In het eerste deel van deze artikelreeks zagen we dat het exporteren van ChatGPT-gegevens veel meer is dan alleen een technische functie. Je geëxporteerde gegevens bevatten een verzameling gedachten, ideeën, analyses en gesprekken die zich over een lange periode hebben verzameld. Maar zolang deze gegevens alleen als een archief op je harde schijf worden opgeslagen, blijft het alleen dat: een archief. De cruciale stap is om deze informatie weer bruikbaar te maken. Dit is precies waar de ontwikkeling van een persoonlijke kennis-AI begint.
Het idee is eigenlijk verrassend eenvoudig: een AI moet niet alleen met algemene kennis werken, maar ook toegang hebben tot je eigen gegevens. Hij moet eerdere gesprekken doorzoeken, geschikte inhoud vinden en deze verwerken in nieuwe antwoorden. Dit verandert een gewone AI in een soort digitaal geheugen. Dit is het tweede deel van de artikelreeks, waarin nu wordt ingegaan op de praktische kant van de zaak.




Teil 1 der Serie: Der unterschätzte Schatz im ChatGPT-Datenexport
Während wir in diesem zweiten Teil konkret in die Praxis einsteigen, lohnt sich ein Blick auf den ersten Artikel dieser Serie. Dort geht es um die grundlegende Frage, warum der ChatGPT-Datenexport überhaupt so interessant ist – und weshalb viele Nutzer sein Potenzial noch unterschätzen. Der Artikel zeigt, welche Daten tatsächlich im Export enthalten sind, wie daraus ein persönliches Wissensarchiv entstehen kann und warum genau dieser Schritt die Grundlage für eine eigene KI mit Gedächtnis bildet. Wenn Du verstehen möchtest, warum wir diese Pipeline überhaupt aufbauen und welchen strategischen Wert Deine eigenen Chatverläufe haben, solltest Du mit Teil 1 beginnen.
Voordat we in het volgende hoofdstuk beginnen met de eigenlijke implementatie, laten we eerst eens kijken hoe zo'n systeem in wezen in elkaar zit.
Het basisidee van een RAG-systeem
De technische basis van ons systeem is een concept dat nu veel gebruikt wordt in de AI-wereld: RAG, of Retrieval Augmented Generation. Achter deze term schuilt een heel praktisch principe.
Normaal gesproken beantwoordt een taalmodel vragen uitsluitend met de kennis die is opgedaan tijdens de training. Hoewel deze kennis uitgebreid is, heeft het twee doorslaggevende beperkingen:
- Ten eerste kent het model geen individuele informatie over je eigen projecten of gedachten.
- Ten tweede heeft het geen toegang tot nieuwe gegevens die na de training zijn aangemaakt.
Dit is precies waar een RAG-systeem om de hoek komt kijken. In plaats van direct een antwoord te genereren, gebeurt er eerst iets anders: het systeem zoekt in een database naar inhoud die overeenkomt met de gestelde vraag. Deze inhoud wordt vervolgens als context overgedragen aan het taalmodel. Pas daarna formuleert de AI zijn antwoord. Eenvoudig gezegd ziet het proces er als volgt uit:
- Je stelt een vraag →
- doorzoekt het systeem een kennisdatabase →
- relevante inhoud is gevonden →
- Deze inhoud wordt overgedragen aan de AI als context →
- genereert de AI een antwoord.
Het beslissende voordeel ligt voor de hand: de AI kan informatie gebruiken die geen deel uitmaakte van de oorspronkelijke training.
En dit is waar je ChatGPT-gegevens om de hoek komen kijken. Als we deze gesprekken integreren in een kennisdatabase, kan de AI ze later openen. Het kan eerdere ideeën vinden, argumenten uit oude dialogen gebruiken of rekening houden met analyses uit eerdere gesprekken. Het systeem begint dus je eigen gedachten te „onthouden“.
De bouwstenen van ons systeem
Om dit te laten werken, hebben we verschillende componenten nodig die samenwerken. Gelukkig is de technische infrastructuur hiervoor tegenwoordig veel gemakkelijker toegankelijk dan een paar jaar geleden. De kern van ons systeem bestaat uit vier centrale componenten.
- De eerste bouwsteen is de ChatGPT-gegevens exporteren. Hier bevinden zich onze ruwe gegevens. Dit bevat alle gesprekken die we eerder met de AI hebben gevoerd.
- De tweede bouwsteen is een Inbeddingsmodel. Dit model vertaalt tekst in wiskundige vectoren. Dit maakt het mogelijk om teksten te vergelijken op basis van hun betekenis.
- De derde bouwsteen is een Vector database. In ons geval gebruiken we Qdrant. Deze database slaat de wiskundige representaties van de teksten op en maakt snel semantisch zoeken mogelijk.
- De vierde bouwsteen is een lokaal taalmodel, die via Ollama loopt. Dit model zal later de werkelijke antwoorden formuleren.
Deze vier componenten werken nauw samen.
- De gegevensexport levert de inhoud.
- Het inbeddingsmodel maakt ze machineleesbaar.
- De vectordatabase slaat ze op en doorzoekt ze.
- Het taalmodel genereert uiteindelijk begrijpelijke antwoorden.
Samen vormen ze de basis voor een persoonlijke kennis-AI.
De gegevensstroom in één oogopslag
Om het systeem te laten werken, moeten de gegevens verschillende stappen doorlopen. De eerste stap is de ChatGPT gegevensexport, die we al in het eerste artikel hebben gemaakt. De gesprekken die het bevat, worden eerst uit de JSON-bestanden gehaald. Deze teksten moeten vervolgens worden voorbereid. Grote chatgeschiedenissen worden opgesplitst in kleinere delen, bekend als tekstbrokken. Dit maakt het daaropvolgende zoeken veel efficiënter.
In de volgende stap genereren we inbeddingen uit deze tekstgedeelten. Elke tekst wordt wiskundig beschreven. Teksten met een vergelijkbare betekenis krijgen vergelijkbare vectoren. Deze vectoren slaan we op in onze vectordatabase Qdrant.
Dit betekent dat het belangrijkste deel van de infrastructuur al aanwezig is. Als er later een vraag wordt gesteld, gebeurt het volgende:
- De vraag wordt ook omgezet in een vector.
- De database zoekt naar teksten met een vergelijkbare betekenis.
- Deze tekstpassages worden als context overgebracht naar het taalmodel.
- Het model gebruikt deze informatie om een antwoord te formuleren.
Dit proces zorgt ervoor dat de AI niet alleen algemene kennis gebruikt, maar ook toegang heeft tot je eigen gegevens.
Wat er uiteindelijk mogelijk zal zijn
Als het systeem eenmaal is ingesteld, verandert de omgang met AI merkbaar. Je werkt niet langer alleen met een algemeen taalmodel, maar met een AI die toegang heeft tot je eigen gegevens. Dit opent compleet nieuwe mogelijkheden. Je kunt bijvoorbeeld vragen stellen als:
„Heb ik ooit met de AI over dit onderwerp gesproken?“
„Welke ideeën had ik eerder over dit project?“
„Welke argumenten heb ik in eerdere gesprekken ontwikkeld?“
De AI doorzoekt vervolgens je eigen gesprekken en vindt geschikte inhoud. In plaats van alleen een algemeen antwoord te geven, kan het verwijzen naar eerdere gedachten, oude analyses samenvatten of verbanden herkennen tussen verschillende gesprekken.
Met andere woorden, de AI gaat werken met je eigen kennisarchief. Dit verandert een eenvoudige chattool in een systeem dat je denken op de lange termijn kan ondersteunen. En het is precies dit systeem dat we in de volgende hoofdstukken stap voor stap zullen opbouwen. In het volgende hoofdstuk beginnen we met het praktische werk en nemen we eerst de gegevensexport van ChatGPT onder de loep. Want voordat we een kennisdatabase kunnen bouwen, moeten we begrijpen hoe onze gegevens eigenlijk gestructureerd zijn.
Huidig onderzoek naar het gebruik van lokale AI-systemen
Voorbereiding: De gegevensexport van ChatGPT begrijpen
In het eerste artikel in deze serie hebben we de ChatGPT-gegevensexport al gemaakt en gedownload als ZIP-bestand. Op het eerste gezicht lijkt dit bestand misschien wat onspectaculair - een archief met wat technische bestanden dat in eerste instantie meer weg heeft van een back-up dan van een waardevolle dataset. Dit archief bevat echter de basis voor ons hele kennissysteem.
Voordat we deze gegevens in een database kunnen laden of aan een AI kunnen koppelen, moeten we eerst begrijpen hoe de export is gestructureerd. Want alleen als we weten welke informatie het bevat en hoe het is gestructureerd, kunnen we het later op een zinvolle manier verwerken. In dit hoofdstuk bekijken we daarom hoe de gegevensexport is gestructureerd, welke bestanden echt relevant zijn en hoe we dit technische archief kunnen omvormen tot een nuttige basis voor ons AI-kennissysteem.
