
Każdy, kto pracuje dziś ze sztuczną inteligencją, jest niemal automatycznie wypychany do chmury: OpenAI, Microsoft, Google, wszelkie interfejsy internetowe, tokeny, limity, warunki. Wydaje się to nowoczesne - ale zasadniczo jest to powrót do zależności: inni określają, z których modeli możesz korzystać, jak często, z jakimi filtrami i za jaką cenę. Celowo idę w drugą stronę: obecnie buduję własne małe studio AI w domu. Z własnym sprzętem, własnymi modelami i własnymi przepływami pracy.
Mój cel jest jasny: lokalna sztuczna inteligencja tekstu, lokalna sztuczna inteligencja obrazu, uczenie się własnych modeli (LoRA, dostrajanie), a wszystko to w taki sposób, abym jako freelancer, a później także klient MŚP, nie był zależny od codziennych kaprysów jakiegoś dostawcy chmury. Można powiedzieć, że to powrót do starej postawy, która kiedyś była całkiem normalna: „ważne rzeczy robisz sam“. Tyle, że tym razem nie chodzi o własny warsztat pracy, ale o moc obliczeniową i suwerenność danych.




Prędkość lokalna pozostaje bezkonkurencyjna
Modele chmurowe są imponujące - tak długo, jak łącze działa, serwery nie są przeciążone, a interfejs API nie jest ponownie dławiony. Ale każdy, kto poważnie pracuje ze sztuczną inteligencją, szybko zdaje sobie sprawę, że najbardziej uczciwą formą szybkości jest szybkość lokalna. Jeśli model działa na twoim własnym Mac Studio lub twoim własnym GPU, to jest to prawda:
- Brak opóźnień sieciowych
- Brak czasu oczekiwania, aż „inni“ będą gotowi
- Brak odwołań godzinowych
- Brak komunikatu „Osiągnięto limit szybkości“ w środku przepływu pracy
Doświadczam tego każdego dnia: na moim Mac Studio uruchamia równolegle model 120B (GPT-OSS) i model 27B Gemma - plus serwer FileMaker i wszystkie moje bazy danych. Mimo to system pozostaje tak responsywny, że mogę pracować z prędkością, która jest prawie niemożliwa do osiągnięcia w systemach chmurowych. Zwłaszcza gdy wykonuje się wiele małych operacji z rzędu - tłumaczenia, przeformułowania, analizy, podpowiedzi obrazów - opóźnienia szybko się sumują. Lokalna sztuczna inteligencja nie działa jak „operacja na serwerze“, ale jak bezpośrednie narzędzie: naciskasz, to się dzieje.
Suwerenność danych: kiedy wrażliwe informacje nie są dostępne online
Jedną z kwestii, która jest często pomijana, ale ma kluczowe znaczenie dla przedsiębiorców, są dane. Gdy tylko korzystasz ze sztucznej inteligencji w chmurze, nieuchronnie zadajesz sobie pytania:
- Czy mogę tam wprowadzić dane klienta?
- Co dzieje się z dokumentami wewnętrznymi?
- Jak długo przechowywane są dzienniki?
- Kto teoretycznie ma dostęp - dziś i za dwa lata?
- Jakie konsekwencje prawne miałby wyciek?
Oczywiście duzi dostawcy oferują obietnice ochrony danych. Ale na koniec dnia przekazujesz swoje treści. I to jest dokładnie to, czego chciałeś uniknąć we własnej firmie w przeszłości: Wewnętrzne rzeczy pozostały wewnętrzne. W lokalnym studiu AI sytuacja wygląda inaczej:
- Dane pozostają w sieci użytkownika.
- Żadna prośba nie opuszcza domu.
- Modele działają bez dostępu do Internetu.
- Dzienniki, dane treningowe i wyniki pośrednie są przechowywane na własnych dyskach.
Kiedy w przyszłości będę przepuszczać moje książki, artykuły, notatki, teksty PR, wewnętrzne dokumenty strategiczne lub dane klientów przez moją sztuczną inteligencję, chcę mieć pewność, że żadna z nich nie trafi do czyjegoś zestawu szkoleniowego. Mogę mieć takie zaufanie tylko wtedy, gdy infrastruktura należy do mnie.
Kontrola kosztów zamiast rosnących subskrypcji
Sztuczne inteligencje w chmurze na pierwszy rzut oka wydają się tanie: kilka centów za 1000 tokenów, miesięczna subskrypcja tutaj, niewielka taryfa tam. Problem polega na tym, że koszty rosną wraz z sukcesem. Im większa produktywność, tym droższa staje się infrastruktura - każdego miesiąca. Lokalna sztuczna inteligencja działa inaczej:
- W sprzęt inwestuje się raz.
- Następnie uruchamiaj modele tak często, jak chcesz.
- Nie „drży palec zamawiającego“, ponieważ każde połączenie kosztuje.
- Możesz swobodniej eksperymentować bez konieczności obliczania każdego wejścia.
Mój RTX 3090 kupiłem z drugiej ręki za około 750 euro - praktycznie jak nowy. Mój Mac Studio z 128 GB RAM kupiłem za około 2750 euro, w oryginalnym opakowaniu i nigdy nie otwierany. To pieniądze, tak - ale:
- Te maszyny będą ze mną przez wiele lat.
