
En la primera parte de esta serie de artículos, vimos que la exportación de datos de ChatGPT es mucho más que una función técnica. Tus datos exportados contienen una colección de pensamientos, ideas, análisis y conversaciones que se han acumulado durante un largo periodo de tiempo. Pero mientras estos datos sólo se almacenen como un archivo en tu disco duro, siguen siendo sólo eso: un archivo. El paso crucial es hacer que esta información vuelva a ser utilizable. Aquí es exactamente donde empieza el desarrollo de una IA de conocimiento personal.
En realidad, la idea es sorprendentemente sencilla: una IA no sólo debe trabajar con conocimientos generales, sino también ser capaz de acceder a sus propios datos. Debe ser capaz de buscar en conversaciones anteriores, encontrar contenido adecuado e incorporarlo a nuevas respuestas. Esto convierte a una IA ordinaria en una especie de memoria digital. Esta es la segunda parte de la serie de artículos, que ahora se centra en el aspecto práctico.




Teil 1 der Serie: Der unterschätzte Schatz im ChatGPT-Datenexport
Während wir in diesem zweiten Teil konkret in die Praxis einsteigen, lohnt sich ein Blick auf den ersten Artikel dieser Serie. Dort geht es um die grundlegende Frage, warum der ChatGPT-Datenexport überhaupt so interessant ist – und weshalb viele Nutzer sein Potenzial noch unterschätzen. Der Artikel zeigt, welche Daten tatsächlich im Export enthalten sind, wie daraus ein persönliches Wissensarchiv entstehen kann und warum genau dieser Schritt die Grundlage für eine eigene KI mit Gedächtnis bildet. Wenn Du verstehen möchtest, warum wir diese Pipeline überhaupt aufbauen und welchen strategischen Wert Deine eigenen Chatverläufe haben, solltest Du mit Teil 1 beginnen.
Antes de empezar con la implementación propiamente dicha en el próximo capítulo, veamos cómo se estructura fundamentalmente un sistema de este tipo.
La idea básica de un sistema GAR
La base técnica de nuestro sistema es un concepto muy extendido en el mundo de la inteligencia artificial: RAG (Retrieval Augmented Generation). Detrás de este término se esconde un principio muy práctico.
Normalmente, un modelo lingüístico responde a las preguntas exclusivamente con los conocimientos aprendidos durante su entrenamiento. Aunque estos conocimientos son amplios, tienen dos limitaciones decisivas:
- En primer lugar, el modelo no conoce ninguna información individual sobre sus propios proyectos o pensamientos.
- En segundo lugar, no puede acceder a nuevos datos creados después del entrenamiento.
Aquí es exactamente donde entra en juego un sistema RAG. En lugar de generar directamente una respuesta, primero ocurre otra cosa: el sistema busca en una base de datos contenidos que coincidan con la pregunta planteada. A continuación, este contenido se transfiere al modelo lingüístico como contexto. Sólo entonces la IA formula su respuesta. En términos sencillos, el proceso es el siguiente:
- Haces una pregunta →
- el sistema busca en una base de datos de conocimientos →
- se encuentra contenido relevante →
- Este contenido se transfiere a la IA como contexto →
- la IA genera una respuesta.
La ventaja decisiva es obvia: la IA puede utilizar información que no formaba parte de su entrenamiento original.
Y aquí es donde entran en juego los datos de ChatGPT. Si integramos estas conversaciones en una base de datos de conocimientos, la IA podrá acceder a ellas más adelante. Puede encontrar ideas anteriores, utilizar argumentos de diálogos antiguos o tener en cuenta análisis de conversaciones pasadas. Así, el sistema empieza a „recordar“ tus propios pensamientos.
Los componentes de nuestro sistema
Para que esto funcione, necesitamos varios componentes que trabajen juntos. Afortunadamente, hoy en día es mucho más fácil acceder a la infraestructura técnica necesaria que hace unos años. En esencia, nuestro sistema consta de cuatro componentes centrales.
- El primer componente es el Exportación de datos ChatGPT. Aquí es donde están nuestros datos en bruto. Contiene todas las conversaciones que hemos mantenido previamente con la IA.
- El segundo componente es un Modelo de incrustación. Este modelo traduce el texto en vectores matemáticos. Esto permite comparar textos en función de su significado.
- El tercer componente es un Base de datos vectorial. En nuestro caso, utilizamos Qdrant. Esta base de datos almacena las representaciones matemáticas de los textos y permite una búsqueda semántica rápida.
- El cuarto componente es un modelo lingüístico local, que se ejecuta a través de Ollama. Este modelo formulará posteriormente las respuestas reales.
Estos cuatro componentes trabajan en estrecha colaboración.
- La exportación de datos proporciona el contenido.
- El modelo de incrustación los hace legibles por máquina.
- La base de datos de vectores los guarda y busca.
- Finalmente, el modelo lingüístico genera respuestas comprensibles.
Juntos, forman la base de una IA de conocimiento personal.
El flujo de datos de un vistazo
Para que el sistema funcione, los datos tienen que pasar por varios pasos. El primer paso es la exportación de datos ChatGPT, que ya creamos en el primer artículo. Las conversaciones que contiene se extraen primero de los archivos JSON. A continuación, hay que prepararlas. Los historiales de chat grandes se dividen en secciones más pequeñas, conocidas como trozos de texto. Esto hace que la búsqueda posterior sea mucho más eficiente.
En el siguiente paso, generamos incrustaciones a partir de estas secciones de texto. Cada texto se describe matemáticamente. Los textos con un significado similar reciben vectores similares. A continuación, guardamos estos vectores en nuestra base de datos vectorial Qdrant.
Esto significa que la parte más importante de la infraestructura ya está instalada. Si más tarde se formula una pregunta, ocurre lo siguiente:
- La pregunta también se convierte en un vector.
- La base de datos busca textos con un significado similar.
- Estos pasajes de texto se transfieren al modelo lingüístico como contexto.
- El modelo utiliza esta información para formular una respuesta.
Este proceso garantiza que la IA no sólo utilice conocimientos generales, sino que también pueda acceder a sus propios datos.
Lo que será posible al final
Una vez configurado el sistema, el trato con la IA cambia notablemente. Ya no se trabaja sólo con un modelo lingüístico general, sino con una IA que puede acceder a sus propios datos. Esto abre posibilidades completamente nuevas. Por ejemplo, puedes hacer preguntas como:
„¿He hablado alguna vez con la IA sobre este tema?“
„¿Qué ideas tenía antes sobre este proyecto?“.“
„¿Qué argumentos he desarrollado en conversaciones anteriores?“.“
A continuación, la IA busca en tus propias conversaciones y encuentra el contenido adecuado. En lugar de limitarse a dar una respuesta general, puede referirse a pensamientos anteriores, resumir análisis antiguos o reconocer conexiones entre distintas conversaciones.
En otras palabras, la IA empieza a trabajar con tu propio archivo de conocimientos. Esto convierte una simple herramienta de chat en un sistema que puede apoyar tu pensamiento a largo plazo. Y es precisamente este sistema el que construiremos paso a paso en los próximos capítulos. En la siguiente sección, comenzamos con el trabajo práctico y primero echamos un vistazo más de cerca a la exportación de datos de ChatGPT. Porque antes de poder construir una base de datos de conocimiento, necesitamos entender cómo están estructurados realmente nuestros datos.
Encuesta actual sobre el uso de sistemas locales de IA
Preparación: Exportación de datos ChatGPT
En el primer artículo de esta serie, ya hemos creado la exportación de datos ChatGPT y la hemos descargado como archivo ZIP. A primera vista, este archivo puede parecer poco espectacular: un archivo con algunos ficheros técnicos que en principio parece más una copia de seguridad que un conjunto de datos valiosos. Sin embargo, este archivo contiene la base de todo nuestro sistema de conocimientos.
Antes de empezar a cargar estos datos en una base de datos o conectarlos a una IA, primero tenemos que entender cómo está estructurada la exportación. Porque sólo si sabemos qué información contiene y cómo está estructurada podremos procesarla después de forma significativa. En este capítulo veremos cómo está estructurada la exportación de datos, qué archivos son realmente relevantes y cómo podemos convertir este archivo técnico en una base útil para nuestro sistema de conocimiento de IA.