ZIP-bestand uitpakken
De eerste stap is triviaal, maar niettemin belangrijk: we moeten het gedownloade archief uitpakken. Het bestand is normaal beschikbaar als een klassiek ZIP-bestand. Afhankelijk van de mate waarin je het eerder hebt gebruikt, kan de grootte variëren. Sommige gebruikers ontvangen een archief van een paar honderd megabytes, anderen meerdere gigabytes.
Nadat je het bestand hebt uitgepakt, wordt er een map aangemaakt met verschillende bestanden en submappen. De exacte structuur kan enigszins variëren, maar je vindt er meestal een aantal JSON-bestanden en mogelijk andere bestanden met aanvullende informatie.
Voor veel gebruikers lijkt deze structuur in eerste instantie wat technisch. Maar als je even de tijd neemt, herken je al snel een patroon: de gegevens zijn relatief netjes georganiseerd en volgen een duidelijke structuur. Dat is goed nieuws, want het is precies deze structuur die het mogelijk maakt om de inhoud later automatisch te verwerken.
Structuur van de chatgegevens
Het belangrijkste deel van de export zijn de eigenlijke chatgegevens. Deze gesprekken worden meestal opgeslagen in één of meerdere JSON-bestanden. JSON is een veelgebruikt gegevensformaat dat vaak wordt gebruikt om gestructureerde informatie op te slaan.
Zo'n bestand bevat niet simpelweg een lange tekst. In plaats daarvan is een dialoog opgedeeld in afzonderlijke elementen. Meestal bestaat een dialoog uit meerdere berichten. Elk bericht bevat informatie zoals
- de eigenlijke tekst van het bericht
- de rol van de afzender (gebruiker of AI)
- een tijdstempel
- gedeeltelijk verdere metagegevens
Hierdoor kan het hele verloop van de dialoog worden gereconstrueerd. Een dialoog begint bijvoorbeeld met een vraag van de gebruiker. Deze wordt gevolgd door een antwoord van de AI. Daarna kunnen er nog meer vragen en antwoorden volgen. Elk van deze berichten wordt afzonderlijk opgeslagen.
Dit heeft één groot voordeel: we kunnen later precies herkennen wie wat zei en hoe een gesprek zich ontwikkelde. Dit is vooral belangrijk voor ons kennissysteem, omdat we later precies deze inhoud willen doorzoeken en analyseren.
Welke gegevens hebben we echt nodig
Hoewel de export veel informatie bevat, hebben we niet alles nodig voor ons kennissysteem. Het belangrijkste onderdeel zijn de teksten van de gesprekken. Deze teksten bevatten de werkelijke inhoud: Ideeën, analyses, vragen en antwoorden. Het is precies deze inhoud die we later willen doorzoeken.
Sommige metadata kunnen ook nuttig zijn. Dit omvat bijvoorbeeld
- Tijdstempel
- Titel gesprek
- Mogelijk interne identificatienummers
Deze informatie helpt ons om de inhoud later beter te sorteren of om een gesprek te categoriseren in termen van tijd. Andere onderdelen van de export zijn minder relevant voor ons project. Hieronder vallen bijvoorbeeld bepaalde technische metadata die alleen interessant zijn voor de interne werking van het platform.
Om onze kennisbank op te bouwen, concentreren we ons daarom bewust op de essentie: de teksten van de gesprekken en wat contextuele basisinformatie. Hoe duidelijker we deze gegevens structureren, hoe beter onze AI er later mee kan werken.
Eerste beoordeling van de gegevens
Voordat we aan de slag gaan met geautomatiseerde scripts, is het de moeite waard om even naar de gegevens zelf te kijken. Open hiervoor een van de JSON-bestanden met een eenvoudige teksteditor of een programma dat JSON-bestanden goed kan weergeven. Veel code editors zoals Visual Studio Code zijn hier zeer geschikt voor, maar eenvoudige teksteditors werken ook.
Als je het bestand voor het eerst bekijkt, zie je waarschijnlijk een relatief grote hoeveelheid gestructureerde gegevens. JSON-bestanden bestaan uit geneste elementen - dat wil zeggen gegevensvelden die op hun beurt weer andere velden bevatten. Dit kan in het begin een beetje ingewikkeld lijken, maar met een beetje geduld zul je de basisstructuur snel herkennen. Je zult bijvoorbeeld zien dat een conversatie uit meerdere berichten bestaat en dat elk bericht een apart object vertegenwoordigt. De eigenlijke tekst staat meestal in een duidelijk herkenbaar veld.
Deze eerste screening heeft een belangrijk doel: het helpt je te begrijpen hoe je gegevens gestructureerd zijn. Want in het volgende hoofdstuk gaan we juist deze structuur gebruiken om de gesprekken automatisch uit te lezen en klaar te maken voor ons kennissysteem. Met andere woorden: We transformeren nu stap voor stap een technisch gegevensarchief in een bruikbare kennisbank. En dit is precies waar we in het volgende hoofdstuk mee beginnen. Het doel daar is om de chatgegevens te extraheren en ze zo voor te bereiden dat ze later efficiënt doorzocht kunnen worden.
Gegevens voorbereiden: Van gesprekken naar analyseerbare teksten
Na het uitpakken van de ChatGPT data-export in het vorige hoofdstuk en een eerste overzicht van de structuur, begint nu het eigenlijke technische deel van ons project. Hoewel de geëxporteerde gegevens compleet zijn, zijn ze in deze vorm nog niet optimaal geschikt voor ons kennissysteem.
De reden is simpel: chatgeschiedenissen zijn meestal lang, bevatten veel onderwerpen en zijn opgeslagen in een structuur die leesbaar is voor mensen, maar niet ideaal voor semantische zoekopdrachten of vectordatabases. Om onze AI in staat te stellen later relevante inhoud te vinden, moeten we deze ruwe gegevens eerst verwerken. Dit betekent in wezen drie dingen:
- De gesprekken uit de JSON-bestanden halen
- de teksten zinvol structureren
- verdeel de inhoud in kleinere secties
Dit proces is een volkomen normale stap in moderne AI-systemen en wordt vaak preprocessing genoemd.
Waarom ruwe gegevens niet direct geschikt zijn
Als je naar een van de JSON-bestanden kijkt, zul je zien dat een enkele chat vaak uit veel berichten bestaat. Een typische dialoog kan er bijvoorbeeld zo uitzien:
- Vraag
- Antwoord
- Aanvraag
- nieuwe verklaring
- verder detail
- Samenvatting
Sommige gesprekken kunnen honderden of zelfs duizenden woorden bevatten. Dit is geen probleem voor mensen. We lezen een dialoog gewoon van boven naar beneden.
Dit werkt echter minder goed voor een AI-zoekopdracht. De reden hiervoor is dat een enkele chat vaak meerdere onderwerpen bevat. Als we later een semantische zoekopdracht uitvoeren, moet het systeem tekstpassages zo precies mogelijk vinden - niet hele conversaties met veel verschillende inhoud.
Daarom worden grote teksten opgedeeld in kleinere delen. Deze delen worden chunks genoemd. Een chunk is gewoon een klein blok tekst dat een samenhangende gedachte bevat. Deze methode verbetert later de kwaliteit van het zoeken aanzienlijk.
Chatgeschiedenis opvragen
De eerste praktische stap is het lezen van de inhoud van de JSON-bestanden. Hiervoor gebruiken we een klein Python-script. Python is bijzonder geschikt voor dergelijke taken omdat het veel bibliotheken bevat voor gegevensverwerking en AI.
Maak eerst een nieuw bestand, bijvoorbeeld:
extract_chats.py
Vervolgens voegen we een eenvoudig script toe dat de chatgegevens laadt.
import json
with open("conversations.json", "r", encoding="utf-8") as f:
data = json.load(f)
print("Anzahl der Gespräche:", len(data))
Als je dit script uitvoert, zou je moeten zien hoeveel gesprekken je export bevat. Laten we nu de eigenlijke teksten extraheren.
texts = []
for conversation in data:
if "mapping" in conversation:
for node in conversation["mapping"].values():
message = node.get("message")
if message:
content = message.get("content")
if content and "parts" in content:
text = " ".join(content["parts"])
texts.append(text)
print("Extrahierte Textabschnitte:", len(texts))
Dit script doorloopt de JSON-structuur en verzamelt alle tekstdelen uit de gesprekken. Dit betekent dat we het belangrijkste deel al hebben voltooid: we hebben de inhoud uit het technische exportformaat gehaald.
Tekstfragmenten maken
Nu komt de volgende belangrijke stap: chunking. In plaats van complete gesprekken op te slaan, verdelen we de teksten in kleinere delen.