- Tworzysz bezpośrednio użyteczne zasoby: książki, artykuły, obrazy, LoRA, przepływy pracy.
- Nie ponoszą one żadnych dodatkowych miesięcznych kosztów poza energią elektryczną.
Dla wydawcy, konsultanta, dewelopera lub małej firmy może to być różnica między „Musimy obliczyć, czy możemy sobie na to pozwolić“ a „Będziemy używać sztucznej inteligencji tylko wtedy, gdy będziemy jej potrzebować“.
Stare zalety, nowe korzyści: Dlaczego posiadanie własnych maszyn znów się opłaca
W przeszłości uważano za oczywiste, że rzemieślnik posiada dobre narzędzia we własnym warsztacie. Warsztat stolarski bez odpowiedniego stołu warsztatowego i pił byłby nie do pomyślenia. Dziś przyzwyczailiśmy się do czegoś odwrotnego: zamiast posiadać własne maszyny, wynajmujemy usługi. Własne studio AI to w zasadzie nic innego jak nowoczesna wersja klasycznego warsztatu:
- The Mac Studio jest centralnym silnikiem dla modeli językowych.
- The Karta graficzna RTX to frezarka do obrazów i szkoleń.
- A Dodatkowy komputer (np. Mac mini) wykonuje specjalne zadania, takie jak głos lub małe modele.
- Oprogramowanie takie jak FileMaker służy jako panel kontrolny: organizuje, zapisuje i dokumentuje.
Buduję taką konfigurację, ponieważ chcę być w stanie zrobić wszystko sam w dłuższej perspektywie:
- Pisanie i tłumaczenie książek,
- Generowanie serii obrazów,
- trenować własne modele LoRA,
- Automatyzacja przepływów pracy,
- a później także oferować klientom rozwiązania, które mogą działać całkowicie lokalnie.
To nie nostalgia, to trzeźwa decyzja: im głębiej sztuczna inteligencja ingeruje w codzienne życie, tym rozsądniej jest zachować kontrolę nad technologią. Lokalna sztuczna inteligencja nie jest „hobbystyczną alternatywą“ dla fantazyjnej chmury, ale świadomym powrotem do niezależności:
- Zyskujesz na szybkości.
- Zachowujesz swoje dane.
- Kontrolujesz swoje koszty.
- Budujesz infrastrukturę, która należy do ciebie.
Jeśli przemyśleć to do końca, domowe studio AI coraz bardziej przypomina klasyczny, dobrze wyposażony warsztat: Nie polegasz na tym, co robią inni gdzieś w tle, ale budujesz własną stabilną bazę.
Bieżąca analiza lokalnych systemów sztucznej inteligencji
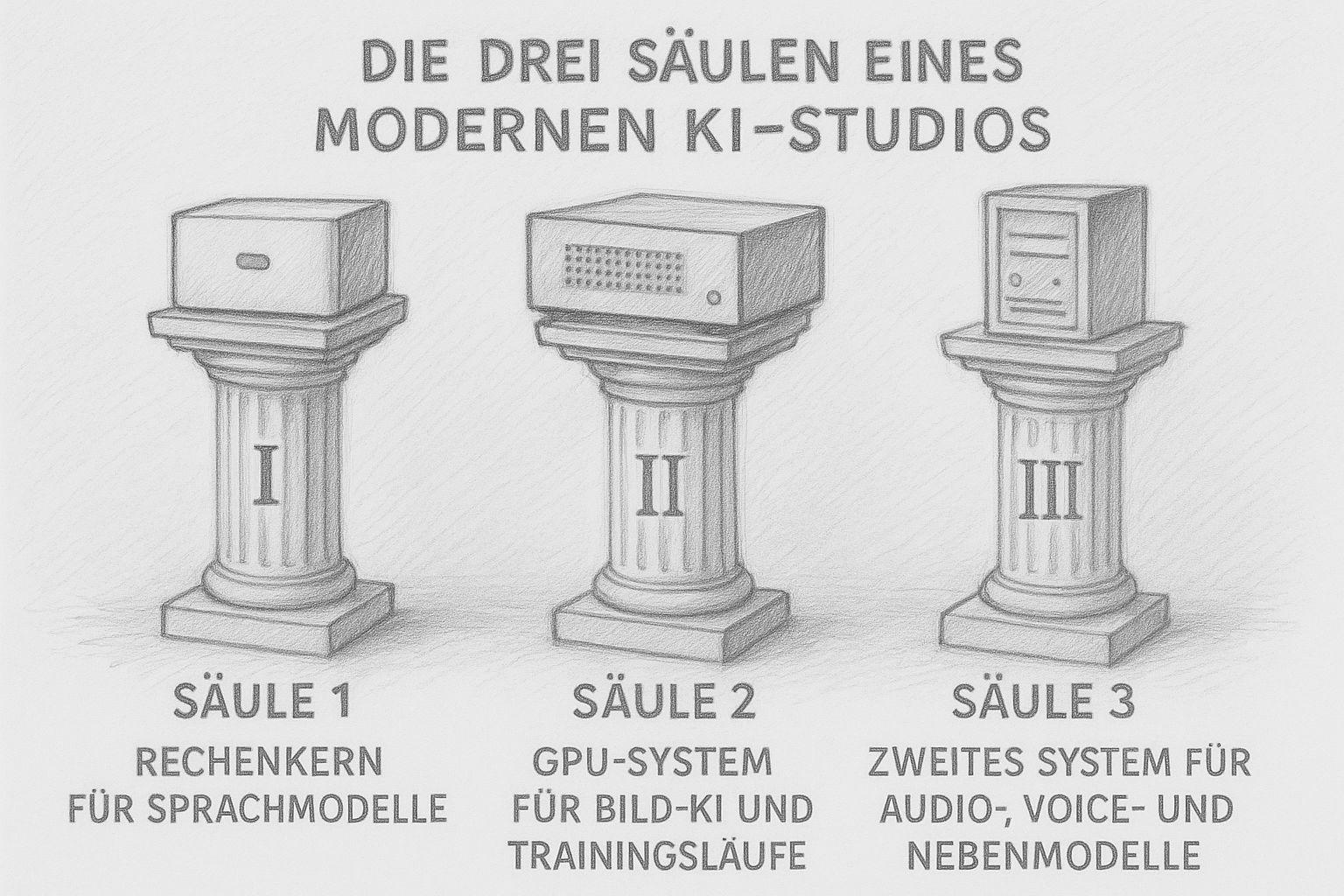
Trzy filary nowoczesnego studia AI
Dziś studio AI nie składa się już z „jednego dużego komputera“, który robi wszystko. Nowoczesne przepływy pracy wymagają różnych mocy: mocy obliczeniowej dla tekstów, dużej ilości pamięci VRAM dla obrazów i przebiegów treningowych oraz mniejszych systemów, które podejmują się zadań pobocznych. Rezultatem nie jest chaotyczna flota urządzeń, ale dobrze przemyślana mała infrastruktura - jak dobrze wyposażony warsztat w przeszłości, w którym każda maszyna spełnia swoje zadanie.