Descomprimir archivo ZIP
El primer paso es trivial, pero no por ello menos importante: tenemos que descomprimir el archivo descargado. Normalmente, el archivo está disponible en formato ZIP clásico. Dependiendo de su uso previo, su tamaño puede variar. Algunos usuarios reciben un archivo de unos cientos de megabytes, otros de varios gigabytes.
Una vez descomprimido el archivo, se crea una carpeta con varios archivos y subcarpetas. La estructura exacta puede variar ligeramente, pero normalmente encontrará varios archivos JSON y posiblemente otros archivos con información adicional.
Para muchos usuarios, esta estructura parece inicialmente algo técnica. Pero si se toman un momento, rápidamente reconocen un patrón: los datos están organizados de forma relativamente ordenada y siguen una estructura clara. Es una buena noticia, porque es precisamente esta estructura la que permite procesar el contenido automáticamente más adelante.
Estructura de los datos del chat
La parte más importante de la exportación son los datos reales de las conversaciones. Estas conversaciones suelen almacenarse en uno o varios archivos JSON. JSON es un formato de datos muy extendido que suele utilizarse para almacenar información estructurada.
Un archivo de este tipo no contiene simplemente un texto largo. Por el contrario, un diálogo se divide en elementos individuales. Normalmente, un diálogo consta de varios mensajes. Cada mensaje contiene información como
- el texto real del mensaje
- el papel del remitente (usuario o IA)
- un sello de tiempo
- en parte más metadatos
Esto permite reconstruir todo el curso del diálogo. Por ejemplo, un diálogo comienza con una pregunta del usuario. A continuación, la IA responde. Después pueden seguir otras preguntas y respuestas. Cada uno de estos mensajes se guarda individualmente.
Esto tiene una gran ventaja: más tarde podemos reconocer exactamente quién dijo qué y cómo se desarrolló una conversación. Esto es especialmente importante para nuestro sistema de conocimiento, ya que queremos buscar y analizar con precisión este contenido más adelante.
Qué datos necesitamos realmente
Aunque la exportación contiene mucha información, no la necesitamos toda para nuestro sistema de conocimiento. El componente más importante son los textos de las conversaciones. Estos textos contienen el contenido real: Ideas, análisis, preguntas y respuestas. Es precisamente este contenido el que queremos buscar más adelante.
Algunos metadatos también pueden ser útiles. Esto incluye, por ejemplo
- Marca de tiempo
- Título de la conversación
- Posiblemente números de identificación internos
Esta información nos ayuda a clasificar mejor los contenidos más adelante o a categorizar una conversación en función del tiempo. Otros componentes de la exportación son menos relevantes para nuestro proyecto. Se trata, por ejemplo, de ciertos metadatos técnicos que sólo tienen interés para el funcionamiento interno de la plataforma.
Para construir nuestra base de conocimientos, nos concentramos deliberadamente en lo esencial: los textos de las conversaciones y alguna información contextual básica. Cuanto más claramente estructuremos estos datos, mejor podrá trabajar después con ellos nuestra IA.
Primera revisión de los datos
Antes de empezar a trabajar con scripts automatizados, merece la pena echar un vistazo rápido a los datos en sí. Para ello, abra uno de los archivos JSON con un editor de texto sencillo o un programa que pueda mostrar bien los archivos JSON. Muchos editores de código como Visual Studio Code son muy adecuados para esto, pero los editores de texto simples también funcionan.
Cuando vea el archivo por primera vez, probablemente verá una cantidad relativamente grande de datos estructurados. Los archivos JSON están formados por elementos anidados, es decir, campos de datos que a su vez contienen otros campos. Esto puede parecer un poco complejo al principio, pero con un poco de paciencia reconocerás rápidamente la estructura básica. Por ejemplo, verá que una conversación consta de varios mensajes y que cada mensaje representa un objeto independiente. El texto propiamente dicho suele estar en un campo claramente reconocible.
Esta primera criba tiene un propósito importante: le ayuda a comprender cómo están estructurados sus datos. Porque en el próximo capítulo utilizaremos precisamente esta estructura para leer automáticamente las conversaciones y prepararlas para nuestro sistema de conocimiento. Dicho de otro modo: Estamos transformando paso a paso un archivo de datos técnicos en una base de conocimientos utilizable. Y aquí es exactamente donde empezamos en el siguiente capítulo. El objetivo es extraer los datos de las conversaciones y prepararlos para que puedan consultarse posteriormente de forma eficaz.
Preparar los datos: De conversaciones a textos analizables
Tras desempaquetar la exportación de datos ChatGPT en el capítulo anterior y obtener una visión general inicial de la estructura, comienza ahora la parte técnica real de nuestro proyecto. Aunque los datos exportados están completos, aún no se adaptan de forma óptima a nuestro sistema de conocimiento en esta forma.
La razón es sencilla: los historiales de chat suelen ser largos, contienen muchos temas y se almacenan en una estructura legible para los humanos, pero no ideal para las búsquedas semánticas o las bases de datos vectoriales. Para que nuestra IA pueda encontrar contenidos relevantes más adelante, primero tenemos que procesar estos datos en bruto. Esto significa esencialmente tres cosas:
- Extraer las conversaciones de los archivos JSON
- estructurar los textos con sentido
- dividir el contenido en secciones más pequeñas
Este proceso es un paso completamente normal en los sistemas modernos de IA y suele denominarse preprocesamiento.
Por qué los datos brutos no son directamente adecuados
Si echas un vistazo a uno de los archivos JSON, te darás cuenta de que una sola conversación a menudo consta de muchos mensajes. Un diálogo típico puede tener este aspecto, por ejemplo:
- Pregunta
- Respuesta
- Consulta
- nueva declaración
- más detalles
- Resumen
Algunas conversaciones pueden contener cientos o incluso miles de palabras. Esto no es un problema para los humanos. Simplemente leemos un diálogo de arriba abajo.
Sin embargo, esto funciona peor para una búsqueda AI. La razón es que un mismo chat suele contener varios temas. Si después realizamos una búsqueda semántica, el sistema debe encontrar pasajes de texto lo más precisos posible, no conversaciones enteras con muchos contenidos diferentes.
Por eso los textos grandes se dividen en secciones más pequeñas. Estas secciones se denominan trozos. Un trozo es simplemente un pequeño bloque de texto que contiene un pensamiento coherente. Este método mejora considerablemente la calidad de la búsqueda posterior.
Extraer historiales de chat
El primer paso práctico es leer el contenido de los archivos JSON. Para ello utilizamos un pequeño script en Python. Python es especialmente adecuado para este tipo de tareas porque contiene muchas bibliotecas para el procesamiento de datos y la IA.
Primero crea un nuevo archivo, por ejemplo
extract_chats.py
A continuación, añadimos un sencillo script que carga los datos del chat.
import json
with open("conversations.json", "r", encoding="utf-8") as f:
data = json.load(f)
print("Anzahl der Gespräche:", len(data))
Cuando ejecute este script, debería ver cuántas conversaciones contiene su exportación. Ahora vamos a extraer los textos reales.
texts = []
for conversation in data:
if "mapping" in conversation:
for node in conversation["mapping"].values():
message = node.get("message")
if message:
content = message.get("content")
if content and "parts" in content:
text = " ".join(content["parts"])
texts.append(text)
print("Extrahierte Textabschnitte:", len(texts))
Este script recorre la estructura JSON y recoge todas las partes de texto de las conversaciones. Esto significa que ya hemos completado la parte más importante: hemos extraído el contenido del formato técnico de exportación.
Crear trozos de texto
Ahora viene el siguiente paso importante: la fragmentación. En lugar de guardar conversaciones completas, dividimos los textos en secciones más pequeñas.
El tamaño típico de estas secciones de texto oscila entre 300 y 800 palabras, es decir, aproximadamente 500 tokens. A continuación se muestra un ejemplo sencillo de cómo dividir textos en trozos.
def split_text(text, chunk_size=500):
words = text.split()
chunks = []
for i in range(0, len(words), chunk_size):
chunk = " ".join(words[i:i+chunk_size])
chunks.append(chunk)
return chunks
Ahora podemos aplicar esta función a nuestros textos.
all_chunks = []
for text in texts:
chunks = split_text(text)
all_chunks.extend(chunks)
print("Gesamtzahl der Chunks:", len(all_chunks))
Ahora hemos creado muchas secciones de texto más pequeñas a partir de nuestros historiales de chat. Estos bloques de texto son ideales para su posterior búsqueda en una base de datos vectorial.
