple ze zintegrowaną obsługą ML.
Aktualna ankieta na temat przyszłości Claris FileMaker i sztucznej inteligencji
Dostrajanie bezpośrednio z FileMaker: LoRA jako nowy standard
Jedną z najbardziej ekscytujących nowych funkcji jest możliwość dostrajania własnych modeli bezpośrednio w FileMaker - całkowicie w ramach znanego interfejsu. Wszystko czego potrzebujesz to komenda skryptu: „Fine-Tune Model“.
Rekordy danych z tabel FileMaker (np. historie wsparcia, dialogi klientów, próbki tekstu) mogą być używane jako dane treningowe. Metoda dostrajania opiera się na LoRA (Low-Rank Adaptation), procedurze oszczędzającej zasoby, która zmienia tylko niewielką część parametrów modelu, a tym samym umożliwia szybkie dostosowanie - nawet na urządzeniach z ograniczoną pamięcią.
Dane treningowe są pobierane z bieżącego znalezionego zestawu lub importowane za pośrednictwem pliku JSONL. Po treningu przypisywana jest nowa nazwa modelu - np. „fm-mlx-support-v1“ - a wynik jest natychmiast dostępny dla dalszych funkcji AI. Pozwala to na tworzenie niestandardowych modeli językowych, które są precyzyjnie dostosowane do danej aplikacji pod względem tonu, słownictwa i zachowania.
Ochrona danych i wydajność - dwie strony tego samego medalu
Fakt, że FileMaker 2025 opiera się na lokalnych modelach z MLX, nie jest przypadkiem. W czasach, gdy suwerenność danych, zgodność z RODO i wewnętrzne wytyczne dotyczące bezpieczeństwa stają się coraz ważniejsze, takie podejście oferuje kilka korzyści:
- Brak chmury, brak zewnętrznych serwerów, brak kosztów APIWszystkie żądania pozostają w sieci użytkownika.
- Szybszy czas reakcji dzięki przetwarzaniu lokalnemu - szczególnie w przypadku powtarzających się procesów.
- Wysoka przejrzystość i możliwość kontroliKażda odpowiedź może być sprawdzona, każda zmiana śledzona, każdy krok szkoleniowy udokumentowany.
- Dostrajanie do własnych danychWiedza specyficzna dla firmy nie jest już przekazywana za pośrednictwem zewnętrznych dostawców, ale pozostaje w całości w systemie firmy.
Jednocześnie ważne jest realistyczne oszacowanie zasobów: Duże modele wymagają również solidnej infrastruktury lokalnej - takiej jak komputer Mac Apple Silicon z 32 lub 64 GB pamięci RAM, ewentualnie z buforowaniem SSD i dedykowanym profilem serwera. Ale ci, którzy wybiorą tę drogę, skorzystają w dłuższej perspektywie z maksymalnej kontroli i pełnej elastyczności.
MLX i FileMaker - nowy sojusz dla profesjonalistów
To, co początkowo wyglądało na równoległą ścieżkę - z jednej strony MLX jako ramy badawcze Apple, z drugiej strony FileMaker jako klasyczna platforma bazodanowa - teraz urosło do rangi zamkniętego systemu.
Firma Claris uznała, że nowoczesne aplikacje biznesowe potrzebują czegoś więcej niż formularzy, tabel i raportów. Potrzebują adaptacyjnej, rozumiejącej sztucznej inteligencji - zintegrowanej, a nie przykręcanej. Dzięki natywnej obsłudze MLX, nowym poleceniom AI i opcji lokalnego dostrajania, FileMaker 2025 oferuje kompletną platformę do tworzenia, kontrolowania i produktywnego wykorzystywania własnych procesów AI po raz pierwszy - bez konieczności polegania na zewnętrznych dostawcach lub zewnętrznych chmurach.
Dla deweloperów, którzy podobnie jak Ty cenią sobie przejrzystą, konserwatywnie przemyślaną i bezpieczną architekturę danych, jest to coś więcej niż postęp - to początek nowego sposobu pracy.
W innym artykule przedstawiam Porównanie Apple Silicon i NVIDIA i wyjaśnić, jaki sprzęt jest odpowiedni do uruchamiania lokalnych modeli językowych na komputerach Mac.


Często zadawane pytania
- Co dokładnie oznacza, że FileMaker 2025 „obsługuje MLX“?
