
Hoy en día, cualquiera que trabaje con IA se ve empujado casi automáticamente a la nube: OpenAI, Microsoft, Google, cualquier interfaz web, tokens, límites, términos y condiciones. Esto parece moderno, pero es esencialmente una vuelta a la dependencia: otros determinan qué modelos puedes utilizar, con qué frecuencia, con qué filtros y a qué precio. Yo voy deliberadamente en la dirección contraria: actualmente estoy construyendo mi propio pequeño estudio de IA en casa. Con mi propio hardware, mis propios modelos y mis propios flujos de trabajo.
Mi objetivo es claro: IA local de texto, IA local de imagen, aprendizaje de mis propios modelos (LoRA, puesta a punto) y todo ello de tal forma que yo, como autónomo y más adelante también cliente de una PYME, no dependa de los caprichos diarios de algún proveedor en la nube. Se podría decir que es una vuelta a una vieja actitud que solía ser bastante normal: „Las cosas importantes las haces tú mismo“. Solo que esta vez no se trata de tu propio banco de trabajo, sino de potencia informática y soberanía de datos.




La velocidad sigue siendo imbatible a nivel local
Los modelos en la nube son impresionantes, siempre y cuando la línea esté conectada, los servidores no estén sobrecargados y la API no esté siendo estrangulada de nuevo. Pero cualquiera que trabaje en serio con IA se da cuenta rápidamente de que la forma más honesta de velocidad es la local. Si un modelo se ejecuta en tu propio Mac Studio o en tu propia GPU, entonces es cierto:
- Sin latencia de red
- Sin tiempo de espera hasta que „los otros“ estén listos
- No hay cancelaciones por horas
- No hay „Límite de velocidad alcanzado“ en medio del flujo de trabajo
Lo experimento cada día: en mi Estudio Mac ejecuta un modelo de 120B (GPT-OSS) y un modelo Gemma de 27B en paralelo, además de un servidor FileMaker y todas mis bases de datos. Sin embargo, el sistema sigue respondiendo tan bien que puedo trabajar a una velocidad casi imposible de alcanzar con sistemas en la nube. Sobre todo cuando se realizan muchas operaciones pequeñas seguidas -traducciones, reformulaciones, análisis, solicitudes de imágenes-, los retrasos se acumulan rápidamente. La IA local no se siente como una „operación de servidor“, sino como una herramienta directa: pulsas, sucede.
Soberanía de datos: cuando la información sensible no pertenece a Internet
Un punto que a menudo se deja de lado, pero que es crucial para los emprendedores: los datos. En cuanto se utiliza la IA en la nube, es inevitable hacerse preguntas:
- ¿Puedo introducir allí los datos de los clientes?
- ¿Qué ocurre con los documentos internos?
- ¿Cuánto tiempo se conservan los registros?
- ¿Quién tiene acceso en teoría, hoy y dentro de dos años?
- ¿Qué consecuencias jurídicas tendría una filtración?
Por supuesto, los grandes proveedores prometen protección de datos. Pero al fin y al cabo, usted está entregando su contenido. Y eso es exactamente lo que querías evitar en tu propia empresa en el pasado: Las cosas internas se quedaban en casa. En un estudio local de IA, la situación es distinta:
- Los datos permanecen en tu propia red.
- Ninguna petición sale de casa.
- Los modelos funcionan sin acceso a Internet.
- Los registros, los datos de entrenamiento y los resultados intermedios se almacenan en sus propios discos.
Cuando en el futuro pase mis libros, artículos, notas, textos de relaciones públicas, documentos de estrategia interna o datos de clientes por mi IA, quiero estar seguro de que nada de ello acabe en el conjunto de entrenamiento de otra persona. Sólo puedo tener esta confianza si la infraestructura me pertenece.
Control de costes en lugar de suscripciones progresivas
Las IA en la nube parecen baratas a primera vista: unos céntimos por cada 1.000 fichas, una suscripción mensual por aquí, una pequeña tarifa por allá. El problema es que los costes aumentan con tu éxito. Cuanto más productivo seas, más cara te resultará la infraestructura, cada mes. La IA local funciona de otra manera:
- Se invierte una vez en hardware.
- A continuación, ejecuta los modelos tantas veces como quieras.
- No „tiembla el dedo al pedir“ porque cada llamada cuesta dinero.
- Puedes experimentar más libremente sin tener que calcular cada entrada.
Compré mi RTX 3090 de segunda mano por unos 750 euros, prácticamente como nueva. Conseguí mi Mac Studio con 128 GB de RAM por unos 2.750 euros, en su embalaje original y nunca abierto. Eso es dinero, sí - pero:
- Estas máquinas me acompañarán durante muchos años.
- Usted crea activos directamente utilizables: libros, artículos, imágenes, LoRA, flujos de trabajo.