Añadir metadatos
Además del texto propiamente dicho, la información adicional puede ser muy útil. Estos metadatos nos ayudan a clasificar o filtrar mejor el contenido. Los metadatos típicos pueden ser
- Fecha de la conversación
- Título de la conversación
- Fuente (ChatGPT Export)
- ID de la llamada
Podemos guardar esta información junto con el texto, por ejemplo así:
documents = []
for conversation in data:
title = conversation.get("title", "Unbekannt")
if "mapping" in conversation:
for node in conversation["mapping"].values():
message = node.get("message")
if message:
content = message.get("content")
if content and "parts" in content:
text = " ".join(content["parts"])
chunks = split_text(text)
for chunk in chunks:
documents.append({
"text": chunk,
"title": title
})
Esto ya ha dado a nuestros datos una estructura mucho mejor. En lugar de un confuso archivo de chats, ahora tenemos una colección de muchas pequeñas secciones de texto, cada una de ellas con información contextual.
Precisamente esta estructura será crucial en el siguiente paso. Porque ahora podemos empezar a generar incrustaciones a partir de estos textos, es decir, representaciones matemáticas del contenido que luego se guardarán en nuestra base de datos vectorial. Y esto es exactamente de lo que trata el próximo capítulo.
Crear incrustaciones
En el capítulo anterior, ya pusimos nuestros datos de ChatGPT en un formato utilizable. Extrajimos las conversaciones de los archivos JSON, limpiamos los textos y los dividimos en secciones más pequeñas, los llamados chunks.
Sin embargo, todavía falta un paso crucial para que nuestra IA pueda realmente buscar contenidos de forma significativa. Los textos deben traducirse a un formato que las máquinas puedan comparar. Aquí es donde entran en juego las incrustaciones.
Las incrustaciones son representaciones matemáticas de los textos. Permiten a los ordenadores comparar el significado de los textos. Dos textos de contenido similar reciben vectores similares, aunque utilicen palabras distintas. Esta es precisamente la propiedad que necesitamos para nuestro sistema de conocimiento. Al fin y al cabo, nuestra IA no sólo debe buscar palabras idénticas, sino también textos cuyo contenido coincida.
Qué son las incrustaciones
Una incrustación es básicamente una lista de números. Estos números describen el significado de un texto en un espacio matemático. Cada texto se convierte en un vector. Un vector de este tipo puede tener este aspecto, por ejemplo:
[0.134, -0.876, 0.442, 0.921, -0.223, ...]
Un solo vector puede contener varios cientos o incluso miles de números. Por supuesto, estos números no son directamente comprensibles para los humanos. Sin embargo, para las máquinas son ideales para calcular similitudes entre textos. Si dos textos tienen un contenido similar, sus vectores están más próximos en el espacio matemático. Un ejemplo:
- Texto A„¿Cómo puedo exportar mis datos de ChatGPT?“
- Texto B: „¿Cómo descargo mis conversaciones de ChatGPT?“
Aunque la redacción es diferente, ambos textos describen básicamente el mismo tema. Un buen modelo de incrustación reconoce esta similitud. Por tanto, los dos textos reciben vectores similares. Más adelante utilizaremos precisamente este principio para nuestra búsqueda semántica.
Modelos de incrustación con Ollama
Necesitamos un modelo especial para crear incrustaciones. Afortunadamente, para ello no tenemos que recurrir a servicios externos en la nube. Muchos modelos de incrustación pueden funcionar ahora localmente, y aquí es donde entra en juego Ollama.
Dado que Ollama ya está funcionando en su sistema, podemos incrustar allí un modelo install. Un modelo muy bueno es, por ejemplo:
nomic-embed-text
Puedes domarlo con el siguiente comando 1TP12:
ollama pull nomic-embed-text
Otros modelos populares son
- mxbai-embed-large
- bge-large
- todas las películas
Para nuestros fines nomic-embed-text es un buen punto de partida. Este modelo genera incrustaciones de alta calidad y se ejecuta localmente sin problemas.
Crear incrustaciones localmente
Ahora queremos ampliar nuestro script Python para que pueda generar incrustaciones. Primero 1TP12Creamos una biblioteca con la que Python pueda comunicarse con Ollama.
pip install ollama
Ahora podemos abordar el modelo de incrustación directamente desde Python. El siguiente es un ejemplo sencillo:
import ollama
response = ollama.embeddings(
model="nomic-embed-text",
prompt="Wie exportiere ich meine ChatGPT-Daten?"
)
print(len(response["embedding"]))
Si todo ha funcionado, obtendrás un vector con varios cientos de números.
Ahora apliquemos esto a nuestros trozos de chat.
embeddings = []
for doc in documents:
text = doc["text"]
result = ollama.embeddings(
model="nomic-embed-text",
prompt=text
)
vector = result["embedding"]
embeddings.append({
"text": text,
"embedding": vector,
"title": doc["title"]
})
Así creamos un vector para cada sección de texto. Estos vectores se guardan posteriormente en nuestra base de datos.
Por qué es crucial este paso
Las incrustaciones son el núcleo de los modernos sistemas de conocimiento. Sin incrustaciones, sólo podríamos buscar textos mediante las clásicas búsquedas por palabras clave. Esto significaría que el sistema sólo encontraría contenidos que contuvieran exactamente las mismas palabras. Pero el lenguaje rara vez funciona así de sencillo. Por ejemplo, un usuario podría preguntar
„¿Cómo he procesado mis datos de ChatGPT?“
Sin embargo, la conversación original podría formularse así:
„¿Cómo puedo analizar mi exportación de datos ChatGPT?“
Una simple búsqueda podría no reconocer esta conexión. Con las incrustaciones es distinto. Como ambos textos tienen significados similares, sus vectores están próximos en el espacio matemático. Por tanto, nuestra base de datos puede encontrar contenidos coincidentes, aunque la redacción sea diferente. Es precisamente esta capacidad la que hace que la búsqueda semántica sea tan potente. Permite a una IA buscar no sólo palabras, sino significados.
Y precisamente por eso las incrustaciones son el elemento central de nuestro sistema. En el próximo capítulo, nos basaremos en esto y installieren nuestra base de datos de vectores. En ella almacenaremos los vectores generados, creando así la base de nuestra IA del conocimiento personal.
Qdrant 1TP12Añadir y configurar
Una vez creadas las incrustaciones para nuestros datos de chat en el capítulo anterior, ahora tenemos una colección de secciones de texto y vectores asociados. Estos vectores describen matemáticamente el significado de los textos y constituyen la base de una búsqueda semántica. Sin embargo, actualmente estos datos sólo están disponibles en la memoria de trabajo de nuestro script o en simples listas. Necesitamos una memoria especializada para que nuestra IA pueda acceder a ellos de forma eficiente más adelante.
Aquí es exactamente donde entra en juego una base de datos vectorial. Una base de datos vectorial está optimizada para almacenar grandes cantidades de tales incrustaciones y buscar rápidamente vectores similares. Para nuestro proyecto utilizamos Qdrant, una moderna base de datos de código abierto desarrollada especialmente para aplicaciones de IA.
En este capítulo 1TP12 instalaremos Qdrant, iniciaremos el servidor y prepararemos la base de datos para poder importar fácilmente nuestros datos de chat más adelante.
Qué es Qdrant
Qdrant es una base de datos especializada en las llamadas búsquedas vectoriales. Mientras que las bases de datos tradicionales almacenan información en tablas -como nombres, números o textos-, una base de datos vectorial trabaja con representaciones matemáticas de los datos.
Esto significa que en lugar de guardar sólo el texto, Qdrant guarda las incrustaciones asociadas. La gran ventaja reside en la búsqueda. Si más tarde se formula una pregunta, nuestro sistema también convierte esta pregunta en un vector. A continuación, Qdrant puede calcular a la velocidad del rayo qué textos almacenados se parecen más a este vector. Esto permite averiguar, por ejemplo:
- qué pasajes del chat coinciden temáticamente con la pregunta
- qué conversaciones anteriores tienen un contenido similar
- qué ideas podrían ser relevantes en su archivo
Esta es precisamente la razón por la que Qdrant se utiliza hoy en día en muchos sistemas modernos de IA, desde búsquedas de documentos hasta complejos asistentes del conocimiento. Otra ventaja: Qdrant es de código abierto, se 1TP12iza rápidamente y funciona sin problemas en una máquina local normal.