Een typische grootte voor zulke tekstdelen is tussen de 300 en 800 woorden of ongeveer 500 tokens. Het volgende is een eenvoudig voorbeeld van hoe je teksten in chunks kunt verdelen.
def split_text(text, chunk_size=500):
words = text.split()
chunks = []
for i in range(0, len(words), chunk_size):
chunk = " ".join(words[i:i+chunk_size])
chunks.append(chunk)
return chunks
Nu kunnen we deze functie toepassen op onze teksten.
all_chunks = []
for text in texts:
chunks = split_text(text)
all_chunks.extend(chunks)
print("Gesamtzahl der Chunks:", len(all_chunks))
We hebben nu veel kleinere tekstblokken gemaakt van onze chatgeschiedenis. Deze tekstblokken zijn ideaal om later in een vectordatabase te doorzoeken.
Metagegevens toevoegen
Naast de eigenlijke tekst kan extra informatie erg nuttig zijn. Deze zogenaamde metadata helpen ons om de inhoud later beter te sorteren of te filteren. Typische metadata kunnen zijn
- Datum van het gesprek
- Titel gesprek
- Bron (ChatGPT Export)
- ID van de oproep
We kunnen deze informatie samen met de tekst opslaan, bijvoorbeeld op deze manier:
documents = []
for conversation in data:
title = conversation.get("title", "Unbekannt")
if "mapping" in conversation:
for node in conversation["mapping"].values():
message = node.get("message")
if message:
content = message.get("content")
if content and "parts" in content:
text = " ".join(content["parts"])
chunks = split_text(text)
for chunk in chunks:
documents.append({
"text": chunk,
"title": title
})
Dit heeft onze gegevens al een veel betere structuur gegeven. In plaats van een onoverzichtelijk chatarchief hebben we nu een verzameling van veel kleine tekstsecties, die elk zijn voorzien van contextuele informatie.
Het is precies deze structuur die cruciaal zal zijn in de volgende stap. Want nu kunnen we beginnen met het genereren van inbeddingen uit deze teksten - dat wil zeggen wiskundige representaties van de inhoud die later zullen worden opgeslagen in onze vectordatabase. En dit is precies waar het volgende hoofdstuk over gaat.
Inbeddingen maken
In het vorige hoofdstuk hebben we onze ChatGPT-gegevens al in een bruikbare vorm gegoten. We hebben de conversaties uit de JSON-bestanden gehaald, de teksten opgeschoond en ze verdeeld in kleinere delen - zogenaamde chunks.
Er ontbreekt echter nog een cruciale stap voordat onze AI echt op een zinvolle manier naar inhoud kan zoeken. De teksten moeten worden vertaald in een vorm die machines kunnen vergelijken. Dit is waar embeddings om de hoek komen kijken.
Embeddings zijn wiskundige representaties van teksten. Ze stellen computers in staat om de betekenis van teksten te vergelijken. Twee teksten met een vergelijkbare inhoud krijgen vergelijkbare vectoren - zelfs als ze verschillende woorden gebruiken. Dit is precies de eigenschap die we nodig hebben voor ons kennissysteem. Onze AI moet immers niet alleen zoeken naar identieke woorden, maar ook naar teksten met overeenkomende inhoud.
Wat inbeddingen zijn
Een inbedding is eigenlijk een lijst getallen. Deze getallen beschrijven de betekenis van een tekst in een wiskundige ruimte. Elke tekst wordt omgezet in een zogenaamde vector. Zo'n vector kan er bijvoorbeeld zo uitzien:
[0.134, -0.876, 0.442, 0.921, -0.223, ...]
Een enkele vector kan honderden of zelfs duizenden getallen bevatten. Deze getallen zijn natuurlijk niet direct begrijpelijk voor mensen. Voor machines zijn ze echter ideaal om overeenkomsten tussen teksten te berekenen. Als twee teksten een vergelijkbare inhoud hebben, liggen hun vectoren dichter bij elkaar in de wiskundige ruimte. Een voorbeeld:
- Tekst A„Hoe kan ik mijn ChatGPT-gegevens exporteren?“
- Tekst B: „Hoe download ik mijn ChatGPT-gesprekken?“
Hoewel de formulering verschilt, beschrijven beide teksten in principe hetzelfde onderwerp. Een goed inbeddingsmodel herkent deze gelijkenis. De twee teksten krijgen daarom vergelijkbare vectoren. We zullen later precies dit principe gebruiken voor onze semantische zoekopdracht.
Modellen insluiten met Ollama
We hebben een speciaal model nodig om embeddings te maken. Gelukkig hoeven we hiervoor geen externe clouddiensten te gebruiken. Veel inbeddingsmodellen kunnen nu lokaal worden gebruikt - en dit is waar Ollama om de hoek komt kijken.
Aangezien Ollama al op uw systeem draait, kunnen we daar een install-model in opnemen. Een heel goed model is bijvoorbeeld:
nomic-embed-text
Je kunt het temmen met het volgende commando 1TP12:
ollama pull nomic-embed-text
Andere populaire modellen zijn
- mxbai-invoegtoepassing-groot
- bge-groot
- all-minilm
Voor onze doeleinden nomische-tekst is een heel goed uitgangspunt. Dit model genereert embeddings van hoge kwaliteit en draait lokaal zonder problemen.
Lokaal inbeddingen maken
Nu willen we ons Python-script uitbreiden zodat het embeddings kan genereren. Eerst 1TP12We maken een bibliotheek waarmee Python kan communiceren met Ollama.
pip install ollama
Nu kunnen we het inbeddingsmodel rechtstreeks vanuit Python benaderen. Het volgende is een eenvoudig voorbeeld:
import ollama
response = ollama.embeddings(
model="nomic-embed-text",
prompt="Wie exportiere ich meine ChatGPT-Daten?"
)
print(len(response["embedding"]))
Als alles gelukt is, krijg je een vector met enkele honderden getallen.
Laten we dit nu toepassen op onze chatchunks.
embeddings = []
for doc in documents:
text = doc["text"]
result = ollama.embeddings(
model="nomic-embed-text",
prompt=text
)
vector = result["embedding"]
embeddings.append({
"text": text,
"embedding": vector,
"title": doc["title"]
})
Hiermee maken we een vector voor elke tekstsectie. Deze vectoren worden later opgeslagen in onze database.
Waarom deze stap cruciaal is
Inbeddingen vormen het hart van moderne kennissystemen. Zonder inbeddingen zouden we teksten alleen kunnen doorzoeken met klassieke trefwoordzoekopdrachten. Dit zou betekenen dat het systeem alleen inhoud zou vinden die precies dezelfde woorden bevat. Maar taal werkt zelden zo eenvoudig. Een gebruiker zou bijvoorbeeld kunnen vragen:
„Hoe heb ik mijn ChatGPT-gegevens verwerkt?“
Het oorspronkelijke gesprek zou echter geformuleerd kunnen worden als:
„Hoe kan ik mijn ChatGPT-gegevensexport analyseren?“
Een eenvoudige zoekopdracht herkent dit verband misschien niet. Het is anders met inbeddingen. Omdat beide teksten dezelfde betekenis hebben, liggen hun vectoren dicht bij elkaar in de wiskundige ruimte. Onze database kan daarom overeenkomende inhoud vinden, zelfs als de bewoordingen verschillen. Het is precies dit vermogen dat semantisch zoeken zo krachtig maakt. Het stelt een AI in staat om niet alleen naar woorden te zoeken, maar ook naar betekenis.
En dit is precies waarom embeddings de centrale bouwsteen van ons systeem zijn. In het volgende hoofdstuk bouwen we hierop voort en installieren we onze vectordatabase. Daarin slaan we de gegenereerde vectoren op - en leggen zo de basis voor onze persoonlijke kennis-AI.
Qdrant installoevoegen en configureren
Nadat we in het vorige hoofdstuk de embeddings voor onze chatgegevens hebben gemaakt, hebben we nu een verzameling tekstsecties en bijbehorende vectoren. Deze vectoren beschrijven de betekenis van de teksten wiskundig en vormen zo de basis voor een semantische zoekopdracht. Deze gegevens zijn momenteel echter alleen beschikbaar in het werkgeheugen van ons script of in eenvoudige lijsten. We hebben een gespecialiseerd geheugen nodig zodat onze AI er later efficiënt toegang toe kan krijgen.
Dit is precies waar een vector database om de hoek komt kijken. Een vector database is geoptimaliseerd om grote hoeveelheden van dergelijke embeddings op te slaan en snel te zoeken naar gelijkaardige vectoren. Voor ons project gebruiken we Qdrant, een moderne open-source database die speciaal is ontwikkeld voor AI-toepassingen.
In dit hoofdstuk 1TP12 installeren we Qdrant, starten we de server en bereiden we de database voor zodat we later gemakkelijk onze chatgegevens kunnen importeren.