- No suponen ningún gasto mensual adicional, salvo la electricidad.
Para un editor, un consultor, un desarrollador o una pequeña empresa, esto puede suponer la diferencia entre „Tenemos que calcular si podemos permitírnoslo“ y „Nos limitaremos a utilizar la IA cuando la necesitemos“.
Viejas virtudes, nuevos beneficios: Por qué volver a tener máquinas propias merece la pena
En el pasado, se daba por sentado que un artesano disponía de buenas herramientas en su propio taller. Un taller de ebanistería sin un banco de trabajo y sierras adecuadas habría sido impensable. Hoy nos hemos acostumbrado a lo contrario: en lugar de tener nuestras propias máquinas, contratamos servicios. Un estudio interno de AI no es más que una versión moderna del taller clásico:
- En Estudio Mac ist die zentrale Maschine für Sprachmodelle.
- En RTX-Grafikkarte ist die Fräsmaschine für Bilder und Trainings.
- A Ordenador adicional (z. B. Mac mini) übernimmt Spezialaufgaben wie Voice oder kleine Modelle.
- Programas como FileMaker sirven de panel de control: orquestan, guardan y documentan.
Estoy construyendo una configuración de este tipo porque quiero ser capaz de hacer todo yo mismo en el largo plazo:
- Escribir y traducir libros,
- Generar series de imágenes,
- entrena tus propios modelos LoRA,
- Automatice los flujos de trabajo,
- y, más adelante, ofrecer también soluciones al cliente que puedan funcionar de forma totalmente local.
No se trata de nostalgia, sino de una decisión sobria: cuanto más profundamente interviene la IA en la vida cotidiana, más sensato es mantener el control sobre la tecnología. La IA local no es la „alternativa de aficionado“ a la extravagante nube, sino una vuelta consciente a la independencia:
- Ganas velocidad.
- Usted conserva sus datos.
- Usted controla sus costes.
- Construyes una infraestructura que te pertenece.
Si lo piensas hasta el final, un estudio de IA en casa se parece cada vez más a un taller clásico bien equipado: No dependes de lo que hacen otros en algún lugar en segundo plano, sino que construyes tu propia base estable.
Encuesta actual sobre sistemas locales de IA
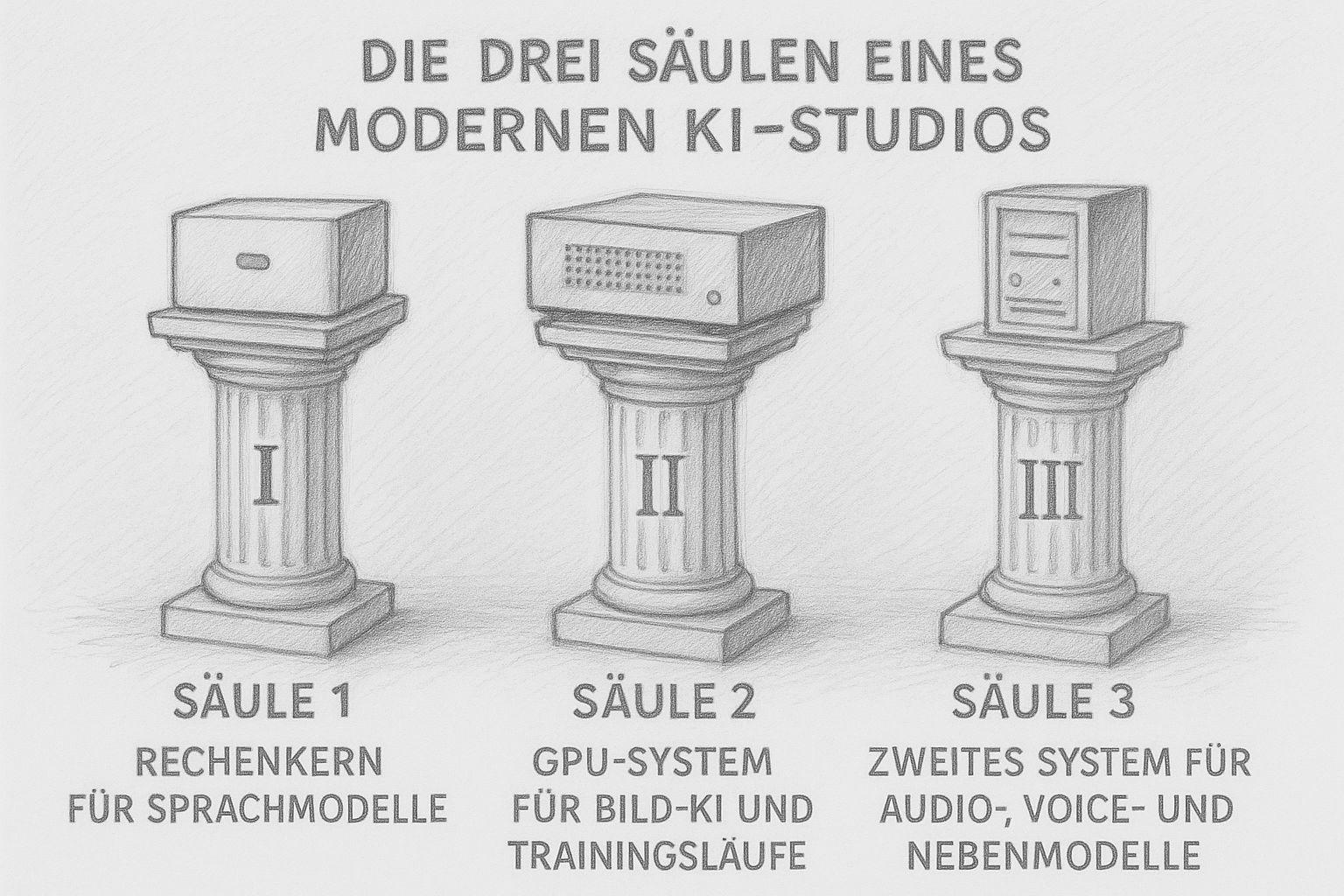
Los tres pilares de un estudio moderno de IA
Hoy en día, un estudio de IA ya no consiste en „un gran ordenador“ que lo haga todo. Los flujos de trabajo modernos necesitan diferentes puntos fuertes: potencia de cálculo para los textos, mucha VRAM para las imágenes y las ejecuciones de entrenamiento, y sistemas más pequeños que se encarguen de las tareas secundarias. El resultado no es una flota caótica de dispositivos, sino una pequeña infraestructura bien pensada, como un taller bien equipado en el pasado, donde cada máquina cumple su función.