Instalación de Qdrant
La forma más sencilla de installieren Qdrant es a través de Docker. Si Docker está disponible en su máquina, puede iniciar el servidor con un solo comando. Aquí puede Descargar Docker, si aún no lo ha instalado en su ordenador installiert.
docker run -p 6333:6333 qdrant/qdrant
Este comando inicia el servidor Qdrant y abre el puerto estándar 6333. Nuestros scripts podrán comunicarse posteriormente con la base de datos a través de este puerto.
Si no desea utilizar Docker, también hay otras maneras de installiere Qdrant, por ejemplo a través de un binario local o gestor de paquetes. En muchos proyectos prácticos, sin embargo, Docker ha demostrado ser la opción más sencilla y estable.
Una vez iniciado el servidor, Qdrant se ejecuta en segundo plano y espera peticiones. Ahora puede comprobar si el servidor es accesible. Para ello, abra la siguiente dirección en su navegador:
http://localhost:6333
Si todo ha funcionado, debería aparecer un simple mensaje de estado. El servidor ya está listo para los siguientes pasos.
Primeros pasos con Qdrant
Antes de poder importar los datos de nuestro chat, necesitamos crear una colección. En Qdrant, una colección es comparable a una tabla en una base de datos clásica. Contiene nuestros vectores y los datos asociados.
Primero installiere la biblioteca Python para Qdrant:
pip install qdrant-client
Ahora podemos establecer una conexión con la base de datos en nuestro script Python.
from qdrant_client import QdrantClient
client = QdrantClient("localhost", port=6333)
Si este código se ejecuta sin un mensaje de error, la conexión es exitosa. Ahora creamos una colección para nuestros datos de chat.
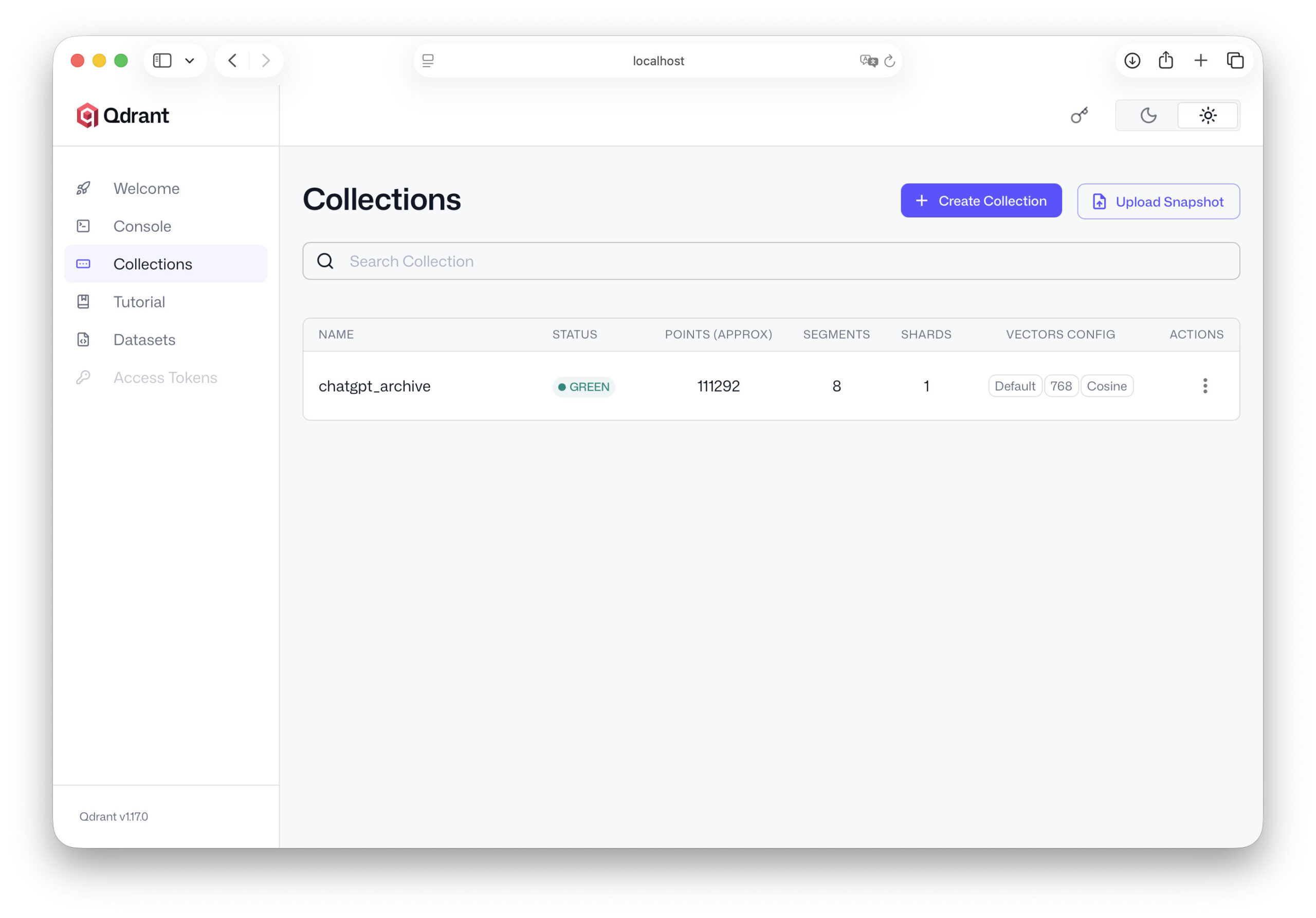
from qdrant_client.models import VectorParams, Distance client.recreate_collection( collection_name="chatgpt_archive", vectors_config=VectorParams(size=768, distance=Distance.COSINE), )
Los parámetros más importantes son
- nombre_colección - el nombre de nuestra base de datos
- talla - la longitud de los vectores de incrustación
- distancia - el método de cálculo de la similitud
El tamaño del vector depende del modelo de incrustación utilizado. Muchos modelos trabajan con vectores de 768 o 1024 dimensiones. La función de distancia coseno es uno de los métodos más comunes para calcular similitudes entre textos. Esto significa que nuestra base de datos ya está lista para ser utilizada.
Estructura de datos del plan
Antes de importar nuestros datos, merece la pena echar un vistazo rápido a la estructura que queremos guardar. Cada entrada de nuestra base de datos de vectores constará de varios componentes:
- ID - un identificador único
- Inserción - el vector del texto
- Carga útil - Información adicional sobre el texto
La carga útil puede contener, por ejemplo
- el texto original
- el título de la conversación
- la fecha
- otros metadatos
Un ejemplo de registro de datos podría ser el siguiente:
{
"id": 1,
"vector": [0.123, -0.452, 0.889, ...],
"payload": {
"text": "Wie kann ich meinen ChatGPT-Datenexport analysieren?",
"title": "Datenanalyse"
}
}
Esta estructura tiene una gran ventaja. Los vectores se utilizan para la búsqueda semántica, mientras que la carga útil contiene toda la información que queremos mostrar o analizar posteriormente. Esto significa que nuestro sistema sigue siendo flexible y puede ampliarse fácilmente más adelante.
Esto significa que la parte más importante de la infraestructura ya está preparada. Nuestro servidor Qdrant está funcionando, la base de datos está configurada y sabemos qué estructura tendrán nuestros datos. En el siguiente capítulo, comenzamos con el paso crucial: importamos nuestros datos de ChatGPT a la base de datos y transformamos nuestro archivo de conversaciones en una base de conocimientos real en la que se pueden realizar búsquedas.
Importar datos de ChatGPT a Qdrant
Ahora que hemos creado Qdrant installiert y una colección en el capítulo anterior, se ha creado la base técnica para nuestra base de datos de conocimiento. Nuestros embeddings ya existen - los hemos creado a partir de los datos de ChatGPT - y Qdrant se está ejecutando como servidor de base de datos en nuestra máquina.