Wat Qdrant is
Qdrant is een gespecialiseerde database voor zogenaamde vectorzoekopdrachten. Terwijl traditionele databases informatie opslaan in tabellen - zoals namen, nummers of teksten - werkt een vector database met wiskundige representaties van gegevens.
Dit betekent dat Qdrant niet alleen tekst opslaat, maar ook de bijbehorende embeddings. Het grote voordeel zit in het zoeken. Als er later een vraag wordt gesteld, zet ons systeem deze vraag ook om in een vector. Qdrant kan vervolgens razendsnel berekenen welke opgeslagen teksten het meest lijken op deze vector. Dit maakt het mogelijk om bijvoorbeeld uit te zoeken:
- welke chatpassages thematisch overeenkomen met de vraag
- welke eerdere gesprekken soortgelijke inhoud bevatten
- welke ideeën relevant kunnen zijn in uw archief
Dit is precies de reden waarom Qdrant tegenwoordig in veel moderne AI-systemen wordt gebruikt - van documentzoekopdrachten tot complexe kennisassistenten. Nog een voordeel: Qdrant is open source, snel 1TP12ised en draait probleemloos op een normale lokale machine.
Installatie van Qdrant
De eenvoudigste manier om Qdrant te installieren is via Docker. Als Docker beschikbaar is op je machine, kan je de server starten met één enkel commando. Hier kan je Docker downloaden, als je het nog niet op je computer hebt geïnstalleerd installiert.
docker run -p 6333:6333 qdrant/qdrant
Dit commando start de Qdrant server en opent de standaardpoort 6333. Onze scripts kunnen later via deze poort met de database communiceren.
Als je Docker niet wilt gebruiken, zijn er ook andere manieren om Qdrant te installiere, bijvoorbeeld via een lokale binary of package manager. In veel praktische projecten heeft Docker echter bewezen de eenvoudigste en meest stabiele optie te zijn.
Nadat de server gestart is, draait Qdrant op de achtergrond en wacht op aanvragen. Je kan nu testen of de server toegankelijk is. Open hiervoor het volgende adres in je browser:
http://localhost:6333
Als alles gelukt is, zou er een eenvoudig statusbericht moeten verschijnen. De server is nu klaar voor de volgende stappen.
Eerste stappen met Qdrant
Voor we onze chatgegevens kunnen importeren, moeten we een zogenaamde collectie aanmaken. In Qdrant is een collectie vergelijkbaar met een tabel in een klassieke database. Ze bevat onze vectoren en de overeenkomstige gegevens.
Eerst installiere we de Python-bibliotheek voor Qdrant:
pip install qdrant-client
Nu kunnen we een verbinding maken met de database in ons Python-script.
from qdrant_client import QdrantClient
client = QdrantClient("localhost", port=6333)
Als deze code wordt uitgevoerd zonder foutmelding, is de verbinding geslaagd. Nu maken we een verzameling voor onze chatgegevens.
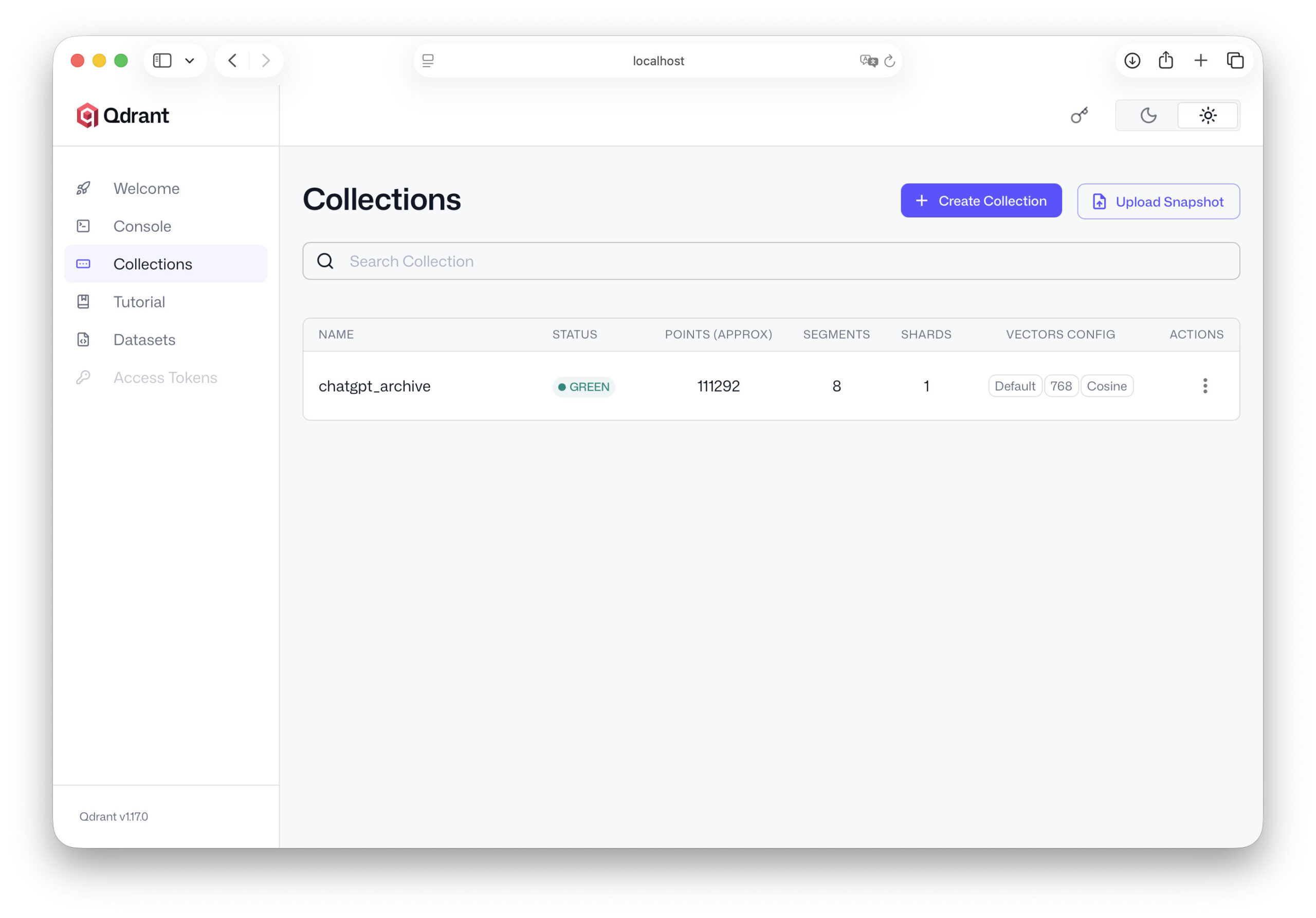
from qdrant_client.models import VectorParams, Distance client.recreate_collection( collection_name="chatgpt_archive", vectors_config=VectorParams(size=768, distance=Distance.COSINE), )
De belangrijkste parameters hier zijn
- collectie_naam - de naam van onze database
- maat - de lengte van de inbeddingsvectoren
- afstand - de methode voor het berekenen van gelijkenis
De vectorgrootte hangt af van het gebruikte inbeddingsmodel. Veel modellen werken met vectoren van 768 of 1024 dimensies. De cosinusafstandsfunctie is een van de meest gebruikte methoden om overeenkomsten tussen teksten te berekenen. Dit betekent dat onze database al klaar is voor gebruik.
Gegevensstructuur plan
Voordat we onze gegevens importeren, is het de moeite waard om even te kijken naar de structuur die we willen opslaan. Elk item in onze vectorgegevensbank zal uit verschillende componenten bestaan:
- ID - een unieke identificatiecode
- inbedden - de vector van de tekst
- Lading - Extra informatie over de tekst
De payload kan bijvoorbeeld het volgende bevatten
- de oorspronkelijke tekst
- de titel van het gesprek
- de datum
- andere metagegevens
Een voorbeeld van een gegevensrecord kan er als volgt uitzien:
{
"id": 1,
"vector": [0.123, -0.452, 0.889, ...],
"payload": {
"text": "Wie kann ich meinen ChatGPT-Datenexport analysieren?",
"title": "Datenanalyse"
}
}
Deze structuur heeft een groot voordeel. De vectoren worden gebruikt voor het semantisch zoeken, terwijl de payload alle informatie bevat die we later willen weergeven of analyseren. Dit betekent dat ons systeem flexibel blijft en later gemakkelijk kan worden uitgebreid.
Dit betekent dat het belangrijkste deel van de infrastructuur al is voorbereid. Onze Qdrant server draait, de database is opgezet en we weten welke structuur onze gegevens zullen hebben. In het volgende hoofdstuk beginnen we met de cruciale stap: we importeren onze ChatGPT data in de database en transformeren ons archief van conversaties in een echte, doorzoekbare kennisbank.
