
Wie vandaag met AI werkt, wordt bijna automatisch in de cloud geduwd: OpenAI, Microsoft, Google, alle web UI's, tokens, limieten, voorwaarden. Dit lijkt modern - maar is in wezen een terugkeer naar afhankelijkheid: anderen bepalen welke modellen je mag gebruiken, hoe vaak, met welke filters en tegen welke kosten. Ik ga bewust de andere kant op: ik bouw momenteel thuis mijn eigen kleine AI-studio. Met mijn eigen hardware, mijn eigen modellen en mijn eigen workflows.
Mijn doel is duidelijk: lokale tekst-AI, lokale beeld-AI, mijn eigen modellen leren (LoRA, fine-tuning) en dat alles op zo'n manier dat ik als freelancer en later ook MKB-klant niet afhankelijk ben van de dagelijkse grillen van een of andere cloudprovider. Je zou kunnen zeggen dat het een terugkeer is naar een oude houding die vroeger heel normaal was: „Belangrijke dingen doe je zelf“. Alleen gaat het deze keer niet om je eigen werkbank, maar om rekenkracht en gegevenssoevereiniteit.




Snelheid blijft lokaal onverslaanbaar
Cloudmodellen zijn indrukwekkend - zolang de lijn in de lucht is, de servers niet overbelast zijn en de API niet weer wordt afgeknepen. Maar iedereen die serieus met AI werkt, beseft al snel dat de meest eerlijke vorm van snelheid lokaal is. Als een model draait op je eigen Mac Studio of je eigen GPU, dan klopt het:
- Geen netwerklatentie
- Geen wachttijd tot „de anderen“ klaar zijn
- Geen annuleringen per uur
- Geen „Rate limit reached“ midden in de workflow
Ik ervaar dit elke dag: op mijn Mac Studio draait een 120B model (GPT-OSS) en een 27B Gemma model parallel - plus FileMaker server en al mijn databases. Desondanks blijft het systeem zo responsief dat ik kan werken met een snelheid die bijna onmogelijk is met cloudsystemen. Vooral als je veel kleine bewerkingen achter elkaar doet - vertalingen, herformuleringen, analyses, beeldaanvragen - lopen de vertragingen snel op. Lokale AI voelt niet als „serverbediening“, maar als een direct hulpmiddel: je drukt, het gebeurt.
Gegevenssoevereiniteit: wanneer gevoelige informatie niet online thuishoort
Een punt dat vaak wordt weggewuifd, maar cruciaal is voor ondernemers: data. Zodra je cloud-AI gebruikt, stel je jezelf onvermijdelijk vragen:
- Kan ik daar klantgegevens invoeren?
- Wat gebeurt er met interne documenten?
- Hoe lang worden logboeken bewaard?
- Wie heeft er in theorie toegang - vandaag en over twee jaar?
- Welke juridische gevolgen zou een lek hebben?
Natuurlijk hebben de grote providers beloften over gegevensbescherming. Maar uiteindelijk geef je je inhoud uit handen. En dat is precies wat je in het verleden in je eigen bedrijf wilde vermijden: Interne dingen bleven intern. In een lokale AI-studio is de situatie anders:
- De gegevens blijven in je eigen netwerk.
- Geen enkel verzoek verlaat het huis.
- Modellen werken zonder internettoegang.
- Logs, trainingsgegevens en tussentijdse resultaten worden opgeslagen op je eigen schijven.
Als ik in de toekomst mijn boeken, artikelen, notities, PR-teksten, interne strategiedocumenten of klantgegevens door mijn AI laat lopen, wil ik er zeker van zijn dat niets daarvan in de trainingsset van iemand anders terechtkomt. Ik kan dit vertrouwen alleen hebben als de infrastructuur van mij is.
Kostenbeheersing in plaats van sluipende abonnementen
Cloud AI's lijken op het eerste gezicht goedkoop: een paar cent per 1.000 tokens, een maandabonnement hier, een klein tarief daar. Het probleem is dat de kosten toenemen met je succes. Hoe productiever je wordt, hoe duurder de infrastructuur wordt - elke maand. Lokale AI werkt anders:
- Je investeert één keer in hardware.
- Voer de modellen vervolgens zo vaak en zo veel uit als je wilt.
- Geen „bestellende vingers trillen“ omdat elk gesprek geld kost.
- Je kunt vrijer experimenteren zonder elke invoer te hoeven berekenen.
Ik heb mijn RTX 3090 tweedehands gekocht voor ongeveer 750 euro - zo goed als nieuw. Mijn Mac Studio met 128 GB RAM heb ik voor ongeveer 2.750 euro gekocht, in de originele verpakking en nooit geopend. Dat is geld, ja - maar:
- Deze machines zullen me nog vele jaren bijblijven.
- Je maakt direct bruikbare middelen: boeken, artikelen, afbeeldingen, LoRA's, workflows.