Ahora viene el paso crucial: cargamos nuestros datos en la base de datos. No sólo guardamos los vectores en sí, sino también los textos y metadatos asociados. Esta combinación permite a nuestra IA encontrar posteriormente contenido relevante y utilizarlo en las respuestas. En este capítulo construimos la base de conocimientos de nuestro sistema.
Guardar incrustaciones
En primer lugar, tenemos que transferir las incrustaciones generadas a la base de datos. Cada entrada de Qdrant consta de tres componentes:
- una identificación
- un vector (incrustación)
- una carga útil con datos adicionales
En nuestro caso, por ejemplo, la carga útil contiene
- la sección de texto
- el título de la conversación
- Posiblemente más metadatos
En Python, podemos preparar esta estructura con relativa facilidad. Un ejemplo:
points = []
for idx, item in enumerate(embeddings):
points.append({
"id": idx,
"vector": item["embedding"],
"payload": {
"text": item["text"],
"title": item["title"]
}
})
Esto genera una lista de puntos de datos que podemos guardar en Qdrant. Cada punto de datos contiene, por tanto, una sección de texto, el vector correspondiente e información contextual adicional. Esta estructura constituirá posteriormente la base de nuestra búsqueda semántica.
Crear script de importación
Ahora conectamos nuestro script Python a Qdrant y transferimos los datos. Para ello, utilizamos el cliente Python de Qdrant, que hemos analizado en el capítulo anterior 1TP12. La importación puede tener este aspecto, por ejemplo:
from qdrant_client import QdrantClient
from qdrant_client.models import PointStruct
client = QdrantClient("localhost", port=6333)
points = []
for idx, item in enumerate(embeddings):
point = PointStruct(
id=idx,
vector=item["embedding"],
payload={
"text": item["text"],
"title": item["title"]
}
)
points.append(point)
client.upsert(
collection_name="chatgpt_archive",
points=points
)
print("Import abgeschlossen:", len(points), "Datensätze gespeichert.")
El comando upsert garantiza que los datos se guardan en la colección. Si ya existe un ID, se actualiza la entrada. En caso contrario, se crea un nuevo registro de datos. Dependiendo del tamaño de su exportación ChatGPT, esta importación puede tardar unos segundos o minutos. Esto es completamente normal para conjuntos de datos más grandes - como varios miles de secciones de texto.
Base de datos de pruebas
Una vez finalizada la importación, debemos comprobar que nuestros datos se han guardado correctamente. La prueba más sencilla consiste en realizar una búsqueda vectorial. Para ello, primero creamos una incrustación para una pregunta de prueba.
query = "Wie kann ich ChatGPT-Daten analysieren?" query_vector = ollama.embeddings( model="nomic-embed-text", prompt=query )["embedding"]
Ahora podemos buscar vectores similares en Qdrant.
search_result = client.search( collection_name="chatgpt_archive", query_vector=query_vector, limit=3 )
Este comando devuelve las tres secciones de texto más similares de nuestra base de datos. Por ejemplo, podemos mostrarlas así:
for result in search_result:
print(result.payload["text"])
print("---")
Si todo ha funcionado, ahora aparecerán las secciones de chat de tu archivo que coincidan con la consulta de búsqueda. Ahora ya lo sabemos: Nuestra base de datos funciona.
Primera evaluación de resultados
Este momento es uno de los más emocionantes de todo el proyecto. Por primera vez, se hace evidente que nuestro archivo de chat puede utilizarse realmente como fuente de conocimiento. Ahora puedes probar diferentes consultas de búsqueda. Por ejemplo:
- „Artículo AI“
- „Sistema RAG“
- „Exportación de datos ChatGPT“
- „Idea de estrategia“
En función del contenido de tu historial de chat, Qdrant encontrará pasajes de texto adecuados. A veces te sorprenderá el contenido que resurge. Conversaciones que habías olvidado hace tiempo pueden volver a ser relevantes de repente. Esto demuestra muy claramente por qué este enfoque es tan interesante. Tus viejas conversaciones de IA ya no son sólo un archivo. Se convierten en una base de conocimientos en la que se pueden hacer búsquedas.
Hemos alcanzado así un hito importante. Nuestros datos ChatGPT están ahora totalmente almacenados en la base de datos vectorial y pueden buscarse semánticamente. En el próximo capítulo, daremos un paso más: conectaremos nuestra base de datos de conocimientos con la propia IA. Esto permitirá al modelo lingüístico acceder a estos datos en el futuro e incorporarlos directamente a las respuestas.
Conectar la IA con la base de datos de conocimientos
Hasta este punto, ya hemos construido gran parte de la infraestructura. Nuestros datos ChatGPT se extrajeron de la exportación, se descompusieron en secciones de texto más pequeñas, se incrustaron y, por último, se almacenaron en la base de datos vectorial Qdrant.
Sin embargo, nuestra IA aún no trabaja con estos datos. Aunque podemos realizar una búsqueda vectorial con Python y encontrar pasajes de texto adecuados, la propia IA aún no es consciente de ello. Cuando le hacemos una pregunta, sigue utilizando únicamente sus conocimientos lingüísticos generales.
Por tanto, el siguiente paso es conectar estos dos mundos. Ahora estamos construyendo un proceso en el que la IA recibe primero el contenido pertinente de la base de datos de conocimientos y luego lo incorpora a su respuesta. Este es precisamente el núcleo de un sistema GAR.
Proceso de consulta
El proceso de una consulta cambia ligeramente gracias a nuestro sistema de conocimiento. Hasta ahora, una conversación con una IA solía ser así:
- Haces una pregunta →
- La IA procesa la pregunta →
- la IA genera una respuesta.
Una base de datos de conocimientos es un paso adicional. El nuevo proceso es el siguiente:
- Haces una pregunta →
- la pregunta se convierte en una incrustación →
- la base de datos vectorial busca textos similares →
- Estos textos se transfieren a la IA como contexto →
la IA formula una respuesta. Esto significa que la IA ya no sólo trabaja con sus conocimientos entrenados, sino también con sus propios datos. Este contexto a menudo hace que las respuestas sean mucho más precisas y personalizadas.
Paso de recuperación
La primera parte de este proceso se conoce como recuperación. Recuperación significa simplemente „recuperar“. En este paso, nuestro sistema busca en la base de datos contenidos que coincidan con el tema de la pregunta. En primer lugar, creamos otra incrustación para la pregunta actual.
query = "Welche Ideen hatte ich zur Nutzung meines ChatGPT-Datenexports?" query_vector = ollama.embeddings( model="nomic-embed-text", prompt=query )["embedding"]
Esta incrustación describe el significado de la pregunta en forma matemática. Qdrant puede ahora buscar vectores similares.
results = client.search( collection_name="chatgpt_archive", query_vector=query_vector, limit=5 )
La base de datos devuelve ahora los cinco pasajes de texto que mejor se ajustan a la pregunta. Estos pasajes de texto constituyen el contexto de la IA. Los recopilamos en una lista.
context_texts = [] for r in results: context_texts.append(r.payload["text"])
Ahora disponemos de una recopilación de contenidos relevantes de nuestro archivo de chats.
Transferir contexto a Ollama
Ahora viene el paso decisivo. Pasamos este contexto junto con la pregunta original a nuestro modelo lingüístico. Ahora el modelo puede utilizar esta información para formular una respuesta.
En primer lugar, construimos lo que llamamos un prompt. Un prompt es simplemente el texto que enviamos a la IA.
context = "\n\n".join(context_texts)
prompt = f"""
Du bist ein KI-Assistent, der mit meinem persönlichen Wissensarchiv arbeitet.
Nutze die folgenden Textausschnitte als Kontext:
{context}
Beantworte nun diese Frage:
{query}
"""
Ahora enviamos este mensaje a nuestro modelo lingüístico en Ollama.
response = ollama.chat(
model="llama3",
messages=[
{"role": "user", "content": prompt}
]
)
print(response["message"]["content"])
La IA recibe ahora tanto la pregunta como los pasajes de texto pertinentes de nuestra base de datos. Esto le permite generar respuestas basadas en nuestros propios datos.