ChatGPT-gegevens importeren in Qdrant
Nu we in het vorige hoofdstuk Qdrant installiert en een collectie hebben aangemaakt, is de technische basis voor onze kennisdatabank gelegd. Onze embeddings bestaan al - we hebben ze aangemaakt vanuit de ChatGPT data - en Qdrant draait als databaseserver op onze machine.
Nu komt de cruciale stap: we laden onze gegevens in de database. We slaan niet alleen de vectoren zelf op, maar ook de bijbehorende teksten en metadata. Dankzij deze combinatie kan onze AI later relevante inhoud vinden en gebruiken in antwoorden. In dit hoofdstuk bouwen we de eigenlijke kennisbank van ons systeem.
Embeddings opslaan
Eerst moeten we onze gegenereerde inbeddingen overbrengen naar de database. Elke invoer in Qdrant bestaat uit drie componenten:
- een ID
- een vector (inbedding)
- een payload met aanvullende gegevens
In ons geval bevat de payload bijvoorbeeld
- het tekstgedeelte
- de titel van het gesprek
- Mogelijk verdere metagegevens
In Python kunnen we deze structuur relatief eenvoudig maken. Een voorbeeld:
points = []
for idx, item in enumerate(embeddings):
points.append({
"id": idx,
"vector": item["embedding"],
"payload": {
"text": item["text"],
"title": item["title"]
}
})
Dit genereert een lijst met gegevenspunten die we vervolgens kunnen opslaan in Qdrant. Elk datapunt bevat dus een tekstgedeelte, de bijbehorende vector en extra contextinformatie. Deze structuur vormt later de basis van onze semantische zoekopdracht.
Importeer script maken
Nu verbinden we ons Python-script met Qdrant en sturen we de gegevens door. Hiervoor gebruiken we de Qdrant Python client, die we in het vorige hoofdstuk 1TP12 hebben geanalyseerd. De import kan er bijvoorbeeld zo uitzien:
from qdrant_client import QdrantClient
from qdrant_client.models import PointStruct
client = QdrantClient("localhost", port=6333)
points = []
for idx, item in enumerate(embeddings):
point = PointStruct(
id=idx,
vector=item["embedding"],
payload={
"text": item["text"],
"title": item["title"]
}
)
points.append(point)
client.upsert(
collection_name="chatgpt_archive",
points=points
)
print("Import abgeschlossen:", len(points), "Datensätze gespeichert.")
Het upsert commando zorgt ervoor dat de gegevens worden opgeslagen in de collectie. Als een ID al bestaat, wordt de invoer bijgewerkt. Anders wordt er een nieuwe gegevensrecord aangemaakt. Afhankelijk van de grootte van je ChatGPT export, kan deze import enkele seconden of minuten duren. Dit is volkomen normaal voor grotere gegevenssets - zoals enkele duizenden tekstsecties.
Testdatabase
Zodra het importeren is voltooid, moeten we controleren of onze gegevens correct zijn opgeslagen. De eenvoudigste test is het uitvoeren van een vectorzoekopdracht. Om dit te doen, maken we eerst een inbedding voor een testvraag.
query = "Wie kann ich ChatGPT-Daten analysieren?" query_vector = ollama.embeddings( model="nomic-embed-text", prompt=query )["embedding"]
Nu kunnen we in Qdrant zoeken naar gelijkaardige vectoren.
search_result = client.search( collection_name="chatgpt_archive", query_vector=query_vector, limit=3 )
Dit commando geeft de drie meest gelijkende tekstsecties uit onze database. We kunnen ze bijvoorbeeld zo uitvoeren:
for result in search_result:
print(result.payload["text"])
print("---")
Als alles heeft gewerkt, verschijnen er nu chatsecties uit je archief die overeenkomen met de zoekopdracht. Nu weten we het: Onze database werkt.
Eerste functioneringsgesprek
Dit moment is een van de spannendste aspecten van het hele project. Voor het eerst wordt duidelijk dat ons chatarchief echt als kennisbron kan worden gebruikt. Je kunt nu verschillende zoekopdrachten uitproberen. Bijvoorbeeld:
- „AI-artikel“
- „RAG-systeem“
- „ChatGPT-gegevens exporteren“.“
- „Strategie idee“
Afhankelijk van de inhoud van je chatgeschiedenis zal Qdrant geschikte tekstpassages vinden. Soms zal je verrast zijn welke inhoud er terug opduikt. Gesprekken die je al lang vergeten was, kunnen plots weer relevant worden. Dit laat heel duidelijk zien waarom zo'n aanpak zo interessant is. Je oude AI gesprekken zijn niet langer alleen een archief. Ze worden een doorzoekbare kennisbank.
We hebben dus een belangrijke mijlpaal bereikt. Onze ChatGPT-gegevens zijn nu volledig opgeslagen in de vectordatabase en kunnen semantisch worden doorzocht. In het volgende hoofdstuk gaan we nog een stap verder: we verbinden onze kennisdatabase met de AI zelf. Hierdoor kan het taalmodel in de toekomst toegang krijgen tot deze gegevens en ze direct verwerken in reacties.
AI verbinden met de kennisdatabase
Tot op dit punt hebben we al een groot deel van de infrastructuur gebouwd. Onze ChatGPT-gegevens werden geëxtraheerd uit de export, opgesplitst in kleinere tekstdelen, ingesloten en uiteindelijk opgeslagen in de Qdrant vector database.
Onze AI werkt echter nog niet met deze gegevens. Hoewel we een vectorzoekopdracht kunnen uitvoeren met Python en geschikte tekstpassages kunnen vinden, is de AI hier zelf nog niet van op de hoogte. Als we het een vraag stellen, gebruikt het nog steeds alleen zijn algemene taalkennis.
De volgende stap is dan ook om deze twee werelden met elkaar te verbinden. We bouwen nu aan een proces waarin de AI eerst relevante inhoud ontvangt uit de kennisdatabase en deze vervolgens verwerkt in zijn antwoord. Dit is precies de kern van een RAG-systeem.
Onderzoeksproces
Het proces van een vraag verandert enigszins dankzij ons kennissysteem. Tot nu toe verliep een gesprek met een AI meestal als volgt:
- Je stelt een vraag →
- De AI verwerkt de vraag →
- genereert de AI een antwoord.
Een kennisdatabank is een extra stap. Het nieuwe proces ziet er als volgt uit:
- Je stelt een vraag →
- wordt de vraag omgezet in een inbedding →
- de vectordatabase zoekt naar gelijksoortige teksten →
- Deze teksten worden overgebracht naar de AI als context →
formuleert de AI een antwoord. Dit betekent dat de AI niet langer alleen met zijn getrainde kennis werkt, maar ook met je eigen gegevens. Deze context maakt antwoorden vaak veel preciezer en persoonlijker.
Ophaalstap
Het eerste deel van dit proces staat bekend als retrieval. Retrieval betekent gewoon „ophalen“. In deze stap zoekt ons systeem in de database naar inhoud die overeenkomt met het onderwerp van de vraag. Eerst maken we een andere inbedding voor de huidige vraag.
query = "Welche Ideen hatte ich zur Nutzung meines ChatGPT-Datenexports?" query_vector = ollama.embeddings( model="nomic-embed-text", prompt=query )["embedding"]
Deze inbedding beschrijft de betekenis van de vraag in wiskundige vorm. Qdrant kan nu zoeken naar gelijkaardige vectoren.
results = client.search( collection_name="chatgpt_archive", query_vector=query_vector, limit=5 )
De database geeft nu de vijf tekstpassages die het beste overeenkomen met de vraag. Deze tekstpassages vormen de context voor de AI. We verzamelen ze in een lijst.
context_texts = [] for r in results: context_texts.append(r.payload["text"])
We hebben nu een verzameling relevante inhoud uit ons chatarchief.
Context overbrengen naar Ollama
Nu komt de beslissende stap. We geven deze context samen met de oorspronkelijke vraag door aan ons taalmodel. Het model kan deze informatie nu gebruiken om een antwoord te formuleren.
Eerst maken we een zogenaamde prompt. Een prompt is simpelweg de tekst die we naar de AI sturen.
context = "\n\n".join(context_texts)
prompt = f"""
Du bist ein KI-Assistent, der mit meinem persönlichen Wissensarchiv arbeitet.
Nutze die folgenden Textausschnitte als Kontext:
{context}
Beantworte nun diese Frage:
{query}
"""
Nu sturen we deze prompt naar ons taalmodel in Ollama.
response = ollama.chat(
model="llama3",
messages=[
{"role": "user", "content": prompt}
]
)
print(response["message"]["content"])
De AI ontvangt nu zowel de vraag als de relevante tekstpassages uit onze database. Hierdoor kan hij antwoorden genereren op basis van onze eigen gegevens.