- Behalve de elektriciteit brengen ze geen extra maandelijkse kosten met zich mee.
Voor een uitgever, een consultant, een ontwikkelaar of een klein bedrijf kan dit het verschil zijn tussen „We moeten berekenen of we het ons kunnen veroorloven“ en „We gebruiken AI alleen als we het nodig hebben“.
Oude deugden, nieuwe voordelen: Waarom het bezitten van je eigen machines weer de moeite waard is
Vroeger was het vanzelfsprekend dat een vakman goed gereedschap in zijn eigen werkplaats had. Een timmerwerkplaats zonder goede werkbank en zagen was ondenkbaar. Tegenwoordig zijn we gewend geraakt aan het tegenovergestelde: in plaats van onze eigen machines te bezitten, huren we diensten in. Een eigen AI-studio is eigenlijk niets meer dan een moderne versie van de klassieke werkplaats:
- De Mac Studio is de centrale engine voor taalmodellen.
- De RTX grafische kaart is de freesmachine voor afbeeldingen en training.
- A Extra computer (bijv. Mac mini) neemt speciale taken op zich zoals spraak of kleine modellen.
- Software zoals FileMaker dient als bedieningspaneel: het orkestreert, bewaart en documenteert.
Ik bouw een setup als deze omdat ik op de lange termijn alles zelf wil kunnen doen:
- Boeken schrijven en vertalen,
- Afbeeldingsreeksen genereren,
- train je eigen LoRA-modellen,
- Automatiseer workflows,
- en bieden later ook oplossingen voor klanten die volledig lokaal kunnen draaien.
Dit is geen nostalgie, dit is een nuchtere beslissing: hoe dieper AI ingrijpt in het dagelijks leven, hoe verstandiger het is om controle te houden over de technologie. Lokale AI is geen „hobbyistisch alternatief“ voor de fancy cloud, maar een bewuste terugkeer naar onafhankelijkheid:
- Je wint snelheid.
- U behoudt uw gegevens.
- Je hebt controle over je kosten.
- Je bouwt een infrastructuur die van jou is.
Als je dit tot het einde doordenkt, lijkt een AI-studio thuis steeds meer op een klassieke, goed uitgeruste werkplaats: Je vertrouwt niet op wat anderen ergens op de achtergrond doen, maar bouwt je eigen stabiele basis.
Huidig onderzoek naar lokale AI-systemen
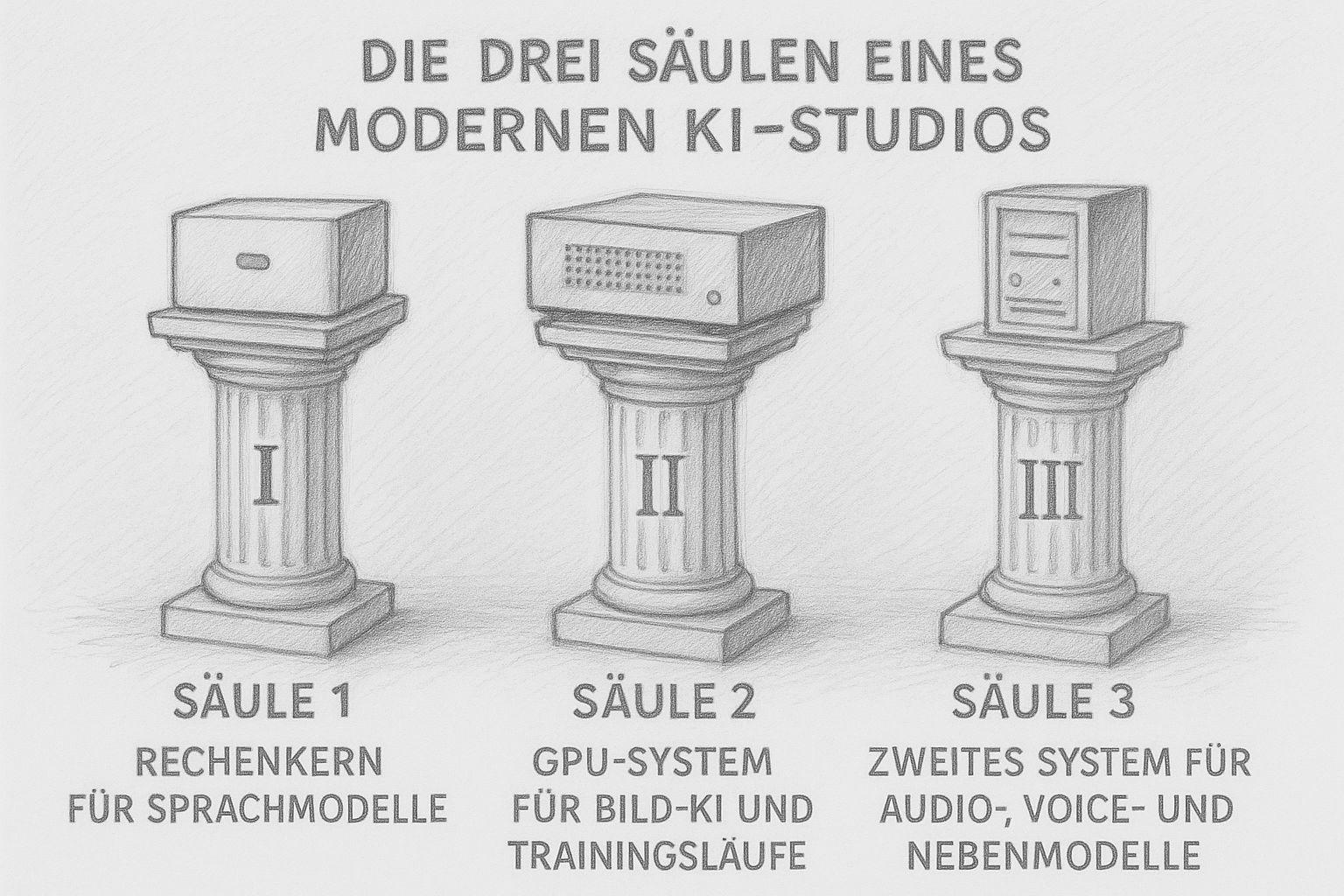
De drie pijlers van een moderne AI-studio
Tegenwoordig bestaat een AI-studio niet meer uit „één grote computer“ die alles doet. Moderne workflows hebben verschillende sterktes nodig: rekenkracht voor teksten, veel VRAM voor afbeeldingen en trainingsruns, en kleinere systemen die de neventaken op zich nemen. Het resultaat is geen chaotische reeks apparaten, maar een goed doordachte kleine infrastructuur - zoals een goed uitgeruste werkplaats vroeger, waar elke machine zijn doel vervult.