Generación de respuestas
El último paso es la generación de respuestas propiamente dicha. El modelo lingüístico combina ahora dos fuentes de conocimiento:
sus propios conocimientos formados
el contexto de nuestra base de datos de conocimientos
Esta combinación es especialmente potente. El modelo puede explicar relaciones generales y al mismo tiempo incorporar contenidos específicos de nuestro archivo. Un ejemplo: Si se pregunta
„¿Qué ideas tenía para utilizar mi exportación de datos ChatGPT?“
la IA puede ahora acceder a conversaciones anteriores y crear un resumen estructurado a partir de ellas. Por ejemplo, puede responder:
- Has hablado de crear un archivo personal de conocimientos
- Querías desarrollar una IA local con un sistema RAG
- Ha desarrollado la idea de una serie de artículos
Sin el paso de recuperación, la IA no habría conocido esta información en absoluto. Con nuestro sistema, su archivo de chat se convierte en una verdadera fuente de conocimiento. Esto completa la parte más importante de nuestro sistema. Ahora lo tenemos:
- una IA local a través de Ollama
- una base de datos vectorial con nuestros datos de chat
- una búsqueda semántica
- un flujo de trabajo RAG
En el próximo capítulo probaremos este sistema en la práctica y comprobaremos lo bien que funciona nuestra IA de conocimiento personal.
Primeras consultas con su conocimiento personal AI
Ahora que hemos establecido la conexión entre nuestra IA y la base de datos de conocimientos en el capítulo anterior, el sistema está técnicamente completo. Nuestros datos ChatGPT están en la base de datos vectorial, la IA puede recuperar el contenido relevante y todo el proceso de un sistema RAG funciona.
Ahora llega la parte más emocionante del proyecto: las primeras consultas reales. Porque sólo ahora podemos ver si nuestro sistema hace realmente lo que esperábamos, es decir, encontrar conversaciones anteriores, analizar contenidos y generar respuestas significativas. En este capítulo ponemos a prueba nuestra IA del conocimiento, analizamos casos de uso típicos y estudiamos posibles optimizaciones.
Ejemplos de consultas
Empecemos con algunas preguntas sencillas. Una buena estrategia es empezar haciendo preguntas que sepas que están en tu archivo de chat. Por ejemplo:
„¿Qué ideas tenía para utilizar mi exportación de datos ChatGPT?“
„¿Qué he escrito sobre los sistemas RAG?“
„¿Qué estrategias he discutido para utilizar la IA?“
Estas preguntas contienen deliberadamente formulaciones abiertas. El objetivo no es encontrar un texto concreto, sino descubrir un contenido temáticamente apropiado. Cuando usted formula una pregunta de este tipo a su sistema, el proceso que establecimos en el capítulo anterior tiene lugar en segundo plano:
- La pregunta se convierte en una incrustación.
- La base de datos vectorial busca secciones de texto similares.
- Estos pasajes de texto se transfieren a la IA como contexto.
- La IA genera una respuesta basada en este contexto.
El resultado puede ser sorprendente. A menudo surgen conversaciones olvidadas hace tiempo. Viejas ideas reaparecen de repente en la pantalla, a veces incluso en un contexto completamente nuevo.
Este es precisamente el punto fuerte de este enfoque. Tu archivo de chat se convierte en una fuente de conocimiento en la que se pueden hacer búsquedas.
Calidad de las respuestas
Si realiza algunas consultas, se dará cuenta de que la calidad de las respuestas puede variar. Esto es completamente normal. La calidad de un sistema de este tipo depende de varios factores. Un factor importante es el tamaño de los trozos de texto. Si los trozos son demasiado grandes, pueden contener varios temas. Esto hace que la búsqueda sea menos precisa.
Sin embargo, si los trozos son demasiado pequeños, a veces falta el contexto necesario. Otro factor es el modelo de incrustación. Los distintos modelos reconocen los contextos de significado de forma diferente. Algunos son especialmente adecuados para textos técnicos, otros para el lenguaje general.
El número de resultados recuperados también influye. Por ejemplo, si sólo se recuperan dos pasajes de texto, puede faltar información importante. Si, por el contrario, se cargan demasiados textos, la IA puede tener dificultades para reconocer el contexto pertinente.
Estos parámetros pueden ajustarse fácilmente más adelante. Lo más importante en primer lugar es disponer de un sistema básico que funcione.
Problemas típicos
Como ocurre con cualquier sistema técnico, aquí también pueden surgir algunas dificultades. Un problema habitual es que la base de datos encuentre textos que sólo son parcialmente relevantes. Esto se debe a que la búsqueda semántica siempre trabaja con probabilidades.
Otro problema puede surgir si los textos se han fragmentado demasiado. Si un pensamiento está repartido en varios trozos, la IA puede tener dificultades para reconocer el contexto.
La indicación también desempeña un papel. Si no está claro, la IA puede no aprovechar al máximo el contexto. Un ejemplo de una indicación mejor podría ser el siguiente:
Utilice los siguientes extractos de texto de mi archivo de conocimientos,
responder a la pregunta con la mayor precisión posible.
Si existen contenidos relevantes, resúmalos.
Estos pequeños ajustes pueden mejorar significativamente la calidad de las respuestas.
Ajuste fino
En cuanto el sistema funciona básicamente, empieza la parte más interesante: la puesta a punto. Aquí puedes experimentar y mejorar tu sistema de conocimiento paso a paso. Algunas optimizaciones típicas son
- Ajustar el tamaño de los trozos
A veces, las secciones de texto más pequeñas proporcionan mejores resultados. En otros casos, es útil disponer de más contexto. - Utilización de un modelo de incrustación diferente
Cambiar el modelo puede mejorar significativamente la calidad de la búsqueda semántica. - Más contexto para la IA
Puede recuperar más resultados de la base de datos, por ejemplo diez pasajes de texto en lugar de cinco. - Utilizar metadatos
Si guarda información adicional, como la fecha o el título de la convocatoria, podrá filtrar la búsqueda con mayor precisión más adelante.
Estos ajustes forman parte de todo sistema GAR real. Rara vez existe un ajuste perfecto para todas las situaciones. Pero ése es precisamente el atractivo de estos sistemas: se pueden mejorar continuamente.
Con este capítulo hemos realizado la primera prueba completa de nuestro sistema. Hemos visto que, efectivamente, nuestra IA de conocimiento personal es capaz de buscar en conversaciones antiguas y recuperar contenido relevante.
Esto significa que el núcleo de nuestro proyecto ya se ha logrado. Pero el sistema aún puede ampliarse considerablemente. Por ello, en el próximo capítulo veremos cómo se pueden integrar fuentes de datos adicionales y ampliar paso a paso el archivo personal de conocimientos.



Extensiones para su sistema personal de conocimiento de IA
Ya has creado un sistema funcional con la configuración anterior. Tus datos de ChatGPT han sido extraídos, convertidos en embeddings, almacenados en Qdrant y finalmente conectados a una IA local. El resultado es una IA de conocimiento que puede acceder a conversaciones anteriores.
Pero, estrictamente hablando, sólo estamos al principio. La arquitectura que has construido no se limita a los datos ChatGPT. Funciona con cualquier tipo de texto. Cualquier cosa que pueda convertirse en documentos o archivos de texto puede pasar a formar parte de este sistema de conocimiento. Aquí es donde reside el verdadero potencial de este tipo de sistemas.
Lo que hemos construido básicamente es una máquina de conocimiento personal. Y esta máquina puede ampliarse paso a paso. En este capítulo veremos las posibilidades que se derivan de ello y cómo puedes ampliar tu sistema a largo plazo.
Integrar fuentes de datos adicionales
El siguiente paso más obvio es añadir más contenido a tu base de conocimientos. Las conversaciones de ChatGPT son un buen comienzo, pero normalmente sólo representan una parte de tus propios conocimientos. Hay mucha información disponible en otros formatos. Por ejemplo:
- artículos propios
- Notas
- Documentos PDF
- Documentos de investigación
- Libros electrónicos
- Protocolos o listas de ideas
Todo este contenido puede procesarse de la misma manera que nuestros datos de chat. El proceso sigue siendo idéntico:
- Extraer texto
- Dividir el texto en trozos
- Crear incrustaciones
- Guardar datos en Qdrant
Un ejemplo: Si ha escrito muchos artículos propios, puede importar estos textos a su base de datos de conocimientos. La IA puede acceder a ellos más tarde y reconocer correlaciones. Por ejemplo, podría preguntar:
„¿Qué artículos he escrito sobre IA?“
o
„¿Qué argumentos he desarrollado sobre este tema en el pasado?“.“
A continuación, la IA busca en tu archivo de artículos y utiliza el contenido que encuentra como contexto. De este modo, el sistema se convierte paso a paso en un completo archivo de conocimientos.