Yo mismo construyo mi estudio siguiendo exactamente este principio. Y cuanto más profundizo en este asunto, más claro lo veo: Tres pilares bastan para dirigir localmente una producción completa de IA.
Pilar 1: El núcleo de cálculo de los modelos lingüísticos (LLM)
Hoy en día, los grandes modelos lingüísticos ya no requieren un servidor en un centro de datos, sino una cosa por encima de todo: mucha RAM muy rápida. Esto es exactamente lo que pueden hacer los modernos sistemas Apple-Silicon o máquinas Linux equipadas de forma similar con mucha RAM. El núcleo informático es la pieza central del estudio. Aquí es donde se ejecuta:
- Grandes LLM (20B, 30B, 70B, 120B MoE ...)
- Modelos de análisis
- Modelos de traducción
- Interno Sistemas de conocimiento (neo4j, RAG)
- también a largo plazo Memoria asistida por IA
- Sistemas de control como n8n
- FileMaker-Procesos de automatización y de servidor
En mi configuración, el Mac Studio M1 Ultra con 128 GB de RAM asume este papel. Y lo hace sorprendentemente bien. Corro con él:
- GPT-OSS 120B MoE (para pensamiento profundo, textos largos y análisis)
- Gemma-3 27B (para trabajos técnicos como FileMaker, código, estructuración precisa)
- Servidor FileMaker + bases de datos
- además de toda la infraestructura de shell y servidor web
Lo increíble es que, incluso con dos modelos grandes al mismo tiempo, quedan libres entre 10 y 15 GB de RAM. Esta es la ventaja de una arquitectura completamente diseñada para la memoria unificada. En pocas palabras: el núcleo informático es el cerebro del estudio de IA. Todo lo que comprende, genera o transforma texto ocurre aquí.
Pilar 2: el sistema de GPU para la IA de imágenes y las ejecuciones de entrenamiento
El segundo pilar es una estación de trabajo GPU, optimizada para Stable Diffusion, ComfyUI, ControlNet y el entrenamiento LoRA. Mientras que los modelos de texto requieren principalmente RAM, la IA de imágenes necesita VRAM. Y mucha. ¿Y por qué? Porque los modelos de imagen bombean cantidades gigantescas de datos a través de la memoria por fotograma. Y para eso están hechas las tarjetas gráficas. En mi estudio, esto lo hace una NVIDIA RTX 3090 con 24 GB de VRAM, y estos 24 GB valen su peso en oro. Permiten:
- SDXL con un tamaño de lote razonable
- Flujos de trabajo ComfyUI
- Síntesis de vídeo
- Serie de imágenes
- Formación sobre materiales y estilos
- Entrenamiento LoRA con 896×896 o incluso 1024×1024
Para la IA de imágenes, la VRAM es más importante que el último chip. Una sólida 3090 puede hacer más hoy que las caras tarjetas de gama media de 2025. La columna de la GPU es, por tanto, el „equipo pesado“ del estudio: la fresadora que sierra todo lo que signifique carga computacional. Sin ella, la producción seria de imágenes apenas es posible.