Sam buduję swoje studio dokładnie według tej zasady. A im bardziej zagłębiam się w tę kwestię, tym staje się ona jaśniejsza: Trzy filary wystarczą, by lokalnie uruchomić kompletną produkcję AI.
Filar 1: Jądro obliczeniowe dla modeli językowych (LLM)
Obecnie duże modele językowe nie wymagają już serwera w centrum danych, ale przede wszystkim jednej rzeczy: dużej ilości bardzo szybkiej pamięci RAM. Dokładnie to potrafią nowoczesne systemy Apple-Silicon lub podobnie wyposażone maszyny Linux z dużą ilością pamięci RAM. Rdzeń obliczeniowy jest centralnym elementem studia. To tutaj wszystko działa:
- Duże programy LLM (20B, 30B, 70B, 120B MoE ...)
- Modele analityczne
- Modele tłumaczeń
- Wewnętrzny Systemy wiedzy (neo4j, RAG)
- również długoterminowy Pamięć obsługiwana przez sztuczną inteligencję
- Systemy sterowania takie jak n8n
- FileMaker-Automatyzacja i procesy serwerowe
W mojej konfiguracji rolę tę pełni Mac Studio M1 Ultra z 128 GB pamięci RAM. I robi to zadziwiająco dobrze. Działam na nim:
- GPT-OSS 120B MoE (do głębokiego myślenia, długich tekstów i analiz)
- Gemma-3 27B (do prac technicznych, takich jak FileMaker, kod, precyzyjne strukturyzowanie)
- Serwer FileMaker + bazy danych
- plus cała infrastruktura powłoki i serwera WWW
Niesamowite jest to, że nawet przy dwóch dużych modelach jednocześnie, 10-15 GB pamięci RAM pozostaje wolne. Jest to zaleta architektury, która jest całkowicie zaprojektowana dla zunifikowanej pamięci. Mówiąc w skrócie: rdzeń obliczeniowy jest mózgiem studia AI. Wszystko, co rozumie, generuje lub przekształca tekst, dzieje się tutaj.
Filar 2: System GPU dla sztucznej inteligencji obrazu i przebiegów treningowych
Drugim filarem jest stacja robocza GPU, zoptymalizowana pod kątem szkoleń Stable Diffusion, ComfyUI, ControlNet i LoRA. Podczas gdy modele tekstowe wymagają przede wszystkim pamięci RAM, sztuczna inteligencja obrazu potrzebuje pamięci VRAM. I to dużo. Dlaczego? Ponieważ modele obrazu przetwarzają gigantyczne ilości danych w pamięci na klatkę. Do tego właśnie służą karty graficzne. W moim studiu robi to NVIDIA RTX 3090 z 24 GB pamięci VRAM - a te 24 GB są na wagę złota. Pozwalają one na:
- SDXL z rozsądną wielkością partii
- Przepływy pracy ComfyUI
- Synteza wideo
- Seria zdjęć
- Szkolenie w zakresie materiałów i stylu
- Trening LoRA w rozdzielczości 896×896 lub nawet 1024×1024
Dla sztucznej inteligencji obrazu pamięć VRAM jest ważniejsza niż najnowszy chip. Solidny 3090 potrafi dziś więcej niż drogie karty średniej klasy z 2025 r. Kolumna GPU jest zatem „ciężkim sprzętem“ w studiu - frezarką, która piłuje wszystko, co oznacza obciążenie obliczeniowe. Bez niej poważna produkcja obrazu jest praktycznie niemożliwa.