Varias bases de datos de conocimientos
A medida que aumenta la cantidad de datos, puede ser útil separar diferentes áreas. Qdrant le permite crear múltiples colecciones. Cada colección puede representar su propia base de conocimientos. Un posible sistema podría tener este aspecto, por ejemplo:
- Colección 1Conversaciones ChatGPT
- Colección 2: Archivo de artículos
- Colección 3Notas personales
- Colección 4Documentación técnica
Esta separación tiene varias ventajas. En primer lugar, la estructura permanece clara. Siempre se sabe dónde se almacenan determinados contenidos. En segundo lugar, las consultas pueden controlarse de forma más específica. Algunas preguntas quizá sólo deban buscar en su archivo de artículos, otras en todo su sistema de conocimiento. Un ejemplo:
- Una pregunta de investigación sólo podría buscarse en el archivo de artículos.
- En cambio, una pregunta estratégica podría tener en cuenta todas las colecciones al mismo tiempo.
Estas estructuras hacen que los grandes sistemas de conocimiento sean mucho más eficientes.
Actualizaciones automáticas
Otro paso útil es actualizar el sistema con regularidad. En el ejemplo anterior, hemos procesado la exportación de datos ChatGPT una vez. En la práctica, sin embargo, se crean nuevos contenidos constantemente.
Nuevas conversaciones, nuevas notas, nuevos documentos... toda esta información también podría pasar a formar parte de tu archivo de conocimientos.
Por tanto, merece la pena pensar en las actualizaciones automáticas. Una solución sencilla consiste en importar regularmente nuevos datos. Por ejemplo:
- Procesar nuevos datos de chat una vez a la semana
- Importación automática de nuevos documentos
- Añadir inmediatamente nuevos artículos a la base de datos
Técnicamente, esto es relativamente fácil de implementar. Un pequeño script puede comprobar periódicamente si hay nuevos archivos disponibles y procesarlos automáticamente. De este modo, el sistema de conocimientos crece continuamente. Con el tiempo, se crea un archivo cada vez más extenso que documenta tus pensamientos y proyectos.
Integración en sus propias aplicaciones
Hasta ahora, nuestro sistema se ha utilizado mediante sencillos scripts en Python. Pero a largo plazo, este sistema también puede integrarse en tus propias aplicaciones. Por ejemplo, muchos desarrolladores están construyendo pequeñas interfaces web que permiten utilizar directamente su IA del conocimiento.
En lugar de iniciar una secuencia de comandos, basta con escribir una pregunta en un campo de entrada. El mismo proceso se ejecuta en segundo plano:
- Crear incrustación
- Buscar en la base de datos
- Transferir el contexto a la IA
- Generar respuesta
El resultado aparece directamente en la interfaz de usuario. Una aplicación de este tipo puede adoptar formas muy diferentes. Por ejemplo:
- una IA de investigación personal
- un asistente de conocimientos para proyectos
- un buscador de ideas
- un archivo de artículos y notas
La combinación de estos sistemas con otras herramientas resulta especialmente interesante. Por ejemplo, un sistema editorial podría acceder automáticamente a su archivo de conocimientos y utilizar artículos anteriores como base para la investigación. O un sistema de notas podría integrar automáticamente nuevas ideas en tu base de datos.
En otras palabras, la IA pasa a formar parte de tu entorno de trabajo diario. Esto deja claro que nuestro pequeño proyecto va mucho más allá de la exportación de datos original de ChatGPT.
No nos hemos limitado a crear un archivo. Hemos creado una arquitectura que puede ampliarse según las necesidades. Y es precisamente ahí donde reside el verdadero valor de estos sistemas. No son estáticos. Crecen con sus conocimientos.
Versión ampliada del gasoducto para descargar
El siguiente script es una versión extendida del pipeline del artículo. Es más robusto y mucho más cercano a una solución productiva. Se han mejorado tres cosas:
- Indicador de progresoEl usuario puede ver en todo momento cuántos textos se han procesado ya.
- Importación por lotesLas incrustaciones se recopilan y escriben en Qdrant en bloques, lo que resulta mucho más rápido que las importaciones individuales.
- Canal de incrustación más rápidoEl script funciona de forma estructurada con trozos preparados y reduce las llamadas innecesarias.
Por lo tanto, este script es especialmente adecuado si la exportación de ChatGPT es mayor: varios miles de conversaciones, por ejemplo. Proceso típico:
- Cargar exportación ChatGPT
- Extraer textos
- Dividir el texto en trozos
- Crear incrustaciones
- Importación por lotes en Qdrant
- Realizar una consulta de prueba
Ajustes importantes en el script
Algunos valores deben ser ajustados por el usuario:
- EXPORT_PFAD
Pfad zu den meist nummerierten Dateien conversations.json aus dem ChatGPT-Export. - NOMBRE_COLECCIÓN
Nombre de la colección de bases de datos vectoriales. - MODELO_EMBED
Embedding-Modell von Ollama, z. B. nomic-embed-text oder mxbai-embed-large - ANSWER_MODEL
Sprachmodell für die Testabfrage, z.B. llama, mistral oder gpt:oss - VECTOR_SIZE
Dimensión del modelo de incrustación.
nomic-embed-text → 768
mxbai-embed-large → 1024 - CHUNK_SIZE
Tamaño de las secciones de texto.
Normalmente de 300 a 600 palabras. - BATCH_SIZE
Cuántas incrustaciones se escriben en Qdrant al mismo tiempo.
Valor típico: 50-200.
Bleib auf dem Laufenden – ohne Werbung
Wenn Du über Updates zu diesem Skript oder über neue Downloads informiert bleiben möchtest, kannst Du Dich in meinen monatlichen Newsletter eintragen. Der Newsletter ist bewusst schlank gehalten, komplett werbefrei und erscheint nur einmal im Monat. Darin findest Du eine Auswahl der wichtigsten neuen Artikel, praxisnahe Inhalte rund um KI, Software und Digitalisierung sowie Hinweise auf aktualisierte Skripte oder neue Download-Angebote. Kein Spam, keine täglichen Mails – nur die relevantesten Inhalte in kompakter Form. Wenn Du diese Entwicklungen kontinuierlich verfolgen möchtest, ist der Newsletter die einfachste Möglichkeit, auf dem aktuellen Stand zu bleiben.
Ausblick auf Teil 3: Feinschliff, Analyse und optimale Nutzung der Daten
Im dritten Teil der Serie gehen wir einen Schritt weiter und schauen uns an, was sich konkret aus der aufgebauten Wissensdatenbank herausholen lässt. Nachdem die ChatGPT-Daten nun in Qdrant gespeichert sind, steht die eigentliche Nutzung im Mittelpunkt. Wir werfen einen Blick auf die Qdrant-Weboberfläche, analysieren die gespeicherten Daten und prüfen, wie gut die semantische Suche bereits funktioniert. Darüber hinaus geht es um wichtige Feinjustierungen: Wie sollte das Chunking je nach Anwendungsfall gewählt werden? Wie lässt sich der Kontext optimal an ein lokales Sprachmodell übergeben? Und wie kann man die Qualität der Antworten gezielt verbessern? Der dritte Teil richtet sich an alle, die aus dem System mehr herausholen und es bewusst weiterentwickeln möchten.




Preguntas más frecuentes
- ¿Para qué sirve integrar la exportación de datos de ChatGPT en mi propia IA?
La mayor ventaja es que puedes utilizar tus propias conversaciones y pensamientos a largo plazo. Muchas personas mantienen conversaciones intensas con sistemas de IA sobre proyectos, ideas, análisis o cuestiones personales. Normalmente, este contenido desaparece en el transcurso de la plataforma. Sin embargo, si lo exportas y lo integras en tu propia base de datos de conocimientos, se convierte en un archivo personal. Tu IA local puede entonces acceder a este contenido, reconocer correlaciones y ayudarte con nuevas preguntas. En lugar de empezar siempre desde cero, construyes tu propio pensamiento paso a paso. - ¿No es muy complicado para alguien que no es desarrollador?