Pilar 3: Un segundo sistema de audio, voz y modelos secundarios
El tercer pilar puede parecer poco llamativo, pero es crucial: un sistema más pequeño y eficiente energéticamente que asuma tareas secundarias. Entre ellas:
- TTS (Texto a voz)
- STT (transcripción)
- modelos más pequeños (4B, 7B, 8B, 14B)
- estático Procesos de fondo
- pequeño Sistemas de agentes
- Herramientas, que desea que funcione por separado del sistema principal
Utilizo un pequeño Mac mini M4 con 32 GB de RAM. Perfectamente adecuado para:
- Susurro-Transcripción
- Voz-modelos
- luz Modelos de optimización
- reacción rápida Asistentes
- Experimentos y Pruebas de funcionamiento
- en paralelo Modelo de contenedor
Esto alivia enormemente el sistema principal. Al fin y al cabo, tiene sentido no cargar modelos grandes para cada trabajo pequeño. Al igual que antes no se encendía la gran sierra circular para cada corte en el taller, sino que se utilizaba una máquina pequeña. El tercer pilar garantiza la organización y la estabilidad.
Separa los grandes modelos de las pequeñas tareas, y eso hace que todo el estudio sea duradero, flexible y a prueba de fallos.
Distribución inteligente de las cargas de trabajo
Un estudio de IA se nutre del hecho de que cada máquina hace aquello para lo que fue construida. El resultado es un orden lógico:
- Núcleo de cálculo → Pensar, escribir, traducir, analizar
- Sistema GPU → Imágenes, modelos de entrenamiento, ComfyUI, vídeo
- Subsistema → Audio, voz, modelos pequeños, agentes
Cuando se añade software adicional -como FileMaker como mi sistema de control central-, se crea una auténtica cadena de producción. No más caos, no más „a ver dónde queda sitio“, sino un sistema organizado que funciona de forma estable todos los días.
Los tres pilares son los cimientos, no el estilo libre
Mucha gente cree que sólo se necesita un estudio de IA una vez que se es una „empresa de IA“. En realidad, es todo lo contrario: un estudio de IA sólido ES la base para convertirse en una. Con estos tres pilares, tienes todo lo que necesitas para:
- Producción de contenidos (texto e imagen)
- Enseñe a sus propios modelos
- Automatice los flujos de trabajo
- Trabajar independientemente de la nube
- desarrollar soluciones propias para los clientes
- operar „bancos de trabajo“ digitales a largo plazo
Para empresarios, creativos, autoeditores y desarrolladores, se trata ahora de una decisión estratégica que garantiza libertad, rapidez y control a largo plazo.
Hardware básico razonable para un pequeño estudio de IA
Si ves los anuncios de hoy en día, es posible que pienses que tienes que seguir comprando lo último en hardware para poder trabajar con IA a nivel local. Pero a menudo ocurre lo contrario: lo decisivo no son los últimos modelos, sino la combinación adecuada de RAM, VRAM y estabilidad. Muchos dispositivos antiguos -especialmente en el sector de las GPU- son ahora auténticos monstruos en relación calidad-precio. Y si se está dispuesto a pensar con originalidad, se puede construir un estudio de IA que haga justicia a una pequeña empresa sin sobrecargarse económicamente. Eso es exactamente lo que estoy haciendo yo mismo en este momento, y está funcionando sorprendentemente bien. Este capítulo te muestra tres clases de hardware: Principiante, Estándar y Profesional. Y, por supuesto, también te explico por qué algunos sistemas antiguos son más valiosos hoy de lo que crees.
1ª clase de entrada (1500-2500 euros)
Para todos aquellos que quieran empezar en el ámbito local, sin grandes inversiones. Esta clase es todo acerca de tomar sus primeros pasos sólidos:
- Mac mini M2 o M4 con 16-32 GB de RAM
- o un PC con RTX 3060/3070 (12-16 GB VRAM)
- y, opcionalmente, un pequeño NAS o externa SSD
Esta es una buena manera de:
- Funcionamiento de los modelos 7B a 14B
- Realizar traducciones locales
- Ejecutar Susurro
- Utilizar modelos de imagen más pequeños como SD 1.5/2.1
- Prueba ComfyUI en versión reducida
- Pruebe sus propios agentes o flujos de trabajo
Para muchos creativos o autónomos, esto es más que suficiente para ser productivos. Lo importante es no complicarse demasiado al empezar. El mayor peligro no es tener poca potencia, sino enredarse en demasiados detalles técnicos. Con un Mac mini M4, por ejemplo, se pueden hacer muchas cosas: Traducciones, investigación, estructura, incluso modelos de escritura más pequeños... y con un consumo de energía mínimo.