Filar 3: Drugi system dla modeli audio, głosowych i drugorzędnych
Trzeci filar może wydawać się niepozorny, ale jest kluczowy: mniejszy, energooszczędny system, który przejmuje dodatkowe zadania. Obejmują one:
- TTS (zamiana tekstu na mowę)
- STT (transkrypcja)
- mniejsze modele (4B, 7B, 8B, 14B)
- statyczny Procesy w tle
- mały Systemy agentowe
- Narzędzia, które mają działać niezależnie od głównego systemu
Używam małego Mac mini M4 z 32 GB pamięci RAM. Idealnie nadaje się do:
- Szept-Transkrypcja
- Głos-modele
- światło Modele optymalizacji
- szybka reakcja Asystenci
- Eksperymenty i Przebiegi testowe
- równoległy Model pojemnika
To ogromnie odciąża główny system. W końcu nie ma sensu ładować dużych modeli do każdego małego zadania. Tak jak w przeszłości nie uruchamiało się dużej piły tarczowej do każdego cięcia w warsztacie, ale zamiast tego używało się małej maszyny. Trzeci filar zapewnia organizację i stabilność.
Oddziela duże modele od małych zadań - dzięki temu całe studio jest trwałe, elastyczne i bezawaryjne.
Inteligentna dystrybucja obciążeń
Studio AI rozwija się dzięki temu, że każda maszyna robi to, do czego została stworzona. Skutkuje to logicznym porządkiem:
- Rdzeń obliczeniowy → Myślenie, pisanie, tłumaczenie, analizowanie
- System GPU → Obrazy, modele treningowe, ComfyUI, wideo
- Podsystem → Audio, głos, małe modele, agenci
Po dodaniu dodatkowego oprogramowania - takiego jak FileMaker jako mój centralny system sterowania - powstaje prawdziwy potok produkcyjny. Koniec z chaosem, koniec z „zobaczmy, gdzie jest jeszcze miejsce“, ale zorganizowany system, który działa stabilnie każdego dnia.
Trzy filary to podstawa - nie styl dowolny
Wiele osób uważa, że studio AI jest potrzebne dopiero wtedy, gdy stajemy się „firmą AI“. W rzeczywistości jest wręcz przeciwnie: solidne studio AI JEST podstawą do stania się taką firmą. Dzięki tym trzem filarom masz wszystko, czego potrzebujesz:
- Tworzenie treści (tekst i obraz)
- Nauczanie własnych modeli
- Automatyzacja przepływów pracy
- Praca niezależnie od chmury
- opracowywanie własnych rozwiązań dla klientów
- obsługiwać cyfrowe „stoły robocze“ w perspektywie długoterminowej
Dla przedsiębiorców, twórców, self-publisherów i deweloperów jest to obecnie strategiczna decyzja, która zapewnia swobodę, szybkość i kontrolę w dłuższej perspektywie.
Rozsądny sprzęt klasy podstawowej dla małego studia AI
Jeśli oglądasz dzisiejsze reklamy, możesz pomyśleć, że musisz kupować najnowszy sprzęt, aby móc lokalnie pracować ze sztuczną inteligencją. Często jest jednak odwrotnie: to nie najnowsze modele są decydujące, ale odpowiednia kombinacja pamięci RAM, VRAM i stabilności. Wiele starszych urządzeń - zwłaszcza w sektorze GPU - to obecnie prawdziwe potwory pod względem stosunku ceny do wydajności. A jeśli jesteś gotowy myśleć nieszablonowo, możesz zbudować studio AI, które oddaje sprawiedliwość małej firmie bez nadmiernego obciążania się finansami. Dokładnie to robię teraz sam i działa to zaskakująco dobrze. Ten rozdział przedstawia trzy klasy sprzętu: Początkujący, Standardowy i Profesjonalny. Oczywiście wyjaśniam też, dlaczego niektóre starsze systemy są dziś bardziej wartościowe, niż mogłoby się wydawać.
1. klasa podstawowa (1500-2500 €)
Dla wszystkich, którzy chcą zacząć lokalnie - bez dużych inwestycji. Zajęcia poświęcone są stawianiu pierwszych solidnych kroków:
- Mac mini M2 lub M4 z 16-32 GB pamięci RAM
- lub PC z RTX 3060/3070 (12-16 GB VRAM)
- plus opcjonalnie mały NAS lub zewnętrzny SSD
To dobry sposób:
- Obsługa modeli od 7B do 14B
- Wykonywanie lokalnych tłumaczeń
- Run Whisper
- Używaj mniejszych modeli obrazu, takich jak SD 1.5/2.1
- Wypróbuj ComfyUI w zmniejszonej formie
- Testowanie własnych agentów lub przepływów pracy
Dla wielu kreatywnych lub samozatrudnionych osób jest to więcej niż wystarczające, aby stać się produktywnym. Ważne jest, aby nie komplikować zbytnio rozpoczęcia pracy. Największym zagrożeniem nie jest posiadanie zbyt małej mocy, ale ugrzęźnięcie w zbyt wielu szczegółach technicznych. Na przykład, Mac mini M4 może zdziałać niesamowicie wiele: Tłumaczenia, badania, struktury, nawet mniejsze modele pisma - i to przy minimalnym zużyciu energii.