Antwoordgeneratie
De laatste stap is het genereren van antwoorden. Het taalmodel combineert nu twee kennisbronnen:
zijn eigen getrainde kennis
de context van onze kennisdatabase
Deze combinatie is bijzonder krachtig. Het model kan algemene relaties verklaren en tegelijkertijd specifieke inhoud uit ons archief opnemen. Een voorbeeld: Als je vraagt:
„Welke ideeën had ik om mijn ChatGPT-gegevensexport te gebruiken?“
De AI kan nu toegang krijgen tot eerdere gesprekken en er een gestructureerde samenvatting van maken. Het kan bijvoorbeeld antwoorden:
- Je had het over het opbouwen van een persoonlijk kennisarchief
- Je wilde een lokale AI ontwikkelen met een RAG-systeem
- Je hebt het idee ontwikkeld voor een serie artikelen
Zonder de opvraagstap zou de AI deze informatie helemaal niet kennen. Met ons systeem wordt je chatarchief een echte bron van kennis. Hiermee is het belangrijkste deel van ons systeem voltooid. We hebben nu:
- een lokale AI via Ollama
- een vector database met onze chatgegevens
- een semantische zoekopdracht
- een RAG-workflow
In het volgende hoofdstuk gaan we dit systeem in de praktijk testen en kijken hoe goed onze persoonlijke kennis-AI eigenlijk werkt.
Eerst vragen met je persoonlijke kennis AI
Nu we in het vorige hoofdstuk de verbinding tussen onze AI en de kennisdatabase tot stand hebben gebracht, is het systeem technisch compleet. Onze ChatGPT-gegevens staan in de vectordatabase, de AI kan relevante inhoud ophalen en het hele proces van een RAG-systeem werkt.
Nu komt het spannendste deel van het project: de eerste echte zoekopdrachten. Want nu pas kunnen we zien of ons systeem echt doet wat we hoopten dat het zou doen - namelijk eerdere gesprekken vinden, inhoud analyseren en zinvolle antwoorden genereren. In dit hoofdstuk testen we onze kennis-AI, bekijken we typische use cases en kijken we naar mogelijke optimalisaties.
Voorbeeldvragen
Laten we beginnen met een aantal eenvoudige vragen. Een goede strategie is om te beginnen met het stellen van vragen waarvan je weet dat ze in je chatarchief staan. Bijvoorbeeld:
„Welke ideeën had ik om mijn ChatGPT-gegevensexport te gebruiken?“
„Wat heb ik geschreven over RAG-systemen?“
„Welke strategieën heb ik besproken om AI te gebruiken?“
Deze vragen bevatten opzettelijk open formuleringen. Het doel is niet om een specifieke tekst te vinden, maar om thematisch geschikte inhoud te ontdekken. Als je zo'n vraag aan je systeem stelt, vindt het proces dat we in het vorige hoofdstuk hebben beschreven op de achtergrond plaats:
- De vraag wordt omgezet in een inbedding.
- De vector database zoekt naar gelijksoortige tekstsecties.
- Deze tekstpassages worden overgebracht naar de AI als context.
- De AI genereert een antwoord op basis van deze context.
Het resultaat kan verrassend zijn. Gesprekken die je al lang vergeten was, komen vaak weer boven. Oude ideeën verschijnen plotseling weer op het scherm - soms zelfs in een compleet nieuwe context.
Dat is precies de kracht van deze aanpak. Je chatarchief wordt een doorzoekbare bron van kennis.
Kwaliteit van de antwoorden
Als je een paar vragen uitprobeert, zul je merken dat de kwaliteit van de antwoorden kan variëren. Dit is volkomen normaal. De kwaliteit van zo'n systeem hangt af van verschillende factoren. Een belangrijke factor is de grootte van de tekstdelen. Als de stukken te groot zijn, kunnen ze meerdere onderwerpen bevatten. Dit maakt het zoeken minder nauwkeurig.
Als de chunks echter te klein zijn, ontbreekt soms de benodigde context. Een andere factor is het inbeddingsmodel. Verschillende modellen herkennen betekeniscontexten verschillend. Sommige zijn bijzonder geschikt voor technische teksten, andere voor algemene taal.
Het aantal opgehaalde resultaten speelt ook een rol. Als er bijvoorbeeld maar twee tekstpassages worden opgehaald, kan er belangrijke informatie ontbreken. Als er daarentegen te veel teksten worden geladen, kan de AI moeite hebben om de relevante context te herkennen.
Deze parameters kunnen later eenvoudig worden aangepast. Het belangrijkste is om eerst een goed werkend basissysteem te hebben.
Typische problemen
Zoals bij elk technisch systeem kunnen ook hier enkele moeilijkheden optreden. Een veel voorkomend probleem is dat de database teksten vindt die slechts gedeeltelijk relevant zijn. Dit komt omdat semantisch zoeken altijd met waarschijnlijkheden werkt.
Een ander probleem kan ontstaan als teksten te veel gefragmenteerd zijn. Als een gedachte verspreid is over verschillende brokken, kan de AI moeite hebben om de context te herkennen.
De prompt speelt ook een rol. Als de prompt onduidelijk is, maakt de AI mogelijk geen optimaal gebruik van de context. Een voorbeeld van een betere prompt zou er zo uit kunnen zien:
Gebruik de volgende tekstfragmenten uit mijn kennisarchief,
om de vraag zo precies mogelijk te beantwoorden.
Als er relevante inhoud beschikbaar is, vat deze dan samen.
Zulke kleine aanpassingen kunnen de kwaliteit van de antwoorden aanzienlijk verbeteren.
Fijnafstemming
Zodra het systeem in principe werkt, begint het interessantste deel: de fijnafstelling. Hier kun je experimenteren en je kennissysteem stap voor stap verbeteren. Enkele typische optimalisaties zijn
- De brokgrootte aanpassen
Soms leveren kleinere stukken tekst betere resultaten op. In andere gevallen is meer context nuttig. - Gebruik van een ander inbeddingsmodel
Het wijzigen van het model kan de kwaliteit van de semantische zoekopdracht aanzienlijk verbeteren. - Meer context voor AI
Je kunt meer resultaten uit de database ophalen, bijvoorbeeld tien tekstpassages in plaats van vijf. - Metagegevens gebruiken
Als je extra informatie opslaat - zoals de datum of de titel van de oproep - kun je de zoekopdracht later nauwkeuriger filteren.
Deze aanpassingen maken deel uit van elk echt RAG-systeem. Er is zelden een perfecte instelling voor alle situaties. Maar dat is precies de aantrekkingskracht van dergelijke systemen: ze kunnen voortdurend worden verbeterd.
Met dit hoofdstuk hebben we de eerste volledige test van ons systeem uitgevoerd. We hebben gezien dat onze AI voor persoonlijke kennis inderdaad in staat is om oude gesprekken te doorzoeken en relevante inhoud op te halen.
Dit betekent dat de kern van ons project al is bereikt. Maar het systeem kan nog aanzienlijk worden uitgebreid. In het volgende hoofdstuk bekijken we daarom hoe je stap voor stap extra gegevensbronnen kunt integreren en je persoonlijke kennisarchief kunt uitbreiden.




Uitbreidingen voor je persoonlijke AI-kennissysteem
Je hebt al een werkend systeem gemaakt met de vorige opstelling. Je ChatGPT-gegevens zijn geëxtraheerd, omgezet in embeddings, opgeslagen in Qdrant en uiteindelijk verbonden met een lokale AI. Het resultaat is een kennis-AI die toegang heeft tot eerdere gesprekken.
Maar strikt genomen staan we pas aan het begin. De architectuur die je hebt gebouwd is niet beperkt tot ChatGPT-gegevens. Het werkt met elk soort tekst. Alles wat omgezet kan worden in documenten of tekstbestanden kan onderdeel worden van dit kennissysteem. Dit is waar het echte potentieel van dergelijke systemen ligt.
Wat we in feite hebben gebouwd is een persoonlijke kennismachine. En deze machine kan stap voor stap worden uitgebreid. In dit hoofdstuk kijken we naar de mogelijkheden die hieruit voortvloeien en hoe je je systeem op de lange termijn kunt uitbreiden.
Extra gegevensbronnen integreren
De meest voor de hand liggende volgende stap is om meer inhoud aan je kennisbank toe te voegen. ChatGPT conversaties zijn een goed begin, maar ze vertegenwoordigen meestal maar een deel van je eigen kennis. Veel informatie is beschikbaar in andere formaten. Bijvoorbeeld:
- eigen artikelen
- Opmerkingen
- PDF-documenten
- Onderzoeksdocumenten
- E-Boeken
- Protocollen of lijsten met ideeën
Al deze inhoud kan op dezelfde manier worden verwerkt als onze chatgegevens. Het proces blijft identiek:
- Tekst uitpakken
- Tekst opsplitsen in stukken
- Inbeddingen maken
- Gegevens opslaan in Qdrant
Een voorbeeld: Als je veel van je eigen artikelen hebt geschreven, kun je deze teksten importeren in je kennisdatabase. De AI kan ze later openen en correlaties herkennen. Je kunt bijvoorbeeld vragen:
„Welke artikelen heb ik over AI geschreven?“
of
„Welke argumenten heb ik in het verleden over dit onderwerp ontwikkeld?“
De AI doorzoekt vervolgens je artikelarchief en gebruikt de gevonden inhoud als context. Op deze manier groeit je systeem stap voor stap uit tot een uitgebreid kennisarchief.