2ª clase estándar (2500-4000 euros)
El punto ideal para trabajar en serio con textos e imágenes. Aquí es donde empieza lo que yo llamaría un “verdadero estudio de IA“: una configuración que puede manejar tanto modelos de texto grandes como modelos de imagen sólidos. Una combinación típica:
- Estudio Mac M1 Ultra o M2 Max con 64 GB de RAM
- Estación de trabajo PC/GPU con RTX 3080, 3090 o 3090 Ti
- opcionalmente un pequeño Ordenador adicional para audio o voz
Con esta clase podrás:
- Accionamiento fiable de los modelos 20-40B
- Utilice Stable Diffusion XL de buena calidad
- Realiza el entrenamiento LoRA en el rango medio de conjuntos de datos
- Distribuir cargas de trabajo paralelas en varios dispositivos
- Establecer automatizaciones (por ejemplo, a través de FileMaker)
Y esto revela una verdad interesante: las GPU más antiguas, como la RTX 3090, siguen aplastando a muchas tarjetas nuevas de gama media. ¿Por qué? Tienen más VRAM (24 GB), mientras que las tarjetas nuevas a menudo han sido castradas. Tienen una interfaz de memoria amplia, ideal para modelos de amplia difusión. Tienen controladores CUDA maduros y estables. Suelen venderse usadas a precios increíbles. Una 3090 puede dar más de sí por 700-900 euros usada que una 4070 o 4070 Ti actual por 1100 euros, simplemente porque la VRAM y la conectividad de la memoria son más importantes que unos pocos puntos porcentuales de rendimiento bruto.
3ª clase profesional (4000-8000 euros)
Para todos aquellos que se toman en serio la producción y aspiran a una independencia total. Esta clase ofrece una potencia de producción real. Configuración típica:
- Estudio Mac M1 / M2 / M3 Ultra con 128 GB de RAM o más
- Sistema PC-GPU con RTX 3090 o 4090
- a segundo ordenador para audio/agentes
- Servidor FileMaker opcional como centro de automatización
Esto te permite:
- Utilizar con fluidez los modelos 70B
- Funcionamiento estable de modelos MoE como GPT-OSS 120B
- Coordinar agentes paralelos de IA
- SDXL, IA de vídeo, ComfyUI funcionando a pleno rendimiento
- Ejecuta los cursos LoRA con 896×896 o 1024×1024
- Prepare sus propias bases de datos para la formación
- Mapea tuberías completas (indicaciones → imágenes → PDFs → libros).
Y aquí es donde se puede ver lo más emocionante: el mejor hardware de IA de 2025 suele ser hardware de gama alta de 2020-2022. ¿Por qué? Se desarrolló para cargas de trabajo de gama alta en aquel entonces. Su precio es una fracción del actual. La tecnología está madura. No hay problemas de controladores beta. Tiene exactamente las características que la IA necesita: mucha VRAM, amplios buses de memoria, núcleos de tensor estables.
Por qué fracasas con poca VRAM y no con poca GPU
Este es un punto que muchos subestiman: La VRAM es el factor decisivo para la IA de imagen, no el rendimiento puro. Ejemplos:
- Un RTX 4060 (8 GB de VRAM) es prácticamente inutilizable para SDXL.
- Un RTX 4070 Ti (12 GB de VRAM) sólo es suficiente para entrenar de forma poco fiable.
- Un RTX 3090 (24 GB de VRAM), en cambio, funciona sin problemas durante años.
En resumen: los modelos grandes necesitan memoria, no marketing. Y memoria es lo que tienen las tarjetas antiguas de gama alta y no las nuevas de gama media.
Cómo ampliar modularmente un estudio de IA
La mayor ventaja de un estudio de tres pilares es su modularidad:
- La estación de trabajo GPU puede actualizarse de forma independiente.
- Puedes conservar el Mac Studio durante años.
- Puedes cambiar el ordenador esclavo sin perturbar el sistema.
- Puedes ampliar los discos duros o SSD por separado.
- Puede utilizar FileMaker, Python o Bash como orquestación.
Es como un taller: No se reconstruye todo al mismo tiempo, sino sólo lo que se necesita en cada momento.
La IA local es ahora REALMENTE utilizable (y funciona en este hardware) | c't 3003
Recomendaciones para 2025 - Este hardware merece realmente la pena
Es fácil perderse en la jungla de anuncios y especificaciones. Pero para el uso de la IA en el hogar o en pequeños estudios, hay clases de hardware que serán especialmente útiles en 2025, porque ofrecen una buena relación calidad-precio, son robustas y suficientes para los modelos actuales. Lo que importa hoy:
- Suficiente VRAM (para tareas de GPU)Para la IA de imágenes, las ejecuciones de entrenamiento, la difusión estable, etc., una tarjeta gráfica debe tener al menos 16 GB, preferiblemente 24 GB de VRAM. Por encima de este umbral, la IA de imágenes se vuelve cómoda y estable.