2. klasa standardowa (2500-4000 €)
Najlepsze miejsce do poważnej pracy z tekstem i obrazami. W tym miejscu zaczyna się to, co nazwałbym “prawdziwym studiem AI“: konfiguracja, która może obsługiwać zarówno duże modele tekstowe, jak i solidne modele obrazów. Typowa kombinacja:
- Mac Studio M1 Ultra lub M2 Max z 64 GB pamięci RAM
- Stacja robocza PC/GPU z RTX 3080, 3090 lub 3090 Ti
- opcjonalnie mały Dodatkowy komputer dla dźwięku lub głosu
Dzięki tej klasie możesz:
- Niezawodny napęd modeli 20-40B
- Używaj Stable Diffusion XL w dobrej jakości
- Przeprowadzenie szkolenia LoRA w średnim zakresie zestawu danych
- Dystrybucja równoległych obciążeń na wielu urządzeniach
- Konfiguracja automatyzacji (np. za pośrednictwem FileMaker)
I to ujawnia interesującą prawdę: starsze GPU, takie jak RTX 3090, wciąż rozbijają na kawałki wiele nowych kart ze średniej półki. Dlaczego? Mają więcej pamięci VRAM (24 GB), podczas gdy nowe karty często są wykastrowane. Mają szeroki interfejs pamięci, idealny dla modeli o szerokiej dyfuzji. Mają dojrzałe i stabilne sterowniki CUDA. Często są sprzedawane jako używane w niesamowitych cenach. Karta 3090 może zrobić więcej za 700-900 euro, niż obecna 4070 lub 4070 Ti za 1100 euro - po prostu dlatego, że VRAM i łączność pamięci są ważniejsze niż kilka procent surowej wydajności.
3. klasa zawodowa (4000-8000 €)
Dla wszystkich, którzy poważnie podchodzą do produkcji i dążą do pełnej niezależności. W tej klasie dostępna jest prawdziwa moc produkcyjna. Typowa konfiguracja:
- Mac Studio M1 / M2 / M3 Ultra z 128 GB pamięci RAM lub więcej
- System PC-GPU z RTX 3090 lub 4090
- a drugi komputer dla audio/agentów
- Opcjonalny serwer FileMaker jako centrum automatyzacji
Pozwala to na:
- Płynne korzystanie z modeli 70B
- Stabilne działanie modeli MoE, takich jak GPT-OSS 120B
- Koordynacja równoległych agentów AI
- SDXL, wideo AI, ComfyUI działające z pełną wydajnością
- Prowadzenie szkoleń LoRA w rozdzielczości 896×896 lub 1024×1024
- Przygotowanie własnych baz danych do szkolenia
- Mapowanie kompletnych potoków (podpowiedzi → obrazy → pliki PDF → książki)
I właśnie w tym miejscu można dostrzec najbardziej ekscytującą rzecz: najlepszy sprzęt AI w 2025 r. jest często wykorzystywanym sprzętem premium z lat 2020-2022. Dlaczego? Został on wówczas opracowany dla zaawansowanych obciążeń. Dziś jest to ułamek jego ceny. Technologia jest dojrzała. Brak problemów ze sterownikami beta. Ma dokładnie te cechy, których potrzebuje sztuczna inteligencja: dużo pamięci VRAM, szerokie magistrale pamięci, stabilne rdzenie tensorowe.
Dlaczego zawodzi zbyt mała ilość pamięci VRAM, a nie zbyt mała moc GPU?
Jest to kwestia, której wielu nie docenia: Pamięć VRAM jest decydującym czynnikiem dla sztucznej inteligencji obrazu, a nie czysta wydajność. Przykłady:
- Jeden RTX 4060 (8 GB VRAM) jest praktycznie bezużyteczna dla SDXL.
- Jeden RTX 4070 Ti (12 GB VRAM) tylko w niewielkim stopniu wystarcza do treningu.
- Jeden RTX 3090 (24 GB VRAM), z drugiej strony, działa płynnie przez lata.
W skrócie: duże modele potrzebują pamięci - nie marketingu. A pamięć jest tym, co mają starsze karty z wyższej półki, a czego nie mają nowe karty ze średniej półki.
Jak modułowo rozbudować studio AI?
Największą zaletą trójfilarowego studia jest jego modułowość:
- Stacja robocza GPU może być aktualizowana niezależnie.
- Komputer Mac Studio można przechowywać przez lata.
- Komputer podrzędny można wymienić bez zakłócania pracy systemu.
- Dyski twarde lub SSD można rozbudowywać oddzielnie.
- Jako orkiestracji można użyć FileMaker, Python lub Bash.
To jak warsztat: Nie przebudowujesz wszystkiego naraz, ale tylko to, co jest potrzebne w danym momencie.

Lokalna sztuczna inteligencja jest teraz NAPRAWDĘ użyteczna (i działa na tym sprzęcie). c't 3003
Rekomendacje na 2025 rok - ten sprzęt naprawdę się opłaca
W gąszczu reklam i specyfikacji łatwo stracić orientację. Jednak do zastosowań AI w domu lub małym studiu istnieją klasy sprzętu, które będą szczególnie przydatne w 2025 roku - ponieważ oferują dobry stosunek ceny do wydajności, są solidne i wystarczające dla obecnych modeli. To, co liczy się dzisiaj:
- Wystarczająca ilość pamięci VRAM (dla zadań GPU)W przypadku sztucznej inteligencji obrazu, przebiegów treningowych, stabilnej dyfuzji itp. karta graficzna powinna mieć co najmniej 16 GB, a najlepiej 24 GB pamięci VRAM. Powyżej tego progu sztuczna inteligencja obrazu staje się wygodna i stabilna.