Zelf bouw ik mijn studio volgens precies dit principe. En hoe dieper ik in deze materie duik, hoe duidelijker het wordt: Drie pijlers zijn genoeg om lokaal een complete AI-productie te draaien.
Pijler 1: De rekenkernel voor taalmodellen (LLM's)
Voor grote taalmodellen is tegenwoordig niet langer een server in een datacentrum nodig, maar vooral één ding: veel en heel snel RAM-geheugen. Dit is precies wat moderne Apple-Silicon systemen of vergelijkbaar uitgeruste Linux machines met veel RAM kunnen doen. De rekenkern is het middelpunt van de studio. Hier draait het:
- Grote LLM's (20B, 30B, 70B, 120B VvE ...)
- Analysemodellen
- Vertaalmodellen
- Intern Kennissystemen (neo4j, RAG)
- ook een lange-termijn AI-ondersteund geheugen
- Besturingssystemen zoals n8n
- FileMaker-Automatisering en serverprocessen
In mijn opstelling neemt de Mac Studio M1 Ultra met 128 GB RAM deze rol op zich. En hij doet het verbazingwekkend goed. Ik draai erop:
- GPT-OSS 120B VvE (voor diepgaand denken, lange teksten en analyses)
- Gemma-3 27B (voor technisch werk zoals FileMaker-dingen, code, precieze structurering)
- FileMaker server + databases
- plus de volledige shell- en webserverinfrastructuur
Het ongelooflijke is dat zelfs met twee grote modellen tegelijk, 10-15 GB RAM vrij blijft. Dit is het voordeel van een architectuur die volledig is ontworpen voor unified memory. Om het in een notendop te zeggen: de rekenkern is het brein van de AI-studio. Alles wat tekst begrijpt, genereert of transformeert gebeurt hier.
Pijler 2: Het GPU-systeem voor beeld-AI en trainingsruns
De tweede pijler is een GPU-werkstation, geoptimaliseerd voor Stable Diffusion, ComfyUI, ControlNet en LoRA-training. Terwijl tekstmodellen voornamelijk RAM nodig hebben, heeft beeld-AI VRAM nodig. En veel ook. Waarom? Omdat beeldmodellen gigantische hoeveelheden gegevens per frame door het geheugen jagen. En daar zijn grafische kaarten voor gemaakt. In mijn studio wordt dit gedaan door een NVIDIA RTX 3090 met 24 GB VRAM - en deze 24 GB zijn hun gewicht in goud waard. Ze maken het mogelijk:
- SDXL met redelijke batchgrootte
- ComfyUI-workflows
- Videosynthese
- Serie afbeeldingen
- Materiaal- en stijltraining
- LoRA-training met 896×896 of zelfs 1024×1024
Voor beeld-AI is VRAM belangrijker dan de allernieuwste chip. Een solide 3090 kan vandaag de dag meer dan dure mid-range kaarten uit 2025. De GPU-kolom is daarom de „zware uitrusting“ in de studio - de freesmachine die alles wegzaagt wat rekenbelasting betekent. Zonder dat is serieuze beeldproductie nauwelijks mogelijk.