- Buena memoria de trabajo y capacidad RAM (para LLMs): Para grandes LLMs, multitarea con servicios de servidor y procesos paralelos, tiene sentido tener tanta RAM como sea posible - idealmente 64-128 GB para Apple-Silicon.
- Hardware estable y probado en lugar de los últimos productos de marketingLas tarjetas antiguas de gama alta, en particular, suelen tener excelentes especificaciones (VRAM, bus de memoria, madurez de los controladores) a un precio moderado.
- Modularidad y mezcla en lugar de monobloqueLa combinación de ordenador LLM, estación de trabajo GPU y sistema secundario/agente es más flexible y duradera que una sola máquina „todo en uno“.
| Clase | Componentes típicos | ¿Para quién? | Puntos fuertes / Compromisos |
|---|---|---|---|
| Nivel inicial (aprox. 1.500-2.500 euros) | Mac mini (16–32 GB RAM) oder PC mit GPU (z. B. RTX 3060 / 3060 Ti / 4060 Ti mit ≥ 12–16 GB VRAM) | Afición, primeros experimentos, modelos pequeños, imagen manejable AI | Günstiger Einstieg, ausreichend für kleinere LLMs, leichte Stable-Diffusion-Workflows und Audio-/Text-KI. Einschränkungen bei großen Modellen, komplexen ComfyUI-Pipelines und LoRA-Training. |
| Estándar (aprox. 2.500-4.000 euros) | Mittelklasse-GPU-Workstation (z. B. mit RTX 3080 oder RTX 3090), Rechner mit 64 GB RAM | Creativos, autoeditores, usuarios ambiciosos de IA, equipos pequeños | Solide Leistung für Texte & Bilder, gutes Preis-Leistungs-Verhältnis. Genug VRAM und RAM für vielseitige KI-Nutzung, inkl. SDXL und ersten LoRA-Trainings. Bei extremen Projekten oder vielen parallelen Workflows stößt das System irgendwann an Grenzen. |
| Profesional / Estudio (aprox. 4.000-8.000 euros) | Hoch-RAM-System (z. B. Mac Studio mit 128 GB RAM oder starke Linux-Workstation) + GPU mit ≥ 24 GB VRAM (z. B. RTX 3090, 4090) + separates Neben-/Agentensystem | Autónomos, editores, producciones audiovisuales, desarrolladores con múltiples proyectos, pequeños estudios de IA... | Maximale Flexibilität, große Modelle (70B, MoE), Bild- und Text-KI parallel, Automatisierungen und Langläufer-Workflows. Sehr zukunftssicher, aber höhere Anfangsinvestition und etwas mehr Planungsaufwand beim Aufbau. |
Por qué las GPU de gama alta usadas y antiguas suelen ser mejores que las tarjetas nuevas de gama media de hoy en día
Muchas tarjetas nuevas se ofrecen con una VRAM limitada, pero esto es crucial para la IA. Los modelos de gama alta más antiguos, como la RTX 3090, suelen ofrecer 24 GB de VRAM, algo muy valioso hoy en día para SDXL, entrenamiento LoRA o IA de vídeo. El hardware se diseñó originalmente para ofrecer rendimiento y estabilidad, con componentes de alta calidad, bus de memoria, refrigeración y un buen soporte de controladores.
Esto significa: durabilidad y rendimiento robusto suelen estar disponibles. Las tarjetas usadas suelen ser bastante más baratas y, por tanto, muy asequibles: ideales para autónomos o pequeños estudios con un presupuesto limitado.
Mi recomendación actual para 2025 (y por qué)
Si estuviera construyendo un estudio hoy y no aspirara a la máxima potencia de superordenador, me decidiría:
- Para imagen AIAl menos una GPU con 24 GB de VRAM, por ejemplo RTX 3090 o 4090.
- Para texto/LLM: 128 GB RAM in einem leistungsfähigen Apple-Silicon-System.
- Para trabajos a tiempo parcial (audio, voz, pequeños modelos, automatización): un pequeño ordenador independiente (por ejemplo, un mini PC o un servidor económico).
- Para la coordinaciónuna capa de software - para mí es FileMaker, para otros podría ser un simple shell o un pipeline de Python.
Esta configuración no es excesiva, ni depende de costosas licencias en la nube, y es suficiente para casi todo lo que se puede hacer con IA en el sector creativo, editorial o de desarrollo en 2025.
El hardware para la IA no tiene por qué ser nuevo, pero sí adecuado.