- Dobra pamięć robocza i pojemność pamięci RAM (dla LLM): W przypadku dużych LLM, wielozadaniowości z usługami serwerowymi i procesami równoległymi, sensowne jest posiadanie jak największej ilości pamięci RAM - najlepiej 64-128 GB dla Apple-Silicon.
- Stabilny, sprawdzony sprzęt zamiast najnowszych produktów marketingowychZwłaszcza starsze karty z wyższej półki często mają doskonałe specyfikacje (VRAM, magistrala pamięci, dojrzałość sterowników) przy umiarkowanej cenie.
- Modułowość i miksowanie zamiast monoblokówPołączenie komputera LLM, stacji roboczej GPU i systemu pomocniczego/agentowego jest bardziej elastyczne i trwałe niż pojedyncza maszyna typu „wszystko w jednym“.
| Klasa | Typowe komponenty | Dla kogo | Mocne strony / kompromisy |
|---|---|---|---|
| Poziom podstawowy (około 1 500-2 500 €) | Mac mini (16-32 GB RAM) lub PC z GPU (np. RTX 3060 / 3060 Ti / 4060 Ti z ≥ 12-16 GB VRAM) | Hobby, pierwsze eksperymenty, małe modele, obraz AI do opanowania | Korzystny poziom wejścia, wystarczający dla mniejszych LLM, lekkich stabilnych przepływów pracy z dyfuzją i sztucznej inteligencji audio/tekstowej. Ograniczenia w przypadku dużych modeli, złożonych potoków ComfyUI i szkolenia LoRA. |
| Standard (ok. 2 500-4 000 EUR) | Stacja robocza z GPU średniej klasy (np. z RTX 3080 lub RTX 3090), komputer z 64 GB pamięci RAM | Kreatywni, self-publisherzy, ambitni użytkownicy AI, małe zespoły | Solidna wydajność dla tekstu i obrazów, dobry stosunek ceny do wydajności. Wystarczająca ilość pamięci VRAM i RAM do wszechstronnego wykorzystania sztucznej inteligencji, w tym SDXL i początkowego szkolenia LoRA. Przy ekstremalnych projektach lub wielu równoległych przepływach pracy system w pewnym momencie osiąga swoje granice. |
| Profesjonalny / Studio (około 4,000-8,000 €) | System z dużą ilością pamięci RAM (np. Mac Studio z 128 GB pamięci RAM lub wydajna stacja robocza z systemem Linux) + GPU z ≥ 24 GB pamięci VRAM (np. RTX 3090, 4090) + oddzielny system pomocniczy/agentowy | Freelancerzy, wydawcy, produkcje medialne, deweloperzy z wieloma projektami, małe studia AI | Maksymalna elastyczność, duże modele (70B, MoE), równoległa sztuczna inteligencja obrazu i tekstu, automatyzacja i długotrwałe przepływy pracy. Bardzo przyszłościowa, ale wyższa początkowa inwestycja i nieco większy wysiłek związany z planowaniem podczas konfiguracji. |
Dlaczego używane i starsze high-endowe układy GPU są dziś często lepsze od nowych kart ze średniej półki cenowej?
Wiele nowszych kart jest oferowanych z ograniczoną ilością pamięci VRAM - ale ma to kluczowe znaczenie dla sztucznej inteligencji. Starsze modele z wyższej półki, takie jak RTX 3090, często oferują 24 GB pamięci VRAM, co jest obecnie bardzo cenne w przypadku SDXL, szkoleń LoRA lub sztucznej inteligencji wideo. Sprzęt został pierwotnie zaprojektowany z myślą o wydajności i stabilności - z wysokiej jakości komponentami, magistralą pamięci, chłodzeniem i dobrym wsparciem dla sterowników.
Oznacza to, że: trwałość i solidna wydajność są często dostępne. Używane karty są często znacznie tańsze, a zatem bardzo przystępne cenowo - idealne dla freelancerów lub małych studiów z ograniczonym budżetem.
Moja obecna rekomendacja na rok 2025 (i dlaczego)
Gdybym dziś budował studio i nie celował w maksymalną moc superkomputera, zdecydowałbym się:
- Dla obrazu AICo najmniej jedna karta graficzna z 24 GB pamięci VRAM - np. RTX 3090 lub 4090.
- Dla tekstu/LLM128 GB pamięci RAM w potężnym systemie Apple-Silicon.
- W przypadku pracy w niepełnym wymiarze godzin (audio, głos, małe modele, automatyzacja): mały, oddzielny komputer (np. mini PC lub niedrogi serwer).
- Koordynacjawarstwa oprogramowania - dla mnie jest to FileMaker, dla innych może to być prosta powłoka lub potok Pythona.
Ta konfiguracja nie jest przesadna, nie zależy od drogich licencji w chmurze - i jest wystarczająca dla prawie wszystkiego, co można zrobić ze sztuczną inteligencją w sektorze kreatywnym, wydawniczym lub deweloperskim w 2025 roku.