Pijler 3: Een tweede systeem voor audio, spraak en secundaire modellen
De derde pijler lijkt misschien onopvallend, maar is cruciaal: een kleiner, energie-efficiënt systeem dat secundaire taken op zich neemt. Deze omvatten:
- TTS (Tekst-naar-spraak)
- STT (transcriptie)
- kleinere modellen (4B, 7B, 8B, 14B)
- statisch Achtergrond processen
- kleine Agent systemen
- Gereedschap, die u afzonderlijk van het hoofdsysteem wilt bedienen
Ik gebruik een kleine Mac mini M4 met 32 GB RAM. Perfect geschikt voor:
- Fluister-Transcriptie
- Stem-modellen
- licht Optimalisatiemodellen
- snel reagerend Assistenten
- Experimenten en Testritten
- parallel Model container
Dit ontlast het hoofdsysteem enorm. Het is immers zinvol om niet voor elke kleine klus grote modellen te laden. Net zoals je vroeger niet voor elke zaagsnede in de werkplaats de grote cirkelzaag aanzette, maar een kleine machine gebruikte. De derde pijler zorgt voor organisatie en stabiliteit.
Het scheidt de grote modellen van de kleine taken - en dat maakt de hele studio duurzaam, flexibel en faalveilig.
Intelligente verdeling van werklasten
Een AI-studio gedijt bij het feit dat elke machine doet waarvoor hij gebouwd is. Dit resulteert in een logische volgorde:
- Berekening kern → Denken, schrijven, vertalen, analyseren
- GPU-systeem → Afbeeldingen, trainingsmodellen, ComfyUI, video
- Subsysteem → Audio, stem, kleine modellen, agenten
Wanneer er extra software wordt toegevoegd - zoals FileMaker als mijn centrale besturingssysteem - ontstaat er een echte productiepijplijn. Geen chaos meer, geen „laten we eens kijken waar er nog ruimte is“, maar een georganiseerd systeem dat elke dag stabiel draait.
De drie pijlers zijn het fundament - niet de freestyle
Veel mensen denken dat je pas een AI-studio nodig hebt als je een „AI-bedrijf“ bent. In werkelijkheid is het tegenovergestelde waar: een solide AI-studio IS de basis om er een te worden. Met deze drie pijlers heb je alles wat je nodig hebt om:
- Inhoud produceren (tekst & beeld)
- Leer je eigen modellen
- Workflows automatiseren
- Onafhankelijk van de cloud werken
- eigen oplossingen voor klanten ontwikkelen
- digitale „werkbanken“ op lange termijn gebruiken
Voor ondernemers, creatieven, self-publishers en ontwikkelaars is dit nu een strategische beslissing die zorgt voor vrijheid, snelheid en controle op de lange termijn.
Verstandig instapmodel hardware voor een kleine AI-studio
Als je tegenwoordig naar de reclames kijkt, denk je misschien dat je de allernieuwste hardware moet blijven kopen om lokaal met AI te kunnen werken. Maar vaak is het tegenovergestelde het geval: niet de nieuwste modellen zijn doorslaggevend, maar de juiste combinatie van RAM, VRAM en stabiliteit. Veel oudere apparaten - vooral in de GPU-sector - zijn nu echte prijs-prestatie monsters. En als je bereid bent om buiten de gebaande paden te denken, kun je een AI-studio bouwen die recht doet aan een klein bedrijf zonder jezelf financieel te overbelasten. Dat is precies wat ik nu zelf doe en het werkt verrassend goed. Dit hoofdstuk laat je drie hardwareklassen zien: Beginner, Standaard en Professional. En natuurlijk leg ik ook uit waarom bepaalde oudere systemen tegenwoordig waardevoller zijn dan je zou denken.
1e instapklasse (1500-2500 €)
Voor iedereen die lokaal wil beginnen - zonder grote investeringen. Deze les gaat over het zetten van je eerste solide stappen:
- Mac mini M2 of M4 met 16-32 GB RAM
- of een PC met RTX 3060/3070 (12-16 GB VRAM)
- plus optioneel een kleine NAS of extern SSD
Dit is een goede manier om:
- Bediening van 7B tot 14B modellen
- Lokale vertalingen uitvoeren
- Rennen Fluister
- Gebruik kleinere beeldmodellen zoals SD 1,5/2,1
- Probeer ComfyUI in verkleinde vorm
- Test je eigen agents of workflows
Voor veel creatieve of zelfstandige mensen is dit meer dan genoeg om productief te worden. Het belangrijkste is om de start niet te ingewikkeld te maken. Het grootste gevaar is niet dat je te weinig kracht hebt, maar dat je verzandt in te veel technische details. Je kunt bijvoorbeeld ongelooflijk veel doen met een Mac mini M4: Vertalingen, onderzoek, structuur, zelfs kleinere schrijfmodellen - en met minimaal stroomverbruik.