Verschillende kennisdatabases
Als de hoeveelheid gegevens toeneemt, kan het nuttig zijn om verschillende gebieden te scheiden. Qdrant laat je toe om meerdere collecties aan te maken. Elke collectie kan zijn eigen kennisbank vertegenwoordigen. Een mogelijk systeem zou er bijvoorbeeld zo uit kunnen zien:
- Collectie 1ChatGPT-gesprekken
- Collectie 2Archief van het artikel
- Collectie 3persoonlijke aantekeningen
- Collectie 4Technische documentatie
Deze scheiding heeft verschillende voordelen. Ten eerste blijft de structuur duidelijk. Je weet altijd waar bepaalde inhoud is opgeslagen. Ten tweede kunnen zoekopdrachten specifieker worden aangestuurd. Sommige vragen moeten misschien alleen in je artikelarchief zoeken, andere in je hele kennissysteem. Een voorbeeld:
- Een onderzoeksvraag kon alleen in het artikelarchief worden doorzocht.
- Een strategische vraag daarentegen zou met alle collecties tegelijk rekening kunnen houden.
Dergelijke structuren maken grotere kennissystemen aanzienlijk efficiënter.
Automatische updates
Een andere nuttige stap is om je systeem regelmatig bij te werken. In het vorige voorbeeld hebben we de gegevensexport van ChatGPT één keer verwerkt. In de praktijk wordt er echter voortdurend nieuwe inhoud gecreëerd.
Nieuwe gesprekken, nieuwe notities, nieuwe documenten - al deze informatie kan ook deel gaan uitmaken van je kennisarchief.
Het is daarom de moeite waard om na te denken over automatische updates. Een eenvoudige oplossing is om regelmatig nieuwe gegevens te importeren. Bijvoorbeeld:
- Verwerk wekelijks nieuwe chatgegevens
- Automatisch nieuwe documenten importeren
- Nieuwe artikelen onmiddellijk toevoegen aan de database
Technisch is dit relatief eenvoudig te implementeren. Een klein script kan regelmatig controleren of er nieuwe bestanden beschikbaar zijn en deze automatisch verwerken. Zo kan je kennissysteem voortdurend groeien. Na verloop van tijd ontstaat er een steeds uitgebreider archief dat je gedachten en projecten documenteert.
Integratie in je eigen applicaties
Tot nu toe is ons systeem gebruikt via eenvoudige Python-scripts. Maar op de lange termijn kan dit systeem ook worden geïntegreerd in je eigen applicaties. Veel ontwikkelaars bouwen bijvoorbeeld kleine webinterfaces waarmee ze hun kennis-AI direct kunnen gebruiken.
In plaats van een script te starten, kun je dan gewoon een vraag in een invoerveld schrijven. Hetzelfde proces draait op de achtergrond:
- Inbedding maken
- Zoeken in database
- Context overbrengen naar de AI
- Antwoord genereren
Het resultaat verschijnt dan direct in de gebruikersinterface. Zo'n toepassing kan heel verschillende vormen aannemen. Bijvoorbeeld:
- een persoonlijk onderzoek AI
- een kennisassistent voor projecten
- een zoekmachine voor ideeën
- een archief voor artikelen en notities
Het wordt vooral spannend als je deze systemen combineert met andere tools. Een redactiesysteem kan bijvoorbeeld automatisch toegang krijgen tot je kennisarchief en eerdere artikelen gebruiken als basis voor onderzoek. Of een notitiesysteem kan nieuwe ideeën automatisch in uw database opnemen.
Met andere woorden, de AI wordt onderdeel van je dagelijkse werkomgeving. Dit maakt duidelijk dat ons kleine project veel verder gaat dan de oorspronkelijke ChatGPT-gegevensexport.
We hebben niet alleen een archief gemaakt. We hebben een architectuur gemaakt die naar behoefte kan worden uitgebreid. En dat is precies waar de echte waarde van dergelijke systemen ligt. Ze zijn niet statisch. Ze groeien met uw kennis mee.
Uitgebreide versie van de pijplijn om te downloaden
Het volgende script is een uitgebreide versie van de pijplijn uit het artikel. Het is robuuster en komt veel dichter bij een productieve oplossing. Drie dingen zijn verbeterd:
- VoortgangsindicatorDe gebruiker kan op elk moment zien hoeveel teksten al zijn verwerkt.
- BatchimportEmbeddings worden in blokken verzameld en weggeschreven naar Qdrant, wat aanzienlijk sneller is dan afzonderlijke invoer.
- Snellere inbeddingspijplijnHet script werkt op een gestructureerde manier met voorbereide chunks en vermindert onnodige oproepen.
Dit script is daarom bijzonder geschikt als de ChatGPT-export groter is - bijvoorbeeld enkele duizenden conversaties. Typisch proces:
- ChatGPT exporteren laden
- Teksten uittreksel
- Tekst opsplitsen in stukken
- Inbeddingen maken
- Batch importeren in Qdrant
- Testvraag uitvoeren
Belangrijke instellingen in het script
Sommige waarden moeten door de gebruiker worden aangepast:
- EXPORT_PFAD
Pfad zu den meist nummerierten Dateien conversations.json aus dem ChatGPT-Export. - COLLECTIE_NAAM
Naam van de vectorgegevensbankverzameling. - EMBED_MODEL
Embedding-Modell von Ollama, z. B. nomic-embed-text oder mxbai-embed-large - ANSWER_MODEL
Sprachmodell für die Testabfrage, z.B. llama, mistral oder gpt:oss - VECTORENGROOTTE
Dimensie van het inbeddingsmodel.
nomische-tekst → 768
mxbai-afbeelding-groot → 1024 - CHUNK_SIZE
Grootte van de tekstsecties.
Meestal 300-600 woorden. - BATCH_SIZE
Hoeveel inbeddingen worden er tegelijkertijd naar Qdrant geschreven.
Typische waarde: 50-200.
Blijf op de hoogte - zonder reclame
Wenn Du über Updates zu diesem Skript oder über neue Downloads informiert bleiben möchtest, kannst Du Dich in meinen monatlichen Newsletter eintragen. Der Newsletter ist bewusst schlank gehalten, komplett werbefrei und erscheint nur einmal im Monat. Darin findest Du eine Auswahl der wichtigsten neuen Artikel, praxisnahe Inhalte rund um KI, Software und Digitalisierung sowie Hinweise auf aktualisierte Skripte oder neue Download-Angebote. Kein Spam, keine täglichen Mails – nur die relevantesten Inhalte in kompakter Form. Wenn Du diese Entwicklungen kontinuierlich verfolgen möchtest, ist der Newsletter die einfachste Möglichkeit, auf dem aktuellen Stand zu bleiben.
Ausblick auf Teil 3: Feinschliff, Analyse und optimale Nutzung der Daten
Im dritten Teil der Serie gehen wir einen Schritt weiter und schauen uns an, was sich konkret aus der aufgebauten Wissensdatenbank herausholen lässt. Nachdem die ChatGPT-Daten nun in Qdrant gespeichert sind, steht die eigentliche Nutzung im Mittelpunkt. Wir werfen einen Blick auf die Qdrant-Weboberfläche, analysieren die gespeicherten Daten und prüfen, wie gut die semantische Suche bereits funktioniert. Darüber hinaus geht es um wichtige Feinjustierungen: Wie sollte das Chunking je nach Anwendungsfall gewählt werden? Wie lässt sich der Kontext optimal an ein lokales Sprachmodell übergeben? Und wie kann man die Qualität der Antworten gezielt verbessern? Der dritte Teil richtet sich an alle, die aus dem System mehr herausholen und es bewusst weiterentwickeln möchten.



Veelgestelde vragen
- Wat is het nut van het integreren van mijn ChatGPT-gegevensexport in mijn eigen AI?
Het grootste voordeel is dat je je eigen gesprekken en gedachten permanent bruikbaar maakt. Veel mensen hebben intensieve gesprekken met AI-systemen over projecten, ideeën, analyses of persoonlijke kwesties. Deze inhoud verdwijnt meestal in de loop van het platform. Als je het echter exporteert en integreert in je eigen kennisdatabase, wordt het een persoonlijk archief. Je lokale AI kan dan toegang krijgen tot deze inhoud, verbanden herkennen en je helpen met nieuwe vragen. In plaats van altijd vanaf nul te beginnen, bouw je stap voor stap voort op je eigen denkwijze. - Is dat niet erg ingewikkeld voor iemand die geen ontwikkelaar is?