Sprzęt dla AI nie musi być nowy, ale odpowiedni
Dziś czas, w którym „sztuczna inteligencja“ była czymś tylko dla dużych korporacji lub laboratoriów w chmurze, dobiega końca. Do 2025 r. prawie każdy - z rozsądnym budżetem i odrobiną wiedzy technicznej - może założyć własne małe studio AI. Uniezależni się w ten sposób od drogich miesięcznych subskrypcji, warunków ochrony danych stron trzecich, kolejek, wąskich gardeł serwerów i niepewności co do tego, jak długo usługi w chmurze będą istnieć. Zamiast tego otrzymujesz:
- Pełna kontrola o danych i przepływach pracy,
- stabilny, szybki i Skalowalna wydajność,
- jeden Zrównoważone inwestycje, który przetrwa lata,
- i Wolność, być kreatywnym, kiedy i jak chcesz - bez zewnętrznych ograniczeń.
Tak więc, jeśli myślisz o wykorzystaniu sztucznej inteligencji w swoich książkach, tekstach, obrazach lub projektach, bardziej niż kiedykolwiek warto założyć własne studio. Nie musisz być inżynierem sprzętu. Nie potrzebujesz ogromnego budżetu. Nie potrzebujesz najnowszego sprzętu.
Przede wszystkim potrzebna jest jasna wizja celu, do którego się dąży - i chęć zachowania kontroli nad własnymi procesami.
Pokażę ci, jak skonfigurować lokalny LLM z Ollama na Macu installier w ten artykuł.
Tutaj znajdziesz porównanie Apple MLX na Silicon vs NVIDIA.
Jak pracować z Qdrant pamięć lokalna dla lokalnej AI można znaleźć tutaj.



Często zadawane pytania
- Dlaczego w ogóle warto mieć własne studio AI, skoro istnieje tak wielu dostawców usług w chmurze?
Posiadanie własnego studia AI sprawia, że jesteś bardziej niezależny, stabilny i tańszy w dłuższej perspektywie. Usługi w chmurze są wygodne, ale kosztują co miesiąc, powodują uzależnienie i często są ograniczone ograniczeniami użytkowania. Lokalna sztuczna inteligencja jest szybka, stale dostępna i może być używana bez zmiennych kosztów. Ponadto wszystkie dane pozostają w firmie - ogromna zaleta dla osób samozatrudnionych, firm, wydawców lub zawodów kreatywnych. - Jakiego minimalnego sprzętu potrzebuję, aby zacząć korzystać z AI lokalnie?
Na początek wystarczy komputer Mac mini z 16-32 GB pamięci RAM lub komputer PC z procesorem graficznym z co najmniej 12 GB pamięci VRAM. Pozwala to na uruchamianie niewielkich modeli językowych, lekkich modeli graficznych i wstępnych automatyzacji. Jeśli chcesz tylko wypróbować, nie musisz inwestować kilku tysięcy euro. - Czy naprawdę potrzebuję Mac Studio, czy jest tańszy?
Jest zdecydowanie tańszy. Mac Studio jest opłacalny, jeśli chcesz uruchamiać duże modele językowe (20-120B), pracować dużo równolegle lub mieć długoterminowe procesy produkcyjne. Do stawiania pierwszych kroków w zupełności wystarczy Mac mini lub solidny komputer PC z systemem Windows. Studio to inwestycja w wygodę i przyszłość - ale nie konieczność. - Dlaczego pamięć VRAM jest ważniejsza dla sztucznej inteligencji obrazu niż nowoczesna generacja kart graficznych?
Ponieważ modele obrazu, takie jak Stable Diffusion, przetwarzają ogromne ilości danych w pamięci. Jeśli pamięć VRAM jest niewystarczająca, proces ten zatrzymuje się lub staje się niezwykle powolny. Starsza karta, taka jak RTX 3090 z 24 GB VRAM, często pokonuje nowe modele średniej klasy z zaledwie 8-12 GB VRAM - po prostu dlatego, że oferuje więcej miejsca na duże modele i przebiegi treningowe. - Czy mogę uruchomić studio AI w całości na sprzęcie Apple bez NVIDIA?
Dla modeli językowych tak. W przypadku sztucznej inteligencji obrazu nie. Apple-Silicon jest niezwykle wydajny dla LLM, ale dla stabilnej dyfuzji, szkolenia LoRA i wielu modeli obrazu, karty NVIDIA (ze względu na rdzenie CUDA / Tensor) są nadal punktem odniesienia. Dlatego też wiele studiów korzysta z kombinacji Apple/LLM i Linux+NVIDIA dla obrazów. - Czy RTX 4080 lub 4070 Ti jest również wystarczający do graficznej sztucznej inteligencji?
Teoretycznie tak - w praktyce zależy to od zamierzonego zastosowania. W przypadku prostych obrazów lub małych przepływów pracy to wystarczy. Ale w przypadku SDXL, złożonych potoków ComfyUI lub szkoleń LoRA, limit 12-16 GB VRAM szybko osiąga swoje granice. RTX 3090 lub 4090 ma zatem większy sens w dłuższej perspektywie. - Dlaczego modele językowe nie są uruchamiane na GPU, ale na pamięci RAM?