2e standaardklasse (2500-4000 €)
De sweet spot voor serieus werk met teksten en afbeeldingen. Hier begint wat ik een “echte AI-studio“ zou noemen: een opstelling die zowel grote tekstmodellen als solide beeldmodellen aankan. Een typische combinatie:
- Mac Studio M1 Ultra of M2 Max met 64 GB RAM
- PC/GPU-werkstation met RTX 3080, 3090 of 3090 Ti
- optioneel een kleine Extra computer voor audio of spraak
Met deze les kun je:
- Betrouwbare aandrijving voor 20-40B-modellen
- Gebruik Stable Diffusion XL in goede kwaliteit
- LoRA-training uitvoeren in het medium datasetbereik
- Parallelle werklasten verdelen over meerdere apparaten
- Automatiseringen instellen (bijv. via FileMaker)
En dit onthult een interessante waarheid: oudere GPU's zoals de RTX 3090 verpletteren nog steeds veel nieuwe mid-range kaarten. Waarom? Ze hebben meer VRAM (24 GB), terwijl nieuwe kaarten vaak zijn gecastreerd. Ze hebben een brede geheugeninterface, ideaal voor brede verspreidingsmodellen. Ze hebben volwassen en stabiele CUDA-stuurprogramma's. Ze worden vaak tweedehands verkocht voor geweldige prijzen. Een 3090 kan meer doen voor €700-900 gebruikt dan een huidige 4070 of 4070 Ti voor €1100 - simpelweg omdat VRAM en geheugenconnectiviteit belangrijker zijn dan een paar procent ruwe prestaties.
3e professionele klasse (4000-8000 €)
Voor iedereen die serieus wil produceren en streeft naar volledige onafhankelijkheid. Echte productiekracht is beschikbaar in deze klasse. Typische opstelling:
- Mac Studio M1 / M2 / M3 Ultra met 128 GB RAM of meer
- PC-GPU-systeem met RTX 3090 of 4090
- een tweede computer voor audio/agenten
- Optionele FileMaker server als automatiseringscentrum
Hiermee kun je:
- Vloeiend 70B-modellen gebruiken
- Stabiele werking van MoE-modellen zoals GPT-OSS 120B
- Parallelle AI-agenten coördineren
- SDXL, video-AI, ComfyUI werken op volle capaciteit
- LoRA-trainingen uitvoeren met 896×896 of 1024×1024
- Bereid je eigen databases voor op training
- Volledige pijplijnen in kaart brengen (aanwijzingen → afbeeldingen → PDF's → boeken)
En dit is waar je het meest opwindende kunt zien: de beste AI-hardware in 2025 is vaak premium hardware uit 2020-2022. Waarom? Die is toen ontwikkeld voor high-end workloads. Het is een fractie van de prijs vandaag. De technologie is volwassen. Geen problemen met bètastuurprogramma's. Het heeft precies de eigenschappen die AI nodig heeft: veel VRAM, brede geheugenbussen, stabiele tensor cores.
Waarom je faalt met te weinig VRAM - en niet met te weinig GPU-kracht
Dit is een punt dat velen onderschatten: VRAM is de beslissende factor voor beeld-AI, niet pure prestaties. Voorbeelden:
- Een RTX 4060 (8 GB VRAM) is praktisch onbruikbaar voor SDXL.
- Een RTX 4070 Ti (12 GB VRAM) is slechts onbetrouwbaar voldoende voor training.
- Een RTX 3090 (24 GB VRAM) daarentegen draait jarenlang probleemloos.
Kortom: grote modellen hebben geheugen nodig - geen marketing. En geheugen is wat oudere high-end kaarten hebben en nieuwe mid-range kaarten niet.
Een AI-studio modulair uitbreiden
Het grootste voordeel van een studio met drie pijlers is de modulariteit:
- Het GPU-werkstation kan onafhankelijk worden geüpgraded.
- Je kunt de Mac Studio jaren bewaren.
- Je kunt de slavecomputer verwisselen zonder het systeem te verstoren.
- Je kunt de harde schijven of SSD's afzonderlijk uitbreiden.
- Je kunt FileMaker, Python of Bash gebruiken als orkestratie.
Het is als een werkplaats: Je verbouwt niet alles tegelijk, maar alleen wat op dat moment nodig is.
Lokale AI is nu ECHT bruikbaar (en het draait op deze hardware) | k't 3003
Aanbevelingen voor 2025 - Deze hardware is echt de moeite waard
Het is makkelijk om het spoor bijster te raken in de jungle van advertenties en specificaties. Maar voor AI-gebruik thuis of in kleine studio's zijn er hardwareklassen die in 2025 bijzonder nuttig zullen zijn - omdat ze een goede prijs-prestatieverhouding bieden, robuust zijn en voldoen voor de huidige modellen. Wat vandaag belangrijk is:
- Voldoende VRAM (voor GPU-taken)Voor beeld-AI, trainingsruns, stabiele diffusie enz. moet een grafische kaart ten minste 16 GB, bij voorkeur 24 GB VRAM hebben. Boven deze drempel wordt beeld-AI comfortabel en stabiel.