A primera vista, términos como incrustaciones, bases de datos vectoriales o sistemas RAG parecen complejos. En la práctica, sin embargo, los pasos individuales están estructurados de forma relativamente clara. Básicamente, sólo se necesitan tres componentes: una IA local (por ejemplo, a través de Ollama), una base de datos vectorial como Qdrant y un pequeño script en Python que procese los datos. Muchos de los pasos se ejecutan automáticamente. Una vez configurado el sistema, funciona como un motor de búsqueda normal o un chatbot, con la diferencia de que trabaja con tus propios conocimientos. - ¿Qué datos contiene realmente la exportación ChatGPT?
La exportación de ChatGPT suele contener todas las conversaciones que has mantenido con el sistema. Esto incluye no sólo los mensajes de texto en sí, sino también metadatos como títulos de conversación, marcas de tiempo e información estructural. Los datos suelen estar disponibles en formato JSON, por lo que pueden procesarse con relativa facilidad mediante scripts. En muchos casos, la exportación también incluye archivos multimedia o de idioma si se utilizaron en las conversaciones. Sin embargo, lo que interesa a la hora de crear una base de datos de conocimientos es sobre todo el contenido textual. - ¿Por qué se utiliza una base de datos vectorial para estos sistemas y no una base de datos normal?
Las bases de datos normales son ideales para buscar términos o ID específicos. Sin embargo, son menos adecuadas para búsquedas semánticas. Una base de datos vectorial almacena los textos no sólo como cadenas de caracteres, sino también como vectores matemáticos que describen el significado de un texto. Esto permite al sistema buscar similitudes en el contenido. Por ejemplo, si pide „ideas para artículos sobre inteligencia artificial“, la base de datos también puede encontrar contenidos que contengan otras frases como „temas para artículos de blog sobre inteligencia artificial“. - ¿Qué son las incrustaciones y por qué son tan importantes?
Las incrustaciones son representaciones matemáticas de los textos. Un modelo lingüístico convierte un texto en una lista de números que describen su significado. Los textos con significados similares se aproximan en el espacio matemático. Esto permite a una base de datos vectorial buscar posteriormente contenidos similares. Sin incrustaciones, una búsqueda semántica difícilmente sería posible. Constituyen la base de los sistemas RAG modernos y son la razón por la que dichos sistemas son mucho más flexibles que las búsquedas clásicas de texto completo. - ¿Qué tamaño puede tener mi exportación de datos ChatGPT?
El tamaño no juega un papel importante. Incluso varios miles de conversaciones pueden procesarse sin problemas. Lo que es más importante es el número de secciones de texto generadas, los llamados chunks. Una exportación mayor conlleva más chunks y, por tanto, más incrustaciones. Sin embargo, las bases de datos vectoriales modernas pueden gestionar fácilmente millones de entradas de este tipo. Incluso un pequeño servidor o un potente ordenador de sobremesa son completamente suficientes para un asistente de conocimiento privado. - ¿Por qué se divide el texto en pequeñas secciones antes de procesarlo?
Si guarda conversaciones completas o textos extensos directamente como incrustaciones, la búsqueda semántica se vuelve imprecisa. Un solo texto puede contener varios temas. Dividiéndolo en secciones más pequeñas, el sistema puede realizar búsquedas más precisas. Cada sección describe un tema más claro. Esto permite a la base de datos encontrar exactamente las partes de una conversación que realmente se ajustan a la pregunta actual. - ¿Qué papel desempeña el Ollama en este sistema?
Ollama sirve de plataforma local para modelos lingüísticos. Le permite ejecutar modelos de IA directamente en su propio ordenador. En nuestro sistema, Ollama realiza dos tareas: Crea incrustaciones para textos y genera respuestas a preguntas. La ventaja es que todos los datos permanecen locales. Esto significa que sus conversaciones y su archivo de conocimientos nunca salen de su propio ordenador. - ¿Por qué se utiliza Qdrant como base de datos vectorial?
Qdrant es una moderna base de datos vectorial especialmente desarrollada para aplicaciones de IA. Es rápida, fácil de installieren y está muy bien documentada. También se puede conectar fácilmente a Python y a muchos marcos de trabajo de IA. Qdrant es, por tanto, una solución especialmente práctica para los sistemas de conocimiento local. Otras alternativas son Chroma, Weaviate o Pinecone. - ¿Qué significa el término sistema RAG?
RAG son las siglas de „Retrieval-Augmented Generation“ (generación mejorada por recuperación). Se trata de una arquitectura en la que una IA recupera primero la información pertinente de una base de datos y luego la utiliza para generar una respuesta. La IA combina así sus propios conocimientos con datos externos. Esto le permite dar respuestas muy precisas y, al mismo tiempo, acceder a información actual o personal. - ¿Puedo integrar también otras fuentes de datos en este sistema?
De hecho, ésta es una de las mayores ventajas de esta arquitectura. El sistema no se limita a los datos de ChatGPT. También puede integrar sus propios artículos, notas, PDF, trabajos de investigación u otros documentos. Siempre que el contenido pueda procesarse en forma de texto, puede pasar a formar parte de la base de conocimientos. Con el tiempo, su sistema se convertirá en un completo archivo de conocimientos. - ¿Hasta qué punto se mantiene actualizado un sistema de conocimientos de este tipo?
La actualización depende de la frecuencia con la que importes nuevos datos. Por ejemplo, puede procesar regularmente nuevas exportaciones de ChatGPT o crear un script que reconozca automáticamente los nuevos documentos. Muchos sistemas están configurados para actualizarse una vez a la semana o al mes. De este modo, la base de conocimientos se mantiene actualizada en todo momento. - ¿Qué hardware necesito para un sistema de este tipo?
Un ordenador de sobremesa moderno es suficiente para proyectos pequeños. Si se desea utilizar un modelo lingüístico más amplio, una GPU puede resultar útil. Sin embargo, muchos usuarios también ejecutan con éxito sus sistemas de conocimiento en un potente portátil o miniservidor. Sobre todo, es importante disponer de suficiente memoria y espacio de almacenamiento para la base de datos. - ¿A qué velocidad funciona un sistema así en la práctica?
La velocidad depende de varios factores, como el tamaño de la base de datos, el hardware y el modelo de lenguaje utilizado. En muchos casos, una consulta sólo tarda unos segundos. La búsqueda vectorial en sí suele ser extremadamente rápida. La mayor parte del tiempo suele emplearse en generar la respuesta a partir del modelo lingüístico. - ¿Es posible separar varias áreas de conocimiento?
Sí, las bases de datos vectoriales como Qdrant permiten el uso de múltiples colecciones. Cada colección puede representar un área temática distinta. Por ejemplo, se puede crear una colección para conversaciones ChatGPT, otra para artículos y otra para notas. Esto permite estructurar claramente las áreas de conocimiento y realizar búsquedas específicas. - ¿Hasta qué punto están seguros mis datos en un sistema local de IA?
La gran ventaja de un sistema local es que sus datos no tienen que transferirse a servicios externos. Toda la información permanece en su propio ordenador o servidor. Esto es especialmente interesante para los contenidos sensibles. Por supuesto, debes hacer copias de seguridad periódicas y proteger tu sistema contra accesos no autorizados. - ¿Puedo integrar este sistema en mis propias aplicaciones?
Sí, se puede acceder a la mayoría de los componentes a través de interfaces de programación. Esto le permite integrar su sistema de conocimientos en sus propias herramientas, por ejemplo en una interfaz web, un sistema editorial o una aplicación de notas. Muchos desarrolladores crean pequeñas aplicaciones que permiten acceder directamente a su base de datos de conocimientos a través de una interfaz de chat. - ¿Cómo podría evolucionar esta tecnología en el futuro?
Las IA de conocimiento personal están probablemente sólo al principio de su desarrollo. En el futuro, estos sistemas podrían integrar automáticamente nuevos contenidos, crear resúmenes o incluso ofrecer sus propias sugerencias de proyectos. Cuantos más datos reciba un sistema de este tipo, más valioso será. A largo plazo, podría convertirse en una especie de memoria digital personal que estructure tus conocimientos y los haga accesibles en cualquier momento.