Modele językowe są zorientowane na pamięć. Muszą przechowywać duże ilości tekstu i kontekstu w pamięci RAM, a niekoniecznie wykonywać operacje graficzne. Procesory graficzne są przeznaczone do przetwarzania obrazu, a nie analizy tekstu. Dlatego też systemy LLM czerpią ogromne korzyści z dużej ilości pamięci RAM, a mniejsze z pamięci VRAM. - Ile pamięci RAM powinien mieć komputer LLM?
W przypadku mniejszych modeli wystarczy 32-64 GB. W przypadku modeli średniej wielkości (20-30B) idealne jest 64-128 GB. W przypadku dużych modeli, takich jak 70B lub modeli MoE, takich jak GPT-OSS 120B, idealnym rozwiązaniem jest 128-192 GB pamięci RAM. Im więcej pamięci RAM, tym stabilniejsze i szybsze działanie. - Czy możliwe jest uruchomienie studia AI całkowicie bez Linuksa?
Tak - ale z ograniczeniami. macOS jest idealny do LLM, ale do sztucznej inteligencji obrazu brakuje mu niektórych narzędzi, które istnieją tylko w systemie Linux / NVIDIA. Windows działa dobrze w przypadku sztucznej inteligencji obrazu, ale jest mniej stabilny i trudniejszy do zautomatyzowania. Pragmatyczne połączenie to zatem często: macOS → LLM, Linux → sztuczna inteligencja obrazu, mały komputer → audio/skrypty - Jak głośno działa takie studio AI?
Mniej niż mogłoby się wydawać. Mac Studio jest praktycznie bezgłośny. Komputer PC z systemem Linux zależy od chłodzenia - wysokiej jakości GPU są ciche przy niskim obciążeniu, ale mogą stać się słyszalne podczas treningów. Jeśli wolisz ciche konstrukcje, możesz użyć stacji roboczych z GPU chłodzonych wodą. - Jaką rolę odgrywa Mac mini jako trzeci komponent?
Służy jako dodatkowa stacja do transkrypcji, TTS, małych modeli AI, procesów w tle, automatyzacji i dodatkowych zadań dla tłumaczeń. Dzięki temu dwie duże maszyny pozostają wolne i zapewniają stabilny przepływ pracy. Trzeci komputer nie jest absolutnie niezbędny, ale zapewnia porządek i niezawodność. - Czy mogę stopniowo rozbudowywać moje studio AI?
Jak najbardziej. W rzeczywistości jest to idealny przypadek. Zakup systemu LLM, a następnie dodanie stacji roboczej GPU, a później małego komputera pomocniczego - to bardzo naturalna konfiguracja, którą można rozciągnąć na miesiące lub lata. Studia AI rozwijają się tak samo, jak tradycyjne warsztaty. - Które systemy operacyjne są najlepsze dla studia AI?
- macOS → optymalny dla modeli LLM i Apple-Silicon
- Linux (Ubuntu, Debian) → najlepszy wybór dla image AI, ComfyUI, Stable Diffusion
- Windows → działa dobrze dla SD/ComfyUI, ale mniej idealnie dla procesów automatyzacji
Wiele studiów korzysta dziś z połączonych konfiguracji - każdy system robi to, do czego najlepiej się nadaje. - Ile energii zużywa studio AI?
Mac Studio jest niesamowicie wydajny i zazwyczaj pobiera między 50-100 W. Stacja robocza GPU z RTX 3090 może pobierać 250-350 W, w zależności od obciążenia. Mac mini pobiera około 10-30 W. Podsumowując, znacznie mniej niż można by się spodziewać - i często taniej niż subskrypcje w chmurze. - Czy trudno jest samemu założyć studio AI?
Nie do końca. Potrzebna jest pewna wiedza techniczna, ale nie wykształcenie informatyczne. Wiele dzisiejszych narzędzi posiada interfejsy webowe, skrypty instalacyjne i automatyczne konfiguracje. A jeśli wyraźnie oddzielisz systemy (LLM / GPU / zadania poboczne), wszystko pozostanie jasne. - Czy naprawdę mogę nim objąć cały proces publikacji?
Tak - i właśnie do tego idealnie nadaje się studio AI. Od pomysłów na książkę po teksty, projekty okładek, serie obrazów, korekty, tłumaczenia i ostateczny plik do druku lub e-booka - wiele rzeczy można zautomatyzować i wyprodukować we własnym zakresie. To ogromna swoboda dla self-publisherów. - Jak przyszłościowe jest dzisiejsze studio AI?
Bardzo. LLM stają się coraz bardziej wydajne, modele obrazu bardziej modułowe, sprzęt bardziej wytrzymały - a lokalna sztuczna inteligencja ponownie zyskuje na znaczeniu na rynku, ponieważ przepisy dotyczące chmury, ochrony danych i kosztów sprawiają, że chmura staje się mniej atrakcyjna. Każdy, kto dziś inwestuje w małe studio AI, buduje infrastrukturę, która w latach 2026-2030 stanie się ważniejsza, a nie przestarzała. - Czy modele AI mogą być później trenowane lub rozszerzane?
Tak, system GPU (np. RTX 3090 lub 4090) może być wykorzystywany do trenowania LoRA, trenowania stylu, trenowania materiałów i trenowania procesów. Oznacza to, że z czasem można trenować własny „język wizualny AI“ lub „kierunek tekstu AI“. Jest to największa strategiczna zaleta studia AI: uniezależniasz się od ogólnych modeli i tworzysz własny styl.