FileMaker Server 2025 po raz pierwszy zawiera zintegrowany serwer modeli AI, który - jeśli jest zainstalowany na Apple Silicon Mac install - natywnie wykorzystuje modele MLX. Oznacza to, że można wdrożyć model kompatybilny z MLX (np. Mistral lub Phi-2) bezpośrednio za pośrednictwem konsoli administratora i używać go w rozwiązaniu FileMaker - bez objazdów za pośrednictwem usług zewnętrznych lub wywołań REST. - Jakiego sprzętu i oprogramowania potrzebuję do tego celu?
- Komputer Mac z procesorem Apple Silicon (M1, M2, M3, M4), najlepiej z 32-64 GB pamięci RAM,
- FileMaker Server 2025, na tym Macu installiert,
- FileMaker Pro 2025 dla rzeczywistego rozwiązania,
- i jeden lub więcej modeli kompatybilnych z MLX - dostarczonych przez Claris lub przekonwertowanych samodzielnie (np. przez mlx-lm). - Jak zintegrować taki model z moim rozwiązaniem FileMaker?
Możesz użyć nowej funkcji „Konfiguruj konto AI“ w skryptach FileMaker, aby określić, który model jest używany. Nazwa serwera, nazwa modelu i klucz autoryzacji są zdefiniowane. Następnie można natychmiast użyć innych funkcji AI - np. do generowania tekstu, osadzania lub wyszukiwania semantycznego. Wszystko działa za pośrednictwem natywnych kroków skryptu, nie jest już wymagana przeglądarka internetowa ani „Wstaw z adresu URL“. - Jakich funkcji AI mogę używać w FileMaker?
Dostępne są następujące funkcje (w zależności od typu modelu):
- Generowanie tekstu („Generuj odpowiedź z modelu“)
- Wyszukiwanie naturalne („Wykonaj wyszukiwanie za pomocą języka naturalnego“)
- SQL w języku codziennym („Perform SQL Query by Natural Language“)
- Wektory semantyczne („Get Embedding“, „Cosine Similarity“)
- Zarządzanie szablonem zachęty („Konfiguruj szablon zachęty“)
- Dostrajanie LoRA za pomocą własnych danych („Fine-Tune Model“)
Wszystkie funkcje są oparte na skryptach i mogą być płynnie zintegrowane z istniejącymi rozwiązaniami. - Jak działa dostrajanie bezpośrednio w FileMaker?
W FileMaker 2025 można dostroić istniejący model MLX bezpośrednio przez LoRA - tj. dostosować go za pomocą własnych danych. Aby to zrobić, należy użyć rekordów danych w tabeli (np. pytania + odpowiedzi) lub pliku JSONL. Wystarczy jedno polecenie skryptu („Fine-Tune Model“), aby utworzyć nowy, dostosowany model - który jest następnie natychmiast dostępny w rozwiązaniu. - Czy nadal muszę znać Python, JSON, API lub formaty modeli?
Nie, niekoniecznie. Claris celowo zadbał o to, by wiele z tych szczegółów technicznych zniknęło w tle. Możesz pracować z natywnymi poleceniami skryptu, samodzielnie zarządzać danymi w FileMaker i po prostu przetwarzać zwroty jako tekst lub wektor. Jeśli chcesz, możesz sięgnąć głębiej - ale teraz możesz to zrobić bez wiedzy programistycznej. - Jakie są zalety korzystania z MLX za pośrednictwem FileMaker w porównaniu z zewnętrznymi interfejsami API?
Zaletami są bezpieczeństwo danych, kontrola kosztów i wydajność:
- Nie jest wymagane połączenie z chmurą, wszystkie dane pozostają we własnej sieci.
- Brak kosztów API lub limitów tokenów - raz installiert jest darmowy.
- Bardzo krótkie czasy odpowiedzi, ponieważ nie występują opóźnienia w sieci.
- Pełna kontrola nad danymi szkoleniowymi, dostrajanie i wersjonowanie modeli.
Jest to prawdziwy przełom, szczególnie w przypadku aplikacji wewnętrznych, rozwiązań branżowych lub wrażliwych procesów. - Czy są jakieś ograniczenia lub rzeczy, na które należy uważać?
Tak - MLX działa tylko na Apple Silicon, czyli serwer Intela jest wykluczony. Aby większe modele działały niezawodnie, potrzebna jest również wystarczająca ilość pamięci RAM. Nie wszystkie modele są od razu kompatybilne - niektóre wymagają konwersji. I na koniec: Chociaż wiele rzeczy działa „automatycznie“, zawsze należy przeprowadzić dedykowany test w celu produktywnego wykorzystania - np. z niewielką ilością danych, jasnymi definicjami celów i dobrą strategią rejestrowania.
Materiał zdjęciowy (c) Claris Inc. i Kohji Asakawa na Pixabay