- Goed werkgeheugen en RAM-capaciteit (voor LLM's): Voor grote LLM's, multitasking met serverservices en parallelle processen is het zinvol om zoveel mogelijk RAM te hebben - idealiter 64-128 GB voor Apple-Silicon.
- Stabiele, bewezen hardware in plaats van de nieuwste marketingproductenVooral oudere high-end kaarten hebben vaak uitstekende specificaties (VRAM, geheugenbus, rijpheid van stuurprogramma's) voor een bescheiden prijs.
- Modulariteit en mixen in plaats van monoblockCombinatie van LLM computer, GPU werkstation en secundair/agent systeem is flexibeler en duurzamer dan een enkele „alles-in-één“ machine.
| Klasse | Typische onderdelen | Geschikt voor wie | Sterke punten / Compromissen |
|---|---|---|---|
| Instapniveau (ongeveer € 1.500-2.500) | Mac mini (16-32 GB RAM) of pc met GPU (bijv. RTX 3060 / 3060 Ti / 4060 Ti met ≥ 12-16 GB VRAM) | Hobby, eerste experimenten, kleine modellen, hanteerbaar beeld AI | Gunstig instapniveau, voldoende voor kleinere LLM's, lichte stabiele diffusieworkflows en audio/tekst-AI. Beperkingen bij grote modellen, complexe ComfyUI-pijplijnen en LoRA-training. |
| Standaard (ca. € 2.500-4.000) | GPU-workstation uit het middensegment (bijv. met RTX 3080 of RTX 3090), computer met 64 GB RAM | Creatieven, zelfuitgevers, ambitieuze AI-gebruikers, kleine teams | Solide prestaties voor tekst en afbeeldingen, goede prijs-prestatieverhouding. Genoeg VRAM en RAM voor veelzijdig AI-gebruik, inclusief SDXL en initiële LoRA-training. Bij extreme projecten of veel parallelle workflows bereikt het systeem op een gegeven moment zijn grenzen. |
| Professioneel / Studio (ca. 4.000-8.000 €) | Systeem met veel RAM (bijv. Mac Studio met 128 GB RAM of krachtig Linux-werkstation) + GPU met ≥ 24 GB VRAM (bijv. RTX 3090, 4090) + apart secundair/agent-systeem | Freelancers, uitgevers, mediaproducties, ontwikkelaars met meerdere projecten, kleine AI-studio's | Maximale flexibiliteit, grote modellen (70B, MoE), beeld- en tekst-AI in parallel, automatisering en langlopende workflows. Zeer toekomstbestendig, maar hogere initiële investering en iets meer planningsinspanning bij het opzetten. |
Waarom gebruikte en oudere high-end GPU's tegenwoordig vaak beter zijn dan nieuwe mid-range kaarten
Veel nieuwere kaarten worden aangeboden met beperkt VRAM - maar dit is cruciaal voor AI. Oudere high-end modellen zoals de RTX 3090 bieden vaak 24 GB VRAM, wat tegenwoordig erg waardevol is voor SDXL, LoRA-training of video-AI. De hardware is oorspronkelijk ontworpen voor prestaties en stabiliteit - met hoogwaardige componenten, geheugenbus, koeling en goede driverondersteuning.
Dit betekent: duurzaamheid en robuuste prestaties zijn vaak beschikbaar. Gebruikte kaarten zijn vaak aanzienlijk goedkoper en daarom zeer betaalbaar - ideaal voor freelancers of kleine studio's met een beperkt budget.
Mijn huidige aanbeveling voor 2025 (en waarom)
Als ik vandaag een studio zou bouwen en niet zou streven naar maximale supercomputerkracht, dan zou ik een beslissing nemen:
- Voor beeld-AITen minste één GPU met 24 GB VRAM - bijvoorbeeld RTX 3090 of 4090.
- Voor tekst/LLM128 GB RAM in een krachtig Apple-Silicon systeem.
- Voor deeltijdbanen (audio, spraak, kleine modellen, automatisering): een kleine, aparte computer (bijv. mini-pc of goedkope server).
- Voor coördinatie: een softwarelaag - voor mij is dit FileMaker, voor anderen kan dit een eenvoudige shell of Python-pijplijn zijn.
Deze opzet is niet overdreven, niet afhankelijk van dure cloudlicenties - en is voldoende voor bijna alles wat er in 2025 met AI gedaan kan worden in de creatieve, uitgeef- of ontwikkelingssector.