Hoy en día, la época en la que la „IA“ era solo cosa de grandes corporaciones o laboratorios en la nube está llegando a su fin. En 2025, casi cualquiera -con un presupuesto manejable y un poco de conocimientos técnicos- podrá montar su propio pequeño estudio de IA. Esto le independiza de las caras suscripciones mensuales, las condiciones de protección de datos de terceros, las colas, los cuellos de botella de los servidores y la incertidumbre de cuánto tiempo seguirán existiendo los servicios en la nube. En su lugar, usted obtiene:
- Control total sobre sus datos y sus flujos de trabajo,
- estable, rápida y Rendimiento escalable,
- un Inversión sostenible, que dura años,
- y el Libertad, ser creativo cuando y como quieras, sin limitaciones externas.
Así que, si estás pensando en utilizar IA para tus libros, textos, imágenes o proyectos, merece más la pena que nunca montar tu propio estudio. No hace falta ser ingeniero de hardware. No necesitas un presupuesto enorme. No necesitas lo último en hardware.
Por encima de todo, se necesita una idea clara del objetivo que se persigue y la voluntad de mantener el control sobre los propios procesos.
Wie Du mit Ollama ein lokales LLM auf einem Mac installierst, zeige ich in este artículo.
Aquí encontrará una comparación de Apple MLX en Silicon frente a NVIDIA.
Cómo trabajar con Qdrant una memoria local para su IA local puede encontrarse aquí.

Preguntas más frecuentes
- ¿Por qué merece la pena tener tu propio estudio de IA cuando hay tantos proveedores en la nube?
Tener tu propio estudio de IA te hace más independiente, más estable y más barato a largo plazo. Los servicios en la nube son cómodos, pero cuestan dinero cada mes, crean dependencia y suelen estar limitados por restricciones de uso. La IA local es rápida, está disponible permanentemente y puede utilizarse sin costes variables. Además, todos los datos permanecen en la propia empresa: una gran ventaja para autónomos, empresas, editoriales o profesiones creativas. - ¿Qué hardware mínimo necesito para empezar con la IA a nivel local?
Para empezar, basta con un Mac mini con 16-32 GB de RAM o un PC con una GPU con al menos 12 GB de VRAM. Esto te permite ejecutar pequeños modelos lingüísticos, modelos de imagen ligeros y automatizaciones iniciales. Si solo quieres probarlo, no hace falta que inviertas varios miles de euros. - ¿Realmente necesito un Mac Studio o es más barato?
Sin duda, es más barato. Un Mac Studio merece la pena si quieres ejecutar grandes modelos lingüísticos (20-120B), trabajar mucho en paralelo o tener procesos de producción a largo plazo. Para tus primeros pasos, un Mac mini o un sólido PC con Windows son perfectamente adecuados. Un estudio es una inversión en comodidad y futuro, pero no una obligación. - ¿Por qué la VRAM es más importante para la IA de imágenes que una generación moderna de tarjetas gráficas?
Porque los modelos de imagen como la Difusión Estable arrastran enormes cantidades de datos a través de la memoria. Si la VRAM no es suficiente, el proceso se detiene o se vuelve extremadamente lento. Una tarjeta más antigua, como la RTX 3090 con 24 GB de VRAM, suele superar a los nuevos modelos de gama media con solo 8-12 GB de VRAM, simplemente porque ofrece más espacio para modelos grandes y ejecuciones de entrenamiento. - ¿Puedo ejecutar un estudio de IA completamente con hardware Apple sin NVIDIA?
Para modelos de lenguaje, sí. Para la IA de imágenes, no. Apple-Silicon es extremadamente eficiente para los LLM, pero para la difusión estable, el entrenamiento de LoRA y muchos modelos de imágenes, las tarjetas NVIDIA (debido a los núcleos CUDA/Tensor) siguen siendo la referencia. Por ello, muchos estudios utilizan una mezcla de Apple/LLM y Linux+NVIDIA para imágenes. - ¿Una RTX 4080 o 4070 Ti también es suficiente para la IA de imágenes?
En teoría sí, pero en la práctica depende del uso previsto. Para imágenes simples o pequeños flujos de trabajo, es suficiente. Pero para SDXL, complejos pipelines ComfyUI o entrenamiento LoRA, el límite de 12-16 GB de VRAM alcanza rápidamente sus límites. Por tanto, una RTX 3090 o 4090 tiene más sentido a largo plazo. - ¿Por qué los modelos lingüísticos no se ejecutan en la GPU, sino en la RAM?
Los modelos lingüísticos están orientados a la memoria. Necesitan almacenar grandes cantidades de texto y contexto en la RAM, no necesariamente realizar operaciones gráficas. Las GPU están diseñadas para el procesamiento de imágenes, no para el análisis de texto. Por eso los sistemas LLM se benefician enormemente de una gran cantidad de RAM, pero menos de la VRAM. - ¿Cuánta memoria RAM debe tener un ordenador LLM?