Op het eerste gezicht lijken termen als embeddings, vector databases of RAG systemen complex. In de praktijk zijn de afzonderlijke stappen echter relatief duidelijk gestructureerd. Je hebt in principe maar drie componenten nodig: een lokale AI (bijvoorbeeld via Ollama), een vectordatabase zoals Qdrant en een klein Python-script dat je gegevens verwerkt. Veel van de stappen worden automatisch uitgevoerd. Zodra het systeem is opgezet, werkt het als een normale zoekmachine of chatbot - behalve dat het werkt met je eigen kennis. - Welke gegevens bevat de ChatGPT-export eigenlijk?
De ChatGPT-export bevat meestal alle gesprekken die je met het systeem hebt gevoerd. Dit omvat niet alleen de tekstberichten zelf, maar ook metadata zoals gesprekstitels, tijdstempels en structurele informatie. De gegevens zijn meestal beschikbaar in JSON-formaat en kunnen daarom relatief eenvoudig worden verwerkt met scripts. In veel gevallen bevat de export ook media- of taalbestanden als deze werden gebruikt in de gesprekken. Het is echter vooral de tekstinhoud die van belang is bij het maken van een kennisdatabase. - Waarom wordt voor dergelijke systemen een vectordatabase gebruikt en geen normale database?
Normale databases zijn ideaal voor het zoeken naar specifieke termen of ID's. Ze zijn echter minder geschikt voor semantische zoekopdrachten. Ze zijn echter minder geschikt voor semantische zoekopdrachten. Een vectordatabase slaat teksten niet alleen op als tekenreeksen, maar ook als wiskundige vectoren die de betekenis van een tekst beschrijven. Hierdoor kan het systeem zoeken naar overeenkomsten in de inhoud. Als je bijvoorbeeld vraagt naar „AI artikel ideeën“, kan de database ook inhoud vinden die andere zinnen bevat, zoals „onderwerpen voor blogartikelen over kunstmatige intelligentie“. - Wat zijn embeddings en waarom zijn ze zo belangrijk?
Embeddings zijn wiskundige representaties van teksten. Een taalmodel zet een tekst om in een lijst getallen die de betekenis van de tekst beschrijven. Teksten met gelijkaardige betekenissen liggen dicht bij elkaar in de wiskundige ruimte. Hierdoor kan een vector database later zoeken naar gelijkaardige inhoud. Zonder embeddings zou semantisch zoeken nauwelijks mogelijk zijn. Ze vormen de basis van moderne RAG-systemen en zijn de reden waarom dergelijke systemen veel flexibeler zijn dan klassieke full-text zoekopdrachten. - Hoe groot kan mijn ChatGPT-gegevensexport zijn?
De grootte speelt geen grote rol. Zelfs enkele duizenden conversaties kunnen zonder problemen worden verwerkt. Wat belangrijker is, is het aantal gegenereerde tekstdelen, de zogenaamde chunks. Een grotere uitvoer leidt tot meer chunks en dus meer inbeddingen. Moderne vectordatabases kunnen echter gemakkelijk miljoenen van dergelijke vermeldingen beheren. Zelfs een kleine server of een krachtige desktop is volledig voldoende voor een eigen kennisassistent. - Waarom is de tekst vóór de verwerking opgedeeld in kleine delen?
Als je volledige conversaties of grote teksten rechtstreeks als embedding opslaat, wordt het semantisch zoeken onnauwkeurig. Een enkele tekst kan meerdere onderwerpen bevatten. Door de tekst op te delen in kleinere secties, kan het systeem later veel preciezer zoeken. Elke sectie beschrijft een duidelijker onderwerp. Hierdoor kan de database precies die delen van een gesprek vinden die echt bij de huidige vraag passen. - Welke rol speelt Ollama in dit systeem?
Ollama dient als lokaal platform voor taalmodellen. Hiermee kun je AI-modellen direct op je eigen computer draaien. In ons systeem vervult Ollama twee taken: Het creëert embeddings voor teksten en genereert antwoorden op vragen. Het voordeel is dat alle gegevens lokaal blijven. Dit betekent dat je gesprekken en je kennisarchief nooit je eigen computer verlaten. - Waarom wordt Qdrant gebruikt als vectordatabase?
Qdrant is een moderne vectordatabase die speciaal ontwikkeld is voor AI-toepassingen. Het is snel, eenvoudig teTP12tieren en zeer goed gedocumenteerd. Het kan ook gemakkelijk worden gekoppeld aan Python en veel AI-frameworks. Qdrant is daarom een bijzonder praktische oplossing voor lokale kennissystemen. Alternatieven zijn Chroma, Weaviate of Pinecone. - Wat betekent de term RAG-systeem?
RAG staat voor „Retrieval-Augmented Generation“. Dit is een architectuur waarbij een AI eerst relevante informatie ophaalt uit een database en deze vervolgens gebruikt om een antwoord te genereren. De AI combineert dus zijn eigen kennis met externe gegevens. Hierdoor kan het zeer nauwkeurige antwoorden geven en tegelijkertijd toegang krijgen tot actuele of persoonlijke informatie. - Kan ik ook andere gegevensbronnen in dit systeem integreren?
Dit is zelfs een van de grootste voordelen van deze architectuur. Het systeem is niet beperkt tot ChatGPT-gegevens. U kunt ook uw eigen artikelen, notities, PDF's, onderzoekspapers of andere documenten integreren. Zolang de inhoud in tekstvorm kan worden verwerkt, kan het onderdeel worden van de kennisbank. Na verloop van tijd zal uw systeem uitgroeien tot een uitgebreid kennisarchief. - Hoe actueel blijft zo'n kennissysteem?
De actualiteit hangt af van hoe vaak je nieuwe gegevens importeert. Je kunt bijvoorbeeld regelmatig nieuwe ChatGPT-exports verwerken of een script maken dat automatisch nieuwe documenten herkent. Veel systemen zijn zo ingesteld dat ze één keer per week of één keer per maand worden bijgewerkt. Zo blijft de kennisbank altijd up-to-date. - Welke hardware heb ik nodig voor een dergelijk systeem?
Een moderne desktopcomputer is voldoende voor kleinere projecten. Als je een groter taalmodel wilt gebruiken, kan een GPU handig zijn. Veel gebruikers draaien hun kennissystemen echter ook met succes op een krachtige laptop of mini-server. Bovenal is het belangrijk om voldoende geheugen en voldoende opslagruimte voor de database te hebben. - Hoe snel werkt zo'n systeem in de praktijk?
De snelheid hangt af van verschillende factoren, bijvoorbeeld de grootte van de database, de hardware en het gebruikte taalmodel. In veel gevallen duurt een zoekopdracht slechts enkele seconden. De vectorzoekopdracht zelf is meestal extreem snel. Het grootste deel van de tijd wordt vaak besteed aan het genereren van het antwoord van het taalmodel. - Is het mogelijk om verschillende kennisgebieden van elkaar te scheiden?
Ja, vectordatabanken zoals Qdrant laten het gebruik van meerdere collecties toe. Elke collectie kan een apart onderwerp vertegenwoordigen. Je kunt bijvoorbeeld een collectie aanmaken voor ChatGPT-gesprekken, één voor artikelen en één voor notities. Zo kunnen kennisgebieden duidelijk gestructureerd en gericht doorzocht worden. - Hoe veilig zijn mijn gegevens in een lokaal AI-systeem?
Het grote voordeel van een lokaal systeem is dat je gegevens niet naar externe diensten hoeven te worden overgebracht. Alle informatie blijft op je eigen computer of server staan. Dit is vooral interessant voor gevoelige inhoud. Natuurlijk moet je nog steeds regelmatig back-ups maken en je systeem beschermen tegen ongeautoriseerde toegang. - Kan ik dit systeem ook integreren in mijn eigen applicaties?
Ja, de meeste componenten zijn toegankelijk via programmeerinterfaces. Hierdoor kunt u uw kennissysteem integreren in uw eigen tools, bijvoorbeeld in een webinterface, een redactiesysteem of een notitie-app. Veel ontwikkelaars bouwen kleine applicaties die hun kennisdatabase direct toegankelijk maken via een chatinterface. - Hoe zou deze technologie zich in de toekomst kunnen ontwikkelen?
Persoonlijke kennis-AI's staan waarschijnlijk nog maar aan het begin van hun ontwikkeling. In de toekomst kunnen dergelijke systemen automatisch nieuwe inhoud integreren, samenvattingen maken of zelfs hun eigen suggesties voor projecten geven. Hoe meer gegevens er in zo'n systeem stromen, hoe waardevoller het wordt. Op de lange termijn zou het zich kunnen ontwikkelen tot een soort persoonlijk digitaal geheugen dat je kennis structureert en op elk moment toegankelijk maakt.