De hardware voor AI hoeft niet nieuw te zijn, maar geschikt
De tijd dat „AI“ alleen iets was voor grote bedrijven of cloudlabs loopt ten einde. In 2025 kan bijna iedereen - met een beheersbaar budget en een beetje technisch inzicht - zijn eigen kleine AI-studio opzetten. Dit maakt je onafhankelijk van dure maandelijkse abonnementen, gegevensbeschermingsvoorwaarden van derden, wachtrijen, serverbottlenecks en de onzekerheid over hoe lang clouddiensten nog zullen bestaan. In plaats daarvan krijg je:
- Volledige controle over je gegevens en je workflows,
- stabiel, snel en Schaalbare prestaties,
- een Duurzame investering, die jaren meegaat,
- en de Vrijheid, om creatief te zijn wanneer en hoe je wilt - zonder externe beperkingen.
Dus als je overweegt om AI te gebruiken voor je boeken, teksten, afbeeldingen of projecten, is het meer dan ooit de moeite waard om je eigen studio op te zetten. Je hoeft geen hardwaretechnicus te zijn. Je hebt geen enorm budget nodig. Je hebt niet de nieuwste hardware nodig.
Bovenal heb je een duidelijk idee nodig van het doel waar je naartoe werkt - en de wil om controle te houden over je eigen processen.
Ik laat je zien hoe je een lokale LLM instelt met Ollama op een Mac installier in dit artikel.
Hier vind je een vergelijking van Apple MLX op Silicon vs. NVIDIA.
Hoe werken met Qdrant een lokaal geheugen voor jouw lokale AI kun je hier vinden.

Veelgestelde vragen
- Waarom is het eigenlijk de moeite waard om je eigen AI-studio te hebben als er zoveel cloudaanbieders zijn?
Een eigen AI-studio maakt je onafhankelijker, stabieler en goedkoper op de lange termijn. Clouddiensten zijn handig, maar ze kosten elke maand geld, creëren afhankelijkheid en zijn vaak beperkt door gebruiksbeperkingen. Lokale AI is snel, permanent beschikbaar en kan worden gebruikt zonder variabele kosten. Bovendien blijven alle gegevens binnenshuis - een enorm voordeel voor zelfstandigen, bedrijven, uitgevers of creatieve beroepen. - Welke hardware heb ik minimaal nodig om lokaal met AI te beginnen?
Om te beginnen is een Mac mini met 16-32 GB RAM of een pc met een GPU met minstens 12 GB VRAM voldoende. Hiermee kun je kleine taalmodellen, lichte afbeeldingsmodellen en eerste automatiseringen uitvoeren. Als je het gewoon wilt uitproberen, hoef je geen duizenden euro's te investeren. - Heb ik echt een Mac Studio nodig of is het goedkoper?
Het is zeker goedkoper. Een Mac Studio is de moeite waard als je grote taalmodellen (20-120B) wilt draaien, veel parallel wilt werken of langdurige productieprocessen hebt. Voor je eerste stappen volstaat een Mac mini of een degelijke Windows-pc prima. Een studio is een investering in gemak en toekomst - maar geen must. - Waarom is VRAM belangrijker voor beeld-AI dan een moderne videokaartgeneratie?
Omdat beeldmodellen zoals Stable Diffusion enorme hoeveelheden gegevens door het geheugen jagen. Als het VRAM niet voldoende is, stopt het proces of wordt het extreem traag. Een oudere kaart zoals de RTX 3090 met 24 GB VRAM is vaak beter dan nieuwe mid-range modellen met slechts 8-12 GB VRAM - simpelweg omdat deze meer ruimte biedt voor grote modellen en trainingsruns. - Kan ik een AI-studio volledig uitvoeren met Apple hardware zonder NVIDIA?
Voor taalmodellen, ja. Voor beeld-AI, nee. Apple-Silicon is extreem efficiënt voor LLM's, maar voor stabiele diffusie, LoRA-training en veel beeldmodellen zijn NVIDIA-kaarten (vanwege CUDA/Tensor cores) nog steeds de referentie. Veel studio's gebruiken daarom een combinatie van Apple/LLM en Linux+NVIDIA voor afbeeldingen. - Is een RTX 4080 of 4070 Ti ook voldoende voor beeld-AI?
Theoretisch ja - in de praktijk hangt het af van het beoogde gebruik. Voor eenvoudige afbeeldingen of kleine workflows is dat voldoende. Maar voor SDXL, complexe ComfyUI-pijplijnen of LoRA-training bereikt de limiet van 12-16 GB VRAM al snel zijn grenzen. Een RTX 3090 of 4090 is daarom op de lange termijn zinvoller. - Waarom worden taalmodellen niet uitgevoerd op de GPU, maar op het RAM?