Para modelos pequeños, basta con 32-64 GB. Para modelos medianos (20-30B), 64-128 GB es lo ideal. Para modelos grandes como 70B o modelos MoE como GPT-OSS 120B, 128-192 GB de RAM es lo ideal. Cuanta más RAM, más estable y rápido funcionará todo. - ¿Es posible ejecutar un estudio de IA completamente sin Linux?
Sí, pero con limitaciones. macOS es perfecto para los LLM, pero para la IA de imágenes carece de algunas herramientas que sólo existen en Linux/NVIDIA. Windows funciona bien para la IA de imágenes, pero es menos estable y más difícil de automatizar. Por lo tanto, la mezcla pragmática suele ser: macOS → LLM, Linux → IA de imágenes, ordenador pequeño → audio/scripts. - ¿Cómo de ruidoso es un estudio de IA como éste en funcionamiento?
Menos de lo que imaginas. Un Mac Studio es prácticamente silencioso. Un PC Linux depende de la refrigeración: las GPU de alta calidad son silenciosas con poca carga, pero pueden hacerse audibles durante los entrenamientos. Si prefieres construcciones silenciosas, puedes utilizar estaciones de trabajo con GPU refrigeradas por agua. - ¿Qué papel desempeña el Mac mini como tercer componente?
Sirve como estación secundaria para transcripciones, TTS, pequeños modelos de IA, procesos en segundo plano, automatización y trabajos secundarios para traducciones. Así se mantienen libres las dos máquinas grandes y se garantiza la estabilidad de los flujos de trabajo. Un tercer ordenador no es absolutamente necesario, pero crea orden y fiabilidad. - ¿Puedo ampliar gradualmente mi estudio de IA?
Por supuesto. De hecho, es el caso ideal. Comprar un sistema LLM, luego añadir una estación de trabajo con GPU y más tarde un pequeño ordenador secundario, es una configuración muy natural que puede alargarse durante meses o años. Los estudios de IA crecen igual que los talleres tradicionales. - ¿Qué sistemas operativos son los más adecuados para un estudio de IA?
- macOS → óptimo para los modelos LLM y Apple-Silicon.
- Linux (Ubuntu, Debian) → mejor opción para IA de imágenes, ComfyUI, Stable Diffusion.
- Windows → funciona bien para SD/ComfyUI, pero es menos ideal para procesos de automatización.
Hoy en día, muchos estudios utilizan sistemas combinados: cada sistema hace lo que mejor se le da. - ¿Cuánta energía consume un estudio de IA?
Un Mac Studio es asombrosamente eficiente y suele consumir entre 50-100 W. Una estación de trabajo GPU con RTX 3090 puede consumir entre 250 y 350 W, dependiendo de la carga. Un Mac mini ronda los 10-30 W. En definitiva, mucho menos de lo que cabría esperar, y a menudo más barato que las suscripciones a la nube. - ¿Es difícil montar uno mismo un estudio de IA?
La verdad es que no. Se necesitan algunos conocimientos técnicos, pero no una licenciatura en informática. Muchas herramientas actuales tienen interfaces web, scripts de instalación y configuraciones automáticas. Y si separas claramente los sistemas (LLM / GPU / trabajos secundarios), todo queda claro. - ¿Realmente puedo cubrir con él procesos completos de publicación?
Sí, y para eso precisamente es ideal un estudio de AI. Desde la idea del libro hasta el texto, el diseño de la cubierta, las series de imágenes, las correcciones, las traducciones y el archivo final impreso o de libro electrónico, muchas cosas pueden automatizarse y producirse internamente. Esto supone una enorme libertad para los autoeditores. - ¿Hasta qué punto está preparado para el futuro un estudio de IA?
Muy. Los LLM son cada vez más eficientes, los modelos de imagen más modulares, el hardware más duradero... y la IA local vuelve a cobrar importancia en el mercado porque las leyes, la protección de datos y los costes de la nube la hacen menos atractiva. Cualquiera que invierta hoy en un pequeño estudio de IA está construyendo una infraestructura que será más importante que obsoleta en 2026-2030. - ¿Pueden entrenarse o ampliarse posteriormente los modelos de IA?
Sí, se puede utilizar un sistema GPU (por ejemplo, RTX 3090 o 4090) para el entrenamiento de LoRA, el entrenamiento de estilos, el entrenamiento de materiales y el entrenamiento de procesos. Esto significa que puedes entrenar tu propio „lenguaje visual de IA“ o „dirección de texto de IA“ con el tiempo. Esta es la mayor ventaja estratégica de un estudio de IA: te independizas de los modelos genéricos y creas tu propio estilo.