Taalmodellen zijn geheugengeoriënteerd. Ze moeten grote hoeveelheden tekst en context opslaan in RAM, niet noodzakelijkerwijs grafische bewerkingen uitvoeren. GPU's zijn gebouwd voor beeldverwerking, niet voor tekstanalyse. Daarom hebben LLM systemen enorm veel baat bij veel RAM, maar minder bij VRAM. - Hoeveel RAM moet een LLM-computer hebben?
Voor kleinere modellen is 32-64 GB voldoende. Voor middelgrote modellen (20-30B) is 64-128 GB ideaal. Voor grote modellen zoals 70B of MoE-modellen zoals GPT-OSS 120B is 128-192 GB RAM ideaal. Hoe meer RAM, hoe stabieler en sneller alles draait. - Is het mogelijk om een AI-studio volledig zonder Linux te laten draaien?
Ja, maar met beperkingen. macOS is perfect voor LLM's, maar voor beeld-AI mist het enkele tools die alleen bestaan op Linux/NVIDIA. Windows werkt goed voor beeld-AI, maar is minder stabiel en moeilijker te automatiseren. De pragmatische mix is daarom vaak: macOS → LLM, Linux → beeld-AI, kleine computer → audio/scripts - Hoe luid is zo'n AI-studio in bedrijf?
Minder dan je zou denken. Een Mac Studio is praktisch geruisloos. Een Linux PC hangt af van de koeling - GPU's van hoge kwaliteit zijn stil bij lage belasting, maar kunnen hoorbaar worden tijdens trainingen. Als je de voorkeur geeft aan stille builds, kun je watergekoelde GPU-werkstations gebruiken. - Welke rol speelt de Mac mini als derde component?
Het dient als secundair station voor transcriptie, TTS, kleine AI-modellen, achtergrondprocessen, automatisering en secundaire taken voor vertalingen. Dit houdt de twee grote machines vrij en zorgt voor stabiele workflows. Een derde computer is niet absoluut noodzakelijk, maar schept wel orde en betrouwbaarheid. - Kan ik mijn AI-studio geleidelijk uitbreiden?
Absoluut. In feite is dat het ideale geval. Een LLM-systeem kopen, dan een GPU-werkstation toevoegen en later een kleine secundaire computer - dit is een heel natuurlijke opstelling die maanden of jaren kan duren. AI-studio's groeien net als traditionele werkplaatsen. - Welke besturingssystemen zijn het meest geschikt voor een AI-studio?
- macOS → optimaal voor LLM- en Apple-Silicon-modellen
- Linux (Ubuntu, Debian) → beste keuze voor image AI, ComfyUI, Stable Diffusion
- Windows → werkt goed voor SD/ComfyUI, maar minder ideaal voor automatiseringsprocessen
Veel studio's gebruiken tegenwoordig gecombineerde opstellingen - elk systeem doet waarvoor het het meest geschikt is. - Hoeveel stroom verbruikt een AI-studio?
Een Mac Studio is verbazingwekkend efficiënt en verbruikt meestal tussen de 50-100 W. Een GPU-werkstation met RTX 3090 kan 250-350 W verbruiken, afhankelijk van de belasting. Een Mac mini is ongeveer 10-30 W. Al met al veel minder dan je zou verwachten - en vaak goedkoper dan cloudabonnementen. - Is het moeilijk om zelf een AI-studio op te zetten?
Niet echt. Je hebt enig technisch inzicht nodig, maar geen graad in computerwetenschappen. Veel tools hebben tegenwoordig webinterfaces, installatiescripts en automatische configuraties. En als je de systemen duidelijk van elkaar scheidt (LLM / GPU / bijbanen), blijft alles duidelijk. - Kan ik er echt volledige publicatieprocessen mee afdekken?
Ja - en dat is precies waar een AI-studio ideaal voor is. Van boekideeën tot teksten, omslagontwerpen, beeldreeksen, correcties, vertalingen en het uiteindelijke druk- of e-bookbestand, veel dingen kunnen worden geautomatiseerd en in-house worden geproduceerd. Dit is een enorme vrijheid voor self-publishers. - Hoe toekomstbestendig is een AI-studio vandaag de dag?
Zeer. LLM's worden efficiënter, beeldmodellen modulairder, hardware duurzamer - en lokale AI wordt weer belangrijker in de markt omdat cloudwetten, gegevensbescherming en kosten de cloud minder aantrekkelijk maken. Wie vandaag investeert in een kleine AI-studio, bouwt aan een infrastructuur die in 2026-2030 eerder belangrijker dan overbodig zal zijn. - Kunnen de AI-modellen later worden getraind of uitgebreid?
Ja, een GPU-systeem (bijv. RTX 3090 of 4090) kan worden gebruikt voor LoRA-training, stijltraining, materiaaltraining en procestraining. Dit betekent dat je na verloop van tijd je eigen „AI visuele taal“ of „AI tekstrichting“ kunt trainen. Dit is het grootste strategische voordeel van een AI-studio: je wordt onafhankelijk van generieke modellen en creëert je eigen stijl.